はじめに
こんにちは、ラクスル株式会社 Data Engineeringチームの梅田です。
データエンジニアとして主にデータ基盤の開発・運用を担当しています。
こちらの記事を書いた飯島さんと一緒に働いています。
我々のチームが扱うデータ基盤は順調にデータ量が増えてきており、全件洗い替えする運用だとコスト的に厳しくなってくるのが見えてきました。
そこで、dbtのincremental modelを用いたBigQueryの差分更新処理を導入することになりました。
この記事では、dbtのincremental modelについて簡単に説明します。
insert_overwrite戦略については簡単な例を挙げて説明します。
この記事はこんな方におすすめ
- BigQuery、dbtを使ってデータ基盤を構築している方
- dbtのincremental modelを導入している方、または導入を検討されている方
dbt incremental model (BigQueryの場合)
BigQueryにおけるdbtのincremental modelでは、以下2つの戦略が用意されています。
- merge戦略
- ソーステーブルと宛先テーブルをスキャンし、マッチするデータを更新する
- 宛先テーブルをフルスキャンするので、宛先テーブルのデータ量が多い場合は時間的コストと経済的コストがかかる
- insert_overwrite戦略
- 宛先テーブルのパーティションを置き換える
- パーティションの設定が必要
- 宛先テーブルのフルスキャンが発生しないので、時間的コストと経済的コスト的に有利
我々はinsert_overwrite戦略がコスパ的に良かったため、insert_overwrite戦略を選択しました。
insert_overwrite戦略にもいくつかの選択肢がありましたので説明します(merge戦略の説明は割愛します)。
insert_overwrite戦略
insert_overwrite戦略は、以下3つのパターンに分かれます。
- Static partitions
- Dynamic partitions
- Copying partitions
これら3つのパターンについて、具体的な例を挙げて説明します。
以下の図に示す、ソーステーブルの増分データで宛先テーブルを差分更新する例になります。
この例には以下の前提条件があります。
- ソーステーブルは「test」データセット配下に作成されている
- 宛先テーブルは「stg_test」データセット配下に作成されている
- これらのテーブルは日別のパーティショニング(パーティショニング列はcreated_at)が設定されている
- dbtのvarsに「start_date(設定値は'2024-04-02')」「end_date(設定値は'2024-04-03')」が設定されている
- dbt_project.ymlのvarsか、'dbt run'の引数に--vsrsで指定
Static partitions
Static partitionsでは、上書き対象のパーティションの静的なリストを設定する必要があります。
Static partitionsを使用するために必要な設定は以下のようなものがあります。
- materialized => 'incremental'を指定
- incremental_strategy => 'insert_overwrite'を指定
- partition_by => パーティションの構成を、'field'、'data_type'、'granularity'で指定する
- partitions => 置き換え対象のパーティションを指定。引用符で囲む必要がある。実業務で使用する場合はここはマクロ化するのが現実的
これらを踏まえてモデルを作成すると以下のようになります。
※to_date_array_with_quotesは引数に指定された値をクオートで囲って配列として返すマクロで、あらかじめ定義されているものとします。
{{
config(
materialized = 'incremental',
incremental_strategy = 'insert_overwrite',
partition_by = {
'field': 'created_at',
'data_type': 'date',
'granularity': 'day'
},
partitions = to_date_array_with_quotes(var('start_date'), var('end_date'))
)
}}
select
*
from
{{ source( 'test', 'ソーステーブル') }}
{% if is_incremental() %}
where
created_at between '{{ var('start_date') }}' and '{{ var('end_date') }}'
{% endif %}
モデルからSQLが生成され、実行されます。(dbt.logより抜粋、見やすくするために整形しています)。
-- 一時テーブルの作成(このコメント行は出力されません)
create or replace table `example`.`stg_test`.`宛先テーブル__dbt_tmp`
partition by created_at
OPTIONS(
expiration_timestamp=TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL 12 hour)
)
as (
select
*
from
`example`.`test`.`ソーステーブル`
where
created_at between '2024-04-02' and '2024-04-03'
);
-- mergeステートメントと一時テーブルの削除(このコメント行は出力されません)
-- 1. run the merge statement
merge into `example`.`stg_test`.`宛先テーブル` as DBT_INTERNAL_DEST
using (
select
* from `example`.`stg_test`.`宛先テーブル__dbt_tmp`) as DBT_INTERNAL_SOURCE
on FALSE
when not matched by source
and date(DBT_INTERNAL_DEST.created_at) in (
'2024-04-02', '2024-04-03'
)
then delete
when not matched then insert
(`id`, `name`, `created_at`)
values
(`id`, `name`, `created_at`)
;-- 2. clean up the temp table
drop table if exists `example`.`stg_test`.`宛先テーブル__dbt_tmp`;
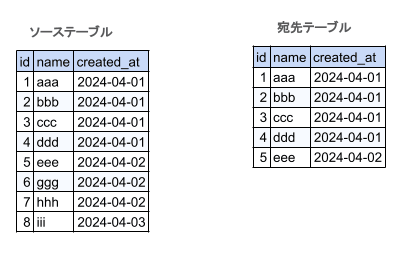
動作イメージは以下の図のようになります。

- ソーステーブルから対象のパーティションのデータを抽出し一時テーブルを作成する
- 宛先テーブルの更新対象パーティションを削除する
- 一時テーブルのデータを宛先テーブルにinsertする
パーティションの静的なリストを設定しないといけないのがやや難点ですが、マクロをうまく利用して設定すれば問題無さそうです。
公式ドキュメントでは、動的に指定するためのマクロについて触れています。
Dynamic partitions
Dynamic partitionsでは、静的なパーティションのリストは設定しません。
モデルSQLで作成された一時テーブルから上書きするパーティションを見つけます。
モデルを作成すると以下のようになります。
{{ config(
materialized = "incremental",
incremental_strategy = "insert_overwrite",
partition_by = {
'field': 'created_at',
'data_type': 'date',
'granularity': 'day'
}
) }}
select
*
from
{{ source( 'test', 'ソーステーブル') }}
{% if is_incremental() %}
where
created_at between '{{ var('start_date') }}' and '{{ var('end_date') }}'
{% endif %}
モデルからSQLが生成され、実行されます。
-- 一時テーブルの作成(このコメント行は出力されません)
create or replace table `example`.`stg_test`.`宛先テーブル__dbt_tmp`
partition by created_at
OPTIONS(
expiration_timestamp=TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL 12 hour)
)
as (
select
*
from
`example`.`test`.`ソーステーブル`
where
created_at between '2024-04-02' and '2024-04-03'
);
-- mergeステートメントと一時テーブルの削除(このコメント行は出力されません)
-- generated script to merge partitions into `example`.`stg_test`.`宛先テーブル`
declare dbt_partitions_for_replacement array<date>;
-- 1. temp table already exists, we used it to check for schema changes
-- 2. define partitions to update
set (dbt_partitions_for_replacement) = (
select as struct
-- IGNORE NULLS: this needs to be aligned to _dbt_max_partition, which ignores null
array_agg(distinct date(created_at) IGNORE NULLS)
from `example`.`stg_test`.`宛先テーブル__dbt_tmp`
);
-- 3. run the merge statement
merge into `example`.`stg_test`.`宛先テーブル` as DBT_INTERNAL_DEST
using (
select
* from `example`.`stg_test`.`宛先テーブル__dbt_tmp`
) as DBT_INTERNAL_SOURCE
on FALSE
when not matched by source
and date(DBT_INTERNAL_DEST.created_at) in unnest(dbt_partitions_for_replacement)
then delete
when not matched then insert
(`id`, `name`, `created_at`)
values
(`id`, `name`, `created_at`)
-- 4. clean up the temp table
drop table if exists `example`.`stg_test`.`宛先テーブル__dbt_tmp`
動作イメージは以下の図のようになります。
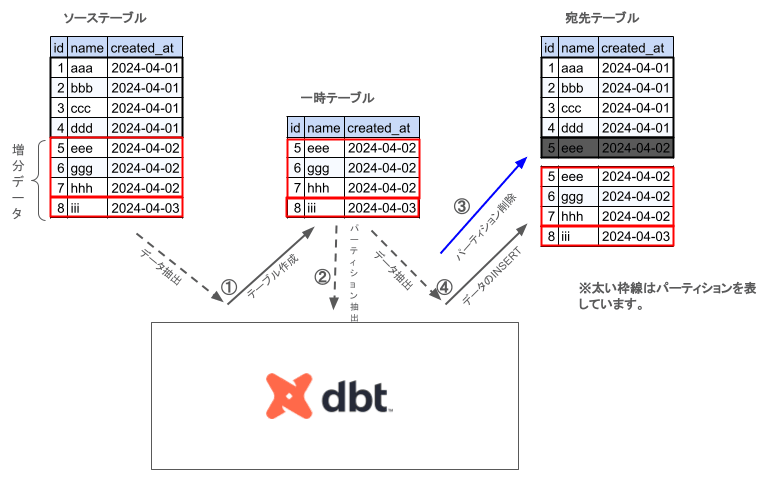
- ソーステーブルから対象のパーティションのデータを抽出し一時テーブルを作成する
- ソーステーブルから個別のパーティションを取得する
- 宛先テーブルの更新対象パーティションを削除する
- 一時テーブルのデータを宛先テーブルにinsertする
パーティション指定をしなくて良いのは若干楽ではありますが、そのために多少処理が増えるのが気になります。
パーティションを上書きする用途よりも、新しいデータのみを宛先テーブルに追加する、といった使い方のほうが向いているのかもしれません。
Copying partitions
Copying partitionsはinsert_overwrite戦略の中で一番新しい機能になります。(2024年4月現在)
Copying partitionsを使用するには、partition_byの設定で、copy_partitionsをtrueにする必要があります。
partitionsの設定がなく、モデルSQLのwhere句で上書き対象のデータを指定する必要があります。
公式ドキュメントによると、copy table APIを使っており、データの挿入にコストが掛からないため、大規模なデータセットでは時間とコストが節約できるとのことです。
モデルを作成すると以下のようになります。
{{ config(
materialized = 'incremental',
incremental_strategy = 'insert_overwrite',
partition_by = {
'field': 'created_at',
'data_type': 'date',
'granularity': 'day',
'copy_partitions': true
}
) }}
select
*
from
{{ source( 'test', 'ソーステーブル') }}
{% if is_incremental() %}
where
created_at between '{{ var('start_date') }}' and '{{ var('end_date') }}'
{% endif %}
モデルからSQLが生成され、実行されます。
(copy table APIについては実行したことを示すログが出ます)
-- 一時テーブルの作成(このコメント行は出力されません)
create or replace table `example`.`stg_test`.`宛先テーブル__dbt_tmp`
partition by created_at
OPTIONS(
expiration_timestamp=TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL 12 hour)
)
as (
select
*
from
`example`.`test`.`ソーステーブル`
where
created_at between '2024-04-02' and '2024-04-03'
);
-- copy table APIの実行 (DispositionにWRITE_TRUNCATEが指定されて実行されたのがわかる)
[0m11:54:09.488329 [debug] [Thread-1 (]: BigQuery adapter: Copying table(s) "/projects/example/datasets/stg_test/tables/宛先テーブル__dbt_tmp$20240402" to "/projects/example/datasets/stg_test/tables/宛先テーブル$20240402" with disposition: "WRITE_TRUNCATE"
[0m11:54:10.873294 [debug] [Thread-1 (]: BigQuery adapter: Copying table(s) "/projects/example/datasets/stg_test/tables/宛先テーブル__dbt_tmp$20240403" to "/projects/example/datasets/stg_test/tables/宛先テーブル$20240403" with disposition: "WRITE_TRUNCATE"
-- 一時テーブルの削除(このコメントは出力されません)
-- Clean up the temp table
drop table if exists `example`.`stg_test`.`宛先テーブル__dbt_tmp`
動作イメージは以下の図のようになります。
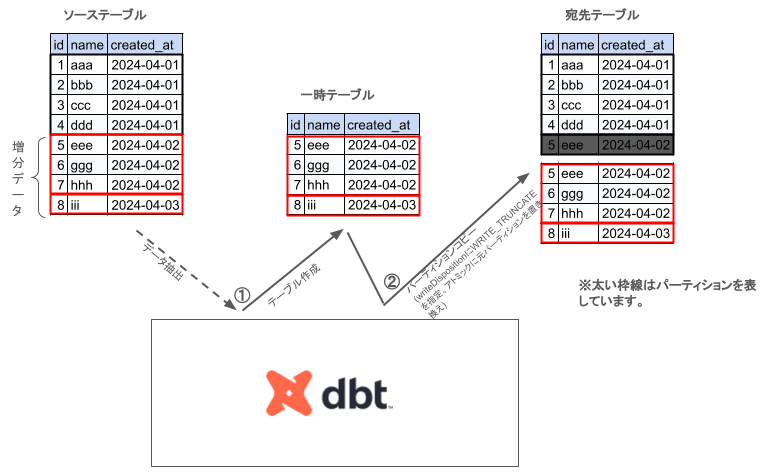
- ソーステーブルからモデルSQLでデータを抽出し一時テーブルを作成する
- 宛先テーブルの更新対象パーティションを一時テーブルのパーティションで上書きする。このとき、copy table APIのwriteDispositionにはWRITE_TRUNCATEを指定しているため、更新対象のパーティションがアトミックに更新される。
copy table APIでパーティションを上書きするため、普通にinsertするより処理時間が短くなります(データが小さい場合はあまり変わらないかもしれません)。
insert_overwrite戦略の中で経済的にも時間的にも最もコストが低くなると思われます。
さいごに
我々の環境では、insert_overwrite戦略のCopying partitionsを用いた差分更新処理を導入することに決定しました。
主な理由としては、恐らく最もコスパが良い(時間的コストと経済的コスト両方)ためです。
まだ導入して間もないですが、今のところ安定して稼働しています。
どなたかの参考になれれば幸いです。
参考にしたもの
dbt公式ドキュメント
必要な情報はだいたいここに書いてあります。
説明が足りなかったりして理解できない部分はdbt公式ブログを読んで補完するのが良いと思います。
dbt公式ブログ

Discussion