dbtの開発構成について
はじめに
dbtの開発時の環境構成について社内で議論があったため、自分なりの構成をまとめてみました。
概要
dbtで開発環境、本番環境などを切り分けるとき、profiles.ymlのtargetを分けることでデプロイ先を切り替えることができます。ですが、複数人で開発を行う際に同じ環境に対してdbt runを実行すると、実行する度にデータマートが書き換えられて開発が行いにくいかと思います。
今回はdbtのカスタムスキーマ機能を用いて開発ブランチごとにスキーマを生成する形をとってみました。ただ無尽蔵にスキーマを生成すると開発環境が散らかるため、github actionsを使って、PRがマージされた際に生成したスキーマを削除するようなCI/CDを組みました。
サンプル
こちらにコードを置いています。
前提
- dbt-coreを使用。version: 1.0.4
- 接続先: Snowflake
- direnvを使用
- サンプルデータとしてjaffle_shopを使います
フォルダ構成
.
├── README.md
├── dbt_packages
├── dbt_project.yml
├── logs
├── macros
├── models
├── profiles
├── requirements.txt
├── seeds
├── target
└── venv
ブランチごとにスキーマ生成
ブランチ名をdirenvを用いて環境変数に入れます。
export CURRENT_BRANCH="$(git branch --show-current | sed -e 's/\//_/g')"
/を含む場合は全て_に変換します。
$ echo $CUURENT_BRANCH
feature_test
次にprofiles.ymlにブランチ名をスキーマとするように設定します。
dbt_sample:
target: dev
outputs:
dev:
type: snowflake
account: "{{ env_var('SNOWFLAKE_ACCOUNT') }}"
user: "{{ env_var('SNOWFLAKE_USERNAME') }}"
password: "{{ env_var('SNOWFLAKE_PASSWORD') }}"
role: DEVELOPER_ROLE
database: TEST_DB
warehouse: TEST_WH
schema: "{{ env_var('CURRENT_BRANCH') }}" # branch name
threads: 1
client_session_keep_alive: False
query_tag: DBT
各modelに対してもスキーマ名を設定します。
name: 'jaffle_shop'
config-version: 2
version: '0.1'
profile: 'dbt_sample'
model-paths: ["models"]
seed-paths: ["seeds"]
test-paths: ["tests"]
analysis-paths: ["analysis"]
macro-paths: ["macros"]
target-path: "target"
clean-targets:
- "target"
- "dbt_modules"
- "logs"
require-dbt-version: [">=1.0.0", "<2.0.0"]
models:
jaffle_shop:
materialized: table
+schema: raw
staging:
materialized: view
+schema: staging
seeds:
jaffle_shop:
+database: test_db
+schema: raw
最後にdevelopブランチとmainブランチでは既定のスキーマ名を使うように、macros以下にcustom_schemaの値を設定するマクロを置きます。
{% macro generate_schema_name(custom_schema_name, node) -%}
{%- set default_schema = target.schema -%}
{%- if default_schema=='main' or default_schema=='develop' -%}
{{ custom_schema_name }}
{%- else -%}
{{ default_schema }}_{{ custom_schema_name | trim }}
{%- endif -%}
{%- endmacro %}
dbt seedでテストデータを挿入し、dbt runを実行します。
SnowflakeのUIからスキーマを確認すると、
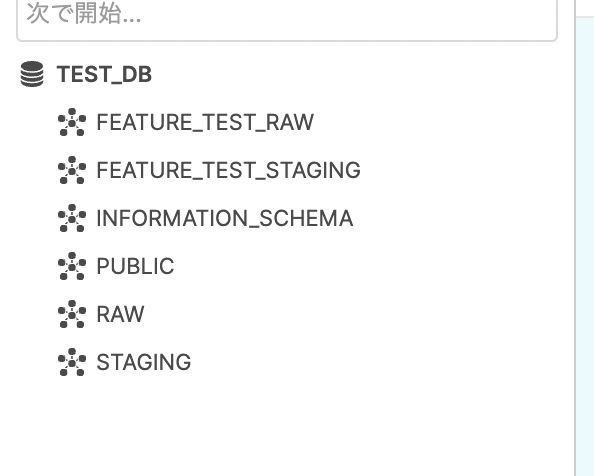
rawとstagingスキーマの他に、feature_test_rawとfeature_test_stagingができていることがわかります。
参考
dbtのカスタムスキーマについて
PRのマージ後にスキーマを削除
snowsqlでdrop schemaを実行するように、github actionsを構成します。
secretsは各自のSnowflakeアカウントへ設定してください。
name: drop_schema
on:
pull_request:
types: [closed]
jobs:
drop-schema:
if: github.event.pull_request.merged == true
runs-on: ubuntu-20.04
container:
image: python:3.8-slim
steps:
- uses: actions/checkout@v2
- env:
BRANCH_NAME: ${{github.head_ref}}
SNOWSQL_ACCOUNT: ${{secrets.SNOWSQL_ACCOUNT}}
SNOWSQL_USER: ${{secrets.SNOWSQL_USER}}
SNOWSQL_DATABASE: ${{secrets.SNOWSQL_DATABASE}}
SNOWSQL_ROLE: ${{secrets.SNOWSQL_ROLE}}
SNOWSQL_WAREHOUSE: ${{secrets.SNOWSQL_WAREHOUSE}}
SNOWSQL_PWD: ${{secrets.SNOWSQL_PWD}}
run: ./.github/workflows/drop_schema.sh
シェルスクリプト内でsnowsqlをインストールし、SQLを実行します。
#!/bin/bash
# get snowsql
apt update
apt-get install -y curl unzip
curl -O https://sfc-repo.snowflakecomputing.com/snowsql/bootstrap/1.2/linux_x86_64/snowsql-1.2.21-linux_x86_64.bash
SNOWSQL_DEST=/root/bin SNOWSQL_LOGIN_SHELL=/root/.profile bash ./snowsql-1.2.21-linux_x86_64.bash
alias snowsql=/root/bin/snowsql
# drop schema
branch_name="$(echo $BRANCH_NAME | sed -e 's/refs\/heads//g' | sed -e 's/\//_/g')"
sql="drop schema ${branch_name}_raw;"
/root/bin/snowsql -q "${sql}"
sql="drop schema ${branch_name}_staging;"
/root/bin/snowsql -q "${sql}"
これで適当なPRを出してマージします。
github actionsのUIを確認すると、
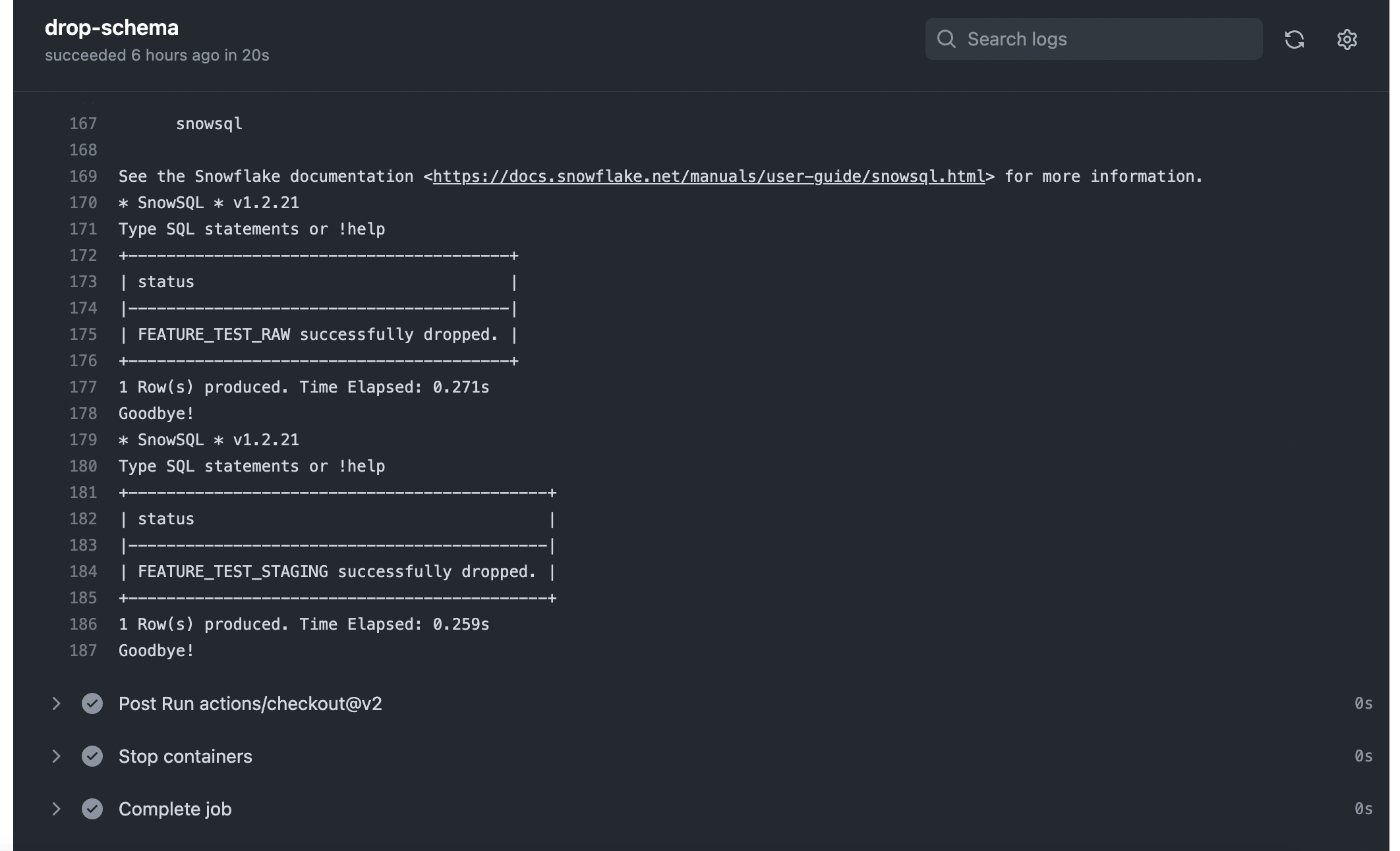
github actionsが正常終了し、スキーマが削除されていることがわかります。
終わりに
dbtの開発環境構成は未だにベストプラクティスが定まっていないらしく、オレオレ設計を晒すチャンスだと思って作ってみました。より良い方法があればご教示いただけると嬉しいです。
Discussion