【dbt】dbt
Wizard for dbt Core (TM)で「列、テーブル、参照の自動補完」機能が全く効かない症状
現象
-
analysesのフォルダでは何故か効かないことが特定できた-
analysesはdbt runの対象外になるフォルダ
-
-
modelsフォルダでは、問題なく動作する
対応
- ephemeral(cte)のフォルダーを作成して、そこで
analysesで作業するファイルを格納する
# dbt_project.yml
models:
dbt_pj:
work_dbt:
materialized: ephemeral
+schema: work_dbt
紹介する VSCode 拡張機能一覧
- Wizard for dbt Core (TM)
- dbt の Language Server
- BigQuery Runner
- VSCode 内から BigQuery にクエリ実行
- sqlfluff
- BigQuery, dbt にも対応した SQL Linter/Formatter
not found in dbt project(sqlfluff)のエラー
dbt テンプレートが機能するには、呼び出し元のディレクトリがsqlfluffdbt プロジェクトのルート ディレクトリである必要がある
- .sqlfluffをルートディレクトリに移動して解決
ショートカット効率化
クエリ実行→ドキュメントフォーマット→ファイル保存の一括実行
multi-commandを利用
// keybindings.json
[
{
"key": "shift+enter",
"command": "extension.multiCommand.execute",
"args": {
"sequence": [
"dbtPowerUser.executeSQL",
"editor.action.formatDocument",
"workbench.action.files.save",
],
}
}
]
dbt test
- dbtでエラー内容確認
--store-failures フラグ
dbt test --select モデル名 --store-failures
テスト内容確認クエリ
-- テストしない方をコメントアウトする
{# {% set check_flag = "not_null" %} #}
{% set check_flag = "unique" %}
{% set table = "table" %}
{% set column = "id" %}
SELECT *
FROM {{ ref(table) }}
{%- if check_flag == "not_null" %}
WHERE {{ column }} IS NULL
{% elif check_flag == "unique" %}
WHERE {{ column }} IN (
SELECT {{ column }}
FROM {{ ref(table) }}
GROUP BY {{ column }}
HAVING COUNT({{ column }}) > 1
)
{% endif -%}
ORDER BY {{ column }} ASC
dbt-osmosis
インストール
結局pip installした、packages.ymlに入れてインストールしても出来なかった。
dbt-osmosis
pip install -r requirements.txt
yml作成コマンド
- 一回、dbt build しないとファイルは作成されるが、カラムリストが生成されない
dbt-osmosis yaml refactor ./models/~フォルダ名
models:
jaffle_shop:
+dbt-osmosis: "{model}.yml" # _{model}.ymlとアンダーバー前に入れるよりファイルの並び的に良い
materialized: table
staging:
materialized: view
BigQueryのコンソール上でdescriptionを参照できるようにする
models:
+persist_docs:
relation: true
columns: true
relation を true にすると、テーブルのdescriptionが反映され、 columns を true にするとカラムのdescriptionが反映されます。
コマンド
dbt-osmosis yaml refactor ./models/~フォルダ名
dbt-osmosis yaml refactor --project-dir ... --profiles-dir ...
dbt-osmosis yaml organize --project-dir ... --profiles-dir ...
dbt-osmosis yaml document --project-dir ... --profiles-dir ...
_int_finance__models.yml
この構成を考えると
+dbt-osmosis: "_{node.schema}_{parent}__models.yml"
models:
jaffle_shop_duckdb:
+dbt-osmosis: "{node.database}/{node.schema}/{node.name}.yml"
materialized: table
staging:
materialized: view
seeds:
jaffle_shop_duckdb:
+dbt-osmosis: "{node.database}/{node.schema}/{node.name}.yml"
ベスプラを考えると
+dbt-osmosis: "_{parent}__models.yml"
✅ フォルダーごとに構成します。上記の例のように、[directory]__models.ymlモデル フォルダー内にディレクトリごとに作成し、そのディレクトリ内のすべてのモデルを構成します。ステージング フォルダーの場合は、[directory]__sources.ymlディレクトリごとにも含めます。
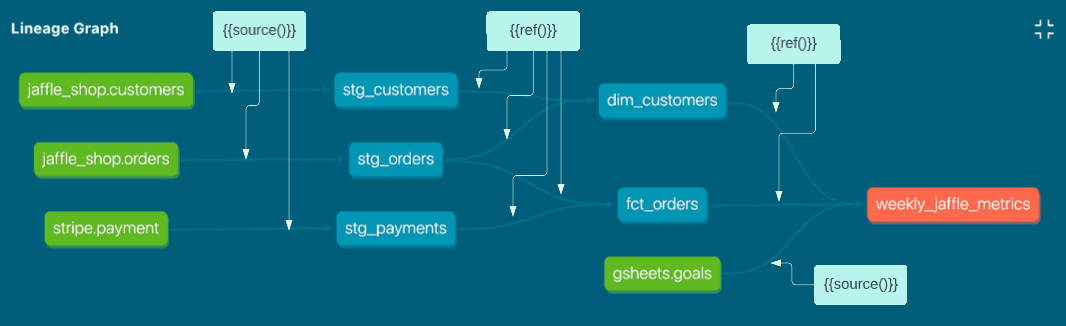
dbt ref() と source() の比較
source基本モデルで を使用し、それ以外はrefを使用する必要があります。
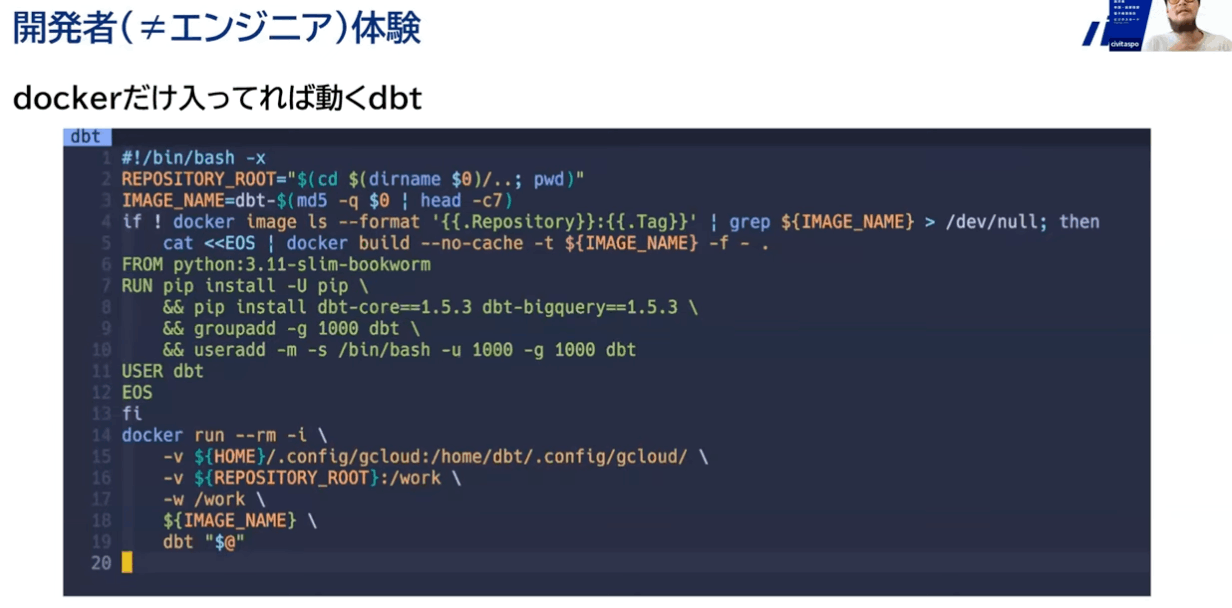
dbt (CLI) × BigQuery 〜Docker
- 【Docker初心者】Dockerfileの書き方について
このDockerfileは、Python 3.9をベースにしてdbt-bigqueryをインストールし、特定の環境設定を行うためのものです。以下に各セクションの解説を行います。
ベースイメージと引数の設定
FROM python:3.9.12-slim-bullseye
ARG dbt_bigquery_ref=dbt-bigquery@v1.0.0
- FROM: Python 3.9.12をベースにしたDebianのスリム版を使用。
- ARG: dbt-bigqueryのバージョンを指定する引数を定義(デフォルトはv1.0.0)。
システムのセットアップ
RUN apt-get update \
&& apt-get dist-upgrade -y \
&& apt-get install -y --no-install-recommends \
git \
ssh-client \
software-properties-common \
make \
build-essential \
ca-certificates \
libpq-dev \
vim \
&& apt-get clean \
&& rm -rf \
/var/lib/apt/lists/* \
/tmp/* \
/var/tmp/*
- apt-get update: パッケージリストを更新。
- apt-get dist-upgrade -y: システム全体を最新の状態にアップグレード。
-
apt-get install -y --no-install-recommends: 必要なパッケージをインストール。具体的には、
git、ssh-client、software-properties-common、make、build-essential、ca-certificates、libpq-dev、vim。 - apt-get clean: キャッシュをクリア。
- rm -rf: 不要なファイルを削除し、イメージのサイズを削減。
環境変数の設定
ENV PYTHONIOENCODING=utf-8
ENV LANG=C.UTF-8
- PYTHONIOENCODING: Pythonの入出力エンコーディングをUTF-8に設定。
- LANG: ロケールをUTF-8に設定。
Pythonのアップデート
RUN python -m pip install --upgrade pip setuptools wheel --no-cache-dir
- pip, setuptools, wheel: これらのパッケージを最新バージョンにアップグレード。
dbt-bigqueryのインストール
RUN python -m pip install --no-cache-dir "git+https://github.com/dbt-labs/${dbt_bigquery_ref}#egg=dbt-bigquery"
- dbt-bigquery: GitHubから指定されたバージョンのdbt-bigqueryをインストール。
設定ファイルのコピー
COPY profiles.yml /root/.dbt/profiles.yml
- profiles.yml: dbtの設定ファイルをコンテナ内の特定のディレクトリにコピー。
作業ディレクトリの設定とエントリポイント
WORKDIR /usr/app/dbt/
VOLUME /usr/app
ENTRYPOINT tail -f /dev/null
-
WORKDIR: デフォルトの作業ディレクトリを
/usr/app/dbt/に設定。 -
VOLUME: ホストの
/usr/appディレクトリをコンテナにマウント。 -
ENTRYPOINT: コンテナ起動後に
tail -f /dev/nullを実行し、コンテナを停止させずに保持。
このDockerfileは、dbt-bigqueryを使うための環境を整備し、設定ファイルを配置して、ユーザーが簡単にdbtの作業を始められるようにしています。
dbt (CLI) × BigQuery 〜Docker 環境構築
poetry dockerなどの情報
sqlfluffでフォーマットしたらエラー
User Error: The dbt templater does not support stdin input, provide a path instead
下記の設定いじってもダメだった
[sqlfluff:templater:dbt]
# 環境に合った設定をする
project_dir = ./
profiles_dir = ~/.dbt/
profile = dbt_project
target = dev
下記で解決
"sqlfluff.linter.run": "onSave",
"sqlfluff.experimental.format.executeInTerminal": true,
"sqlfluff.format.enabled": true
bigquery runnerで見ようとしたら
Query: Invalid value for location: is not a valid value
下記で解決
"bigqueryRunner.location": "asia-northeast1",
Dev Container とgithub




dbtスタイルガイドを活用しましょう
カラム名やデータ型は上流レイヤーで変換しましょう
積極的にカスタムスキーマを使用しましょう
スキーマ名やテーブル名に接頭字(raw_ , stg_ , fct_ , dim_ , mart_)を付けることが出来ます。
作成したモデルのリリース前に
次のコマンドでartifactsファイルから変更のあったモデルとそれに関連するモデルを判断し、runとtestを実行することが可能です。
dbt run -s state:modified+ --defer --state path/to/prod/artifacts
dbt test -s state:modified+ --defer --state path/to/prod/artifacts
post-hookを使ってテーブルの権限設定を行う
マテリアライゼーションのベストプラクティス
view → table → incremental
🔍ビューから始めましょう。ビューが長くなりすぎてエンドユーザーへのクエリが実行できなくなると、
⚒️ テーブルにします。テーブルが長すぎてdbtジョブに組み込めなくなったら、
📚 段階的に構築します。つまり、データが入るたびに、それをチャンク単位で重ねていきます。
{{
config(
materialized='view'
)
}}
select ...
BigQuery の構成
| 定義 | 項目 |
|---|---|
| ephemeral | データベースに直接組み込まれていない |
| table | モデルは実行ごとにテーブルとして再構築されます |
| view | モデルは実行ごとにビューとして再構築されます |
| materialized_view | ターゲットデータベース内でマテリアライズドビューの作成とメンテナンスが可能 |
| incremental | 増分モデルでは、モデルが最後に実行されてから、dbt がテーブルにレコードを挿入または更新できます。 |
{
"field": "<field name>",
"data_type": "<timestamp | date | datetime | int64>",
"granularity": "<hour | day | month | year>"
# Only required if data_type is "int64"
"range": {
"start": <int>,
"end": <int>,
"interval": <int>
}
}
Bigqueryのポリシータグはいずれやる
Bigqueryの現状のテーブル名一意になていいない
- dbtのモデルは一意であるべきなのに、Bigqueryのテーブルが一意になっていない
dbtのエイリアスを使用する
| Model | Config | Detabase Identifier |
|---|---|---|
| ga_sessions.sql | なし | "analitics"."ga_sessions" |
| ga_sessions.sql | {{ config(alias=sessions) }} |
"analytics"."sessions" |
- 引数:
- custom_alias_name:カスタムエイリアス名が指定されている場合にその値を使用します。
- node:dbtのモデルノード。ここからモデル名を取得します。
- target:ターゲットのスキーマ情報を含むオブジェクト。スキーマ名とモデル名を結合する際に使用されます。
- custom_alias_name=none は、引数 custom_alias_name の初期化を意味します。これは、関数やマクロが呼び出されたときに custom_alias_name に値が渡されなかった場合のデフォルト値として none を設定することを示しています。
- {{ custom_alias_name | trim }}:その値をトリム(前後の空白を削除)して返します。
bigqueryのテーブル名を長くしたくない
- dbtのモデル名(SQLファイル名)は一意である必要がある
- デフォルトでは、dbtのモデル名(SQLファイル名)と同じ名前でテーブル名が設定される
- それを回避するため、dbtのエイリアスの機能で、dbtのモデル名(SQLファイル名)と別の名前でテーブル名を設定できる
-
mrt_adsのデータセットにga4というテーブルを作成するとき、dbtのモデル名をmrt_ads_ga4にして、勝手に{{ config(alias='ga4'}}にして欲しい。そのためにマクロ作成
{% macro generate_alias_name(custom_alias_name=none, node=none, target=none) -%}
{%- if custom_alias_name -%}
{{ custom_alias_name | trim }}
{%- else -%}
{%- if node and target -%}
{%- set model_name = node.name -%}
{%- set schema_prefix = target.schema ~ "_" -%}
{%- if model_name.startswith(schema_prefix) -%}
{{ model_name[schema_prefix|length:] }}
{%- else -%}
{{ model_name }}
{%- endif -%}
{%- else -%}
{{ none }}
{%- endif -%}
{%- endif -%}
{%- endmacro %}
generate_alias_name マクロの説明
このマクロは、カスタムエイリアス名やモデルノードとターゲットから生成されたエイリアス名を返します。以下はマクロの各部分の説明です。
引数
-
custom_alias_name: カスタムエイリアス名が指定された場合、その値を使用します。 -
node: dbtのモデルノードで、ここからモデル名を取得します。 -
target: ターゲットのスキーマ情報を含むオブジェクトで、スキーマ名とモデル名を結合する際に使用されます。
処理の流れ
-
カスタムエイリアス名が指定されている場合 (
custom_alias_nameが存在する場合):- 指定された
custom_alias_nameをトリムしてそのまま返します。
- 指定された
-
カスタムエイリアス名が指定されていない場合 (
custom_alias_nameがない場合):-
nodeとtargetが指定されている場合、以下の処理を行います:-
node.nameからモデル名を取得します。 -
target.schemaからスキーマ名を取得し、スキーマ名とアンダースコアを結合してプレフィックス (schema_prefix) を作成します。 - モデル名が
schema_prefixで始まる場合、schema_prefixの長さだけをスライスして、プレフィックスを削除したモデル名を返します。 - モデル名が
schema_prefixで始まらない場合、モデル名をそのまま返します。
-
-
-
nodeとtargetのいずれも指定されていない場合:-
noneを返します。
-
パターン表
| カスタムエイリアス名 | node.name | target.schema | 生成されるエイリアス名 | BigQuery上の表記 |
|---|---|---|---|---|
custom_alias |
model_name |
schema |
custom_alias |
schema.custom_alias |
null |
model_name |
schema |
model_name |
schema.model_name |
null |
schema_model |
schema |
model |
schema.model |
null |
test_model |
test_schema |
test_model |
test_schema.test_model |
null |
schema_test |
schema |
test |
schema.test |
完成品
dbtでディレクトリ名をBigQueryのデータセット名に設定する
macros/generate_schema_name.sql
{% macro generate_schema_name(custom_schema_name, node) -%}
{%- if custom_schema_name is none -%}
{{ target.schema }}
{%- else -%}
{{ custom_schema_name | trim }}
{%- endif -%}
{%- endmacro %}
完成品
macros/generate_alias_name.sql
{% macro generate_alias_name(custom_alias_name, node) -%}
{%- if custom_alias_name -%}
{{ custom_alias_name | trim }}
{%- else -%}
{%- set schema_name = node.schema -%}
{%- set model_name = node.name -%}
{%- set schema_prefix = schema_name ~ "_" -%}
{%- if model_name.startswith(schema_prefix) -%}
{{ model_name[schema_prefix|length:] }}
{%- else -%}
{{ model_name }}
{%- endif -%}
{%- endif -%}
{%- endmacro %}
dbt
models
└── mrt_ads(ディレクトリ)
├── mrt_ads_ga4(モデル: mrt_ads_ga4、エイリアス: ga4)
└── mrt_ads_yahoo(モデル: mrt_ads_yahoo、エイリアス: yahoo)
- モデル名:dbtのクエリファイル名(一意である必要がある)
- エイリアス名:Bigqueryに作成するテーブル名
- モデル名と重複はNG(エイリアス: yahooがある場合、モデル名でyahooが使えない)
- 基本このルールで書いていたら重複しないと思う
- モデル名と重複はNG(エイリアス: yahooがある場合、モデル名でyahooが使えない)
Bigquery
mrt_ads(データセット)
├── ga4(テーブル)
└── yahoo(テーブル)
dwh_ads(データセット)
├── ga4(テーブル)
└── yahoo(テーブル)
- Pros
- Bigquery上でテーブル名の重複が可能
- dbt導入前のテーブル管理がこれなので、テーブル名を変えなくてdbtを部分導入できるのは良い
- テーブル名の表記が長くならない
- クエリ書いた時に、どこのデータセットにあるテーブルかわかりやすい
- Bigquery上でテーブル名の重複が可能
select *
from {{ ref("mrt_ads_yahoo") }}
mrt_ads_yahooがmrt_ads__yahooでアンダーバー2個の方が安全かも
このtag付参考にしよう
models:
kawaii_dbt:
dwh:
+schema: dwh
+ tags:
- "dwh"
ml:
+schema: ml
+tags:
- "ml"
別のプロジェクトにデータセットを作成したい時
dbtのデータベースは、BQで言うところのプロジェクト
結局、troccoでは無理でした。
dataset_id:
+materialized: table
+database: project_id
+schema: dataset_id
dbtジョブ設定
dbt
models
└── mrt_ads(ディレクトリ)
├── mrt_ads_ga4(モデル: mrt_ads_ga4、エイリアス: ga4)
└── mrt_ads_yahoo(モデル: mrt_ads_yahoo、エイリアス: yahoo)
dbt build --select models/mrt_ads

mrt_adsの中で、マスターなど頻繁に更新しないモデルを別のタイミングでビルドしたい
dbt build --select models/mrt_ads
{{ config(
tags=["mst"]
) }}
select * from {{ ref('bbb') }}
特定のディレクトリのタグがmstのやつ実行
dbt run --select models/mrt_ads,tag:mst
特定のディレクトリのタグがmstのないやつ実行
dbt run --select models/mrt_ads --exclude tag:mst
dbt seed
seeds_csvというデータセットにまとめる方針
seeds_jsonもあっても良いかも
データソースごとにデータセットを分けているのでこうなった
seeds
└── seeds_csv(ディレクトリ)
├── seeds_csv__list.csv(モデル: seeds_csv__list、エイリアス: list)
└── seeds_csv__list.yml
seeds_csv__list.yml
version: 2
seeds:
- name: seeds_csv__list
description: |
説明を書く
dbt_project.yml
seeds:
dbt_project:
+full_refresh: true
+persist_docs:
relation: true
columns: true
seeds_csv:
+schema: seeds_csv
BQに日付が入らない
入らない→2024-08-29T07:50:46.704573Z
入った→2024-08-29T07:50:46
df['last_login'] = pd.to_datetime(df['last_login']).dt.strftime('%Y-%m-%dT%H:%M:%S')
Error while reading data, error message: CSV processing encountered too many errors, giving up. Rows: 7; errors: 7; max bad: 0; error percent: 0
Error while reading data, error message: Invalid datetime string "2024-08-19T01:48:37.696484Z"; line_number: 2 byte_offset_to_start_of_line: 209 column_index: 3 column_name: "last_login" column_type: DATETIME value: "2024-08-19T01:48:..."
You are loading data without specifying data format, data will be treated as CSV format by default. If this is not what you mean, please specify data format by --source_format.
dbtのincremental modelを用いたBigQueryの差分更新
挙動を確認する
- ソーステーブル
| id | name | created_at |
|---|---|---|
| 1 | aaa | 2024-04-01 |
| 2 | aaa | 2024-04-01 |
| 3 | ccc | 2024-04-02 |
| 4 | ddd | 2024-04-02 |
| 5 | eee | 2024-04-03 |
| 6 | fff | 2024-04-03 |
| 7 | ggg | 2024-04-04 |
| 8 | hhh | 2024-04-04 |
| 9 | iii | 2024-04-05 |
| 10 | jjj | 2024-04-06 |
- 宛先テーブル
| id | name | created_at |
|---|---|---|
| 1 | aaa | 2024-04-01 |
| 2 | bbb | 2024-04-01 |
| 3 | ccc | 2024-04-02 |
| 4 | ddd | 2024-04-02 |
| 5 | eee | 2024-04-03 |
| 6 | fff | 2024-04-03 |
| 7 | aaa | 2024-04-04 |
{{ config(
materialized = 'incremental',
incremental_strategy = 'insert_overwrite',
partition_by = {
'field': 'created_at',
'data_type': 'date',
'granularity': 'day',
'copy_partitions': true
}
) }}
SELECT *
FROM `ソーステーブル`
{% if is_incremental() %}
WHERE created_at BETWEEN '2024-04-05' AND '2024-04-06'
{% endif %}
- 実行後、宛先テーブル
| id | name | created_at |
|---|---|---|
| 1 | aaa | 2024-04-01 |
| 2 | bbb | 2024-04-01 |
| 3 | ccc | 2024-04-02 |
| 4 | ddd | 2024-04-02 |
| 5 | eee | 2024-04-03 |
| 6 | fff | 2024-04-03 |
| 7 | aaa | 2024-04-04 |
| 9 | iii | 2024-04-05 |
| 10 | jjj | 2024-04-06 |
- この処理で、BQに投げられるクエリ
| jst | table | query |
|---|---|---|
| 2024-08-09 23:37:41 | 宛先テーブル__dbt_tmp | /* {"app": "dbt", "dbt_version": "1.8.3", "profile_name": "dbt_project", "target_name": "dev", "node_id": "宛先テーブル"} */ select distinct date(created_at) from 宛先テーブル__dbt_tmp
|
| 2024-08-09 23:37:39 | ソーステーブル | /* {"app": "dbt", "dbt_version": "1.8.3", "profile_name": "dbt_project", "target_name": "dev", "node_id": "宛先テーブル"} */ create or replace table 宛先テーブル__dbt_tmp partition by created_at OPTIONS( description="""""", expiration_timestamp=TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL 12 hour) ) as ( SELECT * FROM ソーステーブル WHERE created_at BETWEEN '2024-04-05' AND '2024-04-06' ); |
SELECT
FORMAT_TIMESTAMP('%Y-%m-%d %H:%M:%S', creation_time, 'Asia/Tokyo') as jst,
concat(
referenced_table.project_id,"."
,referenced_table.dataset_id,"."
,referenced_table.table_id) as table,
query
FROM `project_id`.`region-asia-northeast1`.INFORMATION_SCHEMA.JOBS_BY_PROJECT,
UNNEST(referenced_tables) AS referenced_table
WHERE DATE(creation_time) > DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)
ORDER BY creation_time DESC
limit 10
{% if is_incremental() %}書いてない挙動を確認する
{{ config(
materialized = 'incremental',
incremental_strategy = 'insert_overwrite',
partition_by = {
'field': 'created_at',
'data_type': 'date',
'granularity': 'day',
'copy_partitions': true
}
) }}
SELECT *
FROM `ソーステーブル`
- 実行後、宛先テーブル
- {% if is_incremental() %}書いてないと、リプレイスされる
| id | name | created_at |
|---|---|---|
| 1 | aaa | 2024-04-01 |
| 2 | aaa | 2024-04-01 |
| 3 | ccc | 2024-04-02 |
| 4 | ddd | 2024-04-02 |
| 5 | eee | 2024-04-03 |
| 6 | fff | 2024-04-03 |
| 7 | ggg | 2024-04-04 |
| 8 | hhh | 2024-04-04 |
| 9 | iii | 2024-04-05 |
| 10 | jjj | 2024-04-06 |
copy_partitions: trueこれは理にかなっています。bigquery のコピーは無料なので、0 バイトは正しいのですが、一時テーブルの構築は最終的には無料ではないため、最終的には予想外です。
直近〜ヶ月のデータを最新化の場合
- 転送先のテーブルが
"granularity": "day",だと時間かかる
03:21:24.855948 [debug] [Thread-1 (]: BigQuery adapter: Copying table(s) "/projects/project_id/datasets/dataset_id/tables/ad_report__dbt_tmp$20231205" to "/projects/project_id/datasets/dataset_id/tables/ad_report$20231205" with disposition: "WRITE_TRUNCATE"
日毎にWRITE_TRUNCATEされるので遅い
- 転送先のテーブルを
"granularity": "month",でパーティション設定する必要がある- 月毎にWRITE_TRUNCATEされる
03:35:24.902314 [debug] [Thread-1 (]: BigQuery adapter: Copying table(s) "/projects/project_id/datasets/dataset_id/tables/ad_report__dbt_tmp$202404" to "/projects/project_id/datasets/dataset_id/tables/ad_report$202404" with disposition: "WRITE_TRUNCATE"
- 全データ
- [CREATE TABLE (10.1k rows, 3.6 MiB processed) in 5.22s]
- 直近12ヶ月を最新化
-
"granularity": "day",:[None (0 processed) in 558.46s] -
"granularity": "month",:[None (0 processed) in 24.34s]
-
スレッド数
- threads: 1、dbt は 1 つのモデルのみの構築を開始し、それを完了してから次のモデルに進みます。
- 設定できるスレッドの最大数に制限はありません。
- 最初は 4 に設定することをお勧め
- スレッド数を増やすとウェアハウスの負荷が増加し、データ スタック内の他のツールに影響する可能性があります。
- troccoのdbt連携で設定できるスレッド数の上限は16
レコード数の出力
dbtで解決したい課題。
- 125.9k rowsではなく完全なレコード数を出力したい。
- "copy_partitions": trueだと全くレコード数取れないので転送したレコード数表示したい
{% macro log_order_items() %}
{%- call statement('count_order_items', fetch_result=True) -%}
SELECT count(*) as count from {{ this }}
{%- endcall -%}
{%- set total_order_items = load_result('count_order_items') -%}
{% if execute %}
{{ log(modules.datetime.datetime.now().strftime('%H:%M:%S') ~ ' | Number of rows transformed ' ~ total_order_items['data'][0][0] ~ ' rows into a table', True) }}
{% endif %}
select 1
{% endmacro %}
"copy_partitions": trueなんでNone (0 processed)になってます
01:05:34 1 of 1 START sql incremental model work_dbt.aaaaa ............................. [RUN]
01:05:36 01:05:36 | Number of rows transformed 2714 rows into a table
01:05:45 1 of 1 OK created sql incremental model work_dbt.aaaaa ........................ [None (0 processed) in 10.92s]
増分モデルの列が変更された場合
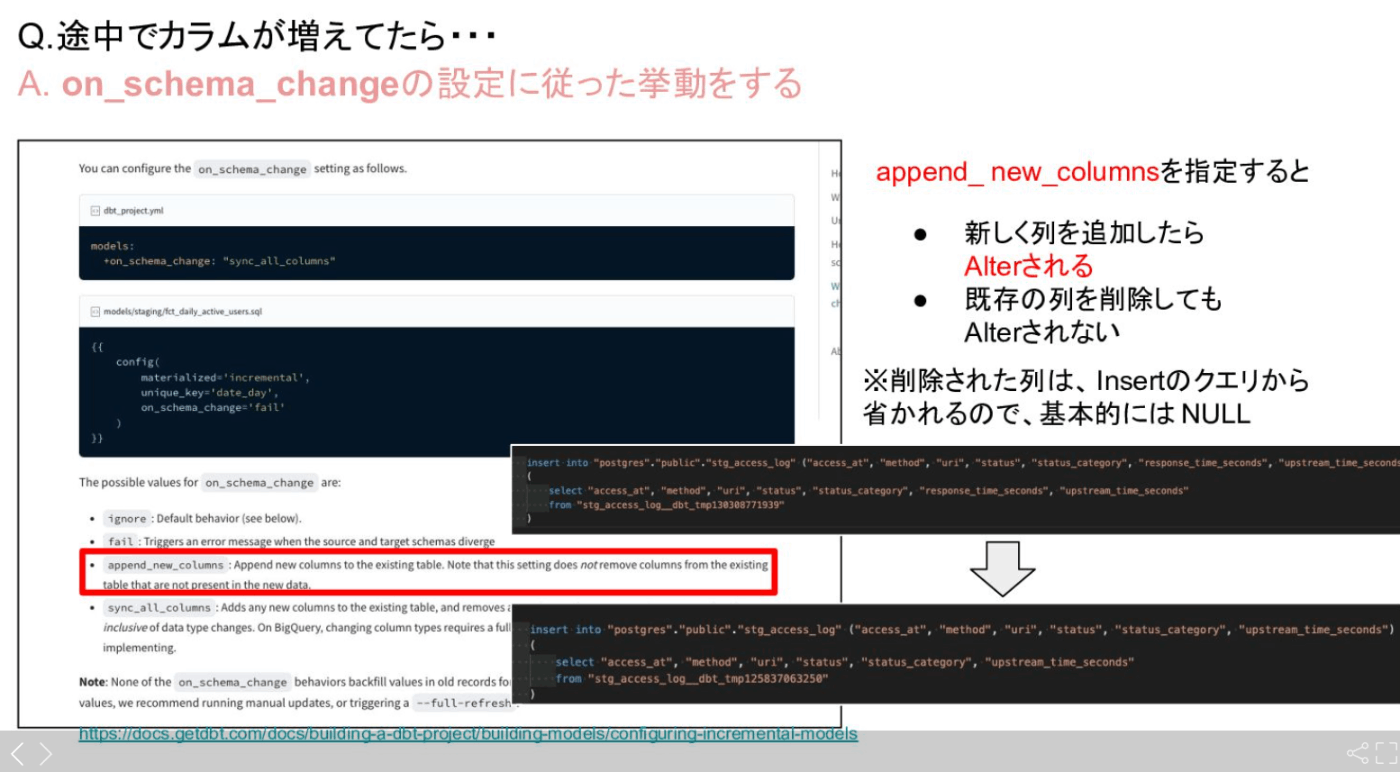
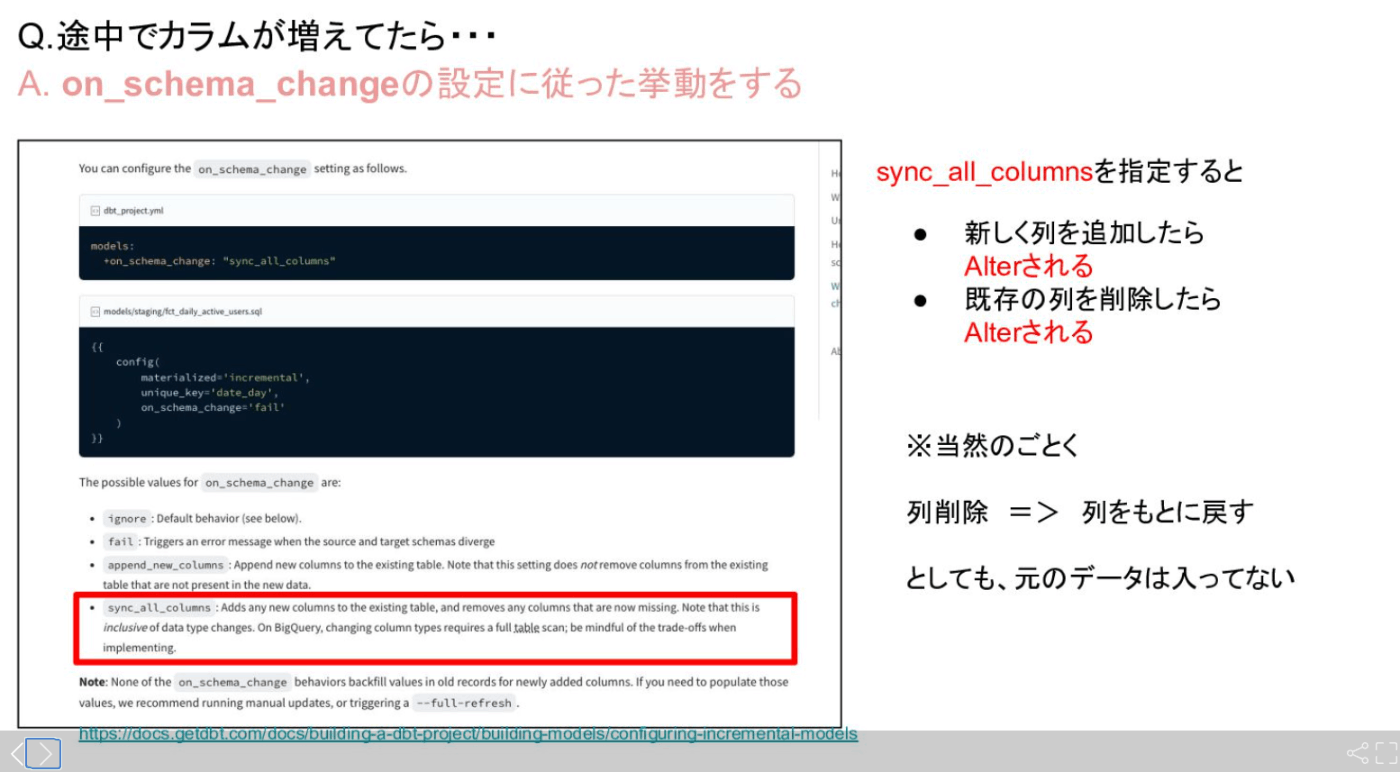
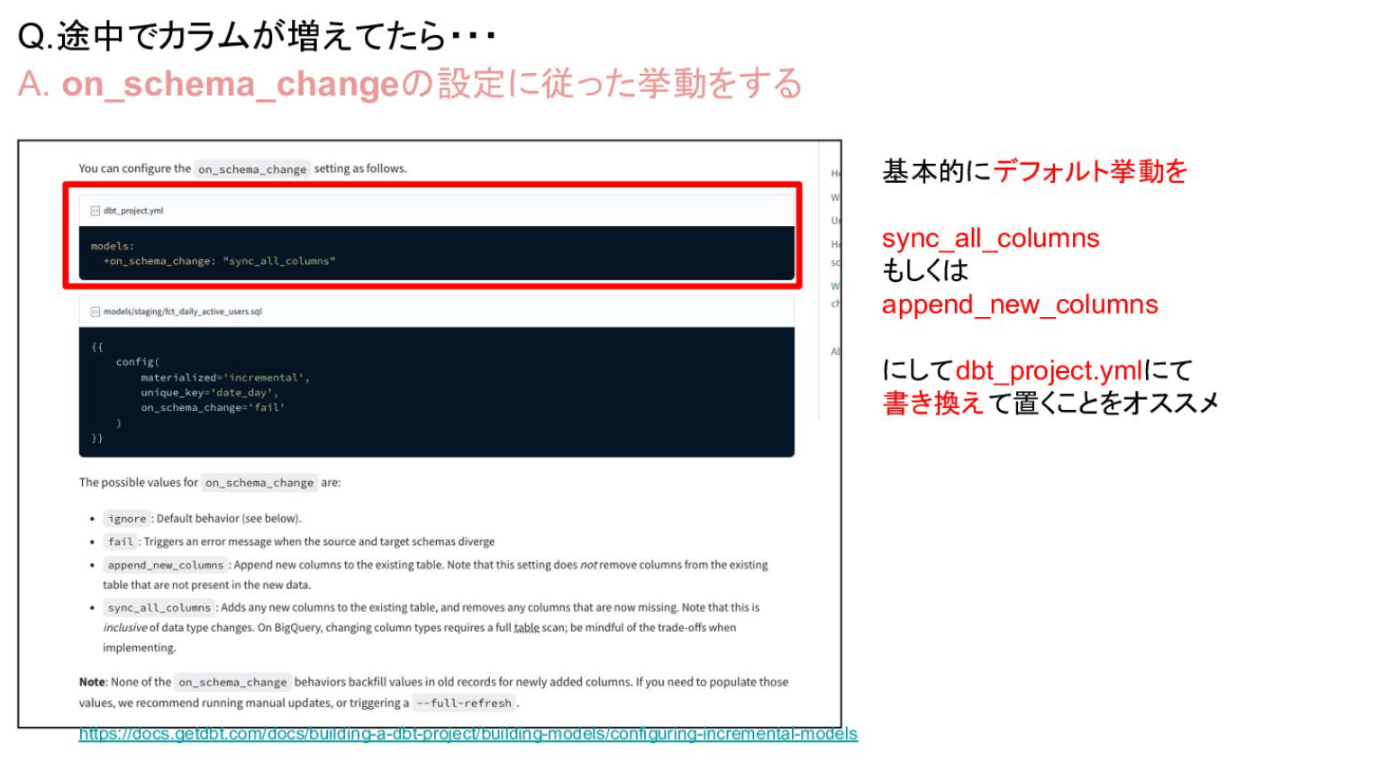
models:
+on_schema_change: "append_new_columns"
dbt docs
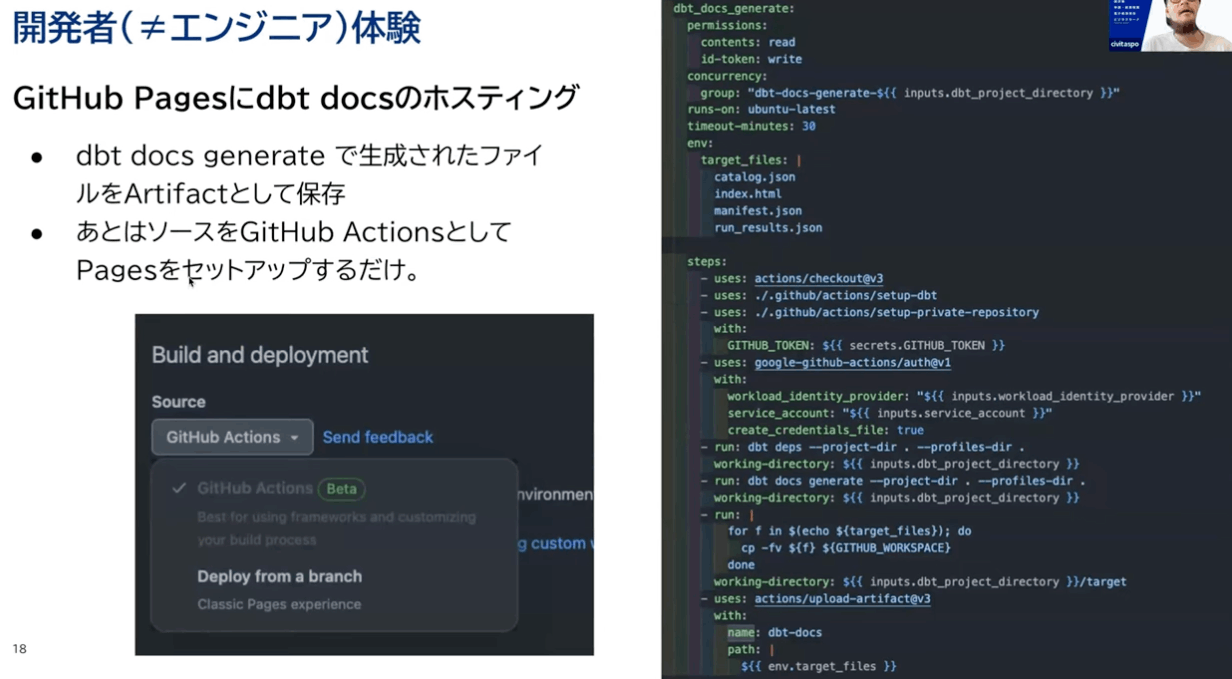
dbt docs generate --staticのコマンドがあるなんて知らなかったわ、これでGCSにdbt docsを静的ファイルにして置けるぜ!
トップページの編集
models配下にoverview.mdというマークダウンファイルを作成し、以下内容を入れます。
{% docs __overview__ %}
### Welcome!
dbtプロジェクトの自動生成ドキュメントへようこそ!
### Navigation
ウィンドウの左側にあるプロジェクトとデータベースのナビゲーションタブを使って、プロジェクト内のモデルを調べることができます。
#### Project Tab
プロジェクトタブはdbtプロジェクトのディレクトリ構造を反映しています。このタブでは、dbtプロジェクトで定義されたすべてのモデル、およびdbtパッケージからインポートされたモデルを見ることができます。
#### Database Tab
データベースタブにもモデルが表示されますが、よりデータベースエクスプローラーに近い形式で 表示されます。このビューには、データベーススキーマにグループ化されたリレーション(テーブルとビュー)が表示されます。エフェメラルモデルはデータベースに存在しないため、このインターフェースには表示されないことに注意してください。
### グラフ探索
ページの右下にある青いアイコンをクリックすると、モデルの系統グラフを見ることができます。
モデルのページでは、探索中のモデルの直接の親と子が表示されます。この血統ペインの右上にある「展開」ボタンをクリックすると、現在調べているモデルを構築するために使用された、あるいは構築されたすべてのモデルを見ることができます。
一度展開されると、`--select` や `--exclude` のモデル選択構文を使って、グラフ内のモデルをフィルタリングすることができるようになります。モデル選択の詳細については、dbtの[ドキュメント](https://docs.getdbt.com/reference/node-selection/syntax)を参照してください。
また、モデルを右クリックすることで、グラフをインタラクティブにフィルタリングしたり、探索したりすることもできます。
------
### More information
- [What is dbt](https://docs.getdbt.com/docs/introduction)?
- Read the [dbt viewpoint](https://docs.getdbt.com/docs/viewpoint)
- [Installation](https://docs.getdbt.com/docs/installation)
- Join the [dbt Community](https://www.getdbt.com/community/) for questions and discussion
{% enddocs %}
自動化参考


freshness最初にやるべきらしい

次にこれらしい

それが出来てかっこいい実装らしい
データ基盤のリリースノートしたい
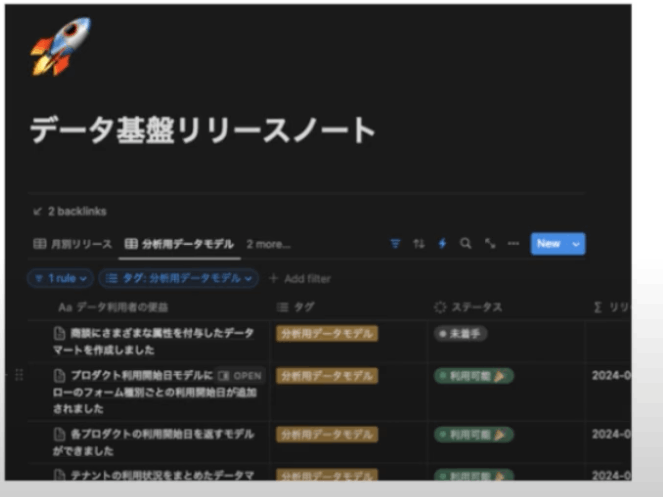
監査ログとBigQuery InformationSchemaを用いたdbt exposureの自動生成
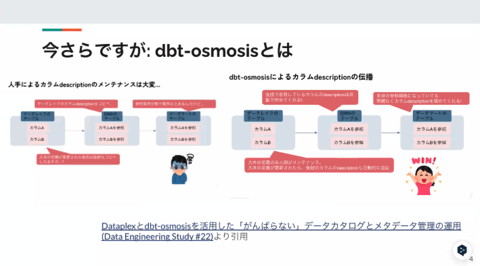
dbt-osmois
yamlディスクリプションだけでクエリかけるんだろうか、業務フローとか、ER図がないとクエリ書けないんですが、皆さんはどうなのか
- 業務フロー:ディメンショナルモデリングでユーザーが使いやすいように、ユーザーが同意がある
- ER図 : リレーションテストで確認する
週イチ運用いいね
ignoreで型伝播止める
全日本dbt-osmosisを愛でる会 (2024/08/26 18:30〜)
dbt CI改善
dbt-audit-helper は 2 つのテーブルを比較し、その差分を出力するツールです。 dbt-profiler は dbt の profile を出力するツールです。 markdown のテーブル形式で各モデルのカラムの統計量を出力することが可能です。
構想
- プルリクエスト時に該当クエリが新規か変更か判別
- 変更だったらテスト環境にフルリフレッシュでテーブル作成
- 既存のテーブルと作成したテーブルを比較
- 比較結果をプルリクエストにコメントする
dbtのカスタムスキーマ機能を用いて開発ブランチごとにスキーマを生成する形
Gitフックを使う方法
Gitのフックを利用して、ブランチ切り替え時に自動的に環境変数を設定する方法もあります。post-checkout フックを使うことで、ブランチの切り替え後にスクリプトが自動実行されるように設定できます。
-
.git/hooks/post-checkoutに以下のスクリプトを追加します:
Terminal上で作業します。
# ファイルの場所確認(パス確認、出力パスで以下実行)
git rev-parse --git-dir
# post-checkoutファイルの作成
touch .git/hooks/post-checkout
# 実行権限を付与
chmod +x .git/hooks/post-checkout
# ファイルを編集(VScodeの場合)
code .git/hooks/post-checkout
#!/bin/bash
# 現在のブランチ名を取得し、/を_に変換
export CURRENT_BRANCH=$(git rev-parse --abbrev-ref HEAD | sed 's/\//_/g')
# 環境変数をシェルにエクスポートするために ~/.bashrc に追加
echo "export CURRENT_BRANCH=$CURRENT_BRANCH" >> ~/.bashrc
# シェル環境をリロード
source ~/.bashrc
# 確認のために表示
echo "CURRENT_BRANCH is set to $CURRENT_BRANCH"
この方法により、ブランチを切り替えるたびにCURRENT_BRANCH環境変数が自動的に更新されます。
{% macro generate_schema_name(custom_schema_name, node) -%}
{%- set default_schema = env_var('CURRENT_BRANCH') | target.schema -%}
{%- if default_schema=='main' or default_schema=='develop' -%}
{%- if custom_schema_name is none -%}
{{ target.schema }}
{%- else -%}
{{ custom_schema_name | trim }}
{%- endif -%}
{%- else -%}
{{ default_schema }}_{{ custom_schema_name | trim }}
{%- endif -%}
{%- endmacro %}
開発環境事例
dbtで見やすいER図を生成する
dbt-audit-helper
- package: dbt-labs/audit_helper
version: 0.12.0
dbt-audit-helper は 2 つのテーブルを比較し、その差分を出力するツールです
$ dbt deps
↓これだといける
{{
audit_helper.compare_all_columns(
a_relation=api.Relation.create(database='DEMO', schema='CORE', identifier='dim_orgs'),
b_relation=ref('dim_orgs'),
primary_key='org_id',
summarize=true
)
}}
↓できない
{% set old_relation = adapter.get_relation(
database = "old_database",
schema = "old_schema",
identifier = "fct_orders"
) -%}
{% set dbt_relation = ref('fct_orders') %}
{{ audit_helper.compare_all_columns(
a_relation = old_relation,
b_relation = dbt_relation,
primary_key = "order_id"
) }}
if executeでいけた。
{% set old_relation = adapter.get_relation(
database = "old_database",
schema = "old_schema",
identifier = "fct_orders"
) -%}
{% set dbt_relation = ref('fct_orders') %}
{% if execute %}
{{ audit_helper.compare_all_columns(
a_relation = old_relation,
b_relation = dbt_relation,
primary_key = "order_id"
) }}
{% endif %}
マクロ化
CLIでの実行
dbt run-operation audit_orders --args '{"old_database": "old_database_name", "old_schema": "old_schema_name", "old_identifier": "old_fct_orders", "dbt_identifier": "fct_orders"}'
{% macro audit_orders(old_database, old_schema, old_identifier, dbt_identifier) %}
{% set old_relation = adapter.get_relation(
database = old_database,
schema = old_schema,
identifier = old_identifier
) -%}
{% set dbt_relation = ref(dbt_identifier) %}
{% if execute %}
{# 2つのリレーションが同一かどうかを比較 #}
{% set check_query = audit_helper.quick_are_relations_identical(
a_relation = old_relation,
b_relation = dbt_relation,
columns = None
) %}
{% set results = run_query(check_query) %}
{% set is_identical = results.columns[0].values()[0] %}
{# お好みの表示どっちか #}
{% do results.print_table() %}
{% do log(results.column_names[0] ~ " : " ~ is_identical, info=True) %}
{# 比較結果をログに出力 #}
{% if is_identical %}
{% do log(dbt_identifier ~ " : テーブルは同一です。", info=True) %}
{% else %}
{% do log(dbt_identifier ~ " : テーブルは一致していません。", info=True) %}
{% endif %}
{% endif %}
{% endmacro %}
run_queryの戻り値は agateと呼ばれるPythonモジュールのTableオブジェクトになります。
{% macro queries_identical(old_model, new_model) %}
{% set new_model_relation = ref(new_model) %}
{% set column_list = adapter.get_columns_in_relation(new_model_relation) | map(attribute='name') | list %}
{% do log("Comparing columns: " ~ column_list, info=True) %}
{% set old_query %}
select * from {{ ref(old_model) }}
{% endset %}
{% set new_query %}
select * from {{ ref(new_model) }}
{% endset %}
{% if execute %}
{# 比較用クエリを生成 #}
{% set check_query = audit_helper.quick_are_queries_identical(
query_a=old_query,
query_b=new_query,
columns=column_list
) %}
{# 比較結果を取得 #}
{% set results = run_query(check_query) %}
{% set is_identical = results.columns[0].values()[0] %}
{# 比較結果をログに出力 #}
{% if is_identical %}
{% do log("✔ クエリが一致しています: " ~ old_model ~ " = " ~ new_model, info=True) %}
{% else %}
{% do log("✘ クエリが一致していません: " ~ old_model ~ " ≠ " ~ new_model, info=True) %}
{% endif %}
{% endif %}
{% endmacro %}
dbt run-operation queries_identical --args '{"old_model": "old_model", "new_model": "new_model"}'
with query_a as (
)
, query_b as (
)
select count(distinct hash_result) = 1 as are_tables_identical
from (
select bit_xor(farm_fingerprint(to_json_string(query_a))) as hash_result
from query_a
union all
select bit_xor(farm_fingerprint(to_json_string(query_b))) as hash_result
from query_b
) as hashes
WITH new_table AS (
),
old_table AS (
)
SELECT
'new_table' AS source_table,
*
FROM (
SELECT * FROM new_table
EXCEPT DISTINCT
SELECT * FROM old_table
)
UNION ALL
SELECT
'old_table' AS source_table,
*
FROM (
SELECT * FROM old_table
EXCEPT DISTINCT
SELECT * FROM new_table
)
model間でref()で参照していないけれど、強制的に依存関係を定義したい
To address this, you can use a SQL comment along with the ref function — dbt will understand the dependency, and the compiled query will still be valid:
-- depends_on: {{ ref('upstream_parent_model') }} {{ your_macro('variable') }}
なんとコメントでdepends_on: {{ ref('upstream_parent_model') }}と書いておけば勝手に認識してくれるみたいです、便利!
フォーマッター設定
dbt cloudと同じにしとくのがいいでしょ
// sqlfmt
"[jinja-sql]": {
"editor.tabSize": 4,
"editor.insertSpaces": true,
"editor.defaultFormatter": "innoverio.vscode-dbt-power-user",
"editor.formatOnSave": true
},
// Prettier
// https://docs.getdbt.com/docs/cloud/dbt-cloud-ide/lint-format
// YAML、Markdown、JSON — Prettierでフォーマットします。
"[json]": {
"editor.defaultFormatter": "esbenp.prettier-vscode",
"editor.formatOnSave": true
},
"[yaml]": {
"editor.defaultFormatter": "esbenp.prettier-vscode",
"editor.formatOnSave": true
},
"[markdown]": {
"editor.defaultFormatter": "esbenp.prettier-vscode",
"editor.formatOnSave": true
},
// Python は Black を使う
// https://docs.getdbt.com/docs/cloud/dbt-cloud-ide/lint-format
"[python]": {
"editor.defaultFormatter": "ms-python.black-formatter",
"editor.formatOnSave": true
},