ブラウザ基礎
概要
Webブラウザは、インターネット上のウェブページにアクセスし、ユーザーに視覚的に表示するためのソフトウェアアプリケーション
HTML、CSS、JavaScriptを解釈して表示し、Webページをレンダリングを基本
ブラウザ = ほぼオペレーティングシステム
- 単なるソフトウェアではなく、フル機能のシステム
- 独自のタイマー、ネットワーク機能、データストレージを持つ
- メモリ管理、レンダリング機能、JavaScript エンジンを内蔵
- 最新ブラウザ
- タブブラウジング、ブックマーク、拡張機能、デバイス間の同期
- セキュリティ
- サンドボックス、HTTPSの強制、ポップアップブロック
主要機能
ナビゲーション機能
- 検索バー: アドレスバーでの直接検索
- ブックマーク: お気に入りページの保存・管理
- 閲覧履歴: 過去のアクセス履歴追跡
- タブブラウジング: 複数ページの同時表示
管理
- ダウンロード管理: ファイルのダウンロード状況監視
- パスワード管理: ログイン情報の自動保存・入力
- データ同期: デバイス間での設定・履歴同期
- プライベートブラウジング: 履歴を残さないモード
カスタマイズ
- UI customization: インターフェース・見た目のカスタマイズ
- 拡張機能/アドオン: 機能追加プラグイン
- ショートカット設定: キーボードショートカット
セキュリティ
- HTTPS暗号化: データ通信の暗号化
- サンドボックス: 悪意のあるコードからの保護
- ポップアップブロック: 迷惑広告の防止
- フィッシング対策: 偽サイトからの保護
種類・分類
1. デスクトップブラウザ
スムーズなブラウジング体験を実現する充実した機能を備えている
タブブラウジング、拡張機能やアドオン、高度なセキュリティなど、より幅広い機能がある
- Google Chrome: 世界シェア1位、V8 JavaScriptエンジン搭載
- Mozilla Firefox: プライバシー重視、カスタマイズ性が高い
- Microsoft Edge: Chromiumベース、Windows統合機能
- Apple Safari: macOS/iOS専用、WebKitエンジン使用
2. モバイルブラウザ
モバイルデバイスの小さな画面とタッチインターフェース向けに設計
スムーズなブラウジングを実現するために、使いやすさと高速な読み込み時間はモバイルブラウザの重要な機能
- iOS Safari: iPhone/iPad標準ブラウザ
- Android Chrome: Android標準ブラウザ
- Samsung Internet: Samsung端末最適化
3. 組み込みブラウザ
他のアプリケーションに組み込まれたウェブブラウザのミニチュア版
ユーザーは別のウィンドウを開かずにウェブブラウザにアクセスできるが、完全なウェブブラウザと比較すると機能は制限
- メールクライアント:Web コンテンツを電子メール内に表示
- ソーシャルメディアアプリ:アプリを離れることなく共有リンクや記事を表示
- ゲームプラットフォーム:ユーザーはオンライン機能のゲームガイドにアクセスしたり、他のプレイヤーと接続
歴史
1990年
世界初のWebブラウザ「WorldWideWeb」(後に「Nexus」に改名)が開発
機能はウェブページの表示とハイパーリンクのナビゲーション・テキストのみのインターフェース
1991年
ラインモードブラウザ
古い端末向けに設計されたテキストベースのブラウザで、特殊なワークステーション以外にも幅広いウェブへのアクセスを可能にした
1993年
「Mosaic」が初のグラフィカルブラウザとして登場、画像表示機能を追加
1994-1995年
Netscape NavigatorとInternet Explorerの競争開始(ブラウザ戦争)
Netscape Navigatorは、広く普及した最初の商用ウェブブラウザ
Internet ExplorerをMicrosoftが開発
同社がこのブラウザをWindowsに無料でバンドルしたことで、Internet Explorerは急速に市場シェアを拡大
2004年
Mozilla Firefoxが登場、セキュリティと拡張性を重視
オープンソース開発とプライバシーに焦点を当て、Internet Explorer に代わる強力な選択肢を提供
2008年
Google Chromeが市場参入、高速化とシンプルさで急成長
ブラウザの構成
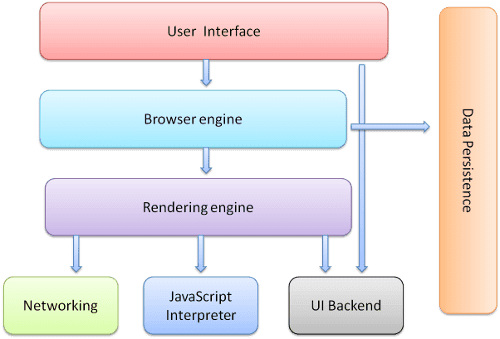
1. ユーザーインターフェース(User Interface)
ユーザーが実際に見る・操作する部分・上位レイヤーとして画像、テキスト、動画などの表示
ウェブサイトのアドレスを入力するアドレスバー、ナビゲーション用の「戻る」ボタンと「進む」ボタン、複数のウェブサイトを同時に開くためのタブなど
2. ブラウザエンジン (Browser Engine)
UI とレンダリング エンジンの間でアクションをマーシャリング
リクエストの処理やプラグインの管理などを担当
3. レンダリングエンジン(Rendering Engine)
HTMLとCSSコードを視覚的要素に変換(HTML/CSS処理)
ブラウザからの指示を受け取り、解釈し、それに従ってウェブページを構築
- 主要エンジン
- Blink(Chrome、Edge) スピードと効率性
- Gecko(Firefox)複雑な Webページをレンダリングするための強力な機能
- WebKit(Safari)オープンソース開発と標準準拠を重視
4. ネットワーク (Networking)
Web サーバーから Web サイトのファイル (コード、画像、ビデオ) やデータを取得する
プロトコルサポート HTTP/HTTPS、FTP、WebSocket
5. JavaScriptインタプリタ (JavaScript Interpreter)
JavaScript コードを解釈して実行し、Web ページがユーザーのアクションに応答して動的なエクスペリエンスを作成できるようにする
- 主要エンジン
- V8(Chrome)
- SpiderMonkey(Firefox)
- JavaScriptCore(Safari)
6. UIバックエンド (UI Backend)
コンボボックスやウィンドウなどの基本的なウィジェットの描画に使用
プラットフォームに依存しない汎用インターフェースを公開
内部では、オペレーティング システムのユーザー インターフェース メソッドを使用
7. データストレージ (Data Storage/Persistence)
永続レイヤでCookieやローカルストレージなど、ユーザーのデータを保存して再利用
ブラウザは、localStorage、IndexedDB、WebSQL、FileSystem などのストレージメカニズムもサポート
ブラウザの仕組み
大きくは以下の流れでブラウザは動く
- ナビゲーション
- DNS
- TCP/TLS
- HTTPリクエスト・レスポンス
- HTMLの解析とDOMツリーの構築
- レンダーツリーの構築
- レンダーツリーのレイアウト
- レンダーツリーのペイント
- JavaScriptの特別な処理

1.ナビゲーション
ページをリクエストしてWebページを読み込む最初のステップ
ユーザーがアドレスバーにURLを入力したり、リンクをクリックしたり、フォームを送信したり、その他の操作によってページをリクエストするたびに発生
1.1 DNS ルックアップ
ページのアセットがどこに保存されているかを確認のため、ドメイン名をIPアドレスに変換
キャッシュからIPアドレスを取得することで、後続のリクエストを高速化
フォント、画像、スクリプト、広告、指標がすべて異なるホスト名を持つ場合は、それぞれに対してDNSルックアップを実行する必要がある
1.2 TCP ハンドシェイク
IPアドレスが判明するとブラウザはTCP 3ウェイハンドシェイクを介してサーバーへの接続を確立
接続確立クライアントとサーバー間の安全な通信路構築
1.3 TLS ネゴシエーション(HTTPS)
TLSネゴシエーションでは、通信の暗号化に使用する暗号方式を決定し、サーバーを検証し、実際のデータ転送を開始する前に安全な接続を確立
2. HTTPリクエスト・レスポンス
ウェブサーバーへの接続が確立されると、ブラウザはユーザーに代わってHTTPリクエストを送信
サーバーはリクエストを受信すると、関連するレスポンスヘッダーとHTMLのコンテンツを返信
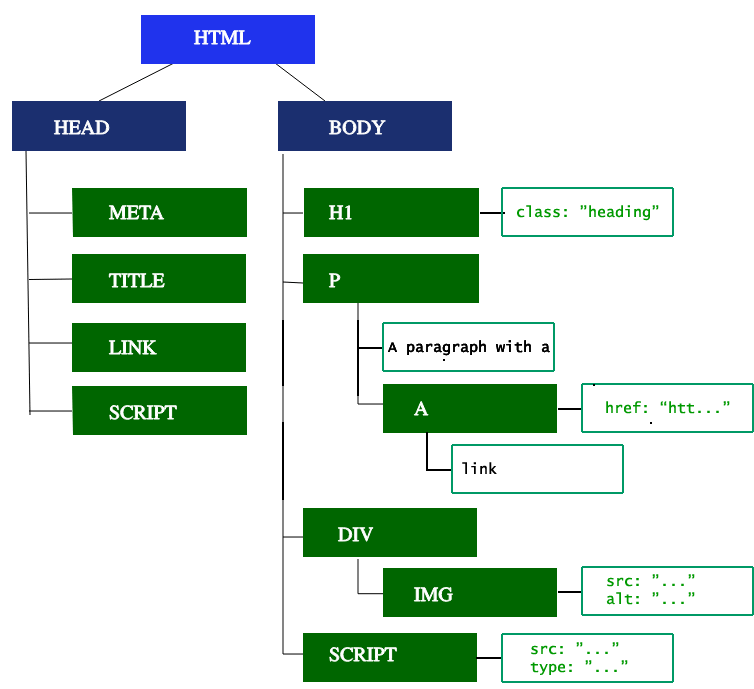
<!doctype html>
<html lang="en-US">
<head>
<meta charset="UTF-8" />
<title>My simple page</title>
<link rel="stylesheet" href="styles.css" />
<script src="myscript.js"></script>
</head>
<body>
<h1 class="heading">My Page</h1>
<p>A paragraph with a <a href="https://example.com/about">link</a></p>
<div>
<img src="my-image.jpg" alt="image description" />
</div>
<script src="another-script.js"></script>
</body>
</html>
3. Parsing HTML to construct the DOM tree(HTMLの解析とDOMツリーの構築)
ブラウザは最初のデータチャンクを受信すると、受信した情報の解析を開始
HTMLをレキサ(字句解析)・パーサ(構文解析)を使ってDOMツリーを構築
解析は、字句解析と構文解析の 2 つのサブプロセスに分割できる
- 字句解析 レキサー
- 入力をトークンに分割するプロセス
- 構文解析 パーサー
- 言語の構文ルールに従ってドキュメント構造を分析してパースツリーを構築
- レキサから識別されたトークンをパーサに渡し、構文解析
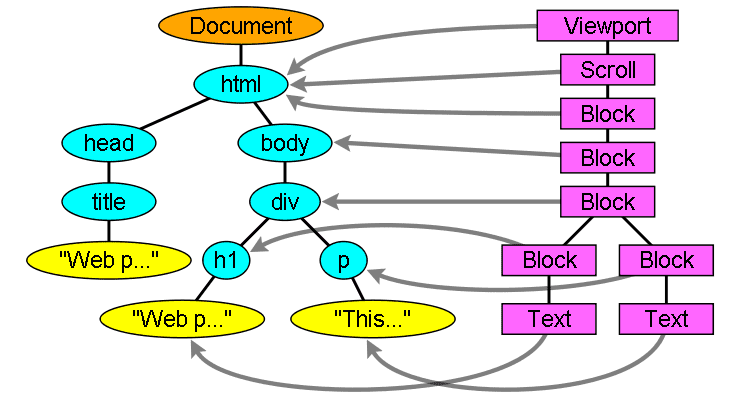
DOMツリーは、ページのすべての要素と属性をノードとして表したもの
コードで使用できる構造、ドキュメントの構造を表すノードのツリー
サンプルDOMツリー
3.1 HTML解析(レキサー)
- トークン化: HTMLマークアップを意味のあるトークンに分割
トークンは言語の語彙であり、有効な構成
要素の集合で言語の辞書に記載されているすべての単語で構成
空白文字や改行などの無関係な文字を取り除く
3.2 DOM構築(パーサー)
- ツリー構築: ノード間の階層関係を確立
- インクリメンタル処理: ストリーミング形式で段階的に構築
- ブロッキング要素:
<script>タグはDOM構築を停止
HTMLはDTD(Document Type Definition)で文脈自由文法なため、機械的に解析
パーサからDOM(Document Object Model)を構築
パーサーが画像などの非ブロッキングリソースを見つけると、ブラウザはそれらのリソースをリクエストし、解析を続行
3.3 プリロードスキャナー
- 高優先度リソース(CSS、JS、画像)を並行ダウンロード
外部リソースへの参照を見つけるまで待つ必要がなくなる
バックグラウンドでリソースを取得するため、メインのHTMLパーサーが要求されたアセットに到達する頃には、既に処理中かダウンロード済みになっている可能性がある
プリロードスキャナーが提供する最適化により、処理のブロックが軽減
流れ
- ファイル読み込み
- ブラウザはすべてをネットワーク経由で読み込む想定
- ローカルファイルも「別のコンピューター」として扱う
- Raw Bytes(生バイト)
- ファイルは最初に0と1の生データとして読み込まれる
- コンピューターはHTML形式を直接理解しない
- Character Conversion(文字変換)
- 生バイトを文字シーケンスに変換
- UTF-8等の文字エンコーディング情報が重要
- 日本語、中国語、英語等の言語指定
- Tokenization(トークン化)
- プログラミング言語と同様のプロセス
- H1、P、HTML、BODYなどのキーワードを抽出
- メモリ内で個別のトークンとして保存
- Object Creation(オブジェクト生成)
- 各トークンから詳細なオブジェクトを作成
- 例:H1タグ → タグタイプ、タイトル属性、内容データを含むオブジェクト
- すべてのHTML要素がオブジェクト化される
- Document Object Model(DOM)生成
- オブジェクト間の関係性を確立(親子、兄弟関係)
- 構造化されたモデルの作成
- 「Document Object Model」という用語の由来
- Node List生成
- 最終的にNode Listとして構造化
- JavaScriptからアクセスする際に取得されるのはこのNode List
- HTML要素ではなくNode Listが実際のブラウザ内データ
4. Render tree construction(レンダーツリーの構築)
DOMとCSSOMツリー(CSSが解析されて構築されたツリー)が結合してレンダーツリーを作成
4.1 CSSOM(CSSオブジェクトモデル)構築
- HTMLと同様のプロセス:Raw Bytes → Character → Tokenization → Objects → Model
- CSS専用のオブジェクトモデル作成
- 並行処理: DOM構築と独立して同時実行
CSSオブジェクトモデルはDOMに似ています。DOMとCSSOMはどちらもツリー構造で、独立したデータ構造
HTMLと同様に、ブラウザは受信したCSSルールをブラウザが処理できる形式に変換する必要
HTMLからオブジェクトへの変換プロセスをCSSに対して繰り返す
4.2 レンダーツリー生成
- DOM + CSSOM = Render Tre としてDOMとCSSOMの情報を統合
- ブラウザエンジンによる瞬時に複雑な計算を実行
- スタイル適用:画面サイズ、要素サイズ(ピクセル、パーセンテージ)の計算
計算スタイルツリー(レンダリングツリー)の構築は、DOMツリーのルートから始まり、表示される各ノードをトラバース
5. Layout of the render tree(レンダーツリーのレイアウト)
レンダーツリーのレイアウトフェーズでは、各ノード(要素)がブラウザのビューポート(表示領域)のどこに表示されるべきか計算
5.1 レイアウト(Reflow)処理
- レイアウト ページ上の各オブジェクトのサイズと位置を決定するプロセス
- リフロー レイアウトの再計算はリフローと呼ばれる
ビューポート基準: 画面サイズに基づく相対計算
ビューポート変更: ウィンドウのリサイズ
6. Painting the render tree(レンダーツリーのペイント)
レンダーツリーの各ノードを画面に描画
ブラウザはレイアウト情報を元に、各ノードに対応するピクセルを画面上に描画
6.1 ペイント(Paint)処理
- Render Tree完成後に実際の描画開始
- 画面上に最終的な表示が実現
レイヤー分割: 複雑な要素は独立レイヤーで処理
GPU活用: ハードウェアアクセラレーションによる高速化
7. JavaScriptの特別な処理と優先順位
- ブラウザがscriptタグを発見すると、すべての処理を停止・DOM、CSSOM構築を中断してJavaScript処理を優先
- 理由:JavaScriptがDOMやCSSを変更する可能性があるため
理想的な順序:HTML/CSS → Painting → JavaScript(インタラクティブ機能)
CSSOM未完成時はJavaScript実行も停止される
- 理由:JavaScriptがDOMやCSSを変更する可能性があるため
インタラクティビティ
インタラクティブとは、最初のコンテンツペイント(First Contentful Paint)後、ページがユーザーインタラクションに50ミリ秒以内に応答する時点
Time to Interactive(TTI)
- 定義: ページが完全にインタラクティブになるまでの時間
- 測定基準: メインスレッドが50ms以上ブロックされない状態
- 最適化目: 5秒以内での達成
First Contentful Paint(FCP)
- 定義: 最初のコンテンツが表示されるまでの時間
- 重要性: ユーザーの体感速度に直結
- 最適化: Critical CSS、フォント最適化
Largest Contentful Paint(LCP)
- 定義: 最大コンテンツ要素の表示完了時間
- 目標値: 2.5秒以内
- 最適化: 画像最適化、プリロード戦略
パフォーマンス最適化戦略・技術
リソース最適化
- リソース圧縮: データ転送量の削減
- 圧縮: Gzip、Brotli圧縮の活用
- 最小化: CSS/JavaScript の minify
- バンドル: リソースの結合によるHTTPリクエスト削減
- マルチプロセス処理: タブ間の独立実行
読み込み戦略
- lazy loading: 画像、iframeの遅延読み込み
- Code splitting: JavaScriptの分割配信
- Progressive loading: 段階的なコンテンツ表示
- DNS prefetching: ドメイン名解決の事前実行
キャッシュ戦略
- キャッシュシステム: 頻繁にアクセスするデータの保存
- Service Worker: オフライン対応、高速な再訪問
- HTTP キャッシュ: ブラウザキャッシュの効果的活用
- CDN: コンテンツ配信ネットワークによる高速化
参考文献
What is a Web Browser: Definition, Types, and Features
How browsers work - Mozilla Developer Network
ブラウザの仕組み | Articles | web.dev
📚ブラウザの仕組みを学ぶ
Webブラウザがどう動くのか?(🔰)
Discussion