【Prompt Engineering Guide】で体系的に学ぶ LLMプロンプトエンジニアリング③
概要
公開されているPrompt Engineering Guideを参考に, Prompt Engineeringのテクニックを体系的に学ぼう、という(個人的な)メモです.
このシリーズもあとはMeta Promptingを残すのみである.
こちらは, いわゆるpromptを言語で追加するHard promptingとは異なる概念である, soft Promptingの一種である.
そのMeta Promptingについて, 知識的背景も整理しながら説明していきたい.
過去の記事は以下のリンクから確認してほしい.
忙しい人向け
(*)本記事の内容をChat GPTにより整理しました.
| 手法名 | 分類 | 特徴 | 代表論文・出典 | 備考 |
|---|---|---|---|---|
| Hard Prompting | Hard Prompt | 人手で設計したテキストプロンプトを直接使用 | 多数の既存研究、GPT-3 論文など | 実装が簡単だが非最適な場合が多い |
| Soft Prompting | Soft Prompt | 学習可能な埋め込みベクトル(数値)をプロンプトとして使用 | 読めない・編集不可、解釈性が低いが効果的 | |
| Prefix Tuning | Soft Prompt | 埋め込みをモデルの入力層に追加(全層に影響) | Li & Liang (2021) “Prefix-Tuning: Optimizing Continuous Prompts for Generation” | テキスト生成タスクに強みあり |
| Prompt Tuning | Soft Prompt | 埋め込みを入力のみに付加、Transformer層は固定 | Lester et al. (2021) "The Power of Scale for Parameter-Efficient Prompt Tuning" | モデル出力への影響範囲は小さいが、高速で効率的 |
| AutoPrompt | Hard Prompt | 勾配ベースで離散トークン列を最適化 | Shin et al. (2020) “AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts” | softでもhardでもない中間的手法(離散トークン) |
| Meta Prompting (MAML) | Soft Prompt + Meta | タスク一般化のためのメタ学習;複数タスクでプロンプトの初期値を最適化 | Zhu et al. (2023) “Meta-Prompting: Learning to Learn Better Prompts” (arXiv:2209.11486) | 未見タスクにも数ステップで迅速適応、MAMLの枠組みを利用 |
Meta Promptingに至るまでの知識的背景
プロンプトも自動で作る流れへ
本シリーズ1回目の記事では, 主にLLMから良い回答を得るために, 人手で良いプロンプトを設計しようというテクニックを紹介した. 例えば, いくつかの例示をプロンプトに取り込むもの(Few-shot Prompting)や, 考え方の推論プロセス自体をプロンプトに取り込むこと(Chaings-of-thought Prompting)もあった.
事前学習済みのLLM(pre-traind/fronzen LLM)であっても, プロンプトを変えるだけで, さまざまなタスクに同じモデルを適用できる可能性がわかった.
自然言語であるプロンプトをLLMに入力するだけで,望ましい回答を得られるということがわかってきた一方で, そのLLMに入力するプロンプトの設計に課題がでてきた.
あとで紹介するAutoPromptの論文では以下のように課題をあげている.
しかしながら, 不幸にもプロンプト術には, 人手によって言語モデルへ文章を入力しなければいけない. この作業は時間を多く要し, 決して直感的にできるものでない. もっと重要なことに, 言語モデルは,そのプロンプトに対してかなり感度が高い.不適切なプロンプトは, モデルのパフォーマンスを下げてしまう.
真面目にプロンプトを設計するには, タスクや, さらには使用する言語モデルに合わせて文章を考えなければいけないという手間がかかる.
本シリーズ1回目の記事で紹介した, Automatic Prompt Engineer (APE)は, プロンプト自体を自動で作ってしまおう, というモチベーションによる手法であった.
そして, 使用する言語モデルやタスクに依存しない汎用的なプロンプトの重要性というものが高まっている.
AutoPrompt
特に, 使用する言語モデルの能力を最大限活かすためには, その言語モデルの内部知識(いわば, 処理の具合)をよく把握しなければいけない.
この手の言語モデルの内部知識を探索する試みは, 浅層プローブ (shallow classfier)や注意重み可視化(Attention visualization) といったアプローチで取り組まれてきた.しかし, 誤検出(false positive)や因果性の誤解につながる懸念があった.
言語モデルの知識を引き出す直接的な方法としては, promptingがある. つまり, 言語モデルに色々質問(Input)してみて, 回答(output)を集めれば, 言語モデルの知識を引き出せるのでは?という方法である. もちろん, 適当なプロンプトを打ち込んでも意味がない.
AutoPromptは, 言語モデルに追加パラメータや微調整を加えることなく、使用する言語モデルのタスク性能を引き出せるようなプロンプトを自動で作成する手法である.
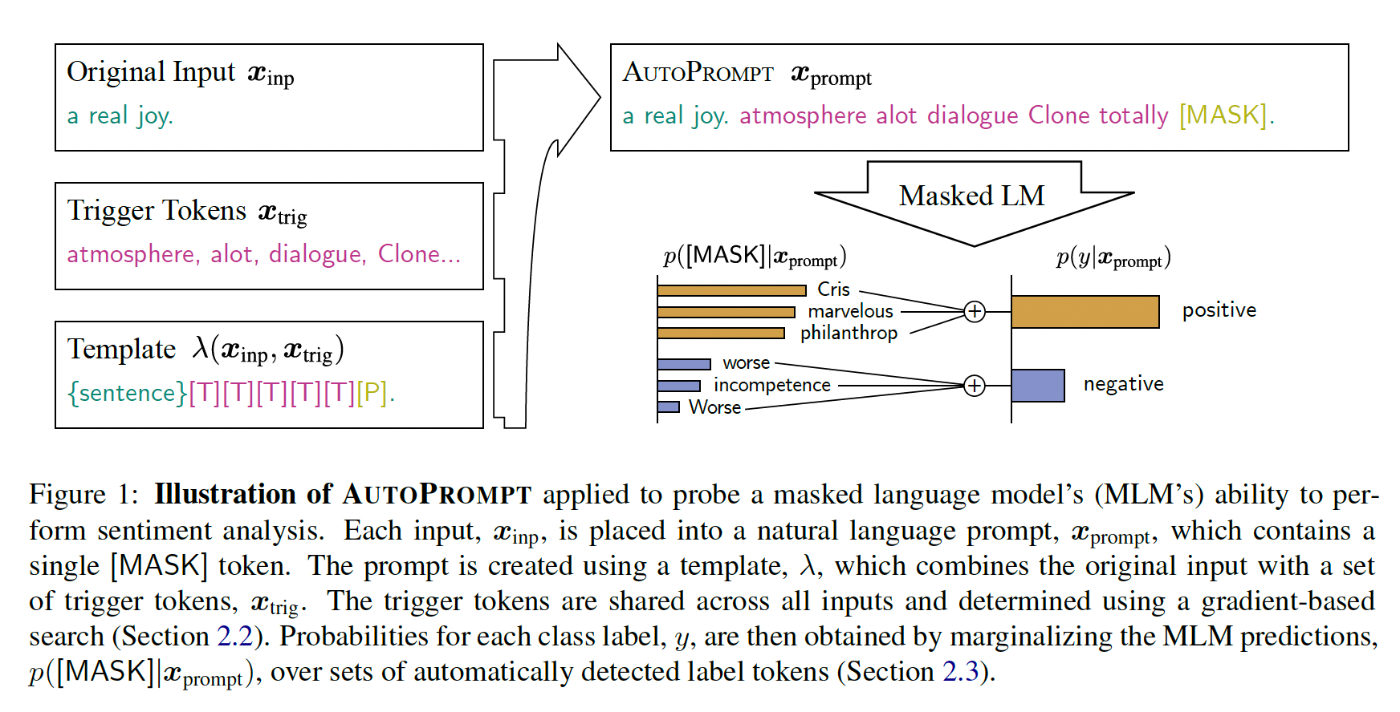
図にあるように, AutoPromptは, マスク位置([MASK])へのトリガーワード列(Trigger Tokens) を自動生成し, タスクに有効なプロンプトを発見するメソッドである. このtrigger TokensはすべてのInputに共通である.
trigger Tokensにどんな文字を埋め込めば, 良い回答を得られるだろうか?というのを, 探索していくこととなる. ここでは, InputとOutputの対数尤度確率を, 勾配
誘導探索(gradient-guided search の略) により最適化するようにトークンを選択していく.[1]
Auto Prompは, プロンプトは「パラメータなし」でタスク指示を与える手段であるが, Trigger Tokensを使用する言語モデルに合わせて最適化することで, MLM(Masked LM)の内部知識を強力に活性化でき, 結果的に良い回答を得ることができる.
プロンプトもモデルに組み込んでしまう
さて, APEやAutopromptにより, 言語モデルに適したプロンプトを自動で生成する手法が提案されてきた. これらプロンプトを自然言語として人にも理解できる形で作ることをHard Promptingと呼ぶ. ChatGPTに対し, "今日の天気は?”みたいな文章をいれることは, もれなくHard Promptingの一種である.
Hard Promptingでもうまく設計できればよい回答をLLMから手に入れられることがわかっている. しかし, さらに上を目指すテクニックがある. それが, soft Promptingである.
ソフトプロンプトは, プロンプトチューニングの過程で作成される.
ハードプロンプトとは異なり, ソフトプロンプトはテキストとして表示・編集することができない.
プロンプトは埋め込み(数値の列)として構成されており, そこから大規模モデルの知識を引き出す.
そのため, 明らかな欠点として, ソフトプロンプトには解釈性がないという点が挙げられる. AIは特定のタスクに関連するプロンプトを自動的に見つけ出すが, それらの埋め込みをなぜ選んだのかを説明することはできない. 深層学習モデルと同様に, ソフトプロンプトもブラックボックス的である.
Prefix Tuning
さて, Soft Promptingの手法として有名なのは, Li et al, 2021により提案された Prefix Tuningである.
手法を要約すると,
Prefix Tuningは, 大規模LMのパラメータを固定したまま, 少量のprefixパラメータのみでタスク対応が可能な技術である. ファインチューニングと同等以上の生成性能, さらにストレージ効率・汎化性能・少量データへの強さも兼ね備えており, ライトな生成タスク適応手法として非常に有望である.
これも, 言語モデルが最適な回答を生成できるように,新たに付け加えたTokenを自動で学習させるというものだ.
しかし, Auto Promptと異なり, Prefix Tuningでは, このTokenはモデルそのものに埋め込まれる.
そして, Auto PromptのTokensが離散記号(単語)であったのに対し, Prefix TuningのTokensは連続値であるため, より豊かな表現力をTokensに埋め込むことができる.
そもそもの研究の動機は, さまざまな言語タスクに対し, 計算コストの高いfine-tuningをせずとも, もっと軽い(light weighted)な調整で済むようにしたい!というものだ.
そのヒントにprompting (Hard Prompting) があった, と述べている. つまり, 入力を少し変えるだけで, 同じモデルを別のタスクにも応用できるという簡便さである.

提案手法では, Prefix(Auto promptでのTokens)を入力(と出力)の前につけることで, モデル本体(Transformer)のパラメータは凍結(Freeze)しなあがらも, タスクごとの小さな連続ベクトル列(prefix)のみを学習できるように工夫している.
このprefixはTransformerの全レイヤーにそれぞれ対応し, 仮想トークンのように動作する. そして, モデルは次のトークン生成時にこのprefixを参照することで, いろいろなタスクに対応した出力をだせるようになる.
わざわざfine-tuningをせずとも, ベースとなる言語モデル(LM)を共通利用し, タスク毎にこのprefixのみを差し替えるだけで対応可能,というお手軽さが売りである.
実際, パラメータは約0.1%のみを更新しながら, タスク性能を達成している.
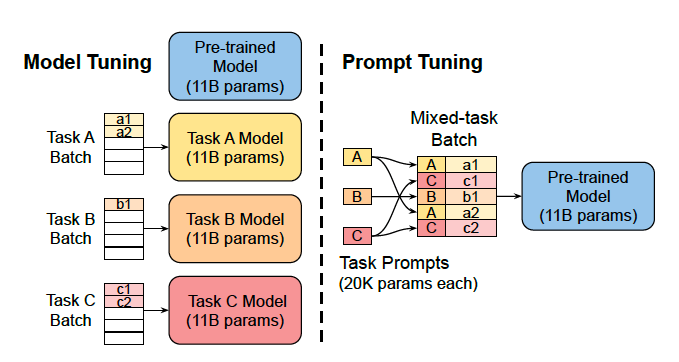
Prompt Tuning
Soft Promptingの手法としてもう一つ紹介しておこう.
Lester et al, 2021に提案されたPrompt Tuningである.
研究の動機の方向性について, さきほどPrefix Tuningと似ている.
Prompt Tuning と Prefix Tuning はどちらも "大規模言語モデル(LLM)の重みを一切更新せずに新しいタスクに適応させるためのパラメータ効率の良い微調整法(Parameter-Efficient Fine-Tuning, PEFT)" である.
しかし, Token列を, 内部でどこに加えているのか, 何をどう操作しているかに違いがある.
一言でいえば,
- Prefix Tuningでは, モデル内の各層に**prefix (Token列)**を配置
- Prompt Tuningでは, モデルの最初, つまり, 入力埋め込み層のみにToken列を配置
それゆえ, Prompt Tuningでは, 学習対象のToken列が限定的なのでとても効率的である.しかし, その分, モデルの各層にToken列を埋め込むPrefix Tuningよりは精度が落ちる可能性はある.
以下に簡単な比較表を載せておく(ChatGPTにより整理😇)
| 比較項目 | Prompt Tuning | Prefix Tuning |
|---|---|---|
| 導入位置 | 入力トークンの前にsoft promptを追加 | 各層のキー・バリュー(KV)にprefixベクトルを追加 |
| 変更するパラメータ | 入力埋め込みのみに対応するsoft prompt | 各層のTransformerブロックに渡すprefixベクトル |
| モデル本体 | 完全に凍結 | 完全に凍結 |
| 実装難易度 | 比較的簡単(embeddingの前処理だけ) | 中程度(各層にフックを入れる必要) |
| 計算コスト | 低い | やや高い(全層にprefixが加わる) |
| 性能(一般的傾向) | 小型モデルでは劣るが、大型モデルで強い | 一般にPrompt Tuningより安定した性能 |
| モデルサイズ | おすすめ手法 | 理由 |
|---|---|---|
| 小〜中規模(<1B) | Prefix Tuning | Prompt Tuningだと性能が安定しない傾向がある |
| 大規模(>1B、特に>10B) | Prompt Tuning | モデル自体の言語知識が強力なので、浅いsoft promptで十分 |
| 高性能+低ストレージ | Prompt Tuning | soft promptだけでOK、軽量(数KB) |
| 安定性・少データ耐性 | Prefix Tuning | 深い層にも介入しているため、汎化性能が高い |
モデル全体を再学習せずとも, 別途用意したToken列を調整するだけで済む, という手法は実務的にもニーズがありそうだ. 以下, Fine TuningとSoft Prompting(Prompt Tuning), Hard Prompting(Prompt Design)の比較図を置いておく(以下のブログより参照)

提案者のGoogle研究者のブログも参考にしてほしい
ここまでのまとめ
| 手法 | タイプ | プロンプト形式 | 解釈可能性 | モデル更新 | 特徴 |
|---|---|---|---|---|---|
| Fine‑Tuning | N/A | モデル全体のパラメータ更新 | — | ✅ 本体も更新 | 高性能だがコスト大 |
| Manual Prompting | Hard | 自然言語文字列 | ✅ 高い | ❌ なし | 手動設計が必要 |
| AutoPrompt (Shin et al., 2020) | Hard | 語彙トークンからなる文字列 | ✅ 高い | ❌ なし | 自動生成だが可視化可能 |
| Prefix‑Tuning (Li & Liang, 2021) | Soft | 各層前に注入される連続ベクトル | ❌ 低い | ❌ 本体は固定 | タスク特化の仮想トークンを学習 |
| Prompt Tuning (Lester et al., 2021) | Soft | 入力直前に学習埋め込みを付与 | ❌ 低い | ❌ 本体は固定 | prefix‑tuningよりシンプル・軽量 ([arXiv][1], [arXiv][2]) |
Meta Prompting
さて, 本記事最後のテクニックはMeta Promptingである.
このテクニックを説明していく前に, promptingを二つに大別してから, Meta Promptingが解決したかった問題を見ていこう.
-
ハードプロンプト(manual prompts)の限界
- manual promptsは, これまで見てきたように, LLMに与えるプロンプトに,"何らかの指示(自然言語)"を加える方法
- 固定された自然言語入力 (“The movie was [MASK]”) によるfew-shotタスクは,手動設計が高難度で, タスクごとの調整が必須
-
ソフトプロンプトの依存性
- Soft Promptでは, 事前学習済みモデルに与える入力にプロンプトを取り付け, プロンプトをパラメータとして学習させることで, 個別のタスクに対するモデルの精度の向上を目指す(自然言語として渡さないことが前者との違い)
- ソフトプロンプト"(連続ベクトルをプロンプトとして付与)は性能向上が期待できるが, その初期化方法に強く依存し, 良い初期値設定なしでは微調整がうまくいかない
- 現在の手法では, 各タスクの内的構造を深く理解し,タスクごとの初期化を手動で設計する必要あり, これが実用性や拡張性を阻害している
Meta Promptingは後者のソフトプロンプトの依存性に対処する手法で, 初期依存やタスク特化に設計されてきたsoft promptの一般的な手法として提案された.
つまり, Meta Promptingは, こうしたsoft promptの「初期化問題」を解決すべく提案された.
具体的には, MAML(モデル非依存メタ学習) を用い, 複数ドメインにまたがるメタタスクから, 学習すべき初期プロンプトパラメータ(φ_meta) を獲得する.
そして, 新タスクでは, この共通初期値をスタートポイントとして, few-shotのみで安定かつ高精度に学習できるようになった.

図に, Meta promptingの処理イメージを載せている(論文より引用)
手順を簡単に説明する:
soft promptのトークン埋め込め表現列を
-
メタタスクのサンプリング
- タスク集合から 複数のタスク(例:
T_{1}, T_{2}, ..., T_{n}
- タスク集合から 複数のタスク(例:
-
各タスクについて内側の更新(Inner Loop)
- 各タスク
T_{i} \theta T_{i}
- 各タスク
-
- これは、プロンプトパラメータ
\theta T_{i} \theta^{'}_{i}
- これは、プロンプトパラメータ
-
メタ更新(Outer Loop)
- 各タスクのテストセット(query set)において、上記で得られた
\theta^{'}_{i}
- 各タスクのテストセット(query set)において、上記で得られた
-
- すべてのタスクに対して平均損失をとり、元の θ を更新:
最終的な狙いが, 各タスクに汎用的かつ安定した学習ができるToken列の獲得, である.
そのため, 上記手順1.では,まず各タスクにあったToken列を個別に作っていきながら, 手順3. でタスク横断的に効果のあるToken列を作っている,という処理イメージである.
まとめ
さて,今回は公開されているPrompt Engineering Guideを参考に,最後に残されたMeta Promptingを説明した.
また, Meta Promptingが代表とするsoft promptingの他手法にも触れた.
今回の内容は, 本家Prompt Engineering Guideにもちゃんとした情報が載っていない内容である. ぜひ何かの参考になれば幸いである.
参考文献
Soft Promptに関する日本語記事
Soft Promptのうち, Prompt Tuning や Prefix Tuningを説明している
-
ここの要素が, APEに似ていると思った ↩︎
Discussion