【Kaggle】ISIC2024 237位🥉 振り返り
今回は、KaggleのISIC2024コンペに参加し、237位でソロ銅メダルを取得することができたので、解法の振り返りを書いていこうと思います。
・Solution
・コード
0. コンペ概要
今回のコンペは、提供された皮膚の画像データから皮膚がんの患者である確率を予測する回帰問題のタスクでした。
・提供データ
画像: 皮膚の画像。患者がスマホで撮影した写真から判別できるようにするために、低解像度です。
テーブル: 病変と思われる部位の色や直径などの細かい情報、及び患者の年齢などの個人データ(test時にも提供される)
・提出ファイルのフォーマット
// target列が皮膚がんである確率
patient_id, target
ISIC_0015657, 0.3
ISIC_0015729, 0.3
ISIC_0015740, 0.3
・評価指標
評価指標はpartial area under the ROC curve (pAUC)で、Ture positive rate が80%以上であるAUCの面積の最大化が目的になります。(最大値2.0)

Kaggle ISIC 2024 - Skin Cancer Detection with 3D-TBP
・コンペの流れ
初めは画像モデルが中心でしたが、画像の解像度の低さと、提供された病変データの多さの影響で、中盤にはLGBMなどのテーブルモデルがPublic Notebookで上位でした。
そしてコンペの後半では、画像モデルが出力した値をテーブルモデルの入力特徴量として使用する、いわゆるスタッキングの手法が非常に高いスコアを出していました。
1. 解法の概要
概要
・テーブルモデルと画像モデルのアンサンブル(1:1の割合)
・テーブルモデルはパブリックのノートブックを使用: ISIC 2024 | Skin Cancer Prediction
・画像モデルはtimmのVITを使用
・正例のデータが非常に少なかった(0.098%)ため、過学習を抑えることを意識
イメージ:
df_subm['target'] = ((df_table['target'].to_numpy() * 0.5) + \
(df_vit_sub["target"].to_numpy() * 0.5))
2. 画像モデル
ここからは、画像モデルについて話していきます。
2.1 設定
model: "maxvit_rmlp_pico_rw_256.sw_in1k"
batch_size: 128
max_epoch: 9
n_folds: 5
optimizer: optim.AdamW
scheduler: OneCycleLR
lr: 1.0e-04
weight_decay: 1.0e-02
img_size: 256
interpolation: cv2.INTER_LINEAR
CV: StratifiedGroupKFold with "patient_id"
バリデーションには患者のidを考慮してfoldを分割できるようにStratifiedGroupKFoldを使用しました。
2.2 モデル
モデルはtimmの事前学習済みモデルを使用しました。
過学習防止のため、Dropoutを多めに入れています。
self.model = timm.create_model(
model_name=model_name,
pretrained=pretrained,
in_chans=in_channels,
num_classes=num_classes,
global_pool=''
)
dim = CFG.output_dim_models[CFG.model_name]
self.dropout = nn.ModuleList([
nn.Dropout(0.5) for i in range(5)
])
self.target=DynamicLinear(out_size=1)
2.3 上手く行ったこと
2.3.1 2-stage learning
2-stage learning(転移学習)を利用しました。
正例が少ない問題に対処するため、2段階の学習を行いました。
- timmの事前学習モデルをバックボーンとしてISIC公式サイトで過去に蓄積された全てのデータを利用して学習
- 1のモデルを事前学習モデルとして、2024年度のデータのみで学習
これによって幅広い画像に対して特徴を抽出する機能を保ちながら、今回のデータに集中した予測を行うことが出来ます。
・timmの事前学習モデル: 一般的な画像の特徴抽出能力を提供
・1st stage モデル: 様々な皮膚画像の特徴抽出能力を提供
・2nd stage モデル: 今回のコンペのデータに集中した特徴抽出、予測能力を提供
この手法が最もCVの向上に貢献しました。
2.3.2 Augmentations
2020年のコンペ解法と、自分の実験の結果から効果がありそうなデータ拡張を選択していました。
過学習を防ぐためにデータ拡張は重要であると思っていたので、多くのパターンで検証を行いました。
augmentations_train = A.Compose([
A.Transpose(p=0.5),
A.VerticalFlip(p=0.5),
A.HorizontalFlip(p=0.5),
A.ColorJitter(brightness=0.2, contrast=0.2, p=0.3),
A.OneOf([
A.MotionBlur(blur_limit=5, p=0.5),
A.MedianBlur(blur_limit=5, p=0.5),
A.GaussianBlur(blur_limit=5, p=0.5),
], p=0.2),
A.GaussNoise(var_limit=(5.0, 30.0), p=0.1),
A.ShiftScaleRotate(shift_limit=0.1, scale_limit=0.1, rotate_limit=15, border_mode=0, p=0.3),
A.CoarseDropout(max_holes=20, min_holes=10, p=0.3),
A.Resize(CFG.img_size, CFG.img_size),
ToTensorV2(p=1)
])
2.3.3 標準化
A.Normalizeによる正規化の代わりに、標準化を行いました。
理由は入力画像の特性として、
- 画質が荒く、また衣類など関係のない物が写り込んでいることもあったため外れ値が多い
- 画像の明るさの影響で、同じ症状でもデータの分布がズレている可能性が高い
ことがあったため、外れ値や分布のズレに強い標準化を利用しました。
これはCVスコアを大きく向上させてくれました。
・正規化と標準化の違い
【Data Method】Normalization VS Standardization
# A.Normalize(
# mean=[0.485, 0.456, 0.406],
# std=[0.229, 0.224, 0.225],
# max_pixel_value=255.0,
# p=1.0
# ),
x, t = batch
if CFG.standardization:
x = (x - x.min()) / (x.max() - x.min() +1e-6) * 255
2.3.4 HSV入力
RGBに加えてHSVの6次元の入力を利用しました。
RGBの色のみに依存するよりも、彩度や明度なども考慮できた方が、過学習してしまう可能性が低いと考えて利用しました。
def F_rgb2hsv(rgb: torch.Tensor) -> torch.Tensor:
cmax, cmax_idx = torch.max(rgb, dim=1, keepdim=True)
cmin = torch.min(rgb, dim=1, keepdim=True)[0]
delta = cmax - cmin
hsv_h = torch.empty_like(rgb[:, 0:1, :, :])
cmax_idx[delta == 0] = 3
hsv_h[cmax_idx == 0] = (((rgb[:, 1:2] - rgb[:, 2:3]) / delta) % 6)[cmax_idx == 0]
hsv_h[cmax_idx == 1] = (((rgb[:, 2:3] - rgb[:, 0:1]) / delta) + 2)[cmax_idx == 1]
hsv_h[cmax_idx == 2] = (((rgb[:, 0:1] - rgb[:, 1:2]) / delta) + 4)[cmax_idx == 2]
hsv_h[cmax_idx == 3] = 0.
hsv_h /= 6.
hsv_s = torch.where(cmax == 0, torch.tensor(0.).type_as(rgb), delta / cmax)
hsv_v = cmax
return torch.cat([hsv_h, hsv_s, hsv_v], dim=1)
2.3.5 学習途中でのデータセットの変更
学習のepochが60%を超えたところで、データ拡張のないデータで訓練するようにしていました。
途中でデータセットを高精度なものに変えるのは、より細かい2-stage learningのように機能すると考えていましたが、データ拡張がないとモデルの一般性が低下する可能性があるため、これは使用しなくてもよかったかもしれません。
if CFG.change_dataset & epoch >= ((CFG.max_epoch+1) * 0.6):
train_loader = train_loader_noaugment
2.3.6 TTA(test time augmentation)
TTAは推論時の入力にデータ拡張を適用する方法で、推論の精度を高めるための手法です。
私はデータ拡張なしで推論した出力と、データ拡張ありで推論した出力を7:3の割合で統合するシンプルな手法を利用しました。
CVやLBに大きな変化はありませんでしたが、PBでは上手く機能しているようでした。
TTA_rate = {'None':0.7, 'with_train_aug':0.3}
# get_dataloader
val_transform_TTA, val_transform = get_transforms()
val_dataset = ISICDataset(df=train_meta[train_meta["fold"] == fold_id], fp_hdf=CFG.TRAIN_HDF5_COMBINED, transform=val_transform)
val_loader = torch.utils.data.DataLoader(val_dataset, batch_size=CFG.batch_size, num_workers=4, shuffle=False, drop_last=False)
if CFG.TTA:
val_dataset_TTA = ISICDataset(df=train_meta[train_meta["fold"] == fold_id], fp_hdf=CFG.TRAIN_HDF5_COMBINED, transform=val_transform_TTA)
val_loader_TTA = torch.utils.data.DataLoader(val_dataset_TTA, batch_size=CFG.batch_size, num_workers=4, shuffle=False, drop_last=False)
# prediction
oof_pred_arr_merged = (oof_pred_arr * CFG.TTA_rate['None']) + (oof_pred_arr_TTA * CFG.TTA_rate['with_train_aug'])
2.3.7 異常データの削除
このdiscussionで指摘されていた、布地のデータなど、明らかに関係のないデータを削除しました。
ids_to_drop = ['ISIC_0573025', 'ISIC_1443812', 'ISIC_5374420', 'ISIC_2611119', 'ISIC_2691718', 'ISIC_9689783', 'ISIC_9520696', 'ISIC_8651165', 'ISIC_9385142', 'ISIC_9680590', 'ISIC_2346081']
以上が主に行った手法になります。
3. 何が機能しなかったか
・オーバーサンプリング
positiveデータを1epoch中に複数回学習に利用する方法。positive rateを0.098%から0.3~1%程度まで引き上げましたが性能は向上しませんでした。
・補助ロス
画像以外の患者のデータを予測するヘッドを追加し、正解との誤差をLOSSに追加する手法。
・adaptive2dPoolの代わりにgemPoolを利用する
gemPool: 平均poolingとmaxpoolingの中間的手法で、どちらを強くするかについて、学習可能なパラメータで決定する。
・より大きなパラメータ数のvitモデル
maxvit_nanoやmaxvit_picoなどを試しましたが、CVスコアは逆に少し悪化しました。画像の解像度が低いため、過学習した可能性があります。
4. 環境
4.1 GPU
コンペ全体を通して、ローカルのRTX4070 ti superを利用していました。主にノートpcから自宅のPCへsshで使用する形をとっています。
コンペ終盤では、Runpod.ioやVast.aiといったクラウドGPUのサービスも利用していました。
あまり慣れておらず環境構築に手間取りましたが、どちらも使いやすいサービスでした。
特徴としては、vast.aiの方が価格が安いですが、runpodの方がスケールしやすく、UIなどが親切で利用しやすかったです。
クラウドGPUの環境構築の方法について気になる方は以下を確認してみて下さい。
・【Cloud GPU】How to use RunPod.io
・【Cloud GPU】How to use the Vast.ai
4.2 Wandb(実験管理)
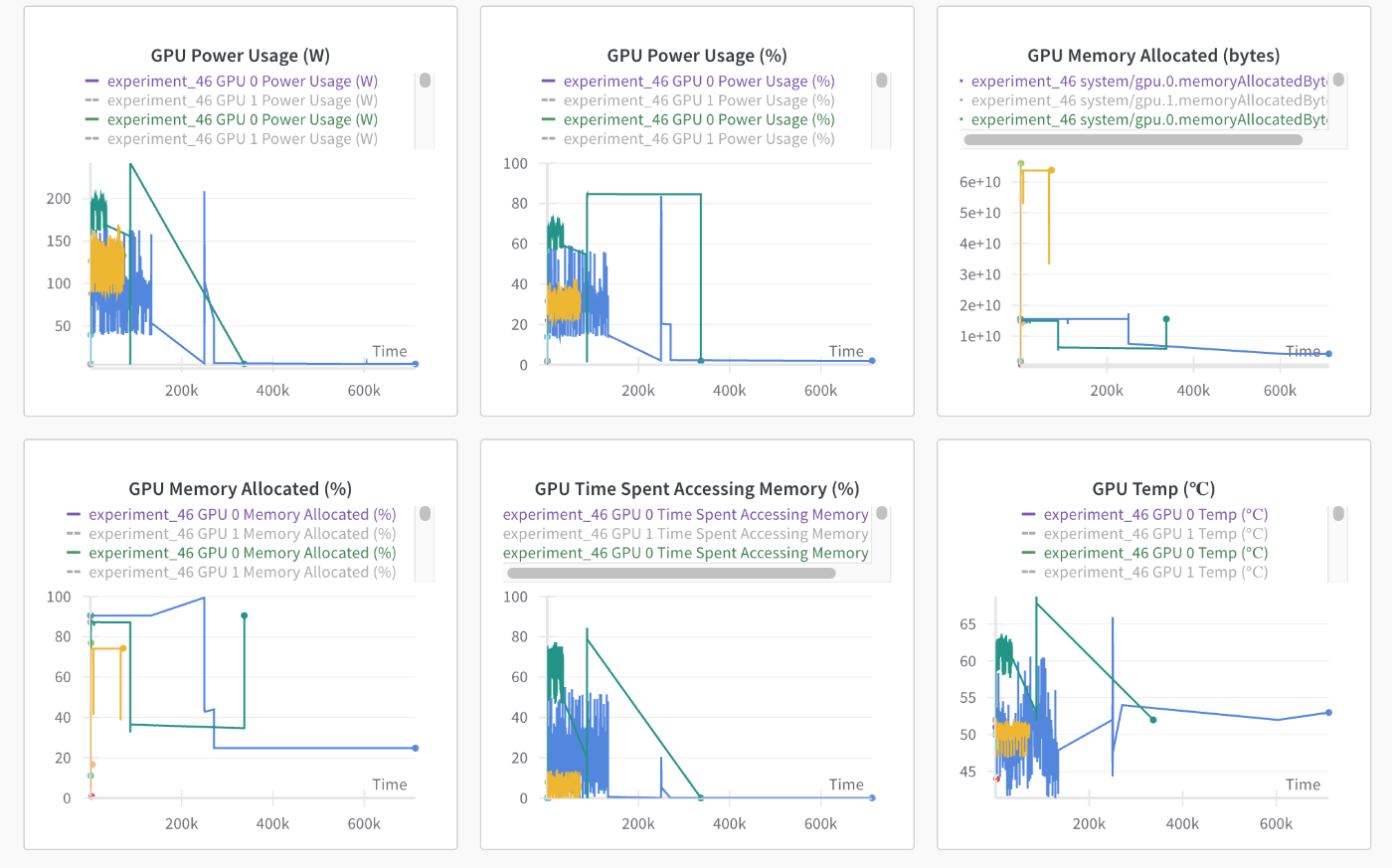
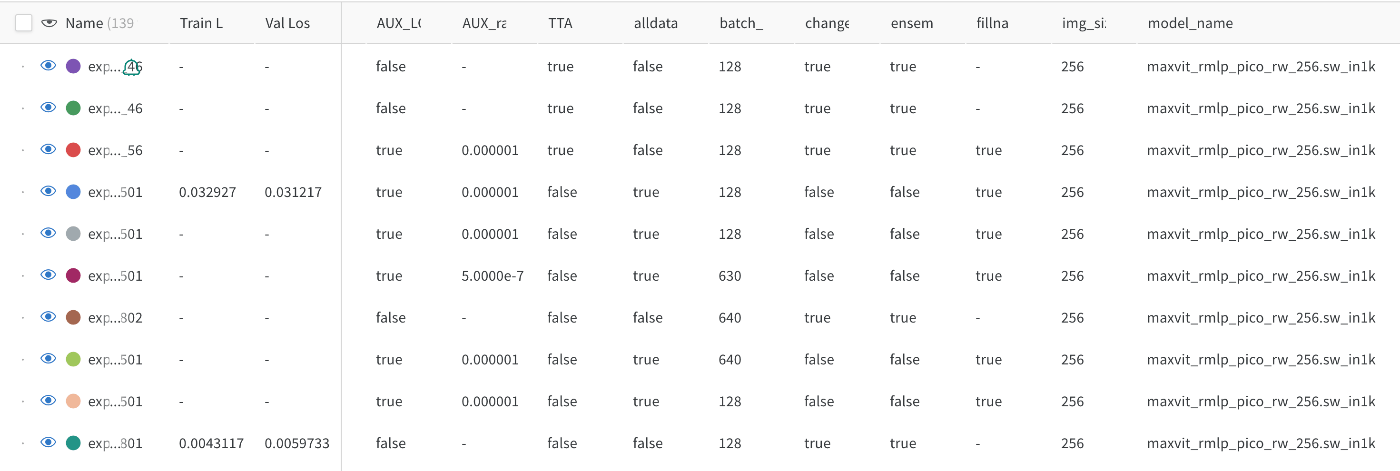
コンペ中盤からWandb(Weights and Biases)を利用して実験管理を行っていました。
実験の設定や特徴量、学習時間などをまとめて管理、さらに学習過程やGPUの状態の可視化も行うことができて非常に便利でした。
LEAPコンペでは、学習LOSSの可視化によって1epoch以内で既に過学習してしまっていることに気づいた人もいたらしく、モデル構築の助けになるツールだと思います。
Wandb解説
・【For Begginer】How to use wandb (Minimum Required)
・学習過程など

・GPUの状態
・実験設定
5. まとめ
本解法ではテーブルモデルとVITによる画像モデルのアンサンブルを使用しました。
コンペを通して、モデルが過学習しないように気をつけていました。
振り返りはここまでになります。読んでいただきありがとうございました!
参考
[1] ISIC 2024 - Skin Cancer Detection with 3D-TBP, Kaggle
Discussion
初めまして、Kaggle コンペがなにかもよくわかっていない AI 研究初心者です。
コンペお疲れさまでした。メダル獲得おめでとうございます。
少し、教えていただけないでしょうか。皮膚腫瘍の正診率を上げる手法として、素人考えですが、YOLOなどで病変をdetect してその部分を切り取り、より精度の高い architecture で学習させれば精度は上がると思いますがいかがでしょうか。しかし、YOLOで病変を検出する過程で、ある程度のアノテーション(バウンディングボックスを設定、ラベリング)を行い、YOLOデータとして検出モデルを作った場合、Kaggle 元画像を改変しないというレギュレーションに違反してしまうのでしょうか。
ありがとうございます。
YOLOによる病変の切り取りですが、提供画像がそもそも皮膚病変部でしたので、効果は少ないかと思われます...
画像の改変について、Kaggleの規則を完全に把握しているわけではありませんが、augmentationの範囲であれば問題ないと思います。
是非コンペに参加して、アイデアを試してみると良いと思います。
ご回答ありがとうございました。私は、病理組織の独自データから化学療法の感受性を予測するモデルを作成しています。Kaggle でメダルを取れるようなようなレベルではありませんが、Kaggle 挑戦してみたいと思います。私の環境では、1000枚程度の教師画像ですので、転移学習でいろいろなモデルを試してみましたが、ViT>EfficientNet_v2>>ConvNeXt>>swin_tarans でした。もっと修行を続けます。