はじめに
株式会社Elithで先月よりインターンとして働き始めた森川です。今回は、大規模言語モデル(以下、LMM)の研修中に興味を持ったパラメータ効率の良いFine Tuning手法(Parameter-Efficient Fine Tuning、 PEFT)について、サーベイを行いました。本記事は、「小さい計算コストでスマートにLLMをチューニング!-Hugging Face PEFT入門」の後編にあたります。前編は、こちらをご覧ください。
本記事で使用する図は、参考文献から引用されています。
Soft Prompt型
2つ目の型は、Soft Prompt型です。
Soft Prompt型は、事前学習済みモデルに与える入力にプロンプトを取り付け、プロンプトをパラメータとして学習させることで、個別のタスクに対するモデルの精度の向上を目指しています。例えば、Prefix-Tuningでは、モデルの重みの0.1%のパラメータ数でFull FTと同等の性能向上を実現しています。
Prompt Tuning
Prompt Tuningは、下流タスクに対する精度向上を目的として、事前学習済みモデルに与えるべき、特定の下流タスクに特化したプロンプトを学習する手法です。プロンプトは、事前学習済みモデルがタスクの文脈や目的を理解するのを助けるために用いられるトークン列(下の図のA、B、C)です。下流タスクの推論時には、そのタスク固有のプロンプトを実際の入力文(以下のa1、a2、b1、c1、c2)に組み込み、プロンプトを含む入力文を事前学習済みモデルに入力します。
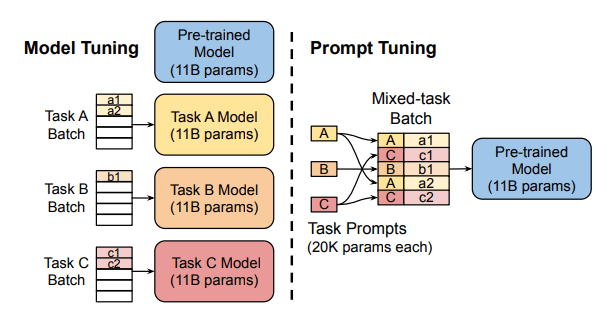
prompt tuningは、モデルのパラメータ数が多い場合(

prompt tuningの問題点として解釈可能性に欠けるという点が挙げられます。AIは各下流タスクに対して最適なプロンプトを発見するがただのトークン列であるため、なぜそのプロンプトが最適であるのか解釈することが困難となっています。
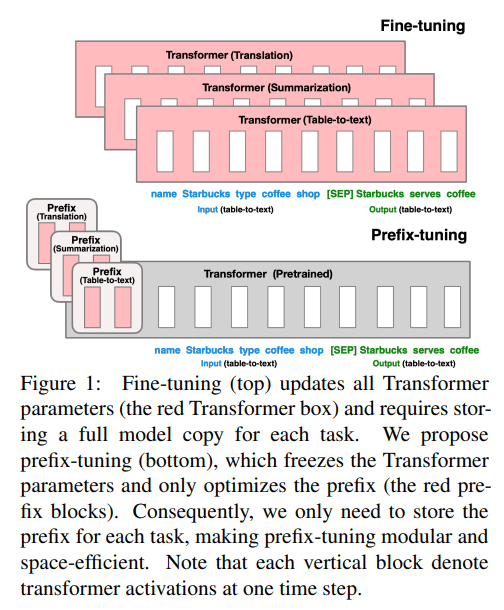
Prefix-Tuning
Prefix-Tuningは、下流タスクに対する精度の向上を図るため、事前学習済みモデルに与えるべきそのタスク固有のprefixを学習する手法です。Prefix-Tuningでは、事前学習済みモデルのそれぞれの層と層の間(以下、層間)において、前の層の出力にその層間のprefixを付加して次の層に入力として与えるようにしています。Prefix-Tuningの学習時には、事前学習済みモデルの各層間のprefixをパラメータとして学習します。
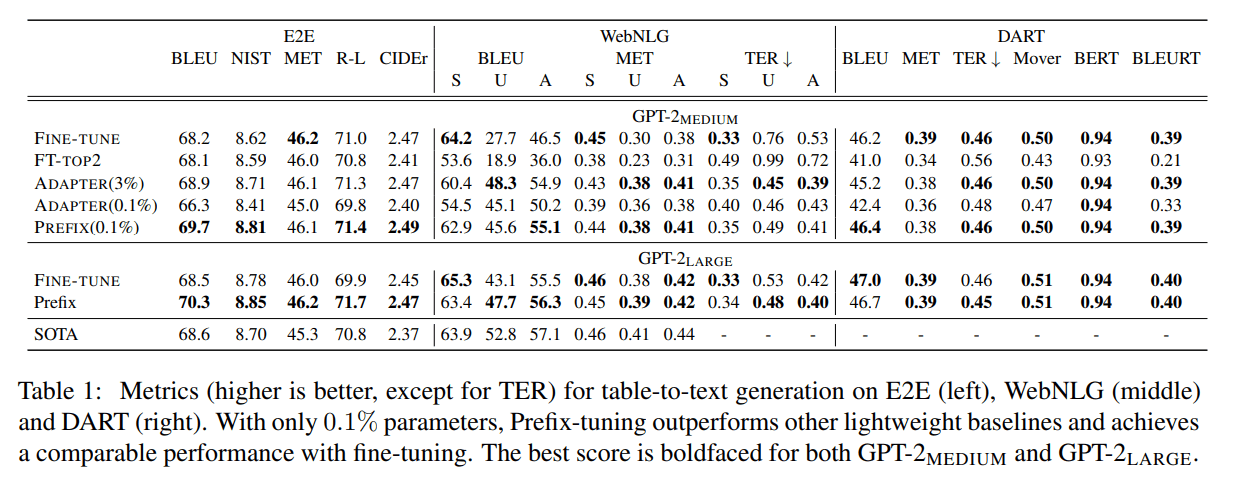
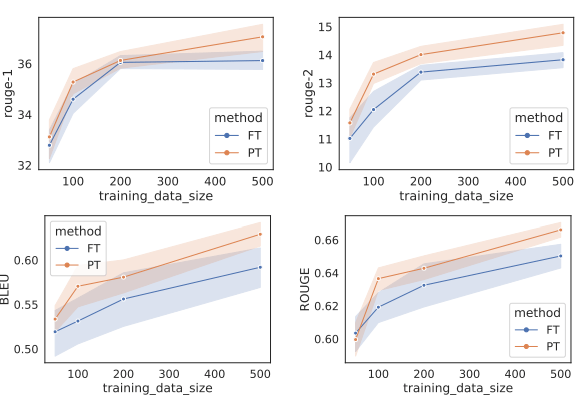
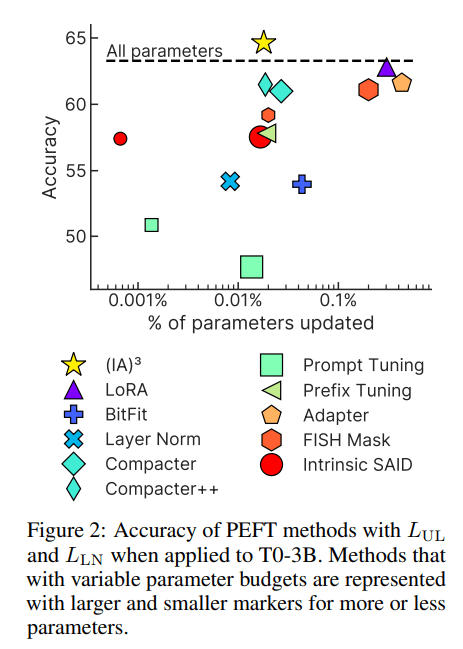
Prefix-Tuningは、表のようにテキスト生成タスクにおいてFull FTに並ぶ性能改善が可能であり、データ数が少ない場合にはグラフのようにFull FTを上回る性能を示します。グラフでは、PTはプロンプトチューニング、FTはFull FTを示しています。
調べている限りでは特に問題点はありませんでしたが、prompt-tuningと同様、解釈可能性の問題があると考えられます。
その他
Infused Adapter by Inhibiting and Amplifying Inner Activations(IA3)
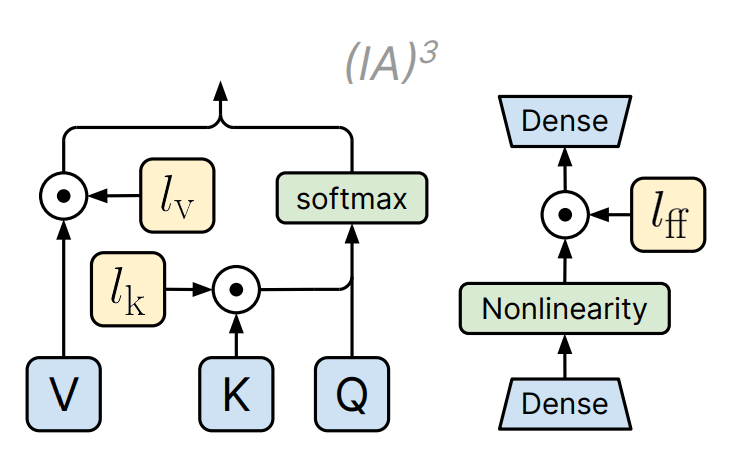
下の図のように、
新しい手法であるため、問題点は特に見つかりませんでした。しかし、個人的な所感として、
今後の展開
PEFTは現在も様々な手法が編み出されていますが、しばらくの間はLoRAが強いのではないかと感じました。
その理由としては、LoRAは事前学習済みモデルの重みに間接的ながらも変更を加えることができるため、モデルの精度が大きく改善することができる点が挙げられます。Soft-Prompt型の手法では事前学習済みモデルの重みは一貫して凍結されており、
今後LLMが社会の様々な場所で実装されるのに比例してPEFTは重要度が増す技術であると考えられるため、PEFTは今後も重要視されると考えられます。
まとめ
本記事ではHuggingfaceで使用されている主要なPEFT手法についてまとめました。PEFT自体には、LLMの研修を行う中で興味を持っていたのですが、今回深くリサーチを行い、より一層PEFT手法について理解が深まったと感じています。PEFTはLLMを実装する際に避けては通れない計算リソースの制限に対する特効薬のような手法であるため、LLMに触れている限り頻繁に使用することになると感じました。
最後に宣伝となりますが、株式会社 Elith は最先端のAI技術をビジネスに実装し、価値を生み出すテックカンパニーです。
最近ではLLMの活用に関して様々な取り組みをしており、多数のイベントにも登壇しています。
少しでも興味がある方は、X(旧Twitter)経由やElithのWebページ経由で、是非気軽にお話を聞きにきてください。
参考文献
全体
https://zenn.dev/timoneko/articles/bb108fa971e6ae
https://www.brainpad.co.jp/doors/contents/01_tech_2023-05-22-153000/
https://huggingface.co/docs/peft/conceptual_guides/adapter
https://note.com/kojiro_iizuka/n/nfc69f3fd5f32
Prompt Tuning
https://arxiv.org/pdf/2104.08691.pdf
Prefix Tuning
https://arxiv.org/pdf/2101.00190.pdf
IA3

Discussion