はじめに
株式会社Elithで先月よりインターンとして働き始めた森川です。今回は、大規模言語モデル(以下、LMM)の研修中に興味を持ったパラメータ効率の良いFine Tuning手法(Parameter-Efficient Fine Tuning、 PEFT)について、サーベイを行いました。本記事では、Hugging Faceで実装されている主なPEFTを紹介し、最後に今後の展望について述べます。本記事で使用する図は、参考文献から引用されています。
Fine Tuningの必要性と問題点
Fine Tuningは各下流タスクに合わせて大規模な事前学習済みモデルの重みを微調整することです。LLMのパラメータをタスクごとに一から訓練することは計算資源や計算時間の観点で現実的ではないため、モデルの作成の際には、事前に汎用的なタスクに使用できるように学習された大規模言語モデルを使用することが一般的です。
しかし、LLMのパラメータ数が数十億に達する現在、事前学習済みモデルの全パラメータを微調整すること(以下、Full FT)はますます困難になっています。このFull FTは、訓練時に必要な計算リソースの量と、パラメータを保存するために必要なデータ容量の両方を著しく増加させます。
しかし、ファインチューニングは各々の状況に応じて個別に行うため、少ない計算リソースとメモリのサイズで行うことが望ましい状況にあります。
PEFT(Parameter-Efficient Fine Tuning)
PEFTは、前述の問題を解決するため、事前学習済みモデルのパラメータ数に比べ少数のパラメータの学習により、下流タスクに対してFull FTと同程度にモデルの性能改善を目指す手法です。PEFTは、多くの場合、事前学習済みモデルの重みを凍結して、事前学習済みモデルに追加した少数のパラメータを学習することにより行われます。例えば、LoRAでは、Full FTで訓練が必要なパラメータの数の10000分の1の数のパラメータの学習により、Full FTと同等の性能改善を達成したと報告されています。
Adapter型
Hugging Faceでは、大きく分けて2種類の型のPEFTが実装されています。
1つ目の型は、Adapter型と呼ばれる型です。Adapter型では、事前学習済みモデルの重みを凍結して新たに導入したパラメータのみを学習させることで、個別のタスクに対する精度の向上を目的としています。
LoRA(LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS)
LoRAは、重みの増分行列を低ランク行列で近似して低ランク行列のみを学習させることで、少ないパラメータ数の学習でFull FTと同等の性能改善を目指す手法です。LoRAは他手法と比べて効率が良いため、LLMにとどまらずdiffusion modelにおいても使用されます。
具体的な手法の流れは以下の通りです。事前学習済みのモデルの重みの行列を
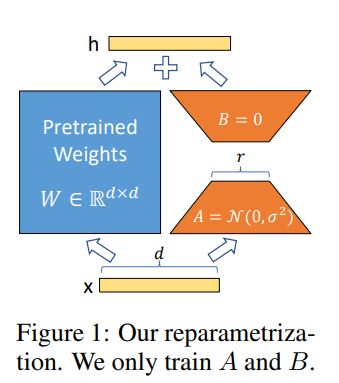
LoRAの利点は、4つあります。
1つ目は、訓練が必要なパラメータ数を大幅に削減できる点です。LoRAでは、Full FTで訓練が必要なパラメータの数の10000分の1の数のパラメータでFull FTと同等の性能改善を達成しました。
2つ目は、事前学習済みモデルと同等の計算コストで推論できるという点です。
3つめは、各下流タスクに対して、それぞれ少ないデータ容量で対応できるという点です。事前学習済みのモデルの重みはLoRAによる学習中には凍結します。そのため、各下流タスクに対して、対応する低ランク行列の重みの情報だけで対応できます。
4つ目は、Full FTよりも少ない訓練パラメータ数であるにも関わらずFull FTと同等の性能改善を図ることができる点です。下の図のように、LoRAを用いてファインチューニングしたモデルの精度は、Full FTを行ったモデルと同等の精度を達成しています。
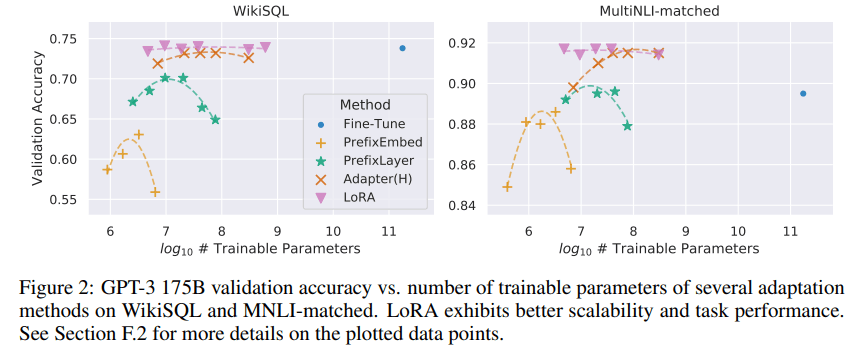
LoRAの問題点として、モデルが特定のパターンを学習する必要があるタスクに対して、その他のFine Tuning手法より精度が劣る場合があることが挙げられます。LoRAは、数学やポーカーのようなルールに基づいた思考を必要とするタスクに対するFine Tuningを苦手とする傾向にあります。
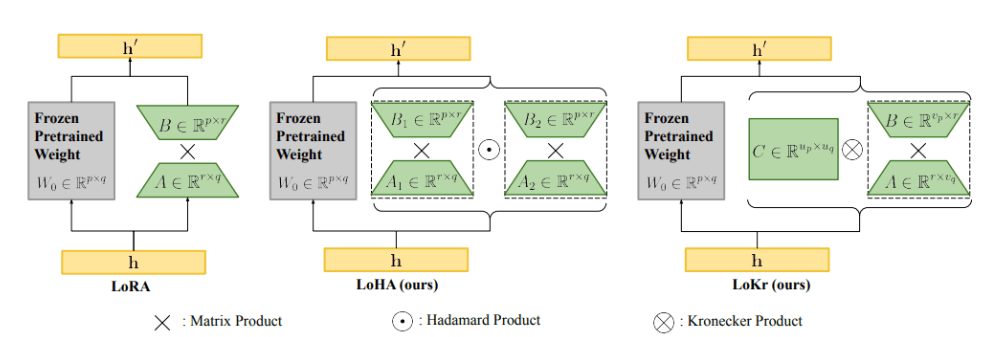
LoRAの派生手法として、LoHA、LoKr、AdaLoRAなどがHugging Faceで実装されています。LoHA、LoKr、AdaLoRAはいずれも重みの増分行列
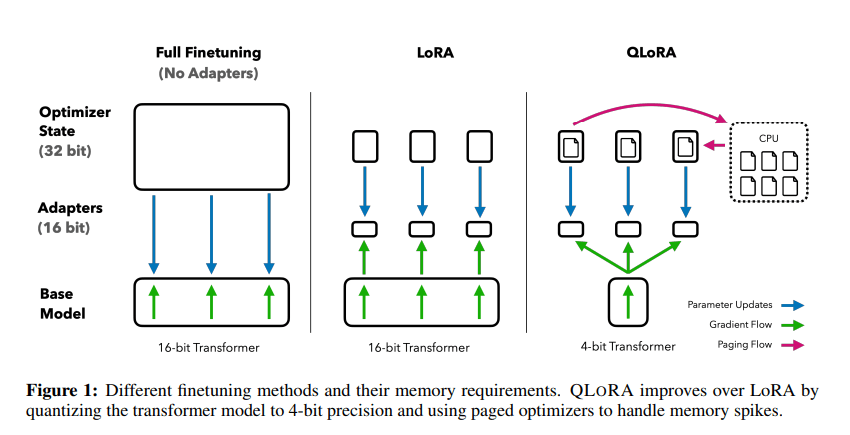
LoRAのメモリ効率を高めるため、QLoRAがHugging Faceで実装されています。QLoRAには、以下のような特徴があります。
- モデルの重みを4bitに量子化することができる量子化のためのデータ型NF4を使用している。
- モデルの重みを量子化した際の定数をさらに量子化している。(Double Quantization, DQ)
- GPUのメモリ不足を防ぐために、最適化の計算において直近での必要性が低い計算途中の値をCPU RAMに退避し、GPUのメモリを常時確保する最適化器(paged optimizer)を使用している。
その他のAdapter型の手法
LoRA以外のAdapter型の手法として、Orthogonal Finetuning(OFT)やLlama-AdapterがHugging Faceで実装されています。
Orthogonal Finetuning(OFT)は、事前学習済みモデルの画像生成タスクに対する能力を保持したまま、新しいタスクにファインチューニングする手法です。事前学習モデルの重みの行列に直行行列
Llama-Adapterは、Transformer機構の上位層のattention機構内で文脈情報と一緒にタスク固有の情報を埋め込むためのattention機構をアダプターとして追加する手法です。学習時には、アダプターとして追加したattention機構内のパラメータとそのattention機構に入力するためのプロンプト(Adaption Prompt)を学習します。LLaMA-Adapterは、70億のパラメータを持つLLaMAに120万のパラメータのファインチューニングを行うことで、LLamaに対してFull FTを行ったAlpacaと同等の性能を達成しています。
まとめ
PEFTに関する調査の前編として、今回はAdapter型について調査を行いました。後編では、Soft Prompt型を中心に調査を行う予定です。
最後に宣伝となりますが、株式会社 Elith は最先端のAI技術をビジネスに実装し、価値を生み出すテックカンパニーです。
最近ではLLMの活用に関して様々な取り組みをしており、多数のイベントにも登壇しています。
少しでも興味がある方は、X(旧Twitter)経由やElithのWebページ経由で、是非気軽にお話を聞きにきてください。
参考文献
全体
https://zenn.dev/timoneko/articles/bb108fa971e6ae
https://www.brainpad.co.jp/doors/contents/01_tech_2023-05-22-153000/
https://huggingface.co/docs/peft/conceptual_guides/adapter
https://note.com/kojiro_iizuka/n/nfc69f3fd5f32
LoRA
https://arxiv.org/pdf/2106.09685.pdf
https://zenn.dev/schwalbe10/articles/low-rank-adaptation
https://qiita.com/mshinoda88/items/fc562ec6a84f45e89e70
QLoRA
http://arxiv.org/pdf/2305.14314.pdf
https://blueqat.com/yuichiro_minato2/bb25fbe5-6c8e-4a81-854f-e46e6d7b34e3
https://reinforz.co.jp/bizmedia/13018/
Orthogonal Finetuning(OFT)
https://arxiv.org/pdf/2306.07280.pdf
LLaMA-Adapter

Discussion