Webブラウザがどう動くのか?(🔰)
はじめに
今日も下記のロードマップを利用して、知識を増やしていきたいと思います!
Frontendの部分について随時更新していきます💪🏻
今日はブラウザの仕組みについて学びました!
ブラウザについて
- How Browsers Work
- Role of Rendering Engine in Browsers
- Populating the Page: How Browsers Work
- How Do Web Browsers Work?
Web ブラウザのアーキテクチャ(構造)を理解する
Webブラウザはフロントエンドとバックエンドのコンポーネントから構成されています。フロントエンドはWebページの表示を担当し、バックエンドはリクエストの処理とデータの伝達を担当します。さまざまなコンポーネントが連携して、シームレスなWebエクスペリエンスを提供しています。
Webブラウザのコンポーネント(部品)
Webブラウザは7つの主要なコンポーネントから構成されています。これらのコンポーネントはブラウザがどのように動作するかを決定します。
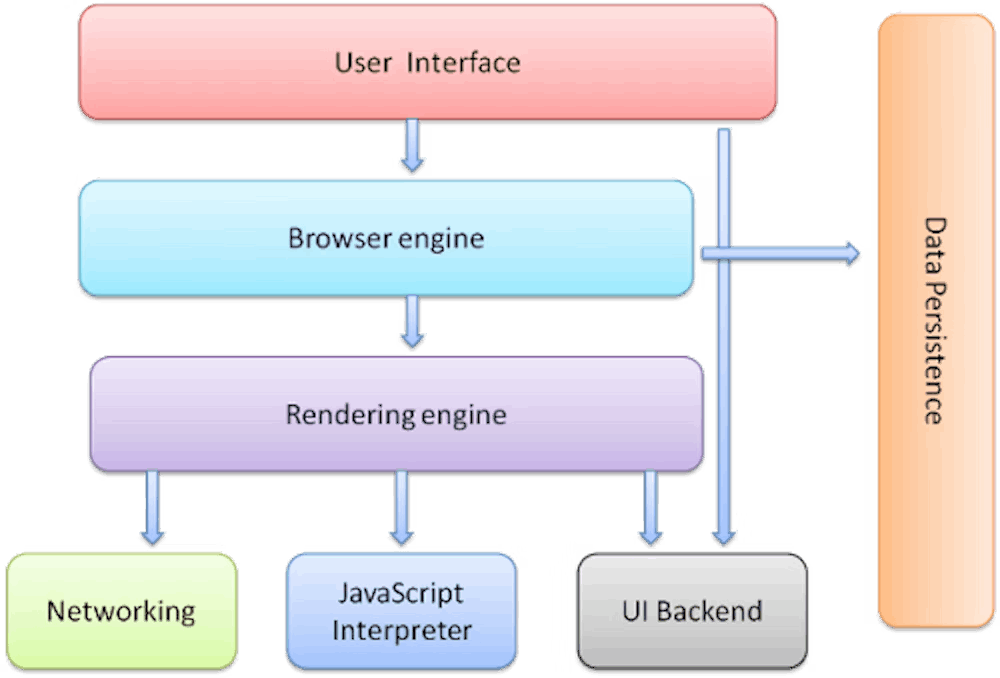
1. ユーザーインターフェース (User Interface)
エンドユーザーがWebページ上の要素を操作するためのインターフェースです。
アドレスバーやボタンなどの要素が含まれます。
2. ブラウザエンジン (Browser Engine)
ブラウザのコア部分であり、ユーザーインターフェースとレンダリングエンジンの間の相互作用を管理します。
リクエストの処理やプラグインの管理などを担当します。
3. レンダリングエンジン (Rendering Engine)
Webページの表示を担当するエンジンです。
指定されたURLのコンテンツを表示するために、HTML、CSS、JavaScriptを解釈して画面にレンダリング(描画)します。
4. ネットワーキング (Networking)
HTTPやFTPなどのプロトコルを使用してネットワーク呼び出しを行います。
5. JavaScriptインタプリタ (JavaScript Interpreter)
Webページに埋め込まれたJavaScriptコードを解析し、実行します。
6. UIバックエンド (UI Backend)
ウィンドウやチェックボックスといった基本的なウィジェットを描画するために使用されます。
7. データの永続性 (Data Storage/Persistence)
Cookieやローカルストレージなど、ユーザーのデータを保存して再利用します。
Webブラウザの動作方法
Webブラウザの仕組み
これらのコンポーネントは連携して動作します。ユーザーがURLをアドレスバーに入力すると、ブラウザはそのURLのWebサーバーにリクエストを送信します。このリクエストはHTTP(HyperText Transfer Protocol)というプロトコルを用いて送信されます。
サーバーはリクエストを受け取り、必要な情報をHTTPレスポンスとしてブラウザに返します。このレスポンスには、HTML、CSS、JavaScriptなどのファイルが含まれています。
ブラウザはレスポンスを受け取ると、これらのファイルを解析し始めます。HTMLはページの構造を、CSSはデザインとレイアウトを、JavaScriptはページの動的な機能を定義します。
ブラウザにおけるレンダリングエンジンの役割
この解析と表示のプロセスは「レンダリングエンジン」によって行われます。レンダリングエンジンはHTMLとCSSを解析し、それらをブラウザ上で見えるウェブページに変換します。
※ブラウザーが異なれば、使用するレンダリング エンジンも異なります。
- Internet Explorer は Trident
- Firefox は Gecko
- Safari は WebKit を使用します。
- Chrome と Opera (バージョン 15 以降) は、WebKit のフォークである Blink を使用します。
- WebKit は、Linux プラットフォーム用のエンジンとしてスタートし、Mac と Windows をサポートするために Apple によって変更されたオープン ソースのレンダリング エンジンです。
主な流れ

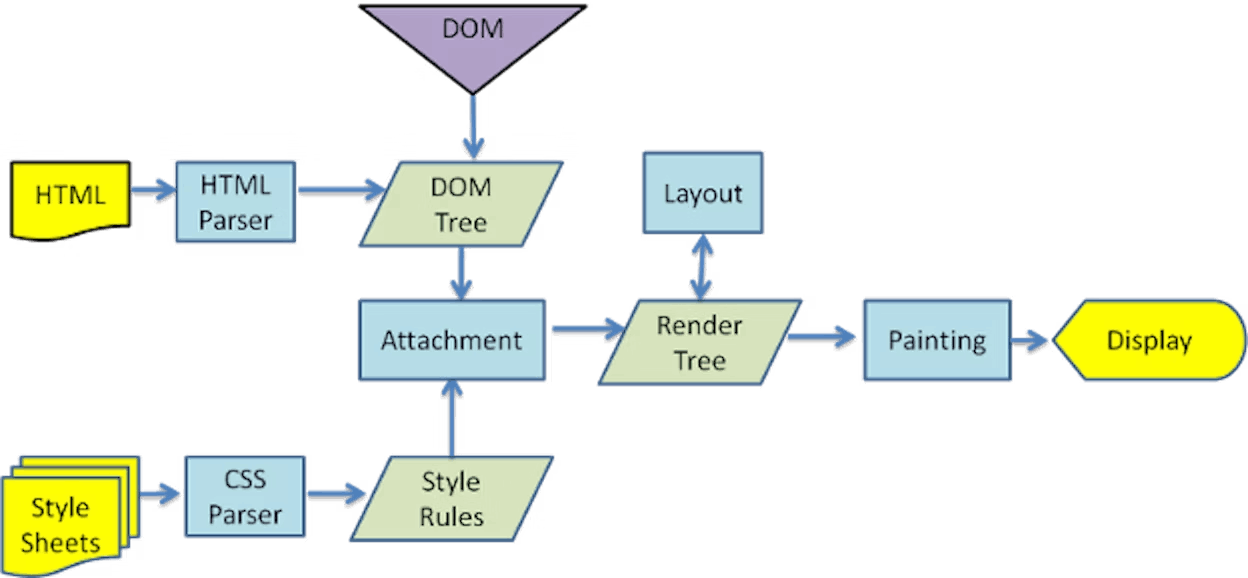
- Parsing HTML to construct the DOM tree
- Render tree construction
- Layout of the render tree
- Painting the render tree
それぞれ簡単に解析してみました!
1. Parsing HTML to construct the DOM tree(HTMLの解析とDOMツリーの構築)
まず、レンダリングエンジンはブラウザがサーバから取得したHTMLを解析し、DOM(Document Object Model)ツリーを構築します。DOMツリーは、ページのすべての要素と属性をノードとして表したものです。
HTMLは開始タグと終了タグで構成された要素(タグ)で書かれており、これらの要素はページの構造を定義します。
解析器はHTMLファイルを読み込み、各要素をDOMノードとしてツリー構造に配置します。このDOMツリーはJavaScriptがウェブページの要素にアクセスしたり、それらを操作したりするためのインターフェースを提供します。
2. Render tree construction(レンダーツリーの構築)
次に、DOMツリーとCSSOMツリー(CSSが解析されて構築されたツリー)が結合されてレンダーツリーが作られます。レンダーツリーは視覚的に描画されるウェブページの要素のみを含みます。
非表示の要素(display: noneのようなCSSプロパティで非表示に設定されている要素)やHTML内の<head>タグなど、実際には表示されないものはレンダーツリーに含まれません。
3. Layout of the render tree(レンダーツリーのレイアウト)
レンダーツリーのレイアウトフェーズでは、各ノード(要素)がブラウザのビューポート(表示領域)のどこに表示されるべきか計算されます。これを「レフロー」または「レイアウト」と呼びます。
このフェーズで、各要素の幅、高さ、位置などの具体的な座標が計算され、各要素の正確な位置が決定されます。
4. Painting the render tree(レンダーツリーのペイント)
最後に、ペイントフェーズではレンダーツリーの各ノードを画面に描画します。ブラウザはレイアウト情報を元に、各ノードに対応するピクセルを画面上に描画します。
このフェーズで、色、画像、ボーダーなどの視覚的な詳細が適用され、最終的にユーザーが見るウェブページが生成されます。
さいごに
これがWebブラウザの基本的な動作ですが、実際にはこれよりもさらに複雑で、さまざまな最適化や改善が行われています。
Webブラウザは多くの複雑な部分から成り立っていますが、それぞれの部分が連携してユーザーがWebをスムーズに閲覧できるようにしています。技術的な詳細は深堀りすればきりがありませんが、これらの基本的な情報を覚えておくと、Webとは何か、ブラウザはどのように動作しているのかについての理解が深まることと思います!
参考にさせていただいた記事🌱
Discussion