【LLM】LoRA まとめ
原理
事前にトレーニングされたモデルの重みをすべて凍結して、追加の重みの変更をトレーニングして行列に保存する。
また高ランクの行列を低ランクの行列の組み合わせに分解する機構を活用している。
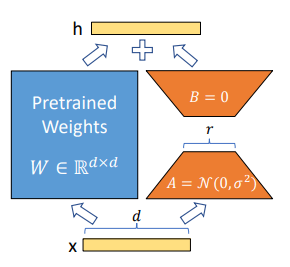
構成
W0 ☛ 事前トレーニングされた重み行列が d * d の次元を持つ。(トレーニング中はフリーズ)
重み変化行列 ∆W ☛低ランク行列AとBとしてトレーニングする。
∆W = BA
二つの低ランク行列にすることで冗長なパラメータを削減できる。
(300,300) ☛ 90000のパラメータ数
(300,2),(2,300) ☛1200のパラメータ数
上記の2は、更新行列のランクであり、LORAのハイパーパラメータとなる。
r: 更新行列のランク。 ランクが低いと、更新行列が小さくなり、トレーニング可能なパラメーターが少なくなる。
運用に関して
アダプタとの差異
アダプタ → 追加のレイヤーを加える
LoRA → 行列レベルでの適応を実装
適応できる箇所
- トランスフォーマーのアテンション層内
- Feed-Forward Network(FFN)ブロック内の全結合層
- 埋め込み層 (でも可)
どのレイヤに適用すべきなのか?
元のLoRA論文 → トランスフォーマーのアテンション層内にフォーカスを当てていた。
LoRAをFFNに適用することは効果的。
アテンションベースのLoRAはメモリ制約の中でより高い効果を発揮。
...LoRAの効果は、ベースモデルのサイズにも影響されます
...LoRAの配置に関する万能な戦略は存在しません。私たちの経験は、段階的なアプローチを推奨しています
(引用:https://arxiv.org/html/2404.05086v1#bib.bibx11)
LoRAをアテンション層のみに適用することで最も安定性が得られたとのこと。
(他のレイヤに適用する場合も効果がないわけではない。)
なので、アテンション行列にLoRAを適用→埋め込み行列→全結合(MLP)行列へとLoRAを段階的に試していくのがおすすめとのこと。(モデルの品質、トレーニング時間、および推論時のメモリ消費の間のトレードオフ)
MoE(Mixture of Experts)モデルに適用する場合
エキスパートにLoRAを個別に適用することで多くの設定でパフォーマンスが向上することがわかった。...ルータ行列にLoRAを適用した際は限定的な成功しか見られなかった。
推論で提供する方法
- LoRAの重みをベースモデルの重みとマージする方法
- メリット推論レイテンシがゼロ
- (あまり実運用では採用されない)
- 再量子化が必要になることがよくある。
- LoRAモデルを非マージ形式で提供
- 単一のベースモデルが複数のデルタLoRA重み、つまり複数のモデルと動的にペアリングできるようになる。
- 同じGPUセット上で共有エンドポイントを介して、受信リクエストを正しい基盤となるLoRAの差分の重みにルーティングする方法
LoRA+

引用:https://arxiv.org/pdf/2402.12354v1
S-LoRAに関して(スケーラブル)
S-LoRA → Serving Thousands of Concurrent LoRA Adapters
多くのLoRAアダプタをスケーラブルに提供するためのシステム

QLoRA
参考・引用
Discussion