📚ブラウザの仕組みを学ぶ
Photo by Remotar Jobs on Unsplash
Webフロントエンジニアたるもの、ブラウザの仕組みに興味を持つのは自然の摂理です。本記事では、私がブラウザの仕組みを学んでいく過程を備忘録として残します。
みんな大好きChrome
Webフロントエンジニアに愛されているブラウザといえば、IEChromeですよね。
ブラウザでHTML,CSS,JSの動作確認するのは、日常茶飯事です。
ブラウザによって動作が異なることは、Webフロントエンジニアなら周知の事実です。
じゃあ、なんで動作が違うのかというと、
- 「レンダリングエンジンが違うから〜」
- 「Javascriptエンジンが違うから〜」
ぐらいは知っているんじゃないかなと思います。
じゃあ、そのレンダリングエンジンってどういう仕組みで動いているのでしょうか。
気になりますよね。
Chromiumについて
Chromiumも、たぶんご存じの方多いのかなと思いますので、簡単に説明します。
Chromiumは、オープンソースのプロジェクト名であり、ブラウザ名でもあります。
Chromeは、Chromiumを元に開発されています。
詳しい説明はChromium - Wikiを見てください。
オープンソースってことは、ソースコードが誰でも読めちゃうってことですよね。
だったら、ブラウザの動作を知ることができちゃうじゃないですか!
わーい!😎
Chromiumのリバースエンジニアリング
ではさっそく、Chromiumのソースコードを見ていきましょう。
これです。
chromium/src - source.chromium.org
Chromium - Wikiによれば、Chromiumのソースコードは約3,500万行あるそうです。
しかも、言語はC++。私はあまりそれを詳しくないのです😞。
実際にソースコードをローカルマシン(Macbook Air)へチェックアウトし、ビルドをしてみました。
マシンが貧弱だというのもあるんですが、ビルドに半日ぐらいかかってしまいました。ヘトヘトです。
これじゃあさすがに、手軽にブラウザの動作確認はできそうにないです。
ブラウザの仕組み資料を読む
ちょっと趣向を変えて、次のような資料を読むことにしました。
-
ブラウザの仕組み: 最新ウェブブラウザの内部構造
- 記事の公開日が2011年8月5日なので、色々古いかもしれません。
では、さっそく見ていきます。
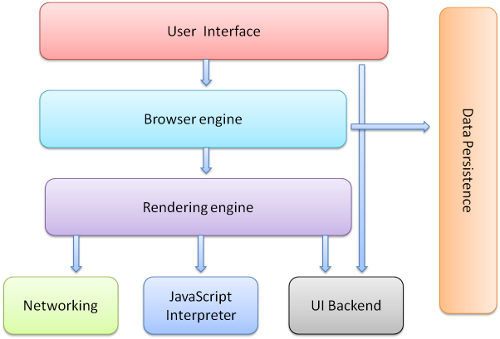
最初に目につくのが、ブラウザの主な構成要素です。
ブラウザの主な構成要素 - www.html5rocks.com
構成要素の内、ユーザーインターフェース、ブラウザエンジン、レンダリングエンジンに着目します。
それぞれ、次の役割があります。
- ユーザーインターフェース
- アドレスバーや戻る/進むボタンのようなUIを担当
- ブラウザエンジン
- UIとレンダリングエンジンの間の処理を整理
- レンダリングエンジン
- 要求されたコンテンツ(HTMLなど)の表示を担当
ちなみに、Chromiumのレンダリングエンジンには、webkitを使っていましたが、blinkに変わりました。
ブラウザの基本的なフローは、次の図の通りです。

レンダリングの基本的なフロー - www.html5rocks.com
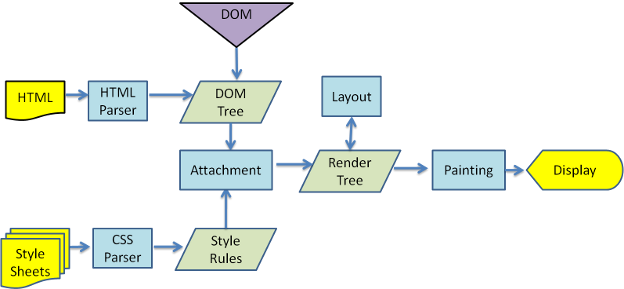
Webkitのメインフロー - www.html5rocks.com
- Parsing HTML to construct the DOM tree
- Render tree construction
- Layout of the render tree
- Painting the render tree
それぞれ見ていきます。
① Parsing HTML to construct the DOM tree
1は、HTMLをレキサ(字句解析. ex:flex)・パーサ(構文解析. ex:bison)を使ってDOMツリーを構築します。
レキサでは、ステートマシンによって読み込み状態を管理しつつトークンを識別します。空白とかコメントなどは削除されます。
レキサから識別されたトークンをパーサに渡し、構文解析していきます。
HTMLはDTD(Document Type Definition)で文脈自由文法なため、機械的に解析できます。
ただ、HTMLは寛大な仕様で、次のようなパターンも許容するようになっています。
- <br>の代わりの</br>
- 迷子のテーブル
- 入れ子のフォーム要素
- 深すぎるタグ階層
- 配置に誤りのある html または body 終了タグ
パーサからDOM(Document Object Model)を構築します。
DOMは、これまでの単なるテキストから、APIを持たせたオブジェクトモデルを作ることで、
以降はDOMを使って処理しやすくなります。
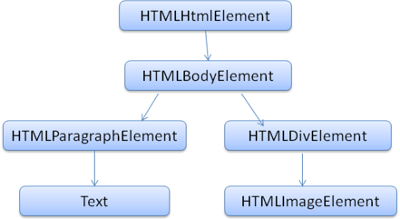
サンプル マークアップのDOMツリー - www.html5rocks.com
これまではHTMLの話をしていましたが、HTMLと並行してCSSも同様に処理していきレンダーオブジェクトというオブジェクトを作っていきます。これは、スタイル情報を付与したオブジェクトになります。
基本的に、CSSとHTMLは互いに独立しているので、並列処理が可能です。例えば、CSSを処理したことで、HTMLが変化することはないはずです。
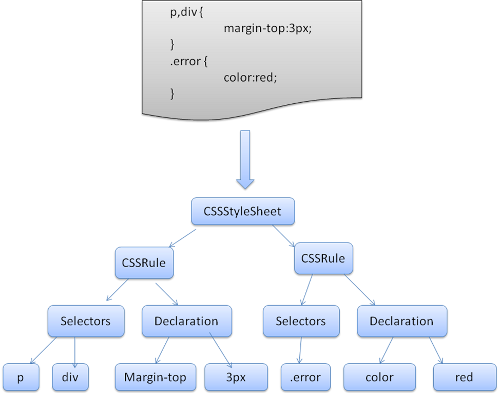
ただ、Javascriptは話が違うので、Javascriptが読み込まれた時点でHTMLのパースを中断してJavascriptのパースが開始されます。
また、Javascriptが、まだ読み込まれていないスタイルシートの影響を受けそうな特定のスタイルプロパティにアクセスした場合、Javascriptはブロックされます。
② Render tree construction
①のDOMとレンダーオブジェクトから、レンダーツリーを構築します。
DOMとレンダーオブジェクトは、1対1という訳ではなく、例えばhead要素や、display:none;の要素もレンダーツリーに含まれません。
レンダーツリーの更新は、DOMツリーが更新される度に行われます。
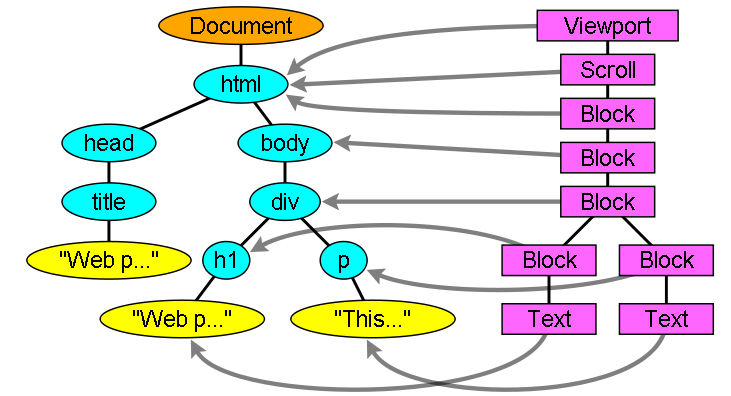
レンダーツリーと対応するDOMツリー - www.html5rocks.com
レンダーオブジェクトからスタイルを計算するのですが、ちょっと複雑です。
詳しくは、スタイルの計算を見てください。
③ Layout of the render tree
レンダーツリーから、レイアウト情報を計算していきます。
レイアウト情報とは、位置(x,y)とサイズ(width,height)です。
レンダーツリーのルートから再帰的にレイアウト情報を計算(layoutメソッド)していきます。
- 親レンダラーが自身の幅を決定します。
- 親が子を確認して、
- 子レンダラーを配置します(xとyを設定します)。
- 必要な場合は子のlayoutメソッドを呼び出します。これにより、子の高さを計算します。
- 親は子の高さの累積、マージンの高さ、パディングを使用して、自身の高さを設定します。この高さは親レンダラーのさらに親によって使用されます。
※ レイアウト処理 参考
CSSボックスモデルの図を参考までに共有しておきます。

CSS 基本ボックスモデル - developer.mozilla.org
④ Painting the render tree
ようやく描画します。
どこに描画するかという配置方法について考えることになります。
大きく分けて、3つに分かれます。
- 通常
- オブジェクトはドキュメント内の場所に従って配置されます。つまり、レンダーツリー内の場所はDOMツリー内の場所と同様になり、ボックスの種類や寸法に従ってレイアウトされます。
- position:static,relative
- オブジェクトはドキュメント内の場所に従って配置されます。つまり、レンダーツリー内の場所はDOMツリー内の場所と同様になり、ボックスの種類や寸法に従ってレイアウトされます。
- フロート
- オブジェクトは最初に通常のフローのようにレイアウトされてから、左右のできるだけ遠くに移動されます。
- float:right,left
- オブジェクトは最初に通常のフローのようにレイアウトされてから、左右のできるだけ遠くに移動されます。
- 絶対
- オブジェクトはレンダーツリー内でDOMツリーとは異なる場所に配置されます。
- position:absolute,fixed
- オブジェクトはレンダーツリー内でDOMツリーとは異なる場所に配置されます。
※ 配置方法
配置方法が分かれば、今度は描画する形について考えます。ブロックボックスとインラインボックスです。
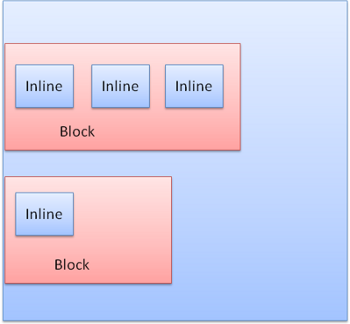
ブロックとインラインの配列 - www.html5rocks.com
ブロックボックスは、短形の形であり垂直に並びます。
インラインボックスは、独自の形を持たず水平に並びます。
z-indexのようなプロパティでは、スタッキングコンテキストという概念を知る必要があります。
詳しくは、重ね合わせコンテキスト - developer.mozilla.org をご確認ください。
ブラウザを自作してみる
前章では、資料を通してブラウザの動作が理解できました。
読むだけじゃなく、動かして理解してみたいとは思いませんか?
そうです、自作してみましょう。
Rust製のServoというブラウザエンジンを開発している人が書いた、次のブラウザ自作に関する記事がとても分かりやすいです。
-
Let's build a browser engine! Part 1: Getting started
-
mbrubeck/robinson
- Toyブラウザエンジン(mbrubeck)
- Rust製
-
mbrubeck/robinson
Toyブラウザエンジン(mbrubeck)のメインフローが、これまでの話ととても似ています。
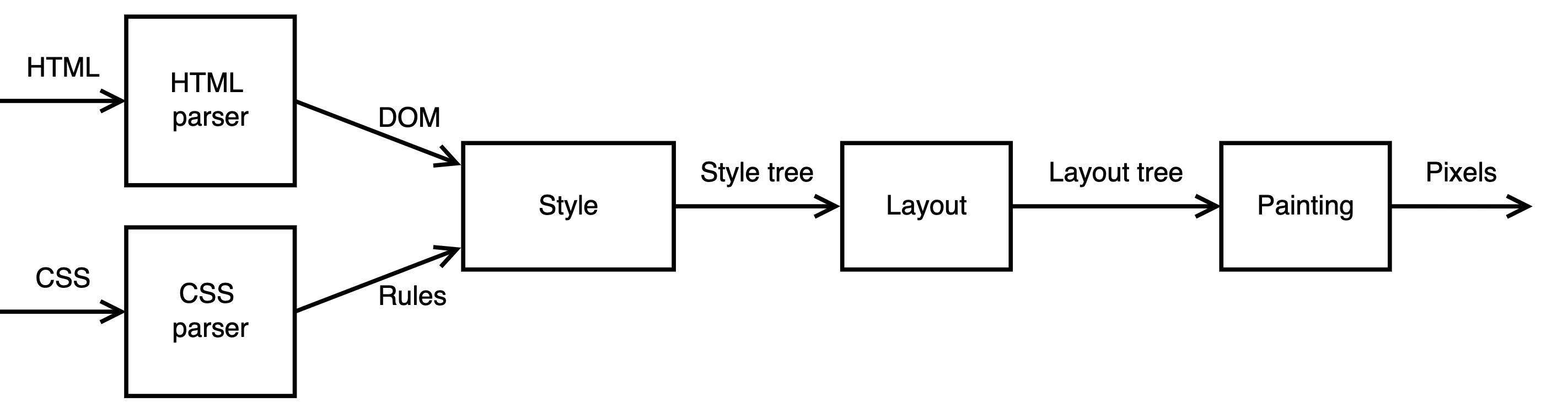
Toyブラウザエンジン(mbrubeck)のメインフロー - limpet.net
Style treeは、これまでの話でいうとRender treeだと思います。
Toyブラウザエンジン(mbrubeck)に、次のHTMLとCSSを読み込ませると、下記の画像のようなアウトプットになります。
<!-- https://github.com/mbrubeck/robinson/blob/master/examples/test.html -->
<html>
<head>
<title>Test</title>
</head>
<div class="outer">
<p class="inner">
Hello, <span id="name">world!</span>
</p>
<p class="inner" id="bye">
Goodbye!
</p>
</div>
</html>
/* https://github.com/mbrubeck/robinson/blob/master/examples/test.css */
* {
display: block;
}
span {
display: inline;
}
html {
width: 600px;
padding: 10px;
border-width: 1px;
margin: auto;
background: #ffffff;
}
head {
display: none;
}
.outer {
background: #00ccff;
border-color: #666666;
border-width: 2px;
margin: 50px;
padding: 50px;
}
.inner {
border-color: #cc0000;
border-width: 4px;
height: 100px;
margin-bottom: 20px;
width: 500px;
}
.inner#bye {
background: #ffff00;
}
span#name {
background: red;
color: white;
}
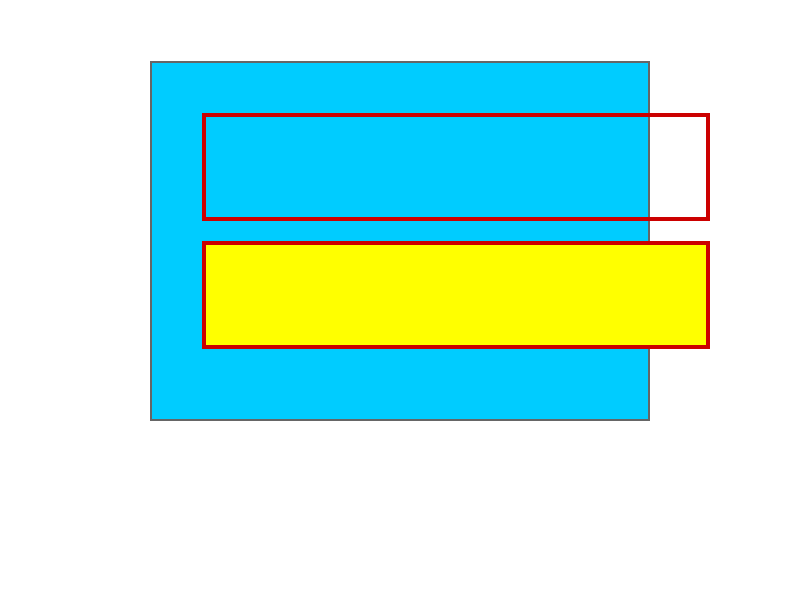
Toyブラウザエンジン(mbrubeck)のアウトプット - github.com/mbrubeck/robinson
次のリンクにある自作ブラウザエンジンは、mbrubeck/robinsonを参考にして作られたものだそうです。
-
askerry/toy-browser
- Toyブラウザエンジン(askerry)
- C++製
Toyブラウザエンジン(askerry)に、次のHTMLとCSSを読み込ませると、下記の画像のようなアウトプットになります。
見たら分かると思いますが、とても高機能です。
<!-- https://github.com/askerry/toy-browser/blob/master/examples/demo.html -->
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Browser Test</title>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<link rel="stylesheet" href="demo.css"/>
</head>
<body>
<div id="page">
<header class="header">
<h1>Toy Browser Engine</h1>
</header>
<div id="main">
<div id="navbar">
<a href="#" class="navitem">
Home
</a>
<a href="#" class="navitem">
About
</a>
<a href="#" class="navitem">
Some random stuff
</a>
<a href="#" class="navitem">
Conclusion
</a>
<img class="img" src="images/otters.jpg"/>
</div>
<div id="content">
<h2>What is this?</h2>
This is a <b>toy</b> browser engine, implemented for
<span>fun </span> <img class="icon" src="images/fun.png"/>
and <span>glory <img class="icon" src="images/glory.png"/></span>.
<h2>Why would anyone do this?</h2>
This seems pretty pointless! But I had a few goals:
<ul>
<li>Something to build to learn C++</li>
<li>Learn more about how browsers work</li>
<li>Make something I've never made before</li>
</ul>
<h2>What can it do?</h2>
<p>
Currently, the engine can parse a subset of HTML
and build a DOM tree. It can also parse a small subset of
CSS (sometimes incorrectly) and use simple selector matching
to apply styles to elements.
</p>
<p>
It supports <em>very basic</em> rendering of boxes, images, and
text with simple block and inline layouts.
</p>
</div>
</div>
</div>
</body>
</html>
/* https://github.com/askerry/toy-browser/blob/master/examples/demo.css */
body {
font-family: Arial, sans-serif;
background-color: #BFC0C0;
color: #253237;
font-size: 16px;
}
#page {
padding: 20;
/* width: 800px; */
margin: auto;
}
header {
padding: 10px;
padding-left: 20px;
background-color: #434371;
color: #4acebd;
}
span {
color: #4acebd;
}
#main {
background-color: white;
display: flex;
}
#navbar {
width: 180px;
padding: 30px;
background-color: #4acebd;
height: 500px;
}
.navitem {
display: block;
text-align: center;
background-color: #434371;
color: #4acebd;
margin-top: 5px;
margin-bottom: 5px;
padding: 10px;
border-radius: 4px;
border-style: solid;
border-width: 2px;
border-color: #253237;
}
#content {
padding: 20px;
width: 500;
}
.img {
width: 180px;
}
.icon {
width: 2em;
}
h2 {
color: #434371;
}
li {
margin-bottom: 5px;
}

Toyブラウザエンジン(askerry)のアウトプット - github.com/askerry/toy-browser
私としては、こちらの方が興味があるので、まずこちらを知り、それをRust版で作り直したいなと思います。
C++ を学ぶ
さて、C++を学ぶために、次のサイトをざっと眺めてみます。
自作ブラウザのソースコード
askerry/toy-browserのメインコード(main.cc)を載せます。
/* https://github.com/askerry/toy-browser/blob/master/src/main.cc */
namespace {
void renderWindow(int width, int height, const style::StyledNode &sn,
sf::RenderWindow *window) {
layout::Dimensions viewport;
viewport.content.width = width;
viewport.content.height = height;
// Create layout tree for the specified viewport dimensions.
std::unique_ptr<layout::LayoutElement> layout_root =
layout::layout_tree(sn, viewport);
// Paint to window.
paint(*layout_root, viewport.content, window);
}
int windowLoop(const style::StyledNode &sn) {
// Create browser window.
std::unique_ptr<sf::RenderWindow> window(new sf::RenderWindow());
window->create(sf::VideoMode(FLAGS_window_width, FLAGS_window_height),
"Toy Browser", sf::Style::Close | sf::Style::Resize);
window->setPosition(sf::Vector2i(0, 0));
window->clear(sf::Color::Black);
// Render initial window contents.
renderWindow(FLAGS_window_width, FLAGS_window_height, sn, window.get());
// Run the main event loop as long as the window is open.
while (window->isOpen()) {
sf::Event event;
while (window->pollEvent(event)) {
switch (event.type) {
case sf::Event::Closed:
window->close();
break;
case sf::Event::KeyPressed:
logger::debug("keypress: " + std::to_string(event.key.code));
break;
case sf::Event::Resized:
logger::debug("new width: " + std::to_string(event.size.width));
logger::debug("new height: " + std::to_string(event.size.height));
window->clear(sf::Color::Black);
renderWindow(event.size.width, event.size.height, sn, window.get());
break;
case sf::Event::TextEntered:
if (event.text.unicode < 128) {
logger::debug(
"ASCII character typed: " +
std::to_string(static_cast<char>(event.text.unicode)));
}
break;
default:
break;
}
}
}
return 0;
}
} // namespace
int main(int argc, char **argv) {
gflags::ParseCommandLineFlags(&argc, &argv, true);
// Parse HTML and CSS files.
const std::string source = io::readFile(FLAGS_html_file);
std::unique_ptr<dom::Node> root = html_parser::parseHtml(source);
const std::string css = io::readFile(FLAGS_css_file);
const std::unique_ptr<css::StyleSheet const> stylesheet = css::parseCss(css);
// Initialize font registry singleton.
text_render::FontRegistry *registry =
text_render::FontRegistry::getInstance();
// Align styles with DOM nodes.
std::unique_ptr<style::StyledNode> styled_node =
style::styleTree(*root, stylesheet, style::PropertyMap());
// Run main browser window loop.
windowLoop(*styled_node);
// Delete styled node and clear font registry.
styled_node.reset();
registry->clear();
return 0;
}
次のとおり、これまで学んできたメインフローと、C++がとても似ていることが分かります。
- HTMLとCSSをパース
// Parse HTML and CSS files.
const std::string source = io::readFile(FLAGS_html_file);
std::unique_ptr<dom::Node> root = html_parser::parseHtml(source);
const std::string css = io::readFile(FLAGS_css_file);
const std::unique_ptr<css::StyleSheet const> stylesheet = css::parseCss(css);
- 1の結果からStyle tree(Render tree)を構築
// Align styles with DOM nodes.
std::unique_ptr<style::StyledNode> styled_node =
style::styleTree(*root, stylesheet, style::PropertyMap());
- 2の結果からLayout treeを構築
// Create layout tree for the specified viewport dimensions.
std::unique_ptr<layout::LayoutElement> layout_root =
layout::layout_tree(sn, viewport);
- 3をpaintという描画
// Paint to window.
paint(*layout_root, viewport.content, window);
Re: ブラウザの仕組み資料を読む
もう一度、ブラウザの仕組み: 最新ウェブブラウザの内部構造 を読むと、初めて読んだときに比べて、深く理解できるんじゃないかなと思います。
最後に
ブラウザの動作について資料や自作を通して理解を深めました。
ブラウザの動作が分かれば、ブラウザに優しいWebフロントエンド開発ができると思います。
(今度こそChromiumのリバースエンジニアリングができるかもしれません。)
その他
Chromiumのアドベントカレンダーがありました。参考までにざっと見てみると良いでしょう。
Chromium Browser Advent Calendar 2017
Discussion
「ブラウザの仕組みを学ぶ」の記事を見て、askerry/toy-browserをダウンロードし、
ビルドして見ようと思いました。
エンジニアでもなく、興味のあることを独学で勉強しているものです。
askerry/toy-browserページのInstructionsにbazelとsfmlをインストールし、WORKSPACEファイルのnew_local_repository
を更新してsfmlがインストールされている場所を指すように変更する
と書かれていたため、まずbazelをインストールしhelloworldのような簡単なものをビルドすることができました。
それからいろいろサイト等見てましたが、toy-browserをビルドすることができません。
初心者のため、sfmlをインストールするということ自体もよくわかっていないのかもしれません・・・
具体的に何をすればビルドすることができるのでしょうか?
ちなみにこの記事は参考になりますか?
環境はmacOS Monterey ver12.4です
なるほどです。
https://github.com/askerry/toy-browser/issues で 質問してみるのが一番です!
そうですか。Github自体やったことがないからそっからですね。
ちょっとやってみます。
また行き詰まったら質問するかもです。