読者コミュニティ2
この度、より議論に適した場として、GitHubに書籍購入者限定コミュニティを用意しましたので、今後の投稿はそちらにお願い致します!
何ができるか
-
掲示板での交流
動画や書籍を進める上で分からないことや、新しいアイデアなどを自由に議論し合うことができます。過去に議論されてきた話題も全て残っており、検索することができるので、何か気になることがある場合や発信したい情報がある場合はぜひ参加してみてください。もちろん「見るだけ」の参加も大歓迎です。 -
共同開発
新バージョンの競馬予想AIは共同開発用に作られており、共同開発リポジトリではPull requestを受け付けています。
「ソースコードの改善点を発見した」「自分のアイデアや書いたコードを反映させたい」などあれば、ぜひPull requestを送ってみてください。
参加対象者
以下のいずれかを満たす人を対象者とします
- 競馬予想で始める機械学習〜完全版〜購入者
- 競馬予想で始める機械学習〜教科書ver〜と競馬予想で始める機械学習〜最先端ver〜を両方購入している人
参加方法
githubのアカウントを作成し、dijzpeb2@gmail.comまで、以下の2点をお送りください
- 書籍の購入証明(購入した時のメールや、支払い完了画面のスクリーンショットなど)
- githubアカウント名
確認が出来次第、招待のリンクを送信します。
本の感想や質問をお気軽にコメントしてください。ソースコードを挿入したい場合は
```python
挿入したいコード
```
でできます。
YouTubeのメンバーシップに登録していて、Zennのアカウント名と異なる場合には、メンバー登録していることを知らせていただけると助かります!
約1カ月、中央競馬で運用してみました。結果と感想です。
使ってみて、「ランク学習が必要なのかな?」と感じました。
使ってみた結果
賭けたレース・賭けていないレースはありますが、本番の実行コードで1頭目に出力された馬の結果です。(7/31-9/4 中央競馬の全レース(348R))
※スコアに関係なく、出力された1頭目(スコアが最も高い馬番に全て賭けた場合)です。
| R | 単勝回収値 | 複勝回収値 | 勝率 | 複勝率 |
|---|---|---|---|---|
| 1R | 166.6% | 100.0% | 34.5% | 62.1% |
| 2R | 71.0% | 61.0% | 24.1% | 48.3% |
| 3R | 76.6% | 65.2% | 17.2% | 41.4% |
| 4R | 71.7% | 96.2% | 24.1% | 48.3% |
| 5R | 157.2% | 114.1% | 6.9% | 17.2% |
| 6R | 186.9% | 189.0% | 24.1% | 48.3% |
| 7R | 83.1% | 79.3% | 31.0% | 55.2% |
| 8R | 53.4% | 61.0% | 20.7% | 34.5% |
| 9R | 42.1% | 65.2% | 17.2% | 65.5% |
| 10R | 54.1% | 96.2% | 17.2% | 48.3% |
| 11R | 72.1% | 114.1% | 17.2% | 37.9% |
| 12R | 93.4% | 189.0% | 31.0% | 55.2% |
| 平均 | 94.0% | 91.6% | 22.1% | 46.8% |
流し馬券の場合、回収率が100%を超えるために、score=3.0以上必要なことが多いです。
score=3.0以上の結果は、348R中12R(全体の3%程度)でした。
現状でこのAIは新馬戦や未勝利戦・1勝クラス・2勝クラスあたりで使える印象です。
ざっくりと「午前のレースが得意・午後は苦手」という結果です。
感想
「戦績が少ない馬のレースは予測できる」状態のため、過去のレース結果の比較が難しいように感じました。
今後の開発ロードマップに記載されているように、「lambdarank」で学習することで的中率の精度が上がるのでは?と感じているところです。
ランク学習について調べたところ、Queryデータを作るのが大変そうな印象で挫折しました。。。
素人には難しいです。。
希望
・精度が上がると思うので、是非「ランク学習」を取り入れて頂きたいです。
使えそうなサイト:[競馬予想AI] ランク学習で着順予想するとなかなか強力だったお話
・賭け方について、「フォーメーション」にすることでBOXよりも回収率が上がるのではないでしょうか。
フォーメーションの場合、「回収率に期待できる賭け方を探す」「レースごとに良い賭け方を出力する」というものでしょうか。。
train_query = train.groupby(level=0)['馬番'].count()
valid_query = valid.groupby(level=0)['馬番'].count()
Queryデータはこれで一発です!
私は先行して試していますが、目的変数の調整が難しいですね…。着順を何着まで評価するかや、オッズの重み付けの度合いなど、色々試行錯誤してます。
ありがとうございます。
queryデータが作れました。
競馬予想AI再び -前編- 〜LambdaRank編〜
をそのまま使うことはできないようなので、もう少しいじってみます。。
初めまして。
新しいコミュニティが出来ていたので、こちらに投稿させて頂いています。
1つ前のコミュニティで、Hamaさんという方が回収率表示する際、gain処理での時間がかかりすぎるという投稿をしていらしたのですが、私も2017年~2021年8月8日までのデータを使用して、馬連BOXで約8時間かかる問題が発生しています。(単勝でも15分程)
プログラミング初心者のため原因を探る方法も掴み切れていない状況です。
どなたか同じような現象が起きた方、改善策がお分かりになる方がいればご教授頂けると幸いです。
だいたい同じくらいのデータ量で試してみましたが、こちらでは1/100完了時点での推定完了時間は40分弱でした。
Hamaさんが何度か試してみたら解決したとあるので、メモリ不足とかじゃないでしょうか。もしくは単純なスペック不足か。
一度jupyter labをシャットダウンしてもう一度試してみてください。スペックの可能性がある場合はgoogle colabを試してみるなどしてみてください。
Keshikiさん
その後別PCで試す機会があり、Keshikiさんと同様に40分弱の推定完了時刻となりました。
仰られる通り、メモリ不足・スペック不足の可能性が高いように思われます。
アドバイス頂きありがとうございました。
はじめまして
merge_horse_results()について質問があります。
この関数は、r_data_peの各レースの馬データに対して、「そのレースより過去の成績を載せた列を付け足す」ものか、「全期間の馬の過去成績を載せた列を付け足す」どちらなのでしょうか?
仮に後者とした場合、04章 【機械学習モデル作成&学習】にてr.data_cを分割してtest,trainデータとしていますが、r.data_cの分割のされ方によってはtrainデータに未来の馬の成績が入った状態になり、testデータによる検証に影響を与えるのではないでしょうか?
(素人考えですが、的外れでしたら申し訳ありません)
前者です。
HorseResultsクラスのaverage()でレースの日付より過去のデータに絞っています。
ありがとうございます。よかったです
いつもお世話になっております。
HorseResultクラスにある上り3Fのデータを使用してみようと思い、preprocessing()にて、開催、距離に応じた基準値からの差を出してみようと思いました。
そこで開催地が01:札幌だったらという感じで条件を追加していこうとしたのですが、うまく条件を記述できません。。初歩的な質問で申し訳ないですが、どのように記載すればよいでしょうか・・?
if df['開催'] == '01':
という感じでやってみたのですが、以下のエラーが出てしまいます。
ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
イメージ的には
if df['開催'] == '01':
if df['馬場'] == '良':
if df['course_len'] == 12:
→札幌で馬場が良で距離1200mのときの3F基準値と、取得した3Fの差を出す
という感じで考えていました。
dfに入るのが1レース分ならif df['開催'].iloc[0] == '01':でできます。開催場所は同じなので一番上のレコードだけ見るという感じです。
1レース分じゃないなら、専用の関数を作っておいて、groupbyしてapply lambdaでその関数を回し、その結果をマージするのがいいと思います。
Keshiki様> いつもありがとうございます。
HorseResultsクラスのpreprocessing()なので、1レースずつの処理になると思います。(他の処理も同様に処理をしているため。)
試しに教わった条件を入れてみたところ、エラーは出なかったのですが、どうも条件に入らないようです。
class HorseResults:
def __init__(self, horse_results):
self.horse_results = horse_results[['日付', '着順', '賞金', '着差', '通過', '開催', '距離','上り','馬場']]
self.preprocessing()
・
・
・
def preprocessing(self):
df = self.horse_results.copy()
# 着順に数字以外の文字列が含まれているものを取り除く
df['着順'] = pd.to_numeric(df['着順'], errors='coerce')
df.dropna(subset=['着順'], inplace=True)
df['着順'] = df['着順'].astype(int)
df["date"] = pd.to_datetime(df["日付"])
df.drop(['日付'], axis=1, inplace=True)
#賞金のNaNを0で埋める
df['賞金'].fillna(0, inplace=True)
#1着の着差を0にする
df['着差'] = df['着差'].map(lambda x: 0 if x<0 else x)
#レース展開データ
#n=1: 最初のコーナー位置, n=4: 最終コーナー位置
def corner(x, n):
if type(x) != str:
return x
elif n==4:
return int(re.findall(r'\d+', x)[-1])
elif n==1:
return int(re.findall(r'\d+', x)[0])
df['first_corner'] = df['通過'].map(lambda x: corner(x, 1))
df['final_corner'] = df['通過'].map(lambda x: corner(x, 4))
df['final_to_rank'] = df['final_corner'] - df['着順']
df['first_to_rank'] = df['first_corner'] - df['着順']
df['first_to_final'] = df['first_corner'] - df['final_corner']
#開催場所
df['開催'] = df['開催'].str.extract(r'(\D+)')[0].map(place_dict).fillna('11')
#race_type
df['race_type'] = df['距離'].str.extract(r'(\D+)')[0].map(race_type_dict)
#距離は10の位を切り捨てる
df['course_len'] = df['距離'].str.extract(r'(\d+)').astype(int) // 100
df.drop(['距離'], axis=1, inplace=True)
#インデックス名を与える
df.index.name = 'horse_id'
#データがないものはNaにする
df['上り'].fillna(0, inplace=True)
# '札幌':'01', '函館':'02', '福島':'03', '新潟':'04', '東京':'05',
# '中山':'06', '中京':'07', '京都':'08', '阪神':'09', '小倉':'10'
#独自追加 基準値から3Fの差を出す
up_3_halong = 0.0
if df['開催'].iloc[0] == '01':
if df['馬場'].iloc[0] == '良':
if df['course_len'].iloc[0] == 12:
up_3_halong = 10
else:
up_3_halong = 100
else:
up_3_halong = 200
else:
up_3_halong = 300
df['up_3halong'] = up_3_halong
self.horse_results = df
self.target_list = ['着順', '賞金', '着差', 'first_corner', 'final_corner',
'first_to_rank', 'first_to_final','final_to_rank','up_3halong']
↑は条件に適した値が入るか試しにup_3_halong変数に値を入れたものです。
しかし結果を見ると全部300が入ってました。
course_len 開催 up_3halong_3R
202101010101 12.0 01 300.0
202101010101 12.0 01 300.0
202101010101 12.0 01 300.0
202101010101 12.0 01 300.0
202101010101 12.0 01 300.0
... ... ... ...
202109020412 14.0 09 300.0
202109020412 14.0 09 300.0
202109020412 14.0 09 300.0
202109020412 14.0 09 300.0
202109020412 14.0 09 300.0
※本当はr.data_hは開催を削除しますが、確認のために残しときました。
if df['開催'].iloc[0] == '01':で札幌のレースを判定できると思ったのですが、何が悪いか分かりますでしょうか・・・??
hrクラスのdfに入るのはすべてのレースですね。
この形だとgroupbyすると少し難しくなるので、ちょっと遅くなってもいいならgroupbyせずに
up_3_halong = df[['開催', '馬場', 'course_len', '上り']].apply(lambda x: self.専用の関数(x), axis=1)
df['up_3halong'] = up_3_halong
とするのが簡単かと思います。
xにはdf[['開催', '馬場', 'course_len', '上り']]の各レコード(Series型)が入りますので、専用の関数でif x['開催'] == '01':という感じでやります。returnは「基準値と3Fの差」の値にします。
前の投稿では「結果をマージ」と書きましたが、up_3_halongはSeries型になるのでmergeやconcatではなく代入でOKです。
Keshiki様>
何度もありがとうございました。おかげさまでやりたいことがようやくでき、開催場所、馬場、コース種類、コース長さ のそれぞれにあった基準タイムを分けることが出来ました!
【ちょっとしたバグ報告】
間違いがありましたらご了承ください。ご指摘いただけると幸いです。
①
ResultsとShutubaTableのスクレイピングについて、一部のレースでcourse_lenが2となってしまっています。例えば内2周3600mの2が引っかかってしまっているようです。以下のように変更することで修正できます。
#変更前
df['course_len'] = [int(re.findall(r'\d+', text)[0])] * len(df)
#変更後
df['course_len'] = [int(re.findall(r'\d+', text)[-1])] * len(df)
②
pedsのデータですが、スクレイピングの時点で重複を削除しているので、血統表の1~4代前までの同じ世代に同じ馬名があるときデータがずれてしまっています。
例) オールドフレイム(2014104728): Hail to Reasonはpeds_14に入るはずですが、peds_13に入ってしまっています。母母からのデータが存在しないため、母母父と母母母が同じNaNとなり重複扱いになってデータがずれていきます。
また、そもそも同名の別馬というのも結構いるようですので、馬名でカテゴリ変数化してしまうと別の馬であるにもかかわらず同じ値のカテゴリ変数を持つものが出てきてしまいます。
したがって、pedsのデータはhorse_idを取得するのがいいと思いますがいかがでしょうか。
③
ModelEvaluatorクラスのpredict_proba()内でprobaをレースごとに標準化する際のx.std()についてですが、pandasではデフォルトで不偏標準偏差の値が求まるようになっているようなので、x.std(ddof=0)として標準偏差の値にするのがいいのではないかと思いますがいかがでしょうか。
①についてですが、私も同じバグを発見しました。
私は、以下のように修正しております。
やりたいことは、0番目の配列を取ることではなく、m(メートル)よりも前の数字を取り出すことなので、こっちの方がしっくりきました。
#変更前
df['course_len'] = [int(re.findall(r'\d+', text)[0])] * len(df)
#変更後
#正規表現によりmより前の数字だけを取り出す
df['course_len'] = [int(re.findall(r"(\d+)(?=m)", text)[0])] * len(df)
y_test = test['rank']について
この式は、要するに、LGBで、的中率を最適化(=MAX)するように加重を求め、その的中率最適化モデルで、回収率を見るということであっていますか?
馬王という競馬ソフトでは、回収率を出し、特徴量を決め、手作業で、以下のような調整をして回収率が適当にちょうどいい感じにイジるという方式をやっていたのでそれから卒業したいのです。
①一番人気をカット
②馬連配当20倍以上
③一番人気の得点(ここでいう、threshold)が高い場合は、見送り
y_test=test[払い戻し累計」、として
y_testを、MAXにするように、パラメターを調整するのは難しいのでしょうか?
いつもお世話になっております。
馬番順に並んでいる調教データを着順で並んでいるrace_resultsに自分なりにあるゆる方法でmergeしようとしてもどうしても上手くいきませんでした。そこでrace_resultsをrace_idごとに馬番順に並び替えて、concatすれば簡単かなと思ったのですが、race_resultsを馬番順に並び替えることが出来ませんでした(笑)groupbyだのsortだの色々したのですが…
どなた様かご教授頂けますでしょうか?
私は下のような感じでやってます。
df = df.groupby(level=0).apply(lambda x: x.sort_values('馬番'))
df.reset_index(level=0, drop=True, inplace=True)
LightGBMでは着順順のまま学習させるとリークになるという話を聞いたので並べ替えています。
ありがとうございます!
相当似た感じでやったのですがカスってました(笑)
リークの問題も確かに思いました。一番目に来るのが熱いみたいに学習するのかなとか。頭数がバラバラなので微妙ですが。そもそも馬ごとに横に学習しているイメージはありますが、縦の関係で学習しているのかどうかもよく分かってません…
お世話になっております。
- メモリ使用量について
10 年分のデータを利用し、独自特徴量を追加したところ、メモリ不足になってしまいました。
import gc
をしておき、例えばですが下記のように要所要所でメモリ解放するのがいいかと思いました。
self.data_p = df
del df
gc.collect()
ただ、これをしていいのかがわからずでアドバイスをお願いできればと存じます。
また、return で返している df については、return 後に同様の処理をするとメモリ解放がされるかご教示いただければと存じます。
例えば、以下のような処理イメージです。
return merged_df
del merged_df
gc.collect()
※ 自分で試したいところなのですが、リソースのスペックが低く検証に時間がかかるため、ご存知であれば、、return してるので、意味はなさそうな気はしております、、
-
型変換につきまして
Kaggle で活用されている reduce_mem_usage 関数があり、利用してみたところメモリの利用減少が認められました。
しかし型を変換しているため、これが学習結果に関連するかを懸念に思っております。アドバイスいただければと存じます。 -
Note Book の分割について
上記のようにメモリ不足になってしまったため、Note Book を分割しようと思っております。
-
- スクレイピング専用
-
- 学習専用
-
- 予想専用
この際ですが、「2. 学習専用」と「3. 予想専用」が違う Note Book の場合でも、利用するデータが同じ、且つ利用するハイパーパラメータが同じであれば(学習する Note Book と 予想する Note Book) を分割しても問題なく同じ結果になるのでしょうか?
第30回のコードを実装し運用していたところ以下のエラーが出てくるようになりました。
最近変更を加えたこととしては直近3週間分のレース結果をスクレイピングし追加しました。
その後このようなエラーが発生し学習が進まない状態となっています。
2021年のresults, horse_results, peds, return_resultsをスクレイピングしupdate_data関数で更新しましたが、改善されませんでした。
エラー解決の糸口かエラー解決の方法がわかる方いらっしゃったら教えていただけないでしょうか?
results.index.unique()とreturn_tables.unique()の長さは一致していました。
<ipython-input-39-7e41a6998438>:11: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray.
states = np.array([self.memory[index]['state'] for index in batch_indexes])
TypeError Traceback (most recent call last)
TypeError: only size-1 arrays can be converted to Python scalars
The above exception was the direct cause of the following exception:
ValueError Traceback (most recent call last)
<ipython-input-41-495cb750bdbb> in <module>
38 }
39 agent.replay_buffer.append(transition)
---> 40 agent.update_q()
41 episode_rewards.append(episode_reward)
42 if episode % 10 == 0:
<ipython-input-40-b29b4c614620> in update_q(self)
12 def update_q(self):
13 batch = self.replay_buffer.sample(self.batch_size)
---> 14 q = self.qnet(torch.tensor(np.float32(batch['states']), dtype=torch.float))
15 targetq = copy.deepcopy(q.data.numpy())
16
ValueError: setting an array element with a sequence.
python初心者です。
Pedsクラスでスクレイピングを行いたいのですが、
peds_results = Peds.scrape(horse_id_list)でスクレイピングを行おうとすると
NameError: name 'horse_id_list' is not defined
となってしまいます。
Results.scrapeとHorseResults.scrapeのスクレイピングはうまくいっています。
気になるのはpickleファイルを読み込んだ時、results.pickleはLastmodifiedが更新されたのに対して、horse_results.pickleは更新されませんでした。
対処法をご教示いただけますと幸いです。
horse_id_listが作成されていないようですので前回スクレイピングしたresultsからhorse_id_listを作成してみてください。
horse_id_list = results['horse_id'].unique()

初めまして!Python初心者です。
Chapter03のデータ加工・前処理の部分で
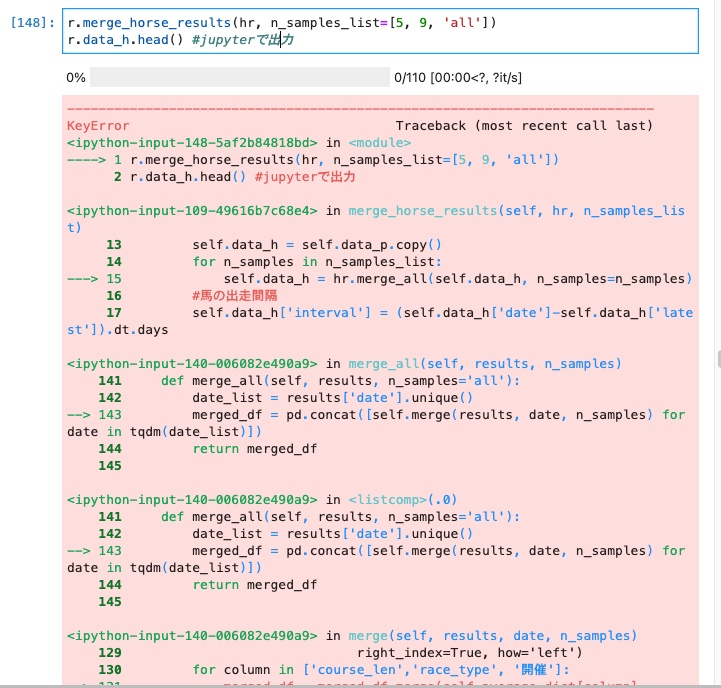
r.merge_horse_results(hr, n_samples_list=[5, 9, 'all'])
r.data_h.head() #jupyterで出力
の入力でKeyError:'開催'と出てきてしまいます。
dfの列にもきちんと入れてあるのでなぜこのようなエラーが出てしまっているかわかりません。
どなたかご教授いただけないでしょうか??
プログレスバーを見ると処理される前にエラーが出ているようですので「開催」列がないことが原因のようですが…
この処理の前に
r.preprocessing()
を実行したと思いますが、r.data_pの中に「開催」列はありますか?
Nobuさん
返信ありがとうございます!r_data_pの中身を確認したところ、抜けていたので追加したら無事に解決しました。ありがとうございました。
初めまして。
初歩的なことかもしれませんが、
Chapter03のデータ加工・前処理にてHorseResultsクラスで前処理を行う際にエラーが発生してしまい解決できません。
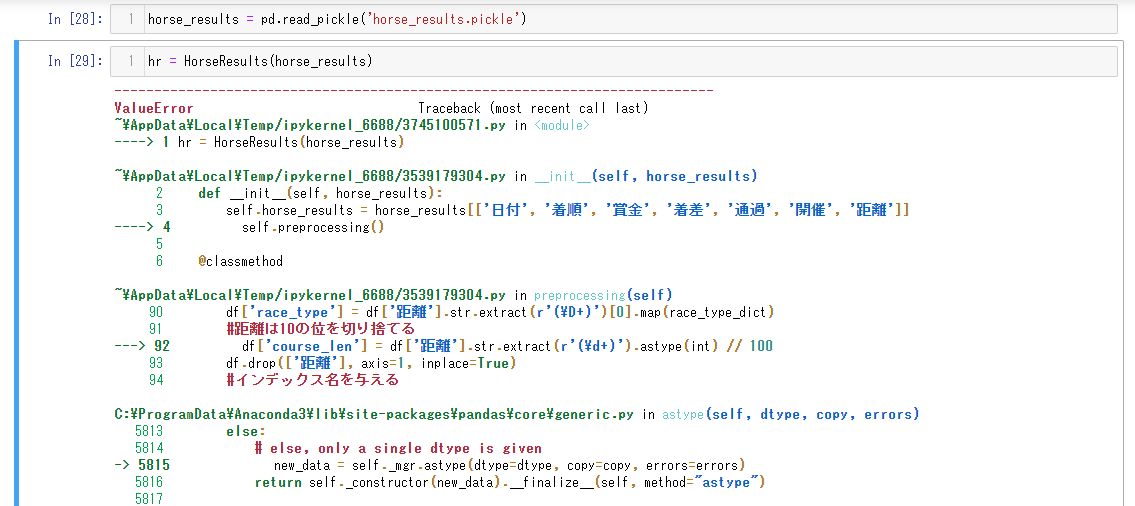


これはNaNがflort型だからエラーが起きているように見受けられますが、
距離をint型に変更すればと思ったのですが上手くいきません。
どなたかご教授いただけませんでしょうか。
こんにちは。
元のデータにNaNが含まれているのでしょうか?まずそれを確認したほうがいいですね。
horse_results['距離'].unique()
#例
array(['芝1800', '芝1200', '芝1500', '芝1000', 'ダ1700', 'ダ1400', 'ダ1800',
'ダ1300', '芝2600', '芝2200', nan , 'ダ2100', '芝2300', 'ダ2400',
'ダ2000', 'ダ1500', 'ダ1900', 'ダ1870', 'ダ1230', '障2970', 'ダ900',
'芝2500', '障2910', '障2890', '障2880', '芝3000', 'ダ2500', '芝1700',
'芝1990', '芝2100'], dtype=object)
中身を確認して変換できない文字やNaNがあればそれを表示し影響がないデータなら行削除したらどうでしょう。
#NaNの行を抽出
horse_results[horse_results['距離'].isnull()]
#削除しても問題なければ行削除
horse_results.dropna(subset=['距離'],inplace=True)
もし大量にあるようなら、何か他の原因があるかもしれません。
お返事ありがとうございます。
ご指摘頂いたとおり元データの確認をした所、NaNは含まれていませんでした。
ですが、芝という記載のみでレース距離の記載がない項目がありました。
これがエラーの原因だとあたりを付け、対象の行を削除し確認しましたらエラー解消出来ました。
少ない情報で色々ご指摘頂きましてありがとうございます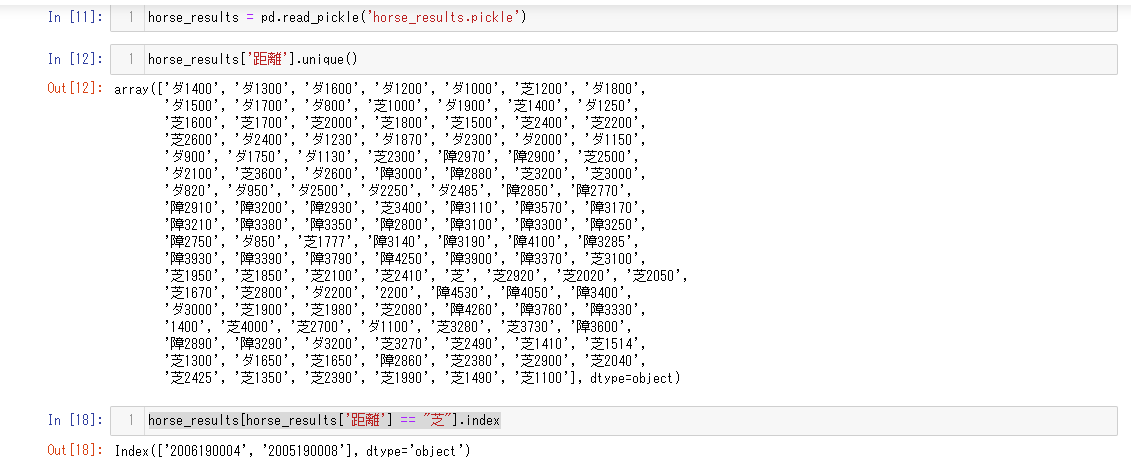

。
深層強化学習の動画を参考に強化学習を試しているのですが、過学習が解消されません。
動画では報酬の設定をいい感じにすれば精度は出ていたかと思うのですが、
なにか過学習の対策になるアイデアあれば教えていただきたいです。
■モデル
入力:予想上位5頭の予測勝率 、 1/ オッズ の10要素
出力:どの馬に賭けるか
報酬:(単勝適正回収値を使って) 1 - 掛け額の総和
モデルの構成:基本的なDQN
(動画では10-16-16-16-5の構成になってたかと思いますが、過学習の対応するため、10-16-12-5として学習させてます。)
■過学習対策でやったこと
バッチサイズをあげる。
モデルの学習するパラメータを減らす(層の数を減らし、層内のパラメータも減らす)。
ドロップダウンを組み込む。
入力データに微量のノイズを載せて、学習データの水増し。
学習の回数などは動画からあまり読み取れませんでしたが、20分ほど回しているので、動画と同じくらいは学習できてるかと思います。
学習率は0.001です。
最近、強化学習を勉強しつつ試してみてるので、どこが学習にとって大事か分からないので、
他に大事なパラメータ等あれば公開します。
精度出せてる方いればご意見伺いたいです。
初めまして。
下記スレッドと同様のエラーで詰まってしまい、解決できないため質問させていただきます。
https://zenn.dev/link/comments/b621c0a7881f6e
下記のコードを実行したところ「UndefinedVariableError: name 'pred' is not defined」といいうエラーが発生しました。
(エラー内容は参照スレッドのSho_003さまと同様です。)
g_umaren = gain(me.umaren_box, X_test)
スレッドに下記の様に変更することで対処できるとありましたので、変更前のコードをコメントアウトし、変更後のコードを追記して再度実行しました。
#変更前
return pred_table[pred_table['pred']==1][['馬番', '単勝', 'score']]
#変更後
return pred_table[pred_table['pred']==1]
しかし「UndefinedVariableError: name 'pred' is not defined」というエラーが発生し解決できませんでした。
マニュアル通りに進めておりますが、抜けている手順やたりないデータ等があるため発生しているのでしょうか?
お忙しいところ恐れ入りますが、ご教示いただけますと幸いです。
こんにちは。
bet_only = False がないようです。
試してみてください。
#変更前
def umaren_box(self, X, threshold=0.5, n_aite=5):
pred_table = self.pred_table(X, threshold)
#変更後
def umaren_box(self, X, threshold=0.5, n_aite=5):
pred_table = self.pred_table(X, threshold, bet_only = False)
素人質問で恐縮なのですが、03データ加工・前処理で書かれてある
r.merge_horse_results(hr, n_samples_list=[5, 9, 'all'])
r.data_h.head()
を実行したのですが、画像のようにマージされてしまいます。どのように解決できますでしょうか?
よろしくお願いいたします。

winのVScodeにてtqdmを使用した場合、エラーになる事があるみたいです。
pip install ipywidgets
で解決できそうな内容でしたが、権限に引っかかり実行できません。
VScodeを管理者権限で起動し、ipywidgetsをpip installすることで解決できます。
html_path_list_ped = glob.glob('data/html/ped/*.bin')
をWindows下で実行すると、
['data/html/ped\\2013100731.bin',
'data/html/ped\\2014103521.bin',
'data/html/ped\\2015101239.bin',
と勝手におきかわってしまい
horse_id = re.findall('(?<=ped/)\d+', html_path)[0]
を通す事ができないみたいです。
ナンテコッタ・・・解決策がみつからないよ。。。
多少、強引ではありますが、prepareData.py186行目
horse_id = re.findall('(?<=ped/)\d+', re.sub(r'\\','/',html_path))[0]
にて、対応できそうです。
あと、最終行のreturnで値が返されていないようです。以下に変更が必要です。
peds_df = pd.concat([peds[key] for key in peds], axis=1).T.add_prefix('peds_')
return peds_df
↑
モジュールのバージョン違い等でエラーが起きるのを防ぐために、
みなさんの環境を参考にさせていただきたいです。
requirement.txtを共有していただくことは可能でしょうか。
(既にどこかの投稿にあったらすみません)
よろしくお願いいたします。
新コードを頂くためにGithubへの招待をメールでお願いしたのですが、どのくらいで招待頂けますでしょうか?
先ほど招待メールを送りました!
ありがとうございます!
先程書籍購入写真と共にメールを送りました!
ご確認のほどよろしくお願いいたします。
はじめまして。
完全版を購入し、いつも動画で勉強させていただいています。
購入写真と、アカウント名をメールで送らせていただきました。
質問ですが、chapter5で「results_addinfo.to_pickle('results.pickle')」を実行すると、
name 'results_addinfo' is not defined のエラーが出てしまいます。
すみませんがご教授をよろしくお願いいたします。
書籍購入画面とメールを送りましたので,確認とGithubへの招待お願いいたします.
書籍購入画面とメールを送りましたので,確認とGithubへの招待お願いいたします.
昨日、書籍購入画面とメールを送りましたので,確認とGithubへの招待お願いいたします.
書籍購入画面とメールを送りましたので、確認とGithubへの招待お願いいたします
書籍購入画面とメールを送りましたので,確認とGithubへの招待お願いいたします.
書籍購入画面とメールを送りましたので,確認とGithubへの招待お願いいたします.
書籍購入画面とメールを送りましたので,確認とGithubへの招待お願いいたします.
メールを送りましたのでGithubへの招待お願いいたします
@desacme
書籍購入画面とメールを送りましたので,確認とGithubへの招待お願いいたします.
書籍購入画面とメールを送りましたので、ご確認お願いいたします。
書籍購入画面及びGithubアカウント名記載のメールを送付いたしました。
ご確認と招待をお願いいたします。
書籍購入画面とメールを送りましたので,確認とGithubへの招待お願いいたします.
書籍購入画面とメールを送りましたので、確認とGithubへの招待お願いいたします。
書籍購入画面とメールを送りましたので,確認とGithubへの招待お願いいたします.
dijzped2@gmail.com宛てにメールを送ったのですがメールを受信できないアドレスと出てしまいました。
代わりの招待を受ける方法はありますか?
書籍購入画面とメールを送りましたので、確認とGithubへの招待お願いいたします。
書籍購入領収書画面とメールを送りましたので、確認とGithubへの招待お願いいたします。
昨日、書籍購入画面とメールを送りましたので,確認とGithubへの招待お願いいたします
書籍購入画面とメールを送りましたので、確認とGithubへの招待お願いいたします。
書籍購入領収書画面とメールを送りましたので、確認とGithubへの招待お願いいたします。
昨日、書籍購入画面とメールをお送りしましたので、確認とGithubへの招待お願いいたします。
書籍購入画面とメールを送りましたので、確認とGithubへの招待お願いいたします。
先ほど、書籍購入領収書とメールを送りましたので、確認とGithubへの招待お願いいたします。
本日、書籍購入の領収書のメールをお送りいたしましたので
お手数ですがご確認とGithubへの招待をお願いいたします。
本日、書籍購入の領収書のスクショを添付した招待依頼のメールをお送り致しました。
ご確認とGithubへの招待をお願いいたします。
2023年3月16日 午前0:22に書籍購入の領収書のメールをお送りいたしましたので、
お手数ですがご確認とGithubへの招待をお願いいたします。
2023年3月18日 午前7:58にメールをお送りいたしましたので、
お手数ですがご確認とGithubへの招待をお願いいたします。
返信
書籍購入領収書画面とメールを送りましたので、確認とGithubへの招待お願いいたします。
はじめまして。書籍購入画面とメールをお送りさせていただきました。お手数ですが、ご確認とGithubへの招待お願いいたします。
書籍の購入しました。
お手数ですが、Gitの招待をお願いします。
2023年4月9日 14:58に書籍購入の領収書のメールをお送りいたしましたので、
お手数ですがご確認とGithubへの招待をお願いいたします。
2023年4月11日 13:55に書籍購入の領収書のメールをお送りいたしましたので、
お手数ですがご確認とGithubへの招待をお願いいたします。
2023年4月12日 21:06に書籍購入の領収書のメールをお送りいたしましたので、
お手数ですがご確認とGithubへの招待をお願いいたします。
2023年4月11日23:11にメールをお送りいたしましたので、
お手数ですがご確認とGithubへの招待をお願いいたします。
2023年4月15日 16:29に書籍購入の領収書のメールをお送りいたしましたので、
お手数ですがご確認とGithubへの招待をお願いいたします。
2023/04/16 20:19に書籍購入の領収書のメールをお送りいたしましたので、
お手数ですがご確認とGithubへの招待をお願いいたします。
本日、書籍購入の領収書のメールをお送りいたしましたので、
お手数ですがご確認とGithubへの招待をお願いいたします
本日、書籍購入の領収書のメールをお送りいたしましたので、
お手数ですがご確認とGithubへの招待をお願いいたします
先日、書籍購入の領収書のメールをお送りいたしましたので、
お手数ですがご確認とGithubへの招待をお願いいたします
4月26日書籍購入の領収書のメールをお送りさせていただきました。
お手数をおかけしますが、ご確認、Githubへの招待をどうぞよろしくお願いいたします。
2023/4/28 17:32に書籍購入の領収書のメールをお送りいたしましたので、
お手数ですがご確認とGithubへの招待をお願いいたします。
2023/05/02に書籍購入領収書とメールを送りましたので、確認とGithubへの招待お願いいたします。
2023/05/02に書籍購入領収書とメールを送りましたので、確認とGithubへの招待お願いいたします。
2023/05/02に書籍購入領収書とメールを送りましたので、確認とGithubへの招待お願いいたします。
2023/05/04に書籍購入領収書とメールを送りましたので、確認とGithubへの招待お願いいたします。
参加できました。ご対応ありがとうございます
2023/05/05に書籍購入領収書とメールを送りましたので、確認とGithubへの招待お願いいたします。
2023/05/05に書籍購入領収書のメールを送りましたので、確認とGithubへの招待お願いいたします。
5月6日9時30分に書籍購入の領収書スクショを添付しメールを送らせていただきました。
お忙しいところ申し訳ありませんが、招待いただけますと嬉しいです。
何卒宜しくお願いします!
先ほど書籍購入領収書とメールを送りましたので、確認とGithubへの招待お願いいたします。
5月10日23時38分に書籍購入の領収書スクショを添付しメールを送らせていただきました。
お忙しいところ申し訳ありませんが、メールの確認とGithubへの招待お願いいたします。
先ほど(5月20日19時20分)に書籍購入の領収書スクショを添付しメールを送らせていただきました。
お忙しいところ申し訳ありませんが、メールの確認とGithubへの招待お願いいたします。
無事参加できました!招待いただきありがとうございます!!
昨日(5/24 22:33)に書籍購入の領収書スクショを添付したメールを送らせていただきました。
お忙しいところ申し訳ありませんが、メールの確認とGithubへの招待お願いいたします。
メールはご確認いただけていますでしょうか。
お忙しいところ大変恐縮ですが、どうぞよろしくお願いいたします。
5月25日21時10分頃メールを送らせていただきました。
購入の証明として領収書を転送しております
お忙しいところ申し訳ありませんが、メールの確認とGithubへの招待お願いいたします。
6月13日21時56分頃、書籍購入のスクリーンショットを添付したメールを送らせていただきました。
お忙しいところ申し訳ありませんが、メールの確認とGithubへの招待お願い致します。
6月17日14時58分頃、書籍購入の領収書を添付したメールを送りました。
お忙しいところ申し訳ありませんが、メールの確認とGithubへの招待お願い致します。
確認致しました。お忙しい中、Githubへ招待いただきありがとうございます。
2023年6月21日 13:30頃に書籍購入の領収書のメールをお送りいたしましたので、
お手数ですがご確認とGithubへの招待をお願いいたします。
2023年6月27日 11:04頃に書籍購入の領収書のメールをお送りいたしましたので、
お手数ですがご確認とGithubへの招待をお願いいたします。
招待ありがとうございます。
迅速な対応に感謝いたします。
2023年7月2日 0:30頃に書籍購入の領収書のメールをお送りいたしましたので、
お手数ですがご確認とGithubへの招待をお願いいたします。
よろしくお願いいたします。
7月2日12時43分に書籍購入のスクショを添付しメールを送らせていただきました。
お忙しいところ申し訳ありませんが、メールの確認とGithubへの招待お願いいたします。
お世話になります。
7月9日(日) 15:01頃、Github招待についてのメールを送付させて頂きました。
お手隙の際、ご確認のほどよろしくお願いいたします。
7月14日(金)23:30に、書籍購入の領収書を添付したメールを送りました。
お忙しいところ申し訳ありませんが、メールの確認とGithubへの招待お願いいたします。
7月19日 0時14分に書籍購入のスクショを添付しメールを送らせていただきました。
お手数ですが、ご確認とGithubへの招待をお願いいたします。
7月19日 17:42に書籍購入の領収書を添付してメールを送りました。
お忙しいところ大変恐れ入りますが、ご確認とGithubへの招待をお願い致します。
2023年7月25日 16:37頃に書籍購入の領収書のメールをお送りいたしましたので、
お手数ですがご確認とGithubへの招待をお願いいたします。
7/25 15:05に書籍購入の領収書を添付の上、メールを送信させていただきました。
お手数ですがご確認とGitHubへの招待をお願いいたします。
7月29日(土) 8:55に書籍購入の領収書を添付の上、メールを送信させていただきました。
お手数ですがご確認とGitHubへの招待をお願いいたします。
書籍購入の領収書を添付の上、メールを送信させていただきました。
お手数ですがご確認とGitHubへの招待をお願いいたします。
2023年8月6日 19:27頃に書籍購入の領収書のメールをお送りいたしましたので、
お手数ですがご確認とGithubへの招待をお願いいたします。
8月16日 18:50に書籍購入の領収書を添付してメールを送りました。
お忙しいところ大変恐れ入りますが、ご確認とGithubへの招待をお願い致します。
8月16日 21:10頃に書籍購入の領収書を添付してメールを送りました。
お忙しいところ大変恐れ入りますが、ご確認とGithubへの招待をお願い致します。
9月10日 8:50頃に書籍購入の領収書を添付してメールを送りました。
お手数ですがご確認とGithubへの正体をお願い致します。
9月10日 14時ごろに書籍購入の領収書を添付してメールを送りました。
お手数ですがご確認とGitHubコミュニティへの招待をお願い致します。
keibaAI-v2-2-mainのソースをダウンロードし、main.ipynbに従い動かしてみています。途中まで順調に動きましたが、「6.2. 前日全レース予想」で、「ValueError: Number of features of the model must match the input. Model n_features_ is 272 and input n_features is 273」とエラーが出ました。
学習時のデータ「'data/tmp/featured_data_20220626.pickle'」と、この予想時のデータ「X」のカラムを比較したところ、「'owner_id'」のカラムの位置がちがうことと、前者に「'rank'と'date'」がの2つカラム数が多く、275と273(前者と後者)になっていることが、目につきました。
どこで、どう対処すべきか、お教えくださる方が’いらっしゃったら、幸いです。
9月30日 17時ごろに書籍購入の領収書を添付してメールを送りました。
お手数ですがご確認とGitHubコミュニティへの招待をお願い致します。
書籍購入の領収書を添付の上、メールを送信させていただきました。
お手数ですがご確認とGitHubへの招待をお願いいたします。
keibaAI-v2-2とkeibaAI-v3の違いはなんでしょうか。
書籍購入の領収書を添付の上、メールを送信させていただきました。
お手数ですがご確認とGitHubへの招待をお願いいたします。
10月14日(土) 22:45 ごろに、書籍購入のスクリーンショットを添付の上、メール送信いたしました。お手数おかけしますが、お手隙の際にご確認と招待をお願いいたします。
2023/10/12 23:45頃に書籍購入の領収書のメールをお送りいたしましたので、
お手数ですがご確認とGithubへの招待をお願いいたします。
2023/10/24 0:40頃に書籍購入の領収書のメールをお送りいたしましたので、
お手数ですがご確認とGithubへの招待をお願いいたします。
2023/10/27 17:45頃に書籍購入の領収書のメールをお送りいたしましたので、
お手数ですがご確認とGithubへの招待をお願いいたします。
2023/10/27 23:16頃に書籍購入の領収書のメールをお送りいたしましたので、
お手数ですがご確認とGithubへの招待をお願いいたします。
先日、書籍購入の領収書のスクリーンショットをメールにてお送りさせていただきました。
お手数おかけして申し訳ありませんがご確認のほど、よろしくお願いいたします。
11月4日(土)19:42 頃に書籍購入の領収書のメールをお送りいたしましたので、
お手数ですがご確認とGithubへの招待をお願いいたします。
招待いただきありがとうございました!
昨日、書籍購入画面とメールをお送りいたしましたので,お手数ですがご確認とGithubへの招待をお願いいたします。
11月23日(木)20:13頃と11月24(金)21:27頃に書籍購入の画面のメールをお送りいたしましたので、
お手数ですがご確認とGithubへの招待をお願いいたします。
ご招待いただきありがとうございました。
11月29日(水)14:47 頃に書籍購入の領収書のメールをお送りいたしましたので、
お手数ですがご確認とGithubへの招待をお願いいたします。
11月28日(火) 17:08頃に書籍購入の領収書のメールをお送りいたしましたので、
お手数ですがご確認とGithubへの招待をお願いいたします。
11月29日(火) 14:57頃に書籍購入の領収書画面のスクリーンショットをメールでお送りいたしましたので、
お手数ですがご確認とGithubへの招待をお願いいたします。
ご招待いただきありがとうございました。
12月1日(金) 11:00頃に書籍購入の領収書のスクリーンショットをメールでお送りいたしました。
お手数ですがご確認とGithubへの招待をよろしくお願いいたします。
12月10日(金) 12:30頃に書籍購入の領収書のスクリーンショットをメールでお送りいたしました。
お手数ですがご確認とGithubへの招待をよろしくお願いいたします。
12月17日(日) 16:56頃に書籍購入の領収書画面のスクリーンショットをメールでお送りいたしましたので、
お手数ですがご確認とGithubへの招待をお願いいたします。
12/21頃に書籍購入の領収書画面のスクリーンショットをメールでお送りいたしました。
お手数ですがご確認とGithubへの招待をよろしくお願いします。
12/26 15時頃に書籍購入の領収書画面のスクリーンショットをメールでお送りいたしました。
お手数ですがご確認とGithubへの招待をよろしくお願いします。
1/5 19時33分に書籍購入の領収書画面のスクリーンショットをメールでお送りいたしました。
お手数ですがご確認とGithubへの招待をよろしくお願いします。
1/6 22時02分に書籍購入の領収書画面のスクリーンショットをメールで送らせていただいた者です。
お手数ですがご確認とGithubへの招待をよろしくお願いします。
1/9 14:31分に書籍購入の領収書画面のスクリーンショットをメールで送らせていただきました。
お手数ですがご確認とGithubへの招待をよろしくお願いします。
1/10 23時24分に書籍購入の領収書画面のスクリーンショットをメールで送らせていただいた者です。
お手数ですがご確認とGithubへの招待をよろしくお願いします。
1月14日(土) 21:40 ごろに、書籍購入のスクリーンショットを添付の上、メール送信いたしました。お手数おかけしますが、お手隙の際にご確認と招待をお願いいたします。
1/15 1:04 頃に書籍購入の領収書画面のスクリーンショットをメールで送らせていただいた者です。
お手数ですがご確認とGithubへの招待をよろしくお願いします。
1月28日(日) 21:00 ごろに、領収書画面のスクリーンショットを添付の上、メール送信いたしました。
お手数おかけしますが、お手隙の際にご確認とGithubへの招待をお願いいたします。
2月18日(日)21:45に領収書画面のスクリーンショットを添付の上、メール送信致しました。
お手隙でご確認とGitHubへの招待をお願い申し上げます。
2月26日(月)18:33に領収書画面のスクリーンショットを添付の上、メール送信致しました。
ご確認とGitHubへの招待をお願いします。
2/24(土)11:28 に領収書画面のスクリーンショットを添付の上、メールを送信いたしました。お手数おかけしますが、ご確認とGitHubへの招待をよろしくお願いいたします。
ご招待いただき、ありがとうございました。
2月27日(火) 16:24 に領収書画面のスクリーンショットを添付して、メールを送信いたしました。
お手数をおかけいたしますが、ご確認とGitHubへの招待をよろしくお願いいたします。
2月23日(金) 19:17 に領収書画面のスクリーンショットを添付して、メールを送信いたしました。
お手数をおかけいたしますが、ご確認とGitHubへの招待をよろしくお願いいたします。
3月16日(土) 22:51に領収書画面のスクリーンショットを添付して、メールを送信いたしました。
お手数をおかけいたしますが、ご確認とGitHubへの招待をよろしくお願いいたします。
ご招待ありがとうございいます!勉強させていただきます!
3月18日(月) 15:04に領収書画面のスクリーンショットを添付して、メールを送信いたしました。
お忙しいところ恐縮ですが、ご確認の上GitHubへの招待をよろしくお願いいたします。
3月23日(土) に領収書画面のスクリーンショットを添付して、メールを送信いたしました。
お忙しいところ恐縮ですが、ご確認の上GitHubへの招待をよろしくお願いいたします。
4月14日(日) 22:01に領収書画面のスクリーンショットを添付して、メールを送信いたしました。
お忙しいところ恐縮ですが、ご確認の上GitHubへの招待をよろしくお願いいたします。
5月4日に書籍購入の領収書画面のスクリーンショットをメールでお送りいたしましたので、
お手数ですがご確認とGithubへの招待をお願いいたします。
youtubeにリメイク版がupされているのを拝見しました。リメイク内容ですが、zennにも反映されてるのでしょうか?どこが変わったか、before/afterが分からずでして。。。
5月8日21:16に書籍購入の領収書画面のスクリーンショットをメールでお送りいたしましたので、
お手数ですがご確認とGithubへの招待をお願いいたします。
ご招待ありがとうございました!
お世話になります。
昨日5/8 16:50ごろに領収書のスクリーンショットとGitHubのIDを送信いたしました。
お手数おかけしますがご確認と招待のほどよろしくお願いします。
2024年5月9日(木) 23:36頃に領収書画面を添付して、メールを送信いたしました。
お忙しいところ恐縮ですが、ご確認の上GitHubへの招待をよろしくお願いいたします。
お世話になります。
5/12(日)9時ごろに領収書メールを添付したメールをお送りいたしました。
お忙しい中恐れ入りますが、ご確認の上、GitHubコミュニティへご招待いただけますでしょうか?
何卒宜しくお願い致します。
初めまして。
質問失礼いたします。
4.学習の下記のコードを実行すると後述のようなエラーが発生します。
ネット記事を検索しましたがLightgbmをインストールすると改善するというような記事がありましたが、pipでインストールしてもすでにインストールされていると出てきます。
どなたか改善方法をご教示いただけると幸いです。
keiba_ai = training.KeibaAIFactory.create(feature_enginnering.featured_data) #モデル作成
keiba_ai.train_with_tuning() #パラメータチューニングをして学習
エラー内容
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_2480\1601418309.py in <module>
----> 1 keiba_ai = training.KeibaAIFactory.create(feature_enginnering.featured_data) #モデル作成
2 keiba_ai.train_with_tuning() #パラメータチューニングをして学習
~\keibaAI-v2-2.1.1\modules\training\_keiba_ai_factory.py in create(featured_data, test_size, valid_size)
12 @staticmethod
13 def create(featured_data, test_size = 0.3, valid_size = 0.3) -> KeibaAI:
---> 14 datasets = DataSplitter(featured_data, test_size, valid_size)
15 return KeibaAI(datasets)
16
~\keibaAI-v2-2.1.1\modules\training\_data_splitter.py in __init__(self, featured_data, test_size, valid_size)
7 def __init__(self, featured_data, test_size, valid_size) -> None:
8 self.__featured_data = featured_data
----> 9 self.train_valid_test_split(test_size, valid_size)
10
11 def train_valid_test_split(self, test_size, valid_size):
~\keibaAI-v2-2.1.1\modules\training\_data_splitter.py in train_valid_test_split(self, test_size, valid_size)
17 self.__train_data, test_size=valid_size
18 )
---> 19 self.__lgb_train_optuna = lgb_o.Dataset(
20 self.__train_data_optuna.drop(['rank', 'date', ResultsCols.TANSHO_ODDS], axis=1).values,
21 self.__train_data_optuna['rank']
~\anaconda3\lib\site-packages\optuna\integration\lightgbm.py in __getattr__(self, name)
29
30 def __getattr__(self, name: str) -> Any:
---> 31 return lgb.__dict__[name]
32
33
KeyError: 'Dataset'
2024年5月27日(月) に領収書画面を添付して、メールを送信いたしました。
お忙しいところ恐縮ですが、ご確認の上GitHubへの招待をよろしくお願いいたします。
2024年5月29日(月) に領収書画面を添付して、メールを送信いたしました。
お忙しいところ恐縮ですが、ご確認の上GitHubへの招待をよろしくお願いいたします。
2024年7月1日(月) に領収書とアカウントをリクエスト用アドレスに送付しました。
ご確認お願いします。
2024年7月20日(土) に領収書とアカウントをGamilに送付しました。
ご確認とリポジトリへの招待をよろしくお願いいたします。
2024年8月16日(金) に領収書画面を添付して、メールを送信いたしました。
お忙しいところ恐縮ですが、ご確認の上GitHubへの招待をよろしくお願いいたします。
2024/09/14 1:36:03 に購入
2024/09/15 23:33 に領収書画面を添付して、メールを送信いたしました。
お忙しいところ恐縮ですが、ご確認の上GitHubへの招待をよろしくお願いいたします。
返信
ご招待ありがとうございました。(^^)
2024/09/30 に領収書画面を添付して、メールを送信いたしました。
お忙しいところ恐縮ですが、ご確認の上GitHubへの招待をよろしくお願いいたします。
2024/10/07に書籍購入の領収書画面のスクリーンショットをメールでお送りいたしました。
お忙しいところ恐縮ですが、ご確認の上GitHubへの招待をよろしくお願いいたします。
2024/10/20に書籍購入証明をメールにてお送りさせていただきました。
お忙しいところ恐縮ですが、ご確認の上GitHubへの招待を宜しくお願いします。