【Prompt Engineering Guide】で体系的に学ぶ LLMプロンプトエンジニアリング①
概要
大規模言語モデル(LLM)を使用している際、応答性能を向上させるには以下の方法がとられる.
-
Prompt Engineering
- LLM へ与えるプロンプトを工夫する方法
- プロンプトに, 回答のヒントとなる追加データを含めたり, 参照するデータが不足している場合に, 外部ツールを呼び出してデータを追加することで回答能力を向上させる方法
- 以前の情報をヒントにして回答, 知らない情報はWeb で検索して回答...etc
-
Fine-tuning
- 新規のデータを導入してLLM 自体を再学習させ, パラメータを調整することで回答精度を向上させる方法
- GPT4に独自データを取り入れて, 新たにモデルを作成する...etc
- 新規のデータを導入してLLM 自体を再学習させ, パラメータを調整することで回答精度を向上させる方法
精度の観点では, (おそらく)Fine-tuningのほうが良いと考えられる. しかし, LLMをFine-tuningするには, 相当の計算機パワーや関連するコストがかかる. その理由から, LLM自体を改良したり, Fine-tuningをすることは, 一部の大組織を除き,手に余る作業であろう.
その点, Prompt Engineeringを用いれば, LLMを再度学習せずとも, 良い回答を生成できる可能性がある. もちろん, 良い回答を得るためのプロンプト術も研究されてきている.
今回は, 公開されているPrompt Engineering Guideを参考に, Prompt Engineeringのテクニックを体系的に学ぼう、という(個人的な)メモです.
忙しい人向け
ささっと理解したい人向けに, 今回紹介するテクニックの概要を表で整理しておく.
| テクニック名 | 特徴・概要 | 利点 | 欠点 | 利用例 | 関連文献・出典 |
|---|---|---|---|---|---|
| Zero-Shot Prompting | 例を含めず直接タスクを与える。 | プロンプトが簡潔で手軽。 | 回答の精度が低くなる場合がある。 | 一般的な質問応答や分類などシンプルなタスク | - |
| Instruct Tuning (FLAN) | 多様な指示データで事前にfine-tuningし、命令理解能力を強化。 | 汎用性の高いモデル設計が可能。 | 学習・構築コストが高い。 | 翻訳、要約、QAなど幅広いタスク | Wei et al., 2022 |
| Few-Shot Prompting | プロンプト内に例(デモ)を含め、文脈学習によりモデル性能を向上させる。 | より高精度な応答が期待できる。 | 適切な例を用意する必要があり、プロンプトが長くなる。 | 翻訳、分類、要約など | Brown et al., 2020, Min et al., 2022 |
| Chain-of-Thought Prompting | 問題から解答に至る解法ステップ(思考の過程)をプロンプトに含める。 | 複雑な推論タスクへの性能向上が期待できる。 | ステップの記述が冗長になり、トークン数が増える。 | 計算問題、論理推論、数学的証明 | Wei et al., 2022 |
| Zero-Shot CoT | 「Let's think step by step」などの一文で中間推論を誘導。 | シンプルな変更で精度向上。例示不要。 | 効果が出にくいタスクもある。 | 推論問題、言語理解 | Kojima et al., 2022 |
| Self-Consistency | 複数の推論パスの出力をサンプリングし、多数決で最終回答を決定。 | 安定した高精度な回答を得やすい。 | 計算コストが高くなる(複数出力の必要)。 | 数式計算、複雑な推論問題 | Wang et al., 2022 |
| Generated Knowledge Prompting | モデルが関連知識を自動生成し、それを使って回答を導出。 | タスク固有の知識を自動で補完できる。 | 知識の正確性が保証されない場合がある。 | 概念理解、専門領域の質問応答 | Liu et al., 2022 |
| Prompt Chaining | 複雑タスクを複数のサブタスクに分解し、各ステップを連鎖的に解く。 | 各ステップを明確化でき、より深い推論が可能。 | 構成と制御が複雑になる。 | 引用抽出、複雑な情報処理 | - |
| Tree of Thought (ToT) | 推論を木構造にし、各ノード(思考)を探索・評価して問題解決を行う。 | 複雑な問題に対して柔軟な探索が可能。 | 実装が複雑で計算コストも高い。 | パズル、計画問題、論理ゲームなど | Yang et al., 2023, Long, 2023 |
| Retrieval-Augmented Generation (RAG) | 外部知識ソースを検索し、それを用いて生成タスクを強化。 | 幻覚の防止、正確性の向上が期待できる。 | 検索精度や情報整合性に依存する。 | 特定分野QA、FAQ、知識ベース生成 | Lewis et al., 2021 |
| Automatic Reasoning and Tool-use (ART) | 推論ステップや外部ツールをモデル自身が自動で選択し、解決する。 | 人手によるfew-shot設計が不要で効率的。 | モデルやツール依存が強く、構成が複雑。 | 数学問題、物理問題、コード実行型タスク | Paranjape et al., 2023 |
Prompt Engineering
Zero-Shot Prompting
あとで紹介する方法と比べ特徴的なのは, モデルに任意の例を提供していないことことである. つまり, 回答の生成内容にヒントを与えない(Zero-Shot) というものだ.
もちろん, このシンプルなプロンプトでは, まだまだ生成される回答の質や内容に納得できないかもしれない. 例えば, ちょっとした計算問題を対処できない場合がある.
そうした場合は, プロンプトにデモンストレーションや例を提供することが有効になるかもしれない.
Few-Shot Prompting
Few-shot promptingは, プロンプト内のデモを提供すること(事例を含めること)で, より高い回答性能を獲得できるよう, モデルの文脈学習を可能にするテクニックである.
このテクニックで重要となるのは, どのような例示をプロンプトに含めるか... というものだ.
そのヒントが, Min et al, 2022にあるかもしれない.
Min et al (2022)は, few-shotにおけるデモ/例についてのいくつかのヒントを紹介しており,
- 「デモで指定されたラベルスペースと入力テキストの分布の両方が重要である(ラベルが個々の入力に対して正しい場合でも)」
- 使う形式も性能に重要な役割を果たす。ただし、ランダムなラベルを使用する場合でも、ラベルがない場合よりもはるかに良い結果が得られます。
- 追加の結果からは、一様分布ではなくラベルの真の分布からランダムなラベルを選択することが役立つことも示されています。
標準的なfew-shot promptingを用いれば, 多くのタスクにて回答精度は改善されるかもしれない.
しかし, より複雑な推論タスクに取り組む場合には, まだ十分なテクニックとはいえない.
実際, 「数字列を偶数か奇数か判断する」推論タスクでは,例え問題と解答のセットを渡しても, 正しく回答できない場合が多々ある.
そうした場合,問題をステップに分解して, モデルにそれをデモンストレーションすることが役に立つかもしれない. つまりは, 問題の解き方 (プロセス) を教えてるということだ.
Chain-of-Thought Prompting
例示を含ませるこれまでのPromptingでは,基本的に問題と解答のセットを与えることを想定していた. さらに拡張し, 問題から解答に至るまでの解き方を含めることで, 高度な推論タスクにも対応しようという方法も提案されている. これにより, 中間的な推論ステップを意識させているといえる.
Wei et al, 2022は,この中間的な推論ステップを含むchain-of-thoughtが高度なタスクへのLLMの能力を向上させることを実験で示している.

通常のプロンプト(standard prompting)では解けない数値計算問題も, その計算過程を明示的に含ませたChain-of-thought Promptingでは正しく回答できる.
Self-Consistency (自己整合性)
さて, 高度な推論タスクの場合, 問題の解き方は一つだとは限らない. つまり, 解に至るまでの複数の推論パスが存在しうる.
そんな推論パスの多様性を活かしたテクニックが, Self-Consistency (自己整合性)Wang et al, 2022である.
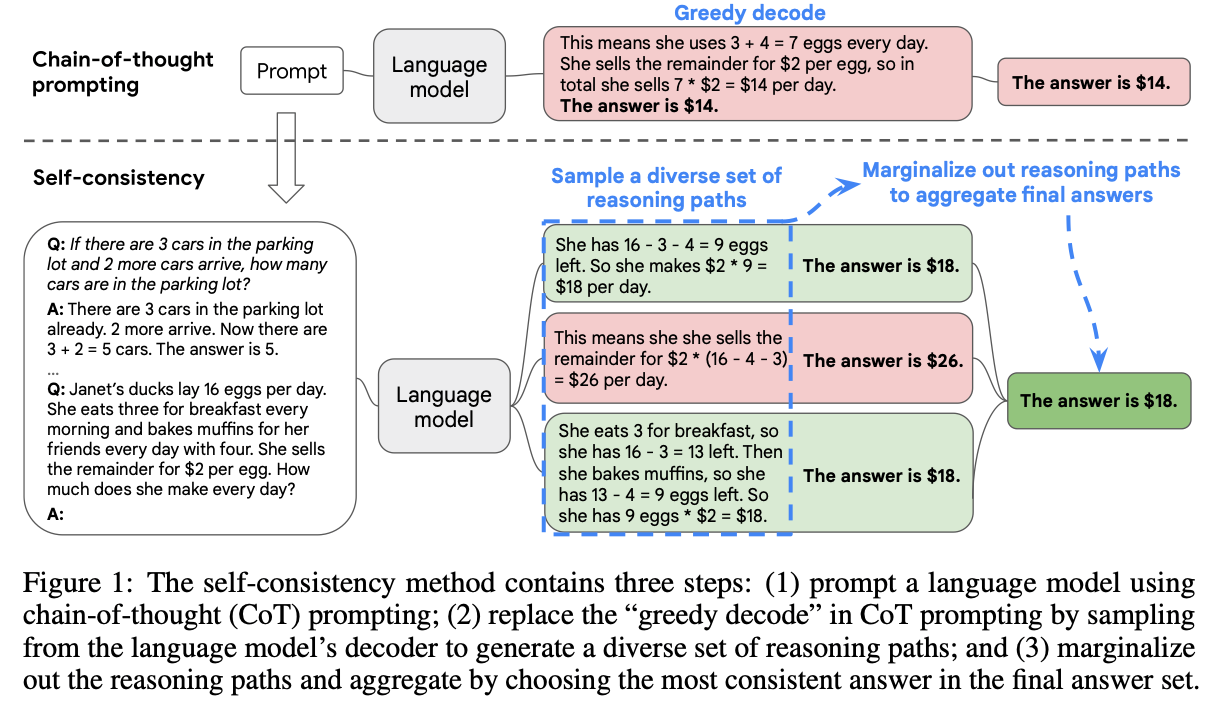
このテクニックは,先に述べたChain-of-Thought PromptingWei et al, 2022の復号化戦略(decoding strategy)を, 貪欲な復号化法(the naive greedy decoding)に置き換えたものである.
図にある例のように, 複数の計算問題例と, 最終的に解かせたい問題をプロンプトに含めることで, 複数の推論パスによるいくつかの回答例をサンプリングする. このとき, これらの回答例をまとめて検討することで最終的な解を得る, というテクニックである.
基本的には,既に多数派の回答が出ていると, それが本質的に最終的な回答になるというものかもしれない. 全ての回答例がバラバラになるような推論タスクだと,もしかしたら別のアプローチが必要かもしれない.
Generated Knowledge Prompting (知識生成プロンプティング)
ここまでpromptingでは, プロンプトの中に何らかの例示を含めることで,回答精度を改善させるものであった. つまり, より正確な予測を行うために知識や情報を組み込む能力を持つことが一般的なテクニックとして認知されてきた.
しかし, その例を作ってあげるのは主に「人間」であった. では, その追加情報自体もLLMに作らせてしまうとどうなるのか?という試みをしたのが, Liu et al, 2022のGenerated Knowledge Prompting (知識生成プロンプティング) である.

イメージとして, とある問いに対し, 回答に有益な関連知識そのものもLLMに生成させ, 問いと関連知識をまとめてプロンプトに含めることで回答精度を高めようというものだ.
具体的な例として, 「ゴルフの競技性」に関する問題が紹介されている.
Q: ゴルフの一部は、他の人よりも高いポイント総数を得ようとすることです。「はい」か「いいえ」か?
A: はい. # False
素直に問題を解かせようとすると, おそらく一般的なスポーツの勝ち負け(得点が大きいほど強い)に回答が誘導されてしまう(のだろう).
そこで,「ゴルフがどのような競技であるのか」という知識を事前に生成させるのだ.
知識1 : ゴルフの目的は、できるだけ少ない打数で一連のホールをプレイすることです。通常、ゴルフのラウンドは18ホールで構成されます。1回のホールは、標準のゴルフコースに1回プレイされます。各打数は1ポイントとしてカウントされ、総打数がゲームの勝者を決定するために使用されます。
知識2 : ゴルフは、競技者(またはゴルファー)が多種多様なクラブを使用して、できるだけ少ない打数でコースの一連のホールにボールを打ち込む精密なクラブ&ボールスポーツです。目標は、各ホールでの総打数を合計した最低スコアでコースを完走することです。最低スコアを出したプレイヤーがゲームに勝ちます。
そして, これらの知識を統合して予測をさせる.
Q:ゴルフの一部は、他の人よりも高いポイント総数を得ようとすることです。「はい」か「いいえ」?
知識:ゴルフの目的は、できるだけ少ない打数で一連のホールをプレイすることです。通常、ゴルフのラウンドは18ホールで構成されます。1回のホールは、標準のゴルフコースに1回プレイされます。各打数は1ポイントとしてカウントされ、総打数がゲームの勝者を決定するために使用されます。
A: いいえ、ゴルフの目的は他の人よりも高いポイント総数を得ることではありません。むしろ、目的はできるだけ少ない打数で一連のホールをプレイすることです。総打数がゲームの勝者を決定するために使用されますが、ポイントの総数ではありません。
論文ではこの「知識」の内容によっては,回答への自信度が揺らぐこと, ひどい場合には回答を間違えてしまうことも議論されている. そのため, 正しい回答へ導くための「良い知識とは?」 を考える必要もありそうだ.
Prompt Chaining
高度な推論タスクの場合, その解き方(中間の推論プロセス)を含めることで精度が改竄されることが発見されてきた. しかし,もっと複雑な推論タスクの場合はどうだろうか? その場合, ひとつのプロンプトのなかに, 解き方をただひとつ載せるだけでは解にたどりつけないだろう.
そこで, タスクを複数のサブタスクに分割することで対処できるかもしれない.つまり, 大きなタスクを, まだ解きやすい簡単なサブタスクに分類し, それぞれにプロンプトで対応させることで, 問題を解く,というものだ.
LLMはそれぞれに対してプロンプトを出し, その回答を次のプロンプトの入力として利用する. これらの一連のプロンプトのI/Oにちなんで, Prompt Chainingと呼ぶ.
紹介されているプロンプト例は以下のものである.
ここでは, 文書から引用文献をリストアップさせるタスクで,
- サブタスク1: 文書から引用文献を抽出する
- サブタスク2: 抽出した引用文献を<quotes></quotes>で囲ませ, リストにする
という手順を指示している.
あなたは親切なアシスタントです。
あなたの仕事は、文書で与えられた質問に答えるのを助けることです。最初のステップは、####で区切られた文書から質問に関連する引用を抽出することです。
引用のリストは<quotes></quotes>を使って出力してください。関連する引用が見つからなかった場合は「関連する引用は見つかりませんでした。]と返信してください。
####
{{document}}
####
Tree of Thought (ToT)
Self-Consistency (自己整合性) は, 高度な推論タスクには複数の推論パスが存在しうることを活かし, 複数の回答例から多数決で決められた回答を出力させるテクニックであった. シンプルな方法で, 高度な推論タスクに対処しうるという点では魅力である. しかし, 推論方法自体を最適にしているわけではない....
まさにこのポイントをとらえた方法が, 思考の木(Tree of Thoughts、ToT) というフレームワークにより, Yang et al, 2023やLong, 2023から提案されている.

ToTでは, 思考が問題解決への中間ステップとなる一貫した言語の連続を表す思考の木を保持させる. このアプローチにより, LLMは熟考プロセスを通じて, 解に到達するまでの中間の思考(つまり, 木の各ノード)の達成度を自己評価することが可能となる.
思考の生成と評価能力は, 木構造データに適用される探索アルゴリズム(例:幅優先探索や深さ優先探索)と組み合わされ, 先読みとバックトラッキングを伴う思考の系統的な探求を可能にしている.
以下の図に報告されている結果からもわかるように, ToTは他のプロンプト手法に比べて大幅に優れており, Chain-of-ThoughtやSelf-Consistencyの拡張フレームワークとして有用である.

Retrieval Augmented Generation (RAG)
より複雑で知識集約的なタスクの場合, タスクを完遂するために外部の知識ソースにアクセスすることで, より事実との整合性を向上させ, 生成される回答の信頼性が向上し, 「幻覚(hallucination)」の問題を軽減することができる.
そのような外部知識を活かしたテクニックが, ご存知 Retrieval Augmented Generation (RAG)である.
いまやさまざまなテクニックが世に出ているため, ここでは深くは紹介しないが, 特定分野のナレッジをLLMに入れ込むことで, その分野特有の知識問題に対処できるようにするテクニックとイメージしてほい.
より一般的には, RAG は情報検索コンポーネントとテキスト生成モデルを組み合わせたもので, ファインチューニングが可能で, モデル全体の再トレーニングを必要とせず効率的な方法で内部の知識を変更することができる.
Lewis et al, 2021により, RAG のための汎用的なファインチューニングのレシピが提案されているので確認して欲しい.
日本語での説明書では以下の本をお勧めしたい.
Automatic Reasoning and Tool-use (ART)
Chain-of-thought Promptingは, 高度な推論タスクに対処するテクニックとして, さまざまなpromptingの基本をつくったといえる.しかし, 実用的には, プロンプトに含めるべき例示に課題が残され, 解きたいタスクに特化したサンプルを人手で用意しなければいけない, というコストのかかる作業である.
Paranjape et al, 2023は, 学習済みのLLMを用いて, 中間の推論プロセスを自動で生成するフレームワークを提案している.

ARTでは以下のように機能している.
- 新しいタスクが与えられると, タスクライブラリ(Task library)から, 多段ステップの推論の例示と, タスクツール(task tool)を選択する.
- 検証時, 外部ツールが呼ばれるごとに生成を一時停止し,一旦出力内容を統合して, 次の生成処理へ移る


具体的な例を見ていこう. 上の図では, ある高校物理の問題を解くタスクである.
この問題を解く前に, Task Libraryから, 関連するタスク(Anachronisms(時代錯誤問題) , MathQA(算数問題))や事例を引っ張ってくる. また, この事例には明示的に推論ステップ([search]や[code execute])が含まれている.
これらの類似例を自動で選択し, また推論ステップも自動で選別することで, 解きたいタスクに特化したサンプルを人手で用意しなければいけないという先の課題を解決する.
さらに, 生成された回答例に対するHuman Feedbackも考慮されている.
まとめ
今回は, 公開されているPrompt Engineering Guideを参考に, Prompt Engineeringのテクニックを体系的に学ぼう、というチャレンジであった. 本記事では,まだ半分しか説明していない. 残りは次の記事で紹介したい.
Discussion