読者コミュニティ|競馬予想で始める機械学習
書き込み数が上限に達したので、取り急ぎ新しいコミュニティを作りました!
いつも動画大変勉強なってます。
動画では2019年レースデータをスクレイピングして予想が始まりましたが、
2020年のレースデータを予想で読み込みたいときは、2020年のレースデータをスクレイピングし、
2019年のデータと結合して、新たにファイルをつくるのでしょうか。
動画で2020年のデータも予想に使っていると言っていましたが、どこでデータを更新したのか見つけることができませんでした。教えてください。
この動画で2020年のデータを追加しています!
ありがとうございます。
動画さがしていました。助かります。。
もう一つ質問なんですが、単勝回収値のグラフを作成すると、
最高が1.9,最低が1.3のおかしなグラフになってしまいます。
考えられる原因ってなにが挙げられますか。教えてください。。
ごめんなさい、ここソースコードのミスでした!
test → trainに修正しておいたので、これで正しくモデル学習ができると思います。
yuyaさん
len()で分割し確認したとこ、おっしゃる通りでした。
コード書きなおし、実行すると動画に近い値となりました。
お騒がせしました。
修正いただきましてありがとうございます。
当方、仕事で機械学習・ディープラーニングを用いたシステム開発をしております。
色々な特徴量で回収率アップトライ中ですので、また別途コメントで紹介させていただけたらと思います。
今後ともどうぞよろしくお願いいたします。
僕自身もまだまだ機械学習の勉強途中なので、何かお気付きの点があればぜひコメントいただけると嬉しいです!
今後ともよろしくお願いいたします。
def merge(self, results, date):
dd = self.merged.copy()
dd = dd[dd["date"]<date] #今回使用する過去戦績
df = results[results['date']==date] #dateで指定された日のレース結果
horse_id_list = df['horse_id'] #dateで指定された日に出走した馬のリスト
dict_r = {}
sample_hi_list = dd["horse_id"].unique() #初出走ではない、過去戦績のある馬のリスト
for horse_id in horse_id_list:
if horse_id in sample_hi_list: #過去戦績をもつ馬について
horse_r = df[results["horse_id"]==horse_id]
n_sample = 1 #前走について
a = dd.copy()
a = a[a["date"]<date].sort_values('date', ascending=False).groupby(["horse_id"]).get_group(horse_id)[n_sample-1:n_sample]
a = a.rename(columns={'枠番':'枠番_{}R'.format(n_sample), '騎手':'騎手_{}R'.format(n_sample), ... #前走競走情報として扱うので列名を_1Rに直す
n_sample = 2 #前々走について
b = dd.copy()
b = b[b["date"]<date].sort_values('date', ascending=False).groupby(["horse_id"]).get_group(horse_id)
if len(b) >= 2: #過去戦績が2レース分以上ある場合
b = b[n_sample-1:n_sample]
b = b.rename(columns={'枠番':'枠番_{}R'.format(n_sample), '騎手':'騎手_{}R'.format(n_sample),... #前々走競走情報として扱うので列名を_2Rに直す
else: #過去戦績が1走分しか無い場合
b = b[b["date"]<date].sort_values('date', ascending=False).groupby(["horse_id"]).get_group(horse_id)[0:1]
b.loc[0, ['枠番', '騎手'... = 0 #前々走部分は0の値で扱う
n_sample = 7 #近7走分について、賞金など平均を求める
c = dd.copy()
c = c[c["date"]<date].sort_values('date', ascending=False).groupby(["horse_id"]).get_group(horse_id).head(n_sample)...
horse_r = horse_r.merge(a, on="horse_id", how="left")
horse_r = horse_r.merge(b, on="horse_id", how="left")
horse_r = horse_r.merge(c, on="horse_id", how="left")
dict_r[horse_id] = horse_r
else:
horse_r = df[results["horse_id"]==horse_id]
dict_r[horse_id] = horse_r
self.merged_df = pd.concat([dict_r[key] for key in dict_r])
return self.merged_df
def merge_all(self, results):
date_list = results['date'].unique()
self.merged_df = pd.concat([self.merge(results, date) for date in tqdm(date_list)])
self.merged_df["中9週"] = (self.merged_df["date"] - self.merged_df["date_1R"]) > "65 days"
self.merged_df["中9週"] = self.merged_df["中9週"].astype(int) #ついでに列を20ほど追加
return self.merged_df
質問失礼いたします。
長かったので部分的に端折っておりますが、上記のような形でhr.merge_all を前走・前々走・7走平均で
欲しい特徴量を加えていきました。
このhr.merge_allを2019年分のデータについて(110日分と出ています)行うと、処理に6時間くらいかかる見込みなのですが、merge_allはこのくらい処理時間掛かるものなのでしょうか?
それとも、自作したコードにものすごく時間が掛かる部分が出てきてしまったのでしょうか?
詳しい方教えて頂けるとたすかります!m(__)m
110日分のデータで6時間は結構時間がかかっていますね。
おそらくhorse_id_listを回すfor文の処理が重いのだと思うのですが、ぱっと見ただけではどこに処理時間がかかっているのかわからないので、for文の中のコードを取り出して%%timeitなどをを使って処理時間を計測するか、
import time
def merge(self, results, date):
#省略
t1 = time.time()
n_sample = 7 #近7走分について、賞金など平均を求める
c = dd.copy()
c = c[c["date"]<date].sort_values('date',ascending=False).groupby(["horse_id"]).get_group(horse_id).head(n_sample)...
t2 = time.time()
break
などのようにすれば、
t2-t1
で、挟まれた部分の処理にかかった時間がわかるので、これでどのコードに時間がかかっているのか検証して見てください。
ありがとうございます。
良い改善方法が表現できず、とりあえず時間掛けて実行しています。
主さんの製作方法を参考に自分なりに特徴量なり加えて4年分くらいのデータでモデルを学習→今週3日間予想 までやってみたのですが、
データをsplitさせて学習→テストの段階ではpredの結果を見る限り納得できる確率(明らかに来そうな人気馬のpredが0.5〜0.8)が算出されるのですが、
実際に出馬表をmeクラスで予想させると同じような明らかに来そうな人気馬のpredが平気で0.1と算出したり、ちょっと理解できない結果が表示されたのですが、モデル作成の時点と実際の予想とでこんなにも性格が変わることってあるのでしょうか?
過学習を抑えようとパラメータを弄る過程でfeature fractionを0.05〜0.2程度まで低くしていました。kaggleの本を読むには0.6〜0.95くらいが典型的な設定みたいですね...。
これくらいの設定ですと、学習結果がデタラメになるのでしょうか?(auc scoreは80.4/80.0でした)
学習データは予想した日の直前までのものを使っていますか?
実際に予想する日に対して学習データ(特にhorse_resultsデータ)の日にちが離れていると、最近の成績が反映されず、精度の良い学習ができない可能性があります。
なのでテストをするときは訓練データとテストデータを分けますが、実際に使うときは全て訓練データにしたほうが良いかもしれません。
2017〜2020年データを使っているので、一応直近と言えば直近とは思うのですが...。
lightgbmが難しいので一旦、ランダムフォレストに戻ってモデルやり直しています。
また、以前merge_all関数でhorse_idを回すところでかなり時間か掛かっていた件ですが、自分が扱いたかった過去n走前のレコードについては、groupby(horse_id).nth(n)で満足いく処理が出来ることに気が付き、解決しました😅
素晴らしい動画をいつもありがとうございます。
Chapter 04
機械学習モデル作成&学習
を参考にoptunaによるハイパーパラメータチューニングを実行しています。
しかし、optunaを実行するたびにハイパーパラメータの値が変わるため、
その後のLightGBMの学習結果も毎回異なってしまいます。
期待値としては毎回同じ結果が欲しいのですが、そのようなやり方はないのでしょうか?
<実行1回目のlgb_clf_o.params>
{'objective': 'binary',
'random_state': 100,
'feature_pre_filter': False,
'lambda_l1': 2.763814491446932e-07,
'lambda_l2': 4.848539250253659e-07,
'num_leaves': 31,
'feature_fraction': 0.7,
'bagging_fraction': 1.0,
'bagging_freq': 0,
'min_child_samples': 25,
'num_iterations': 1000,
'early_stopping_round': 10}
<実行2回目のlgb_clf_o.params>
{'objective': 'binary',
'random_state': 100,
'feature_pre_filter': False,
'lambda_l1': 3.1893294433877453e-07,
'lambda_l2': 3.534217732516116e-07,
'num_leaves': 31,
'feature_fraction': 0.7,
'bagging_fraction': 1.0,
'bagging_freq': 0,
'min_child_samples': 25,
'num_iterations': 1000,
'early_stopping_round': 10}
そうなんですよね、random_stateを固定しているにもかかわらず結果が変わってしまうのでおかしいと思い、僕も原因を調べているのですが、ちょっとまだ分からないです・・・
返信ありがとうございます。
やはり毎回結果が変わってしまうのですね。
毎回結果が変わるものなのか、固定するやり方があるのか、今の私の知識ではわかりませんが、
もし解決したら教えていただけるとありがたいです。
これからも動画楽しみにしています。
購読させていただいている者です。update_data(old, new)関数の具体的な利用方法を教えていただきたいです!
update_data(古いDataFrame, 新しいDataFrame)
でデータを更新します!(Chapter02参照)
ご返信ありがとうございます!
無事利用することができました!
重ねてのご質問となるのですが、
本コードではthresholdを0.5としています。
「pred値が〜以上の場合に賭けると良い」といった
thresholdの最適化?のような操作は行わなくてよろしいのでしょうか?
また、具体的な方法があれば教えていただきたいです!
私自身、機械学習初学者であり分かりにくい文章で申し訳ないです…
シミュレーションの章のコードを見ると分かりますが、threshold=0.5はあくまで初期値で、thresholdを0.5から1まで変化させることで賭ける枚数を変化させて回収率をプロットしています。
なので、回収率でthresholdを最適化をすると「thresholdは大きく設定すればするほど良い」ということになります。
実際にはそれだと月に数枚しか賭けないことになるので、どれくらい競馬を楽しみたいかによって賭ける枚数は増やすことになりそうですが。
更新ありがとうございます。
更新箇所はリンクにしたらいかがしょうか?
そうすることで探す手間も省けるかと。
よろしくお願いいたします。
たしかに、そのほうが良いですね!
【競馬予想】Pythonでスクレイピングして過去成績を入れた出馬表を作る方法【データ分析】のコメントで
Che Che さんの質問にあるように動画の12分15秒で
1 st = ShutubaTable()
2 st.scrape_shutuba_table(['202006010101'])
を実行すると全く同じエラーが出ていたのですが
Headlessモードを有効にすることで解決しました。
import time
options.set_headless(True)
url = 'https://race.netkeiba.com/race/shutuba.html?race_id=202106010407'
options = ChromeOptions()
sample_driver = Chrome(options=options)
sample_driver.get(url)
いつもありがとうございます。
本や動画を参考に、一部特徴量を除けば目的変数の設定(1着なら1、他は0)、採用モデルという点でほぼほぼ同じような予測モデルでやらしていただいています。
ところが、モデルの評価まではまずまずのスコアが出るのですが、実際に未知データ(2021年のレース)を与えて予測させてみると、大概の馬がpred=0.005とかになり、各レース1頭ずつくらいでpred=0.28の馬がいる、というような予測結果になります。
皆さんはこんな感じの予測結果になることはありますか?
目的変数が1≒8%、0≒92%と不均衡なためこのような予測結果になるのでしょうか。。。
ご教示ください🙇🙇🙇
predはLightGBMで予測された値をそのまま使っていますか?
それとも、僕のモデルのように標準化やmin-maxをかけたものですか?
ありがとうございます。
predはlightGBMで予測された値をそのまま使用しています。
試しにCatBoostでも予測してみたのですが、似たような予測結果になりました。
具体的には、中山ですと内田・横山典。中京ですと幸・和田が騎乗する馬ばかりが上位スコアになり、ほかの馬はすべて一定のきわめて小さな値が算出されています...。
なるほど、騎手だけが重要視されてしまっている感じですね。
feature_imporanceをみるとどうなっていますか?
違う特徴量を使っているということなので、もしかしたらその特徴量の中だと騎手を重要視せざるを得ないという可能性もあります。
もう一つの可能性としては、僕のモデルと同じようにLightGBMのcategorical_featuresを使っている場合、その列を重要視しすぎてしまう場合があります。なので方法としては
- categorical_featuresを使わずにLabelEncodingで止める
- early_stoppingを使う
などがあるかなと思います。
質問が2点あります。
①Resultsについて(Chapter3)
Resultsクラスのpreprocessing関数内の馬体重を体重と体重変化に分割する箇所ですが、
馬体重に「計不」があり整数型へキャストできません。
df = df[df["馬体重"] != '計不']
として排除して対応していますがどうするべきなのでしょうか?
②出馬表データの加工について(Chapter3)
no_pedsへの対処ですが、変数pedsはどこで定義しているのでしょうか?
そのようなものはデータ数として少ないでしょうし、排除してしまっても良いと思います。それか、欠損値にするのもありだと思います。
df['体重'] = df['馬体重'].str.split("(", expand=True)[0]
df['体重'] = pd.to_numeric(df['体重'], errors='coerce')
で、キャストできない場合は欠損値にしてくれます。
ご回答ありがとうございます。②については如何でしょうか?
no_pedsへの対処ですが、以下を追加してから処理すれば問題ないと思います。
peds = pd.read_pickle('peds.pickle')
私もまだまだ勉強中ですが、助けになれば幸いです。
実践的な動画で大変勉強なってます。
エラーが出ても挫折することなく続けられる内容になっていますね。
質問なんですが
2019年分と2021年分は正常に変換できるのですが
2020年分だとエラーになってしまいます。
対処方法を教えてください。お願いします。
Returnクラス
def fukusho(self):
fukusho = self.return_tables[self.return_tables[0]=='複勝'][[1,2]]
wins = fukusho[1].str.split('br', expand=True).drop([3], axis=1)
wins.columns = ['win_0', 'win_1', 'win_2']
returns = fukusho[2].str.split('br', expand=True).drop([3], axis=1)
returns.columns = ['return_0', 'return_1', 'return_2']
df = pd.concat([wins, returns], axis=1)
for column in df.columns:
df[column] = df[column].str.replace(',', '')
return df.fillna(0).astype(int)
ValueError Traceback (most recent call last)
<ipython-input-12-1c79a4487a71> in <module>
1 rt = Return(return_tables_2020)
----> 2 rt.fukusho
<ipython-input-5-fdc8134a3438> in fukusho(self)
61 fukusho = self.return_tables[self.return_tables[0]=='複勝'][[1,2]]
62 wins = fukusho[1].str.split('br', expand=True).drop([3], axis=1)
---> 63 wins.columns = ['win_0', 'win_1']
64 # wins.columns = ['win_0', 'win_1', 'win_2']
65 returns = fukusho[2].str.split('br', expand=True).drop([3], axis=1)
~\anaconda3\lib\site-packages\pandas\core\generic.py in setattr(self, name, value)
5150 try:
5151 object.getattribute(self, name)
-> 5152 return object.setattr(self, name, value)
5153 except AttributeError:
5154 pass
pandas_libs\properties.pyx in pandas._libs.properties.AxisProperty.set()
~\anaconda3\lib\site-packages\pandas\core\generic.py in _set_axis(self, axis, labels)
562 def _set_axis(self, axis: int, labels: Index) -> None:
563 labels = ensure_index(labels)
--> 564 self._mgr.set_axis(axis, labels)
565 self._clear_item_cache()
566
~\anaconda3\lib\site-packages\pandas\core\internals\managers.py in set_axis(self, axis, new_labels)
224
225 if new_len != old_len:
--> 226 raise ValueError(
227 f"Length mismatch: Expected axis has {old_len} elements, new "
228 f"values have {new_len} elements"
ValueError: Length mismatch: Expected axis has 4 elements, new values have 2 elements
1
横から失礼します。自分も同じような現象が起きましtが以下のコードで解決しております。
def fukusho(self):
fukusho = self.return_tables[self.return_tables[0]=='複勝'][[1,2]]
wins = fukusho[1].str.split('br', expand=True).drop([3,4], axis=1)
wins.columns = ['win_0', 'win_1', 'win_2']
returns = fukusho[2].str.split('br', expand=True).drop([3,4], axis=1)
returns.columns = ['return_0', 'return_1', 'return_2']
df = pd.concat([wins, returns], axis=1)
for column in df.columns:
df[column] = df[column].str.replace(',', '')
return df.fillna(0).astype(int)
詳しく言うと、
3行目の、wins = fukusho[1].str.split('br', expand=True).drop([3,4], axis=1)
↑4を追加
5行目の、wins = fukusho[2].str.split('br', expand=True).drop([3,4], axis=1)
↑4を追加
なぜか2020年度のは不要なカラムがあるためそこを切り落とさないとエラーが起きるようです。
mawari web さん
返信ありがとうございます。
問題が解決しました。助かりました。
何日も悩んでいたのでこれでゆっくり眠れます。
ありがとうございました。
はじめまして。
質問するのも恥ずかしいレベルの初心者です。
競馬Aiを作りたく現在勉強中です。
見よう見まねでコードを打っておりますが、エラーが出てしまい対処方法が
わかりません。
定義されてないというエラーなのですがどういうことなのでしょうか。
何度打ち直してもエラーになります。
def scrape_race_results(race_id_list):
race_results = {}
for race_id in race_id_list:
url = "https://db.netkeiba.com/race/" + race_id
race_rasults[race_id] = pd.read_html(url)[0]
return race_results
race_id_list = ["201901010101","201901010102","201901010103"]
test = scrape_race_results(race_id_list)
NameError Traceback (most recent call last)
<ipython-input-1-101a93d83cbe> in <module>
1 race_id_list = ["201901010101","201901010102","201901010103"]
----> 2 test = scrape_race_results(race_id_list)
NameError: name 'scrape_race_results' is not defined
初歩的な質問で大変恐縮ですがよろしくお願いします。
def scrape_race_results(race_id_list):
race_results = {}
for race_id in race_id_list:
url = "https://db.netkeiba.com/race/" + race_id
race_rasults[race_id] = pd.read_html(url)[0]
return race_results
のコードは下のようにインデントを入れていますか?
def scrape_race_results(race_id_list):
race_results = {}
for race_id in race_id_list:
url = "https://db.netkeiba.com/race/" + race_id
race_rasults[race_id] = pd.read_html(url)[0]
return race_results
いつもためになる動画やソースコードをありがとうございます。
毎回大変勉強させていただいております。
今後の開発ロードマップで修正予定とされている単勝適正回収値についてですが、
モデルの評価指標として重要な部分だと思いますので優先的に修正いただけると非常に助かります。
ご参考までに汚いコードですが、修正したものを添付させて頂きます。
一応計算結果に間違いはないと思いますが、その辺りも含めてお返事いただけますと幸いです。
修正のソースコード、ありがとうございます!
そうですね、重要な部分なのでなるべく早く修正できるようにします。
修正しようとしたのですが、よく考えたらレース結果にある単勝オッズのデータはレース終了後に確定しているものなので、払い戻し金額を基準にして計算した場合と同じになります。実際に単勝オッズを100倍したものと払い戻し金額を比較すると全てのデータで一致しました。
実際にはレース開始直前の単勝オッズと終了後の単勝オッズは異なりますが、今取れているデータを使ってシミュレーションするなら今の評価指標のままで良いかなと思います。
コメントありがとうございます。
確かに当たり馬券の単勝オッズは、払い戻し表にある単勝の金額のちょうど1/100になるかと思います。
しかし、払い戻し表には勝ち馬の払い戻し金額しか記載されていないので、ハズレ馬券に関しては払い戻し表からオッズを算出することはできないかと思います。
例えば、以下のような例を考えると分かり易かと思います。
<昨年の第50回高松宮記念>(https://db.netkeiba.com/race/202007010811/)
「レース結果」
1位:モズスーパーフレア(オッズ:32.3倍)
2位:グランアレグリア(オッズ:4.1倍)
3位:ダイアトニック(オッズ:9.2倍)
・・・
「払い戻し」
単勝:3,230円
このレースに関してモデルが「モズスーパーフレア」にかけると判断した場合、賭け金は10,000円/32.3≒300円となります。この場合の32.3は払い戻し表の3,230円を100で割って算出する現行のtansho_return_properでの計算と一致します。
しかし、モデルが「グランアレグリア」にかけると判断した場合、賭け金は10,000円/4.1≒2,400円となりますが、現行のtansho_return_properでは「モズスーパーフレア」にかける場合と同額の300円をかけることになります。
予想する馬券の全てが的中する場合は現在のtansho_return_properでも問題ないかと思いますが、そうではない限りにおいてはやはりレース結果のテーブルにある単勝オッズを用いて算出するべきかと思います。
確かにその通りでした。的中していない馬について、賭ける金額が異なってくるのを完全に見落としていました・・・
次の動画で修正予定です!
ありがとうございます!動画楽しみにしております!
今後も質問させていただくこともあろうかと思いますが宜しくお願い致します。
当該修正を行った場合、回収率が芳しくありません。やはりリークが影響しているのでしょうか。。。
次に出す動画で詳しく話しますが、修正すると回収率下がります。
具体的には、今までの計算方法だと「賭ける馬の単勝オッズ」が低い馬にも「結果1着になった馬の単勝オッズ」が高い時には、低い金額を賭けていることになります。
つまり、「あらかじめレースが荒れるかどうかを知っている」ことになっていて、このため今の単勝適正回収値は実際よりも高いものになってしまっています。
この点は完全に見落としていました。。。申し訳ありません。
謝っていただくことではありません!訂正があったとしても競馬予想動画シリーズが素晴らしいものに変わりないので、今後ともよろしくお願いします。
ありがとうございます!修正入れました。
初めまして! 動画を見て本を購読しました、現在勉強中の者です。
本にある通りにコードを打っていき、何とか無事?にoptunaのハイパーパラメータチューニングにまで進みましたが、lgb_clf_o.paramsで実行したら、
TypeError: float() argument must be a string or a number, not 'Timestamp'
というエラーメッセージが表示されました。
検索してみてもサッパリ…。正直手詰まりです。
教えて頂けませんでしょうか。お願いします!
Timestampは日付や時刻を表すときの型なので、おそらくdateの列がデータに入っているのだと思います。なので訓練データとテストデータからdate列を除いてください。
ありがとうございます!
早速試してみます!
こんにちは。
現在、2021/01/24にアップされた「競馬予想AIの単勝回収率が159%に到達!馬の得意なコースを機械学習で判定させる方法とは?」をもとにコードを打ち進めているのですが、エラーが出てしまって止まっています。
クラスの中身を変更したあと下の手順の通り実行しました。
r = Results.read_pickle(['results.pickle'])
r.preprocessing()
hr = HorseResults.read_pickle(['horse_results.pickle'])
r.merge_horse_results(hr, n_samples_list=[5, 9, 'all'])
p = Peds.read_pickle(['peds.pickle'])
p.encode()
r.merge_peds(p.peds_e)
r.process_categorical()
race_id_list = ['2021060108{}'.format(str(i).zfill(2)) for i in range(1, 2, 1)]
st = ShutubaTable.scrape(race_id_list, '2021/01/24')
※↑とりあえず1レース分だけ抜き出しています。
st.preprocessing()
ここまではいままでどおり、いけてたんですが
st.merge_horse_results(hr)
↑を実行したらエラーがでてしまいました。
エラー文は
KeyError: '開催'
となっています。
自分でも調査進めていますが、原因をご教授いただければ幸いです。
よろしくお願いいたします。
たぶん解決しました。
class ShutubaTable(DataProcessor):
#前処理
def preprocessing(self):
~中略~
不要な列を削除→どの列を使うか
df = df[['枠', '馬番', '斤量', 'course_len', 'weather','race_type',
'ground_state', 'date', 'horse_id', 'jockey_id', '性', '年齢',
'体重', '体重変化','開催']]
↑ こいつが入っていませんでした。
これでKEYERRORはなくなると思います。
コメントありがとうございます。
ご指摘の通り修正しました。あと本家の動画コメントにあります通りShutubaTableクラスのpreprocessing関数の中で「 df['開催'] = df.index.map(lambda x:str(x)[4:6])」をしたうえで上記の修正内容をfixさせないといけなかったようです。
無事解決できました。ありがとうございました。
いつもありがとうございます。
現在は、馬の情報がメインで学習結果が算出されていると思うのですが、馬の過去レース結果+騎手の過去レース結果みたいな感じでできないものなのでしょうか?
初心者的な考えで申し訳ございません。。
騎手の過去レース結果も入れたいですよね!
特徴量の重要度でjockey_idがかなり上の方に来てますが今のところカテゴリ変数として直接入れているだけなので。
騎手のデータは数ページに渡るので、少しスクレイピングが面倒でまだやっていないですが、そのうちやりたいと思っています。
ありがとうございます!!
M1チップのmacで、
この教材のためのimportなどうまくできた方、selenium、numpy、pandasなどのインストールの方法
やり方教えていただけませんでしょうか?
M1チップのmacでも可能でしょうか?
windowsPCの買い替えを検討しています。
著者の方や読者の方でm1のmacを使用されているかたはいらっしゃいますか?
何かと設定が複雑と聞いたので、上記の環境設定について確証を得てから購入したいものです。
僕はM1チップのmac使ってますよ!
インストール方法など基本的には旧モデルのmacと変わらなかったです。
シェルがzshというものになっていることだけ注意すれば、という感じです。(今言われても何のことか分からないかもしれないですが書いておきますね)
以下の定義の追加が必要だと思います。
class HorseResults 中の
#開催場所
df['開催'] = df['開催'].str.extract(r'(\D+)')[0].map(place_dict).fillna('11')
↑
place_dictの定義(動画の中ではありましたが)
#race_type
df['race_type'] = df['距離'].str.extract(r'(\D+)')[0].map(race_type_dict)
↑
race_type_dict定義
place_dict={
"札幌":"01","函館":"02","福島":"03","新潟":"04","東京":"05",
"中山":"06","中京":"07","京都":"08","阪神":"09","小倉":"10"
}
race_type_dict={
"芝":"芝","ダート":"ダ","障害":"障"
}
を追加ですかね??
その後
#前処理
st.preprocessing()
#馬の過去成績データの追加。新馬はNaNが追加される
st.merge_horse_results(hr)
まで進めましたが、その際に
KeyError Traceback (most recent call last)
<ipython-input-50-f2b92f817292> in <module>
3
4 #馬の過去成績データの追加。新馬はNaNが追加される
----> 5 st.merge_horse_results(hr)
<ipython-input-16-eaf84c8c2324> in merge_horse_results(self, hr, n_samples_list)
14 self.data_h = self.data_p.copy()
15 for n_samples in n_samples_list:
---> 16 self.data_h = hr.merge_all(self.data_h, n_samples=n_samples)
17 self.data_h.drop(['開催'], axis=1, inplace=True)
18
<ipython-input-38-a6232dc9026e> in merge_all(self, results, n_samples)
136 def merge_all(self, results, n_samples='all'):
137 date_list = results['date'].unique()
--> 138 merged_df = pd.concat([self.merge(results, date, n_samples) for date in tqdm(date_list)])
139 return merged_df
<ipython-input-38-a6232dc9026e> in <listcomp>(.0)
136 def merge_all(self, results, n_samples='all'):
137 date_list = results['date'].unique()
--> 138 merged_df = pd.concat([self.merge(results, date, n_samples) for date in tqdm(date_list)])
139 return merged_df
<ipython-input-38-a6232dc9026e> in merge(self, results, date, n_samples)
129 right_index=True, how='left')
130 for column in ['course_len','race_type', '開催']:
--> 131 merged_df = merged_df.merge(self.average_dict[column],
132 left_on=['horse_id', column],
133 right_index=True, how='left')
~\anaconda3\lib\site-packages\pandas\core\frame.py in merge(self, right, how, on, left_on, right_on, left_index, right_index, sort, suffixes, copy, indicator, validate)
7282 from pandas.core.reshape.merge import merge
7283
-> 7284 return merge(
7285 self,
7286 right,
~\anaconda3\lib\site-packages\pandas\core\reshape\merge.py in merge(left, right, how, on, left_on, right_on, left_index, right_index, sort, suffixes, copy, indicator, validate)
71 validate=None,
72 ) -> "DataFrame":
---> 73 op = _MergeOperation(
74 left,
75 right,
~\anaconda3\lib\site-packages\pandas\core\reshape\merge.py in init(self, left, right, how, on, left_on, right_on, axis, left_index, right_index, sort, suffixes, copy, indicator, validate)
625 self.right_join_keys,
626 self.join_names,
--> 627 ) = self._get_merge_keys()
628
629 # validate the merge keys dtypes. We may need to coerce
~\anaconda3\lib\site-packages\pandas\core\reshape\merge.py in _get_merge_keys(self)
1006 join_names.append(None)
1007 else:
-> 1008 left_keys.append(left._get_label_or_level_values(k))
1009 join_names.append(k)
1010 if isinstance(self.right.index, MultiIndex):
~\anaconda3\lib\site-packages\pandas\core\generic.py in _get_label_or_level_values(self, key, axis)
1690 values = self.axes[axis].get_level_values(key)._values
1691 else:
-> 1692 raise KeyError(key)
1693
1694 # Check for duplicates
KeyError: '開催'
となりました。
このクラスでスクレイピングをして、プロセッシングをしても、["開催"]がKeyで入っていないんですよね・・・見た感じだと。
解決しました。
class ShutubaTable(DataProcessor):
#前処理
def preprocessing(self):
~中略~
# 不要な列を削除→どの列を使うか
df = df[['枠', '馬番', '斤量', 'course_len', 'weather','race_type',
'ground_state', 'date', 'horse_id', 'jockey_id', '性', '年齢',
'体重', '体重変化','開催']]
↑ こいつが入っていませんでした。
- place_dict, race_type_dictの定義(HorseResultsクラスのコードの下)
- 「使用する列に開催を追加」
の2点修正しました!エラー報告ありがとうございます。
Returnクラスの単勝(複勝等も)が出力できません。
Returnクラスを本と同様に定義したあと
return_tables = Return.read_pickle(['return_tables.pickle'])
rt = Return(return_tables)
rt.tansho #jupyterで表示
とすると以下のエラーが出ます。
TypeError Traceback (most recent call last)
<ipython-input-37-adcad8812fe5> in <module>
1 return_tables = Return.read_pickle(['return_tables.pickle'])
2 rt = Return(return_tables)
----> 3 rt.tansho #jupyterで表示
<ipython-input-32-45ce5e0e672c> in tansho(self)
67 @property
68 def tansho(self):
---> 69 tansho = self.return_tables[self.return_tables[0]=='単勝'][[1,2]]
70 tansho.columns = ['win', 'return']
71
TypeError: 'Return' object is not subscriptable
どなたか原因と解決方法をご教示いただけないでしょうか。
Return.read_pickleはReturnクラスのインスタンスを返しているようなので、
以下でうまくいくのではないでしょうか?
rt = Return.read_pickle(['return_tables.pickle'])
#rt = Return(return_tables)
rt.tansho #jupyterで表示
もしくはReturnクラスのコンストラクタを使うなら以下でしょうか。
#return_tables = Return.read_pickle(['return_tables2.pickle4'])
rt = Return(pd.read_pickle('return_tables.pickle'))
rt.tansho #jupyterで表示
python自体はあまり詳しくないのですが、助けになれば幸いです。
ありがとうございます!無事解決しました。
単勝適正回収率 修正版において、ShutubaTable クラスのスクレイピングを"単勝"オッズをスクレイピングするため、以前のchrome driverを使用したバージョンにしないといけないと思うのですがいかがでしょうか?
そこで、chromedriverを使用して以前の処理+BeautifulSoupバージョンのような処理をすると、以下のような状態が発生します。
1 取消のrowだけcolumnずれを起こします。
例えば、11列に記載されているはずの情報が、10列に記載されています。
→これは、preprocessing()の段階で、その行だけ削除すれば問題ありません。
2 障害レースがある場合、本来なら右回り、左周りが書かれている部分に”芝”などの情報が入るため、通常の列+1のサイズのdfが出来てしまいます。
→ こっちのほうは厄介でした。結局、row毎、appendする前に、「障害」がある場合に、del row[17]をしてあげる必要がありました。
ソースを、一応載せておきます。ただし、このソースでスクレイピングすると時間がかかります。私のパソコンで(性能 core i 5 3470)1日分のレース(36レース)だと、8分ぐらいかかりました。
class ShutubaTable(DataProcessor):
def __init__(self, shutuba_tables):
super(ShutubaTable, self).__init__()
self.data = shutuba_tables
@classmethod
def scrape(cls, race_id_list, date):
data = pd.DataFrame()
options = ChromeOptions()
options.add_argument('--headless')
driver = Chrome(options=options)
for race_id in tqdm(race_id_list):
url = 'https://race.netkeiba.com/race/shutuba.html?race_id=' + race_id
driver.get(url)
elements = driver.find_elements_by_class_name('HorseList')
for element in elements:
tds = element.find_elements_by_tag_name('td')
race_infos = driver.find_elements_by_class_name('RaceData01')
row = []
for td in tds:
row.append(td.text)
if td.get_attribute('class') in ['HorseInfo', 'Jockey']:
href = td.find_element_by_tag_name('a').get_attribute('href')
row.append(re.findall(r'\d+', href)[0])
for race_info in race_infos:
texts = re.findall(r'\w+', race_info.text)
for text in texts:
if 'm' in text:
row.append(int((re.findall(r'\d+', text)[0])))
if text in ["曇", "晴", "雨", "小雨", "小雪", "雪"]:
row.append(text)
if text in ["良", "稍重", "重"]:
row.append(text)
if '不' in text:
row.append('不良')
# 2020/12/13追加
if '稍' in text:
row.append('稍重')
if '障' in text:
row.append('障害')
if '芝' in text:
row.append('芝')
if 'ダ' in text:
row.append('ダート')
#if "障" in text:
# print(row)#del row[17]
row.append(date)
#2/9障害レースの時に削除
if "障害" in row:
del row[17]
data = data.append(pd.Series(row, name=race_id))
time.sleep(1)
driver.close()
return cls(data)
def preprocessing(self):
df = self.data.copy()
#2/9取消の馬のために2を追加し、印と定義する。
df = df[[0,1,2,3,4,5,6,7,8,10,11,12,15,16,17,18,19]]
df.columns = ['枠', '馬番','印', '馬名', 'horse_id', '性齢', '斤量', '騎手', 'jockey_id',
'馬体重', '単勝', '人気','course_len','race_type','weather','ground_state','date']
df = df[df["印"] == '--']#2/9取消の馬を削除
df['course_len'] = df['course_len'].astype("int")
df['単勝'] = df['単勝'].astype("float")
df['人気'] = df['人気'].astype("int")
df["性"] = df["性齢"].map(lambda x: str(x)[0])
df["年齢"] = df["性齢"].map(lambda x: str(x)[1:]).astype(int)
# 馬体重を体重と体重変化に分ける
df = df[df["馬体重"] != '--']
df["体重"] = df["馬体重"].str.split("(", expand=True)[0].astype(int)
df["体重変化"] = df["馬体重"].str.split("(", expand=True)[1].str[:-1]
# 2020/12/13追加:増減が「前計不」などのとき欠損値にする
df['体重変化'] = pd.to_numeric(df['体重変化'], errors='coerce')
df["date"] = pd.to_datetime(df["date"])
df['枠'] = df['枠'].astype(int)
df['馬番'] = df['馬番'].astype(int)
df['斤量'] = df['斤量'].astype(float).astype(int)
df['開催'] = df.index.map(lambda x:str(x)[4:6])
df = df[['枠', '馬番', '斤量', 'course_len', 'weather','race_type',
'ground_state', 'date', 'horse_id', 'jockey_id', '性', '年齢',
'体重', '体重変化','開催','単勝']]
print(df)
self.data_p = df.rename(columns={'枠': '枠番'})
ソースコードありがとうございます!
現在のモデルで実際に賭けることを想定すると、馬体重などが直前でないと出馬表に入ってこないので、レース直前に1レース分スクレイピングして予測し、賭ける馬を決める感じになると思います。
なので今の段階だと直接単勝オッズを見て手動で賭ける金額を決めた方が早い気がします。
ちゃんと回収率を狙おうとするとおそらく賭ける馬は多くても1レースに一頭でしょうし、ChromeDriverだとスクレイピングに時間がかかるので、その間に単勝オッズの値も変化してしまいます。
ただ将来的には単勝オッズの値もスクレイピングして使うかもしれません。
HorseResultsクラス内の実際のコードと説明文で差異がありました。
埋め込まれている実際のコード(HorseResultsクラス内96,97行目)
self.target_list = ['着順', '賞金', '着差', 'first_corner',
'first_to_rank', 'first_to_final','final_to_rank']
説明文
"この列と着順、着差、賞金をまとめて処理したいので、preprocessing関数内でリストにして変数に保存しておきます。"
self.target_list = ['着順', '賞金', '着差', 'first_corner', final_corner,
'first_to_rank', 'final_to_rank', 'first_to_final']
説明文の方が正しいのかなと思いますが、ご確認よろしくお願い致します。
修正しておきました。ご指摘ありがとうございます!
回収率を上げるための提案として、新馬戦を除くというのはいかがでしょうか?
新馬戦は血統しか活かせず、調教やパドックといった要素が大きくなってしまうからです。
ご検討宜しくお願いします。
いつも勉強させていただいております。
さて、LightGBMによる学習で発生するエラーについてご教示ください。
「ValueError: For early stopping, at least ~」のエラーが生じたため
本誌のとおり、 パラメータからearly_stopping_roundの行を削除しましたが
解決しません。
またearly stoppingに起因するものか全くわかりませんが、複数のエラー表示
が出ております。
恐縮ですが、エラーの対処をご教示ください。よろしくお願いします。
ValueError Traceback (most recent call last)
<ipython-input-48-0f3210d7fe74> in <module>
8
9 lgb_clf = lgb.LGBMClassifier(**lgb_clf_o.params)
---> 10 lgb_clf.fit(X_train.values, y_train.values)
~\anaconda3\lib\site-packages\lightgbm\sklearn.py in fit(self, X, y, sample_weight, init_score, eval_set, eval_names, eval_sample_weight, eval_class_weight, eval_init_score, eval_metric, early_stopping_rounds, verbose, feature_name, categorical_feature, callbacks, init_model)
845 valid_sets[i] = (valid_x, self._le.transform(valid_y))
846
--> 847 super(LGBMClassifier, self).fit(X, _y, sample_weight=sample_weight,
848 init_score=init_score, eval_set=valid_sets,
849 eval_names=eval_names,
~\anaconda3\lib\site-packages\lightgbm\sklearn.py in fit(self, X, y, sample_weight, init_score, group, eval_set, eval_names, eval_sample_weight, eval_class_weight, eval_init_score, eval_group, eval_metric, early_stopping_rounds, verbose, feature_name, categorical_feature, callbacks, init_model)
610 init_model = init_model.booster_
611
--> 612 self._Booster = train(params, train_set,
613 self.n_estimators, valid_sets=valid_sets, valid_names=eval_names,
614 early_stopping_rounds=early_stopping_rounds,
~\anaconda3\lib\site-packages\lightgbm\engine.py in train(params, train_set, num_boost_round, valid_sets, valid_names, fobj, feval, init_model, feature_name, categorical_feature, early_stopping_rounds, evals_result, verbose_eval, learning_rates, keep_training_booster, callbacks)
260 try:
261 for cb in callbacks_after_iter:
--> 262 cb(callback.CallbackEnv(model=booster,
263 params=params,
264 iteration=i,
~\anaconda3\lib\site-packages\lightgbm\callback.py in _callback(env)
217 def _callback(env):
218 if not cmp_op:
--> 219 _init(env)
220 if not enabled[0]:
221 return
~\anaconda3\lib\site-packages\lightgbm\callback.py in _init(env)
187 return
188 if not env.evaluation_result_list:
--> 189 raise ValueError('For early stopping, '
190 'at least one dataset and eval metric is required for evaluation')
191
ValueError: For early stopping, at least one dataset and eval metric is required for evaluation
9 lgb_clf = lgb.LGBMClassifier(**lgb_clf_o.params)
---> 10 lgb_clf.fit(X_train.values, y_train.values)
を見ると削除前のパラメータのようですが、削除後のパラメータを使いましたか?
いつも拝見させて頂いてます。
python歴半年未満のため稚拙な質問でしたら申し訳ありません。
動画を参考に競馬予想できる形にはしましたが、私も最新の動画のように回収率が約80%になりました。
そこで回収率を上げるため以下を行いました。
・threshold値を変更する (0.5より上げる)
・predict関数の変更
①確率を生のデータに戻し、そこに単勝オッズを賭けた値(期待値)で賭ける賭けないを判定
②期待値と確率両方で判定
・上記を使い、複勝、三連複で賭ける
・特徴量削減(馬の過去データを使用しない)
・データ期間変更(2012年以降→2016年以降に変更)
これらをgain関数を使いプロットしましたがどれをやっても回収率80%あたりで収束しています。
別サイト https://result.db-keiba.com/#! で「前走馬体重(525kg以上)」&「脚質(逃)」&「距離増減(-200m)」と設定するだけで単勝回収率は100%を超えるので、本AIが80%にとどまっているのに違和感を感じております。
急ぎませんが、何か見落しや改善策などあればアドバイス頂けるとありがたいです。
このサイトで単勝回収率100%越えるときは、どの期間のものを何枚くらい賭けた時ですか?
この本のモデルでもthresholdの高いところ(賭ける枚数の少ないところ)では100%を超えているので、枚数を絞った買い方になっているのかなと思いました。
返信ありがとうございます。
確かに8年で約100枚に絞った結果でしたので100%を超えてるのだと納得いたしました。
もう一つ質問させてください。
特徴量のひとつに馬齢を使ってますが、私のモデルではfeature_importanceで確認すると最も重要なものになってます。lightgbmの中身を理解してないので的外れな質問かもしれませんが、2歳限定や3歳限定のレースがあるため、2,3歳馬の3着内数が確実に一定数生じるためと考えてます。馬齢はそのまま使っても大丈夫でしょうか?
LigthGBMは交互作用も反映するので、例えば
「馬年齢2歳で、馬の成績が〜の時は勝ちやすい」
という処理をしているかもしれないので、基本的には精度が上がるかどうかで特徴量の良し悪しは判断します。実際に馬齢を省いてみると回収率はどうなりますか?
交互作用を反映するのならあえて無くす必要はないかもしれませんね。実際馬齢省いた場合は回収率は0.01ポイント下がるので効いているようです。今後も気になる特徴量はとりあえず入れて検証するスタンスで進めようと思います。ありがとうございました。
回収率検証の際に実行ごとのぶれが大きいので、TimeSeriesSplitを用いて時系列交差検証を用いると安定かつ汎用化できる気がします(まだ実装ができていませんので検証不十分ですが…)。
ご検討ください。
過去レース結果をスクレイピングするとき、
過去動画のようにtqdmで10/150のように10まで進んだと仮定して、
その10のスクレイピング済みのものを再利用するコードにしたいです。
今、この教本にのっているコードではそうなっていないと思います。
過去動画のように、pre_race_resultsを引数に入れたいのですが、、、
今のソースコードだと関数内でDataFrame型に変換してしまっているので、
class Results:
@staticmethod
def scrape(race_id_list, pre_race_results=pd.DataFrame()):
#スクレイピング済みのrace_idを省く
race_id_list = set(race_id_list) - set(pre_race_results.index)
race_results = {}
for race_id in tqdm(race_id_list):
#同じなので省略
return pd.concat([pre_race_results, race_results_df]) #pre_race_resultsと結合
とすればできると思います。
素人で申し訳ないのですが
動画中のソースコード(第1回〜第4回)の一番最初のプログラムを打つと以下のような分が出力されます
HBox(children=(FloatProgress(value=0.0, max=7200.0), HTML(value='')))
これはどういう意味なのでしょうか、
うまく実行できていないということでしょうか。
解決策やどういう意味なのか教えていただけますでしょうか。
JupyterLabを使っていますか?
もしそうであればipywidgetsを入れてください。
(参考:https://youtu.be/zhr_MWfZahc)
返信いただきありがとうございます。
tqdmの方のダウンロードでエラーが出ていました。
そこを改善すると、動画通りプログレスバーの確認ができました。
特徴量に頭数を追加したいのですが、良い方法はありますでしょうか。
HorseResultにはもともと入っているので問題ないのですが、Resultには入っておらず、以下のコードを追加して試しましたがfor文で回しているため膨大な時間がかかります。レースIDが一致している数を数える方法なのですが…
df['num_horse'] = pd.NA
for i in range(len(df)):
df['num_horse'][i] = (df.index == df.index[i]).sum()
改善案、代替案があればご教示いただきたいです。
お世話になります。初めての書き込み失礼します。
競馬予想で始める機械学習〜完全版〜のChapter5 モデル評価の部分でエラーが出てしまい、解決できませんでしたのでこちらで質問させていただきます。
こちらが該当部分のコードです。
#ModelEvaluatorクラスのオブジェクトを作成
me = ModelEvaluator(lgb_clf, './data/scraped_data/%s/return_tables.pickle' % year)
#単勝適正回収値=払い戻し金額が常に一定になるように賭けた場合の回収率
g_proper = gain(me.tansho_return_proper, X_test)
#単勝の回収率
g_tansho = gain(me.tansho_return, X_test)
#プロット
plt.plot(g_proper.index, g_proper['return_rate'])
plt.plot(g_tansho.index, g_tansho['return_rate'])
plt.grid()
そしてエラー内容です。
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-109-257e9404f607> in <module>
3
4 #単勝適正回収値=払い戻し金額が常に一定になるように賭けた場合の回収率
----> 5 g_proper = gain(me.tansho_return_proper, X_test)
6 #単勝の回収率
7 g_tansho = gain(me.tansho_return, X_test)
<ipython-input-82-fe9216fe0c83> in gain(return_func, X, n_samples, min_threshold)
4 for i in tqdm(range(n_samples)):
5 threshold = 1 * i / n_samples + min_threshold * (1-(i/n_samples))
----> 6 n_bets, return_rate, n_hits = return_func(X, threshold)
7 if n_bets > 2:
8 gain[n_bets] = {'return_rate': return_rate,
<ipython-input-107-a4af226328d6> in tansho_return_proper(self, X, threshold)
66 def tansho_return_proper(self, X, threshold=0.5):
67 #モデルによって「賭ける」と判断された馬たち
---> 68 pred_table = self.pred_table(X, threshold)
69 n_bets = len(pred_table)
70
<ipython-input-107-a4af226328d6> in pred_table(self, X, threshold, bet_only)
34
35 def pred_table(self, X, threshold=0.5, bet_only=True):
---> 36 pred_table = X.copy()[['馬番', '単勝']]
37 print(pred_table)
38 pred_table['pred'] = self.predict(X, threshold)
/opt/anaconda3/lib/python3.8/site-packages/pandas/core/frame.py in __getitem__(self, key)
2906 if is_iterator(key):
2907 key = list(key)
-> 2908 indexer = self.loc._get_listlike_indexer(key, axis=1, raise_missing=True)[1]
2909
2910 # take() does not accept boolean indexers
/opt/anaconda3/lib/python3.8/site-packages/pandas/core/indexing.py in _get_listlike_indexer(self, key, axis, raise_missing)
1252 keyarr, indexer, new_indexer = ax._reindex_non_unique(keyarr)
1253
-> 1254 self._validate_read_indexer(keyarr, indexer, axis, raise_missing=raise_missing)
1255 return keyarr, indexer
1256
/opt/anaconda3/lib/python3.8/site-packages/pandas/core/indexing.py in _validate_read_indexer(self, key, indexer, axis, raise_missing)
1302 if raise_missing:
1303 not_found = list(set(key) - set(ax))
-> 1304 raise KeyError(f"{not_found} not in index")
1305
1306 # we skip the warning on Categorical
KeyError: "['単勝'] not in index"
return_tablesの保存先以外は特にいじっていません。gain関数やModelEvaluator, Returnクラスはそのまま使わせていただいております。また、return_tablesの中身はこのようになっており問題なく思えます。
解決法がわかる方がいらっしゃいましたら、ご教授のほど何卒よろしくお願いいたします。
お世話になっております。
現在、動画(第1回)を見てスクレイピング作業をしているのですが
スクレイピングが途中で終了してしまう問題が発生しております。
特にエラーが出て終了というわけではなく、300件ほどのデータをスクレイピングすると
処理が終わってしまいます。
この問題について、どのような原因が考えられるのか
または、対処法をご存知でしたら教えていただけると助かります。
書いてあるソースコードはほぼ動画のとおりです。
tqdmのみ自分の環境では動作しないことが判明しましたので書いておりません。
また、動画中では2019年度のデータのリストを作成していたと思いますが
2020年度のデータのリストを作成しております。
def scrape_race_results(race_id_list, pre_race_results={}):
race_results = pre_race_results
for race_id in race_id_list:
#途中でまで取得しているデータ分がある場合それらのデータをスキップ
if race_id in race_results.keys():
continue
try:
time.sleep(1)
url = 'https://db.netkeiba.com/race/' + race_id
race_results[race_id] = pd.read_html(url)[0]
except IndexError:
continue
except:
break
return race_results
race_id_list = []
#開催場所は10箇所ある
for place in range(1,11,1):
#開催場所で最大6回行われる
for kai in range(1,7,1):
#1回に付き最大12日行われる
for day in range(1,13,1):
#1日に付き12レースが開催される
for race in range(1,13,1):
race_id = '2020'\
+ str(place).zfill(2)\
+ str(kai).zfill(2)\
+ str(day).zfill(2)\
+ str(race).zfill(2)
race_id_list.append(race_id)
test = scrape_race_results(race_id_list)
処理が終わってしまうところのrace_idはわかりますか?
返信ありがとうございます。
先程スクレイピングをしたところ、202004020612のkeyを最後に
スクレイピングが終了していました。
202002020612
試しにもう一度やったところ、上記のを最後にスクレイピングが終了していました。
except:
break
のところを
except Exception as e:
print(e)
break
として、どのようなエラーが発生しているのか確認してみてください!
ありがとうございます。
指示通りに例外処理を変更して、再度スクレイピングしたところ
以下のエラーが出ました。
これはスクレイピング時にはよく出るエラーなのでしょうか?
<urlopen error [Errno 50] Network is down>
お世話になります。
2021年のスクレイピングで以下のIndexErrorが出ました。
2020年までは問題なかったのですがサイト側のソースを見ても
解決できなかったので改善案があればよろしくお願いします。
url = 'https://db.netkeiba.com/race/202110020807/'
df = pd.read_html(url)[0]
時間をあけて再度トライしてみたら難なくいけました
原因がよく分かりませんがお騒がせしました。
データが新しすぎる場合、まだデータベースの方にちゃんとデータが入っていないことがたまにあるので、それが原因かなと思います!
データ加工をしている時になぜか教科書のように賞金5R 着順5Rを表示することができません。
解決策が見つからないので教えていただきたいです。
表示される列が省略されているだけだと思います!例えば
r.data_h.iloc[:, 10:20]
と実行すれば、r.data_hの10列目〜20列目が表示できるので、これでどうですか?
無事表記することができました。ありがとうございます。
レベルの低い質問をしてすみません。
いえいえ、全然なんでも聞いてください!
optunaを利用しようとすると以下エラーが出るようになりました。
AttributeError: partially initialized module 'lightgbm' has no attribute 'Dataset' (most likely due to a circular import)
以前は出ていなかったのですが解決策に心当たりの方がいらっしゃいましたらご教授ください。
most likely due to a circular import
とあるので、lightgbmやoptuna周りのパッケージをインポートするコードをもう一度見直してみてください!
ファイル名をlightgbmとしていたためインポート先が不正になっていたことが原因でした。初歩的なミスでした。。。
お世話になっております。
最近勉強を始めた初心者なのですが、ご質問がございます。
第一回の動画を拝見させていただき、動画の内容通りにしたのですが下記エラーが出てきました。
自分なりに調べたのですが、解決できない為ご教授ください。
データ取得中にエラーが出ました。
<urlopen error [WinError 10013] アクセス許可で禁じられた方法でソケットにアクセスしようとしました。>
接続が一時的に切断されたのだと思います。
そのためにtry〜exceptを使って途中まででもデータを返すようにしているので、途中から進めてください。
途中からちょっとずつ取得したら無事にできました。
ありがとうございます。
続けてすみません。
単勝回収率を計算する際に、各レースの指数1位と指数2位の差が一定以上なら賭ける、という条件を加えることで回収率が上がると思い、実装しようと試行錯誤しましたが、力不足でうまくいきませんでした。どなたか、お助けください…。
素晴らしいアイデアだと思います。
スマートではないですが、race_idごとの指数1位、指数2位を算出して、
差を求めるやり方が私はわかりやすいです。
df_1 = pred_table.sort_values(['pred'], ascending=[False]).groupby(level=0)[['pred']].nth(0).add_suffix('_1')
df_2 = pred_table.sort_values(['pred'], ascending=[False]).groupby(level=0)[['pred']].nth(1).add_suffix('_2')
pred_table = pred_table.merge(df_1, left_index=True, right_index=True, how='left')
pred_table = pred_table.merge(df_2, left_index=True, right_index=True, how='left')
pred_table['pred_diff'] = pred_table['pred_1'] - pred_table['pred_2']
pred_table
馬番 pred pred_1 pred_2 pred_diff
202006020101 8 0.679014 0.679014 0.521127 0.157887
202006020101 7 0.236240 0.679014 0.521127 0.157887
202006020101 9 0.281369 0.679014 0.521127 0.157887
202006020101 6 0.414115 0.679014 0.521127 0.157887
202006020101 12 0.059108 0.679014 0.521127 0.157887
... ... ... ... ... ...
202106020212 3 0.068125 0.422127 0.344886 0.077242
202106020212 4 0.031521 0.422127 0.344886 0.077242
202106020212 2 0.110103 0.422127 0.344886 0.077242
202106020212 1 0.044287 0.422127 0.344886 0.077242
202106020212 10 0.293999 0.422127 0.344886 0.077242
5937 rows × 5 columns
助けになれば幸いです。
ありがとうございます。
pred_tableにpred_diffを追加して回収率をプロットしたところ、以下のようにグラフがおかしくなってしまいました。どんな原因が考えられますか?
おかしいというのは具体的にどの部分のことでしょうか?
グラフが二つ表示されている部分でしょうか?
仮説と結果にギャップがありすぎるということでしょうか?
もう少し詳しく説明(もしくはコードを提示)いただければ答えられるかもしれません。
グラフが2つ表示されている点です。
コードは、dfにpred_diffを定義したあと
df = df[df['pred_diff'] > min_diff]
で範囲を指定しています。
pred_diffは、関数pred_table内で以下のように定義し、returnに追加しています。
pred_1 = pred_table.sort_values(['pred'], ascending=[False]).groupby(level=0)[['pred']].nth(0)
pred_2 = pred_table.sort_values(['pred'], ascending=[False]).groupby(level=0)[['pred']].nth(1)
pred_min = pred_table.sort_values(['pred'], ascending=[False]).groupby(level=0)[['pred']].nth(-1)
pred_table['pred_diff'] = (pred_1 - pred_2) / (pred_1 - pred_min)
今回の変更でグラフが二つ表示されてしまっているのであれば、
df = df[df['pred_diff'] > min_diff]
の部分をコメントアウトして、以前と同じ結果になるのか確認して、
コード部分に誤りや考慮漏れがないかトレースしてみるのはいかがでしょうか?
私はModelEvaluatorクラスを使った回収率計算ではなく、
自前で回収率計算を行っているので、具体的な修正点を提示するのが難しそうです。
賭けると判断したrace_idのみをX_testから抽出して試してみるのもひとつの手かもしれません。
コメントアウトするとグラフは1つに直りました。どう処理されているかもう一度考え直してみます。
いろいろ試したところ、無事直りました。ありがとうございます。
馬連の回収率シミュレーションを指数1位からの流しにしようとしました。
umaren_return関数の中で以下のコードを追加しようとしたところ、エラーが出て困っています。
pred_table = self.pred_table(X, threshold)
pred = self.predict_proba(X)
pred_table['pred'] = pred
ValueError: cannot reindex from a duplicate axis
こちらの対処法を教えて下さい。
解決しました。
ど素人な質問で申し訳ございませんが、03 データ加工・前処理の部分で以下の様に開催の列がDropされないからErrorになっているのかと思うのですが、対処方法を教えて頂けませんでしょうか。
class DataProcessor:の部分はこちらのZennの内容をそのまま使っております。
再度申し訳ないのですが、第5回の動画内でスプレイピングを実行したのですが
以下のエラーが発生しました。
HTTPSConnectionPool(host='db.netkeiba.com', port=443): Max retries exceeded with url: /race/202010010608 (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x00000240BE2BE280>: Failed to establish a new connection: [WinError 10013] アクセス許可で禁じられた方法でソケットにアクセスしようとしました。'))
このエラーは接続が切れたからなのでしょうか?
その場合はscrape_race_results(race_id_list[:])で続きを取得する認識でよろしいでしょうか?
youtubeを含め、楽しく勉強させていただいております。
chapter2について質問させてください。いきなりつまづき、お恥ずかしい限りです
Peds.scrape()の最後、「スクレイピングできたら、同様にpeds.pickleに保存してください」とありますが、どのようなコードを書けば良いのか分かりません。自分なりに模索しましたが、うまくいきませんでした。
おそらくReturn.scrape()でも、同じことが起こるのだと思います。
ご指導いただければ幸いです。よろしくお願いします
Pedsの場合は下記のようにしました。
peds_results = Peds.scrape(horse_id_list)
peds_results.to_pickle("peds.pickle") ←ここで"peds.pickle"に保存しています
コメント、ありがとうございました。
ご指導の通りにやったところ、
ValueError: No objects to concatenate
というのが出ました。
ここまでのコードを一通り確認するなど、対策を考えてみたいと思います
改めて、ありがとうございました
無事に前に進めました。コードを全体的に見直して、うまくいきました。
改めて、ご指導、ありがとうございました
いつも楽しく拝見しています。
『競馬予想で始める機械学習~完全版~』を見ながら、動画のコードを実行し、いろいろと試しています。
「第14回 Pythonで単勝回収率122%の競馬予想AIを作る方法」のコードを実行し、2019年のデータでは単勝回収率120%オーバーは再現できたのですが、自分でスクレイピングした2020年のデータで試すと、横軸が4000ぐらいのときに回収率が0.82029ぐらいのグラフとなります。
年によって、これほどまでに成績が変わるものなのでしょうか?
それとも、処理等が間違っているのでしょうか。
同じように2020年や2021年のデータで試された方がいらっしゃいましたら、アドバイスをいただけると嬉しいです。
よろしくお願いいたします。
みなさま、
32bitのPC環境でlightgbmやoptunaを導入できた方はいらっしゃいますか。
この環境が整わない限り、コードが動かない印象です。
何か方法をご存じの方、ご教示お願いします。
いつも参考になる動画をアップロードして下さり、ありがとうございます。
購読させていただき、実際にノートブックを作成しているのですが1点質問させてください。
「競馬予想で始める機械学習〜完全版〜、06実際に賭けてみた」の章でレースデータを取得しモデルのpredictを行う際、下記の様に記載されております。
#馬が勝つ確率を予測
pred = me.predict_proba(st.data_c.drop(['date'], axis=1))
手元のノートブックで試したところ、「st.data_c.drop(['date'], axis=1)」を実行した場合、特徴量の順番が学習時データセットの特徴量の順番と異なっている気がするのですが認識あってますでしょうか。
lightGBMを利用しているので、学習時の特徴量順番と合わせなければ、正しく予測が出来ないと思い質問させていただきました。
以下のように出力して確認してみるのがいいかもしれませんね。
romacさんの質問で私自身、いくつかコード誤りを発見できました。
ありがとうございます。
for i in range(0, len(X_test.columns), 10):
display(X_test.iloc[0:2, i:i+10])
for i in range(0, len(st.data_c.drop(['date'], axis=1).columns), 10):
display(st.data_cc.drop(['date'], axis=1).iloc[0:2, i:i+10])
助けになれば幸いです。
お返事ありがとうございます。
公開されているコードをコピペして自身のノートブックで試した場合、カラムの順番が誤っていたので、他の方々はどうなのかと思い質問いたしました。
なので自身のノートブックでは以下のように修正しております。
col = list(X_test.columns)
st.data_c[col]
初めてコメントします。素晴らしい教材で勉強の意欲が掻き立てられます。
質問なのですが「動画中のソースコード(1~4)」の「第4回 ロジスティック回帰で競馬予想してみた」のRandomUnderSamplerを使うところでこんなエラーがでました。
AttributeError Traceback (most recent call last)
<ipython-input-4-c8c2b746a92a> in <module>
30 sampling_strategy={1: rank_1, 2: rank_2, 3: rank_3, 4: rank_1}, random_state=71
31 )
---> 32 X_train_rus, y_train_rus = rus.fit_sample(X_train.values, y_train.values)
33
34 from sklean.linear_model import LogisticRegression
AttributeError: 'RandomUnderSampler' object has no attribute 'fit_sample'
imblearnのインストールで少してこずったので、もしかしら上手くインストールできていないせいかもしれいと思いコメントしました。
今までのコメントでこの箇所のこと出てきてないってことは私の環境で何かしらの不具合が出たってことかなと思っています。
_sampleを消して実行すると、
cannot unpack non-iterable RandomUnderSampler objectと見たことのないエラーが出てきてちょっと悩困っています。
手がかりのようなものでも構いません。何かご教授願います。
fit_sample → fit_resample
にして解決するようです。
Nobu Sさんわざわざ返信ありがとうございます。
早速試してみます。
いろいろ試してAnacondaをアンインストールして、もう一度初めからscikit-learnとかも導入し直しました。scikit-learnのバージョンを変えたらうまくいったという情報も見かけたのでまた試してみます。
ここの教科書を買って動画を見ながら勉強しているのですがなかなかうまくいかず、いつも第5回か6回で対処できないことにぶつかってしまいます。
質問の第4回を飛ばして第6回のAUCスコアをだす直前のROC曲線のところでまた問題がでまして。
いきなりグラフが直角ででるんですよね。原因をいろいろ考えましたがうまくrace_infosのDataFrameと結合できなかったかもしれないし、そもそもうまくスクレイピングできていたのかもあやしいのです。
Index: 47118 entries, 201901010101 to 201910021212
Data columns (total 17 columns):
Column Non-Null Count Dtype
0 着順 47118 non-null int32
1 枠番 47118 non-null int64
2 馬番 47118 non-null int64
3 馬名 47118 non-null object
4 斤量 47118 non-null float64
5 騎手 47118 non-null object
6 単勝 47118 non-null float64
7 人気 47118 non-null float64
8 course_len 47118 non-null object
9 weather 47118 non-null object
10 race_type 47118 non-null object
11 ground_state 47118 non-null object
12 date 47118 non-null datetime64[ns]
13 性 47118 non-null object
14 年齢 47118 non-null int32
15 体重 47118 non-null int32
16 体重変化 47118 non-null int32
dtypes: datetime64ns, float64(3), int32(4), int64(2), object(7)
memory usage: 4.3+ MB
第5回の最後に保存したresults_addinfoのinfoです。int32とかもありますし、47118っていう数字がそもそもおかしいかもしれません。動画のなかの数字より常に自分がスクレイピングした時の方が多いです。第一回でも動画の中では4800でしたが自分のプログレスバーでは7200とでてきます。
ほとんど前に進めない状況なのでどんなコメントでもありがたいです。
はじめまして。最近Pythonを勉強し始めたばかりです。
JRAでなくてNAR(地方競馬)でデータ分析をやろうと思っています。
「第1回:Pythonで競馬データをスクレイピングする」のスクレイピングするURLの部分だけ変えてやってみたのですがNo table foundとエラーが出ます。
初心者すぎる質問かもしれないのですが教えていただけると助かります。
動画のコードとの変更点は
・try以下のURL部分
・#レースIDのリストを作る。NARの場合、年・競馬場・月・日・レース番号なので作り変えました。
def scrape_race_results(race_id_list, pre_race_results={}):
race_results = pre_race_results
for race_id in tqdm(race_id_list):
if race_id in race_results.keys():
continue
try:
time.sleep(1)
url = "https://nar.netkeiba.com/race/result.html?race_id=" + race_id
race_results[race_id] = pd.read_html(url)[0]
except IndexError:
continue
except Exception as e:
print(e)
break
except:
break
return race_results
#レースIDのリストを作る
race_id_list = []
place = 46
for month in range(1, 13, 1):
for day in range(1, 32, 1):
for r in range(1, 13, 1):
race_id = "2020" + str(place).zfill(2) + str(month).zfill(2) +\
str(day).zfill(2) + str(r).zfill(2)
race_id_list.append(race_id)
rece_resultsを取得するときのurlは変更しなくてもよいと思います。
正:url = "https://db.netkeiba.com/race/result.html?race_id=" + race_id
誤:url = "https://nar.netkeiba.com/race/result.html?race_id=" + race_id
urlを変更するのはShutubaTableを作成するときですね。
助けになれば幸いです。
Yusuke Isakaさん
ありがとうございます。
こんなにすぐに答えていただけると思わなかったので嬉しいです。
早速、試してみたらできました!
はじめまして。1年ほど前からぼちぼちPythonを勉強し始めたアラフィフ男です。
Pythonで機械学習を学び始めて、面白い題材だなと思い昨年
「競馬予想で始める機械学習〜完全版〜」を購入したのですが、長らく積読していました。
連休ですが緊急事態でどこにも出かけられないので一念発起挑戦しています。
よろしくお願い致します。
Chapter 08から始めて、Chapter 09の「第6回 lightgbm・ランダムフォレストで競馬予想」
まで来ましたが、どうしてもエラーで進めなくなってしまいました。
どなたかヘルプいただけると幸いです。
#ランダムフォレストによる予測モデル作成
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(random_state=100)
rf.fit(X_train, y_train)
のrt.fit(X_train,y_train)を実行したところでエラーが出ます。
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-198-ac1696b17d2e> in <module>
3
4 rf = RandomForestClassifier(random_state=100)
----> 5 rf.fit(X_train, y_train)
(中略)
ValueError: could not convert string to float: 'ルビーカサブランカ'
最初テキスト記載のスクリプト通りにやったのですが、
うまくいかないので、動画を何回も見て以下のようにもしてみましたがまだうまくいきません。
#上で保存したpickleファイルの読み込み
results = pd.read_pickle('results_addinfo.pickle') #第5回の結果を'results_addinfo.pickle'に保存
#前処理
results_p = preprocessing(results)
#着順を0or1にする
results_p['rank'] = results_p['着順'].map(lambda x: 1 if x<4 else 0)
results_p.drop(['着順'], axis=1, inplace=True)
#もし、動画のように着順をdropしてrankを作っている場合は
results_p['rank'] = results_p['rank'].map(lambda x: 1 if x<4 else 0)
train,test = split_data(results_p) # 動画に倣って実行
X_train = train.drop(['rank','date'],axis=1) #動画に倣って実行
y_train = train['rank'] #動画に倣って実行
X_test = test.drop(['rank','date'],axis=1) #動画に倣って実行
y_test = test['rank'] #動画に倣って実行
#ランダムフォレストによる予測モデル作成
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(random_state=100)
rf.fit(X_train, y_train)
どのように対処すればよろしいでしょうか。
miniconda環境で都度足らないライブラリをインストールしながら進めていますので、
各種ライブラリのインストールがうまくできていないのかもしれませんが、ご教示お願いいたします。
Windows10 Home 64bit
miniconda 3
conda 4.10.1
jupyter lab 3.0.14
scikit-learn 0.24.1
第6回動画の5:45あたりの馬名dropとダミー変数化はしていますか?
一応確認してみて下さい。
Nobu Sさん、早速のアドバイスありがとうございます。
おかげさまで、解決しました。
ご指摘の通り馬名dropとダミー変数化辺りに注目して
動画の通り忠実にやってみたところ無事実行できました。
これで先に進めます。
変にテキストからのコピペだけに頼りすぎていたのかもしれません。
今後気を付けます。
実は、別の方へのヘルプ
「fit_sample → fit_resample
にして解決するようです。」
にも助けられたりしています^^ゞ
解決してよかったですね。
私も初心者ですが、一応動画だけでポチポチ入力してエラーを繰り返しながら最後まで行っています。
作者さんが仕事で忙しそうなのでお役に立ててよかったです。
ここだけでなく、youtubeのコメントも見ると参考になるものもあります。
お互い頑張りましょう。
連投しましてすみません。
またまたつまずいてしまいましたので、どなたかご教示いただけると助かります。
「競馬予想で始める機械学習~完全版~」Chapter 10の
「第7回 Pythonで過去成績データをスクレイピングする」をやっているのですが、
scrape_horse_results()関数でhorse_resultsをスクレイピングしていると
途中でtqdmのカウンタが進まなくなってしまいます。
エラー表示は出ておらず、そのうち動き出すのかなと2,3時間放置しているのですが、
一旦止まると、その後カウンタは一つも進みません。
そうなると、Jupyter labの「Interrupt the kernel」も効かず、
Restart kernelをするしかありません。
そのため、pre_horse_resultsによる途中再開もできず毎回1からの読み込みです。
止まる際のtqdmカウンタはその時によって異なります。
922/11495まで進むときもあれば、98/11495、354/11495の場合もあります。
forループ内にhorse_IDを表示するようにしておいて、
止まった際にそのhorse_IDでkeiba.comさんのお馬さん情報をみてみると
正しくみられるので、存在しないページを見ているわけではないようです。
# 復旧再開
import pandas as pd
import time
from tqdm.notebook import tqdm
#前回保存したpickleファイルからデータ取得
results = pd.read_pickle('results.pickle')
horse_id_list = results['horse_id'].unique()
def scrape_horse_results(horse_id_list, pre_horse_results={}):
#horse_idをkeyにしてDataFrame型を格納
horse_results = pre_horse_results
for horse_id in tqdm(horse_id_list):
try:
url = 'https://db.netkeiba.com/horse/' + horse_id
df = pd.read_html(url)[3]
#受賞歴がある馬の場合、3番目に受賞歴テーブルが来るため、4番目のデータを取得する
if df.columns[0]=='受賞歴':
df = pd.read_html(url)[4]
print(horse_id, df) #監視用
horse_results[horse_id] = df
time.sleep(1)
except IndexError:
continue
except Exception as e:
print(e)
break
except:
break
return horse_results
horse_results = scrape_horse_results(horse_id_list)
race_results()やrace_info()は最後まで読み込めましたのですが、
ここにきてネットの調子が悪いのですかね。
ひたすら待っていれば、スクレイピング進んでくれるのでしょうか。
同じような現象に合われた方、アドバイスいただけると幸いです。
Windows10 Home 64bit
Python 3.8.5
miniconda 3
conda 4.10.1
jupyter lab 3.0.14
scikit-learn 0.24.1
こんにちは。
連休も最終日ですが、まだ「馬の過去成績データ」(horseResults)のスクレイピングで足踏みしたままです。
Chapter 02のクラス版で試しているのですが、
上記と同じようにエラーも出ずにtqdmのカウンタが進まなくなりフリーズしているようです。
途中にprint()文をはさんでデバッグしてみたところ、
for horse_id in tqdm(horse_id_list):
try:
url = 'https://db.netkeiba.com/horse/' + horse_id
df = pd.read_html(url)[3]
の"df = pd.read_html(url)[3]"を実行するところで止まっているようです。
(デバッガの使い方がよくわからず、print文をはさむという原始的な方法で見ています。)
実行後いきなり止まるのではなく、tqdmのカウンタ100/11702未満で止まるときもあれば、
1000/11702近くまで行くときもあります。
(残念ながら1000超えることがないです。。。)
「レース結果データ」(Results.scrape)のスクレイピングは無事終了しています。
(2020年のデータを取りました。)
try~except文を外してやってみたのですが、
やはりエラーも出してくれずただフリーズしてるっぽいので困っています。
(jupyter lab自体は生きてて、一晩たっても止まったままなのでRestart Kernel and Clear All Outputsで止めました。)
WiFiでやっているのですが、
Ethernetケーブルでルーターに直接つないでやってみようかと思いますが、
何か手立てはないものでしょうか。
私も2021年の4月までのスクレイピングをしている時に同じようなことが起きていましたが、何度かやり直してみると最後までスクレイピングしてくれました。なので、何回か試してみるといいかもしれません。
根本的な解決になっていなくて申し訳ないです。
PyCKさん、コメントありがとうございます。
PyCKさんのように、いつか最後までスクレイピングできることを願って(?)今はとりあえず、
動画とテキストで勉強進めようと思います。
動画のように2019年のデータならうまくいくのかな?!
読み込めたところまでで保存できるようにならないかなと考えているのですが、
なかなか…(^^;
僕もここでツマヅイているので参考になりました。
ありがとうございました!
相変わらず途中でエラーもなくフリーズするので、
func_timeoutなるライブラリを使って、タイムアウト処理を入れてみました。
from func_timeout import func_timeout, FunctionTimedOut
#馬の過去成績データを処理するクラス
class HorseResults:
@staticmethod
def scrape(horse_id_list, pre_horse_results=pd.DataFrame()):
"""
馬の過去成績データをスクレイピングする関数
Parameters:
----------
horse_id_list : list
馬IDのリスト
Returns:
----------
horse_results_df : pandas.DataFrame
全馬の過去成績データをまとめてDataFrame型にしたもの
"""
#スクレイピング済みのhorse_idを省き、
#horse_idをkeyにしてDataFrame型を格納
horse_id_list = set(horse_id_list) - set(pre_horse_results.index)
horse_results = {}
for horse_id in tqdm(horse_id_list):
try:
url = 'https://db.netkeiba.com/horse/' + horse_id
df1 = func_timeout(30, pd.read_html, args=(url,))
df = df1[3]
#受賞歴がある馬の場合、3番目に受賞歴テーブルが来るため、4番目のデータを取得する
if df.columns[0]=='受賞歴':
df = df1[4]
df.index = [horse_id] * len(df)
horse_results[horse_id] = df
time.sleep(1)
except IndexError:
continue
except FunctionTimedOut:
print ('Time out!')
break
except Exception as e:
print(e)
break
except:
break
#pd.DataFrame型にして一つのデータにまとめる
horse_results_df = pd.concat([horse_results[key] for key in horse_results])
horse_results_df = pd.concat([pre_horse_results, horse_results_df]) # pre_horse_resultsと結合
return horse_results_df
これで、pd.read_html()の最中にフリーズしても30秒経てば
タイムアウトで帰ってきてくれる様ですので、
それを検出していったん抜け出しています。
止まるたびに手動で再開していたのですが、面倒になって
while len(horse_results.index.unique()) < len(results['horse_id'].unique()):
horse_results = HorseResults.scrape(horse_id_list, horse_results)
print ('Completed!')
のように、七転び八起きで全部終わるまで繰り返すようにして現在スクレイピング続行中です。
(しまいに、netkeibaさんに叱られないか少し不安です…)
まだスクレイピング最後まで完了していませんので、果たしてこれでできるのかは?です。
再開して得たデータをつなげる式も合っているのかは?です。
(うまくいってから投稿した方がよかったかも)
何かアドバイスあれば、お願いいたします。
(追記)
上記の方法でHorse_Resultsのスクレイピングが完了しました。
つぎはぎデータがちゃんと役立つかはこれから確認ですが進めてみます。
ありがとうございました。
初めまして。ほんの数週間前からpythonを学び始めた初心者です。(以前は軽くCやJavaを触った程度)
いつも動画見て勉強させてもらっています。
質問があります。(質問というより助けていただきたいというのが正確かもしれません...)
実際に予測結果を出す段階で下記のコードを実行したところエラー(実行コードの下にあるような)が発生しました。
KeyError: "['単勝'] not found in axis" と出ているのでどこかで単勝の列がないのだろうかと思って色々触ってみたのですが、エラーを解消できませんでした。
考えられる原因、エラーの解消方法についてご意見頂けませんでしょうか?
もし、この関数やクラスの中身を見たいということがあればそちらも随時載せますので、どうかよろしくお願いいたします。
実行したコード
#馬が勝つ確率を予測
pred = me.predict_proba(st.data_c.drop(['date'], axis=1))
#予測結果を表に結合
pred_table = st.data_c[['馬番']].copy()
pred_table['pred'] = pred
#確率が高い順に出力
pred_table.sort_values('pred', ascending=False)
出力されたエラー
predictpredict---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-174-e2fd6271b8c1> in <module>
1 #馬が勝つ確率を予測
----> 2 pred = me._proba(st.data_c.drop(['date'], axis=1))
3
4 #予測結果を表に結合
5 pred_table = st.data_c[['馬番']].copy()
<ipython-input-172-0bdde96d1f23> in predict_proba(self, X)
10 #3着以内に入る確率を予測。
11 def predict_proba(self, X):
---> 12 proba = pd.Series(self.model._proba(X.drop(['単勝'], axis=1))[:, 1], index=X.index)
13 #proba = pd.Series(self.model.predict_proba)
14 if self.std:
/opt/anaconda3/lib/python3.8/site-packages/pandas/core/frame.py in drop(self, labels, axis, index, columns, level, inplace, errors)
4161 weight 1.0 0.8
4162 """
-> 4163 return super().drop(
4164 labels=labels,
4165 axis=axis,
/opt/anaconda3/lib/python3.8/site-packages/pandas/core/generic.py in drop(self, labels, axis, index, columns, level, inplace, errors)
3885 for axis, labels in axes.items():
3886 if labels is not None:
-> 3887 obj = obj._drop_axis(labels, axis, level=level, errors=errors)
3888
3889 if inplace:
/opt/anaconda3/lib/python3.8/site-packages/pandas/core/generic.py in _drop_axis(self, labels, axis, level, errors)
3919 new_axis = axis.drop(labels, level=level, errors=errors)
3920 else:
-> 3921 new_axis = axis.drop(labels, errors=errors)
3922 result = self.reindex(**{axis_name: new_axis})
3923
/opt/anaconda3/lib/python3.8/site-packages/pandas/core/indexes/base.py in drop(self, labels, errors)
5280 if mask.any():
5281 if errors != "ignore":
-> 5282 raise KeyError(f"{labels[mask]} not found in axis")
5283 indexer = indexer[~mask]
5284 return self.delete(indexer)
KeyError: "['単勝'] not found in axis"
最新のModelEvaluatorクラスでは
#3着以内に入る確率を予測。出馬表のデータを入れるときはdrop_tansho=Falseにする。
def predict_proba(self, X, drop_tansho=True):
となっているのでdrop_tansho=Falseを設定してみてはいかがでしょうか。
エラーメッセージの内容を見るとModelEvaluatorクラスの中身が最新ではなさそうなので、
そちらも最新にする必要がありそうです。
とりあえずModelEvaluatorクラスの.drop(['単勝'], axis=1)を
削除して試してみてもよいかもしれません。
※私、ModelEvaluatorクラスを使っていないので誤ったコメントだったらすみません。
助けになれば幸いです。
ご返信いただきありがとうございます!
ModelEvaluatorクラスの書き換えも適宜あるようですね。古い方から動画を辿っているので対応できていないところがあるかもしれないです(・・;)
ご返信にありました、
「ModelEvaluatorクラスの.drop(['単勝'], axis=1)
を削除して試してみてもよいかもしれません。」
をしたところエラーなく実行できました!
初歩的な質問にも回答いただきありがとうございました!
今後ともよろしくお願いいたします。
私も同じところでつまづいて、ModelEvaluatorクラスの
proba = pd.Series(self.model._proba(X.drop(['単勝'], axis=1))[:, 1], index=X.index)
の
「.drop(['単勝'], axis=1)」部分を削除したらエラーはなくなり実行できたのですが、
出馬表のデータ(st.data_c)を使って予想する時は、削除するのが正解なのでしょうか。
ModelEvaluatorクラスは最新のものを使っています。(のはずです)
ちなみに、本日のダービーを予想したら、
1着の10番シャフリヤールを2番手予想していましたよ!
そう捉えるしかないかと思っていました。
実際のところどうなのか実際にかけてみる回でお話があると助かりますよね、、
ダービーの予測ですが、いつからいつまでの過去データを使っていましたか?
自分の場合は2011〜2021年4月までの過去データでやってましたが、シャフリヤールは7番評価だったので気になりました。
1番評価はエフフォーリアでした。
さらに付け足すとサトノレイナスがビリ2評価でホンマかってちょっと疑ってまして…笑
コードは最新のものと相違ないはずです!
自分でソース見て、こうだからこう使って…とできればいいのですがね。なかなか。。。
私の環境では2015~2020年までデータ用意しました。
用意するデータがそれぞれ違うので、同じAIソフトでも予想が違ってきますね。
こちらでも1番確率が高かったのは同じくエフフォーリアだったと思います。
ようやく動画シリーズの最新回まで追いついたところで、
データ一式もやっとこさスクレイピングできたところです。
なので当方の環境でちゃんと「学習」させて予想で来てるのかも不安だったのですが、
ダービーの結果をひとまずは動いてくれているのかなと安心したところです。
まだわからないところだらけで、2周目見ないといけないなと思っています。。。
先日ここで質問して助けていただいたおかげで「第5回 BeautifulSoupで競馬データを取得する」まで進めました。ありがとうございました。
また初歩の初歩みたいな質問なのですが第5回のアンダーサンプリングのところでimblearnのインストールができませんした。色々ネットで調べたのですが皆さんどうやってインストールされたか教えていただけると助かります。
condaを使っているので
conda install -c conda-forge imbalanced-learn
conda install imbalanced-learn
conda install -c glemaitre imbalanced-learn
を試してみたのですが上手くインストールすることができませんでした。
よろしくお願いします。
楽しく拝読しています。
まだまだ初心者なのですが、
払い戻し表をスクレイピングするところで
return_tablesを認識出来ません。
どうしたらよろしいでしょうか。
質問の仕方が間違っていたらすいません。
皆さんに質問なんですが、私は以下のようなエラーが出たのですが新しく更新されたReturnクラスとMEクラスは問題なく実行できましたか?
return_tables.pickle
FileNotFoundError Traceback (most recent call last)
<ipython-input-51-94c866045c8a> in <module>
1 #ModelEvaluatorクラスのオブジェクトを作成
----> 2 me = ModelEvaluator(lgb_clf, 'return_tables.pickle')
<ipython-input-38-a01eaac4745d> in init(self, model, return_tables_path)
2 def init(self, model, return_tables_path):
3 self.model = model
----> 4 self.rt = Return.read_pickle(return_tables_path)
5 self.fukusho = self.rt.fukusho
6 self.tansho = self.rt.tansho
<ipython-input-50-908912972b66> in read_pickle(cls, path_list)
6 def read_pickle(cls, path_list):
7 print(path_list)
----> 8 df = pd.read_pickle(path_list[0])
9 for path in path_list[1:]:
10 df = update_data(df, pd.read_pickle(path))
~\anaconda3\lib\site-packages\pandas\io\pickle.py in read_pickle(filepath_or_buffer, compression)
167 if not isinstance(fp_or_buf, str) and compression == "infer":
168 compression = None
--> 169 f, fh = get_handle(fp_or_buf, "rb", compression=compression, is_text=False)
170
171 # 1) try standard library Pickle
~\anaconda3\lib\site-packages\pandas\io\common.py in get_handle(path_or_buf, mode, encoding, compression, memory_map, is_text, errors)
497 else:
498 # Binary mode
--> 499 f = open(path_or_buf, mode)
500 handles.append(f)
501
FileNotFoundError: [Errno 2] No such file or directory: 'r'
me = ModelEvaluator(lgb_clf, ['return_tables.pickle'])
と、リストでファイルパスを入れるように変更しました!(複数ファイルを結合できるようにするため)
回収率グラフの見方、考え方の認識が合っているかご教授お願いいたします。
2011年から2021年4月までのデータで三連複、三連単の回収率を出したところ下図のようになりました。
この場合、三連複はthresholdが0.8くらいでちょうど回収率100%だと思います。
つまり、「threshold=0.8以上の馬が3頭以上いる場合三連複boxを買い、2頭以下の場合単勝を買う」を繰り返すと回収率100%になるということでしょうか?
もう一つ例を挙げると、threshold=1.25くらいで回収率130%くらいですが
「threshold=1.25以上の馬が3頭以上いる場合三連複boxを買い、2頭以下の場合単勝を買う」を繰り返すと回収率130%になるということでしょうか?
またグラフからthresholdが1.6以上に絞って同じように買うことは期待値が低いと読み取れますか?
(もっともthresholdが1.6以上の場合はほとんど1〜2頭しかおらず三連複は買えないので単勝を買っていそうですが)
根本的に見方、考え方が間違っている場合、遠慮なく指摘くださいますと幸いです。
optunaでパラメータを最適化する際に、
同じデータを用いているのにもかかわらず、optunaするたびにハイパパラメタが変化するのはなぜなのでしょうか。
この問題を回避された方はいらっしゃいますか?
そのため、回収率グラフの評価に疑問が残ります。
Returnクラスを使用して払い戻し表のスクレイピングをしているのですが、何度やっても500件もいかずに下記エラーで止まってしまいます。(本日5/26 9:00~13:00の間で6回試行して全てNG)
<urlopen error [WinError 10060] 接続済みの呼び出し先が一定の時間を過ぎても正しく応答しなかったため、接続できませんでした。または接続済みのホストが応答しなかったため、確立された接続は失敗しました。>
race_id_listは2019年のものを使用しており下記を実行しているだけです。
return_tables = Return.scrape(race_id_list)
解決法をご存じな方いらっしゃいますか?
まずrace_id_listに手動で201901010101だけ入れたりして、return_tablesに結果が取り込めるか試してみてはどうでしょう?
コードに不備があればそれすらエラーになります。
ちゃんと取り込めているなら、race_id_listの中身は正しいか確認したり、途中まではいけてるならどこで止まっているのかreturn_tablesをみて見当をつけたいですね。
あとは、必要なパッケージは入っていますか?
今回ならfrom urllib.request import urlopenですかね。書き方はこれだけじゃないかもですが。
今回実際に動かしているクラスとエラー内容を丸々貼った方が皆さんの目にパッと入って解決が早いかもしれません。
参考までに、私は2011年から2021年4月まで全てエラーなく取り込めました。
ご回答ありがとうございます。
私の質問の最初に書いてあるReturnクラスはリンクも貼ってありますが「競馬予想で始める機械学習 〜最先端ver〜」の「chapter 02 スクレイピング」に載っているReturnクラスのソースコードをそのまま使用しています。。。(リンク先参照できないでしょうか?)
途中のレースまではスクレイピングできており、異常後にreturn_tablesを出力しても途中までの分が格納されています。return‗tablesを表示すると末尾のインデックスが「201901020612」になっているので、
次取得しようとするレースのURL https://db.netkeiba.com/race/201901020701 を確認すると存在しないレースIDだというのはわかっています。
ですが存在しないレースを無視するために下記の処理があると認識しています。
except IndexError:
continue
from urllib.request import urlopen もインポートしています。
手詰まり状態ですがもう少し模索してみます。。。
原因がわかりました。最初にレース結果データを作成する際に使用したrace_id_listをそのまま払い戻し表のスクレイピングでも指定していた為、存在しないレースIDのページをurlopenで指定した結果except IndexError:ではなく、except Exception:で拾ってそのままbreakしていました。
なので、すでに作成済みのレース結果データのレースIDをユニーク化したリストでrace_id_listを更新して払い戻しのスクレイピングで指定したら止まらずに動いています。まだ動作中ですが大丈夫かと思います。
レース結果データではpandasのread_htmlメソッドを使用していて、
戻り値のリストの[0]を指定しているので存在しない場合にIndexErrorになってたのでちゃんとcontinueされていたのだと気づきました。
ここにするコメントじゃなかったらすみません。
05モデル評価&回収率シュミレーションのModelEvaluatorクラスの
2つ目のdefのelse内のproba(X))となっている部分はカッコ閉じが1つ多いみたいです。
追加で05の回収率シュミレーションでmatplotlibを使ってますが、01にimportにないよいです
初心者質問で申し訳ないのですが、2021/5/21更新のModelevaluaterクラスに関して、出馬表データから単勝の数値を取り出せない現在のプログラムでは実際のレースを予測する際に
def predict_proba(self, X, std=True, minmax=False):
proba = pd.Series(self.model.predict_proba(X.drop(['単勝'], axis=1))[:, 1], index=X.index)
この部分で['単勝']のdropでエラーが出てしまいます。
me3 = ModelEvaluator3(lgb_clf, ['return_tables.pickle'])
pred = me3.predict_proba(st.data_c.drop(['date'], axis=1))
KeyError Traceback (most recent call last)
<ipython-input-71-b140a86e1687> in <module>
----> 1 pred = me3.predict_proba(st.data_c.drop(['date'], axis=1))
<ipython-input-69-8f8cbcb6e7f0> in predict_proba(self, X, drop_tansho)
15 def predict_proba(self, X, drop_tansho=True):
16 if drop_tansho:
---> 17 proba = pd.Series(self.model.predict_proba(X.drop(['単勝'], axis=1))[:, 1], index=X.index)
18 else:
19 proba = pd.Series((self.model.predict_proba(X))[:, 1], index=X.index)
~\Anaconda3\envs\Keiba\lib\site-packages\pandas\core\frame.py in drop(self, labels, axis, index, columns, level, inplace, errors)
4313 level=level,
4314 inplace=inplace,
-> 4315 errors=errors,
4316 )
4317
~\Anaconda3\envs\Keiba\lib\site-packages\pandas\core\generic.py in drop(self, labels, axis, index, columns, level, inplace, errors)
4151 for axis, labels in axes.items():
4152 if labels is not None:
-> 4153 obj = obj._drop_axis(labels, axis, level=level, errors=errors)
4154
4155 if inplace:
~\Anaconda3\envs\Keiba\lib\site-packages\pandas\core\generic.py in _drop_axis(self, labels, axis, level, errors)
4186 new_axis = axis.drop(labels, level=level, errors=errors)
4187 else:
-> 4188 new_axis = axis.drop(labels, errors=errors)
4189 result = self.reindex(**{axis_name: new_axis})
4190
~\Anaconda3\envs\Keiba\lib\site-packages\pandas\core\indexes\base.py in drop(self, labels, errors)
5589 if mask.any():
5590 if errors != "ignore":
-> 5591 raise KeyError(f"{labels[mask]} not found in axis")
5592 indexer = indexer[~mask]
5593 return self.delete(indexer)
KeyError: "['単勝'] not found in axis"
動画で見逃しているだけかもしれないのですが、自分でこのようにクラスを書き替えました。
#3着以内に入る確率を予測
def predict_proba(self, X, std=True, minmax=False, drop_tansho=True):
if drop_tansho:
proba = pd.Series(self.model.predict_proba(X.drop(['単勝'], axis=1))[:, 1], index=X.index)
else:
proba = pd.Series((self.model.predict_proba(X))[:, 1], index=X.index)
このプログラムでも、予想自体に影響はないでしょうか? 曖昧な質問申し訳ありません。回答いただけると幸いです
良く見返したら同じような質問をされていた方が上のコメントにいらっしゃったので、そちらへのリンクを貼ります。申し訳ありません……!
また初心者質問で申し訳ないのですが、HorseResultクラスに、上り3Fのデータとペースのデータ、上り3Fのタイムがペースよりも上かどうかを特徴量として採用したく、格闘しています。
スクレイピングした馬の成績データを見ると、「上り」「ペース」にそれぞれデータがあったので、取り出し、NaNデータ(出走停止やレース中止、途中退場等)のデータをfillnaで置き換えました
horse_results['ペース'].fillna('0', inplace=True)
horse_results['上り'].fillna(0, inplace=True)
horse_results['ペース']
#2018102049 34.9-38.0
#2018102049 34.7-38.5
#2018102049 35.3-38.7
#2018102049 34.8-36.5
#2018102049 35.7-37.5
# ...
#2017105794 34.8-37.9
#2017105794 0.0-38.9
#2017105794 34.9-35.2
#2017105794 34.9-35.2
#2017105794 34.8-36.5
#Name: ペース, Length: 87528, dtype: object
その後正規表現と文字列の分割を用いて、上り3Fのペースを取得しました。
horse_results['ペース'].str.split('-', expand=True)[1].astype(float)
#2018102049 38.0
#2018102049 38.5
#2018102049 38.7
#2018102049 36.5
#2018102049 37.5
# ...
#2017105794 37.9
#2017105794 38.9
#2017105794 35.2
#2017105794 35.2
#2017105794 36.5
#Name: 1, Length: 87528, dtype: float64
得られた上り3Fのペースデータと馬の上り3Fのデータを上下で比べ、Booleanで出力。その後、0,1のint型に直すことで、HorseResultsクラスのaverage関数へ導入した際に、0~1のデータで取り戻せると思い、実行しました。
sample = horse_results['ペース'].str.split('-', expand=True)[1].astype(float) > horse_results['上り']
sample.astype(int)
#2018102049 1
#2018102049 0
#2018102049 0
#2018102049 0
#2018102049 0
# ..
#2017105794 1
#2017105794 0
#2017105794 1
#2017105794 0
#2017105794 0
#Length: 87528, dtype: int32
これをHorseResultsクラスのpreprocessing関数に組み込もうとしたのですが、pickleファイルを読み込んだ時に以下のようなエラーが出てしましました
class HorseResults:
def __init__(self, horse_results):
self.horse_results = horse_results[['日付', '着順', '上り', 'ペース', '賞金', '着差', '通過', '開催', '距離']]
self.preprocessing()
~~~~~
def preprocessing(self):
df = self.horse_results.copy()
.
.
.
df['上り'] = df['上り'].fillna(0, inplace=True)
df['ペース'] = df['ペース'].fillna('', inplace=True)
on_pace_bool = df['ペース'].str.split('-', expand=True)[1].astype(float) > df['上り']
df['on_pace'] = on_pace_bool.astype(int)
df.drop(['ペース'], axis=1, inplace=True)
#インデックス名を与える
df.index.name = 'horse_id'
self.horse_results = df
self.target_list = ['着順', '上り', 'on_pace', '賞金', '着差', 'first_corner', 'final_corner',
'first_to_rank', 'first_to_final','final_to_rank', '上り']
~~~~~
def average(self, horse_id_list, date, n_samples='all'):
.
.
.
self.average_dict = {}
self.average_dict['non_category'] = filtered_df.groupby(level=0)[self.target_list].mean()\
.add_suffix('_{}R'.format(n_samples))
for column in ['course_len', 'race_type', '開催', '上り', 'on_pace']:
~~~~~
def merge(self, results, date, n_samples='all'):
.
.
.
merged_df = df.merge(self.average_dict['non_category'], left_on='horse_id',
right_index=True, how='left')
for column in ['course_len', 'race_type', '開催', '上り', 'on_pace']:
merged_df = merged_df.merge(self.average_dict[column],
left_on=['horse_id', column],
right_index=True, how='left')
hr = HorseResults.read_pickle(['horse_results.pickle', 'horse_results_2021.pickle'])
hr.horse_results.head()
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
~\Anaconda3\envs\Keiba\lib\site-packages\pandas\core\indexes\range.py in get_loc(self, key, method, tolerance)
350 try:
--> 351 return self._range.index(new_key)
352 except ValueError as err:
ValueError: 1 is not in range
The above exception was the direct cause of the following exception:
KeyError Traceback (most recent call last)
<ipython-input-239-611bca3af063> in <module>
----> 1 hr = HorseResults.read_pickle(['horse_results.pickle', 'horse_results_2021.pickle'])
2 hr.horse_results.head() #jupyterで出力
<ipython-input-229-c5674dd92de7> in read_pickle(cls, path_list)
15 for path in path_list[1:]:
16 df = update_data(df, pd.read_pickle(path))
---> 17 return cls(df)
18
19 @staticmethod
<ipython-input-229-c5674dd92de7> in __init__(self, horse_results)
8 def __init__(self, horse_results):
9 self.horse_results = horse_results[['日付', '着順', '上り', 'ペース', '賞金', '着差', '通過', '開催', '距離']]
---> 10 self.preprocessing()
11
12 @classmethod
<ipython-input-229-c5674dd92de7> in preprocessing(self)
101 df['上り'] = df['上り'].fillna(0, inplace=True)
102 df['ペース'] = df['ペース'].fillna('', inplace=True)
--> 103 on_pace_bool = df['ペース'].str.split('-', expand=True)[1].astype(float) > df['上り']
104 df['on_pace'] = on_pace_bool.astype(int)
105 df.drop(['ペース'], axis=1, inplace=True)
~\Anaconda3\envs\Keiba\lib\site-packages\pandas\core\frame.py in __getitem__(self, key)
3022 if self.columns.nlevels > 1:
3023 return self._getitem_multilevel(key)
-> 3024 indexer = self.columns.get_loc(key)
3025 if is_integer(indexer):
3026 indexer = [indexer]
~\Anaconda3\envs\Keiba\lib\site-packages\pandas\core\indexes\range.py in get_loc(self, key, method, tolerance)
351 return self._range.index(new_key)
352 except ValueError as err:
--> 353 raise KeyError(key) from err
354 raise KeyError(key)
355 return super().get_loc(key, method=method, tolerance=tolerance)
KeyError: 1
そもそもの方法が間違っているのか、リストの引数が違うのか。また、ペースや上り3Fのデータの欠損値に0を代入するのはあっているのか等、思いついたことやお気づきの点がございましたらご教授いただけると幸いです。長文失礼しました。
HorseResultsクラスを以下に修正したらいかがでしょうか?
■変更前
df['上り'] = df['上り'].fillna(0, inplace=True)
df['ペース'] = df['ペース'].fillna('', inplace=True)
■変更後
df['上り'].fillna(0, inplace=True)
df['ペース'].fillna('', inplace=True)
助けになれば幸いです。
Yusuke Isaka様、コメントありがとうございます。
あれからもう少し格闘して、上りのデータとペースのデータをHorseResults関数に組み込むことができました。
そもそも、上りとペースのデータが無いレースは成績として取得する必要が無い(着順データと同じ処理をするべき)だと判断したので、dropnaメソッドに入れて消すことにしました。
df.dropna(subset=['着順' ,'ペース', '上り'], inplace=True)
ペースのタイムより上かどうかの処理はあまり変わっていません。
on_pace_bool = df['ペース'].str.split('-', expand=True)[1].astype(float) > df['上り'].astype(float)
df['on_pace'] = on_pace_bool.astype(int)
その他target_listにもカラム名を入れ、通常の予想を行いました。
以下はデフォルトのデータ構成と、上り、on_paceデータを入れたデータ構成での単勝回収率のグラフ比較です。ただ、あまりこのあたりのクラス操作が分かっていないので、正しい結果の保証がないことは念頭に置いてご覧いただけると幸いです。
データは2020年~2021年の5/29までのを入力しています。
デフォルト: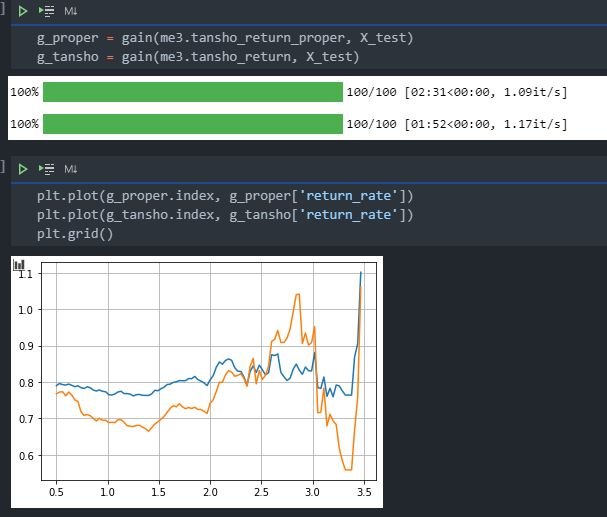
今回: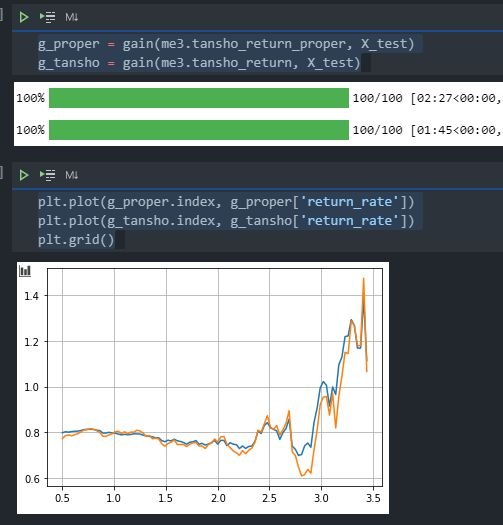
正当性があるのか、上りやペース以上のタイムが出たかどうかのデータがリーク等禁則に当たらないかどうかが判断できないので、コメントでご指摘等いただけると幸いです。
初めまして。optunaによるハイパーパラメータの設定が実行のたびに変わる問題について、自分でも気になったので調べてみました。
機械学習どころかプログラミングすら初心者ですので的外れなことを言っていたらすみません。
この問題について、Githubで次のようなページを見つけました。
曰く、optuna.integration.lightgbm.LightGBMTunerCVにはseedオプションがあるが、optuna.integration.lightgbm.LightGBMTunerにはないそうです。
これに対し開発者さん?が、LightGBMTunerにseed parametersを作るにあたってそのデザインを決める発言の中に、
Since the original lightgbm has multiple seeds, it may be confusing if we add the seed option for Optuna. If we reuse the seed in params, users will not have to take care of Optuna's seeding. On the other hand, they may want to change the Optuna seed while keeping the seed for lightgbm to check the optimization performance/stability of Optuna.
とあります。
つまり現行の、
params = {
'objective': 'binary', #今回は0or1の二値予測なのでbinaryを指定
'random_state': 100
}
におけるrandam_stateは、チューニング中には無視されている?のかもしれません。
ちなみに、このseedオプションの開発は完了しているっぽいです(流し読みしただけですが…)。 optunaのマニュアルページにも、versionをlatest()とすると、optuna.integration.lightgbm.LightGBMTunerの引数に
optuna_seed=None
とあります。 ※Githubのlatest releaseはv2.7.0ですが、マニュアルページのlatestは2.8.0.dev0です。
前述の通り初心者ですので、詳しい方に確認して、間違いがあれば訂正いただきたく存じます。
情報のアップデートを忘れていました。もう結構経ってしまいましたが、すでにv2.8.0が出ていますのでoptuna_seedが使えるようになり、ハイパーパラメータが実行のたびに変わる問題を回避できるようになっています。
そのやりかたのコードやバージョン確認などの方法はどうすればよろしいでしょうか。
よろしければご教授願えませんでしょうか?
バージョン確認の方法は環境によって多少異なると思いますが、anacondaを使われているのであればAnaconda Powershell Promptで
optuna --version
と入力してエンターで出てきます。
やり方はlgb_o.train()の引数にoptuna_seed=100を追加してください。数字はなんでも大丈夫です。
optunaのバージョンが2.5.0なのですが、これでも大丈夫でしょうか?
それとも、バージョンをアップデートしなければなりませんか?
PC周りは苦手でして、何度も申し訳ありません。
バージョン2.8.0以上でないとできません。
conda uninstall optuna
conda install optuna
で解決いたしました
2021/05/15追加のModelEvaluatorクラスのsanrenpuku_box()とsanrentan_box()における、
#賭けたい馬が3頭いない時は単勝で賭ける
if len(preds)<3:
return_list.append(np.sum([self.bet(race_id, 'tansho', umaban, 1) for umaban in preds['馬番']]))
n_bets += 1
は、n_bets += 1 ではなく n_bets += len(preds) ではないでしょうか。
勘違いだったらすみません。
この指摘が正しければ、単勝を2枚買っているのに1枚しか買っていない計算になってしまう場合があるということですよね。成績が本来より高く見積もられてしまうのでは
おっしゃる通り、かなり高く見積もられてしまうようです。
上記の通りに修正すると、確か(threshold後半部分を除いて)回収率1を超えるところが無くなってしまったと記憶しています。
単勝を「thresholdを超える馬が2頭以下の時だけ賭ける」としても、回収率は(threshold後半部分を除いて)ほぼ0.8あたりをさまよっていたので、三連単・三連複で賭けたい馬が3頭いない時は賭けないようにするのがいいのではと思います。
語弊があったので訂正します。
× 単勝を「thresholdを超える馬が2頭以下の時だけ賭ける」としても
〇 tansho_return()を「thresholdを超える馬が2頭以下の時だけ賭ける」としても
おっしゃる通りで、ソースコードのミスでした。
対応遅くなってしまい申し訳ありません!
ご指摘ありがとうございました。
更新ありがとうございます!
youtubeを毎回楽しみに拝見してます。
これからも応援してますので、楽しい動画おねがいします!
##予測する
#訓練データとテストデータに分ける
train, test = split_data(r.data_c)
#説明変数と目的変数に分ける。dateはこの後不要なので省く。
X_train = train.drop(['rank', 'date', '単勝'], axis=1)
y_train = train['rank']
#2021/3/12追加: テストデータの単勝オッズはシミュレーション時に使用するので残しておく
X_test = test.drop(['rank', 'date'], axis=1)
y_test = test['rank']
X_test = test.drop(['rank', 'date'], axis=1)
こちらの行に単勝がないとfeature_importanceが表示できなくて困っております。
me.feature_importance(X_test)
エラーは「ValueError: arrays must all be same length」です。
X_test = test.drop(['rank', 'date', '単勝'], axis=1)
頭捻って考えてみたのですが、追加して実行する以外に
良い案が思いつきませんでした良い解決方法はありませんか?
あと、youtubeを見ていて拾ってきた情報ですが、統計的に優位性がみられると感じた特徴量のアイディアがあります。お時間あれば、ご検討ください!
当日に取得したレースデータに、オッズとそれに付随した人気順がありますが、
人気順にソートした場合、「馬」と「次の人気の馬」との間にオッズ(倍率)差があります。
人気 オッズ
A馬 1 2.1
B馬 2 3.5
C馬 3 9.8
A馬B馬間の差は1.4で、B馬C馬間の差は6.3あります。
この差が1.8倍を超えると、前者の馬が3着以内に入る確率が上がるようです。(20~30%)
計算式的には、
(C馬オッズ/B馬オッズ)>=1.8 3着以内に入る可能性が見受けられる?
また、3倍を超えると、極端に3着以内に入る可能性が高くなるそうです。
特徴量的には、
if (C馬オッズ/B馬オッズ - 1.7)>0
(C馬オッズ/B馬オッズ - 1.7)
elif
0
因果関係はわかりませんが、人が必死に予測する内容に「勝つであろうと予測する馬とそれ以外の馬」の
間に、熱量(想いの強さ)のゆがみが発生している気がしています(笑
拾ってきた情報なので、ネタの一つだと受け取ってください(笑)
me.feature_importance(X)の引数Xはそのカラム名を使っているだけなので、カラムの順番さえ狂っていなければどちらでもいいとは思いますが、これは「学習の際どんな特徴量がそのモデルの精度にどれだけ関わったか」を示すものなので、通常XにはX_testではなくX_trainを入れるのがいいと思います。
X_testを入れる必要があるならば、me.feature_importance(X_test.drop(['単勝'], axis=1))でOKです。
ありがとうございます!
丁寧な説明で、やっと理解できました。
初めまして。3か月前に馬券購入の強化学習についての動画を上げていたと思うのですが、その部分のソースコードはあげていただけないのでしょうか?
私が見つけれてないだけなら申し訳ないです。
いつも為になる動画やコメントありがとうございます。私は地方競馬中心ですが予想に競馬AIを試しているのですが除外馬がいるレースの出馬テーブルのスクレピングができず悩んでいます。もし解決を知っている方いましたらお知らせして頂けたら大変助かります。
エラーは:
ValueError: Length of values () does not match lenght of index ()
カッコ内は数字。出走数(除外を除いた)とインデックス数です。
ShutubaTableクラスを次のように変更します。
#変更前
jockey_td_list = soup.find_all("td", attrs={'class': 'Jockey'})
#変更後
jockey_td_list = soup.find_all("span", attrs={'class': 'Jockey'})
変更前は、「tdタグでclass属性に'Jockey'という文字列が入っているもの」を検索します。中央の出馬表を見てみると、騎手情報は<td class="Jockey">に、除外となった馬の騎手情報は<td class="Cancel_NoData Jockey">に振り分けられているようです(参考: https://race.netkeiba.com/race/shutuba.html?race_id=202109011104 )。一方、地方では除外の騎手情報は<td class="Cancel_NoData">に振り分けられます。それゆえ、変更前のコードでは除外の騎手情報がスルーされてしまいます。
ただし、地方の場合は除外か否かに関わらず、tdタグの中に<span class="Jockey">というタグが作られるようで、必要な情報はその中にあります。したがって、"td"を"span"と変えることで対応できます。
なお、すでに対処済みかもしれませんが、地方のjockey_idはアルファベットも入る場合があるようですので、その部分も修正が必要です。
#変更前
jockey_id = re.findall(r'\d+', td.find('a')['href'])[0] #数字のみを抽出
#変更後
jockey_id = re.findall(r'jockey/(\w*)', td.find('a')['href'])[0] #'jockey/'より後ろの英数字(及びアンダーバー)を抽出
Resultsクラスも同様に変更が必要になるかと思います。
改善されました。大変助かりました。ありがとうございます。しかも生データのst.dataには除外された馬がスクレピングされているのにst.data_cには入っていないのです。私の知識では全くどうなっているのか分かりませんが、これがまさしく私が望んでいたことです。地方のjockey_idにアルファベットが入っていることは私も途中で気づいて再スクレイピングしました。2週間ほど解決しようとして何もできなかったことなので本当に助かりました。
「回収率122%の競馬予想AIを実際に使うには?〜後編〜」の動画の「17:36 新しい馬の血統データの扱い方」の部分で分からないところがでてきたので質問いたします。
エラー内容:'scrape peds at horse_id_list "no_peds"'が出てきてしまった。
該当のコードは
def merge_peds(self, peds):
self.results_pe = self.results_h.merge(peds,left_on='horse_id', right_index=True, how='left')
self.no_peds = self.results_pe[self.results_pe['peds_0'].isnull()]['horse_id'].unique()
if len(self.no_peds) > 0:
print('scrape peds at horse_id_list "no_peds"')
出馬表の
st.merge_peds(p.peds_e)
st.shutuba_tables_pe.head()
でエラーが起こらなかったのに、次の動画のクラスの継承のところでエラーが起こったのです。
r.merge_peds(p.peds_e)
r.results_pe.head()でまず起こり、
r.merge_peds(p.peds_e)
r.data_pe.head()親クラスを作った後でもやはり同じように"no_peds"が出てきてしまいました。
r.no_pedsで48個のhorse_idが出てきました。
その内の一つ'2017102027'ミアキヒルゼファーに関しては一度だけ出走していてresults.loc['201904020905']で見てみるとhorse_idもありました。
スクレイピングに関しては最近始めたので19年と20年のデータは全て揃っているのにはずなのにどうしてこのようなことが起こったのかが分かりません。動画ではエラーは起こらなかったですし。
簡単な問題かもしれませんが初心者なのでどうしてこうなったのかが分かりません。
よろしくお願いします。
詳しくは分からないですが、printで意図的に表示してるコメントみたいなので、その前のコードから推測するには
スクレイピングして保存しているpedsのデータに、no_pedsででてくる48個のデータが含まれていないのではないでしょうか。
horse_idにno_pedsを指定して、48個スクレイピングして、アップデートしてみてはいかがでしょうか
npeds = Peds.scrape(r.no_peds)
newpeds = update_data(p.peds, npeds)
こんな感じだと思います。
(私の環境では再現できないので、想像で書きました)
自分ももう一度スクレイピングするしかないなと思ってました。
コードも書いていただきありがとうございました。
お世話になっております。
06 実際に掛けてみた・・・ページで下にスクロールをしていただくと
本番の実行コードという見出しの中に以下のコードが有るかとおもいます。
scores = me_st.predict_proba(st.data_c.drop(['date'], axis=1), train=False)
pred = st.data_c[['馬番']].copy()
pred['score'] = scores
pred.loc['202105021211'].sort_values('score', ascending=False)
上記のコードのme_stというコードはどこから現れたのかご存じの方はいらっしゃいますか?
もし、知っているがいるなら教えていただけますと助かります。
私も何が正解は知りませんが下記のように'me.predict_'でエラーなく動いているので、これが正解だと思い使わせて貰っています。
Warningが出ている理由が分からず怖いです。
ですよね。。
ModelEvaluatorにしかpredict_proba関数はないので、
me.predict_probaとなるはずですよね!
共有していただいてありがとうございます!
初心者です。
Chapter 03のデータ前処理の所で
#5世代分の血統データの追加
st.merge_peds(p.peds_e)
#scrape peds at horse_id_list "no_peds"と表示された場合
peds_new = Peds.scrape(st.no_peds)
peds.to_pickle('peds_h.pickle') #pedsを更新する前にバックアップ
↑このコードを実行するとデータがありませんみたいなエラーが起きます。
このpeds_h.pickleはどこにあるのですか?
そもそも私の使い方が間違っているのかもしません。
もしかして#scrape peds at horse_id_list "no_peds"と表示された場合に以下のコードを使うってことですか?
peds = update_data(peds, peds_new)
peds.to_pickle('peds.pickle')
p = Peds.read_pickle(['peds.pickle'])
p.encode()
st.merge_peds(p.peds_e)
一行ずつ追っていくとわかりやすいと思います
「scrape peds at horse_id_list "no_peds"」と表示されたところは、pedsデータをResultsデータに追加しようとして、
Resultsの馬のうちpedsの中に血統データが無いから、no_pedsに保管している分を確認して!というところだと思います。
無いものは仕方ないので、peds_new = Peds.scrape(st.no_peds)でno_peds分をスクレイピングします。
保存してるPedsデータを簡単に上書きしたら、もし間違ってたら後戻りできないので、peds.to_pickle('peds_h.pickle')
で一旦バックアップ。
Peds.pickleがメインで、peds_h.pickleが何かあった時用のバックアップになってると思います。
peds = update_data(peds, peds_new)で、メインにno_pedsをスクレイプしたデータをくっ付けて、
peds.to_pickle('peds.pickle')で今後のために保存。
p = Peds.read_pickle(['peds.pickle'])で改めて読み込んで、p.encode()で使える並びに加工して
st.merge_peds(p.peds_e)で改めてResultsデータに追加。
たぶん、コードを更新続けていくうちに、調整が漏れたんだと思います。
お困りの所は、ちょっとコードの前のほうで ??? = Peds.read_pickle(['peds.pickle'])で、peds.pickleを最初に読み込んでるとおもいますが、Pedsのところは、???.pedsにするとうまくいくのではないかとおもいます。
>このpeds_h.pickleはどこにあるのですか?
peds_h.pickleが無いのではなくて、保存したいけどPeds変数には何も入ってないって言ってるのだと思います
丁寧に教えて頂きありがとうございます。助かりました。
一度実践してみます。
どうしても出馬表からオッズを取り出したいので以下のソースコードを書いたのですが、実行してみると最後の馬番のデータしか取得できませんでした。
以下のコードをどのように変更すればオッズデータを取得できるか、ご存知の方教えていただけないでしょうか?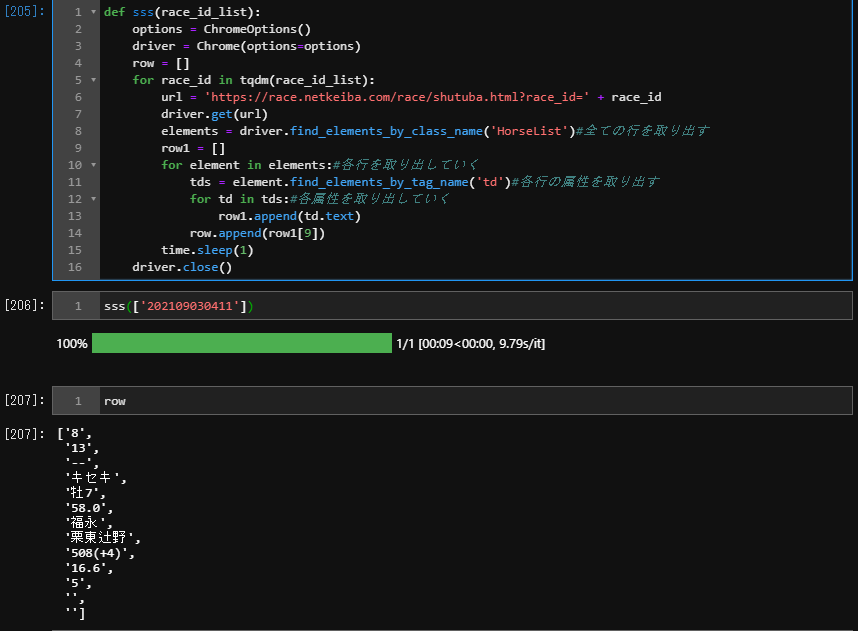
def sss(race_id_list):
options = ChromeOptions()
driver = Chrome(options=options)
row = []
for race_id in tqdm(race_id_list):
url = 'https://race.netkeiba.com/race/shutuba.html?race_id=' + race_id
driver.get(url)
elements = driver.find_elements_by_class_name('HorseList')#全ての行を取り出す
row1 = []
for element in elements:#各行を取り出していく
tds = element.find_elements_by_tag_name('td')#各行の属性を取り出す
for td in tds:#各属性を取り出していく
row1.append(td.text)
row.append(row1[9])
time.sleep(1)
driver.close()
sss(['202109030411'])
print(row)
実行結果
['8', '13', '--', 'キセキ', '牡7', '58.0', '福永', '栗東辻野', '508(+4)', '16.6', '5', '', '']
除外の馬はどうしますか?
例えば、除外などがあるレースの場合、r.data(rはResultsクラス)やst.data(stはShutubaTableクラス)と照合するなら、これらは除外の馬の行を削除する前なので、除外の馬のオッズに欠損値か何か入れておく必要があります(行数がずれるので)。
一方r.data_cやst.data_cと照合する場合、これらは除外の馬の行は削除されているので(厳密にはdata_pの時点で除外の馬の行は削除されています)、除外の馬のオッズは無視してもいい(スクレイピングしない)ことになります。
とりあえず簡単な後者の方のコードだけ貼っておきます。race_id_listを使われているので、race_idをindexにしたDataFrameの形で出力するようにしました。
from selenium import webdriver
import chromedriver_binary
def sss(race_id_list):
data = pd.DataFrame()
for race_id in tqdm(race_id_list):
time.sleep(1)
df = pd.DataFrame()
driver = webdriver.Chrome()
url = 'https://race.netkeiba.com/race/shutuba.html?race_id=' + race_id
driver.get(url)
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
odds_list = []
odds_td_list = soup.find_all("td", attrs={'class': 'Txt_R Popular'})
for td in odds_td_list:
odds = re.findall(r'bold">(\d+\.\d+)', str(td))[0]
odds_list.append(float(odds))
df['odds_list'] = odds_list
df.index = [race_id] * len(df)
data = data.append(df)
driver.quit()
return data
改善案を提案していただきありがとうございます!
今回必要なのはst.data_cと照合するためでしたのでご提案いただいたコードを実装し検討してみたいと思います。
ありがとうございます!
特徴量はオリジナルのものを追加してるいるけれども基本は掲載されているコード通りなのですが、optunaを使用すると最後に追加した特徴量を最重要視するという奇妙な現象が起きるのですが、皆様はどうなんでしょうか…
「最後に追加した」というのはオリジナルの特徴量ですか?最後に追加した特徴量を最重視するなんて現象、コードのミスとは考えにくいですし、普通に考えればリークがあるとかですかね…?
自分は特徴量の追加までまだできていないので何とも言えませんが…
お返事ありがとうございます。
最初にその現象に出くわしたのが主さんが追加した"n_horses"でした。何故か頭数が重要視されていておかしいなと思い他のどうでもいいような特徴量どれを入れても最後に追加したものが重要視されてしまうようになってしまいました…
optunaのバグなのか自分の何かが間違っているのか今研究中です(笑)
n_horses追加してみましたが、重要度は上から10番目でした。「optunaを使用すると」ということは使用しない場合は問題ないのでしょうか?だとするとそのあたりに何かミスがあるかもしれませんね。
初めまして。
質問させていただきます。
netkaiba.comからスクレイピング
の部分で紹介されているコードに関して、既に保存されている部分のcontinueが機能していないのですが、同じような状況の方はいらっしゃいますでしょうか?
また、以下の部分も機能していません。
test3 = scrape_race_results(race_id_list)
for key in test3:
test3[key].index = [key] * len(test3[key])
results = pd.concat([test3[key] for key in test3], sort=False)
results.to_pickle('results.pickle')
内容は特に書き換えておらず、そのまま実行しています。
また、pickleファイルを開こうとすると
:\Users\name\results.pickle is not UTF-8 encoded
のエラーが出ます。
コメント失礼します。
Returnクラスでのスクレイピングについて質問があります。
#払い戻し表データを処理するクラス
class Return:
@staticmethod
def scrape(race_id_list):
return_tables = {}
for race_id in tqdm(race_id_list):
try:
url = "https://db.netkeiba.com/race/" + race_id
#普通にスクレイピングすると複勝やワイドなどが区切られないで繋がってしまう。
#そのため、改行コードを文字列brに変換して後でsplitする
f = urlopen(url)
html = f.read()
html = html.replace(b'<br />', b'br')
dfs = pd.read_html(html)
#dfsの1番目に単勝〜馬連、2番目にワイド〜三連単がある
df = pd.concat([dfs[1], dfs[2]])
df.index = [race_id] * len(df)
return_tables[race_id] = df
time.sleep(1)
except IndexError:
continue
except Exception as e:
print(e)
break
except:
break
#pd.DataFrame型にして一つのデータにまとめる
return_tables_df = pd.concat([return_tables[key] for key in return_tables])
return return_tables_df
return_tables_df.to_pickle("return_tables.pickle")
このように記載しているのですが、
以下のようなエラーが出ています。
Resultクラス・Hose_Resultクラス・Pedsクラスまでは順調にスクレイピングできていましたが、
払い戻しの部分のみ上手く実行できません。初歩的な質問で申し訳ございませんが、解決策をご教示いただけますと幸いです。
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-26-d2b104e36dd5> in <module>
5
6 #払い戻し表データを処理するクラス
----> 7 class Return:
8 @staticmethod
9 def scrape(race_id_list):
<ipython-input-26-d2b104e36dd5> in Return()
40 return_tables = {}
41
---> 42 return_tables_df = pd.concat([return_tables[key] for key in return_tables])
43
44 return_tables_df.to_pickle("return_tables.pickle")
~\anaconda3\lib\site-packages\pandas\core\reshape\concat.py in concat(objs, axis, join, ignore_index, keys, levels, names, verify_integrity, sort, copy)
283 ValueError: Indexes have overlapping values: ['a']
284 """
--> 285 op = _Concatenator(
286 objs,
287 axis=axis,
~\anaconda3\lib\site-packages\pandas\core\reshape\concat.py in __init__(self, objs, axis, join, keys, levels, names, ignore_index, verify_integrity, copy, sort)
340
341 if len(objs) == 0:
--> 342 raise ValueError("No objects to concatenate")
343
344 if keys is None:
ValueError: No objects to concatenate
最下部の書き換えで解決しました(__)
return_tables = Return.scrape(race_id_list)
return_tables.topickle('return_tables.pickle')
me = ModelEvaluator(lgb_clf, ['return_tables_2017.pickle','return_tables_2018.pickle','return_tables_2019.pickle','return_tables_2020.pickle','return_tables_2021.pickle'])
#単勝適正回収値=払い戻し金額が常に一定になるように賭けた場合の回収率
g_proper = gain(me.tansho_return_proper, X_test)
#単勝の回収率
g_tansho = gain(me.tansho_return, X_test)
#プロット
plt.plot(g_proper.index, g_proper['return_rate'])
plt.plot(g_tansho.index, g_tansho['return_rate'])
plt.grid()
としたところ
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-30-4819ef9dd1e3> in <module>
2
3 #単勝適正回収値=払い戻し金額が常に一定になるように賭けた場合の回収率
----> 4 g_proper = gain(me.tansho_return_proper, X_test)
5 #単勝の回収率
6 g_tansho = gain(me.tansho_return, X_test)
<ipython-input-19-562656c8c820> in gain(return_func, X, n_samples, min_threshold)
4 for i in tqdm(range(n_samples)):
5 threshold = 1 * i / n_samples + min_threshold * (1-(i/n_samples))
----> 6 n_bets, return_rate, n_hits = return_func(X, threshold)
7 if n_bets > 2:
8 gain[n_bets] = {'return_rate': return_rate,
ValueError: too many values to unpack (expected 3)
とエラーになってしまいました。
こちらは何が原因になりますでしょうか?
よろしくお願いいたします。
gain()を次のように修正します。
#変更前
n_bets, return_rate, n_hits = return_func(X, threshold)
#変更後
n_bets, return_rate, n_hits, std = return_func(X, threshold)
右辺の戻り値の数が左辺の変数の数と合っていないのがエラーの原因です。
return_funcにはgain()の1つ目の引数が入ります。
me.tansho_return_proper()やme.tansho_return()を見てみると、
return n_bets, return_rate, n_hits, std
となっているので、左辺にも4つの変数を設けてあげる必要があります。
ありがとうございます。こちら試したところ
g_proper = gain(me.tansho_return_proper, X_test)
で
0%| | 0/100 [00:00<?, ?it/s]
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-65-e618dcdc9ddb> in <module>
----> 1 g_proper = gain(me.tansho_return_proper, X_test)
<ipython-input-7-4b6bde1d804a> in gain(return_func, X, n_samples, min_threshold)
4 for i in tqdm(range(n_samples)):
5 threshold = 1 * i / n_samples + min_threshold * (1-(i/n_samples))
----> 6 n_bets, return_rate, n_hits, std = return_func(X, threshold)
7 if n_bets > 2:
8 gain[n_bets] = {'return_rate': return_rate,
<ipython-input-3-40431ea3ef86> in tansho_return_proper(self, X, threshold)
117 #単勝適正回収値: 払い戻し金額が常に一定になるように単勝で賭けた場合の回収率
118 def tansho_return_proper(self, X, threshold=0.5):
--> 119 pred_table = self.pred_table(X, threshold)
120 n_bets = len(pred_table)
121
<ipython-input-3-40431ea3ef86> in pred_table(self, X, threshold, bet_only)
46 def pred_table(self, X, threshold=0.5, bet_only=True):
47 pred_table = X.copy()[['馬番', '単勝']]
---> 48 pred_table['pred'] = self.predict(X, threshold)
49 if bet_only:
50 return pred_table[pred_table['pred']==1][['馬番', '単勝']]
<ipython-input-3-40431ea3ef86> in predict(self, X, threshold)
33 #0か1かを予測
34 def predict(self, X, threshold=0.5):
---> 35 y_pred = self.predict_proba(X)
36 return [0 if p<threshold else 1 for p in y_pred]
37
<ipython-input-3-40431ea3ef86> in predict_proba(self, X, train, std, minmax)
16 if train:
17 proba = pd.Series(
---> 18 self.model.predict_proba(X.drop(['単勝'], axis=1))[:, 1], index=X.index
19 )
20 else:
~/.pyenv/versions/anaconda3-5.3.1/lib/python3.7/site-packages/lightgbm/sklearn.py in predict_proba(self, X, raw_score, start_iteration, num_iteration, pred_leaf, pred_contrib, **kwargs)
918 pred_leaf=False, pred_contrib=False, **kwargs):
919 """Docstring is set after definition, using a template."""
--> 920 result = super().predict(X, raw_score, start_iteration, num_iteration, pred_leaf, pred_contrib, **kwargs)
921 if callable(self._objective) and not (raw_score or pred_leaf or pred_contrib):
922 _log_warning("Cannot compute class probabilities or labels "
~/.pyenv/versions/anaconda3-5.3.1/lib/python3.7/site-packages/lightgbm/sklearn.py in predict(self, X, raw_score, start_iteration, num_iteration, pred_leaf, pred_contrib, **kwargs)
723 "match the input. Model n_features_ is %s and "
724 "input n_features is %s "
--> 725 % (self._n_features, n_features))
726 return self._Booster.predict(X, raw_score=raw_score, start_iteration=start_iteration, num_iteration=num_iteration,
727 pred_leaf=pred_leaf, pred_contrib=pred_contrib, **kwargs)
ValueError: Number of features of the model must match the input. Model n_features_ is 186 and input n_features is 185
となりました。どうもデータが合わないっぽいのですが何が原因でしょうか?
モデル(lgb_clf)に入れたトレーニングデータ(X_train)の特徴量の数(カラム数)が、テストデータであるX_testの特徴量の数と一致していないのが原因と思われます。
トレーニングデータとテストデータは、カラム数もカラムの順番も一致させる必要があります。ただしテストデータの'単勝'に関しては、コードの設計上一時的に残しておく必要があり、実際のシミュレーションの際にはdropされるようになってるので、
pd.set_option('display.max_columns', 190) #表示する最大カラム数を190に設定。
X_train
と
X_test.drop(['単勝'], axis=1)
をそれぞれ別のセルで実行して比べてみてください。おそらくX_trainのほうが何か1つ多くなっていると思います。
ありがとうございました!何とか動きました。
単勝カラムのdropが違ったみたいでした。
競馬好きな初心者ですがいつも拝見させてもらい勉強させていただいております。
質問なんですが馬体重を出馬表に抽出しないようにできますか?
class ShutubaTableにて↓
df.columns = ['枠', '馬番','印', '馬名', 'horse_id', '性齢', '斤量', '騎手', 'jockey_id',
'馬体重', '単勝', '人気','course_len','race_type','weather','ground_state','date']
この中の馬体重を除外してもうまくいきません。
近年では長期休養や外厩調教で馬体重の大きな増減があっても活躍する馬が多いのでいっそのこと馬体重変化を抽出項目に入れないほうが回収率アップになるのではないかと思い検証したく思っております。
※7月4日CBC賞 ファストフォース(-18減)でもレコード優勝
何卒、ご教授いただけますようよろしくお願い申し上げます。
抽出というのはスクレイピングのことでしょうか?
とりあえず、'馬体重'は'体重'と'体重変化'という特徴量に変換されるので、'馬体重'を操作するとその部分も変更しなければならず面倒になります。スクレイピングしなおすのも面倒です。なので、最終的なデータから'体重'と'体重変化'というカラムをdropしてしまいましょう。
それと、検証するだけならShutubaTableクラスは使わず、r.data_cを訓練データとテストデータに分け、テストデータを使ってModelEvaluatorクラスで検証する方が早いと思いますが、なにか独自のやり方でされているのでしょうか?いずれにしても、ShutubaTableクラスを使うのであれば、st.data_cとr.data_c.drop(['単勝', 'rank'], axis=1)のカラムの数や順番が一致するよう注意してください。
st.data_c = st.data_c.drop(['体重', '体重変化'], axis=1)
#訓練(&テスト)データとなるr.data_cも同様にします。
r.data_c = r.data_c.drop(['体重', '体重変化'], axis=1)
それと、余談ですが'回収率'で比較するのはお勧めしません。optunaが「最適」とする基準は回収率ではありません。同じデータであっても、optuna_seedを設定しなければ、特に三連複などは実行のたびに回収率は大きく変化します。optuna_seedを設定すればそのランダム性はなくなりますが、新旧データの比較では「設定したシード値が、たまたま新しい方のデータに有利に働くものだった」ということもあり得ます(そもそも'回収率'をどう評価するのかという問題もあります)。
このAIが「改善した」と言えるのは、「3着以内かどうか」の正解率が上がった時だと思うので、比較はaucスコアで行うことをお勧めします。もちろんこれもシード値によって多少ブレはありますので、例えばスコアが一定以上上がったなら、optuna_seedを設定せず複数回学習させてみて、平均して明らかな上昇傾向がみられるなら「改善した」として新しいデータを採用する、などがいいかと思います。
ご丁寧にありがとうございます。
お陰で馬体重を考慮しない予測ができるようになりました。
第5回の動画について、質問をお願いします
このように、KeyError:着順 と出て、どうしてうまく行きません。
素人の推測ですが、2行目でget_dummiesをしているので、この段階だとresults_dは「着順_1」、「着順_2」 … となっています。よって、3行目の「着順」がないので、エラーが出ていると思います。
ご指導いただければ幸いです
ご指摘の通り"着順"列が先にダミー変数化されているため、"着順"列が無くなるはずです。
単純にエラーを回避するだけならば以下のようにコードを変更すれば良いと思います。
results_p["rank"] = results_p["着順"].map(lambda x: x if x < 4 else 4)
results_p.drop(["馬名", "着順"], axis=1, inplace=True)
results_d = pd.get_dummies(results_p)
train, test = split_data(results_d, test_size=0.3)
X_train = train.drop(["date", "rank"], axis=1)
y_train = train["rank"]
X_test = test.drop(["date", "rank"], axis=1)
y_test = test["rank"]
返信ありがとうございます。
やってみたのですが、今度は
TypeError: '<' not supported between instances of 'str' and 'int'
というエラーが出ました
results_dを出力すると、データフレームには着順がなくなり、rankが1~4となっていますが...
対応策について、あらためて教えていただけると幸いです
あと、せっかくなので、重ねて伺います
完全版のコードを上から順に実行しているのですが、どうして「KeyError:着順 」と出てしまうのでしょうか?
コピペも試しているので、打ち間違いではないと思うのですが
試しにテストしてみましたが私の環境では問題なく動きました。
エラー内容としては文字列型が着順列内にいると考えられます。
処理前にpreprocessing関数での処理は実施したでしょうか?
results = pd.read_pickle("ファイル名")
results_p = preprocessing(results)
↑を実行してから
results_p["rank"] = results_p["着順"].map(lambda x: x if x < 4 else 4)
で動作するかと思います。
追加質問の補足になりますがソースコードとして貼り付けてあるものと動画内で実際に使っているコードは100%一致しているわけではありません。(私が見た限りでは)
コピペしているだけだと不一致部分でつまづいてしまうと思いますので、初心者の場合は動画メインの学習をお勧めします。(私も初心者でそのように学習しました)
毎回、ご丁寧にありがとうございます。初心者の場合は、動画優先が良いんですね。教わったことを生かして、引き続き格闘してみます!
本が新しく更新されましたね。質問ばかりで申し訳ないですが、現状の予測されるスコアを各馬の「勝率」に変換する方法が思い付きません。(統計と組み合わせる!?)ご存知のかた居られたら、教えて頂きたいです。
モデルが出すのは「複勝率(厳密には3着以内率)」で「勝率(1着率)」とは全く違う性質なので、数学的なアプローチで導くのは難しいのではないかと思います。
「1着かどうか」を予測するように学習させたモデルを別に用意してあげるのが一番手っ取り早いのではないでしょうか。
もしくはテストデータをme.tansho_returnでシミュレーションして n_hits / n_bets でそのthreshold以上の馬に賭けたときの勝率がわかるので、そのシミュレーションを元に「この馬のスコアはこのthreshold以上だから、勝率は〇%のはずだ」という見方はできるかもしれません。といってもこれは「馬の勝率」ではなく、「予測スコアの勝率」ですが…。加えて、そのthresholdにおけるn_betsが十分大きくないと信用できる数値にはならないので、必然的に低い値のthresholdしか参照できず、かなりぼやけたものになってしまうと思われます。
なお、「実際に賭けてみた結果・・・」にあるようなscoreを、モデルが出した確率で表示したいということであれば、これはme.predict_proba()の標準化前のprobaに入っていますので、引数に std=False とすれば出すことができます。
最終的にオッズで期待値を出すなら、勝率が欲しいですよね。
std=False にして
pred['score'] = scores / scores.sum()
でどうでしょう。複勝率ですし厳密には違いますが。
皆様、わざわざありがとうございます!!
複勝率でも勿論良いのですが、モデルが出すのは、レースに出馬する馬の中での確率では無いと思うので期待値計算には使えないのですよね。
なのでNobu Sさんの提示してくださったやり方はだいぶ近いのかなと思います。
モデルで「強い馬」を選んで回収率を調べてもそれは結局80%に近付くだけなんですよね(当りまでですが)。
研究続けてみます。いつもすみません。
これは最終的に1Rずつ出す場合ですね。(実際に賭けてみた結果・・・のところ)
モデルを作る段階ではレースごとに計算しないとならないので、groupbyとか使うのでしょうか?
どなたか分かる方がいればお願いしたいです。
私も最終的にはレース内の確率とオッズでシミュレーションしたいです。
二段階方式にすれば出来そうですけどどうなんでしょうかね、一度ふつうに計算させてその結果をデータフレーム化してgroupbyするんですかね。素人なんであれですが…
質問の趣旨を勘違いしていました。すみません。
最終的にどういう形にしたいか次第ですが、me.predict_probaの中で、標準化する前にself.proba = probaを入れて外部からprobaにアクセスできるようにしておいて、
me.proba.groupby(level=0).apply(lambda x: x / x.sum())
でどうでしょう?
スマートな式ありがとうございます!!
いつも参考になります。
新しく更新された「3連単流し」について質問があるのですが
例えば
馬番13のスコアが最も高く、馬番5のスコアが2位でこの2頭が「軸馬」の場合
13-5からの流しになるのが良いと思うのですが
現状のコードでは
5-13からの流しになっていないでしょうか?
私もKさんの意見を見て気になったため調べてみました。
pred_tableをそのまま使っていることが原因と考えます。
pred_tableはX_testを基に作られており、さらに遡ればスクレイピングしたレース結果が基になっています。
つまり、レース順位通りにデータが並べられている=2頭軸の1,2着がすでに分かっていることになります。
異様に回収率が高いのはこれが原因です。
2頭軸の表裏を買うor事前にsort_valuesでscore順に並べ替える処理を追加すべきではと思います。
返信ありがとうございました。
回収率がものすごく高かったので驚きましたが、リークがあったのですね。
sort_valuesでかなり下がりました。
購入しましたが、class 毎のソースコード記述が雑多に記載されているだけで、最終的な全体のソースコードがないため、端的な情報のみが記載されているだけで、全体像が掴めない構造になっているように感じます。
全体的なソースコードを記載し、かつ購入者が容易に改変できるような記述になりませんでしょうか?
このままだとググって情報を収集し、ツギハギだらけのソースを書くのと何ら変わりはなく、わざわざ購入する必要性がないように感じてしまいます。
def update_data(old, new):
スクレイピングの重複除去のために必要かと思いますが、こちらの関数はどこで、どのように使っておられるでしょうか、、
解説用の動画も解像度が低く、その点も敷居が高く感じてしまいます。
おっしゃってることは何となく理解できるのですが、全体を把握する方法が本書にもないように感じております。
全体的に構成の改善をお願いできないでしょうか?
全体的なソースコードがあって、ここを変えたければ、こうしな、というのが理想なのですが、、
こんにちは。
この本はYouTubeのソースコードをまとめたものですので 「競馬予想で始める機械学習・データ分析」 のチャンネルを見れば内容は分かると思いますよ。
確かに最初の頃は解像度が低くてコードが分かりづらいですが、そこでこの本が役に立ちます。
題名にもあるように目的は機械学習とデータ分析の勉強がメインで、それを競馬予想AIを作りながら教えてくれます。私はプログラミングの初心者ですが、一から見ていますので全体像はもちろん、かなり勉強になっています。
確かに、松風AIやゆま牧場とまではいかなくても、ある程度完成された競馬AIのソースコードがあって、あとは特徴量だけオリジナルに追加できるなら私も欲しいですが、さすがに2,000円では無理ですし・・・。
ただ、作者さんも理想が高いので数年後にはそれに近いものが出来るかもしれませんね。
お互い頑張って勉強しましょう!
def update_data(old, new):
ご質問の回答ですが、このコードは馬の過去成績をスクレイピングした際に使用します。最初は良いのですが、最新の過去成績を取得すると、以前取得した馬も含まれてしまいますので、その馬は最新のデータに置き換えます。
動画は【スクレイピング】回収率122%の競馬予想AIを実際に使うには?〜前編〜【Python】
ご返信ありがとうございます。
私も初心者であり、理解を深めようと思っておりますが、
全体像はわかります。でも、細部がわからず、、といった状況です。
例えば結果のスクレイピングですが、年度毎に毎回する必要はなくてpickle形式で保存するというのはわかるのですが、年度を2019、2018と増やしていったときにどのように処理すればいいのか?
馬毎の成績や血統を得るための、horse_id のリストはどこから取得するのかなど。
.ipynbを公開していただければ、こういう使い方をするのかと、理解が深まるのではないかと思っております、、
確かに、松風AIやゆま牧場とまではいかなくても、ある程度完成された競馬AIのソースコードがあって、あとは特徴量だけオリジナルに追加できるなら私も欲しいですが、さすがに2,000円では無理ですし・・・。
的中率が良いものが欲しいのではなくて、見様見真似でまずは素人でも動かせるコードが欲しいのです。
値段云々はどうでもいいというか、、設定したのはこちらではないですし、、
ただ、有料ではありますよね?という、、
2000円だからこの程度でいい、という思想であれば仕方ないですが、、
optunaとLightGBMを使った学習は、その基本的な流れはほとんど共通であり、以下のようになっています。
データの用意
↓
データの加工・前処理
↓
データセットの作成(訓練データとテストデータ)
↓
optunaでハイパーパラメータの生成
↓
LightGBMで学習、モデルの作成
↓
作成したモデルを評価
本プログラムも現状ほとんど同様ですが、「A: シミュレーションによるモデルの評価」と「B: 実際の予想」という別々のゴールが設定された2種類のパターンがあります。
モデルの改善を目指す場合は、前者を繰り返します。実際の運用を目的とする場合は、一度前者でシミュレーションし馬券購入パターンを見極めた後、前者で作ったハイパーパラメータを流用して「実際の予想」を行います。それぞれの流れは以下のようになっています。説明のために番号を振ります。
Aのパターン
1: データの用意(スクレイピング)
↓
2: データの加工・前処理
↓
3: データセットの作成(訓練データとテストデータ)
↓
4: optunaでハイパーパラメータの生成
↓
5: LightGBMで学習、モデルの作成
↓
6: シミュレーションによるモデルの評価
Bのパターン
7: データの用意(スクレイピング)
↓
8: データの加工・前処理
↓
9: データセットの作成(訓練データのみ)
↓
10: ハイパーパラメータを流用してLightGBMで学習、モデルの作成
↓
11: 実際の予想
とりあえずAのパターンについて理解できれば凡そ全体像はつかめると思うので、Aのみ説明します。本書完全版Chapter03~05を元に解説します。
1で使うクラスは、DataProcessor, Results, HorseResults, Pedsです。
※厳密にはここではDataProcessorは使いませんがResults(とShutubaTable)の抽象クラスなので一緒の扱いとしておきます。実行時にはあまり意識しなくて大丈夫です。なお、ShutubaTableクラスはAのパターンでは使いません。
1ではこれらのクラスを使ってスクレイピングを行い、データの用意をします。
#race_id_listの作成は省略
results = Results.scrape(race_id_list)
horse_id_list = list(results['horse_id'].unique())
horse_results = HorseResults.scrape(horse_id_list)
peds = Peds.scrape(horse_id_list)
results.to_pickle('results.pickle')
horse_results.to_pickle('horse_results.pickle')
peds.to_pickle('peds.pickle')
#既にスクレイピングされたデータがある場合は以下だけでOK
r = Results.read_pickle(['results.pickle'])
hr = HorseResults.read_pickle(['horse_results.pickle'])
p = Peds.read_pickle(['peds.pickle'])
実際のデータは、r.data, hr.horse_results, p.pedsに入っています。
2で使うクラスはDataProcessor, Results, HorseResults, Pedsです。
2ではこれらのクラスを使ってデータを加工します。必要な処理を行いつつ、r.dataのデータにhr.horse_results, p.pedsのデータを追加していくイメージです。詳細はコードを読むなりしてください。
r.preprocessing()
r.merge_horse_results(hr, n_samples_list=[5, 9, 'all'])
p.encode()
r.merge_peds(p.peds_e)
r.process_categorical()
最終的なデータはr.data_cに入ります。
3, 4, 5で使う関数は、split_data関数です。
3, 4, 5ではsplit_data関数を使ってr.data_cのデータを訓練データとテストデータに分けた後、optunaでハイパーパラメーターを生成し、それを使ってLightGBMで学習を実行、モデルの作成を行います。
これに関してはほとんど実行コードなのでChapter04を読んだ方が早いでしょう。
モデルはlgb_clfに入っています。
6で使うクラス・関数は、Return, ModelEvaluator, gain関数, plot関数です。
※ReturnクラスはModelEvaluatorクラスのインスタンスを作る際に呼び出されますが、特に意識的に実行するクラスではないのでとりあえずオッズの情報をスクレイピングするときに使うものという認識でOKです。オッズの情報は、ModelEvaluatorクラスの中でシミュレーションの際に回収率等を算出するために使われます。
6ではModelEvaluatorクラスを使ってシミュレーションを行います。ModelEvaluatorクラスは基本的にはgain関数によって呼ばれます。ModelEvaluatorクラスはシミュレーションをする機械本体、gain関数はそのスイッチといったイメージでいいでしょう。plot関数でシミュレーション結果をグラフ化して表示します。
#シミュレーションの前にオッズのスクレイピングがまだの場合は行います。
race_id_list = list(X_test.index.unique())
return_tables = Return.scrape(race_id_list)
return_tables.to_pickle('return_tables.pickle')
#既にスクレイピングされたデータがある場合は以下だけでOK
me = ModelEvaluator(lgb_clf, ['return_tables.pickle']) #インスタンスの生成
g_tansho = gain(me.tansho_return, X_test) #引数はModelEvaluatorクラス内の関数から望む賭け方を。ここでは単勝を例示。
plot(g_tansho, 'tansho')
g_tanshoにはシミュレーション結果がDataFrameの形で代入されます。
Bのパターンではこのシミュレーションの代わりに実際の予測を行います。やってることはほとんど同じで、Aのパターンでは作成したテストデータの代わりに、実際に予測したいレースのデータを使うというだけです。実際に予測したいレースのデータはShutubaTableクラスを使ってスクレイピング・加工をします。Chapter06を参照してください。
私はこの本の構成はよくまとまっていると思います。少なくともツギハギではありません。
Keshikiさん
詳しい説明ありがとうございます。
なるほど、このようにコードを書けばある程度一発で実行できるのですね。
大変勉強になります。
jltさん
私もあらためて本書の01.はじめに~05.モデル評価&回収率シミュレーションまでをソースコードをコピペとコメントを記入して、一つの.ipynbを作ってみましたが、数時間で全体のコードが完成し実行できました。(データは既にあるのでスクレイピングはしていませんが)
一度作成してみると流れが分かるかもしれません。ただし細部までは動画を見ないと分からない部分もあると思います。
Keshikiさんのおっしゃる通り、機械学習のモデルを作るには段階を踏まないとできないようですので、一つのコードを実行!では出来ないようです。ただしKeshikiさんが載せてくれたコードを実行すると最小限で実行できそうです。
最終的なモデルが完成し実際の予想時には完全自動化も出来るみたいですが、本書ではまだそこまではいっていません。
私も本書はよくまとめられていて、現時点でも素晴らしいものと思っています。
Keshiki さん
Nobu S さん
詳しいご解説をありがとうございます。
Chapter 02 と Chapter 03 に同じ class 名があって何故?となっておりましたが、
Chapter 02 をほぼ全無視、Chapter 03 からだけのコード+αのトライ&エラーで、おかげさまで無事に Chapter 06 まで完遂することができました。
つまり、予想まで実行できたことになります。
本当にありがとうございます!
Chapter 03 からソースコードだけですと update_data 関数についての記述がなく、また、これは各 class に付与するメソッドだと勘違いしていたのですが、class 外に記載するグローバルな関数なのですね、、
この辺が初心者なので理解できず、完遂まで時間がかかったとこです。
無事に完遂できたのですが、ソースコードのインデントがおかしい部分が多々あり、
そこは作者さんに修正をしていただきたいところです。
単なるコピペだけだと、このコードは for 文の中?外?というエラーも多くあり、
ハマるポイントかと思っています
はじめして。最近プログラミングを学び始めたものです。
まずは見様見真似でやってみようと思い、Chapter 02に記載されているResults.scrape()で
レース結果データをスクレイピングしてみようとしたのですが、データを読み込んでいる途中で
<urlopen error [WinError 10060] 接続済みの呼び出し先が一定の時間を過ぎても正しく応答しなかったため、接続できませんでした。または接続済みのホストが応答しなかったため、確立された接続は失敗しました。>
といったようなエラー?が出てしまいスクレイピングすることができません。コードは記載されているものをそのまま使っています。
解決策を教えていただけると非常に助かります。
どのような環境かはわかりかねますが、エラー内容にあるとおり、
単純に実行環境から netkeiba に接続できてないだけかと思います
Proxy 環境内にあるのであれば、Proxy 設定の見直し
docker 環境内にあるのであれば、dokcer から外部ネットワークに接続できるかなど設定の見直し
この辺が参考になるかもしれません。
いずれにしましても、ソースではなく実行環境の問題ですので、まずは環境の見直しをしていただければと思います
ご丁寧にありがとうございます!
見直してみます。
<urlopen error [Errno 11001] getaddrinfo failed>
昨日完全版を購入し、スクレイピングの作業をしていたところ先ほどから急にこのエラーコードが出るようになりました。恐らく競馬予想AIをコーディングする過程でのエラーではないと思うのですが、同じ問題を抱えている人がいるようなのでここで質問させていただきました。どうぞよろしくお願いします。
今朝もう一度やってみたところ、現状では正常にスクレイピングが出来ています。7月23日の0時ごろから調子が悪かったのでDNS障害の影響かと思うのですが、他の皆さんは同じようなエラーに遭遇したでしょうか。
コッシーさんの報告にもあるように、netkeiba 側の DNS 名前解決の一時的なエラーかもしれません。再度試してみてスクレイピングがうまくいけば、名前解決の一時的なエラー、そうでなければ、実行環境のネットワーク周りのエラーかと思われます
回収率(return_tables)のスクレイピングに関して、質問があります。
完全版を購入し、「単勝回収率が159%に到達!」の動画まで視聴しています。
動画のコード(chapter8-20)・完全版のコード(chapter2-5)をそれぞれ実行してみましたが、うまくいきません。
動画の場合は、testデータとして3割をスクレイピングしています。
完全版の説明(Return.scrape())を実行すると、1年分のデータをスクレイピングしています。
--質問--
1.どちらの方法(動画・本)で進めると良いですか?
2.return_tablesのスクレイピングは、どのコードを使用していますか?
3.chapter8-20のコードを使用するならば、いつ頃のデータを使用すると良いでしょうか?
--本について--
現在は2021年です。「2020年以前のデータのみを使用・2021年は後で追加」という内容であれば、全員同じようなグラフや結果が作成できるのになぁ。。。と思います。
今後始める人は同様の回収率などのグラフが、データによって変わってくると思います。
また、購入している人は分からなくなったら、「本のコードをコピペする」ことで「とりあえず、エラーなく動く」という状態に近づけるのではないか?と思います。
その結果として、作者さんへの似たような質問(動画や本と同じようにコードを入力したのに動かない!など)が減ると思いますが・・・
私もそのとおりだと思っていて、断片的にソースコードを掲示され、やっぱりこう改変しましょう、だと何が正なのかわからない状況です。
機会学習の部分は、非公表、不完全でもいいのですが、全体を一貫して実行できるコードが欲しいです
1.どちらの方法(動画・本)で進めると良いですか?
どちらでも構いません。私は初心者でしたが、テキストベースでの勉強がしたかったため、本を中心に進めました。「はじめに」にもある通り、この部分は「ある程度Python、機械学習に精通している方」を対象としているので、作ったクラスの使い方など、基本的な部分についてはYoutubeを見るなりして自分で調べながら進めました。動画の場合は、初歩的な部分の説明やコードの設計についても順に解説されていますが、その性質上情報のアップデートが難しいので、後になって「このやり方は間違っていた」といった少し冗長な部分もあるようです。こちらの場合も本を補助的に使い、うまく情報を整理しながら進めましょう。
2.return_tablesのスクレイピングは、どのコードを使用していますか?
race_id_list = list(X_test.index.unique())
return_tables = Return.scrape(race_id_list)
本に準拠しています。
3.chapter8-20のコードを使用するならば、いつ頃のデータを使用すると良いでしょうか?
いつのデータを使っても問題ありません。3年程度の量はあった方がいいかもしれません。
現在は2021年です。「2020年以前のデータのみを使用・2021年は後で追加」という内容であれば、全員同じようなグラフや結果が作成できるのになぁ。。。と思います。
今後始める人は同様の回収率などのグラフが、データによって変わってくると思います。
結果が全く同じでないと不安になる気持ちはわかりますが、特に問題ないので安心してください。
jltさん
やはり、関数などのコードがあれば、初心者にも分かりやすいかと思います。
5月の中頃にYouTubeで見つけて6月の初めに完全版を購入しました(初心者のため「教科書ver.」で良かったですが、完全版が売れているらしいので。)。
ほぼ毎日動画を1本ずつ進めていましたが、回収率のグラフや思ったように進めないことが多々あります。
pythonはソフトウェアなので、更新することで操作方法やコードが変わることは仕方ないと思っています。
「一貫して実行できるコード」はできれば私も欲しいですが、テキストの目的が「機械学習の勉強」のため、難しいかもしれません。
ただ、optunaの計算結果や訓練データ・testデータなど、曖昧な点がいくつかあります。プログラム(パッケージ?)の性質上、仕方ない点はありますが、「どのくらいの数値なら異常(回収率)」・「同じようにやったら、小数点以下の桁数は同じくらいになるはず!(optunaの結果)」などのコメント・ヒントがあると助かると思います。
話は脱線しますが、「最新のところまで進めました!」「ここまで何時間くらいで出来ました!」のようなコメント欄、投票機能などあるいいなぁと思います。元気づけられる人、「今は使えないのか?」と不安な人を減らせるかも。。。このテキストの信頼度も増しそうですし。
Keshikiさん、ご回答ありがとうございます。
競馬予想AIの回収率を約35%上げる馬券の買い方とは?【機械学習】(第24回)の動画で、うまくいかなくなったため、前の動画に戻る・最初から動画の全てのコードを書いてみるなどをしてみました。
不安に感じた内容
chapter02-05のコードを実行したところ、進められそうだと感じて進めています。
optunaを実行したところ、lambda_l1'・lambda_l2のバラつきが大きく、違和感を感じました。
{ 'lambda_l1': 1.7926979585127533e-06,
'lambda_l2': 5.999007532418601,}
このコミュニティにバラつきがあるとは記載されていますが、私の場合e-06、6.○○など、桁が6,7のバラつきがありました。
現在は、2019・2020年のデータを使用しています。
2018年を追加して、もう一度やり直してみます。
質問があります
「3年程度の量はあった方がいいかもしれません。」とのご回答があり、質問させていただけますでしょうか?
このデータはどのように使用していますか?
動画で2枚目のシートに移行したときに使用したやり方(update_data関数・concat)で、1つのデータにまとめ、「データ加工・前処理」からやり直そうと考えています。
しかし、「実際に賭けてみた結果・・・」ではhorse_results.pickleを年ごとに分けて追加していたので。。。
lambda_l1'・lambda_l2のバラつきが大きく、違和感を感じました。
lambda_l1, lambda_l2などのoptunaが出すハイパーパラメータの値は人間には理解できない…というか専門的すぎるので気にしなくて大丈夫です。
私がやった実験の記録の中に
{'lambda_l1': 7.799143053839719e-05,
'lambda_l2': 5.985239797542531,}
となっているものもありましたので安心してください。
それよりも重要なのは、学習モデル(lgb_clf)のauc scoreです。予測の正答率のようなものです。
以下のようにして算出できます。
from sklearn.metrics import roc_auc_score
roc_auc_score(y_test, lgb_clf.predict_proba(X_test))
本プログラムではこれが0.7~0.85あたりなら、データの収集~加工~optuna~LightGBMでの学習 まではひとまずうまくいっていると考えてOKです。0.5とかだと50%なのでほとんど当てずっぽうといった感じです。0.9を超えてくるとリークを疑った方がいいかもしれません。
注意したいのは「回収率では(単純には)比較できない」という点です。ややこしいですが、使っているデータが違えば当然結果は違いますし、使っているデータが同じでもoptunaが出すハイパーパラメータが違えば、auc scoreがほとんど同じ値だったとしても回収率は異なることがあります。
ただし、auc scoreが異常な値でなければ、bet数が十分に多い部分(7000くらい~)の回収率については通常そこまで差が出ることはありません。例えば単勝なら7000も賭ければ、現状のこのAIでは普通80%くらいの回収率に落ち着くはずですが、ここが30%しかないとか、120%超えるなどであれば異常だと考えられます。その場合、auc scoreに異常がないことは確認済みですので、データの収集~加工~optuna~LightGBMでの学習 までは問題ない、つまりシミュレーションを行う部分のコードに問題がある可能性が高いと判断できます。
質問
書籍の方ではHorseResults.read_pickle()の引数には、リストにして複数のpickleファイルを読み込めるようになっています(ResultsクラスやPedsクラスも同様です)。したがって、
#リストを代入した変数を入れる
horse_results_list = ['horse_results_2019.pickle', 'horse_results_2020.pickle']
hr = HorseResults.read_pickle(horse_results_list)
#複数のpickleファイルを入れる
hr = HorseResults.read_pickle(['horse_results_2019.pickle', 'horse_results_2020.pickle'])
#update_data関数やconcatで1つにまとめたデータを入れる
hr = HorseResults.read_pickle(['horse_results_all.pickle'])
以上のいずれのやり方でも問題ありません。
※書籍の方ではhr = HorseResults.read_pickle('horse_results_list')となっていますが、正しくはhr = HorseResults.read_pickle(horse_results_list)だと思います。
ただ、動画の方をざっくりと確認しましたが、動画の方ではそもそもHorseResultsクラスの中にread_pickle関数がないのではないでしょうか?
その場合、おそらく「クラスの引数に一つの変数を入れる」という形になっていると思いますので、
#変数に、1つにまとめたデータを代入してから
horse_results = pd.read_pickle('horse_results_all.pickle')
#クラスの引数にその変数を入れる
hr = HorseResults(horse_results)
という風にしてください。
keshikiさん、コードや具体的な数値の目安・判断基準を説明いただき、ありがとうございます。
lambda_l1'・lambda_l2について
optunaの計算結果について、「毎回同じような結果が出るもの」と考えていたため、値の違い・桁数の違いに違和感がありました。
(同じデータを使用しているから、四捨五入したら「だいたい0」になるはず!結果にバラつきがあっても、桁数まで変わるはずがない!と考えていました。)
auc_scoreについて
確かに、lightgbmのauc_scoreであれば数値化して一目で判断できるため分かりやすいです。具体的な値の目安・判断基準を説明いただき、「実際に何をしたらよいか?、解決できそうか?」という方向性が見えてきました。
質問(pickleファイルの追加方法)について
具体的なコードを記載していただき、ありがとうございます。
「いずれの方法でも問題ない」ため、まとめたデータを使用していきたいと思います。(動画でも使用されており、個人的に使いやすいと思っています。)
#update_data関数やconcatで1つにまとめたデータを入れる
hr = HorseResults.read_pickle(['horse_results_all.pickle'])
現在はスクレイピングの途中です。
スクレイピング→optunaでハイパラメータの確認→auc_scoreの確認
数値に異常があれば、optuna→auc_score
の順に実行する予定です。場合によっては、スクレイピングするデータ(年数)を増やし、完成に近づけたらと思います。
ご返信ありがとうございます。
本書の扱い方がわかりました。
(誤) 本書に完全版のコードが記載されており、コードを打ち込んで動画で情報を補完する
(正) 動画が主であって、本書はあくまで動画で誤った部分を補完するためのものである
この辺が他の教育素材とは違っていたので、齟齬や混乱が生じておりました。
まずは動画を見る。
急いでいて、上記を飛ばしてしまっていたことが私の印象に繋っていたのかと思います。
動画とソースだけでは難しい部分はありますが、良質なコミュニティがあり、先に進めそうです。
ありがとうございます。
sho_003さん
数値に異常があれば、optuna→auc_score
の順に実行する予定です。場合によっては、スクレイピングするデータ(年数)を増やし、完成に近づけたらと思います。
auc_scoreの値に異常があれば、まずは「データを正しく加工できているか?」「訓練データとテストデータを正しく分けて扱えているか?」を疑ってください。特に後者はありがちなミスです。
とはいえやる前から未来のミスついて考えていても仕方がないので、とりあえずやってみて、異常があれば見直す、見直してみてわからなければ遠慮なくご質問ください。
一つアドバイスさせていただきたいのが、「行き詰った時は最初からやり直す」ではなく、「原因を突き止める」ことです。もちろんやり直すのも一つの手ですし、右も左もわからない状態で原因を突き止めることは大変な労力を要することになりますが、自分の理解度を高める最も効果的な方法でもあります。「このコードは何をしているのか」「何のためにしているのか」をひとつずつメモしていくと効果的です。そうすることで、エラーや失敗の原因も自然とつかめるようになります。
上から目線の説教っぽくなってしまい恐縮ですが、ご参考までに。
jltさん
動画が主であって、本書はあくまで動画で誤った部分を補完するためのものである
これについては正しいというより、人それぞれです。私はむしろ書籍をメインに使い、行き詰った時は動画を見たり検索して調べて進めました。
「完全版のコード」というのがどういったものをイメージされているのかイマイチよくわかりませんが、一連の発言から察するに、「定義するコード」と「(何らかの処理を)実行するコード」を分けて考えるようにするのがいいのではないかと思います。(私なりの考え方です)
以下は書籍の情報に準拠して考えてください。
「定義するコード」とは、Resultsクラスやupdate_data関数などのクラスや関数のコードです。これらだけを書いたセルを実行しても、具体的な処理は特に何も起こりません。「定義するコード」とは「機械本体」であり、これらのコードを書いてセルを実行することは「機械を用意する」というイメージです。
「実行するコード」とは、こちらに書いた一連のコードなどです。これらをセルに記入し実行すると具体的な処理が実行されます。「実行するコード」とは「機械のスイッチ」であり、これらのコードを書いてセルを実行することは「スイッチを押す」というイメージです。
コードにしてもう少し具体的に見ていきましょう。
#足し算する機械
def addition(a, b):
result = a + b
return result
#掛け算する機械
def multiplication(a, b):
result = a * b
return result
上記は「定義するコード(機械)」です。実行(機械を用意)しても(見た目には)何も起こりません。
#変数two, threeに数字を代入する
two = 2
three = 3
「代入」に関しては上記の説明では少しややこしくなってしまいますね。「機械本体」でもなく「機械のスイッチ」でもありません。むしろ「機械に入れる素材」といったイメージでしょうか。このセルを実行することで「素材を用意」します。
addition(two, three)
multiplication(two, three)
上記は「実行するコード(スイッチ)」です。引数に先ほど用意した「素材」を入れています。それぞれ実行(スイッチを押下)すると、5, 6と返ってきます。
代入と組み合わせて以下のようにすることもできます。
five = addition(two, three)
multiplication(five, two)
10が返ってきます。
書籍に戻りましょう。
前述の通り、「定義するコード」とはクラスや関数のコードで、イメージとしては「機械本体」であり、これらのコードを書いてセルを実行することは「機械を用意する」ということになります。したがって、書籍のChapter02~05のすべてのクラス・関数をまとめてコピペして実行することで、このAIを作るためのすべての「機械を用意」することができます(Chapter02のクラスはChapter03のクラスと重複するので必要ありません。update_data関数は一応コピペしておきましょう)。「用意」するだけなので先にまとめて書いて実行してしまって構いません。
そしてその機械を動かすための「素材」や「スイッチ」はこちらに書きました通りです(ほとんど書籍にも書いてあることですが、一部初心者の方が躓きそうな部分を補完してあります)。
したがって、これらをコピペして上記の通りに「機械」を用意し、順番に「スイッチ」を押してやることで、ひとまずAIは作れます。
余談ですが、このコミュニティは誰でも閲覧できるオープンな場所となっています。したがって書籍の内容を書きすぎてしまうと、本を購入していない人でも同じAIが作れてしまう可能性があります。
そこで自分ルールではありますが、ここには極力書籍の「定義するコード」は書かないようにしています。なぜなら、「定義するコード」さえわかれば、知識さえあれば誰でもその「スイッチ」は自分で書いてしまうことができるからです(反対に「スイッチ」がわかっても「機械本体」の中身がわからなければ、知識があっても全く同じものを作ることはできません)。
つまり、「定義するコード」こそがこのAIを作成するプログラムの全容であり、それ以外の内容はすべてHowToUseに過ぎません。「全容」ですので「完全版のコード」であると言えるかと思います。
Keshiki さん
余談ですが、このコミュニティは誰でも閲覧できるオープンな場所となっています。したがって書籍の内容を書きすぎてしまうと、本を購入していない人でも同じAIが作れてしまう可能性があります。
こちら認識できておらずでした、、
で、あれば Keshiki さんの仰せのとおりかと思います。
諸々サポートいただけましたこと感謝いたします。
おっしゃっていることはよくわかりますが、私はプログラマではないのですが、
インフラエンジニアではあるので、逆に混乱していた部分があるかと思います。
しかし、ご丁寧な解説で理解することができました。
ありがとうございます!
Keshiki さん
先日は、ご回答ありがとうございました。
2018年のデータを追加し、2018-2020年(計3年分のデータ)で進めています。auc_scoreは0.7~0.85の範囲に収まりました。
しかし、標準偏差つき回収率プロットが上手く出力されませんでした。お時間のある時に、見て頂けますでしょうか?
auc_score
LightGBMによる学習に記載されているX_train、X_testではtrainデータとtestデータの数が違い、auc_scoreが表示できませんでした。
そのため、trainデータ・testデータのdropする内容を統一し、スコアを確認しました。
- drop(['rank', 'date', '単勝']の場合、0.7265
- drop(['rank', 'date']の場合、0.7973
どちらも0.7~0.85の範囲にあることから、LightGBMまでの範囲では「うまくいっている」と判断できる状態です。
標準偏差つき回収率プロット
現在は、chapter 05を進めています。
標準偏差つき回収率プロット(2021/2/25追加)にて以下のコードを実行したところ、「賭けた枚数:3.5」となってしまいました。テキスト通りに進めていますが、シミュレーションに問題があるのでしょうか?
plot(g_tansho, 'tansho')
plot(g_proper, 'proper')
plt.xlim
出力されたグラフです。
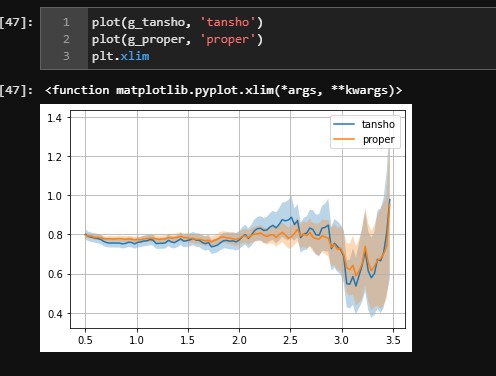
auc_scoreを表示するために変更していたため、gain関数・plot関数と「#ModelEvaluatorクラスのオブジェクトを作成」の間に以下のコードを入力しています。
train, test = split_data(r.data_c)
X_train = train.drop(['rank', 'date', '単勝'], axis=1)
y_train = train['rank']
X_test = test.drop(['rank', 'date'], axis=1)
y_test = test['rank']
関係があるか分かりませんが、直前のグラフは以下の通りでした、
#プロット
plt.plot(g_proper['n_bets'], g_proper['return_rate'])
plt.plot(g_tansho['n_bets'], g_tansho['return_rate'])
plt.grid()
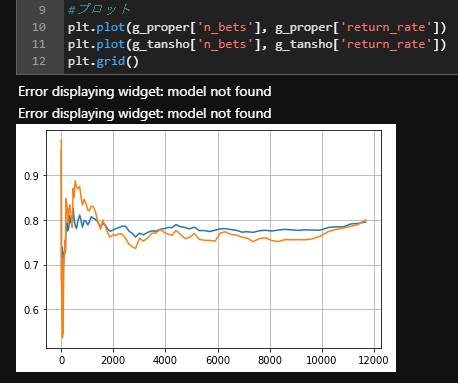
trainデータとtestデータの数が違い、auc_scoreが表示できませんでした。
そうでした。X_testの「単勝」はModelEvaluatorクラスの中で使うので残してありますが、実際にモデルに確率を出させるときにはdropしています。そしてroc_auc_scoreに入れるtestデータは、実際にモデルに確率を出させるときに与えるデータと同じでなければなりません。しかも[:, 1]も必要でした。なので
roc_auc_score(y_test, lgb_clf.predict_proba(X_test))
はミスで、正しくは
roc_auc_score(y_test, lgb_clf.predict_proba(X_test.drop(['単勝'], axis=1))[:, 1])
でした。すみません。したがって、0.7265が正しいauc_scoreとなります。
「単勝」をdropさせるのは、「単勝」は確定オッズを使っているため、実際に予測の段階で得ることができる直前のオッズの情報とは性質が異なるのと、モデルが「単勝」を重視して予測してしまうと回収率が伸びにくくなってしまうからです。
標準偏差つき回収率プロット
問題ありません。グラフを見てもうまくいっているようです。
plot関数を使って出したグラフのx軸は「賭けた枚数」ではなく「threshold(閾値)」の値になっています。ModelEvaluatorクラスでは、モデルが出した各馬の「3着以内率」を各レースの出走馬間で標準化しています。要は各レース内での偏差値のようなものです(本番の実行コードで「score」という名前が与えられているのでscoreと呼ぶことにします)。そしてシミュレーションでは、0.5から3.5を100等分した各値を「threshold」として、このthreshold以上のscoreを持つ馬に対して賭けた場合の回収率を計算しています。ですのでグラフの見方としては、「scoreが1以上の馬に単勝で賭けたときの回収率は76%くらいかなー」といった感じです。賭ける枚数をx軸としてプロットしたグラフと違い、thresholdをx軸としたグラフではscoreが高くなるほど賭けられる枚数も減ってしまうので右に行くほど回収率のブレが大きくなっています。
ちなみに1:
各thresholdごとの回収率や賭けた枚数などはg_tanshoやg_properに入っています。個人的にはグラフよりこちらを重視しています。
ちなみに2:
なぜこんな方法を採っているかというと、データ数を増やしたりしたとき賭けられる枚数に違いが出てしまうため、賭けた枚数をx軸にするとグラフを見て視覚的に比較することが難しくなってしまうからです。
ちなみに3:
グラフのx軸はplt.plot()の一つ目の引数です。ここを変えれば好きなグラフにできます。例えばplot関数のplt.plot(df.index, df['return_rate'], label=label)をplt.plot(df['n_bets'], df['return_rate'], label=label)とすれば、2つ目のグラフのような賭けた枚数をx軸としたグラフを出すことができます。
Keshiki さん
trainデータとtestデータの数
回収率を伸ばすために、「単勝」をdropしているということですね。
標準偏差つき回収率プロット
plt.plot(df.index, df['return_rate'], label=label)をplt.plot(df['n_bets'], df['return_rate'], label=label)
を実行したことで、テキストのようなグラフを出力できました。
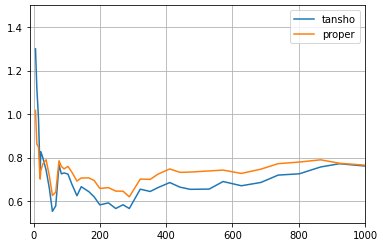
テキストのコードを使用すると、「テキストに添付されたグラフが出力される」と勘違いしていました。
BOX馬券について
現在、馬連・馬単のシミュレーションをしています。
以下のコードを実行すると、「name 'pred' is not defined」というエラーが出てしまいます。
「predが定義されていない」ため、「def pred~」のような定義が必要かと考えています。
何度も質問してしまい、申し訳ありませんが解決方法などはご存じでしょうか?
実行したコード
#gain関数で回収率を計算
g_umaren = gain(me.umaren_box, X_test)
g_umatan = gain(me.umatan_box, X_test)
出力されたエラー
KeyError Traceback (most recent call last)
~\anaconda3\lib\site-packages\pandas\core\computation\scope.py in resolve(self, key, is_local)
199 if self.has_resolvers:
--> 200 return self.resolvers[key]
201
~\anaconda3\lib\collections\__init__.py in __getitem__(self, key)
897 pass
--> 898 return self.__missing__(key) # support subclasses that define __missing__
899
~\anaconda3\lib\collections\__init__.py in __missing__(self, key)
889 def __missing__(self, key):
--> 890 raise KeyError(key)
891
KeyError: 'pred'
During handling of the above exception, another exception occurred:
KeyError Traceback (most recent call last)
~\anaconda3\lib\site-packages\pandas\core\computation\scope.py in resolve(self, key, is_local)
210 # e.g., df[df > 0]
--> 211 return self.temps[key]
212 except KeyError as err:
KeyError: 'pred'
The above exception was the direct cause of the following exception:
UndefinedVariableError Traceback (most recent call last)
<ipython-input-29-ac98b20bcb5b> in <module>
1 #gain関数で回収率を計算
----> 2 g_umaren = gain(me.umaren_box, X_test)
3 g_umatan = gain(me.umatan_box, X_test)
<ipython-input-18-8fc95e8145cf> in gain(return_func, X, n_samples, t_range)
4 #min_thresholdから1まで、n_samples等分して、thresholdをfor分で回す
5 threshold = t_range[1] * i / n_samples + t_range[0] * (1-(i/n_samples))
----> 6 n_bets, return_rate, n_hits, std = return_func(X, threshold)
7 if n_bets > 2:
8 gain[threshold] = {'return_rate': return_rate,
<ipython-input-15-93df8f10c403> in umaren_box(self, X, threshold, n_aite)
253 for race_id, preds in pred_table.groupby(level=0):
254 return_ = 0
--> 255 preds_jiku = preds.query('pred == 1')
256 if len(preds_jiku) == 1:
257 continue
~\anaconda3\lib\site-packages\pandas\core\frame.py in query(self, expr, inplace, **kwargs)
4053 kwargs["level"] = kwargs.pop("level", 0) + 1
4054 kwargs["target"] = None
-> 4055 res = self.eval(expr, **kwargs)
4056
4057 try:
~\anaconda3\lib\site-packages\pandas\core\frame.py in eval(self, expr, inplace, **kwargs)
4184 kwargs["resolvers"] = kwargs.get("resolvers", ()) + tuple(resolvers)
4185
-> 4186 return _eval(expr, inplace=inplace, **kwargs)
4187
4188 def select_dtypes(self, include=None, exclude=None) -> DataFrame:
~\anaconda3\lib\site-packages\pandas\core\computation\eval.py in eval(expr, parser, engine, truediv, local_dict, global_dict, resolvers, level, target, inplace)
346 )
347
--> 348 parsed_expr = Expr(expr, engine=engine, parser=parser, env=env)
349
350 # construct the engine and evaluate the parsed expression
~\anaconda3\lib\site-packages\pandas\core\computation\expr.py in __init__(self, expr, engine, parser, env, level)
804 self.parser = parser
805 self._visitor = PARSERS[parser](self.env, self.engine, self.parser)
--> 806 self.terms = self.parse()
807
808 @property
~\anaconda3\lib\site-packages\pandas\core\computation\expr.py in parse(self)
823 Parse an expression.
824 """
--> 825 return self._visitor.visit(self.expr)
826
827 @property
~\anaconda3\lib\site-packages\pandas\core\computation\expr.py in visit(self, node, **kwargs)
409 method = "visit_" + type(node).__name__
410 visitor = getattr(self, method)
--> 411 return visitor(node, **kwargs)
412
413 def visit_Module(self, node, **kwargs):
~\anaconda3\lib\site-packages\pandas\core\computation\expr.py in visit_Module(self, node, **kwargs)
415 raise SyntaxError("only a single expression is allowed")
416 expr = node.body[0]
--> 417 return self.visit(expr, **kwargs)
418
419 def visit_Expr(self, node, **kwargs):
~\anaconda3\lib\site-packages\pandas\core\computation\expr.py in visit(self, node, **kwargs)
409 method = "visit_" + type(node).__name__
410 visitor = getattr(self, method)
--> 411 return visitor(node, **kwargs)
412
413 def visit_Module(self, node, **kwargs):
~\anaconda3\lib\site-packages\pandas\core\computation\expr.py in visit_Expr(self, node, **kwargs)
418
419 def visit_Expr(self, node, **kwargs):
--> 420 return self.visit(node.value, **kwargs)
421
422 def _rewrite_membership_op(self, node, left, right):
~\anaconda3\lib\site-packages\pandas\core\computation\expr.py in visit(self, node, **kwargs)
409 method = "visit_" + type(node).__name__
410 visitor = getattr(self, method)
--> 411 return visitor(node, **kwargs)
412
413 def visit_Module(self, node, **kwargs):
~\anaconda3\lib\site-packages\pandas\core\computation\expr.py in visit_Compare(self, node, **kwargs)
716 op = self.translate_In(ops[0])
717 binop = ast.BinOp(op=op, left=node.left, right=comps[0])
--> 718 return self.visit(binop)
719
720 # recursive case: we have a chained comparison, a CMP b CMP c, etc.
~\anaconda3\lib\site-packages\pandas\core\computation\expr.py in visit(self, node, **kwargs)
409 method = "visit_" + type(node).__name__
410 visitor = getattr(self, method)
--> 411 return visitor(node, **kwargs)
412
413 def visit_Module(self, node, **kwargs):
~\anaconda3\lib\site-packages\pandas\core\computation\expr.py in visit_BinOp(self, node, **kwargs)
530
531 def visit_BinOp(self, node, **kwargs):
--> 532 op, op_class, left, right = self._maybe_transform_eq_ne(node)
533 left, right = self._maybe_downcast_constants(left, right)
534 return self._maybe_evaluate_binop(op, op_class, left, right)
~\anaconda3\lib\site-packages\pandas\core\computation\expr.py in _maybe_transform_eq_ne(self, node, left, right)
450 def _maybe_transform_eq_ne(self, node, left=None, right=None):
451 if left is None:
--> 452 left = self.visit(node.left, side="left")
453 if right is None:
454 right = self.visit(node.right, side="right")
~\anaconda3\lib\site-packages\pandas\core\computation\expr.py in visit(self, node, **kwargs)
409 method = "visit_" + type(node).__name__
410 visitor = getattr(self, method)
--> 411 return visitor(node, **kwargs)
412
413 def visit_Module(self, node, **kwargs):
~\anaconda3\lib\site-packages\pandas\core\computation\expr.py in visit_Name(self, node, **kwargs)
543
544 def visit_Name(self, node, **kwargs):
--> 545 return self.term_type(node.id, self.env, **kwargs)
546
547 def visit_NameConstant(self, node, **kwargs):
~\anaconda3\lib\site-packages\pandas\core\computation\ops.py in __init__(self, name, env, side, encoding)
96 tname = str(name)
97 self.is_local = tname.startswith(LOCAL_TAG) or tname in DEFAULT_GLOBALS
---> 98 self._value = self._resolve_name()
99 self.encoding = encoding
100
~\anaconda3\lib\site-packages\pandas\core\computation\ops.py in _resolve_name(self)
113
114 def _resolve_name(self):
--> 115 res = self.env.resolve(self.local_name, is_local=self.is_local)
116 self.update(res)
117
~\anaconda3\lib\site-packages\pandas\core\computation\scope.py in resolve(self, key, is_local)
214 from pandas.core.computation.ops import UndefinedVariableError
215
--> 216 raise UndefinedVariableError(key, is_local) from err
217
218 def swapkey(self, old_key: str, new_key: str, new_value=None) -> None:
UndefinedVariableError: name 'pred' is not defined
エラー
ほんとですね。ModelEvaluatorクラスなどは最近アップデートされたんですが、私はまだ試してなかったので気づきませんでした。
これはpredsという変数にDataFrame型のオブジェクトが入っているんですが、その中に"pred"というカラムがないために起きているエラーのようです。
me.pred_table()の以下の部分を次のように変更することで対処できます。
#変更前
return pred_table[pred_table['pred']==1][['馬番', '単勝', 'score']]
#変更後
return pred_table[pred_table['pred']==1]
ちなみに他の賭け方でもそうですが、完了時に警告文が出ることがあるかもしれません。
これはreturn_rateやstdを出す際、n_betsで割る式がありますが、n_betsが0の時もその式を通ってしまうためです。なのでreturn_rateやstdを出す際、n_bets == 0の時とそれ以外とで条件分岐するようそれぞれの賭け方の関数を改造してあげれば警告文は出なくなります。エラーではなく警告なので気にしなくてもいいですが……。
Keshikiさん
ModelEvaluatorクラスの「def pred_table~」内のコードを変更しました。
return pred_table[pred_table['pred']==1]
すると、combinations、permutationsでエラーが発生してしまいました。この場合も、ModelEvaluatorクラスで変更するのでしょうか?
実行したコード①
g_umaren = gain(me.umaren_box, X_test)
エラーの内容
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-30-41b66e3575b5> in <module>
----> 1 g_umaren = gain(me.umaren_box, X_test)
<ipython-input-18-8fc95e8145cf> in gain(return_func, X, n_samples, t_range)
4 #min_thresholdから1まで、n_samples等分して、thresholdをfor分で回す
5 threshold = t_range[1] * i / n_samples + t_range[0] * (1-(i/n_samples))
----> 6 n_bets, return_rate, n_hits, std = return_func(X, threshold)
7 if n_bets > 2:
8 gain[threshold] = {'return_rate': return_rate,
<ipython-input-15-5fb899929d1d> in umaren_box(self, X, threshold, n_aite)
257 continue
258 elif len(preds_jiku) >= 2:
--> 259 for umaban in combinations(preds_jiku['馬番'], 2):
260 return_ += self.bet(race_id, 'umaren', umaban, 1)
261 n_bets += 1
NameError: name 'combinations' is not defined
実行したコード②
g_umatan = gain(me.umatan_box, X_test)
エラーの内容
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-31-40453eda048d> in <module>
----> 1 g_umatan = gain(me.umatan_box, X_test)
<ipython-input-18-8fc95e8145cf> in gain(return_func, X, n_samples, t_range)
4 #min_thresholdから1まで、n_samples等分して、thresholdをfor分で回す
5 threshold = t_range[1] * i / n_samples + t_range[0] * (1-(i/n_samples))
----> 6 n_bets, return_rate, n_hits, std = return_func(X, threshold)
7 if n_bets > 2:
8 gain[threshold] = {'return_rate': return_rate,
<ipython-input-15-5fb899929d1d> in umatan_box(self, X, threshold, n_aite)
279 continue
280 elif len(preds_jiku) >= 2:
--> 281 for umaban in permutations(preds_jiku['馬番'], 2):
282 return_ += self.bet(race_id, 'umatan', umaban, 1)
283 n_bets += 1
NameError: name 'permutations' is not defined
この場合はcombinationsとpermutationsがインポートされていないというエラーだと思われます。書籍の方も記述が抜けているようですね。
from itertools import combinations
from itertools import permutations
を実行してもう一度試してみてください。
Keshikiさん
from itertools import combinations
from itertools import permutations
を実行したところ、シミュレーションができるようになりました。
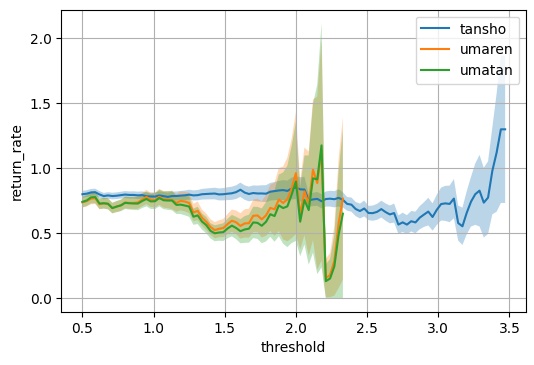
また、実際に賭けてみた結果・・・にて、予測スコアを出すところまで進めることができました。
何度もご回答いただき、ありがとうございます。
<urlopen error [Errno 11001] getaddrinfo failed>
昨日完全版を購入し、スクレイピングの作業をしていたところ先ほどから急にこのエラーコードが出るようになりました。恐らく競馬予想AIをコーディングする過程でのエラーではないと思うのですが、同じ問題を抱えている人がいるようなのでここで質問させていただきました。どうぞよろしくお願いします。
今朝もう一度やってみたところ、現状では正常にスクレイピングが出来ています。7月23日の0時ごろから調子が悪かったのでDNS障害の影響かと思うのですが、他の皆さんは同じようなエラーに遭遇したでしょうか。
#払い戻し結果を取得
retern_tables = Return.scrape(race_id_list)
retern_tables.to_pickle('return_tables.pickle')
retern_tables.to_csv('return_tables.csv')
この辺の処理一般ですが、
一括で一年 (race_id) 分を取得してメモリ上に保持 ⇒ pickle 形式で保存
という処理になっているかと思いますが、
1 レコード毎に pickle に都度保存するという形に変更することは難しいのでしょうか?
4 時間スクレイピングしたけど最後の最後で接続が切れてしまって、
半端な pickle ファイルが積み上がってしまっているので何とか改善したいという状況です
SQLite3 や MongoDB などに取り敢えず一時的に突っ込んでおいて、最終的に pickle で保存できるようになればいいのかなと
途中で接続が切れてしまったデータを何とかしたい、ということでしたら、以下のようにすればOKです。
#切れてしまったデータを読み込んで変数に代入
return_tables_tochuu = pd.read_pickle('return_tables_tochuu.pickle')
#切れてしまったデータの最後のレースIDを代入
race_id = return_tables_tochuu.index.unique()[-1]
#そのレースIDがrace_id_listの何番目にあるか調べてその番号を代入
index = race_id_list.index(race_id)
#そのレースID以降のレースID(スクレイピングできてないID)のみを代入
race_id_list2 = race_id_list[index:]
#スクレイピングできていないレースをスクレイピングする
return_tables = Return.scrape(race_id_list2)
#データをくっつける(※重複部分は上書きするので引数の順番に注意)
return_tables = update_data(return_tables_tochuu, return_tables)
Keshiki さん
諸々ありがとうございます!
本当に助かっております、、
pickle 形式がよくわからなかったので、to_csv で一旦馴染みのある csv にして、加工するコードを書くという無駄な時間を過しておりました、、
いただいたコードを試してみます。
ありがとうございます
LightGBM の GPU の利用について
ディープラーニング自体がはじめてであり、
時間がかかるとは思っていたのですが、
間違えて GPU を指定せずに CPU で処理した方が 10 倍近く速かったのですが、
こういうものでしょうか?
- CPU
60 分 - GPU
600 分
逆なら納得できるのですが、、
Chapter 04. 機械学習モデル作成&学習
- trainで学習
設定したパラメータ
# データセットを作成
lgb_train = lgb_o.Dataset(X_train.values, y_train.values)
lgb_valid = lgb_o.Dataset(X_valid.values, y_valid.values)
params = {
# 今回は0or1の二値予測なのでbinaryを指定
'objective': 'binary',
'random_state': 100,
'max_bin' : 255,
'device' : 'gpu',
'gpu_use_dp' : True
}
# チューニング実行
lgb_clf_o = lgb_o.train(
params, lgb_train,
valid_sets=(lgb_train, lgb_valid),
verbose_eval=100,
early_stopping_rounds=10
)
環境
CPU: Intel Xeon E3 1225 (Sandy Bridge) 4Core/4Thread
Mem: 16GB
GPU: NVIDIA GeForce 1050 Ti 8GB
OS: Ubuntu 20.04
Python: 3.6.14
lightgbm: 3.2.1
NVIDIA DRIVER: 470.57.02
CUDA: 11.4
問題点
Quadro ではなくて GeForce
倍精度を指定してるので遅い?
そもそも、処理するデータが軽いので、オーバーヘッドが大きい?
自己解決です。
CPU を使う場合と GPU を使う場合は、デフォルトのパラメータに違いがあるようです。
- CPU の場合
'num_leaves': 31,
- GPU の場合
'num_leaves': 256,
などなど。
このパラメータが違うせいで、そもそもの訓練モデルを作成するツリー構造が違うようです。
また、適切にパラメータを指定しないと過学習(わかってないですが、、)になってしまうようで、作成した訓練モデルから予測をおこなうとスコア 2.0 を越える馬が多く出てしまうという状況でした。
'max_bin': 63,
'num_leaves': 89,
このあたりの値にすることで CPU と同等の時間で学習モデルの作成をすることができました。
また、過学習も抑止されたようで、適切(と思える)値が得られました。
GPU も適切に使ってくれるようになったようです。
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.57.02 Driver Version: 470.57.02 CUDA Version: 11.4 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... On | 00000000:13:00.0 Off | N/A |
| 50% 41C P0 N/A / 75W | 405MiB / 4040MiB | 30% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 26139 C ...ions/3.6.14/bin/python3.6 401MiB |
+-----------------------------------------------------------------------------+
一度前半の教科書版でコードを組み概略を掴んでから、今は動画で勉強しています。動画第七回のscrape_horse_resultsのスクレイピングについて質問です。現状↓のようにコードを組んだところ
def scrape_horse_results(horse_id_list):
#horse_idをkeyにしてDataFrame型を格納
horse_results = {}
for horse_id in tqdm(horse_id_list):
try:
url = 'https://db.netkeiba.com/horse/' + horse_id
df = pd.read_html(url)[3]
#受賞歴がある馬の場合、3番目に受賞歴テーブルが来るため、4番目のデータを取得する
if df.columns[0]=='受賞歴':
df = pd.read_html(url)[4]
horse_results[horse_id] = df
time.sleep(1)
except IndexError:
continue
except Exception as e:
print(e)
break
except:
break
return horse_results
#スクレイピング実行
horse_results = scrape_horse_results(horse_id_list)
#インデックスをhorse_idにする
for key in horse_results:
horse_results[key].index = [key] * len(horse_results[key])
#一つのDataFrame型のデータにまとめる。
horse_results = pd.concat([horse_results[key] for key in horse_results])
#pickleファイルに保存
horse_results.to_pickle('horse_results.pickle')
NameError Traceback (most recent call last)
<ipython-input-54-10c069de0924> in <module>
23
24 #スクレイピング実行
---> 25 horse_results = scrape_horse_results(horse_id_list)
26
27
NameError: name 'horse_id_list' is not defined
となってしまいスクレイピングがうまくいってないことが分かりました。しかし、一つ前のscrape_race_resultsのスクレイピングはうまくいっており、また教科書バージョンで組んだ時もhorse_resultsのスクレイピングはうまくいきました。恐らく私のケアレスミスなのですが、原因がわかりません。どうぞよろしくお願いします。
動画第七回でresults_newを第一回でやったような辞書型をデータフレーム型に変換する作業で↓のコードを実行したところ、horse_idとjockey_idが消えてしまいました。変換する前のresults_newにはしっかりhorse_idもjockey_idも入ってました。もちろんresultにも入ってます。どうすればよいでしょうか、よろしくお願いします。
results_new = pd.concat([test3[key] for key in test3], sort=False)
results_new.to_pickle('results_new.pickle')
for key in results_new:
results_new[key].index = [key] * len(results_new[key])
#一つのDataFrame型のデータにまとめる。
results_new = pd.concat([results_new[key] for key in results_new])
results_new.to_pickle('results_new.pickle')
で解決しました。
こんにちは。
皆さんに質問させていただきます。
①皆さんのAUCのスコアはどのあたりでしょうか?
②そのAIにはオリジナルの特徴量を追加していますか?
③optunaでチューニングしているか?手動でチューニングしているか?
④過去何年分のデータを学習させているか?
自分のAIのAUCのスコアが低いのではないか?と思い、投稿させていただきます。
情報共有していただける方は宜しくお願い致します。参考にさせていただきます。
例(自分):①0.742653393100994 ②追加していない ③optuna ④5年分
教材に沿っているのならば、オリジナルの特徴量を入れない限りは同じような値になるのでは、、? なので、むしろ、高い低いはなくて、近似値にならない方が不自然ではないかという気も。
(1) 0.786793773382456
※ 何とかして 0.8 は最低限越えたい
(2) 追加していないが、追加したい
※ ファミリーナンバー、走破タイム、月齢など。作成途中なので、もしかしたら半端に追加されている可能性があります
(3) Optuna を利用していますが、ハイパーパラメーターはいくつかいじっています
(4) 2016/01/01 ~ 2021/06/30
※ 期間中の開催日ベースとなります
ご返信ありがとうございます。
教材に沿っているのならば、オリジナルの特徴量を入れない限りは同じような値になるのでは、、?
なので、むしろ、高い低いはなくて、近似値にならない方が不自然ではないかという気も。
おっしゃる通りです。
動画上では0.82などのスコアが出ていた時があったので気になった次第です。
自分としては、データ量などでも変化があるのではないかと思っており、皆さんが過去何年分のデータで作成されているかが気になっていました。
自分とjltさんとの比較でも0.04ほど差があるのですね。
この辺の差がなぜ生まれてくるのかなども気になっています。
① 0.7511943288923658
② 追加していない
③ optunaでチューニング
④ 2019/01/05 ~ 2021/07/18
教材通りに実行した結果です。
① 0.7329070692065967
② 追加していない 後々スピード指数を導入したいと考えています
③ optunaでチューニング
④ 2013/01/05 ~ 2021/07/25
初めまして。
ひと月前に偶然youtubeで競馬AIの動画を拝見し、永らく競馬から遠ざかっていた自分も競馬AIを作ってみようと動画を見ながら何とか、学習、optunaでパラメータを最適化、単勝、複勝の回収率を確認するところまで来ました。ただ私は競馬データをJRA-VANから得ているため、本に載っているコードはそのままでは使えないところが多くあるのが現状です。
そこで申し訳ありません要望なのですが、動画のコードを旧コードとして本に掲載して頂きたく。
現在の本に載っている最新コードは動画のものとは異なり、python、pandas”何だそれ”から始めた私では何をどう変えていけばいいのかハードルが高いです。
お手数お掛けしますがご検討下さい。
こんにちは。
独自の特徴量追加についてアドバイスを頂きたいです。
現在、調教師や馬主を追加していて、さらにレース結果のタイムや着差を追加しようとしています。
そこで質問なのですが、タイムのようなレース結果として決まる値は、学習時やレース予測する時にどう扱ったらよいのでしょうか。
・ハイパーパラメータチューニングする際のtrainとvalidのタイムの値
・LightGBMによる学習時のtrainとtestのタイムの値
・実際に予測する際のShutubaTableのタイムの値
など。
事前にレース結果のタイムがわかっているのはおかしいと思うので、testのタイムの値はnp.nanとかに変換しておくというのは正しいでしょうか。
それと、検証用のvalidは実際のタイムのままでよいのか、等。
機械学習について初心者ですので的外れなことを書いていたらすみません。
ShutubaTableを利用した予測では、そもそもレース前なのでnp.nanにしておくのは正しいでしょうか。
それとも着順(3着以内に入るか)のように、タイムもpredict_probaで予測→その予測タイムをShutubaTableに追加してさらに着順を予測、のような流れになるのでしょうか。
既に同様の特徴量を追加している方、あるいは知見のある方がいらっしゃいましたらご教示頂けると幸いです。
私はpythonに触れ始めてひと月ほどですのでコードに関しては全くわからないのですが、競馬の予想はレースの結果で知り得る情報を用いてはできないのと同様に、機械学習する際もそれらの情報を入れるべきではないと思っています。
私は土日が仕事のことが多く購入馬券は前日に決定する必要があるので、当日のレース直前にわかるような情報(レース当日の馬体重や馬場状態等)も変数に入れていません。馬体重は前走の馬体重を入れています。
タイムに関しては、私はJRA-VANのデータを使っているので参考にならないかも知れませんが、競馬場や距離毎に自分なりの基準タイムを設定して馬のタイムを比較できるようにしています。基準タイムだけは過去の全レースから計算しているので未来の情報が混じっていることになります。
ですが、これをすることで回収率がかなりアップしましたので有効な手段だと思います。
貴重な情報ありがとうございます。
素晴らしいですね、確かにタイムは競馬場や距離などによって違いますから、基準タイムによって比較するのはいいですね。
しかもそれで回収率アップに繋がったということで、実体験も含めての情報助かります。
netkeibaでのタイムは「1:33.3」のような値ですので、これをミリ秒に変換したり、着差については1着馬から何ミリ秒差があったか、程度までしか私は加工していないので、基準タイムという考えが非常に参考になりました。
私も似たような形で比較できるように試してみたいと思います。ありがとうございます。
余談ではございますが、調教師や馬主、生産者といった情報は、私の環境では回収率アップに大きな効果はもたらしておりません。
horse resultsにタイム等を加え時系列を考えてmergeすれば良いと思いますよ。つまり主さんのコードなら着順平均とか上がりの平均等のとこですね。それなら過去のデータになりますね。
私は調教師は変数に入れており、割と重要度上位に入っています。
私の環境で割と具合がよかったもの、別に隠すこともないものを挙げると
①馬齢をやめて馬日にした(誕生日からレース日までの日にち)
②基準タイムは競馬場、コース形状、距離等でgruopby、平均値として、各馬の偏差値を作成、条件が変わっても比較できるようにした。
③基準タイムは前半3H、上り3H、全体タイムの3種類
これらを加えて調整していったところ、最初はこんな感じだったものが
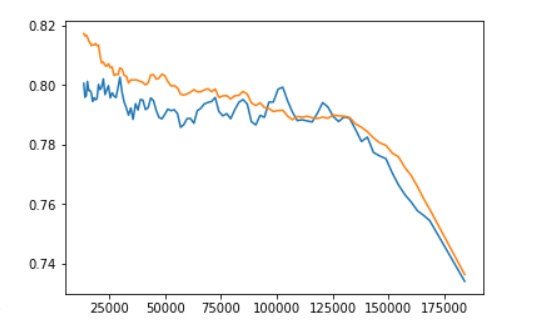
こうなりました。
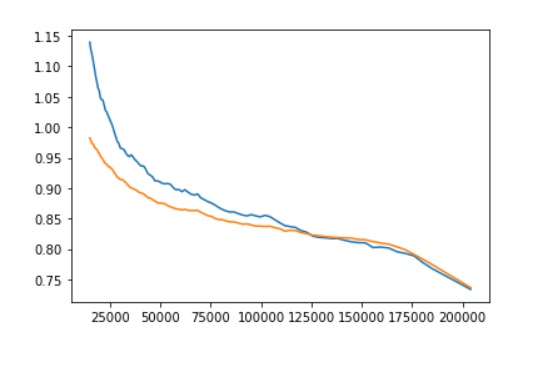
あとは、過去レースの格付けやペース、私の考える馬のやる気、慢心度みたいなものを数値化して加えたものがこれです。漠然と思っていた予想ファクターを形にできたこと、動画と教科書に感謝します!

これで私の予想ファクターは尽きました。
あとは馬券種を増やして回収率を確認していきたいのですが、pythonの知識を向上しないと無理そうです。
なるほどなるほど。それならできそうです。
重ね重ねありがとうございます。
maghanさん、貴重な情報ありがとうございます。
コメントが入れ違いになってしまい、気付くのが遅れてしまいました。
すごい、回収率が上がりつつ、ブレもほとんどなくなってますね。
結構特徴量を追加しておられますね。しかも結果として表れていて素晴らしいです。
やはりタイムはそのままではなく、そういった加工を施して比較できる形にするのが良いようですね。
私も今回の調整する前と後とで差がわかるようにグラフを保存して投稿しますね。
Pythonに関しては私も勉強中ですので、現時点では著者のかたのModelEvaluatorをそのまま利用させて頂いています。
ある程度自分で馬券種のバリエーションを増やせるようにしたいですね。
情報感謝します。
レース結果のタイムや着差を追加しようとしています。
レース結果の「タイム」 or 「着差」が分かる = 複勝圏内かが分かる
なのでレース結果の「タイム」 or 「着差」を特徴量とすると、正答率100%のモデルが簡単にできてしまいますが、少し専門的にいうとデータリークの状態となり意味のないモデルになります。
機械学習の基本的な話として「タイム」や「着差」のように事前に分からないものは学習に使うべきではありません。
「タイム」や「着差」のデータを何らかの形で使いたい場合は各馬の過去タイムといった形で取り出して使うべきですね。(上の方のように基準タイムなど)
ありがとうございます。
現在、コメントしてくださった方々のアドバイスを元に、基準タイムを定義して各馬が比較できる形にするのと、それらを時系列を考えて過去のデータのみ使用するというのを実装しています。
まとまった時間が取れないので少々報告が遅くなるとは思いますが、このスレッドなり新規の投稿なりで結果を報告したいと思います。
第十四回で新しいノートに移ってからLightGBMを実行しようとすると↓のようなエラーコードが出てきます。
TypeError
Traceback (most recent call last)
<ipython-input-30-04b4ea3f5e8b> in <module>
8
9 lgb_clf = lgb.LGBMClassifier(**params)
---> 10 lgb_clf.fit(X_train.values, y_train.values)
~\anaconda3\lib\site-packages\lightgbm\sklearn.py in fit(self, X, y, sample_weight, init_score, eval_set, eval_names, eval_sample_weight, eval_class_weight, eval_init_score, eval_metric, early_stopping_rounds, verbose, feature_name, categorical_feature, callbacks, init_model)
888 valid_sets[i] = (valid_x, self._le.transform(valid_y))
889
--> 890 super().fit(X, _y, sample_weight=sample_weight, init_score=init_score, eval_set=valid_sets,
891 eval_names=eval_names, eval_sample_weight=eval_sample_weight,
892 eval_class_weight=eval_class_weight, eval_init_score=eval_init_score,
~\anaconda3\lib\site-packages\lightgbm\sklearn.py in fit(self, X, y, sample_weight, init_score, group, eval_set, eval_names, eval_sample_weight, eval_class_weight, eval_init_score, eval_group, eval_metric, early_stopping_rounds, verbose, feature_name, categorical_feature, callbacks, init_model)
614
615 if not isinstance(X, (pd_DataFrame, dt_DataTable)):
--> 616 _X, _y = _LGBMCheckXY(X, y, accept_sparse=True, force_all_finite=False, ensure_min_samples=2)
617 if sample_weight is not None:
618 sample_weight = _LGBMCheckSampleWeight(sample_weight, _X)
~\anaconda3\lib\site-packages\sklearn\utils\validation.py in inner_f(*args, **kwargs)
61 extra_args = len(args) - len(all_args)
62 if extra_args <= 0:
---> 63 return f(*args, **kwargs)
64
65 # extra_args > 0
~\anaconda3\lib\site-packages\sklearn\utils\validation.py in check_X_y(X, y, accept_sparse, accept_large_sparse, dtype, order, copy, force_all_finite, ensure_2d, allow_nd, multi_output, ensure_min_samples, ensure_min_features, y_numeric, estimator)
869 raise ValueError("y cannot be None")
870
--> 871 X = check_array(X, accept_sparse=accept_sparse,
872 accept_large_sparse=accept_large_sparse,
873 dtype=dtype, order=order, copy=copy,
~\anaconda3\lib\site-packages\sklearn\utils\validation.py in inner_f(*args, **kwargs)
61 extra_args = len(args) - len(all_args)
62 if extra_args <= 0:
---> 63 return f(*args, **kwargs)
64
65 # extra_args > 0
~\anaconda3\lib\site-packages\sklearn\utils\validation.py in check_array(array, accept_sparse, accept_large_sparse, dtype, order, copy, force_all_finite, ensure_2d, allow_nd, ensure_min_samples, ensure_min_features, estimator)
671 array = array.astype(dtype, casting="unsafe", copy=False)
672 else:
--> 673 array = np.asarray(array, order=order, dtype=dtype)
674 except ComplexWarning as complex_warning:
675 raise ValueError("Complex data not supported\n"
~\anaconda3\lib\site-packages\numpy\core_asarray.py in asarray(a, dtype, order)
83
84 """
---> 85 return array(a, dtype, copy=False, order=order)
86
87
TypeError: float() argument must be a string or a number, not 'Timestamp'
ノートを変える前は何も異状なく使えていたので何かしらライブラリを入れ忘れたり、今まで作ったクラスや関数がインポートの段階で何かしらミスがあったりしたかと思いましたが、今のところ原因がわかりません。
見てほしい場所のコードを貼ろうと思ったのですがほとんど完成品みたいな状態なので読者コミュニティに乗せるのはよくないと思い載せませんでした。
このエラーコードに心当たりや解決した経験がある方は是非お力添えをお願いします。
import やクラス、関数の部分を一から直したところ解決しました。しかし結局どこが原因だったかは力技で解決したのでわかりません。似たようなエラーの質問を見かけたことがあるので、心当たりのある人は是非お願いします。
初めまして.最近この記事を見つけおもしろそうだなと思いYoutubeなども拝見させていただいております.
スクレイピングについて思ったことです.
下のコードのように,考えられるすべてのraceIDのリストを作成したあとにResults.scrape()を使用して,データを集めていると思うのですが,
race_id_list = []
for place in range(1, 11, 1):
for kai in range(1, 13, 1):
for day in range(1, 13, 1):
for r in range(1, 13, 1):
race_id = "2019" + str(place).zfill(2) + str(kai).zfill(2) + str(day).zfill(2) + str(r).zfill(2)
race_id_list.append(race_id)
results = Results.scrape(race_id_list)
この場合だと,101212*12 = 17,280回netkeibaにアクセスすることになり,最低でも約5時間かかると思います.
例えば,201901060101(2019年の札幌第一回一日目1R)にアクセスして存在しなかった場合,201901060101~201901121212までを飛ばすことで時間を節約できると思ったのですがいかかでしょうか?
私も厩舎IDが欲しくて再スクレイピングしようと思っていたので、タイムリーな話題でした。
現在は丸々総ナメをしていて、今年もそうですが競馬場改修などで丸々一年間競馬場を利用できないこともあるので無駄な時間が生じます。
sleep 処理があるので、ある特定の競馬場や開催回にアクセスできなければスキップという処理があれば効率的ですよね。
※ netkeiba.coim さんにも迷惑がかからない
例えば,201901060101(2019年の札幌第一回一日目1R)にアクセスして存在しなかった場合,201901060101~201901121212までを飛ばすことで時間を節約できると思ったのですがいかかでしょうか?
レース番号以外は、昇順ではなく降順の方が確実で効率的だと思って作成中です。
最大値をつくっておけば、そこから下ればいいだけなので。
レース番号は、過去に 11 R までということもあったので、これは昇順がいいかと思ってます
あとは馬毎のレース結果ですが、これも新しいものが存在していれば、古い年度の結果をスクレイピングしないという処理も入れられればと思います。
新しいデータからを読み込んで、古いデータをスクレイプする際に除外するイメージです。
うまくいけば共有できればと思いますが、初心者なのでうまくいくか、、
存在しない race_id を叩いても 404 にならないのですね、、なるほど、、
ステータスコードが 404 なら race_id_list に追加しないというのを想定していたいのですが、、
そもそも race_id が存在するかを sleep 付きで探していたらあまり効率化にはならないですね、、うーん
参考になるかわかりませんが、私の場合Seleniumを使用してnetkeibaさんのデータベース検索からrace_idを取得しています。
アクセスして初めて存在していないことがわかるみたいなので存在しているいないに関わらず1秒sleepしてしまいますね.一応ここの書いていたコードを改良してみたのを載せておきます.
これを使うと一年分のデータを取得するのに5時間以上かかっていたものが1時間半ほどで終わりました.
201901030101のような各競馬場である回の最初の日程における最初のレースが存在しない場合は,20190103以下にアクセスするのをやめて,20190104から始まるrace_idにアクセスするというものになっております.思い付きで書いたため大部汚いですが参考までに...
from bs4 import BeautifulSoup
import pandas as pd
import numpy as np
import datetime
from pandas.io import html
import requests
from tqdm import tqdm
import time
import re
from urllib.request import urlopen
class RaceResults:
@staticmethod
def scrape(race_id_list):
"""
レース結果をスクレイピングする関数
引数:レースIDのリスト
race_id_list
返り値:全レース結果データをまとめてDataFrame型にしたもの
race_results_df:pandas.DataFrame
"""
race_results = {}
skip_req = "no"
current_race_id = int(race_id_list[0])
for race_id in tqdm(race_id_list):
previous_race_id = int(current_race_id)
current_race_id = int(race_id)
diff_race_id = current_race_id - previous_race_id
if (skip_req == "day"):
if (diff_race_id == 8889):# dayが
skip_req = "no"
elif (skip_req == "kai"):
if (diff_race_id == 888889):
skip_req = "no"
if (skip_req == "no"):
time.sleep(1)
try:
url = 'https://db.netkeiba.com/race/' + race_id
df = pd.read_html(url)[0]
# get table data of each race
html = requests.get(url)
html.encoding = "EUC-JP"
soup = BeautifulSoup(html.text, "html.parser")
# 天候,レースの種類.コースの長さ,馬場の状態,日付をスクレイピング
texts = (
soup.find("div", attrs = {"class": "data_intro"}).find_all("p")[0].text
+ soup.find("div", attrs = {"class": "data_intro"}).find_all("p")[1].text
)
info = re.findall(r'\w+',texts)
for text in info:
if text in ["芝", "ダート"]:
df["race_type"] = [text] * len(df)
if "障" in text:
df["race_type"] = ["障害"] * len(df)
if "m" in text:
df["course_len"] = [int(re.findall(r"\d+", text)[0])] * len(df)
if text in ["良", "稍重", "重", "不良"]:
df["ground_state"] = [text] * len(df)
if text in ["曇", "晴", "雨", "小雨", "小雪", "雪"]:
df["weather"] = [text] * len(df)
if "年" in text:
df["date"] = [text] * len(df)
# 馬ID,騎手IDをスクレイピング
horse_id_list = []
horse_a_list = soup.find("table",attrs={"summary":"レース結果"}).find_all("a", attrs={"href": re.compile("^/horse")})
for a in horse_a_list:
horse_id = re.findall(r"\d+", a["href"])
horse_id_list.append(horse_id[0])
jockey_id_list = []
jockey_a_list = soup.find("table",attrs={"summary": "レース結果"}).find_all("a", attrs={"href": re.compile("^/jockey")})
for a in jockey_a_list:
jockey_id = re.findall(r"\d+", a["href"])
jockey_id_list.append(jockey_id[0])
df["horse_id"] = horse_id_list
df["jockey_id"] = jockey_id_list
# インデックスをrace_idにする
df.index = [race_id] * len(df)
race_results[race_id] = df
# 存在しないrace_idを飛ばす
except IndexError:
if (diff_race_id == 89):# dayが存在しない場合
skip_req = "day"
diff_race_id = 0
elif (diff_race_id == 8889):# kaiが存在しない場合
skip_req = "kai"
diff_race_id = 0
continue
# ネットが切れた時などでも途中までのデータを返せるようにする
except Exception as e:
print(e)
break
# 停止した場合の対処
except:
break
# pd.DataFrame型にして一つのデータにまとめる
race_results_df = pd.concat([race_results[key] for key in race_results])
return race_results_df
こんなことしなくても前もってnetkeibaのデータベースから先にrace_idだけをスクレイピングするのもありかもしれませんね...
スポーツナビのレースIDがnetkeibaのものとほとんど同じ(年度の部分の上二桁がスポナビにはないだけ)なのでそれを利用できます。「日程・結果」の各競馬場別のスケジュールのページに行くと、「開催日」のカラムに例えば「1回札幌1日」というリンクがありますが、そのURLの数字部分が都合よく"21010101"という風に"年/場所/回/日"という形になっているので、これの末尾にレース番号としてfor文で01~12の数字をくっつけて年の部分を直せば、1年につき10回のアクセスでほぼ冗長なIDのないすべてのレースIDを取得できます(冗長なIDがまったくないよう取得することもできますがアクセス回数が増えて却って遅くなるのでお勧めしません)。また、「1回札幌1日」といった文字列がリンクになるのは既に開催されたレースのみなので、年度の途中でスクレイピングすると未開催のレースIDは取得しません。Seleniumも使わないのでエラーもなく早いです。
有益な情報ありがとうございます。
そちらの方が確実かもしれませんね。
ValueError: Number of features of the model must match the input. Model n_features_ is 94 and input n_features is 93 について質問です。
私は2020年と2021年のデータで予想を作っているのですがモデルの特徴量のインプットの数が合わないと言われました。理由がわかる方や同じようなエラーに合われた方はいらっしゃるでしょうか。どうぞよろしくお願いします。
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-410-d4dff0433b4b> in <module>
1 #予測
----> 2 pred = me.predict_proba(st.data_c.drop(['date'], axis=1))
3 pred_table = st.data_c[['馬番']].copy()
4 pred_table['pred'] = pred
5 pred_table.sort_values('pred', ascending = False)
<ipython-input-406-c5a8f3f5868e> in predict_proba(self, X)
223
224 def predict_proba(self, X):
--> 225 proba = pd.Series(self.model.predict_proba(X)[:, 1], index=X.index)
226 if self.std:
227 standard_scaler = lambda x: (x - x.mean()) / x.std()
~\anaconda3\lib\site-packages\lightgbm\sklearn.py in predict_proba(self, X, raw_score, start_iteration, num_iteration, pred_leaf, pred_contrib, **kwargs)
918 pred_leaf=False, pred_contrib=False, **kwargs):
919 """Docstring is set after definition, using a template."""
--> 920 result = super().predict(X, raw_score, start_iteration, num_iteration, pred_leaf, pred_contrib, **kwargs)
921 if callable(self._objective) and not (raw_score or pred_leaf or pred_contrib):
922 _log_warning("Cannot compute class probabilities or labels "
~\anaconda3\lib\site-packages\lightgbm\sklearn.py in predict(self, X, raw_score, start_iteration, num_iteration, pred_leaf, pred_contrib, **kwargs)
720 n_features = X.shape[1]
721 if self._n_features != n_features:
--> 722 raise ValueError("Number of features of the model must "
723 "match the input. Model n_features_ is %s and "
724 "input n_features is %s "
ValueError: Number of features of the model must match the input. Model n_features_ is 94 and input n_features is 93
①Resultsのスクレイピングで'上り'が取得できないのはなぜでしょうか?
JSで作成されているわけではないと思っています。
②'調教師'などのResultsになく、出馬テーブルにあるものを特徴量として追加したい場合はどのように取得すれは宜しいでしょうか?
③生産者の特徴量を追加したいと考えています。
初心者なので下記のような下手下手コードです。
アドバイスいただきたいです。
______
url = "https://db.netkeiba.com/horse/" + horse_id
df = pd.read_html(url)[1]
if len(df)==11:
df.drop(3, axis=0,inplace=True)
df.reset_index(level=0, drop=True,inplace=True)
df.drop({4,5,6,7,8,9}, axis=0,inplace=True)
df=df.T
df.rename(columns={0: '生年月日',1: '調教師',2: '馬主',3: '生産者'},inplace=True)
df.drop(0, axis=0,inplace=True)
df.reset_index(level=0, drop=True)
df.index = [horse_id] * len(df)
df_horse = df_horse.append(df)
______
考えてみましたが解決に至らなかったので質問させていただきます。宜しくお願い致します。
①理由については自分も以前調べましたがよくわかりませんでした。pandasのread_htmlのソースを調べたらわかるかもしれません。
②Results.scrape()からdf = pd.read_html(url)[0]を消して、soup = BeautifulSoup(html.text, "html.parser")の下に以下を挿入。
table = soup.findAll('table',{'class':'race_table_01 nk_tb_common'})[0]
rows = table.findAll('tr')
list_2d = []
for i in range(1, len(rows)):
list_ = []
for cell in rows[i].findAll('td'):
list_.append(cell.get_text().replace('\n', ''))
list_2d.append(list_)
df = pd.DataFrame(list_2d,
columns=['着順', '枠番', '馬番', '馬名', '性齢', '斤量',
'騎手', 'タイム', '着差', 'タイム指数', '通過',
'上り', '単勝', '人気', '馬体重', '調教タイム',
'厩舎コメント', '備考', '調教師', '馬主', '賞金(万円)'])
③特に問題はないと思いますが、私の場合は以下のようにしています。参考までに。読みやすさと拡張性重視です。
df = pd.DataFrame()
url = 'https://db.netkeiba.com/horse/' + horse_id
info_df = pd.read_html(url)[1]
#生産者
df['生産者'] = [info_df[info_df[0]=='生産者'].iloc[0, 1]]
#他も必要であれば同じように(例:産地)
df['産地'] = [info_df[info_df[0]=='産地'].iloc[0, 1]]
#インデックスをhorse_idにする
df.index = [horse_id]
Keshiki様 ご回答ありがとうございます。返信が遅くなり申し訳ございません。
①理由については自分も以前調べましたがよくわかりませんでした。
Keshiki様もそうでしたか。。。もう少しPythonやPandasについて知識をつけてから考えてみたいと思います。ありがとうございます。
②に関して、この方法を用いることによって①の問題も解決できるのですね。
貴重な情報をありがとうございます。今後、タイム指数なども使ってみたいと考えていたので感謝します。
③自分のコードと違い、とてもスマートですね。
今後のことを考えると間違いこちらのなくKeshiki様のコードの方が拡張性、利便性に長けています。
こちらのコードを参考にさせていただきます。
また分からない点などがありましたら宜しくお願い致します。
補足です。
②のコードでタイム指数などの有料情報も正しく取得できるかはわかりません。有料会員ではないので…。
③改めて見返してみて少し気になったところがあったので修正してみました。テーブルから複数のデータを抜き取るならこっちの方がコードも短く、変更もtargetの中身を変えるだけでいいので便利かもしれません。
horse_info = {}
target = ['生年月日', '調教師', '馬主', '生産者']
for horse_id in tqdm(horse_id_list):
time.sleep(1)
try:
url = 'https://db.netkeiba.com/horse/' + horse_id
info_df = pd.read_html(url)[1]
data = list(map(lambda x: info_df[info_df[0]==x].iloc[0, 1], target))
horse_info[horse_id] = data
except:
#省略
df = pd.DataFrame(horse_info, index=target).T
追記(8/12)
一部コードに誤りがあったので修正しました。
df = pd.DataFrame(horse_info, index=[target]).T
↓
df = pd.DataFrame(horse_info, index=target).T
Keshiki様 ご返信ありがとうございます。
②タイム指数などは今後余裕が出来たときに触ってみたいと考えております。
まだまだ先の話なので、また躓いたら勉強させてください。ありがとうございます。
③改良版の投稿ありがとうございます。
自分はmap関数とlamda関数の勉強が足りていない為、まだ到達できないコーディングですね。
targetに必要な情報を追加するだけで良いのは本当に助かります。
【追加の質問】
Keshiki様の投稿なさっていたスポーツナビのレースIDについてここで質問させていただいてもよろしいでしょうか?
参考情報から下記のように作成してみました。
race_id_list = []
for place in tqdm(range(1,11,1)):
for year in ['2016','2017','2018','2019','2020','2021']:
try:
url = "https://keiba.yahoo.co.jp/schedule/list/" + year + "/?place=" + str(place)
html = requests.get(url)
html.encoding = "EUC-JP"
soup = BeautifulSoup(html.text, "html.parser")
links_with_text = []
for a in soup.find_all('a', href=True):
if a.text:
links_with_text.append(a['href'])
l = []
for text in links_with_text:
if "race/list" in text:
l.append('20'+re.sub("\\D", "", text))
for header in l:
for r in range(1,13,1):
race_id = header + str(r).zfill(2)
race_id_list.append(race_id)
except ValueError:
continue
スクレイピングの時短になればと考えています。
アドバイスいただけないでしょうか?宜しくお願い致します。
【追加の質問について】
まず一番大事なtime.sleep(1)は忘れずに…。
yearの中身を手打ちするのは面倒なので、for year in range(2016, 2022, 1):としてしまって、urlにはplaceと同じようにstr(year)とした方が楽です。もっと言えばたぶん関数にすると思うので、例えばdef make_race_id_list(start_y, end_y):と引数を設定して、for year in range(start_y, end_y+1, 1):とすると外部から設定できて便利です。
html.encodingは'EUC-JP'ではなく'UTF-8'ですね。どちらにせよ数字しか取得しないのであまり関係ないですが。この文はまるまるなくてもうまくやってくれるみたいです。
links_with_text以降の部分についてですが、文章で説明するよりも実際にコードを触ってもらった方がわかりやすいと思うので、以下のものをいろいろいじってみてください。少しだけ補足も書きました。
a_list = soup.find_all('a', attrs={'href': re.compile(r'^/race/list')}) #※1
for a in a_list:
pl_kai_day = re.findall(r'\d+', a['href'])[0][2:] #※2
for r in range(1, 13, 1):
race_id = str(year) + pl_kai_day + str(r).zfill(2)
race_id_list.append(race_id)
※1 '/race/list'から始まるa hrefだけ取得。
※2 a['href']でURL部分だけに絞ってそこから数字部分を正規表現で取得。findallはリストで返すので[0]で中身を取り出してから、年度の部分をスライス[2:]で消す。
Keshiki様、ご返信ありがとうございます。
time.sleepが抜けておりましたね、、、
ここは忘れてはいけない部分なので気を付けていきます。ありがとうございます。
def make_race_id_list(start_y, end_y):と引数を設定して、
for year in range(start_y, end_y+1, 1):とすると外部から設定できて便利です。
おっしゃる通り利便性も操作性もこちらの方が上がると思いました。
links_with_text以降の部分についてもアドバイスありがとうございます。
pl_kai_dayの中身を確認しました。補足もご丁寧にありがとうございます。
年度の部分をスライス[2:]で削除し、ループで回している年を結合されていて、なるほどなと思いました。
これからも勉強させていただきます。
Keshiki 様
kyan 様
スクレイピングに関する改善のご提案をいただきありがとうございます。
教本以外にもこうして学べており、大変感謝いたします。ありがとうございます。
※ 目の病気になってしまい、お礼遅れまして申し訳ございません、、
早速改良いただいたコードを試したのですが、教本にあるコードとスクレイピング結果が違うという現象が生じております。
※ 何年分のデータを喰わせればいいかという検証もあり、get_year には取得する年を入れております
get_year = 2020
race_id_list = []
for place in tqdm(range(1,11,1)):
for year in [str(get_year)]:
try:
url = "https://keiba.yahoo.co.jp/schedule/list/" + year + "/?place=" + str(place)
time.sleep(1)
html = requests.get(url)
html.encoding = "UTF-8"
soup = BeautifulSoup(html.text, "html.parser")
a_list = soup.find_all('a', attrs={'href': re.compile(r'^/race/list')})
for a in a_list:
pl_kai_day = re.findall(r'\d+', a['href'])[0][2:]
for r in range(1, 13, 1):
race_id = str(year) + pl_kai_day + str(r).zfill(2)
race_id_list.append(race_id)
except ValueError:
continue
race_id_list の数は違いがないように見えます。
len(race_id_list)
3456
awk -F"," '{print $1}' ../../data/results_2020_new.csv | sort |uniq|wc -l
3457
なのですが、実際にスクレイピングした結果数の差異となります。
wc -l results_2020.csv ../../data/results_2020_new.csv
41979 results_2020.csv
48283 ../../data/results_2020_new.csv
90262 合計
※ わかりにくくて申し訳ございませんが、_new 付きが教本どおりのスクレイピング結果となり、_new なしが今回ご提案いただいた改良コードのスクレイピング結果となります
ファイアーウォールで netkeiba.com のログを確認しておりますが、タイムアウトが発生しているということもなく、何度試しても同じ結果になってしまいます。
なお、Results.scrape については教本から変更を加えておりません。
コードに問題があるようには思えず、スポーツナビで直接 URL を叩けば結果は返って来るので本当に謎です、、
何か思い付く点があればご教示いただければと存じます。
diff -U 0 <(awk -F"," '{print $1}' results_2020.csv | sort |uniq) <(awk -F"," '{print $1}' ../../data/results_2020_new.csv | sort |uniq) | head -20
--- /proc/self/fd/13 2021-08-18 01:35:29.130332366 +0900
+++ /proc/self/fd/14 2021-08-18 01:35:29.131332396 +0900
@@ -553,0 +554 @@
+202004010101
@@ -555,0 +557 @@
+202004010104
@@ -558,0 +561 @@
+202004010108
@@ -560,0 +564,2 @@
+202004010111
+202004010112
@@ -563,0 +569 @@
+202004010204
@@ -564,0 +571 @@
+202004010206
@@ -565,0 +573 @@
+202004010208
@@ -567,0 +576 @@
+202004010211
@@ -578,0 +588,2 @@
何とぞよろしくお願いいたします。
- 追記
教本から下記コードを取り除くと、list index error となりましたので、もう少し調べます
#存在しないrace_idを飛ばす
except IndexError:
continue
謎ですね…。
jlt様のコードをコピペして同じようにやってみましたが、データ数は48282となりました。
追記についてですが、2020年はたまたますべての開催日において第12レースまで開催しているようなので、スポナビから取得したrace_id_listに冗長なrace_idは一つもありません。つまり、2020年についてはrace_id_listの中に余分なrace_idは一つも含まれていないので、index errorは発生しえないはずです。
そしてまったく同じようにやってみた結果こちらでは正常にスクレイピングできましたので、race_id_list自体に問題はなさそうです。
以上から、やはりResults.scrape()になんらかの問題がある可能性が高いと思います。
Results.scrape()のtryの中をすべて取り出して取得できていないrace_idに対して実行し、index errorの発生個所を特定してみてください。
Keshiki 様
わざわざ同じコードで実行までしていただきありがとうございます。
2020年についてはrace_id_listの中に余分なrace_idは一つも含まれていないので、index errorは発生しえないはずです。
冷静に考えれば race_id_list 自体は正しい値を返しているので、スクレイピングする処理に問題がありそうです。解決したらどこが悪かったのかを含めてご報告するようにいたします。
まだ解決はしておりませんが、コードの改良いただきありがとうございます。
スクレイピングは皆が使うコードで且つ時間がかかるところなので、ここで時短ができることに感謝いたします。
ありがとうございます。
Keshiki 様
まだ解決に至ってはおりませんが、独自に追加したコードが悪さをしていたようです、、
早速改良いただいたコードを試したのですが、教本にあるコードとスクレイピング結果が違うという現象が生じております。
こちらの情報が誤りでした。お詫びして訂正いたします、、
if "m" in text:
df["course_len"] = [int(re.findall(r"\d+", text)[0])] * len(df)
if "障" in text:
df["clockwise_type"] = ["障害"] * len(df)
else:
df["clockwise_type"] = [re.split('芝|ダ', re.findall(r"\D+", text)[0])[1]] * len(df)
df["clockwise_type"] = df['course_corner'].str.replace('ート', '障害')
右回り、左回り、直線、障害、での近走平均を出したかったので上記コードに修正したのですが、うまく取得できずにエラーになっていたようです。
※ 主に芝・ダート双方を走る、回りが記載されていない、障害レースでエラーが発生したおりました
race_id: 201404010101 など
race_id_list の数・内容共に問題はなく、コードの追加により意図したものが取得できておりました。
完全に自己責任でスレ汚し、せっかく有用なコードを記載していただいたのにも関わらず、大変申し訳ございませんでした、、
- 障害レース
回りは無視 - 新潟の 1000m
直線で処理 - その他
競馬場毎に準じる
スクレイピングをできればいいのですが、ちょっと難しそうなので、後処理を入れることにします
Keshiki様、お世話になっております。
アドバイスいただきたく連絡させていただきました。
今回お聞きしたいのは「タイム指数」に関してです。
タイム指数を持っているのは、ResultとHorseResultの2データになります。
まず初めに自分はHorseResultのtarget_listに下記のように追加して検証してみました。
self.target_list = ['着順', '賞金', '着差', 'first_corner', 'final_corner',
'first_to_rank', 'first_to_final','final_to_rank', 'タイム指数']
しかし、特徴量としてあまり精度が上がらず、Resultの方のタイム指数を使用してみたいと考えております。
この場合ですと出馬テーブルの方にもタイム指数の項目が必要になってきます。
出馬テーブルのタイム指数はどのように扱うべきでしょうか?
自分としては0で作成するという方法しか思い浮かびませんでした。
また、この指数の扱い方で良い案などございましたら、是非とも教えていただきたいです。
宜しくお願い致します。
タイム指数はレースの結果情報なのでそのまま使うとリークになります。HorseResultと似たようなことをやることになりますが、「前走のタイム指数、前々走のタイム指数、...、n走前のタイム指数」(nはすべての馬に共通)という風に特徴量を追加していくのはどうでしょう?データがない場所は欠損値で。
HorseResultは値を条件ごとに平均してしまうのでその分ぼやけてしまいます。その点この方法なら実際の値を使うので効果が上がるかもしれません。
私の場合はタイム指数は使っていませんが、他の特徴量について同じようなことをしています(HorseResultは使っていません)。といってもまだ作ってる最中ですが…。
ただ、タイム指数は他の様々なデータについて人間が比較や判断をしやすいようにいろいろと加工しただけに過ぎないので、その加工元となった値が特徴量として入っていたら、タイム指数を特徴量として組み込んでもそもそもあまり精度の向上は期待できないかもしれません。かといって消す必要もないとは思いますが。
Keshiki様、お世話になっております。
「前走のタイム指数、前々走のタイム指数、n走前のタイム指数」(nはすべての馬に共通)という風に特徴量を追加していくのはどうでしょう?データがない場所は欠損値で。
丸1日試行錯誤してみましたが、成果物は0でした。
タイム指数は是非とも利用してみたいと考えております。
n行分のデータを取得まではたどり着きそうでしたが、そのn行を1行にまとめるという案が浮かびませんでした。
また明日つくれるように頑張ってみます。宜しくお願い致します。
追記(09/02)になります。
Keshiki様。お世話になっております。
n_samples=3
horse_results_s = pd.read_pickle('horse_results_X.pickle')
horse_results_s["date"] = pd.to_datetime(horse_results_s["日付"])
horse_results_s.drop(['日付'], axis=1, inplace=True)
horse_results_s.index.name = 'horse_id'
filtered_df_s = horse_results_s.sort_values('date', ascending=False).groupby(level=0).head(n_samples)
上記コードで各馬の3レース分のデータは取得できたと思っています。
このデータを横繋ぎにする方法が分かりません。
アドバイスいただけないでしょうか?引き継ぎどうぞ宜しくお願い致します。
お世話になっております。
2016~2021(8/1まで)のデータを用いて以下のように回収率を表示しようとしているのですが
gainの処理でものすごく時間がかかっています。
単勝で7分程度
馬連が表示される予想時間で8時間程度かかるようです。(予想時間を見て中断)
データ量的にこの程度時間がかかるのはしょうがないのでしょうか?
me = ModelEvaluator(lgb_clf, ['return_tables_2016.pickle','return_tables_2017.pickle','return_tables_2018.pickle','return_tables_2019.pickle','return_tables_2020.pickle','return_tables_2021.pickle'])
g_tansho = gain(me.tansho_return, X_test)
g_umaren_box = gain(me.umaren_box, X_test)
plot(g_tansho, 'tansho')
plot(g_umaren_box, 'umaren_box')
参考ですが、データが少ない今年のデータのみですと以下のような時間になります。
単勝:50秒程度
馬連:10分程度
改善方法等がございましたらご教示をお願い致します。
いつもお世話になっております。
netkeibaの有料会員になったのですがスピード指数を入れた馬の過去データを上手くスクレイピングすることができません。
sessionを用いてログイン状態になるようしているのですが、pd.get_htmlはログインしていない時のデータをもってきます。
どのようにすればスピード指数等をスクレイピングできるでしょうか?
わかる方がいれば教えていただきたいです。
お願いいたします。
コードを見てないので正確なことは分かりませんが...
例えば下記のようにセッションを開始し無事ログインできたとします。
session = requests.Session()
session.post(login_url, data=payload) #payloadはログイン時に必要になるデータ
あくまで予想ですが質問主様はデータ取得の際ログインしない場合と同じように下記のようにしているのではないでしょうか?
url = 'スクレイピング先のurl'
pd.read_html(url)
よくよく考えてみると分かるかと思いますが、
ログイン状態を保持しているのはあくまでもsessionオブジェクトであり、変数urlにはログイン情報はもちろん含まれていません。そのためいくら事前にログインしていようが当然上記コードではログインしていないときのデータしか取得していません。
sessionオブジェクト経由で情報を取得するときちんとスピード指数の情報も手に入ります。
pandasでデータを取得したい場合は以下のよいに書くと大丈夫だと思います。
html = session.get(url)
pd.read_html(html.content)
ありがとうございます。アドバイスをもとにうまくデータを入手することができました。
とても勉強になる教材でいつも楽しく見させていただいております。
第19回のところに転記されているResults関数ですが、不要な列を削除のところに'単勝'が抜けているようです。動画内では単勝を追加しておりました。
第19回のサンプルをそのまま使用すると学習データで使用する際に、モデルの特徴数と入力がエラーになってしまうと思います。ご確認をよろしくお願いします。
こんにちは。
次の第20回で単勝適正回収値というのを追加していますが、この動画の修正版、第27回で単勝を再び使用することになりました。
そのため予測の時に単勝を削除することになっています。コードだけが最新になっていますので分かりづらいかもしれませんね。
Nobuさん、返信ありがとうございます。なるほど!第20回で単勝が復活してるんですね!まだ第20回は視聴していなかったので気づきませんでした。ご指摘ありがとうございます。 できれば第19回のところでは動画のままにしておいて、第20回のところで変更点みたいな感じで修正のサンプルコードあったら自分みたいなに勘違いする人は減りそうですね。
それでも他の部分は分かりやすく、とても素晴らしい教材だと思いますw
ShutubaTableクラスに関してなんですが、preprocceing関数の中でcourse_lenに対して10の位の切り捨てが行われてないと思いました。Resultクラスのpreprocceing関数では以下の処理があったので…
# 距離は10の位を切り捨てる
df["course_len"] = df["course_len"].astype(float) // 100
自分の見落としや勘違いだった場合にはご放念ください。
if 'm' in text:
df['course_len'] = [(float(re.findall(r'\d+', text)[0]) // 100)] * len(df)
が正しそうな気がしますね。。。有識者の皆様の回答を待ちましょう。
助けてください。
"実際に賭けてみた結果"のページで本番の実行コード
st.preprocessing() #前処理
st.merge_horse_results(hr) #馬の過去成績結合
st.merge_peds(p.peds_e) #血統データ結合
st.process_categorical(r.le_horse, r.le_jockey, r.data_h) #カテゴリ変数処理
を実行したところ、下記のエラーメッセージが出て先へ進めません。
st.merge_horse_results(hr)の部分でエラーが出ているようなので、書籍の部分を再度コピペして貼り付けを行ったのですが、改善しません。
対応策がわかりましたら教えてください。
KeyError Traceback (most recent call last)
<ipython-input-93-0162002ab2da> in <module>
1 #データ加工
2 st.preprocessing() #前処理
----> 3 st.merge_horse_results(hr) #馬の過去成績結合
4 st.merge_peds(p.peds_e) #血統データ結合
5 st.process_categorical(r.le_horse, r.le_jockey, r.data_h) #カテゴリ変数処理
<ipython-input-88-5cf7d69dca0a> in merge_horse_results(self, hr, n_samples_list)
38 self.data_h = self.data_p.copy()
39 for n_samples in n_samples_list:
---> 40 self.data_h = hr.merge_all(self.data_h, n_samples=n_samples)
41
42 #6/6追加: 馬の出走間隔追加
<ipython-input-76-6934b0d7d7a9> in merge_all(self, results, n_samples)
460 def merge_all(self, results, n_samples="all"):
461 date_list = results["date"].unique()
--> 462 merged_df = pd.concat([self.merge(results, date, n_samples) for date in tqdm(date_list)])
463 return merged_df
464
<ipython-input-76-6934b0d7d7a9> in <listcomp>(.0)
460 def merge_all(self, results, n_samples="all"):
461 date_list = results["date"].unique()
--> 462 merged_df = pd.concat([self.merge(results, date, n_samples) for date in tqdm(date_list)])
463 return merged_df
464
<ipython-input-76-6934b0d7d7a9> in merge(self, results, date, n_samples)
454 merged_df = df.merge(self.average_dict["non_category"], left_on='horse_id', right_index = True, how = "left")
455 for column in ["race_type", "course_len", "開催"]:
--> 456 merged_df = merged_df.merge(self.average_dict[column], left_on = ["horse_id",column], right_index = True, how="left")
457
458 return merged_df
~\anaconda3\lib\site-packages\pandas\core\frame.py in merge(self, right, how, on, left_on, right_on, left_index, right_index, sort, suffixes, copy, indicator, validate)
8193 from pandas.core.reshape.merge import merge
8194
-> 8195 return merge(
8196 self,
8197 right,
~\anaconda3\lib\site-packages\pandas\core\reshape\merge.py in merge(left, right, how, on, left_on, right_on, left_index, right_index, sort, suffixes, copy, indicator, validate)
72 validate=None,
73 ) -> "DataFrame":
---> 74 op = _MergeOperation(
75 left,
76 right,
~\anaconda3\lib\site-packages\pandas\core\reshape\merge.py in init(self, left, right, how, on, left_on, right_on, axis, left_index, right_index, sort, suffixes, copy, indicator, validate)
666 self.right_join_keys,
667 self.join_names,
--> 668 ) = self._get_merge_keys()
669
670 # validate the merge keys dtypes. We may need to coerce
~\anaconda3\lib\site-packages\pandas\core\reshape\merge.py in _get_merge_keys(self)
1056 join_names.append(None)
1057 else:
-> 1058 left_keys.append(left._get_label_or_level_values(k))
1059 join_names.append(k)
1060 if isinstance(self.right.index, MultiIndex):
~\anaconda3\lib\site-packages\pandas\core\generic.py in _get_label_or_level_values(self, key, axis)
1682 values = self.axes[axis].get_level_values(key)._values
1683 else:
-> 1684 raise KeyError(key)
1685
1686 # Check for duplicates
KeyError: '開催'
KeyErrorに関しては自己解決しました。
その先のsocreのコードを実行したところ下記のエラーが出ました。
NameError Traceback (most recent call last)
<ipython-input-71-d50772d8f0af> in <module>
----> 1 scores = me_st.predict_proba(st.data_c.drop(['date'], axis=1), train=False)
2 pred = st.data_c[['馬番']].copy()
3 pred['score'] = scores
4 pred.loc['202101020301'].sort_values('score', ascending=False)
NameError: name 'me_st' is not defined
me_stはどう定義すればよいでしょうか?
"実際に賭けてみた結果"のページを見ても見当たりません。
me_stは書籍編集上のミスだと思います。字面から察するにShutubaTable用のModelEvaluatorクラスを仮で作ったか、インスタンスを別で作っておきたかったか、いずれにしてもそのときのコードをそのまま載せてしまっただけだと思いますが、仮に変更があったとしても具体的にどこをどう変えたのかはわかりませんし、おそらく最終的には条件分岐だけしてModelEvaluatorクラスにまとめると思うのでmeに置き換えておけばいいと思います。
過去ログに同じ質問があります。 → https://zenn.dev/link/comments/f00073cd7d888e
kenshikiさん、ありがとうございます。
過去ログ見落としていました。
無事scoreを出力することができました。
いつもお世話になっております。Youtubeの動画を全部視聴し終わったので、最新のサンプルコードを用いて競馬予想を試してみました。スクレイピングのデータは2015年から2021年8月までのデータを使用しています。
試しに著者様の「実際に賭けてみた結果・・・」のページにある、'202105021211'を実行してみたところ、以下のようになりました。
馬番 score
202105021211 6 1.600109
202105021211 7 1.364208
202105021211 1 1.215089
202105021211 9 0.932922
202105021211 12 0.691840
202105021211 4 0.412416
202105021211 14 0.168728
202105021211 10 0.139668
202105021211 8 0.111254
202105021211 5 -0.149823
202105021211 2 -0.202075
202105021211 11 -0.268903
202105021211 13 -0.655374
202105021211 17 -0.790839
202105021211 3 -1.151461
202105021211 16 -1.420962
202105021211 15 -1.996796
著者様の結果では10→7→13・・・という結果になっていました。5月以降にn_horsesとinterval が特徴量に追加されたということと、学習させるデータの違いはあると思いますが、こんなにも差異があるのかとビックリしています。お手数ですが最新のサンプルコードを使ってる方で、202105021211のデータがどのようになったか教えてもらってもよろしいでしょうか?
おそらくですが自己解決しました。
以下のことを変更したところ、10番が一位に出てきました。
・r_dataとstのデータのcolumnsの並びを同一にした
>horse_idとjockey_idが入っている位置が上の二つでずれていたので手動で調整
・ShutubaTableクラスでcourse_lenを÷100した
>Resultクラスでは÷100していたので合わせた
ただlightgbmを使うたびに結果が変わってくるので、ここをどうにかしたいですね^^;
書籍と同じようにしていて、かつ使用しているデータが全く同じであるなら、
△ lightgbmを使うたびに結果が変わる
○ ハイパーパラメータが変わると結果が変わる
です。
ハイパーパラメータが同じであれば同じ結果が出力されます。
このハイパーパラメータはoptuna_seedという引数を追加することで固定できます。 → https://zenn.dev/link/comments/1f5bd39846ef11
Keshikiさん>
情報ありがとうございます。著者様が実行したときのoptuna_seedは不明ですが、少なくともこれで自分の環境内では同じ結果が出力できそうですね。早速試してみたいと思います。
こんばんは。
ちょっと直感に反する状況になっているため、よければ皆様の環境での結果をお聞かせください。
私の環境でoptunaでパラメータチューニングを行なった上でLGBMで学習を行い、特徴量のimportanceを出力すると、馬場状態(ground_state)、天気(weather)の値がsplit, gain共に全て0となっており、全く参照されていない状態になっています。特徴量の次元数は現在243です。
よく「馬場状態が悪いとレースが荒れる」などと言われているため、ある程度は予測に影響するものと考えていたのですが、皆様はimportanceがこのような結果になっていないでしょうか?
ks 様
私の importance も 0 ではないものの、同様に馬場状態は下位に存在しています。
また、性別も下位に存在している状態です。
このことからダミー変数化されていることによる影響もあるのでは?と思っておりますが、
機械学習は素人なので何とも言えずです、、有識者の方に見解をいただけるといいのですが。
jit様
回答ありがとうございます。
こちらも同様に性別も下位になっています。
とりあえず私だけがおかしい訳ではないようで安心(?)しました。
データの扱いについては少し調べてみようと思います。
「馬場状態が悪いとレースが荒れる」といっても当然100%荒れるわけではありません。仮に「不良」の時20%の割合で「荒れる」とすると、80%は「荒れない」のでそれだけノイズの多い(解像度の低い)特徴量となり重要度が下がります(※1)。
こちらがわかりやすいです → https://aotamasaki.hatenablog.com/entry/bias_in_feature_importances
※1 厳密にはground_stateやweatherは「荒れるかどうか」ではなく、「その状況でどういった馬が強い(目的変数y=1になりやすい)か」を求めるためのものです。「荒れる」とは期待度順にレースが決まらない状況をいいますが、仮に 期待度=単純な馬の能力 として、ground_stateやweatherは「(上記の例でいえば)80%がその単純な馬の能力でy=1を求められる、20%がそれ以外の要素が単純な馬の能力以上に結果を左右する」ということを示す特徴量になります。上記では単純化のために「荒れる荒れない」と書きましたが。
次元数も書籍のものよりいくらか多いので、追加した特徴量が結果を強く左右するなら解像度の低いground_stateやweatherは相対的に重要度が低くなっていきます。
とはいえすべて0というのは少し引っ掛かる気がします。
何らかのミス以外で他に考えられる要因としては、データが少ないというのがあるかもしれません。
書籍の通りに行なっているならtrain, valid, testのデータに分けられていると思いますが、例えばvalidのデータのground_stateがたまたますべて「良」であるとしたら、ground_stateが「良」以外のデータについて評価できませんので、結果的にすべてのデータに対してground_stateは無視してもいい特徴量だと学習されてしまうかもしれません。実際にvalidのすべてが「良」でなくとも、先述のようにground_stateやweatherは解像度の低いデータである可能性があるので、データ量が少ないと良・不良などそれぞれの状態での傾向を十分に評価できないかもしれません。傾向を掴むにはサンプルがたくさん必要ということです。
ただこれはあくまで私の想像です。実際にそういう記述を読んだわけでも実験したわけでもありませんので…。ご了承ください。
根本的にはデータ量を増やすのがいいと思いますが、もし余裕があれば使用するデータはそのままでoptunaのクロスバリデーションの方でチューニングをやってみてください(必ずtime series splitで行なってください)。同じデータ数でも実質的にvalidデータを増やせます。ついでにauc scoreもほんの少しだけ上がるかもしれません。
追記(8/27)
記述に間違いがあったので一部削除しました。
Keshinki 様
お世話になっております。
何となくではありますが、イメージがつきました。
用いるデータによって、データを分ける段階で偏りが生じる可能性があるというところは、初心者でも納得できました。上の方にもありましたが、学習結果がその都度異るのも都度用いるデータによるものだと思われました。
※ その他難しいので勉強いたします、、
わかりやすいご解説いただきありがとうございます。
可能であれば、ご教示いただいたクロスバリデーションも試してみたいと思います。
ちなみに別件で申し訳ございませんが、n_horses ですが出走頭数が少なければ 3 着以内になる確率が高いのは当たり前だと思っています。
importance も高い状況なのですが、機械学習的にみてに用いる必要がある特徴量でしょうか?
多頭数に強い or 小頭数に強いという、出走頭数を用いるにしても別途閾値を設けたフラグ分けの方が良さそうな気がしております。
n_horsesについて
結論としては、n_horsesは必要だと思います。ただし結果に変なバイアスが掛かっている可能性があるので、回避するならランキング学習などをした方がいいかもしれません。
順を追って説明します。
確かに、出走数が少ないと各馬の3着以内率も上がります。そのため、AI的にはn_horsesの値が低ければ予想確率を高く算出し、n_horsesの値が高ければ予想確率を低く算出することで正答率が上がってしまうので、こういった望まないバイアスの掛かった学習をしてしまいます。極端な話、1頭しか出走しないレースと99頭出走するレースの2レースしかなかったとして、前者のレースは1、後者のレースはすべて0というように予想確率を出してしまえば99%正解となってしまいます。
実際に見てみました。
n_horsesの値が低いほど、AIが出した確率の平均値が高くなってしまっているのがわかります。
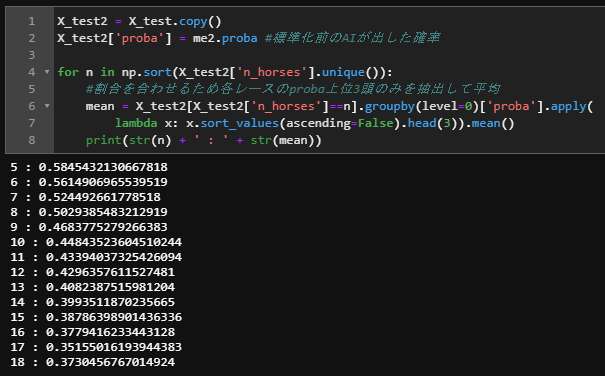
ただ最終的にはAIが算出した確率をそのまま使うのではなく、レースごとに標準化していますのでこういったバイアスはいくらか抑えられます。
例えば、あるレースにA, B, Cという3頭の馬のみが出走するとします。n_horsesだと例示がややこしくなりそうなので代わりにzという特徴量で説明します。zもn_horsesと同様に各レースごとに同じ値を持ち、「値が低ければ予想確率が高く算出され、値が高ければ予想確率が低く算出される」とします。
まずzという特徴量を追加しない状態でAIに予想させてみると、以下のような確率が返ってきました。
| 馬名 | 予想確率 |
|---|---|
| A | 0.3 |
| B | 0.4 |
| C | 0.7 |
| これを標準化すると | |
| 馬名 | score |
| ---- | ---- |
| A | -0.980581 |
| B | -0.392232 |
| C | 1.372813 |
| となります。 |
今度はzを追加して予想してみます。このレースのzの値は5とし、これは低い値であるとします。z=5のとき、すべての馬に均等に元の確率よりも0.2上がるとします。
| 馬名 | 予想確率 |
|---|---|
| A | 0.5 |
| B | 0.6 |
| C | 0.9 |
| これを標準化すると | |
| 馬名 | score |
| ---- | ---- |
| A | -0.980581 |
| B | -0.392232 |
| C | 1.372813 |
| と、上と全く同じ値になります。 | |
| 今度は全く同じレースですが、zが18だったとし、これは高い値であるとします。z=18のとき、すべての馬に均等に元の確率よりも0.2下がるとします。 | |
| もう省略してしまいますが、これも標準化後は全く同じ値になります。 |
つまり、「値が低ければ予想確率が高く算出され、値が高ければ予想確率が低く算出される」というバイアスが掛かっていたとしても、レースごとに標準化してしまえば、別レース間でのバイアスの効果はなくなります。
とはいえ、じゃあn_horsesは意味のない特徴量なのかと言えばそうではなく、他の特徴量との交互作用が働いているはずです。例えば、「出走数が多いと大外枠は不利」という説が真だとすれば、枠番という特徴量との交互作用が働くはずです。あるいは「出走数が多いと馬体重が重い方が有利」という説が真だとすれば、馬体重という特徴量との交互作用が働くはずです。そのときの「出走数が多い」というのはどれくらいからいえるのかなどの閾値はAIがうまく設定して学習してくれます。また、どういった特徴量と交互作用が働き、それがどれくらい有用なのかは人間にはわかりません。ここを人間の判断(感覚)で「こういう説があるから値をそのまま入れるより、この特徴量と組み合わせたものだけ入れておけばいいだろう」と取捨選択してしまうとせっかくのAIの特性を損ねてしまう可能性があります。Lightgbmは無駄な特徴量があってもノイズとなりにくいという性質があるので特にそう言えます。なのでn_horsesはあった方がいいと思います。
少し話を戻します。
n_horsesは、「値が低ければ予想確率が高く算出され、値が高ければ予想確率が低く算出される」という望まないバイアスが学習プロセスにあるかもしれない、しかしそれはレースごとに標準化することで「別レース間でのバイアスの効果はなくなる」と言いました。しかし、実際のところ「同レース間でのバイアスの効果は残る」可能性があります。
先ほどの表の例では、「すべての馬に均等に元の確率よりも0.2上がる(下がる)」と仮定して進めましたが、これが実際には「元の確率が低い(高い)ほど上がり(下がり)幅が大きい」としたら標準化後の値は異なってきます。そうなるとこれは本来期待値の低い(高い)馬が不当に高い(低い)スコアを出すことになってしまいます。
また、そもそも望まないバイアスが学習プロセスにあること自体、リソースを無駄なところに割いてしまっているので学習精度が落ちてしまうということがあるかもしれません。
これを回避するにはランキング学習をすればいいとは思います…が、これは私もまだあまり勉強できてないないのでハッキリしたことは言えません。
Keshiki 様
お世話になっております。
わざわざ検証までしていただきありがとうございます。
例えば、「出走数が多いと大外枠は不利」という説が真だとすれば、枠番という特徴量との交互作用が働くはずです。あるいは「出走数が多いと馬体重が重い方が有利」という説が真だとすれば、馬体重という特徴量との交互作用が働くはずです。
また、どういった特徴量と交互作用が働き、それがどれくらい有用なのかは人間にはわかりません。ここを人間の判断(感覚)で「こういう説があるから値をそのまま入れるより、この特徴量と組み合わせたものだけ入れておけばいいだろう」と取捨選択してしまうとせっかくのAIの特性を損ねてしまう可能性があります。
なるほど。完全に理解はできておりませんが、例えが素晴しく、隠れた要因を複合的に発見できるのも機械学習ならではの醍醐味だと感じました。
確かに、そこに思い込みが発生しては、機械学習の域を越えてしまいますね。
ありがとうございます。
いただいた情報や、上記サイトのようなものも合せて、機械学習の面白さを体験できております。
重ねてありがとうございます。
競馬はブラッドスポーツともいいますが、私の importance では、血統的な特徴量では ped_0 や ped_1 よりも、ped_20 の方が上にいる状況です。
この位置?と思ったのですが、色々調べるとインブリードが発生している可能性が高い位置、最近は同じような血統構成の馬が多いので、この位置が重要なのは「なるほど」と思ったりもしました。
Keshiki 様のおっしゃるとおり、複合的な要因・要素、掛け合せで機械学習が判断していると感じております。
今回に限らず、度々ありがとうございます。
引続きよろしくお願いいたします。
自分でもわかりにくいなぁと思うので改めて結論だけまとめますね。
①n_horsesは、その値が「低いほど予想確率が高くなり、高いほど予想確率が低くなる」よう学習されてしまっている。これは間違った学習プロセスで、ある意味リークに近い。
②n_horsesは、他の特徴量との交互作用が働くはず。n_horsesは同レース内ではすべての馬に同じ値であるため、本来これだけが期待される(はず)。
③①の問題は「n_horsesが同じとき、該当する馬すべてに同じ割合で予想確率に変化を与える」なら問題はない。同じ割合でないなら問題は残る。
④そもそも間違った学習プロセスがあること自体避けるべき。
⑤ただn_horsesという特徴量自体は有用なものであるはず。
自分の考えでは(間違っていなければ)これは結構大きな問題だと思うので、いつか何らかの形で修正されるんじゃないでしょうか。
これについて私も質問いただくまでその問題について気づいていませんでしたので、こちらこそありがとうございます。
リンクのサイトもわかりやすくて助かります。
pedsに関しては正直難しくて私はほとんどお手上げですね…。
今後の開発ロードマップにあるfastTextを使ったベクトル化をいろいろ実験してみたりしたのですが、なかなか満足のいく結果にならないのと、うまくいったとしてもそれを特徴量として入れたときLightGBMがうまく扱ってくれないのではと思い保留中です。
追記(9/3)
よくよく考えたらn_horsesやそれが絡む特徴量が「n_horsesが同じとき、該当する馬ごとに異なる割合で予想確率に変化を与える」ことはおそらくないですね。例えば「n_horsesが多いほど馬体重が重い馬が強い」としてもn_horsesが同じなら同じ割合で予想確率に変化を与えるはず…。
依然として「n_horsesが低いほど予想確率が高くなり、高いほど予想確率が低くなる」よう学習されてしまっている、「n_horsesやそれが絡む特徴量が予想確率に変化を与える場合、n_horsesが異なるときはその変化の割合が異なる可能性がある」のは変わりませんがこれは先述の通り、レースごとに標準化するので特に問題はないです。
つまり、標準化後の確率を使う分にはn_horsesは問題ないと思います。
ちょっと自分でもいろいろこんがらがっていました。申し訳ございません。
前回の投稿も含め誤った記述になっている部分を打ち消し線で訂正しました。
Keshiki 様
完結にまとめていただきありがとうございます。
とてもわかりやすく、大変勉強になりました。
また、勿体ないお言葉もいただき、こちらこそありがとうございます。
知らない、わからないこそ出来た疑問かと思います。
おかげさまで機械学習は実際にどのような事をしているのか?ということにも興味を持ちはじめ、学んでいるところです。
今後の開発ロードマップにあるfastTextを使ったベクトル化をいろいろ実験してみたりしたのですが、なかなか満足のいく結果にならないのと、うまくいったとしてもそれを特徴量として入れたときLightGBMがうまく扱ってくれないのではと思い保留中です
既にお試し中とは。私には未知の世界過ぎて手の出しようがございません、、
お世話になっております
私も独自の特徴を追加しようと思っております。
- results
右回り、左回り、直線、障害を追加 - peds
ファミリーナンバーを抜出し独自列を追加
インブリードしている or していない判別
インブリードしている場合はその馬と血量率を追加
ここまではそれぞれのクラス内で追加できたのですが、生産者など horse_results を利用する特徴量が追加できていない状況です。
平均を取り出したいわけではなく、ユニークな値を追加したいのですが(馬主は途中で変わる可能性があるので面倒ですが)、r.data_p の中から hr のデータフレームを呼び出せず、トライ & エラーを繰り返しております。
※ self と DataFarame の考えが足りていないのだと思います、、
['生年月日', '生産者', '産地', '馬主'] を馬ごとの成績 rdata_h に追加したいのですが、アドバイスいただけないでしょうか?
素人考えで self.latest を参考につくってみたコードが以下ですが、実行の度に kerner resterting が出てしまっております。
※ 変な処理をしているか、メモリ不足をしている感じです
if n_samples == 5:
self.birthday = filtered_df['生年月日'].rename('birthday')
self.owner = filtered_df['馬主'].rename('owner')
self.breder = filtered_df['生産者'].rename('breder')
self.birthplace = filtered_df['産地'].rename('birthplace')
if n_samples == 5:
merged_df = merged_df.merge(self.birthday, left_on='horse_id', right_index=True, how='left')
merged_df = merged_df.merge(self.breder, left_on='horse_id', right_index=True, how='left')
merged_df = merged_df.merge(self.birthplace, left_on='horse_id', right_index=True, how='left')
merged_df = merged_df.merge(self.owner, left_on='horse_id', right_index=True, how='left')
merged_df = merged_df.merge(self.remarks, left_on='horse_id', right_index=True, how='left')
※ 追記
['生年月日']の追加だけなら kernel restarting になりませんでした。
が、同じ race_id に、同じ horse_id で、同じ生年月日の馬が出走していることになってました。
やはりデータの追加の仕方が根本からおかしいようです、、
groupby で処理するのが良さそうなのですが、平均値が欲しいわけでなく、、
そもそも何で self.avarage では hr の値が取得できているのかもわからず、、
目的が合っていましたら、少し前の自分の質問にKeshiki様が回答してくださった内容で解決できるかもしれません。詳細は遡っていただければと思います。
#-------------------
#Keshiki様引用
#-------------------
horse_info = {}
target = ['生年月日', '調教師', '馬主', '生産者']
for horse_id in tqdm(horse_id_list):
time.sleep(1)
try:
url = 'https://db.netkeiba.com/horse/' + horse_id
info_df = pd.read_html(url)[1]
data = list(map(lambda x: info_df[info_df[0]==x].iloc[0, 1], target))
horse_info[horse_id] = data
except:
#省略
df = pd.DataFrame(horse_info, index=target).T
これ単体で取得、保存し、data_h作成後にエンコードして、マージするイメージです。
その後作成したdata_d(仮)にpedsをマージし、data_peを作成しています。
余談ですが、悲しいことに'馬主'や '生産者'は特徴量としてはイマイチだったので自分は除外しています。
kyan 様
私も Keshiki 様のコードを利用させていただき、スクレイピングしておりました。
これ単体で取得、保存し、data_h作成後にエンコードして、マージするイメージです。
その後作成したdata_d(仮)にpedsをマージし、data_peを作成しています。
しかし認識不足で、元の HorseResults.scrape にマージして pickle ファイルとして保存しておりました、、
なるほど、単体で使うものだったのですね、、
DataFrame を分離してチャレンジしてみます。
ご返信いただきありがとうございます。
余談ですが、悲しいことに'馬主'や '生産者'は特徴量としてはイマイチだったので自分は除外しています。
おお、、なるほど、、
こちらも参考?になりました。ありがとうございます、、
余談ですが、私の importance は jokey_id がダントツで一番高い状態でして、なんとか騎手以外による、馬、せめて調教師や馬場の特徴量でこれを打破したいと奮闘しておるところです。
平均を中央値に変更したり、最頻値を追加したりしておりますが、なかなか難しいです、、
横から失礼します。
余談ですが、私の importance は jokey_id がダントツで一番高い状態でして
jockey_idをそのまま使うのはおすすめできないです。
jockey_idは適切に(過学習を起こさないように)エンコーディング等を行うことが必要です。
例えば2018年1~12月のデータで学習する際、詳しい計算はさておき、モデルは当該jockey_idの馬が2018年1~12月に勝っているかを少なからず学習することになります。
ただこの場合、例えば2018年1月のレースの勝敗を当てるときに2018年1月~12月の結果が部分的に分かった状態を学習するので学習データ内でデータリークを起こしています。
結果として学習データ内で予測するのにjockey_idが大きく寄与するのでimportanceが高くなりますが、完全に過学習状態なのででテストデータに対する予測はむしろ悪影響を与えます。
あき 様
例えば2018年1月のレースの勝敗を当てるときに2018年1月~12月の結果が部分的に分かった状態を学習するので学習データ内でデータリークを起こしています。
教本どおりそのまま利用していたのですが、驚愕の事実です。
馬 7 , 騎手 3 などとも言われるように騎手も大事なのでその表れかと思っておりましたが、過去ではわからない未来のデータを利用してしまっている状態だったとは。
確かに特徴を増やしてみたのですが jockey_id の importance はほとんど変化なく不思議に思っておりました。
データリークを状態を避けるためには、具体的にどういった修正を加えれば良いでしょうか?
学習データでは drop するだと、予想の際に jockey_id は無視されますよね。
また、jockey_id をそのまま使用せず、Horse_Results にある騎手のデータをラベルエンコーディングして試してみようと思っているのですが、結局同じことを別の方法で学習するだけなのでしょうか?
※ 追記
現在の auc score は 0.74 近辺なのですが、データリークが起きているとすると実際はもっと低い値なのかと思いました。n_horses を入れた状態で 0.78 近辺、外して 0.74 近辺だったので。
現在の auc score は 0.74 近辺なのですが、データリークが起きているとすると実際はもっと低い値なのかと思いました。n_horses を入れた状態で 0.78 近辺、外して 0.74 近辺だったので。
ちょっとややこしいんですが、
今回のデータリークの意味合いでは 学習データ→テストデータ にデータが流れているわけではないので
テスト結果自体の正当性は保証されます。なので通常のリークのように本来より過剰に高いauc scoreがテストデータに対して出ているということはないと思います。
リークという表現は適切ではなかったかもしれませんが、要は過学習の原因になっている(なのでimportanceも高い)ので、騎手データを使う際は適切な処理が必要だと考えています。むしろテストデータに対する精度悪化の原因にもなりえます。
データリークを状態を避けるためには、具体的にどういった修正を加えれば良いでしょうか?
ズバッと適切なものを提示できればいいのですが、こちらは私もいろいろ考え中です…
あき 様
早速のご返信ありがとうございます。
テスト結果自体の正当性は保証されます。なので通常のリークのように本来より過剰に高いauc scoreがテストデータに対して出ているということはないと思います。
また、jockey_id をそのまま使用せず、Horse_Results にある騎手のデータをラベルエンコーディングして試してみようと思っているのですが、結局同じことを別の方法で学習するだけなのでしょうか?
こちら試してみたところ、騎手が過剰に評価される (importance が異常に高い)ということはなくなりました。
素人目には同じことをしているように思ったのですが、、機械学習は難しいですね。
auc score の方も 0.74 近辺で、ほぼ変わりなくでした。
※ ハイパーパラメータを調整してなる早で完了するように調整したので、最終的には変化があるかもしれません
こちらで少し様子をみます。
まずはご指摘いただきましてありがとうございます。
いつもお世話になっております。
2011年のレース結果をスクレイピングしていたところ、'NoneType' object has no attribute 'find_all'というエラーになってしまいました。
該当するレースIDは201104020701です。
ここは変更してないので教本通りのResults.scrapeを使用しているのですが、ほかに同じような現象になった方はいますでしょうか? よろしければ対処方法などを教えていただけると幸いです。
race_id_list = ['201104020701']
results = Results.scrape(race_id_list)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-347-68800bf31b33> in <module>
----> 1 results = Results.scrape(race_id_list)
<ipython-input-346-e1fffd35f3f4> in scrape(race_id_list)
295
296 #pd.DataFrame型にして一つのデータにまとめる
--> 297 race_results_df = pd.concat([race_results[key] for key in race_results])
298
299 return race_results_df
~\anaconda3\lib\site-packages\pandas\core\reshape\concat.py in concat(objs, axis, join, ignore_index, keys, levels, names, verify_integrity, sort, copy)
283 ValueError: Indexes have overlapping values: ['a']
284 """
--> 285 op = _Concatenator(
286 objs,
287 axis=axis,
~\anaconda3\lib\site-packages\pandas\core\reshape\concat.py in __init__(self, objs, axis, join, keys, levels, names, ignore_index, verify_integrity, copy, sort)
340
341 if len(objs) == 0:
--> 342 raise ValueError("No objects to concatenate")
343
344 if keys is None:
ValueError: No objects to concatenate
2011年の2回新潟開催は6日間しか開催されておらず、レースID201104020701が存在しないため、それによるエラーではないのでしょうか?
回答ありがとうございます。race_idが存在しない場合は、以下の処理で解決してるのかなと思ったのですが、間違っていますでしょうか・・・?
#存在しないrace_idを飛ばす
except IndexError:
continue
念のためscrape処理を記載します。教本通りだと思いますが。
@staticmethod
def scrape(race_id_list):
"""
レース結果データをスクレイピングする関数
Parameters:
----------
race_id_list : list
レースIDのリスト
Returns:
----------
race_results_df : pandas.DataFrame
全レース結果データをまとめてDataFrame型にしたもの
"""
#race_idをkeyにしてDataFrame型を格納
race_results = {}
time.sleep(1)
for race_id in tqdm(race_id_list):
try:
url = "https://db.netkeiba.com/race/" + race_id
#メインとなるテーブルデータを取得
df = pd.read_html(url)[0]
html = requests.get(url)
html.encoding = "EUC-JP"
soup = BeautifulSoup(html.text, "html.parser")
#天候、レースの種類、コースの長さ、馬場の状態、日付をスクレイピング
texts = (
soup.find("div", attrs={"class": "data_intro"}).find_all("p")[0].text
+ soup.find("div", attrs={"class": "data_intro"}).find_all("p")[1].text
)
info = re.findall(r'\w+', texts)
for text in info:
if text in ["芝", "ダート"]:
df["race_type"] = [text] * len(df)
if "障" in text:
df["race_type"] = ["障害"] * len(df)
if "m" in text:
df["course_len"] = [int(re.findall(r"\d+", text)[0])] * len(df)
if text in ["良", "稍重", "重", "不良"]:
df["ground_state"] = [text] * len(df)
if text in ["曇", "晴", "雨", "小雨", "小雪", "雪"]:
df["weather"] = [text] * len(df)
if "年" in text:
df["date"] = [text] * len(df)
#馬ID、騎手IDをスクレイピング
horse_id_list = []
horse_a_list = soup.find("table", attrs={"summary": "レース結果"}).find_all(
"a", attrs={"href": re.compile("^/horse")}
)
for a in horse_a_list:
horse_id = re.findall(r"\d+", a["href"])
horse_id_list.append(horse_id[0])
jockey_id_list = []
jockey_a_list = soup.find("table", attrs={"summary": "レース結果"}).find_all(
"a", attrs={"href": re.compile("^/jockey")}
)
for a in jockey_a_list:
jockey_id = re.findall(r"\d+", a["href"])
jockey_id_list.append(jockey_id[0])
df["horse_id"] = horse_id_list
df["jockey_id"] = jockey_id_list
#インデックスをrace_idにする
df.index = [race_id] * len(df)
race_results[race_id] = df
#存在しないrace_idを飛ばす
except IndexError:
continue
#wifiの接続が切れた時などでも途中までのデータを返せるようにする
except Exception as e:
print(e)
break
#Jupyterで停止ボタンを押した時の対処
except:
break
#pd.DataFrame型にして一つのデータにまとめる
race_results_df = pd.concat([race_results[key] for key in race_results])
return race_results_df
対処方法
exceptが並んでるところに他と同じように
except AttributeError:
continue
を追加。
以下解説
存在しないレースIDについてはdf = pd.read_html(url)[0]の時点でIndexErrorとなるように想定されて設計されていますが、201104020701に関してはなぜか「馬場情報」と「レース分析」というテーブルだけ存在しており、したがってpd.read_htmlがこれらのテーブルを拾ってしまっていたためIndexErrorが発生せずcontinueされなかったようです。
対処法はいろいろあるのですが、とりあえず想定外が一番起きにくそうな「soup.findのところで発生するAttributeErrorをキャッチする」という方法を採りました。
とはいえ201104020701以外のレースについてはテストできていませんので、必要に応じてexcept AttributeErrorを通ったIDをリストにappendするなどして、間違って存在するIDも飛ばしてしまっているなどの想定外の挙動をしていないか後から確認してください。
keshikiさん、対処方法および解説ありがとうございます。
早速試したところexceptの並んでいるところの一番先頭にしたところエラーが出なくなりました。後ほど想定外の挙動をしていないか確認をしたいと思います。
あ、そうですね。except Exception as e:より上のところでないといけませんでしたね。
失念しておりました。すみません。
こちらの動画を参考に自分も馬券購入最適化に挑戦してみました。
スコア上位6頭のスコアと予測オッズ(別でLightGBMで予測)から、軸馬6通り×券種(単勝or馬連or三連複)3通りを選択するというものです。
全く学習されない(Episodeが増えてもRewardが上がらない)課題に直面したため、アドバイスを頂きたいです。
〈追記〉
初歩的なコードミスが原因でした…。
「=」を「==」と入力。
エラーが出てくれればすぐ気づいたのに…
いつもお世話になっております。特徴量について教えてください。
独自の特徴量を追加してみようと思い、馬番を見て、内枠、外枠の情報を与えるようにしてみました。
(1~3だったら内枠で0、6~8だったら外枠で2、それ以外は1として列を追加)
ただ追加したあと思ったのですが、結局、馬番や枠番は特徴量としてすでに与えてあるので、この情報は2重になってしまうのではないかということです。機械学習で枠番や馬番の傾向をある程度見れているのであれば、今回追加した外枠、内枠は過剰に情報を与えてるだけなのではないかと思いました。
すでに特徴量として与えてあるデータを加工して新たに別の特徴量として与えるのは、機械学習的に問題あるか教えていただきたいです。 どうぞよろしくお願いします。
追記(9/3)
早速新しいコミュニティを作ってくださったのでそちらをご利用ください!
以下の避難所は念のため数日の後、クローズにします。
この投稿をもってこのスクラップは書き込み上限となってしまうようなので、対応いただけるまでの間の一時避難場所として私のアカウントにてscrapを作成しました。ここと同じようにお使いください。
ただし、作成にあたって著者様に連絡はさせていただきましたが、事前の許可等はいただいておりませんので、その点ご注意ください。
link:
こちらから避難場所の方にまたがる回答等についての更新情報
- kyan様の質問(https://zenn.dev/link/comments/188d68623996a3)に対する回答
- akirak1108様の質問(https://zenn.dev/link/comments/cbedd6ac61fdc5)に対する回答