3行でまとめると
- LLM分散学習ハッカソンに参加し、Vision-Languageモデルの一つであるBLIP2のHuggingFaceモデルを拡張して動画からテキスト生成するVideoBLIPを作成しました。ソースコードはGithubで公開しています。
- 運転映像に対する説明文章を学習に用いてVideoBLIPの学習を行い、運転映像を説明するモデルを作成しました。(以下のように運転映像に対して説明文が出力されます)
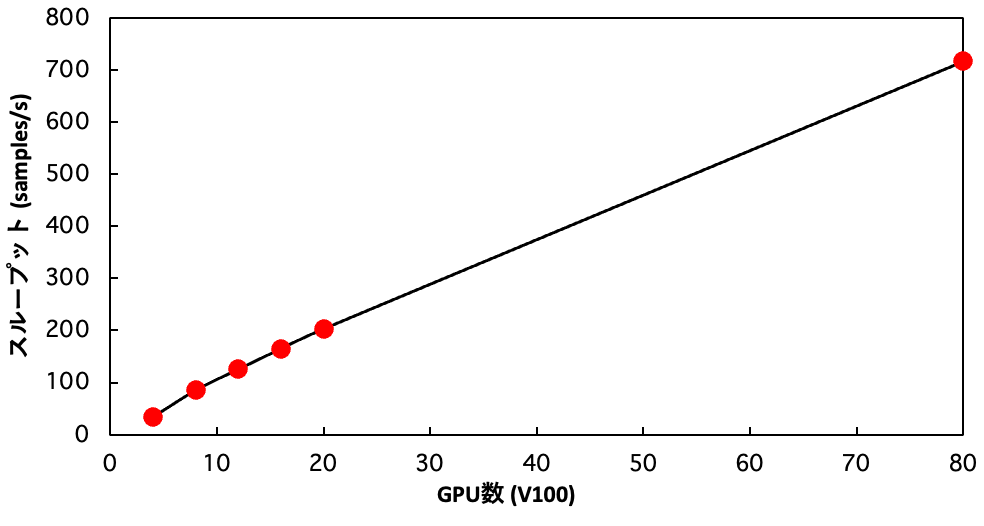
- 学習を高速化するためにマルチノードで学習を行えるようにし、実際にABCIのGPU80台を使って分散学習を行い、4GPUで行った場合の20倍の計算速度が実現できました(Strong Scaling!) 分散並列学習にはDeepSpeedを用いました。
はじめに
Brain Researchチームで自動運転AIを開発している棚橋です。Brain Researchチームではレベル5の完全自動運転を行うための研究開発を行っているのですが、これを達成するためには車の周囲の状況をより高度な文脈で把握するモデルの開発が必要であると考えています。
例えば…
- 右折待ちをしていたら直進車がライトをパッシングした。道を譲ってくれたのだろう。
- 前の車が急にブレーキを踏んで右側に避けた。自転車が走っているのかもしれない。
というように、人間は運転中、常に高度な状況判断を行っています。
つまり、単純に周囲の車や歩行者の位置座標を数値として把握すれば自動運転ができるわけではなく、その状況がどういう状況なのか、周囲の人や車の意図まで含めたコンテキストを汲み取る必要があります。
なぜVision-Languageモデルなのか
端的にいうと画像を言語で説明させることで「世界を表すベクトル」を獲得するためです。
現在提案されている画像からテキストを生成するVision-Languageモデルは以下の図のような構造をしています。画像をEncoderに通してConverter経由でLLMに入力すると、LLMが文章を出力します。さらに画像に対して質問を投げかけることができ、それをLLMから出力させることができます。
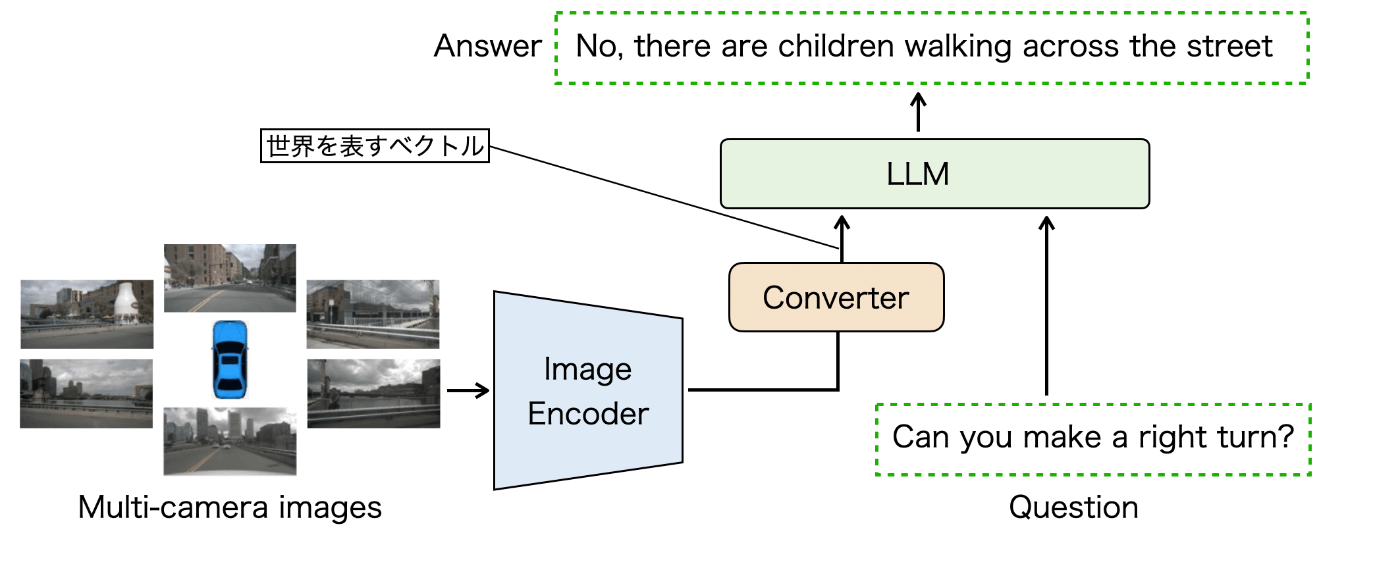
つまり、運転画像に対してさまざまな質問を投げかけて、適切に答えさせることができれば、このモデルは実質的に「運転状況を理解した」と言えそうです。
さらにこのモデルにおいて、Converterを経由して画像から抽出した特徴ベクトルは「世界を表すベクトル」と言えます。LLMによって言語を出力させなくても、この世界を表すベクトルを経路計画などのさまざまな自動運転タスクに用いることで、高度な文脈を考慮したモデルの作成が可能になると考えています。
Vision-Languageモデル
LLMを用いて画像からテキストを生成するVision-Languageモデルは、学習済みの画像エンコーダと学習済みの言語モデルを接続することによって作成することができます。この接続のための学習を”Alignment”と呼びます。
代表的なvision-languageモデルとして、LLaMA Adopter、Flamingo、BLIP2、MiniGPT4、LLaVAなどがあります。構造の種類を大きく分けると以下の図のように3種類に分けることができます。

FlamingoではPerceiver Resamplerで画像特徴を固定長のトークンに変換します。このように作成した画像特徴をLLMのtransformerに対してGatedクロスアテンションすることでLLMに画像情報を付与するという仕組みです。学習開始時にLLMに対して影響を与えないようにゲートを使うようになっています。
BLIP2はQ-Formerと呼ばれるBERTにクロスアテンション層が挿入された構造を持っており、画像エンコーダからの画像特徴が学習可能なクエリに対してクロスアテンションされ、その出力がLLMに画像トークンとして挿入される仕組みになっています。画像エンコーダと言語モデルのパラメータは固定して、Q-Formerのパラメータのみの学習を行うという特徴があります。
LLaVAとMiniGPT4では、画像エンコーダの出力と言語モデルを線形変換で結んだだけのシンプルな構造になってます。学習の一段階目では線形変換層のみを学習し、学習の二段階目では画像エンコーダのみ固定して、線形層と言語モデルのパラメータの学習を行います。
BLIP2を動画入力に対応させる
画像だけではなく動画を扱うことができれば、動画の中の動きの情報をテキスト出力に反映させることができます。特に運転映像では車の速度の情報も重要となりますので、動画に対応できると良さそうと思い、BLIP2を動画入力に対応させることを考えました。
既存のモデルでは画像をvision encoderに入れてそれをQ-Formerのcross-attentionレイヤーにKey, Valueとして渡していました。これを動画対応させるために、画像を複数渡すようにします。
以下の図のように、元々のEncoderから出力された画像特徴はバッチサイズB×系列長N×特徴次元Dの形をしています。

Transformerのcross-attentionに渡すKey, Valueの系列は長さを変えることができるので、動画対応させるために複数の画像特徴を系列方向に並べて連結させるということを行ないます。最終的なテンソルのサイズはB×Nn×Dとなります。ここでnは動画のフレーム数です。さらにフレーム位置の情報を入れるために学習可能な位置埋め込みベクトルを足し合わせます。このようにして作成した系列長Nnの動画特徴をQ-Formerのcross-attention層に挿入することによって動画の特徴量を取り入れることができます。
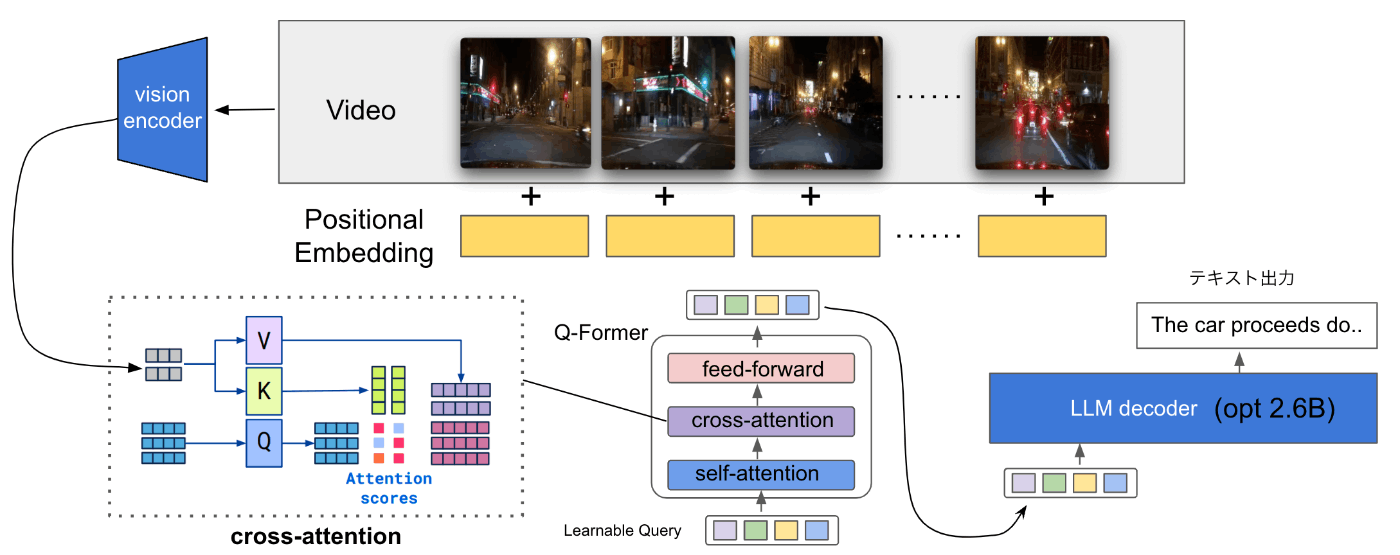
動画特徴を作るコードは以下になります。pixel_valuesには複数フレームの画像情報が入っており、これが1枚ずつvision_modelに渡されるとvision_outputsにB×N×Dの特徴が出力されるので、それをリストであるvisual_featuresに追加します。最後にvisual_featuresをdim=1でconcatして動画特徴であるvideo_embedsを作成しています。
visual_features = []
num_frames = pixel_values.shape[1]
for frame_idx in range(num_frames):
# 画像特徴を計算
vision_outputs = self.vision_model(
pixel_values=pixel_values[:, frame_idx, :, :],
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
visual_features_frame = vision_outputs[0]
# ポジションエンコーディングを加算
visual_features_frame += self.img_temperal_embedding[frame_idx]
visual_features.append(visual_features_frame)
# visual_featuresを系列方向に連結して動画特徴を作成
video_embeds = torch.cat(visual_features, dim=1)
HuggingFaceを使ったモデルの学習
今回作成したVideoBLIPの学習方法について説明します。学習の処理はfeature_blip_deep_speed.pyのmain関数の中に記述されているのですが、非常に簡単に記述できます。
画像と文字列を扱うデータセットの作成
まず、学習対象となる学習用と評価用のデータセットを作成します。今回はpytorchのDatasetクラスを継承してオリジナルのデータセットを作っています。データセットの__index__(self, index)メソッドではindex番目のデータを提供するように記述するのですが、dict形式でVideoBLIPのforwardメソッドの引数に対応する項目「input_ids, labels, attention_mask, pixel_values」を返す必要があります。promptには画像に対する質問と回答をつなげた文字列が入っており、これをtokenizeしたものをinput_idsにいれています。また渡した文字列の長さによらずに出力されるtoken列の長さが常に一定に保たれるように、tokenizerにはtruncation=Trueとmax_lengthを指定しています。これにより文字列よりも長い分の空白はpadding tokenで埋められるようになり、max_lengthより長い文字列は途中で切られます。attention_maskは文字列が入っている箇所の部分だけが1になり、入っていない箇所には0が入っているマスクです。
def preprocess_image(self, images):
return self.processor(images=images, return_tensors="pt")["pixel_values"]
def tokenize(self, text):
return self.processor(
text=text, return_tensors="pt", padding='max_length',
max_length=self.max_length, truncation=True)
def __getitem__(self, index) -> dict:
row = self.data_df.iloc[index]
answer = row["action"] + " " + row["justification"] + "."
prompt = f"Question: Could you describe the driving image? Answer: {answer}"
tokenized_prompt = self.tokenize(prompt)
tokenized_prompt = tokenized_prompt["input_ids"][0]
prompt_attn_mask = tokenized_prompt["attention_mask"][0]
base_filename = row['img_path'][:-4].split("_")[0]
index = int(row['img_path'][:-4].split("_")[1])
images = []
for i in range(self.n_frames):
tmp_index = index - 15 * (self.n_frames - i)
tmp_img_path = f"images/%s_%05d.jpg" % (base_filename, tmp_index)
tmp_image = Image.open(tmp_img_path)
images.append(tmp_image)
return_dict = {
"input_ids": tokenized_prompt,
"labels": tokenized_prompt,
"attention_mask": prompt_attn_mask,
"pixel_values": self.preprocess_image(images)
}
return return_dict
labelsには出力されるべき文字列が入るのですが、これは入力値と同じになるので、input_idsと同じものを渡します。以下の図ではinput_idsとlabelsがどのように使われるかを示しています(便宜的に1文字=1トークンとしています)。LLMの前半にはQ-Formerの出力として作成された動画トークンが入力されます。動画トークンに続いて、質問と回答を合わせたテキストのトークン列であるinput_idsが入力されます。この入力に対するLLMの出力は次のトークンの予測となるので、それがinput_idsと同じものを予測するようにロスを計算します。この時、内部的には1つトークンをずらすことで予測に対するロスを計算しています。

元々BLIP2はSalseforceが作成したLAVISというvision-language系モデルのライブラリの中で実装が公開されていました。その一部がHuggingFaceに移植されている形になっているのですが、LAVISのBLIP2のコードではpromptにおいて質問部分と回答部分を区別して扱い、質問部分においてロスを計算しないようになっています。我々が興味があるのは出力された質問の回答部分なので、このロスの計算方法は理にかなっていると言えます。
TrainingArgumentsの設定
学習にはHuggingFaceのTrainerクラスを使っています。このTrainerクラスに渡すさまざまな設定はTrainingArgumentsオブジェクトとして渡しています。この設定はconfig_finetune.yamlに記述されており、中身は以下のようになっています。
training:
per_device_train_batch_size: 8
gradient_accumulation_steps: 1
num_train_epochs: 5
dataloader_num_workers: 4
fp16: true
optim: "adamw_torch"
learning_rate: 1.0e-4
logging_steps: 10
evaluation_strategy: "steps"
save_strategy: "steps"
eval_steps: 1000
save_steps: 1000
save_total_limit: 30
report_to: "wandb"
deepspeed: ds_config.json
output_dir: "output_dir/"
- per_device_train_batch_size: GPU単位でのミニバッチサイズを指定します。今回の場合、メモリが溢れない中で値を大きくした方が全体のスループットが向上することが確認できました。
- gradient_accumulation_steps: この値を大きくすると擬似的にミニバッチのサイズを大きくすることができます。メモリの限界でバッチサイズがどうしても小さくなるが学習において勾配計算に使うバッチサイズを大きくしたい時に使います。
- dataloader_num_workers: trainerクラスにはDatasetオブジェクトを渡すと内部的にdataloaderが作成されます。このdataloaderは非同期でデータをモデルに提供するのですが、このワーカー数を指定します。今回は1ノードにGPUが4つ接続されていたので4を指定しています。
- fp16: 学習時に計算を高速化するfp16計算を有効にするかどうかを指定します。類似の技術であるbf16の方が表せる値の範囲が大きいのでディープラーニングモデルの学習が安定すると言われているのですが、A100などのAmpereアーキテクチャーが搭載されているハードウェアでないと利用することができません。今回私はv100を使ったのでfp16を利用する設定にしています。
- learning_rate: 最初学習率を1.0e-3で学習すると出力される文字列が全て同じになってしまったため、値を1.0e-4に下げたところロスも下がるようになり、出力もまともになりました。
- report_to: wandbでログを可視化して見れるようにしたいので”wandb”を設定しています。
- deepspeed: 適用したいDeepSpeedの設定ファイルのパスを指定します。HuggingFaceのTrainerを用いることのメリットの1つは、DeepSpeedを手軽に利用できるという点です。DeepSpeedは複数のGPUを用いてスケーラブルにモデルを分散学習するためのツールで、Zero Redundancy Optimizer (ZeRO)という技術を用いることでオプティマイザーやモデルの勾配情報を分散させて保持することで少ないGPUメモリで巨大なモデルを扱うことができます。また、どの程度まで分散させるのかという最適化の程度に応じてstage1~stage3までの設定が存在する(以下のテーブルの2~3行目に対応)。stageを上がると必要なメモリ数が非常に少なくて済むようになっていることがわかると思います。
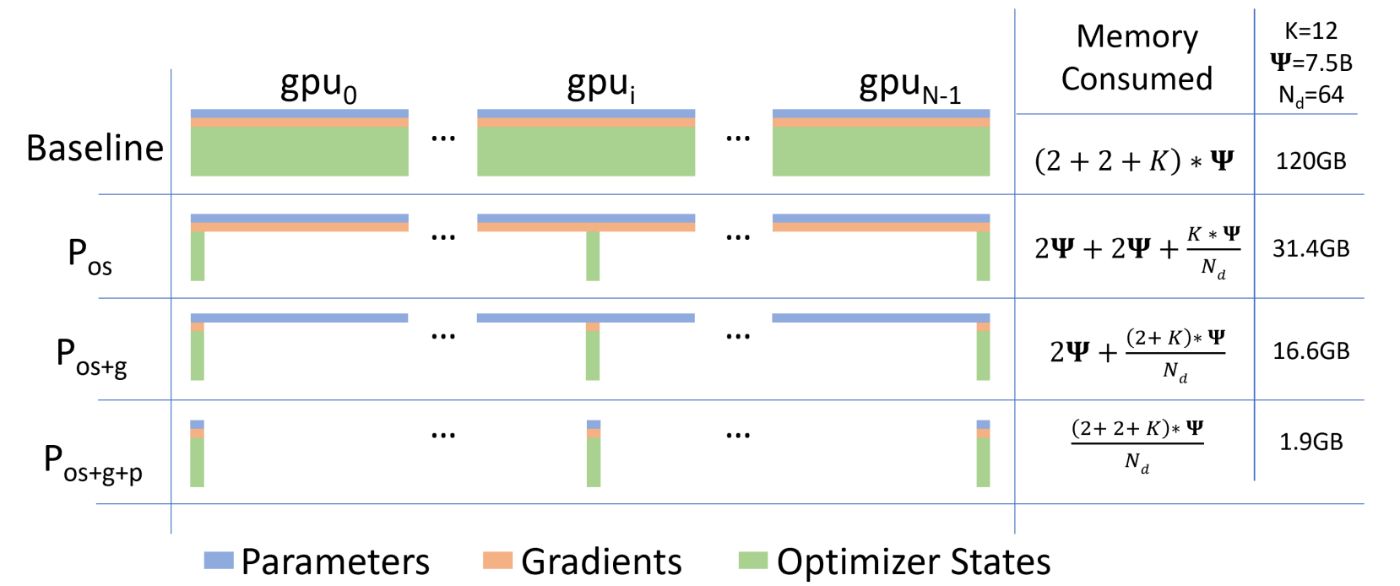
ただし、stageが上がるとCPUとの通信コストが大きくなってくるので、モデルのサイズを考えながらどの最適化を用いるかを決める必要があります。今回はZeroのstage2の設定を適用しています。以下は用いたDeepSpeedのZeROの設定に関する部分です。DeepSpeedを使って学習処理を行う方法は後述します。
...
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"contiguous_gradients": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
...
学習するパラメータの指定
続いて、モデルの中でどの部分を学習するかを指定します。BLIP2のファインチューンではVisionモデルとLLMのパラメータを固定して、それ以外のQ-Formerのパラメータの学習を行います。
これを行うにはmodel.named_parameters()を使って全てのモデルパラメータを取得して、学習しないパラメータのrequires_gradプロパティをFalseに変更します。最後に、Trainerクラスを作成してモデルの学習を行なっています。
from blip_2_video import Blip2ForConditionalGeneration
def main(config_file: str, model_name: str):
deepspeed.init_distributed()
train_df = ...
eval_df = ...
# データセットの作成
train_dataset = SupervisedDataset(model_name, train_df, max_length=64)
eval_dataset = SupervisedDataset(model_name, eval_df, max_length=64)
# モデルの読み込み
model = Blip2ForConditionalGeneration.from_pretrained(
model_name, torch_dtype=torch.float16)
# TrainingArgumentsの設定
with open(config_file, "r") as i_:
config = yaml.safe_load(i_)
training_args = transformers.TrainingArguments(**config["training"])
# 凍結するパラメータと学習するパラメータの設定
for name, param in model.named_parameters():
if "vision_model" in name:
param.requires_grad = False
if "language_model" in name:
param.requires_grad = False
# Trainerクラスを使って学習を開始
trainer = transformers.Trainer(
model=model,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
args=training_args,
)
with torch.autocast("cuda"):
result = trainer.train()
ABCIの80台のGPUを使ったマルチノード分散学習
LLMハッカソンはABCIのスパコンのV100ノードをたくさん使ってLLMを学習しようというテーマなので、今回作成したVideoBLIPを複数のGPUで分散学習してみました。VideoBLIPでは2.6BのOPTをLLMに使っているため、V100のGPUにはモデルのパラメータすら乗せることができません。学習を行うにはモデルのパラメータに加えて、勾配情報、モメンタムなどのオプティマイザの状態が必要となるため、さらに大きなGPUメモリを必要とします。このような場合においてもDeepSpeedを用いることで大きなモデルの学習が可能となります。
ABCIの環境でDeepSpeedコマンドを使って学習を行うコマンドを以下に記します。(ユビーの太田さんが提供してくれたサンプルコードが非常に参考になりました!) ABCIの場合、launcherをOpenMPIに設定する必要があるという点などが注意ポイントです。
#!/bin/bash
#$ -l rt_F=10
#$ -l h_rt=2:00:00
#$ -j y
#$ -N finetune_blip
#$ -o logs/
#$ -cwd
source /etc/profile.d/modules.sh
module load python/3.11 cuda/11.7 cudnn/8.6 hpcx-mt/2.12
source .venv/bin/activate
export WANDB_NAME="BLIP-batch-"$(date "+%Y-%m-%d-%H:%M")
cat ${SGE_JOB_HOSTLIST} | awk '{print $0, "slots=4"}' > hostfile
export HF_HOME=/scratch/$(whoami)/.cache/huggingface/
export PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python
export CONFIG="exp/${EXP}/config_finetune.yaml"
export MODEL="Salesforce/blip2-opt-2.7b"
export MASTER_ADDR=$(cat ${SGE_JOB_HOSTLIST} | head -n 1)
export TOKENIZERS_PARALLELISM=false
export WANDB_PROJECT="abci-llm-hackathon"
export PYTHON_FILE="exp/${EXP}/finetune_blip_deepspeed.py"
deepspeed --hostfile hostfile --launcher OpenMPI --no_ssh_check --master_addr=$MASTER_ADDR $PYTHON_FILE --model_name $MODEL --config_file $CONFIG
学習の過程
先述の学習の設定でreport先をwandbに設定したため、wandbのwebサイト上のダッシュボードでモデルの学習結果を確認することができます。下のグラフは学習ロスを表しており、イテレーションとともに順調に下がっていることが確認できます。wandbでは学習過程をリアルタイムに記録して表示してくれるので実験管理にとても便利なツールです。
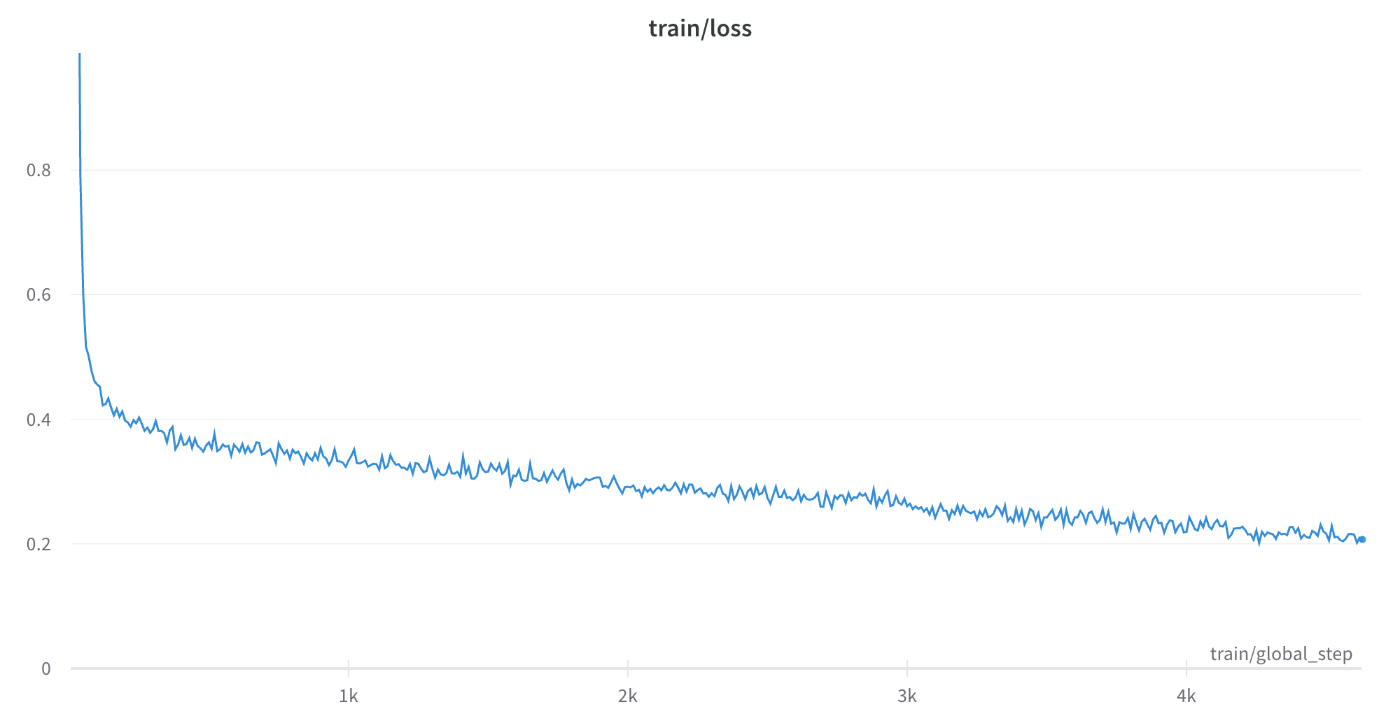
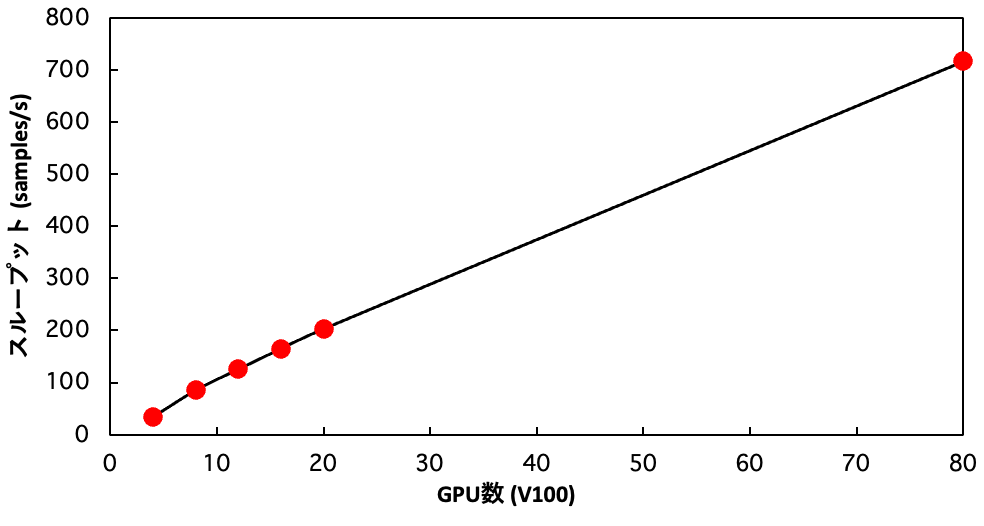
1イテレーションでは、ミニバッチサイズ×GPU数のデータサンプルが処理されます。次に、GPU数(つまりノード数)を増やした時にどのようにスループットが変化するかを計測した結果が下のグラフになります。GPU数を上げるとそれにおおよそ比例してスループットも大きくなっていることが確認できます。80GPU(20ノード)で学習を行うと、4GPU(1ノード)で学習した場合の20倍の学習速度が実現されていることを確認することができました。今回使ったABCIの環境ではディスクアクセスに時間がかかる傾向が見られたため、学習計算そのものよりもディスクIOの方が計算のボトルネックになっていた可能性があります。そのためにノード数に対して綺麗に計算速度が比例したと考えられます。
学習したモデルの出力結果
今回の学習にはBDD-Xと呼ばれる運転動画に対する説明文を手動でラベリングしたデータセットを利用しています。この動画を0.5秒間隔で5枚の画像を一つの動画としてVideoBLIPに入力しています。つまり、直前の2.5秒の映像の出来事をテキストで出力させるようになっています。実際に動画と出力されたテキストを見ていると、信号が赤から青に変化したことや、車の速度の変化、右左折を検知できていることが確認できました!

また、学習したデータは海外の道路ですが、試しに日本の運転映像に対して推論を行って見たところ、少し不安定な部分もありますが料金所に入る様子を説明することができました。データが変わるとカメラの画角や道路の形式、交通標識なども変わってくるので、学習データをどのように準備するかということの重要性を確認することができました。
まとめ
今回は自動運転におけるvision-languageモデルの紹介、BLIP2を動画に拡張する方法、またそのモデルを複数のGPUを使って分散学習する方法について紹介しました。
LLMの分散並列学習の技術に関しては、弊社の過去のテックブログの記事でも詳細に解説していますのでぜひ読んでみてください!
採用情報
Turing では自動運転モデルの学習や、自動運転を支えるための基盤モデルの作成のために分散並列学習の知見を取り入れた研究開発を行っています。興味がある方は、Turing の公式 Web サイト、採用情報などをご覧ください。話を聞きたいという方は私やAIチームのディレクターの山口さんの Twitter DM からでもお気軽にご連絡ください。


Discussion
参考になる記事をありがとうございます。githubレポジトリにアクセスできなかったのですが、非公開にされましたでしょうか?