【Prompt Engineering Guide】で体系的に学ぶ LLMプロンプトエンジニアリング②
概要
前回に引き続き,公開されているPrompt Engineering Guideを参考に, Prompt Engineeringのテクニックを体系的に学ぼう、という(個人的な)メモです.
今回はMeta promptingを除く, 残りのテクニックについて整理する. 以前の内容は前の記事を参考にしてください.
忙しい人向け
ささっと理解したい人向けに, 今回紹介するテクニックの概要を表で整理しておく.
(本文をChatGPTで整理したものである)
| 手法名 | 特徴 | 関連文献・リンク |
|---|---|---|
| Automatic Prompt Engineer (APE) | - LLMで指示文を自動生成・スコアリングし、最適化 - ブラックボックス最適化として指示文探索 - モンテカルロ法で意味を保った再構成も実施 |
Zhou et al., 2022 |
| Active-Prompt | - 有効なCoT例示を選ぶことに着目 - 問題の不確実性を推定して注釈対象を決定 - 少数の有効例だけで精度向上を目指す |
Diao et al., 2023 |
| Directional Stimulus Prompting (DSP) | - 小型LMがヒントを生成 → LLMに入力補強 - SFT+RLによってヒント生成モデル(Policy LM)を学習 - LLM本体は触らず利用可能 |
Li et al., 2023 |
| PAL (Program-Aided Language Models) | - 中間推論を自然言語でなくコードで記述 - Pythonなど実行可能コードによって問題解決 - コーディング的推論が可能に |
Gao et al., 2022 GitHub: PAL |
| ReAct | - 推論(Thought)+ 行動(Action)を統合 - 外部APIやツールと連携しながら思考を深める - 可視性・柔軟性・性能のバランスが優秀 |
Yao et al., 2022 Qiita記事 |
| Reflexion | - ReAct + 自己反省 + 記憶モデル - Actor, Evaluator, Self-reflection の3構成 - 軌跡を評価し、次の思考に活かす - 高い解釈性・汎用性あり |
Shinn et al., 2023 |
| Multimodal CoT | - テキスト+画像を統合した思考連鎖 - 理由生成 → 回答推論の2段階構成 - 小規模モデルでも大規模LLM並の性能達成 |
Zhang et al., 2023 arXiv:2302.14045 |
| Graph Prompting | - GNNにプロンプトの概念を導入 - 類似性予測タスクで一貫した形式化 - 下流タスクへの事前学習知識活用が容易に |
Liu et al., 2023 続編: Generalized Graph Prompt |
Prompt Engineering
Automatic Prompt Engineer
LLMからよりよい回答を得るためには, プロンプトに適切な指示を含めることが有効であることはいくつもの研究で示されてきた. しかし, その「適切な指示」については, 操作する人間の知識に頼り, 人の手で作成することが多い.
Zhou et al, 2022は, 自動指示生成と選択のためのフレームワークである自動プロンプトエンジニア(APE) を提案した.
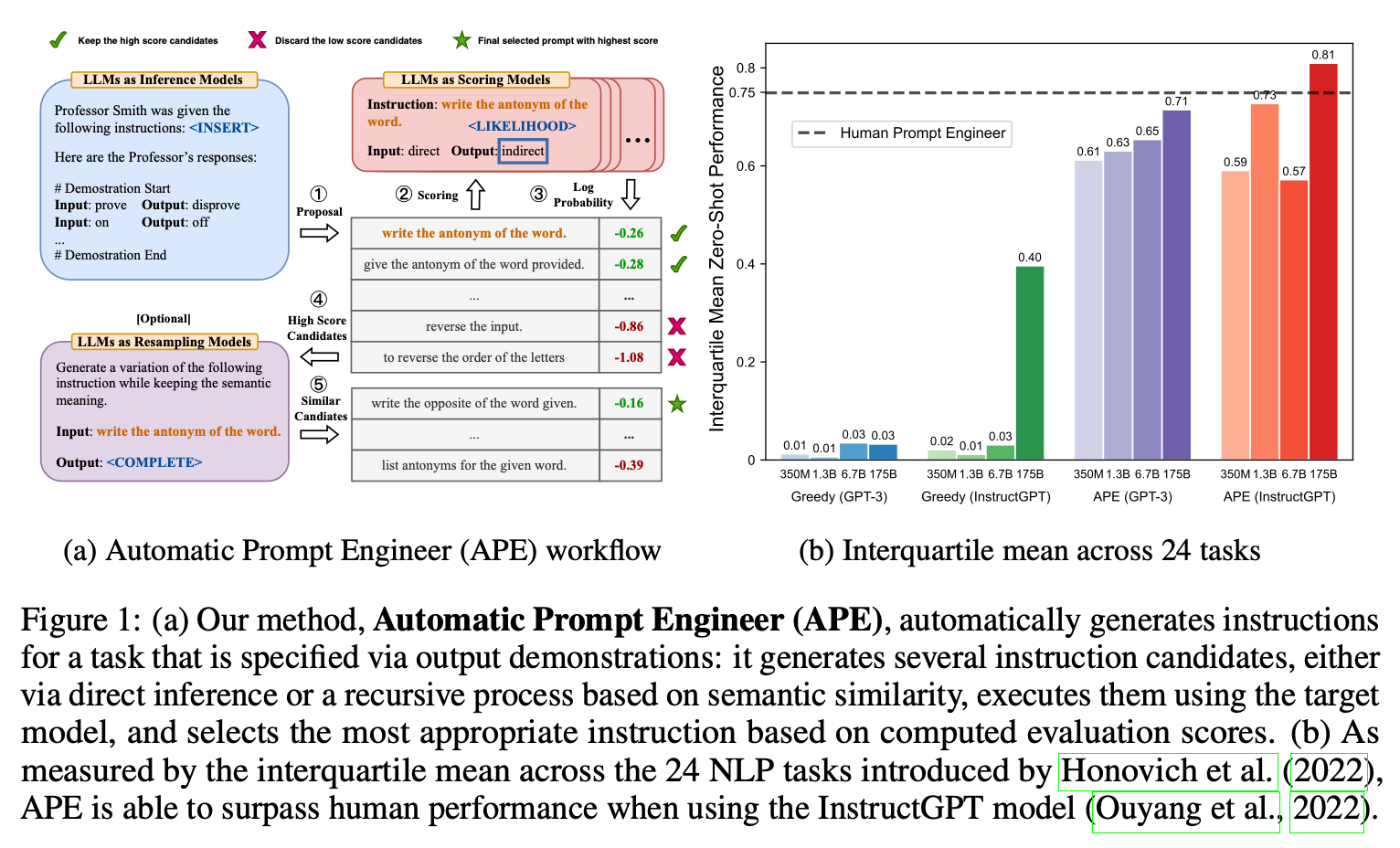
この論文では, 以下のような手順で, 適切な指示の自動生成を遂行する. このとき, この指示の自動生成を, 自然言語合成("natural language program synthesis")と呼び, ブラックボックス最適化問題として対処している.
図に従いつつ説明を続ける.
- まず, LLMを推論モデルとして用い, 少数のデモンストレーションから, 指示候補を列挙させる. (図(A)では, input-outputのペアが与えられ, 教授が指示した作業内容を推論するというタスクを解こうとしている. まず, input-outputのペアを参照し,あったかもしれない指示候補を列挙している.(①))
- 次に, LLMを用いてそれぞれの指示候補の「良さ」をスコア化する.(ここでは, ひとつずつの指示文をもとの教授の発言に組み込み(②), デモのinputからoutputを生成させ,その予測文と真値のoutputの比較より, それぞれの指示候補の「尤もらしさ」を対数確率で算出している.(③))
- 最後に, モンテカルロ法(
Monte Carlo Method)に則り, 2.でベストスコアであった指示文を,その意味を変えずにバリエーションを増やし, 再度スコア化していく作業を繰り返す. これにより, 最終的にはベストな指示文が獲得されるという仕組みへ.(例では, 2.でベストスコアであった, "write the antonym of the word"と同意味の文章,"write the opposite of the word given"などをスコア化している.)
つまり, 良い指示文とは, 文章が変化しようが, その優位性がそうそうに崩れない, 本質を捉えた指示内容を含むものだ, という視点をもったアプローチであると考えられる.
以前の記事で, プロンプトに"Let's think it step by step"の一文を入れるだけで高度な推論タスクを解けるようになる, という研究を紹介した.
APEでは, このプロンプトよりも,優れたゼロショットCoTプロンプトを発見している. ("Let's work this out in a step by step way to be sure we have the right answer")
人の手で探すよりも,より効率的かつ精度の良い回答を得られる指示文を生成するフレームワークとして効果を発揮したといえる.
Active-Prompt
引き続き, 良い例示を含むpromptingテクニックとは?に言及した手法である.
Chain-of-thought (CoT) メソッドは, いくつかの中間的な推論プロセスを明示的に示したプロンプトを作成することで, 高度な推論プロセスに対処できるよううにするテクニックである.
しかし, これまで指摘したように, 人間による注釈付き(human-annotated)の例示セットに依存しており, 異なるタスクを扱う場合には, 良い例示セットになっているとは限らない可能性が指摘されている.
Diao et al, 2023は, タスク特化の例示プロンプトを用いながらも, 異なるタスクへLLMを適応させる方法として, Active Promptを提案した.
主な狙いとしては, 事前に想定する問題集のうち, どれがアノテーションする上で重要で有益であるかを決定する, という課題を考えていることである.つまり, 人手で中間の推論プロセスを組み込むというChain-of-thought (CoT) Promptingにおいて, 少ない問題事例だけでもLLMからの応答精度が改善されるような,そのような問題事例を自動で選択したい, という動機である.
最終的には, 例示作りの手間を省けるようにしたいというものである.
ざっくりとは以下のようなアプローチをとる.
-
プール内(unlabeled)の問いをスコアリング
- 各問いに対し、LLMが生成する複数のCoT推論の**不確実性(uncertainty)**を測定。
- 不確実性の高い問いほど、モデルが困難とする問いとみなされる。
-
例題の選択(active selection)
- 不確実性上位の問いを選び、人手でCoTステップと答案を注釈する。
-
例題セットの構築と推論
- 選ばれた例題セットをfew‑shotプロンプトとして用いる。
- 自己一貫性(self‑consistency、一種の多数決ラベリング)と組み合わせることで性能をさらに改善。

論文中の図を用いて具体的な流れを整理しよう.
まず, 事前に問題集が用意されているとする(Unlabeld Questions). これには, まだ人の手によるアノテーションは入っていない, 手付かずの状態である.
そしてこれからLLMが解こうとするタスクにおいて,この問題集のうち,本当に有益な問題だけを抽出し, 人にアノテーションするように指示したい,というのが最終的な狙いである.
次に, このUnlabeld Questionsと,事前にアノテーションされている少数の例示を統合し, LLMに解かせる. ここで, k回解答させて, それぞれの解答の不確かさuncertaintyを算出する((1)Uncertainty Estimation).
そして, uncertaintyの総合平均が高い問いを選択し((2)Selection), その問いに対し, 追加でアノテーションをしてもらうように,人に指示する. ((3)Annotation)
そして, 選別された問いと, それに対してアノテーションを行った例示集を用いて, 本来のタスクに対して, LLMの応答を確認する.((4)Inference)
Active Promptは, アクティブラーニングのアイディアをCoT promptingに応用した点が新しく, モデルが「何に困っているか」を可視化し, それに応じて例題を動的に補強できる手法である.
この考えかたは, 今後のプロンプト設計に強力な示唆を与える可能性がある. またm 不確実性に基づく例題選択はコスト効率の面でも有望である.
Directional Stimulus Prompting
LLMから良い回答を獲得するために,どのような指示を含めたら良いか,という課題に対する別アプローチとして, Li et al, 2023は小型のチューナブル・ポリシー言語モデル(例えば T5)を導入し, 入力ごとに出力を誘導する刺激プロンプト(directional stimulus prompt) を生成する手法を提案した.

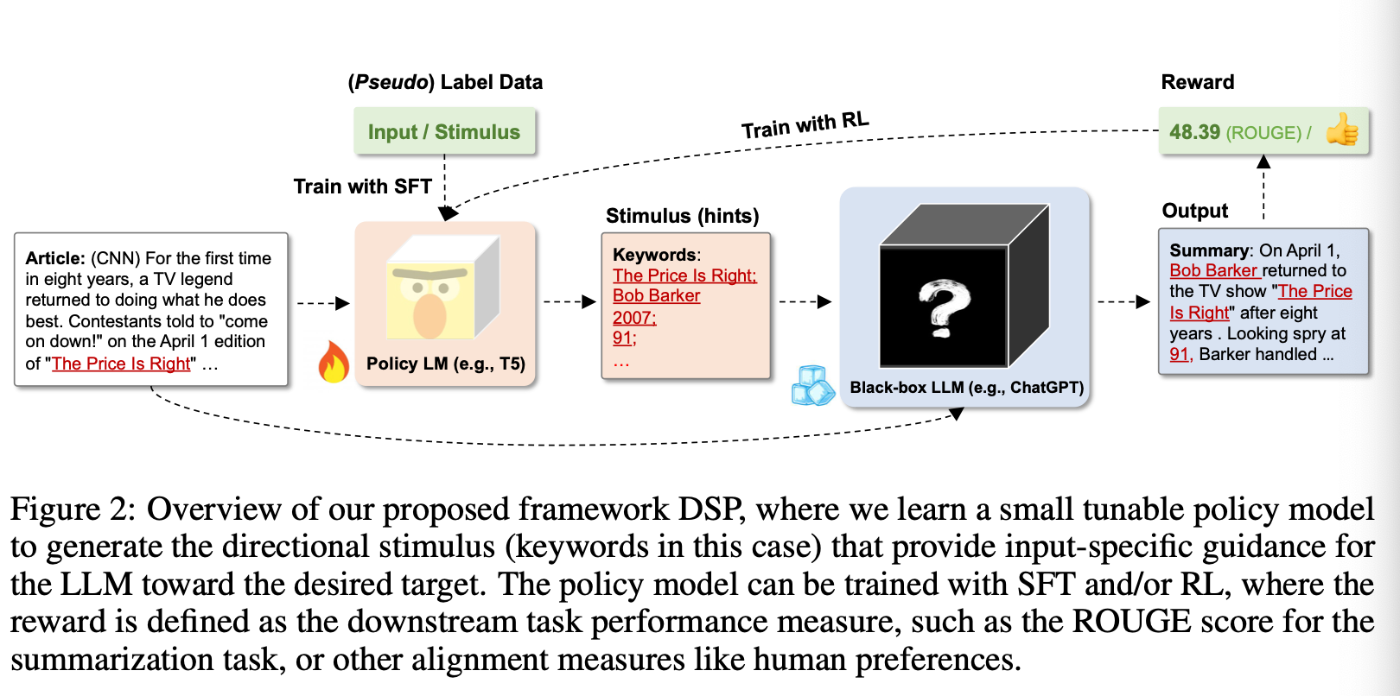
上記1番目の図では, 論文の要約タスクにおいて, 望んだ要約文が得られるように, Hintをプロンプトに含ませる, 誘導する刺激プロンプト(directional stimulus prompt) を示している.
そして2番目の図では, その刺激プロンプトを自動で作成するためのPolicy LMを別途用意している, というフレームワークを示している.
つまり, この論文が提案するDSP (Directional Stimulus Prompting) の特徴としては,
-
ポリシーLMによる刺激生成
- 元の入力文に対し, キーワードやヒントとなる単語群などのディスクリート(離散的)刺激を生成し, これを元にLLMへの入力を補強
-
学習方式
- 教師ありファインチューニング(SFT):既知の正解付きデータで刺激生成モデルを初期学習。
- 強化学習(RL):LLMの最終出力に対する評価(例:ROUGEスコア、人手評価)を報酬としてポリシーモデルを微調整
-
エンドツーエンド設計
- ポリシーモデルだけが調整対象とし, LLM本体はそのままブラックボックスとして保持され汎用性を維持。
LLMとは独立したモデルを別途用意し, より良い指示文を作成するという点で, LLMの特徴や能力に依存しない,という点で, 応用が効きそうな手法にみえる.
ReAct
LLMはChain-of-thought(CoT)による推論能力と, 行動(action)を出力する能力, の両方を持つが, これらはこれまで個別に扱われることが多かった.
推論では内的思考を浮かび上がらせる一方で,行動は外部ツールやAPIとの連携を必要とする. しかし, 推論だけでは知識の取得や誤りの修正に限界があり, 行動だけでは一貫した思考プロセスを維持しづらいという課題がある.
そうした課題に対し提案された手法が, みなさんご存知, ReAct (Reason + Act) である.(Yao et al, 2022)
ReAct は, 推論(Thought)と行動(Action)の融合をプロンプトレベルで実現する新手法である.

従来のCoTが陥りがちな創作や誤謬をAPIとの連携によって補完し, インタラクティブな環境でも動的にタスク対応できる点が大きな特徴である. 特に,「少量数ショット」「高性能」「可視化可能な思考」というバランスは, 説明性・実用性・運用効率のすべてにおいて秀でており, 今後のエージェント設計の支柱になりうる手法と考えられる.
図に示したように, ReActでは, 入力された問いに対し, 具体的な推論プロセスの可視化(例:「Search]」)や, それの実行(例:Googleで情報を検索(Search)する)を繰り返し, 回答精度を改善していく循環プロセスをもつ.
すでに有名な手法だと思うので, 具体的な説明は他者の記事に譲りたい.
Reflexion
ReActは, 推論プロセスと行動プロセスを同時に繰り返すことで, より良い回答を生成するためのフレームワークであった.
しかし, これらのプロセス自体を洗練する,という仕組みが考慮されていないがゆえに, 計算コストは余計に高まる一方である.
さて人間はというと, 人間は失敗から反省し, 計画を改善し, より効率的な計画の立案と行動を生成できる.
つまり, LLMエージェントにはこの“自己反省(self-reflexion)”能力が欠如していた, といえる.
Shinn et al, 2023が提案したReflexionは, 言語的フィードバックを通じて言語ベースのエージェントを強化するためのフレームワークである.

図にあるように, Reflexionは以下の三つの異なるモデル(LM)で構成されている.
-
Actor
- 状態観測に基づいてテキストと行動を生成する.それによって軌跡が生成される.
- Actorモデルとしては, Chain-of-Thought (CoT) と ReAct が使用されている,
- また, 追加のコンテキストをエージェントに提供するために記憶コンポーネント(short-term memory, long-term memory)も加えられている.
-
Evaluator
- Actorが生成した出力を採点する. 具体的には, 生成された軌跡(短期記憶とも表される)を入力として受け取り報酬スコアを出力する.
- タスクに応じて異なる報酬関数が使用する.
-
Self-reflection
- 自己改善を支援するための言語的強化の手がかりを生成する.
- この役割はLLMによって達成され, 将来の試行に対する貴重なフィードバックを提供
- 具体的かつ関連性のあるフィードバックを生成するために、自己反省モデルは報酬シグナル、現在の軌跡、および持続的な記憶を活用する.
- これらの経験(Long-term memory)は、エージェントが意思決定を迅速に改善するために活用されます。
Reflexionは自己評価, 自己反省, 記憶コンポーネントを導入することでReActフレームワークを拡張しているといえる.
下の図は, リフレクションエージェントが意思決定, プログラミング, 推論など様々なタスクを解決するために行動を反復的に最適化する方法の例を示している.

与えられたTask(a)に対し, まず推論プロセスと行動プロセスの一連の軌跡(Trajectory)を生成する(b).
生成された軌跡に対し, 内部的に(Evalator),あるいは外部的に(人手)評価する(c).
評価をもとに, 自身の生成した軌跡を自己反省する(d). その経験を記憶しておき, 次にまた新しい軌跡を生成する(e)...ということを繰り返す.
すべてのモデルがLM(言語モデル)で用意されていることから, とても汎用性の高いフレームワークであると考えられる.他にも,以下の特徴を備える.
- 軽量・非微調整型:LLMの重みに変更を加えず迅速に適用可能
- 解釈性・透明性:言語的な反省により, 失敗理由や改善案が明示され, 学習過程が可視化される.
- 柔軟なフィードバック形式:数値評価, ヒューリスティック, セルフテストなど多様な信号に対応可能
Graph Prompting
Graphは, さまざまなデータの抽象表現をなしえる強力なツールであり, Graph Neural Netwrok(GNNs)の登場により, 複雑なグラフ構造から意味のある潜在表現を獲得することができるようになってきている.
LLMの文脈では, Multi-modal CoTのように, 自然言語以外のモーダルに対しても, CoTの枠組みを適用とする動きが出てきている.
Graph(グラフ構造)にアプローチをしたものが, Liu et al, 2023によるGraph Promptである. これは, ラフのための新しいプロンプティングフレームワークであり, 下流タスクのパフォーマンスを向上させる.
そもそも, これまでの欠点として事前学習した汎用的なモデルと, それらのモデルを用いて行う具体的な下流タスクでの利用にギャップが生じていた.
-
ラベル付きデータが少ない
- ノード分類やグラフ分類といった下流タスク(downstream task)には,多数のタスク固有のラベル付きデータが必要
- しかし、ラベルの作成には高い専門性・コストが伴う(例:医療・化学の分野では専門家による注釈が必要)
-
モデルのタスクごとの再学習
- 現行のGNNは,タスクごとにモデルの出力構造や損失関数を変えて再学習する必要がある.
- そのため, 事前学習と下流タスクでアーキテクチャや学習方法が異なるという構造的不整合が生じている
もう少しこの問題を考えると, 自然言語ではこのpre-traingと, downstream tasksのギャップを埋めるために, promptingが活用されてきた. 例えば, 何らかの事前学習LLMを用いて, 単語の予測タスクや, 要約タスクなどの多種多様なタスクを, 単なるpromptingを変えるだけで解けていた.
では, GNNではどうかというと, まだまだ以下のような点で, 自然言語のようにpromptingで対処しきれていない.
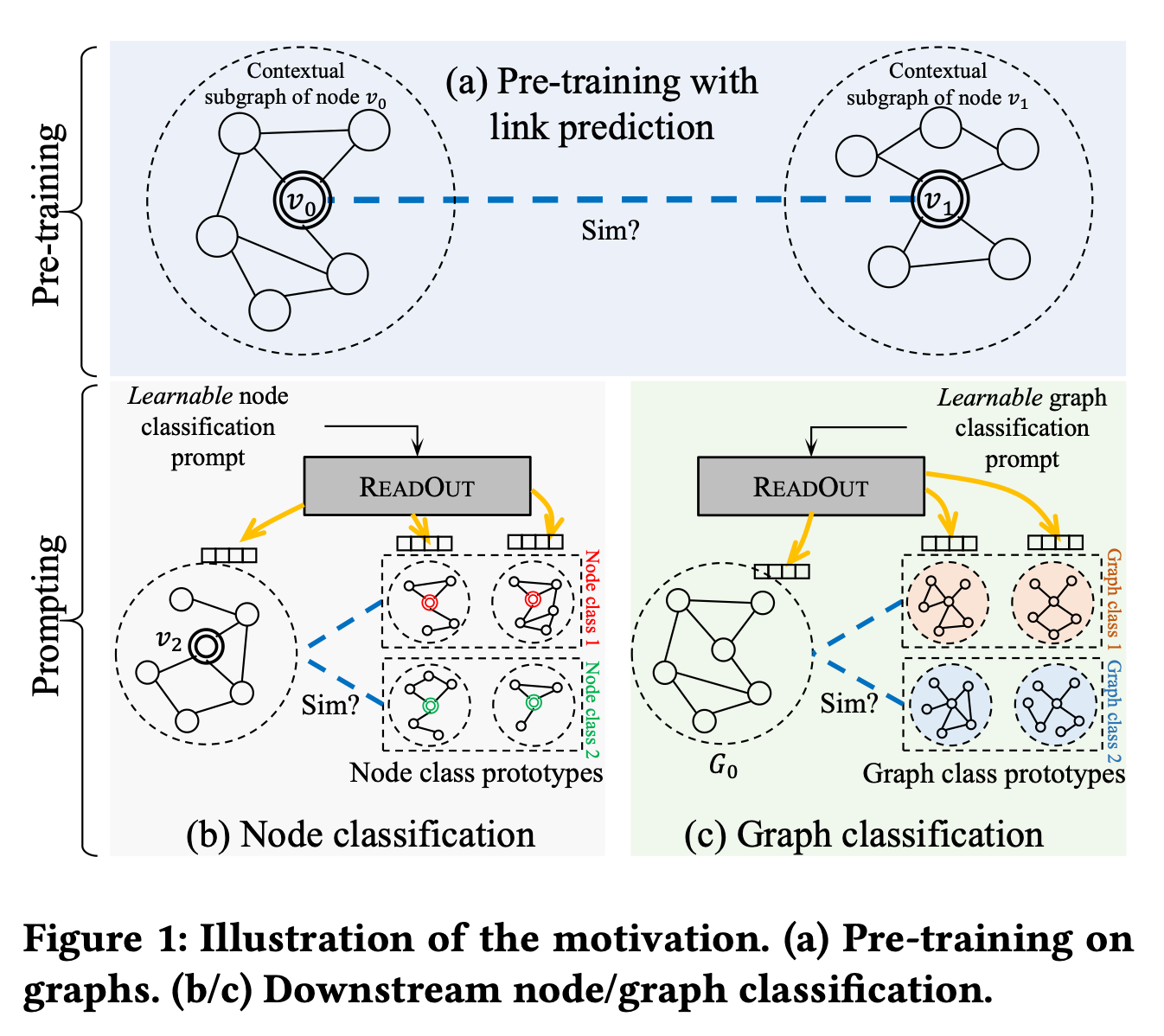
- ノードやサブグラフなどの構造はNLPのようなシーケンシャル入力とは異なり, プロンプトに適した入力形式の設計が困難
- また, タスクごとにReadout関数(プーリング)や分類器を変える必要があるため, 事前学習の知識をそのまま下流タスクに活かしにくい
これらのせいで, 結果的に事前学習で得た知識(表現)を再利用しにくいのだ.
以上を踏まえ, 次のような疑問を出発点に研究がスタートしている.
「GNNにも、NLPのように統一的なプロンプトテンプレートを導入し、事前学習と下流タスクを一貫した方法で扱えるのではないか?」
その解決策として提案されたのが以下の2点:
-
サブグラフのペアを使った類似性予測を共通タスクとして定式化
- 事前学習でも下流タスクでも、「この2つのグラフは似ているか?」という形で同じフォーマットで扱えるように。
-
タスク固有プロンプトを導入して情報抽出を制御
- タスクごとに異なるプロンプトベクトルをReadout層で使い, 目的に応じて学習済み表現から最適な情報を引き出す
つまり, GraphPromptは「構造類似度による統一テンプレート」+「学習可能なプロンプトベクトル」の導入により,GNNにおける事前学習とタスク適応の分断を橋渡しする新しい解決法である.

以上のポイントを整理すると, 特徴は以下の2つである.
- 下流タスクをプロンプトで条件付けすることで, 統一的なインターフェースを実現
- 入力形式(プロンプト付きグラフ)を工夫し複数タスクに柔軟対応
なお,提案手法は後続論文「Generalized Graph Prompt」でさらに拡張されている. こちらもぜひ参照してほしい.
まとめ
さて, 前回に引き続き,公開されているPrompt Engineering Guideを参考に, Prompt Engineeringのテクニックを体系的に学ぼう、という記事でした.
今回扱ったテクニックは, 前回よりも高度なものとなっており, 「良いプロンプトをいかに生成するか」という観点や, 自然言語以外のデータへの適用などと応用的な話となった.
ReActやReflexionのように, 今や有名になりすぎているテクニックもあれば, Graph PromptやMulti-modal CoTのように, これから注目されるようなテクニックもあった.
特に後半の内容は, 元のPrompt Engineering Guideにもほとんど内容が記載されていないため, 論文を改めて読み直すこともした.
さて, あとはMeta Promptingを残すのみである. こちらは, いわゆるpromptを言語で追加するHard promptingとは異なる概念である, soft Promptingの一種である.
Meta Promptingについては, 知識的背景も別途整理する必要があると考えたため, 別途記事を切り分けて説明することとする.
Discussion