🔡
文字をコンピュータで扱うための変換(文字エンコーディング)
導入
私たちは普段10進数の数値/文字/色などを扱いますが、
コンピュータは2進数しか理解できません。
コンピュータで2進数を使う理由については以下ご確認ください。
よって、10進数の数値/文字/色などをコンピュータで理解してもらうためには、
2進数に変換する必要があります。
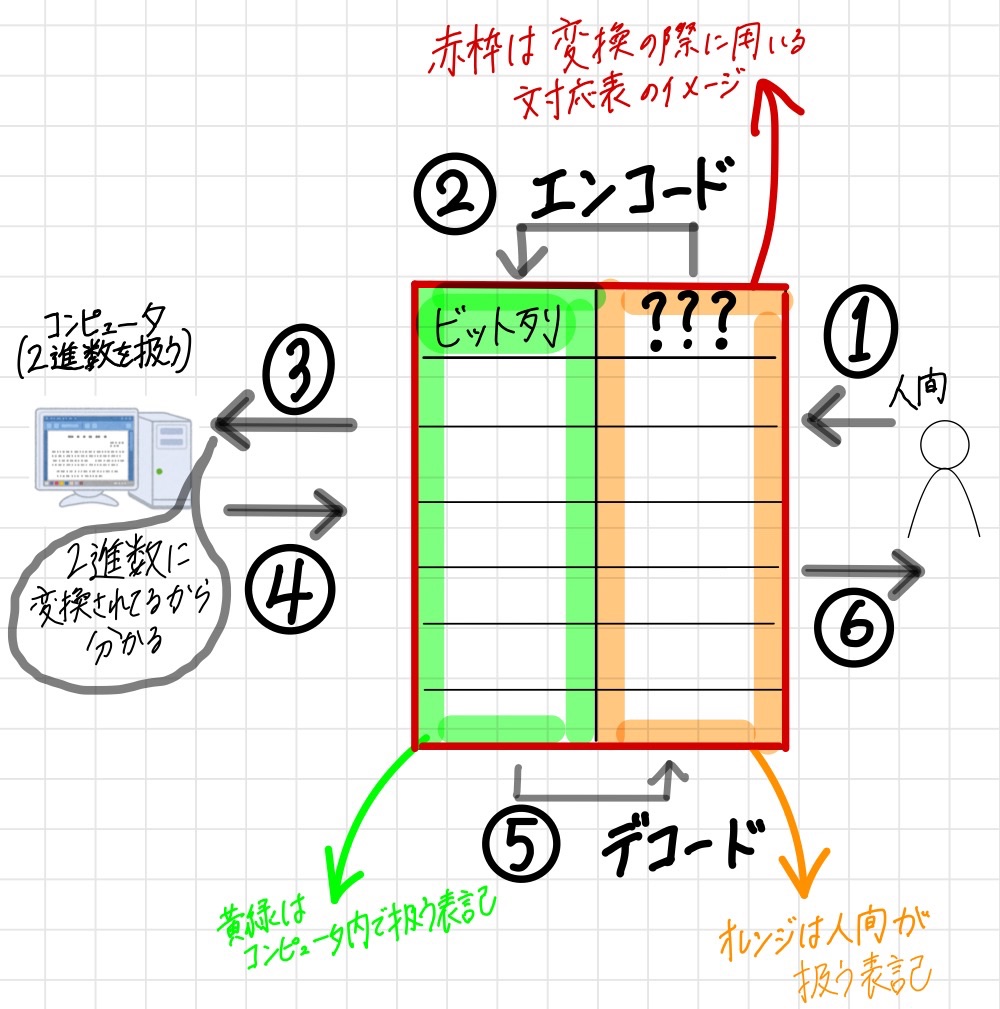
エンコード / デコード
エンコード(符号化):コンピュータが理解できる方式に変換すること
デコード:人間が理解できる方式に変換すること
10進数の数値を、コンピュータで扱うための変換については以下で説明しています。
ですので今回は、
文字をコンピュータで扱うための変換について説明していきます。
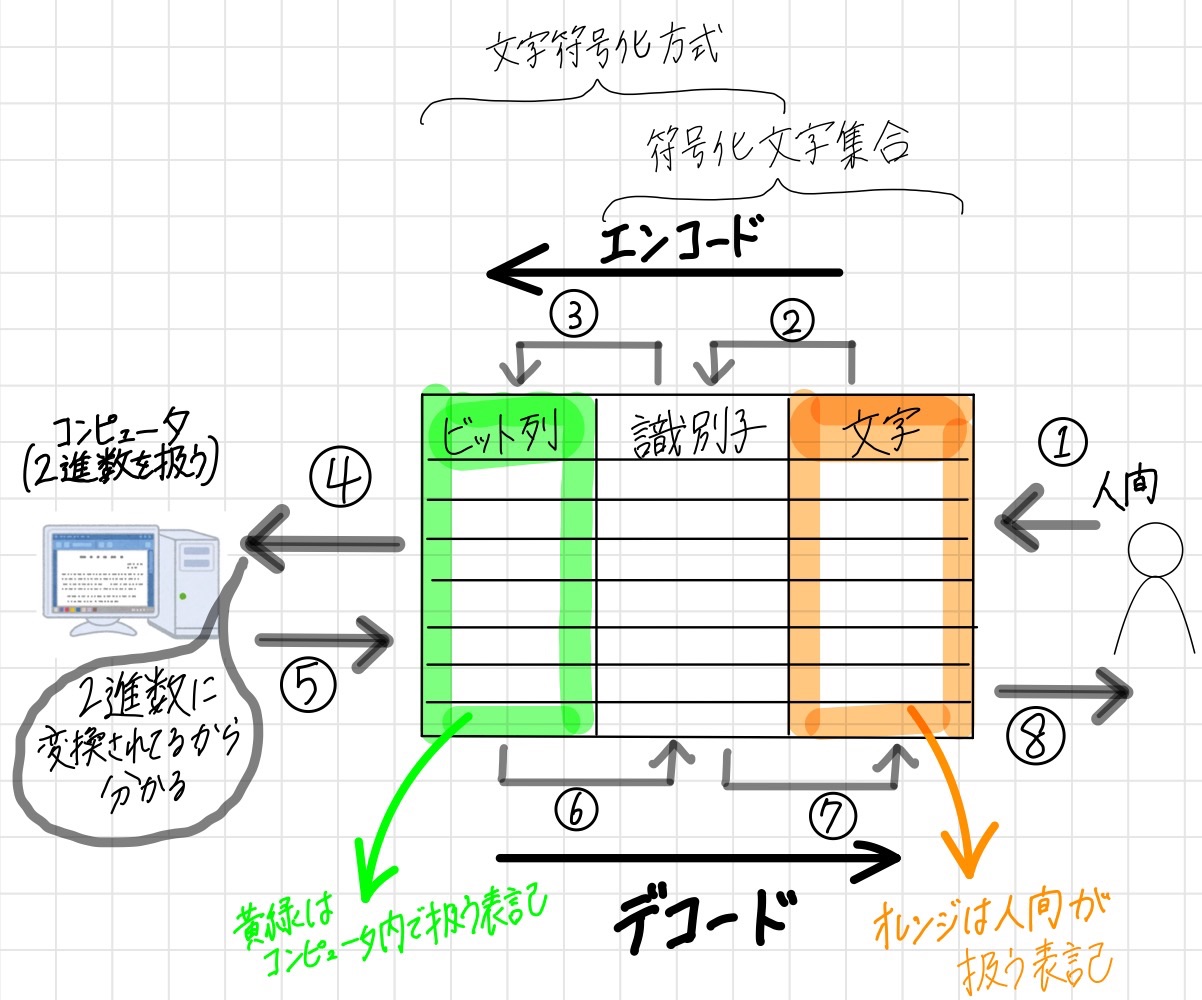
文字をコンピュータで扱うための変換
- 符号化文字集合(Coded Character Set)
- 文字と識別子(一意な数値)を対応させたもの
- 対応表をイメージするとわかりやすい
- 文字符号化方式(Character Encoding Scheme)
- 文字集合で定義した識別子と、コンピュータが理解できる形式を対応させたもの
- 対応表をイメージするとわかりやすい
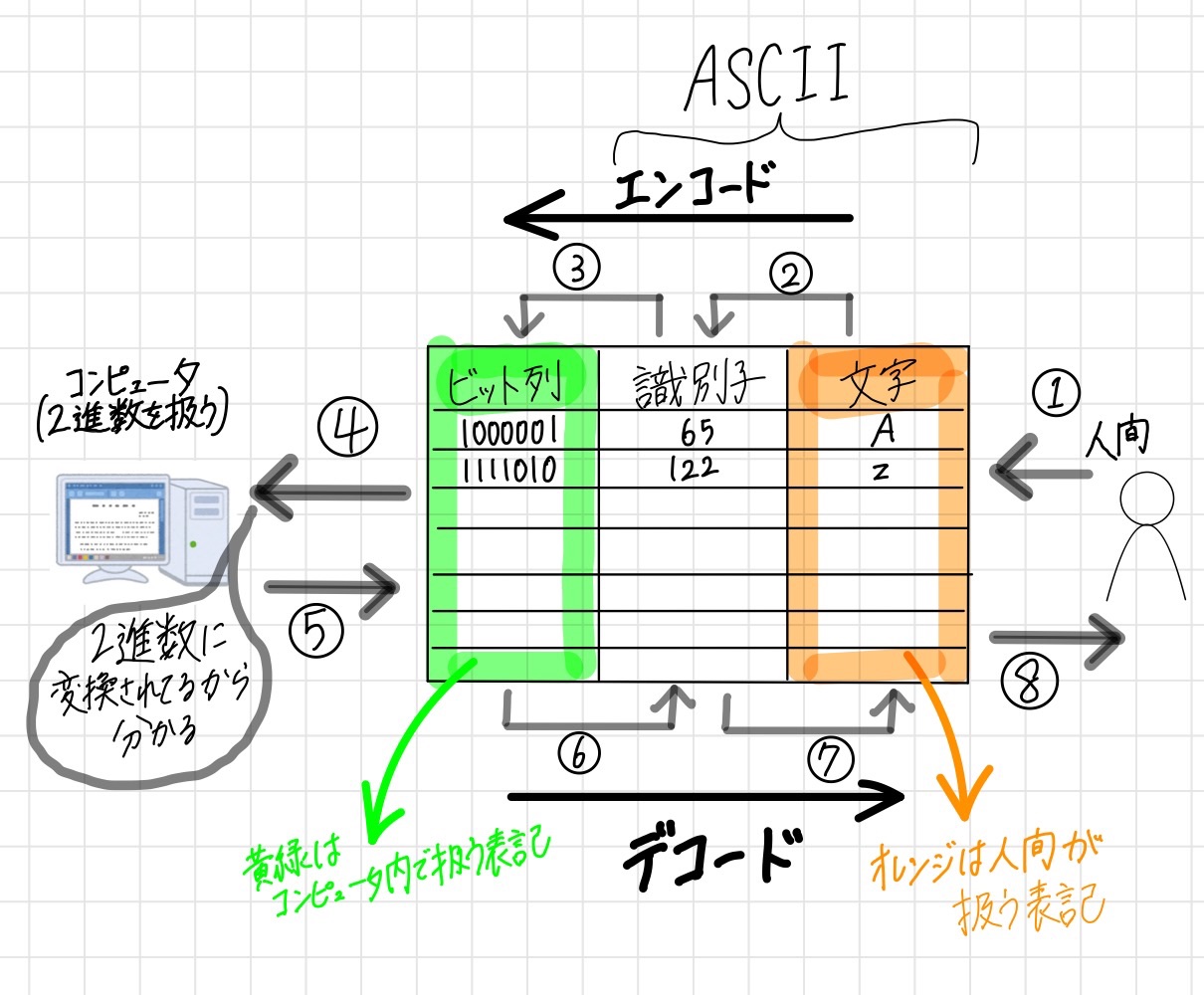
ASCII
-
2^7 - 対応表としてイメージするならば、128行しかないので日本語や中国語には対応していません
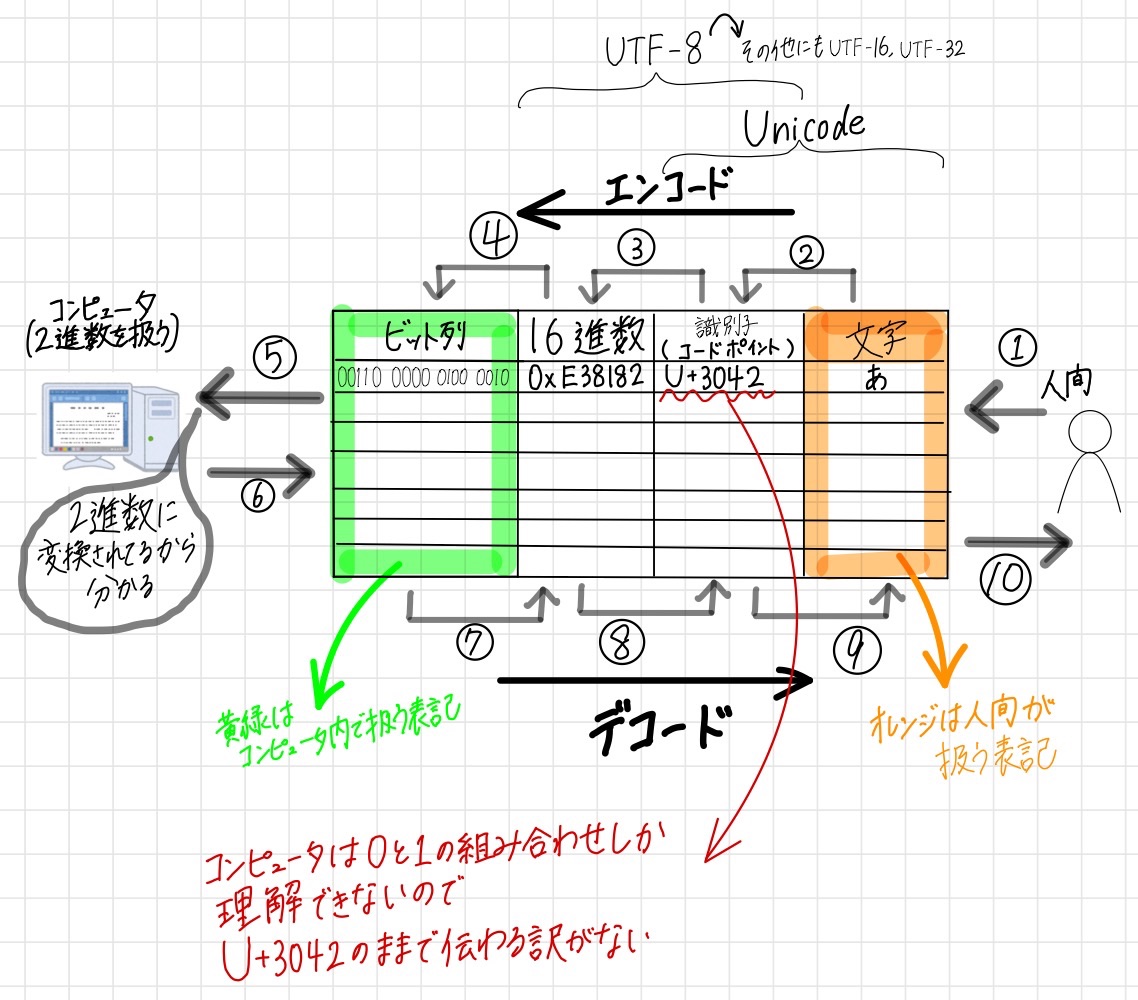
Unicode ↔︎ UTF-8
- Unicode
- 符号化文字集合の一種
- Unicodeにて、文字に割り当てられる識別子のことをコードポイントと呼びます
- 世界中の言語で使われる文字を表現することができる
- UTF-8 / UTF-16 / UTF-32
- 文字符号化方式の一種
- コードポイントをコンピュータが理解できる形式に変換していきます
JIS X 0208 ↔︎ JISコード(ISO-2022-JPのこと)
- JIS X 0208
- 符号化文字集合の一種
- JISコード(ISO-2022-JPのこと) / Shift_JIS
- 文字符号化方式の一種
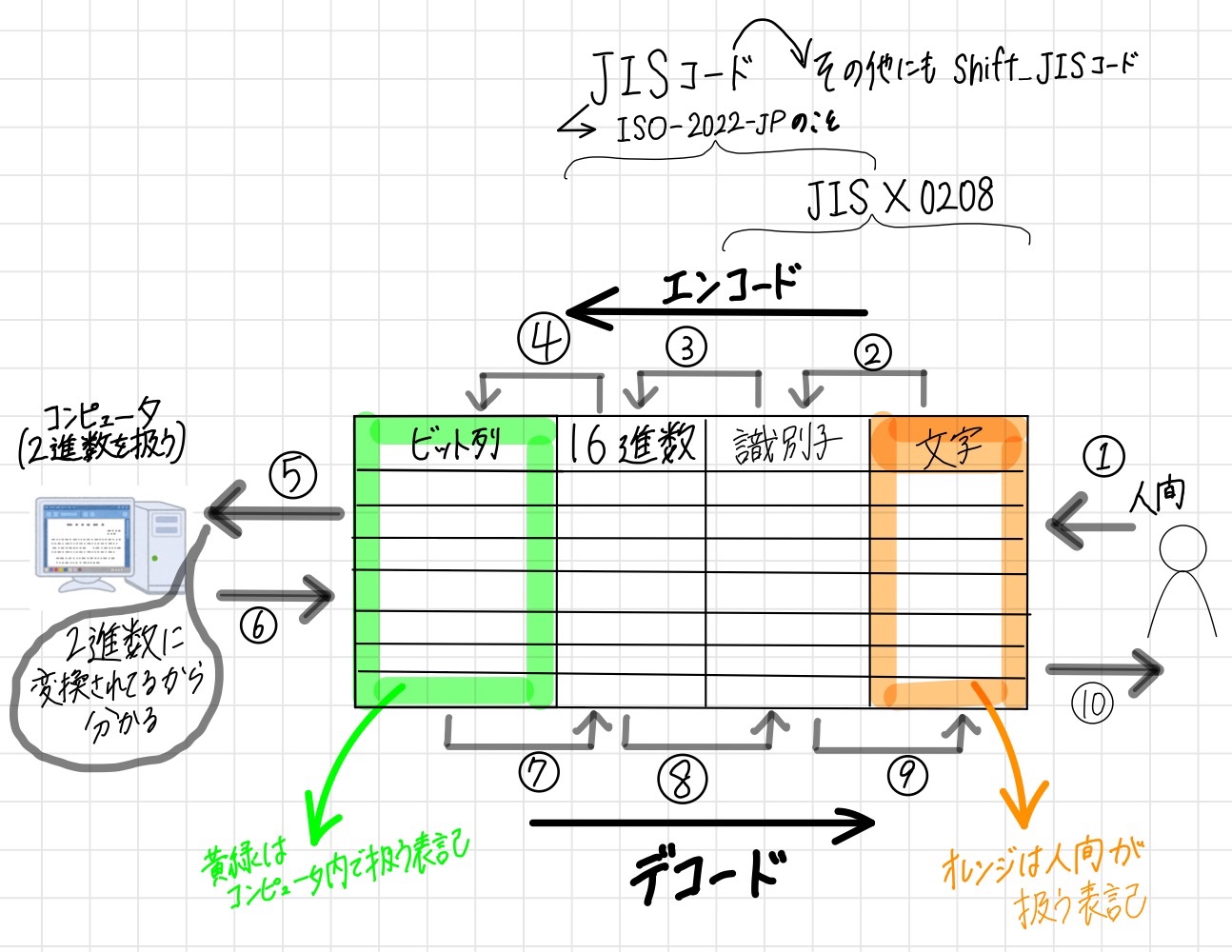
- 文字符号化方式の一種
文字化け
例えば、エンコード時とデコード時で、異なる文字符号化方式を利用した際に発生します。
- Aさんが、テキストデータを「UTF-8」を利用して作成する(つまりエンコードにUTF-8を利用)
- Bさんが、そのテキストデータを「Shift_JIS」を利用して開く(つまりデコード時にShift_JISを利用)
- 文字化けが発生
これは作成時とは異なる対応表を用いて変換しているので当然のことです。
文字化けについては以下もご確認ください。
補足
16進数が採用されている理由については以下をご確認ください。
参考
Discussion