はじめに
TURINGの井ノ上です。TURINGは「We Overtake Tesla」をミッションに、完全自動運転EVの開発・製造を行っています。TURINGはEnd-to-Endな深層学習モデルでLv5完全自動運転車の開発を目指しています。現在、TURINGではカメラセンサから得た画像を用いて車体の操作や経路選択、安全性の判断を行えるAIモデルの開発を行っています。(実際の車を動かす事例はこちらの記事やこちらの記事をご覧ください。)
この記事では私達が目標としているTeslaの自動運転のAIモデルについて紹介します。
Teslaの自動運転
こちらは2022年に公開されたTeslaの自動運転をユーザーが使っている動画です。
車の中央にあるディスプレイにはAIが道路や車を認識してどういった経路を進むかを示しており、その情報をもとに自動運転している様子があります。Teslaの自動運転の能力の高さを表しており、私のお気に入りの動画です。このような自動運転システムをTeslaはいったいどのように作っているのでしょうか?その一端2021年のTesla AI Dayで発表されました。
そもそもTesla AI Dayとは?
Tesla AI DayとはTeslaが技術的に大きな躍進をした時に開催されるTesla DayのAI版です。2021年8月19日に第1回が開催され、2022年9月30日には第2回のTesla AI Dayが開催されました。今回は第1回の内容について見ていきます。
発表された内容の概略と本記事の概略
※断りのない限り、画像はこの動画から引用しています。
2021年の発表では、Teslaの自動運転システムであるAutopilot、AI学習用のコンピュータDojo、そしてTeslabotの開発状況などについて発表されました。TeslaのAIのコアとなるようなニューラルネットのアーキテクチャや経路予測の手法の紹介に加え、大規模データセットを自動で作成するAuto Labeling、シミュレーション機能についても解説されています。
その中でも、Teslaが自動運転をするためにどのようなニューラルネットワークを使って空間を認識しているか読み解いていき、さらにそれに関連する近年の論文もあわせて紹介していきます。
TeslaがTry & Errorで得た学び
認識モデルのパートは、まずはTeslaがどのようなアプローチをし、どういった課題があったかから始まります。
単一画像ではFSDが無理
フロントカメラから得た画像から車線、交通標識、信号機、車の位置や向き、奥行き、速度を予測し、FSD(Full Self Driving)につなげるというアプローチです。

この写真では、一時停止の標識や、停止線、車や信号などさまざまなものが認識されているのがわかります。このように認識はある程度行えているのですが、これだけではTeslaの目指すFSDには到底及ばないと言い切っています。
マルチカメラで空間認識をする難しさ
単一の前方カメラだけでは不十分なので、複数のカメラを扱うアプローチにシフトしていきます。
さまざまな方向から画像を取得して合成することで周囲の空間認識をする手法に取り組みましたが、いくつかの大きな課題が浮かび上がってきました。
1つめが複数カメラの情報を1つの空間に良い感じに統合するためには、パラメタチューニングに多くの労力を割かなくてはいけませんでした。
2つめとして、画像空間と出力空間を正確に合わせることがそもそも難しいということでした。出力空間は車の上から見たようなBird eye view空間(以下、BEV空間)で表現しようとしています。実空間上にある傾斜やさまざまな物体によって画像空間からBEV空間にマッピングするとどうしても位置がズレてしまいます。加えて、複数のカメラから得た画像の情報をうまくBEV空間で統合する必要があります。このは作業は想像以上に困難でした。
最後に物体検出の難しさも課題としてあがりました。複数のカメラで認識された一つの物体を一つのもとのして統合するのはかなり難しいことがわかりました。

Teslaが提案したTransformerベースのモデル
FSDを進める中で生まれたこれらの課題に対して、TeslaはTransformerの機構を活用して解決していきます。
Transformerを用いた空間情報交換の効率化
複数のカメラで取得した画像情報は実空間の傾斜などによって、BEV空間に変換するのが困難でした。そこで、複数カメラの画像空間からBEV空間に変換するためにニューラルネットを用いた手法を用いました。特に近年高い注目を集めているTransformerの機構を活用しています。自然言語処理の分野で発案されたTransformerですが、その汎用性は様々なところで示されています。Computer Visionの分野でもVisual transformer(ViT)を初めとした、これまでの畳み込みニューラルネットに変わる新たなアーキテクチャとして注目を集めています。
Transformerの中でもCross-attentionという機構を用いており、これによってマルチカメラの画像情報を統合し、効率よくBEV空間のベクトルに変換することに成功しました。詳細については、後半のパートでこれに近いアプローチの論文があったのでそちらで紹介します。

この手法を用いることで、BEV空間での認識精度が向上し、さらには物体検出の結果も改善されて複数のカメラで認識した1つの車を正しく1つの車として認識できるようになりました。
時空間情報の追加し、精度の向上を目指す
上記の状態では時間方向に関しての考慮はまだなされていません。しかし、自動運転というタスクに時系列情報が必要なのは言うまでもありません。では、どのように時系列をこのモデルに組み込むか?単に時系列の情報を渡しただけでは不十分と判断し、空間情報も組み込むアプローチを提案しています。
Transformerを用いて作成したBEV空間に埋め込まれた2次元の特徴ベクトルをそのまま活用し、空間情報も保持した時系列情報として扱っています。
このBEV型の時空間情報をどのように扱うか、3次元の畳み込みニューラルネットやTransformer、リカレントニューラルネット(RNN)などいくつかの方法が考えられます。Teslaはその中でピクセル単位でRNNを用いた手法、Spatial RNNが最も効率がよかったと説明しています。

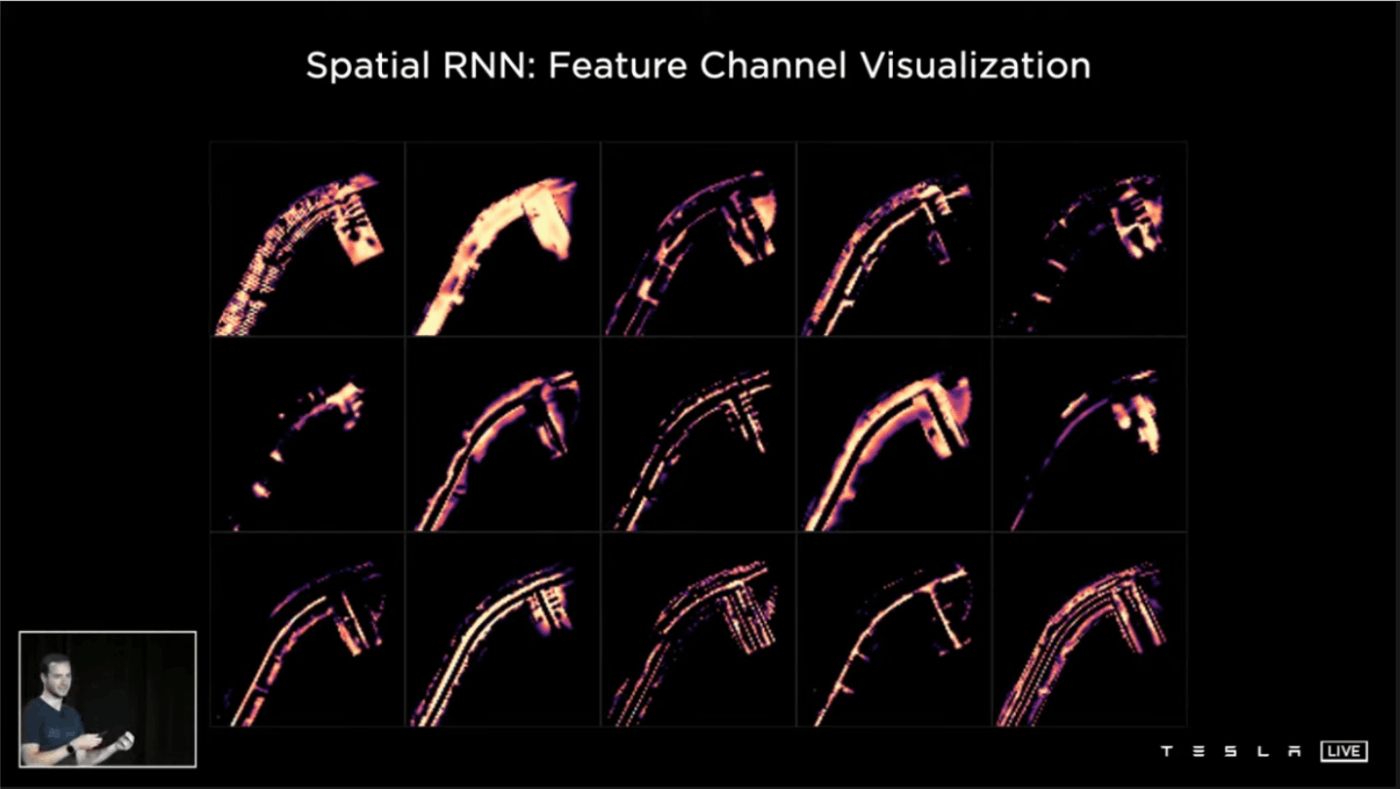
少し先にある信号や50メートル手前で道路標識を認識すること、検知した車の停止や速度なども判断することが可能になったのです。
上記の動画では車が交差点で信号待ちをしているケースを示しています。車が目の前を横切ると一時的に前方の車が遮られるのですが、Spatial RNNを用いたVideo Moduleを導入したことで、車が存在していることを記憶しているため、車を見失うことがありません。
以上のTransformerとSpatial RNNを組み込んで、さらに物体検出やBEVセグメンテーション、深度推定など複数のタスクを同時に学習させたEnd-to-endのモデルがこの発表で紹介されたTeslaの自動運転のAIモデルです。

他にも参考になった論文
Tesla AI Dayの理解を深めるにあたって参考になった論文をいくつかご紹介します。
End-to-End Object Detection with Transformers
Carion, Nicolas, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. 2020.
引用元:http://arxiv.org/abs/2005.12872.

BEVモデルの論文を見ていく前にまず最初に紹介したいのが、こちらの画像の分野においてCross-attentionを導入した超重要論文です。Object queriesという形でQueryを用意し、畳み込みニューラルネットのあとTransformer encoderにかけた特徴ベクトルとObject queryとでCross-attentionしています。Metaによって提案され、引用件数は3,000以上になりました。Teslaのモデルでも使われており、このCross-attentionがBEVのタスクでも鍵となりそうです。
Projecting Your View Attentively: Monocular Road Scene Layout Estimation via Cross-view Transformation
Yang, Weixiang, Qi Li, Wenxi Liu, Yuanlong Yu, Yuexin Ma, Shengfeng He, and Jia Pan. n.d. CVPR 2021.

画像空間からBEV空間への変換で初めてBEV空間と画像空間でのCross-attentionを明示的に使用した論文です。BEV空間の特徴量であるX'をQuery、Encoderから抽出された画像空間の特徴量XをKey、X'から今一度画像空間に戻したX''をValueとしたBEV空間特徴と画像空間特徴のCross-attention構造になっています。
NEAT: Neural Attention Fields for End-to-End Autonomous Driving
Kashyap Chitta and Aditya Prakash and Andreas Geiger
Book Title:International Conference on Computer Vision. ICCV 2021
引用元:https://avg.is.mpg.de/publications/chitta2021iccv

画像空間からBEV空間への変換でTransformerを使っているわけではないですが、MLPを使ってAttentionを計算しています。Neural Attention Field (NEAT)moduleを2回繰り返している点も特徴的です。1回目がBEV空間への射影で、2周目でCross-attention的な役割を果たしているのではないかと私は考えています。
Cross-view Transformers for real-time Map-view Semantic Segmentation
Brady Zhou,Philipp Krähenbühl. CVPR 2022
引用元:http://www.philkr.net/media/zhou2022crossview.pdf

私が個人的にTeslaの開発にかなり近いと感じている論文です。BEV空間のQueryを用意して画像空間の特徴ベクトルから生成したKey, ValueとCross-attentionしています。こちらの図が非常にイメージしやすいと思います。QueryがBEV情報を持っているベクトルで、畳み込みニューラルネットから抽出した複数のscaleの画像空間の特徴ベクトルを順々にCross-attentionしていくことで、BEV空間のQueryを更新していってる点が特徴です。とてもシンプルな構造ながら精度も良さそうだと感じています。
Tesla AI Dayでは、Transformerの構造を用いることで空間の情報の変換が効率良く行われることがわかったと説明されています。TeslaのモデルはBEV空間のQueryベクトルをあらかじめ作って、マルチカメラで取得した特徴マップとCross-attentionしてるので、この論文と言っていることはかなり近いです。下記のような結果を得られており、この変換はかなり良い結果につながっていると思っています。

BEVSegFormer: Bird's Eye View Semantic Segmentation From Arbitrary Camera Rigs
Peng, Lang, Zhirong Chen, Zhangjie Fu, Pengpeng Liang, and Erkang Cheng. arXive 2022.
引用元: http://arxiv.org/abs/2203.04050

BEVのQueryを用意して画像空間の特徴量とCross-attentionしています。この論文の特徴は、画像空間の全特徴量とCross-attentionをすると非常に計算が多くなるので、Deformable Attentionを使って関係ありそうなところを効率よくCross-attentionに加えている点です。下記の通り、こちらもBEVのセグメンテーションがかなりうまくいっているように思います。

BEVFormer: Learning Bird's-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chonghao Sima, Tong Lu, Qiao Yu, Jifeng Dai. ECCV 2022
引用元:https://arxiv.org/abs/2203.17270

BEVSegFormerに時系列を考慮するためにTemporal Self-Attentionを追加しています。Temporal Self-AttentionもDeformable Attentionを利用しており、TeslaのSpatial RNNに近いです。CVPR 2022のWaymoのWorkshopで優勝しているので実際にちゃんと精度が出ています。下図のようにBEV Segmentationに加えて車の検出や白線の検出もかなり良くなっている印象です。

Simple-BEV: What Really Matters for Multi-Sensor BEV Perception?
Harley, Adam W., Zhaoyuan Fang, Jie Li, Rares Ambrus, and Katerina Fragkiadaki. arXive 2022
引用元:https://arxiv.org/abs/2206.07959

この論文では、画像から畳み込みニューラルネットで得られた特徴量をBEV空間に直接投写して、さらにもう一つ畳み込みニューラルネットを用いてBEV特徴を使ったタスクを解いています。Simple Baselineという名前をつけてる点も個人的に好きです。畳み込みニューラルネットでもまだまだいけるんだぞという意志が伝わってきますし、Waymoのコンペで優勝したBEVFormerよりも精度が良いのでまだまだ研究の余地があると感じます。
このようにCross-attentionだけではなく畳み込みニューラルネットを使用した手法でもすばらしい精度が出たりとまだまだ発展途上の領域ではあります。今後はアプリケーションを想定した実車で動作できる速度がだせるかや十分軽量かどうかも重要になってくると考えています。
まとめ
2021のTesla AI Dayでの発表では、下記の2点がポイントだと感じました。
- BEVのセグメンテーションタスクでもTransformerの機構が有効であること
- マルチカメラをうまくBEV空間に持っていけば精度が高くなりそうだということ
一方で、実際の車で推論することまで考慮して、精度を出せてるのTeslaだけではないかと感じました。さまざまな研究や実験をしたであろうTeslaがここまでシンプルなモデルにまとめあげている点もさすがだと感じました。
2022年のTesla AI Dayでは、BEVから3次元に世界を拡張したこのモデルの進化系も紹介されていました。2022年版の記事もTURINGのテックブログとして近日公開予定ですので楽しみにしていてください!
最後に
お決まりですがTURINGの採用についても紹介させてください。TURINGでは完全自動運転システムの開発と、そのシステムに適した車両の開発をゼロから行なっています。シニアなエンジニアや日産出身のエンジニアなども集まっており、日に日に面白い方々がジョインしている状況です。
もしもTURINGの開発の進み具合や課題感が気になるという方や、Tesla AI Day・完全自動運転について語り合いたい!という方いればぜひカジュアルに話しましょう!採用HPでも私のMeetyからでもご連絡お待ちしています!

Discussion
ちょうどテスラの元テックリード(Andrej Karpathy)が有名YouTuberのLexと対談
していたので面白かったです。
Andrej自身もYouTubeを始めており、こうした情報発信は助かりますね。