TuringでResearcherをしているいのいちです。
先日、会社にサポートしていただいてニューオーリンズで開催されたNeurIPS 2023に参加させていただくことができたので、今年のNeurIPSで発表された自動運転系の論文をいくつかピックアップして紹介しようと思います。

NeurIPSとは
NeurIPSは1987年から開かれている機械学習系でトップの国際会議です。この会議が発足した当初はBiologicalとArtificialの両方の側面からニューラルネットワークを研究しようという趣旨があり、長らく神経科学からも理解しようという趣旨があったようです。現在はこの国際会議で発表される多くの研究が機械学習や人工知能といったコンピューターサイエンス系のものが主体にはなっていまが、参加してみて他の機械学習やコンピュータビジョン系の学会よりも生物学と関連した研究も多く、生物学出身の私としてはどこか郷愁を感じる学会でした。
そのような学会のカルチャーもあり、自動運転が大々的に取り上げられるわけではないのですが、やはり自動運転における機械学習というのは非常に重要な分野であり、NeurIPSでも面白い研究がいくつか発表されていました。
自動運転の研究 in NeurIPS
この記事では、特にTuringでも興味を持っているカメラを使った自動運転に関連のありそうな論文をピックアップして紹介します。自動運転の論文自体そんなに多いわけではないですが、近年このカメラを用いた自動運転の手法は注目されている分野でもあるので、非常に面白い論文がNeurIPSでも発表されていました。
(断りのない限り、図は該当論文から引用しています。)
Leveraging Vision-Centric Multi-Modal Expertise for 3D Object Detection
arxiv: https://arxiv.org/abs/2310.15670
最近、自動運転のセンサーとしてカメラのみを使うVision Centricな自動運転モデルの研究が盛んです。Teslaが量産車でも実現可能な自動運転の方法としてPure visionの自動運転を掲げており、アカデミアでもカメラのみを使う自動運転の研究が盛んになってきました。参考1, 2, 3
しかし、カメラではやはりLiDARよりも深度情報をとるのが苦手で、3次元の物体検出などでいまだにLiDARも使った手法には及びませんでした。そこで、LiDARも使ったモデルをExpertモデルとしてVisionベースのモデルがその中間状態を真似るように蒸留学習する手法がこれまでいくつも提案されてきました。しかし、LiDARを用いた手法とVisionベースの手法にはドメインギャップがあり、このような蒸留が不十分でした。

この論文では、このドメインギャップを埋める手法を提案しています。さらに、周囲の物体の時系列情報もうまく蒸留する方法も提案しています。
ドメインギャップを埋めるために、Expertモデルも基本はVision用のモデルを用いてLiDARから取得したデータは深度情報として使用します。カメラ映像から抽出した特徴量からLiDARの震度情報を使ったOccupancyとカメラ情報のみから作成したOccupancyでの蒸留学習と、鳥観図空間に射影したBEV特徴量での蒸留学習を行うことで、ドメインギャップのない蒸留学習ができるようになりました。
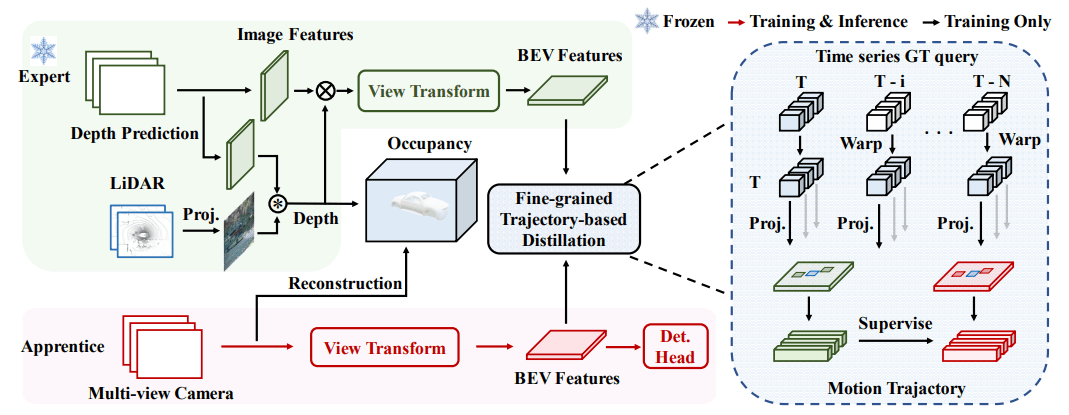
さらに、BEV特徴量での蒸留では時系列情報から周囲の物体の軌跡を求めて、その軌跡に該当する特徴量を学習対象にすることで時系列情報をいい感じに加味した蒸留学習ができるようになったと説明しています。
この論文の手法は、LiDARを使ってデータ収集することが前提ではありますが、強いVisionベースモデルを作る手法としてしっかりとキャッチアップしたい手法だと思います。
Online Map Vectorization for Autonomous Driving: A Rasterization Perspective
arXiv: https://arxiv.org/abs/2306.10502
この論文もVisionベースの自動運転で重要な「オンラインマッピング」に関する論文です。LiDARベースの手法では、あらかじめ用意された高精度3次元地図を用いて自己位置推定をしっかりとすることで非常に安定した自動運転を実現しています。しかし、このような高精度な地図は非常にコストが高く、Visionベースでは利用せずにカメラ映像から地図を再構築しようという手法が提案されています。
オンラインマッピングの手法として、BEVFormerのような鳥瞰視点から色分けしたような「ラスタライズマップ」と、MapTRのように白線や横断歩道に線を引いてそれをいくつかの点で表現して結んでいった「ベクターマップ」の2つの手法が代表的です。
ベクターマップを予測する手法は、性質上スパースな点を予測することになるので精度が低い、点をL1距離で学習することが難しいといった課題がありました。それを解決するために、本論文ではベクターマップの学習にラスタライズを組み合わせる手法を提案しています。
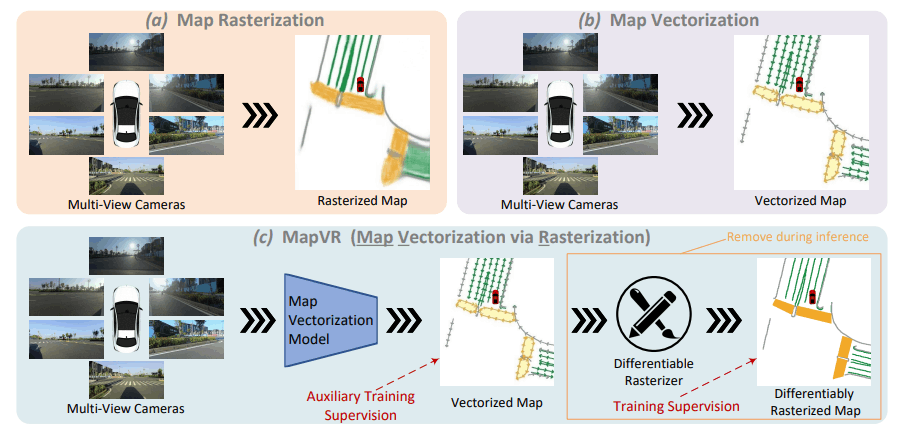
これを実現する方法はシンプルで、ベクターマップの点の情報からラスターマップを作成します。このとき、微分可能な方法でラスタライズすることでEnd-to-endに学習ができるようにしています。モデルが予測するベクターマップも正解のベクターマップも両方微分可能ラスタライズでラスタライズマップを作成し、それを用いてセグメンテーションのタスクとして学習します。

この手法は、ベクターマップを予測するようなどんなモデルにも適用することが可能です。さらに、推論時は微分可能ラスタライズはせずにベクターマップまでを推論結果として用いるので、推論のコストは変わりません。シンプルな設計ながらもとても強力な手法なのでベクターマップのモデルを作るときはぜひ参考にしたいアプローチです。
Occ3D: A Large-Scale 3D Occupancy Prediction Benchmark for Autonomous Driving
arXiv: https://arxiv.org/abs/2304.14365
2022年にTeslaのAIチームが発表したOccupancy Predictionという手法は、多くの研究者の興味を引き、2023年にはたくさんの関連論文が出ました。Occupancy Predictionとは、周囲の空間をボクセルで表現してそれを再構築する手法です。LiDARから得られる点群をボクセル空間で表現して、カテゴリーごとに色分けしたイメージです。それをVisionベースの手法で予測することで、LiDARがなくても物体の形状や深度をある程度理解した表現の獲得を目指す手法でもあります。
この論文では、nuScenesとWaymo Open Datasetの2大自動運転データセットでOccupancy Prediction用のデータセットを作成しています。

Occupancyのデータを作成する方法を簡単に紹介しようと思います。
まず、LiDARAの点群データをカテゴリーごとに色分けします。次に、時系列方向に点群情報を集めていきます。このとき、道などの背景となるような移動しない点群と、車や人のように移動する点群を別々で扱い、動く物体に関しては移動も考慮して前後の時間から点群を集めてきます。これによって、疎な点群データをより密なデータにすることができ、ボクセルで表現したときに穴が開かないようにします。時系列方向に点群を集めただけでは、まだまだ穴が開いているのでVDBFusionというアルゴリズムを用いてメッシュ再構成を行い、欠けている部分をふさぎます。
LiDARとカメラの視点から実際に観測可能なボクセルをマスクという形で持つようにして、評価の際にはそのマスクから観測可能なボクセルのみを評価対象できるようにするのが図中の「Occulusion Reasoning」です。さらに、画像でカテゴリーごとにセグメンテーションし、ピクセルに該当するボクセルのカテゴリーと比較して、ボクセルの精度を上げる処理も最後に行っています。
ボクセルのカテゴリーに関して、もともとのデータセットには存在しないが物体として存在するものにはGeneral Objectカテゴリーというものを振り分けています。走行データには、下の図(b)のように、あらかじめ定義してないけど物体として確かに存在するものはよく出てくるので、こういったカテゴリー分けはとても良いなと勉強になりました。
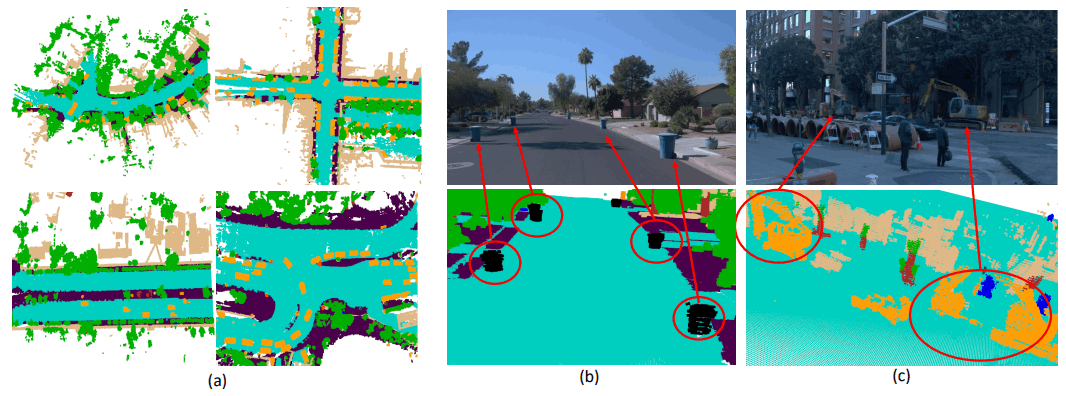
図中の(c)のような掘削機もいい感じで形がとれているのは、3次元物体検出では扱うのが難しいがいい感じにできてほしい良い例だと思います。この論文はOpen Reviewの評価を見てもとても高い評価を受けていました。Occupancy Predictionというタスクは今後も重要な自動運転の認識タスクの一つとして多くの研究が発表されると思いますし、Turingとしても研究を続けていかなければならない分野だと思っています。
その他の面白そうな論文
上記のほかにNeurIPSで私が興味を持った論文をいくつか紹介します。
自動運転系だとWaymoとGoogle DeepmindでJaxを使って開発したGPUでスケーラブルな自動運転のシミュレータである「Waymax: An Accelerated, Data-Driven Simulator for Large-Scale Autonomous Driving Research」、シンガポール大や精華大のチームが経路予測について議論している「What Truly Matters in Trajectory Prediction for Autonomous Driving?」などがありました。
自動運転以外だと、やはり大規模言語モデルに絡んだ研究が多かったです。特にNeurIPSのPaper Awardにも選ばれていた「Are Emergent Abilities of Large Language Models a Mirage?」では、大規模言語モデルの特徴である「創発」について議論しています。「創発」とは大きなパラメータのモデルにすることで突如ある能力を獲得する現象のことですが、この「創発」現象は本当に起こるのか?を評価指標の観点から問い直しており、評価方法をうまく設計すれば「創発」を予測できるのではないかと主張していてとても興味深かったです。
他にも、適切なAPIを呼んできて言語モデルだけでは答えきれないタスクも正確に答えられるようにした「Toolformer: Language Models Can Teach Themselves to Use Tools」もNeurIPSで発表されていました。最近では、ChatGPTでも似たようなことができるので、このような機能は普通に感じるかもしれませんが、データセットの作成から学習、パラメータサイズによる比較、元の言語能力がどのくらい残ってるかといった比較もしており、しっかりした研究だなと感じました。
後は、Vision language modelの代表格であるLLaVAもNeurIPSに通っています。論文としては、初代LLaVAの論文である「Visual Instruction Tuning」になります。強い大規模言語モデルとCLIPなどから学習した強いViTを線形層でつないで、画像とセットになったInstruction tuning用のデータセットを使えば、1日程度の学習で強力なVision language modelが作れるという、シンプルながらその後のVision language modelの指針となった論文になります。TuringのリサーチチームでもLLaVAにはかなりお世話になっています。日本語のVision language modelを作るときに、LLaVAのInstruction tuning用のデータセットを日本語にして使うことで簡単に強力な日本語Vision language modelを作ることができたという思い入れもあります。いつもお世話になっている論文をトップの国際会議で見ることができ、いつか彼らに並ぶ質の高い意味のある成果を世界に向けて出せるといいなと改めて思いました。
Machine Learning for Autonomous Driving Symposium
NeurIPSと同じタイミングで開催されていたMachine Learning for Autonomous Driving Symposium(ML4AD)にも参加しました。ML4ADは毎年NeurIPSでWorkshopとして開かれており、第8回の今年はSymposiumという形で開催されていました。
NeurIPS公式のWorkshopではありませんが、例年開かれていたということもあり招待講演のスピーカーはかなり豪華だったと思います。動画も以下のリンクに上がっているので、興味がある方はぜひ視聴してみてください。
NVIDIA Researchのトークセッション
豪華なスピーカの中でも、特に印象に残ったのはNVIDIA ResearchのBoris Ivanovicさんの発表でした。こちらの発表では主に3つのことが発表されていました。
個の発表で初めに紹介されていたのは、VisionベースでEnd-to-endのモデルの最強版を作ったよ、といったものでした。VisionベースでEnd-to-endなモデルはCVPR 2023でベストペーパーをとった「UniAD: Planning-oriented Autonomous Driving」をきっかけに、いくつもその改良版が提案されました。マルチタスクのモデルとして物体検出やマップセグメンテーションなど様々なタスクを解くように設計しながらも、最終的な経路予測を最適化できるようにしようというフレームワークがUniADです。NVIDIA Researchでは、これまで提案されたマルチタスクのモデルでどのタスクが必要かをしっかり吟味して、速度面も考慮しながら最適なアーキテクチャを検討しましょうという研究のようです。
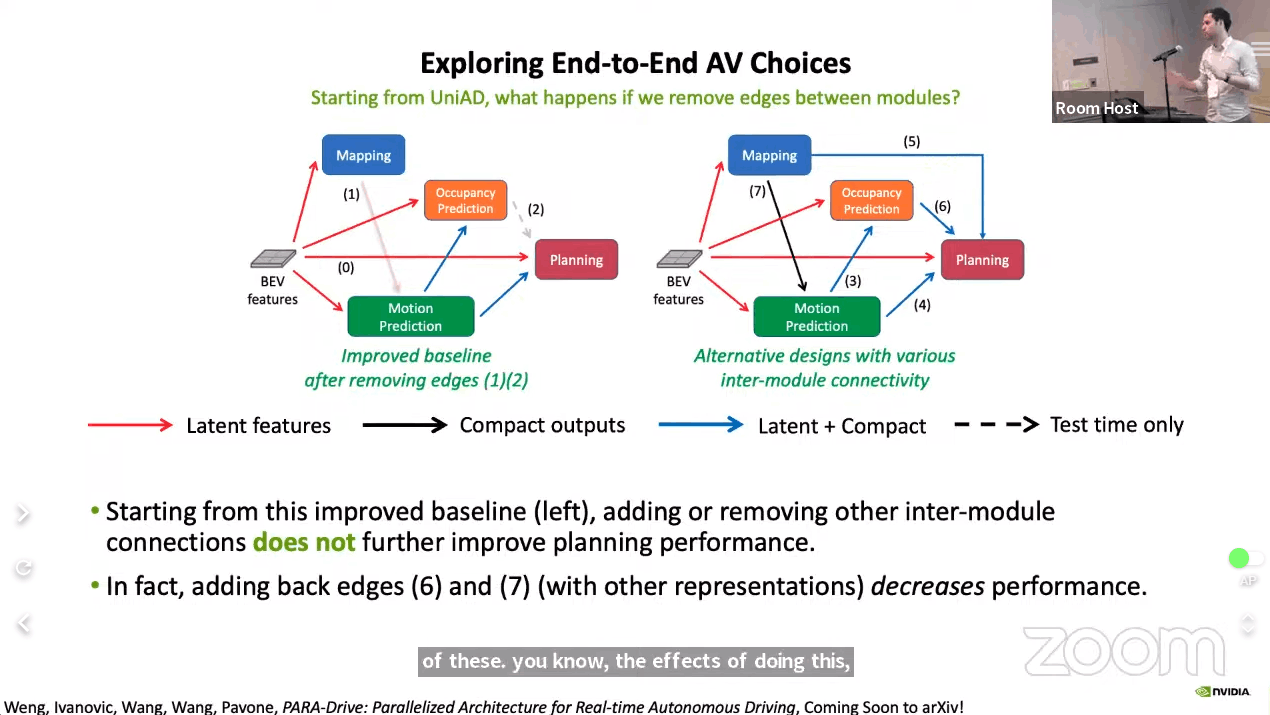
こちらの研究は近いうちに「PARA-Drive: Parallelized Architecture for Real-time Autonomous Driving」というタイトルでarXivで公開されるそうなので、今から楽しみにしています。
次に紹介されていたのは、自動運転用のNeRFである「EmerNeRF」についてです。カメラやLiDARなど普通の自動運転で収集しているデータを使って、一切のラベル付けなしに走行映像からNeRFを行ったという研究です。
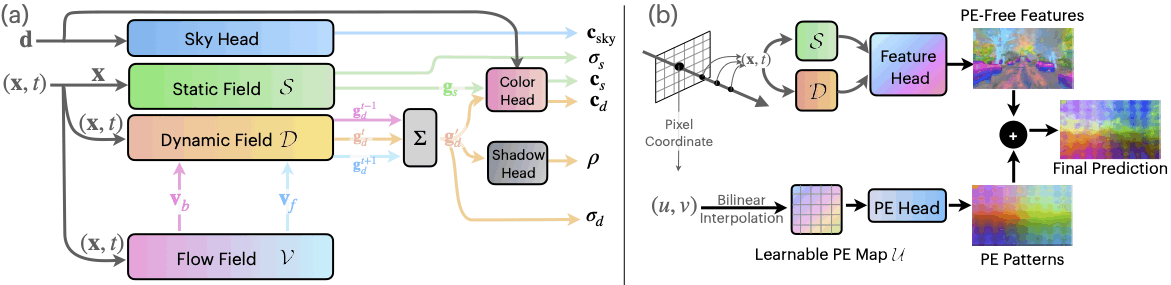

時系列を加味して移動する物体に対してFlowを用いた表現学習をしたり、DINOv2の特徴量を活用してセマンティックな表現を学習させたり、そのときにPositional embeddingsが邪魔するので打ち消すようなモデル構造にしたりと、いろいろなチップスを詰め込んでクオリティの高い自動運転用のNeRFを提案しています。自動運転におけるNeRFは、上でも紹介したOcc3Dとは違った角度から3次元世界を再構成するような手法であったり、ハイクオリティなシミュレータ環境を構築したりと、活用の余地がかなりあるので今後もしっかり追いかけていきたい領域です。
最後に紹介されていたのは、「trajdata: A Unified Interface to Multiple Human Trajectory Datasets」という研究です。上では紹介しませんでしたが、こちらの論文もNeurIPSの本誌に通っています。
自動運転データセットは数多く存在し、それぞれのフォーマットで提供されています。trajdataではそれを統一的に扱えるようにしらライブラリを提案、提供しています。周囲の物体の経路予測やマップ構築、シミュレータの構築などを、複数のデータセットで同じインターフェースで扱えるようにしたというとても素晴らしい仕事です。READMEに書かれているDataloadingのコードを見ても、理想的すぎる簡単さです。
import os
from torch.utils.data import DataLoader
from trajdata import AgentBatch, UnifiedDataset
# See below for a list of already-supported datasets and splits.
dataset = UnifiedDataset(
desired_data=["nusc_mini"],
data_dirs={ # Remember to change this to match your filesystem!
"nusc_mini": "~/datasets/nuScenes"
},
)
dataloader = DataLoader(
dataset,
batch_size=64,
shuffle=True,
collate_fn=dataset.get_collate_fn(),
num_workers=os.cpu_count(), # This can be set to 0 for single-threaded loading, if desired.
)
batch: AgentBatch
for batch in dataloader:
# Train/evaluate/etc.
pass
今回のトークで発表されたどの研究を見ても、かなりハイレベルな研究力と実装力を感じさせられました。NVIDIA Researchの研究成果はGithubで公開されているものも多いので、自分たちでも動かしながら研究していきたいと思っています。
Turingからも論文を出しました
リサーチチームができたのが2023年7月ということもあり、NeurIPSの本会議にはまったくもって間に合わなかったのですが、こちらのML4ADではTuringからも2本の論文を投稿しました。
1つは先日作成した信号機モデルの論文です。詳しくはこちらの記事を参考にしてください。
もう一つは大規模言語モデルと自動運転に関する論文です。6月にTuringで行っていた大規模言語モデルで車を動かすというデモを行っていました。ところから、素の大規模言語モデルでそもそもどのくらい自動運転っぽいことできるんだっけ?という着想にいたり、簡単なサンプルを作って評価した論文になります。
論文を出すことで、それをきっかけに世界の研究者の人と議論できるきっかけを作れるのはとてもすばらしいことだと思っています。論文という点ではかなり粗削りですが、論文は書かないと書けるようにならないよな...と思いながら(泣きながら)、これからもチャンスがあれば論文も出せるように頑張ろうと思っています。

おわりに
今回はNeurIPSで発表された自動運転系の論文の紹介と、同時開催され知多自動運転のSymposiumでの発表内容などを紹介しました。
Turingのリサーチチームでは、基本的には製品に載せるための自動運転開発を行っています。一方で、大規模言語モデルを用いた自動運転といった先進的なアプローチの可能性も探っており、その成果の一端を国際会議などでも発表できるような状態を目指しています。リサーチチームが結成されてまだ半年程度ですが、今後も面白い開発や研究は盛りだくさんなので興味がある方はぜひ声をかけてください。

(ニューオーリンズでとった写真)

Discussion