某コミュニティ一時避難場所(closed)
Keshikiさん、対応していただきありがとうございます!
コメントへの回答なども、いつもありがとうございます。
取り急ぎ新しいコミュニティを作りましたので、ご活用ください
早速ご対応いただきありがとうございます!事前の許可もなく申し訳ありませんでした。
こちらのscrapは念のため数日置いてからクローズにいたします。
オリジナルのコミュニティ(https://zenn.dev/dijzpeb/scraps/cea06a673aae5c)が書き込み上限になってしまったので、著者様が対応してくださるまでの間の一時避難場所です。
スクラップ作成にあたって、著者様(https://zenn.dev/dijzpeb/books)がお忙しそうなのと、ないよりはいいという観点から作りましたが、事前の許可等はいただいていないのでその点ご注意ください(一応Twitterにて連絡はさせていただきました)。
追記(9/3)
新しいコミュニティを作ってくださったので後日閉鎖いたします。
kyan様 質問(https://zenn.dev/link/comments/188d68623996a3)に対する回答
そのやり方だと「スクレイピングした日付より過去nレースのデータ」になってしまいますね。「各レースの開催日より過去nレースのデータ」じゃないとリークになってしまいます。
とりあえず暫定的に作ってみましたが、間違いや例外がないかなど細かいところまで確認できていないのと、結構ややこしい処理なのでもっといい方法があるかもしれません。
#lambda用
def make_past_data(x, n):
"""
Parameters:
----------
x : pandas.DataFrame
ある馬のある日付よりも過去のデータ(ソート済み)
n : int
過去何レース採用するかの値(n_samples)
Returns:
----------
s : pandas.Series
過去nレースのデータ
"""
#前走のデータ
s = x.iloc[0].add_suffix('_p1')
#過去のデータがない部分に欠損値を埋めるためのダミーを作成
if len(x) < n:
col = x.columns
dummy_s = pd.Series([np.nan]*len(col), index=col)
#前々走以前のデータ
for row in range(1, n):
try:
s = pd.concat([s, x.iloc[row].add_suffix('_p{}'.format(row+1))])
except IndexError: #過去のデータが存在しない部分の処理
s = pd.concat([s, dummy_s.add_suffix('_p{}'.format(row+1))])
return s
n_samples=3
results = r.data_pe #r.data_p でも r.data_hでも可
target = ['タイム指数'] #必要に応じて追加
horse_results_s = pd.read_pickle('horse_results_X.pickle')
horse_results_s["date"] = pd.to_datetime(horse_results_s["日付"])
horse_results_s.drop(['日付'], axis=1, inplace=True)
past_data_dict = {}
date_list = results['date'].unique()
for date in tqdm(date_list):
horse_id_list = results[results['date']==date]['horse_id']
target_df = horse_results_s.query('index in @horse_id_list')
filtered_df = target_df[target_df['date'] < date].sort_values(
'date', ascending=False)
past_data = filtered_df[target].groupby(level=0).apply(
lambda x: make_past_data(x, n_samples))
#最後にmergeする際のキーとしてhorse_idとdateを追加
past_data['horse_id'] = past_data.index
past_data['date'] = [date]*len(past_data)
#一旦dictに保存(ここでconcatすると遅い)
past_data_dict[date] = past_data
#保存したpast_dataを一つにまとめる
past_data_all = pd.concat([past_data_dict[key] for key in past_data_dict])
#merge
merged_df = pd.merge(results, past_data_all,
left_on=['horse_id', 'date'], right_on=['horse_id', 'date'],
how='left').set_axis(results.index)
Keshiki様、お世話になっております。
投稿出来なかった為、こちらから連絡させていただきます。
そのやり方だと「スクレイピングした日付より過去nレースのデータ」になってしまいますね。「各レースの開催日より過去nレースのデータ」じゃないとリークになってしまいます。
ここも自分の認識が甘かったです。自分のコードですと全てのレースで同一の直近3レースを使用してしまいますね、、、連結にgroupby().cumcount() などを使い、試行錯誤してみましたが、まだまだ勉強不足でした。素晴らしいコードをありがとうございます。解決できないことに悔しさを覚えるので、これからも勉強していきます。特にPandasの勉強が不足していると感じています。
こちらの避難場所も作成していただきありがとうございます。
自分の質問で時間を割いてしまい申し訳ございません。本当にありがとうございます。
追記です。
追加した特徴量はなかなか効くことが分かりました。
feature_importanceでも3つともTOP20までにはランクインしています。
ありがとうございますm(__)m
Keshiki、お世話になっております。
こちらに関しての質問は受け付けていただけないでしょうか?
ご検討宜しくお願い致します。
何でしょう?
可能であれば、新しくできたGitHubのコミュニティの方がいいかもしれません(#32のissueに引き継がれています)。
連絡が遅くなり、申し訳ありません。
承知致しました。宜しくお願い致します。
ご質問の方がまだ確認できておりませんが、大丈夫でしょうか?
Keshiki様、お世話になっております。
パソコンの調子がイマイチで修理に出していました。
連絡が遅くなり、大変申し訳ありません。
昨日戻ってきましたので、改めて質問させていただきます。
引き続き宜しくお願い致します。
追記です。
issuesの32に質問させていただきました。
宜しくお願い致します。
なるほど、そうでしたか。
回答させていただきましたのでまた時間のある時にご確認ください。
Keshiki様、お世話になっております。
ご回答ありがとうございます。
帰宅後にしっかり理解した上で返信させていただきます。
宜しくお願い致します。
いつもご教示ありがとうございます。
Keshiki様、お世話になっております。
調子が悪かったパソコンがなくなりになり、データが吹き飛んでしまいました。
AI作成はローカル環境のみで作業していましたので、ご察しの通りです。
上記などもあり、連絡などが遅くなってしまいました。
大変申し訳ありません。
モチベーションは変わらずあるので引き続きご教示宜しくお願い致します。
いつもありがとうございます。
そうだったんですか。それは大変ですね…。
返信等はいつでも大丈夫ですので、お気になさらず。
復旧作業頑張ってください。
Keshikiさん、ご無沙汰しております。
ようやくモチベーションが復活してきました。
毎回レベルの低い質問ばかりでご迷惑をおかけしておりますが、
引き続きのご指導宜しくお願い致します。
今回githubに質問させていただきましたが、悲しいことに誰からも相手にされなかったので、
質問させていただきます。。。
ハイパーパラメータについてです。
①毎週ハイパーパラメータを取り直し、利用している(1度のみ)
②毎週ハイパーパラメータを取り直し、利用している(複数回取り直し、何かしらの基準で良いものを選択)
③今まででAUCスコアが一番高かったハイパーパラメータを使い続ける
④その他
おそらく正解があるのもだと思いますが、如何せん知識がなく、ふとした疑問として出てきました。
ちなみにですが自分は開発当初は③、現状は①で利用しております。
是非とも参考にさせていただきたいです。
宜しくお願い致します。
ーーーーーーーーーーーー
また、1点追記させていただきます。
今回、新たに「乗り替わり」、「距離増減」、「回りの変化」などを追加したいと考えております。
一日ほど考えた結果、ここでご教示していただいた「タイム指数」の関数を応用したら作成できるのではないかという結論に至りました。
その中で現在試行錯誤中です。
この考えは合っていますでしょうか?
ーーーーーーーーーーーー
さらに、1点追記させていただきます。
horseID = 2017110151 のカフェファラオの競争成績を見て、気づいたのですが、
同じ騎手でもDB上で「ルメール」と「C.ルメ」と複数パターン存在するパターンを発見しました。
何も触っていない状態ですと、この場合、別の騎手としてAIは学習しているのでしょうか?
重ねて宜しくお願い致します。
ーーーーーーーーーーーー
さらに、1点追記させていただきます。
同じ騎手でもDB上で「ルメール」と「C.ルメ」と複数パターン存在するパターンを発見しました。
こちらに関しては、地方競馬のレース結果は対象データとしていない為、
気にする必要がない気がしております。。。
そして、Keshiki様に枠組みを作成していただきました過去の「タイム指数」取得関数上では、
地方の数値も取り込んでしまっているのではないか?と気が付きました。
この件に関しましても、修正案を模索中です。
githubの方に返信しました。
akirak1108様 質問(https://zenn.dev/link/comments/cbedd6ac61fdc5)に対する回答
内・中・外というカテゴリ変数化をするなら、どちらかというとmin-maxスケーリングをした方がいいと思います。
ただ、そもそも枠番や馬番という特徴量は、出走数と同様にリークに近い問題を起こしています。というのも、馬番や枠番のそれぞれの値に該当しうるレコード数が異なってしまうからです。
話を単純化するために枠番ではなく馬番で考えます。
ある年、5頭出走のレースと10頭出走のレースの2レースしかなかったとすると、1~5番の馬は6~10番の馬に比べて1レコードずつ多いというのがわかると思います。したがって、馬の実力等は考慮せず、馬番だけ考慮するとき、1~5番の馬は6~10番の馬に比べて確率が高く算出されてしまいます。
枠番や馬番を内・中・外のカテゴリ変数化したり、min-maxスケーリングしたりしても結局各値に該当しうる馬の数がバラバラなのでこの問題を厳密には回避できません。
枠番や馬番を特徴量として使いつつ、こうした問題を回避するには、出走数ごとに分けて別々に学習するか、出走数が違うとき同じ値を使わないという方法(※1)しかないと思います。
(他の方法をご存じの方いらっしゃいましたらぜひ教えてください…)
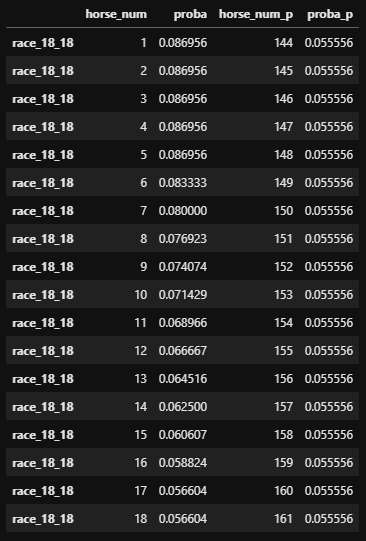
※1: 馬番なら、5頭のレースの場合[1, 2, 3, 4, 5]、6頭のレースの場合[6, 7, 8, 9, 10, 11]と順番に増やしていく。18頭レースの18番は161となる。これなら各値に該当しうる馬の数がバラバラという問題を回避できる。内・中・外というような特徴量もいらない。
検証
5~18頭のレースでそれぞれの頭数のレースにおいて各馬番が必ず1回rank=1となるようにしたデータを用意した。rank=1となるのは各レースに1頭のみ。
馬番のみを説明変数、rankを目的変数として学習。出力される確率を見るだけなので訓練データとテストデータは同じものを使用(わかりやすいように名前だけは分けた)。
画像は例として'race_18_18'を示した(18頭レースの18番がrank=1という意味)。左が通常通りの馬番を使って学習したもの。右の'_p'とついてる方が※1の方法で加工した馬番を使って学習したもの。左は該当しうる馬の数が同じ1~5番は同じ確率で、6番以降下がってしまっているのがわかる。右はすべて同じ確率となっている。
追記(9/7)
改めて考えてみての追記です。
※1の、馬番を5頭のレースの場合[1, 2, 3, 4, 5]、6頭のレースの場合[6, 7, 8, 9, 10, 11]と順番に増やしていくという方法だと、例えば訓練データ内である条件で5番(5頭出走の外枠)の馬が多く勝っていたとして、テストデータの6番(6頭出走の内枠)が同じ条件であった時、外枠が有利という条件であるはずなのに、5と6が数値上近いので6番の確率が上がってしまうと思います。
出走数が変わる場所で数値に一定の間隔を空ける(5の次は105など)と緩和しそうですが、根本的な解決にはなっていないのと、影響を無視できるほどになるかは不明です。
Keshikiさん、いつも回答ありがとうございます。説明を読まさせていただき、なるほど!と感心してしまいました。確かにレコード数が違うのは、公平にならないですね。現状の馬番でこのような問題が起きているとは気づきませんでした。ありがとうございます。