8️⃣
文字化け解消法 CSVファイルを例に
概要
文字化けは、エンコード時とデコード時で異なる文字符号化方式を利用した際などに発生します。
ざっくりと流れを説明すると以下となります。
- Aさんが、「UTF-8」を利用してファイルを作成する(つまりエンコードにUTF-8を利用)
- Bさんが、そのファイルを「Shift_JIS」を利用して開く(つまりデコード時にShift_JISを利用)
- 文字化けが発生
文字をコンピュータで扱う仕組みについては以下をご確認ください。
結論
CSVファイルをExcel(Shift_JIS)で開いたら文字化けが発生
↓
Visual Studio Code(UTF-8)で開いたら解消
ExcelはCSVファイルをShift_JISで開いてしまいます。
それが原因の場合、
UTF-8で開きさえすれば文字化けを解消できるはずです。
詳細
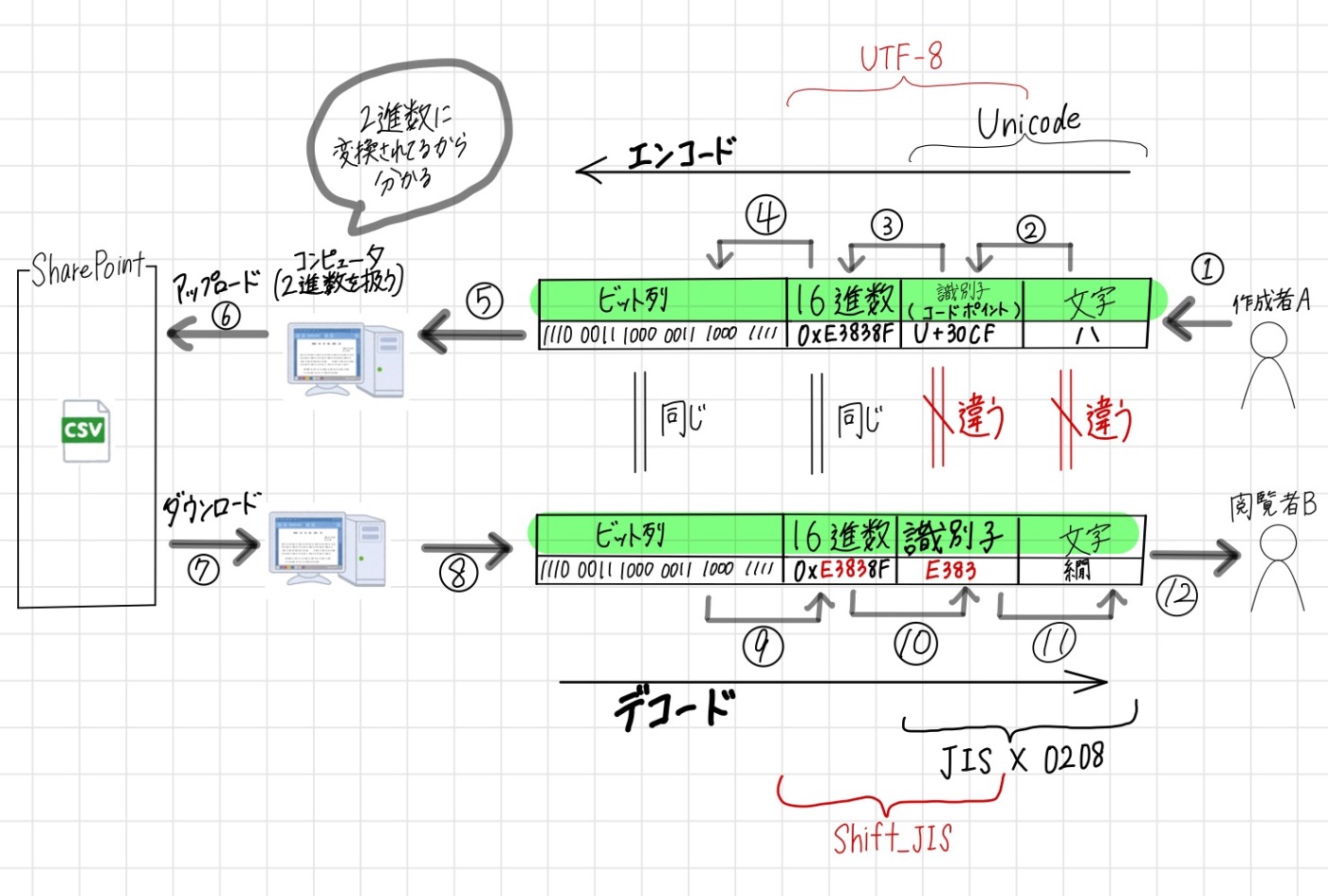
- 作成者Aがカタカナの「ハ」を入力する
- カタカナの「ハ」 → 符号化文字集合Unicodeでコードポイント「U+30CF」 に変換される
- コードポイント「U+30CF」 → 文字符号化方式UTF-8で16進数「0xE3838F」に変換される
- 16進数「0xE3838F」 → ビット列「1110 0011 1000 0011 1000 1111」に変換される
- コンピュータがビット列「1110 0011 1000 0011 1000 1111」を認識する
- 作成者AがSharePoint等、共有ディレクトリにファイルをアップロードする
- 閲覧者Bがそのファイルをダウンロードする
- コンピュータがビット列の解釈を始まる
- ビット列「1110 0011 1000 0011 1000 1111」 → 16進数「0xE3838F」に変換される
- 16進数「0xE3838F」の「E383」部分が、文字符号化方式Shift_JISによって、識別子「E383」に変換される
- 識別子「E383」 → 符号化文字集合JIS X 0208で「繝」に変換される
- 閲覧者Bが「繝」を認識する
作成者Aがカタカナの「ハ」を入力しているのに対して、
閲覧者Bには「繝」として認識されてしまっています。
対処法
デコード時(ファイルを開くとき)の文字符号化方式を適切なものに変更する。
上記図の場合だと、エンコード時の文字符号化方式がUTF-8なので、
デコード時(ファイルを開くとき)の文字符号化方式も、それに合わせてUTF-8に変更すれば解消します。
UTF-8でファイルを開く方法は色々ありますが、Visual Studio Codeで可能です。
Discussion
こんにちは。
これは繰り返し話題になっている(?)ようです。Excel の現状の仕様は、UTF-8 については、BOM 付き CSV ファイルを与えた場合に正しい文字符号で読み込みます。そうでない場合に生じる文字化けの原因は、(趨勢から取り残された)この仕様と説明する人もいるようです。