【LLM】ファインチューニング
ファインチューニングとは
事前トレーニングされたモデルを取得し、新しいデータを使用して新しいタスクでさらにトレーニングすること。基本的にデータはラベリングされているので教師あり学習(Supervised Learning)となる[1]。
prtraining ---> Fine-Tuning
脚注1に関して
FFT:(full-model fine-tuning/Full Parameter Fine-Tuning)
事前学習済みのモデルのパラメータも含めてフルでチューニングする。
近年は、LLMがかなり大きくなってきたため、フルパラメータチューニングはコストがかかる。
PEFT(Parameter-Efficient Fine-Tuning)
モデル全体をフリーズした状態に保ち、学習可能な小さなパラメーター/レイヤーをモデルに追加するだけで済む。パラメータの一部を学習する。
☛パラメーター効率の高い微調整をめざす。
以下の手法がある。
・LoRA
・Adapter
・Prefix-tuning
◇(LLM-Adaptersの論文)による分類
・Prompt-based learning
・Reparametrization-based method
低ランク(行列)の技術を使って、重みを変えていく手法。
☛LORA
・Series Adapter
特定のサブレイヤー内に追加の学習可能なモジュールを順次組み込む
・Parallel Adapter
追加の学習可能なモジュールを、内部の個別のサブレイヤーと並行して組み込む
バックボーンモデル。
ぶんるいの参考
(PEFT) methods:
prompt-based learning, reparametrization-based
methods, series adapters, and parallel adapters
https://arxiv.org/pdf/2304.01933.pdf
we just train a very tiny portion of the parameters. The most famous method in this category is LORA, LLaMA Adapter and Prefix-tuning.
(llama-recipes)https://github.com/facebookresearch/llama-recipes/blob/main/docs/LLM_finetuning.md
■ LORA: LOW-RANK ADAPTATION (論文日時:16 Oct 2021)
↓HFにはマージ機能も搭載してる模様
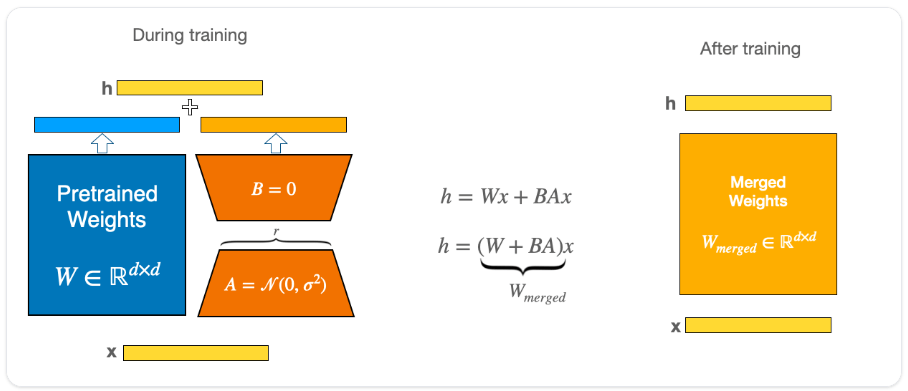
参考:https://huggingface.co/docs/peft/conceptual_guides/lora
■アダプター
参考文献
-
教師なしFinetuningも分野としてはある ↩︎
Discussion