チューリング株式会社の岩政 (@colum2131) です。
近年は、Neural Radiance Fields (NeRF) や 3D Gaussian Splatting (3DGS) といった一連の2次元画像から複雑な3次元再構築が可能な技術が多く発展しています。これらの技術は自動運転にも活用されつつあります。
例えば、オープンソースの自動運転ソフトウェアのAutowareの開発を主導している株式会社ティアフォーでは、NeRFを活用した技術としてNeural Simulatorの構築を目指すというプレスリリースがありました。これは車載カメラやLiDARなどのセンサデータからNeRFモデルを構築し、自動運転の環境認識機能を検証することを目的としており、地上のみならず宇宙でも利用可能なシミュレータを構築するとのことです。
シミュレータとして3次元再構成技術が使われること以外にも、直接的に自動運転AIの学習にも活用する例が研究でも産業でも多く提案されています。
今回のテックブログでは3次元再構成技術の理論的なところは触れません。近年の自動運転に応用されるNeRFや3DGSの研究に焦点をあてて、チューリングがどのように3次元再構成技術を使っていくのかをまとめました。
0. そもそもNeRF / 3DGSとは?
NeRFについては「NeRF-RPN:NeRF上で物体検出する技術」の説明が参考になります。
また、Gaussian Splattingについては「驚くほどキレイな三次元シーン復元、「3D Gaussian Splatting」を徹底的に解説する」の説明が導出から説明されて、勉強になります。
1. NeRF / 3DGS × Autonomous Drivingの発展と課題
NeRF/3DGS × Autonomous Drivingにおいて課題なのがデータです。多くのNeRF/3DGS手法は動画像が、ある静止物体中心のシーンで撮影されていることを前提としています。一方で、自律走行の分野で用いられるストリートビューデータは各カメラ間のオーバーラップは少なく、自車両は高速に動いており、動的なオブジェクトが多く存在するデータです。そのため既存のNeRF/3DGS手法で最適化することを困難にしていました。
近年は、この課題を解決する手法が多く提案されています。以下でその代表的な例を紹介します。

S-NeRF[Xie+ ICLR2023]
1.1 ストリートビューに応用したNeRF
1.1.1 S-NeRF [ICLR2023]
S-NeRF[Xie+ ICLR2023]はパラメトリック関数な手法で、ストリートビューデータに対応したいくつかの工夫がなされています。工夫として、LiDAR点群や単眼深度推定を用いて仮想的なカメラを想定して、車などのForeground Objectの多視点画像を作成するところです。従来の手法で発生していたアーティファクトや不正確なメッシュが改善することが示され、Autonomous Drivingの分野で多く用いられるnuScenesやWaymo Open Datasetなどのデータセットでもロバストな新規視線合成を達成しました。
しかし、この手法は基本的には静的なシーンに焦点を当てているため動的な物体には特別な処理が必要なこと、学習・レンダリングに時間がかかる問題がありました。

S-NeRF[Xie+ ICLR2023]
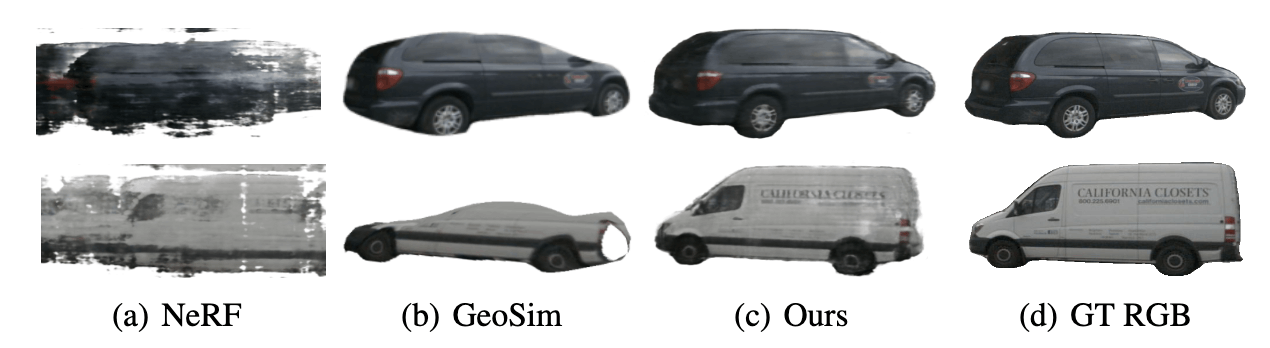
S-NeRF[Xie+ ICLR2023]
1.2 動的シーンに対応したNeRF
1.2.1 D-NeRF [CVPR2021]
NeRFは静的シーンに限った制約があり、動的シーンでオリジナルのNeRFの学習には課題がありました。D-NeRF[Pumarola+ CVPR2021]は、入力として3次元位置(x, y, z)と視線方向(θ, φ)に加えて1次元の時間方向(t)を与えることと、直接密度や色を求めるのではなく、一度基準シーンに変換して基準シーンから密度や色を求める2段階の処理を行っています。これにより合成データにおいて3次元位置と時間方向で操作可能なレンダリングが実現されて、後の研究のNeural Scene Flow Field[Li+ CVPR2021]で実世界動画像で時空間にわたるレンダリングが達成されました。

D-NeRF[Pumarola+ CVPR2021]
1.2.2 K-Planes [CVPR2023]
現在のNeRFはグリッドベース手法も多く提案されています。グリッドベース手法の紹介はこちらの「Introducing "Instant Neural Graphics Primitives with a Multiresolution Hash Encoding"」の資料が非常にわかりやすく、本記事での説明は省きます。
グリッドベース手法における動的シーンの課題としては、空間方向の3次元だけでなく時間方向の軸も入った4次元で表現する必要があり、メモリ消費量が非現実的です。K-Planes[Fridovich-Keil+ CVPR2023]では、3次元空間面(x-y, y-z, x-z)と時空間面(x-t, y-t, z-t)の6つの平面にテンソル分解して時間方向の軸を表現することで現実的な計算量で柔軟に表現することを可能にしました。同様の手法としてHexPlane[Cao+ CVPR2023]が提案されて、Gaussian Splattingにおいても時間方向に拡張した4D Gaussian Splatting[Wu+ CVPR2024]も提案されています。

K-Planes[Fridovich-Keil+ CVPR2023]
1.2.3 EmerNeRF [ICLR2024]
EmerNeRF[Yang+ ICLR2024]は、動的シーンに対応したNeRFをストリートビューデータに拡張した手法になっています。グリッドベース手法であり、学習可能なハッシュ関数で静的場では3次元空間(x, y, z)、動的場やフロー場では4次元空間(x, y, z, t)でそれぞれ特徴量gと密度σを構築します。色に関しては特徴量gを用いてMLP Headで予測し、密度σを用いてレンダリングします。こちらのプロジェクトページでEmerNeRFの様々なデモが見れますが、非常に鮮明な画像が生成できているのが確認できます。
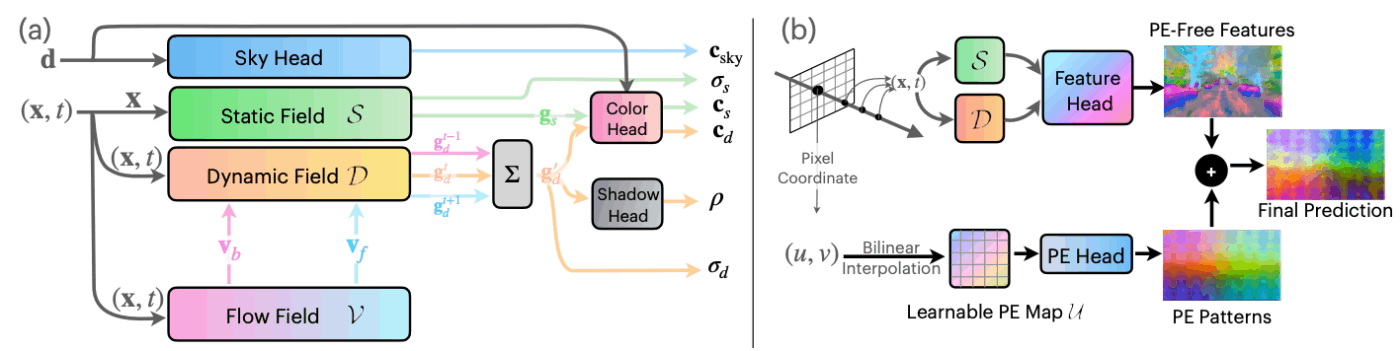
EmerNeRF[Yang+ ICLR2024]
EmerNeRFの面白い特徴の1つが、DINOv2などの画像特徴量を3次元にlift可能なところです。後述する3次元のPerceptionタスクなどにおけるオートラベリングへの応用が期待されます。

EmerNeRFから引用
1.3 Gaussian Splattingの活用
DrivingGaussian[Zhou+ 2023]やStreet Gaussians[Yan+ 2024]は、動的なストリートビューデータに対応したGaussian Splatting手法です。どちらの手法もNeRF手法と比較して高速なレンダリングが可能で、新規視点生成した画像の品質が改善されています。特にStreet Gaussiansは、シーンの編集や2次元のセマンティックセグメンテーションなどの様々なCVタスクに応用できることを主張しています。
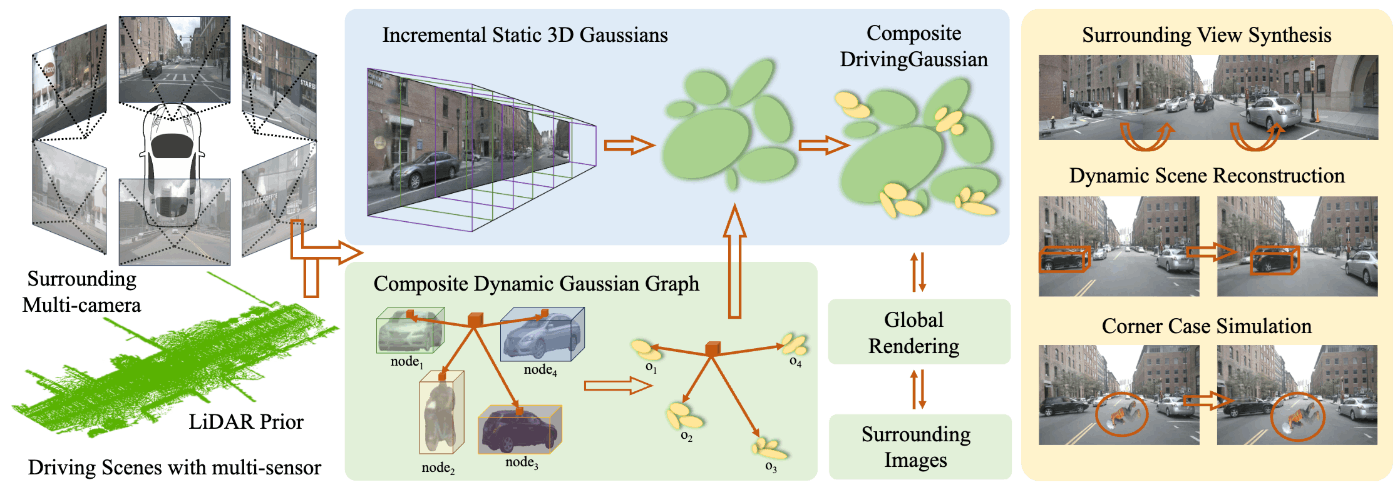
DrivingGaussian[Zhou+ 2023]

Street Gaussians[Yan+ 2024]
2. NeRF / 3DGSの活用
これらNeRF/3DGSは自動運転に関わる多くのタスクに応用されています。特にチューリングが注目している応用先として、収集したデータから構築するclosed-loop simulator、自己教師あり学習への活用、3次元物体検出などのオートラベリングの3つです。
2.1 Closed-loop simulator
自律運転システムの評価は、open-loopでの評価(オフライン評価)とclosed-loopでの評価(オンライン評価)の2つに分かれます。Open-loop評価は実際の走行データに対して、そのシステムが実際の走行とどれだけ誤差なく同様の操作ができているかを評価します。一方で、closed-loop評価はシミュレータなどを用いて、自律車両の行動と他の交通エージェントの行動がタイムステップ毎に相互作用するような世界で走行能力(e.g., 衝突性、ルートの逸脱性、交通ルールの厳守性)を評価します。
チューリングが開発するモデルのパスプランニングにおいては、模倣学習を行います。実際の運転データの経路とモデルが予測する経路の誤差を最小化するように学習し、いわばopen-loop評価機構が損失関数として機能します。
この模倣学習で実世界で自律走行を行うには、様々な課題があります。Codevillaら[ECCV18]はopen-loop評価とclosed-loopでの運転品質には必ずしも相関がないことを主張し、共変量シフト問題というclosed-loop評価時には誤差が蓄積され続けて学習時と異なるデータ分布になり正常的な行動が取れない問題を指摘しています。詳細については「【E2E連載企画 第1回】End-to-end 自動運転という新しいパラダイム」をご覧ください。
では、CARLAなどのシミュレータを用いて学習・シミュレータをすればいいか、といわれると異なる難しさがあります。大規模に様々なバリエーションのシナリオを作成することには限界があり、シミュレーションデータと実世界とのドメインギャップが発生してしまいます。そのため理想的には、実世界で起きる様々な状況下での走行データをもとにしたデータ駆動型のclosed-loop simulatorが必要になります。
2.1.1 Ghost Gym - Wayve
Wayveはイギリスに拠点を置く自動運転スタートアップで、E2Eの深層学習ベースの自動運転システムの開発を行っています。WayveはGhost GymというNeRFをベースとしたnerual simulatorを開発しています。このNeRFは収集した走行データの動画をもとに3次元空間と時間の4D表現を学習し、様々な時空間点で新規視点の作成が行えるようになりました。さらに自律車両の内部システムをモデル化することで、より正確にシミュレートすることを可能にしています。
実際、Ghost Gymを活用して同じシーンで異なるモデルのclosed-loopでの評価を行い、相対的にモデルの運転性能を評価していることをブログで述べています。また、以下の動画では学習時にもGhost Gymを活用したデータ増強を行っていることを主張しており、共変量シフト問題など模倣学習に起こる課題に対する1つの解決策としてNeRFを活用しています。
2.1.2 UniSim - Waabi
Waabiはカナダに拠点を置く自動運転スタートアップで、ドライバーレスな自動運転トラックの開発を行っています。WaabiはUniSim[Yang+ CVPR2023]というデータ駆動型でマルチセンサ対応のclosed-loop simulatorを開発しています。カメラ画像およびLiDAR点群の新規視点生成だけでなく、交通エージェント(アクター)の追加・削除などの操作後のセンサーデータのシミュレートも可能にします。closed-loop simulatorやデータ増強にも広く活用できます。
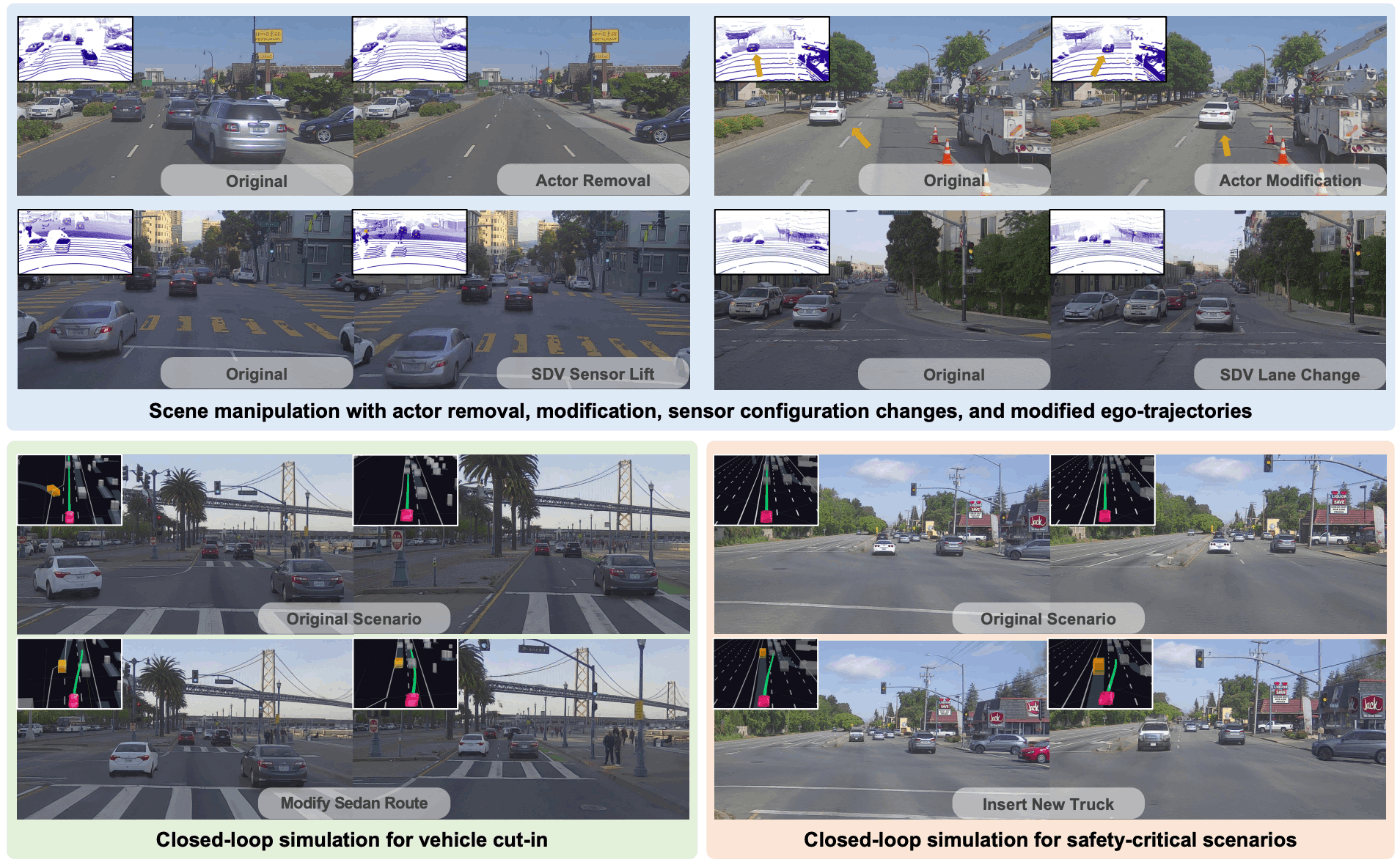
UniSim[Yang+ CVPR2023]
2.1.3 世界モデル
NeRFや3DGSとは直接関係はありませんが、先日、チューリングから「運転版の"Sora"を作る: 動画生成の世界モデルTerraの開発背景」として世界モデルの開発を進めていることを発表しました。この世界モデルは主に短い動画を与えるとその続きを生成するvideo rolloutと、その先で辿って欲しい軌跡を条件づけるとその通りに動画生成するaction-conditioned generation機能を有しています。この世界モデルもゆくゆくシミュレータとして応用していきます。
2.2 オートラベリング
NeRFや3DGSを活用したオートラベリングも期待されています。先に紹介したEmerNeRFは画像特徴を3次元空間にliftしているため、3次元情報とその画像特徴を使うことができます。論文中では空間中の物体の占有を予測するOccupancy predictionというタスクを少数のサンプルで学習しており、単純な画像のセマンティックセグメンテーションや深度推定以外にも、画像特徴のエンコーダとしてCLIPなどを用いればOpen Vocabularyな物体認識にも応用が可能です。
特にOccupancy predictionはNeRF技術が応用されており、マルチカメラ画像のみでOccupancyの自己教師あり学習を行うSelfOcc[Huang+ CVPR2024]が提案されています。画像特徴からBEV空間に変換した後に、微分可能なボリュームレンダリングを採用してSDF場(Signed Distance Function; 符号付き距離関数)を求めて、最終的にはボクセル表現に変換します。

2.3 事前学習への活用
自己教師あり学習を行うOccupancy predictionは画像エンコーダーの事前学習にも応用されています。MIM4D[Zou+ 2024]は画像の一部をマスクし、またボクセル特徴をドロップして復元して微分可能なボリュームレンダリングで再度2次元平面に投影した画像と元の画像を比較した損失で自己教師あり学習を行います。これによって学習された画像エンコーダーを用いることで、BEVセグメンテーションや3D Object Detectionなど様々な下流タスクで改善が見られました。

MIM4D[Zou+ 2024]
3. おわりに
NeRFや3DGSは自動運転の分野でも強く使われ続けており、特にデータ駆動なシミュレータとしての活用が顕著なように感じます。それ以外にもオートラベリングの活用であったり、NeRFの技術を応用した事前学習など個人的に面白い話がどんどん提案されています。
チューリングではこういった技術も追っていきたいですが、いかんせん人が足りません。チューリングで収集した走行データもたくさんあるので、ぜひこういった技術に興味がある方、チューリングのデータで遊んでみたい方はお声かけください!
4. 参考
- NeRF-RPN:NeRF上で物体検出する技術
- 驚くほどキレイな三次元シーン復元、「3D Gaussian Splatting」を徹底的に解説する
- Introducing "Instant Neural Graphics Primitives with a Multiresolution Hash Encoding"
- Ghost Gym: A Neural Simulator for Autonomous Driving
- Mildenhall, B., Srinivasan, P. P., Tancik, M., Barron, J. T., Ramamoorthi, R., & Ng, R. (2021). Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 65(1), 99-106.
- Xie, Z., Zhang, J., Li, W., Zhang, F., & Zhang, L. (2023). S-nerf: Neural radiance fields for street views. arXiv preprint arXiv:2303.00749.
- Pumarola, A., Corona, E., Pons-Moll, G., & Moreno-Noguer, F. (2021). D-nerf: Neural radiance fields for dynamic scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 10318-10327).
- Li, Z., Niklaus, S., Snavely, N., & Wang, O. (2021). Neural scene flow fields for space-time view synthesis of dynamic scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 6498-6508).
- Fridovich-Keil, S., Meanti, G., Warburg, F. R., Recht, B., & Kanazawa, A. (2023). K-planes: Explicit radiance fields in space, time, and appearance. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 12479-12488).
- Cao, A., & Johnson, J. (2023). Hexplane: A fast representation for dynamic scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 130-141).
- Wu, G., Yi, T., Fang, J., Xie, L., Zhang, X., Wei, W., ... & Wang, X. (2024). 4d gaussian splatting for real-time dynamic scene rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 20310-20320).
- Yang, J., Ivanovic, B., Litany, O., Weng, X., Kim, S. W., Li, B., ... & Wang, Y. (2023). Emernerf: Emergent spatial-temporal scene decomposition via self-supervision. arXiv preprint arXiv:2311.02077.
- Zhou, X., Lin, Z., Shan, X., Wang, Y., Sun, D., & Yang, M. H. (2024). Drivinggaussian: Composite gaussian splatting for surrounding dynamic autonomous driving scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 21634-21643).
- Yan, Y., Lin, H., Zhou, C., Wang, W., Sun, H., Zhan, K., ... & Peng, S. (2024). Street gaussians for modeling dynamic urban scenes. arXiv preprint arXiv:2401.01339.
- Yang, Z., Chen, Y., Wang, J., Manivasagam, S., Ma, W. C., Yang, A. J., & Urtasun, R. (2023). Unisim: A neural closed-loop sensor simulator. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 1389-1399).
- Huang, Y., Zheng, W., Zhang, B., Zhou, J., & Lu, J. (2024). Selfocc: Self-supervised vision-based 3d occupancy prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 19946-19956).
- Zou, J., Liao, B., Zhang, Q., Liu, W., & Wang, X. (2024). MIM4D: Masked Modeling with Multi-View Video for Autonomous Driving Representation Learning. arXiv preprint arXiv:2403.08760.

Discussion