はじめに
チューリングの横井です。チューリングでは視覚と言語を統合的に理解できるAIを自動運転に応用するため、Vision Language モデル(VLM)「Heron」の開発に取り組んでいます。このたび、経済産業省およびNEDOが推進する日本の生成AIの開発力強化に向けたプロジェクト「GENIAC」第2期の支援のもと開発したVLM「Heron-NVILA」15B, 2B, 1B, 33Bを公開しました。
この記事では開発したHeron-NVILAのアーキテクチャ、学習内容、ベンチマーク評価を紹介します。
モデルアーキテクチャ
Heron-NVILAのアーキテクチャは名前の通りNVIDIAが提案したVLMであるNVILAを用いています。
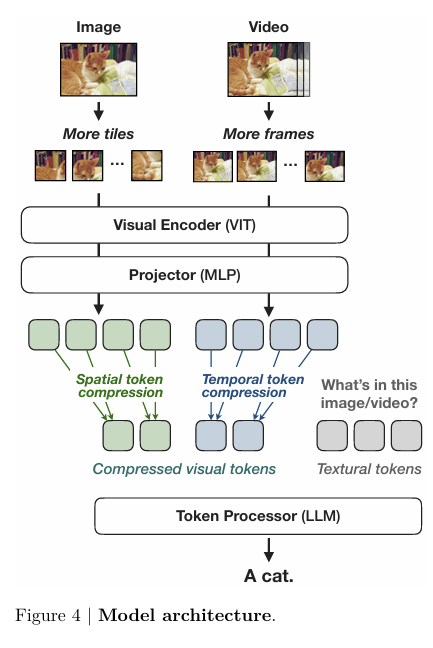
NVILAは 「Vision Encoder → Projector(2 層 MLP)→ LLM」 という 3 段構成を取りつつ
- Scale ─ 画像を入力解像度のタイルに分割して、細部まで取り込む
- Compress ─ 空間 / 時間方向でトークンを絞り込む
という Scale-then-Compress 戦略を取り入れることで、性能を維持しつつ計算コストの削減を実現しています。
上記の論文の図では「Projector → Compress → LLM」の順に見えますが、公式リポジトリでは圧縮処理がProjectorブロックの冒頭に組み込まれており、データは「Compress → Projector → LLM」の順で流れます。
実際のデータの流れは以下のイメージです。
入力画像
▼
Scale
└ 画像のアスペクト比を極力保つようにリサイズし、画像を 448x448 などVision Encoderの入力解像度のタイルに分割
・元のアスペクト比に近いタイル構成を選び、その構成が作れるサイズに画像をリサイズするため、完全に元のアスペクト比が維持されるわけではない
・Liteでは画像全体を入力解像度にリサイズしたものも1タイルとして使う
▼
Vision Encoder
└ SigLIP-ViT(patch 14×14, hidden 1152)などで各タイルをエンコード
・448x448の解像度でパッチサイズが14x14なら、(448/14) x (448/14) = 32 x 32 = 1024 個のパッチトークンが出力されます
▼
Compress(Spatial-to-Channel 圧縮)
└ 2 × 2 圧縮 / 3 × 3 圧縮
2 × 2 圧縮の場合:
・隣接する 2 × 2 = 4 のトークンを連結 → 1 トークン化
・トークン数:32 x 32 / 4 → 256
・各トークンの埋め込み次元:1152 × 4 = 4608
・32×32など1タイルのトークンが 2 や 3 で割り切れない場合はゼロパディングで割り切れるようにする
▼
Projector
└ 2 層 MLP で LLM へ射影
・出力形状は各タイルごとに [256 (圧縮されたトークン数), 4096 (LLMの隠れ層次元数)]のようになる
▼
LLM
└ 視覚トークンとテキストトークンを連結して自己回帰でテキストを生成
・入力は「<1タイル分の視覚トークン>\n<1タイル分の視覚トークン>\n...<テキストトークン>」のようなイメージ
論文では、元の画像サイズに加えて (448, 448)、(896, 896)、(1344, 1344) にリサイズした画像でもScale処理を行うマルチスケール対応の Dynamic-S2 が紹介されていますが、Heron-NVILAではこのマルチスケール化を行わないLite方式を採用しています。論文によると、Liteの方がわずかな性能低下はありますが、マルチスケール対応は学習・推論時間が増加するため実用性を重視してLiteを選択しました。そのため、モデル名はHeron-NVILA-LiteとLiteを明記しています。なお、NVILA-Liteの詳細な説明は2025/4時点でのarXiv論文には記載されておらず、公式リポジトリのissue#167で簡単に触れられているのみです。
Heron-NVILAのVision EncoderとLLMは公式リポジトリで使用している以下のモデルを採用しました:
- Vision Encoder:paligemma-siglip-so400m-patch14-448
- LLM:Qwen2.5シリーズ
LLMについては、日本語特化のLlama-3.1-Swallow-8Bを用いて少ないステップ数での学習を試しましたが、Heron Benchにおける評価スコアがQwen2.5-7B-Instructを用いた方が高かったためQwen2.5を採用しました。
公式のNVILA-Liteの重みは公開されていますが、ライセンスがCreative Commons Attribution-NonCommercial 4.0で商用利用が許可されていません。そのため、公式のNVILA-Liteの重みは使用せず、上記のVision EncoderとLLMから学習を行いました。
Projectorの2層MLPについてはランダムな初期重みを用いています。
学習時間を短縮するため、Heron-NVILA-Lite-15Bでは 3×3 圧縮を使用し、Heron-NVILA-Lite-1BおよびHeron-NVILA-Lite-2Bでは 2×2 圧縮を使用しました。3×3 圧縮は視覚トークン数を1/9に削減できるため学習・推論の高速化やメモリ使用量の削減に有効ですが、大幅なトークン数の削減によってProjectorの学習を難しくなり、2×2 圧縮に比べて性能低下することが論文に記載されています。(LLMの計算コストの一つは、トークン間の関連性を計算するSelf-Attention。Self-AttentionはQueryとKeyの内積をトークン数Nの全組み合わせについて計算するため、トークン数の2乗に比例して計算量が増加する。このため、LLMの入力トークン数が増えるほど学習・推論時間が増加します。また、Self-AttentionのAttention MatrixのサイズはN × Nであるため、必要なVRAMも同じくトークン数の2乗に比例して増加します。)
学習
ABCI 生成AIハッカソンで日本語VLMを作成しましたの記事と同じように、オープンソースの日本語・英語データセットを用いて継続事前学習を行いました。NVILAの論文では5ステージの学習(学習データや学習率を段階的に変更し、計5回の学習を実施)を採用していますが、5ステージ学習に対応する日本語データの確保が困難であったため、NVILAの前身であるVILAの3ステージ学習を採用しました。
以下の表が各学習ステージの概要です。
| 学習ステージ | 役割 | 学習対象 | 学習データ | 学習データ件数 |
|---|---|---|---|---|
| Stage 1 | Alignment | Projector のみ学習 | Japanese image text pairs, LLaVA-Pretrain | 1.1M |
| Stage 2 | Pretraining | Projector と LLM のみ学習 | Filtered MOMIJI (CC-MAIN-2024-46, CC-MAIN-2024-51, CC-MAIN-2025-05) | 13M |
| Japanese image text pairs (subset), Japanese interleaved data (subset), mmc4-core (subset), coyo-700m (subset), wikipedia_ja, llava_pretrain_ja, stair_captions | 20M | |||
| Stage 3 | Supervised Fine-tuning (SFT) | Vision Encoder, Projector, LLM すべて学習 | llava-instruct-v1_5-en-subset-358k, llava-instruct-ja, japanese-photos-conv, ja-vg-vqa, synthdog-ja (subset), ai2d, synthdog-en, sherlock | 1.1M |
データ
データの工夫としては、Stage2のPretrainingにCommon Crawlの日本語データであるMOMIJIを追加した点です。 このデータはGENIACの成果物です。
今回の学習では以下の最小限の前処理を施しています。
- テキスト長フィルタ:本文が 5,000 文字を超えるサンプルを除外
- 画像サイズフィルタ:縦・横いずれかが 10 px 未満、または 16,000 px を超える画像を持つデータを除外
- 画像挿入位置を変更:CLIP ViT-H/14で画像とテキストの類似度を計算し、類似度が最も高いテキストの直前に画像を配置
前処理には多くの改善の余地があります。社内で検証した範囲でも、性能向上の可能性が確認できました。
学習データの詳細は以下です。
Stage1の学習データ
Data Type: 画像-短いキャプション データ
-
Japanese image text pairs (558k)
- 画像データ: CommonCrawl from 2020-2022
- テキスト: alt-text ベース
-
LLaVA-Pretrain (595K)
- 画像データ: CC3M
- テキスト: BLIPによる合成テキスト
Stage2の学習データ
Data Type: 画像-短いキャプション データ, 画像-長いキャプションデータ, 画像-テキストインターリーブデータ
-
MOMIJI (13M subset)
- 画像データ: CommonCrawl from 2024/02 - 2025/01
- テキスト: Web文書 (image-textが交互に配置) ベース
-
Japanese image text pairs (6M subset)
- 画像データ: CommonCrawl from 2020-2022 (COYOのやり方を踏襲)
- テキスト: alt-text ベース
-
Japanese interleaved data (2M subset)
- 画像データ: CommonCrawl from 2020-2022 (MMC4 のやり方を踏襲)
- テキスト: Web文書 (image-textが交互に配置)ベース
- 画像の位置は、CLIPによる類似度で決定する
-
coyo-700m (6M subset)
- 画像データ: CommonCrawl from 2020/10-2021/08
- テキスト: alt-text ベース
-
mmc4-core (4M subset)
- 画像データ: CommonCrawl from 2018-2019
- テキスト: Web文書 (image-textが交互に配置)ベース
- 画像の位置は、CLIPによる類似度で決定する
-
wikipedia_ja (1.6M)
- 画像データ: Wikipedia
- テキスト: 画像とその周辺にあるテキストベース
-
llava_pretrain_ja (595K)
- 画像データ: CC3M
- テキスト: BLIPによる合成テキストをDeepLで日本語訳したもの
-
stair_captions (414k)
- 画像データ: COCO2017
- テキスト: COCOの画像に対して人手で説明文を付与したもの
Stage3の学習データ
Data Type: 画像対話データ, 画像-長いキャプションデータ, 一般的なVQA(自由記述解答), 一般的なVQA(選択肢解答), GQA(位置関係), OCR(画像文字読み取り), BBox推定
-
llava-instruct-v1_5-en-subset-358k (358k subset)
- 画像データ:
Dataset Images 画像抽出元 LLaVA 158K COCO2017 VQAv2 53K COCO2014 GQA 46K COCO2014, Flickr OCRVQA 80K Original TextVQA 22K Open Images v3 - テキスト:
- type1: conversation (LLaVA)
- type2: detailed description (LLaVA)
- type3: complex reasoning (LLaVA)
- type4: VQA (VQAv2; 一般的なQA)
- type5: GQA (GQA; 位置関係)
- type6: OCR (OCRVQA, TextVQA; OCR)
- 画像データ:
-
llava-instruct-ja (156k)
- 画像データ:
Dataset Images 画像抽出元 LLaVA 158K COCO2017 - テキスト:
- type1: conversation (LLaVA)
- type2: detailed description (LLaVA)
- type3: complex reasoning (LLaVA)
- 画像データ:
-
japanese-photos-conv (11.8k)
- 画像データ: 日本画像 (https://huggingface.co/datasets/ThePioneer/japanese-photos)
- テキスト: GPT-4o を使用した対話データ
-
ja-vg-vqa (98.7k)
- 画像データ: Visual Genome Dataset
- テキスト: GPT-4o を使用した対話データ
- Japanese Visual Genome VQA dataset の QA データを複数ターンの対話データにしている
- ただし、評価ベンチ JA-VG-VQA-500 に含まれているデータは除く
-
synthdog-ja (66.3k)
- 画像データ: Original
- テキスト: 翻訳テキストデータ
-
synthdog-en (65.5k)
- 画像データ: Original
- テキスト: 翻訳テキストデータ
-
AI2D (3.09k)
- 画像データ: Original
- テキスト: 選択式 QA データ
-
sherlock (317k)
- 画像データ: Vizual Genome Dataset + Original Dataset
- テキスト: 対話データ (bbox推定, brief VQA)
Heron-NVILAの学習データは商用利用可能とみなせるデータだけを使用しています。ただし、SFTでGPT-4oの出力を学習データに使用しているため、Heron-NVILAの重みはOpenAIの利用規約に従う必要があります。
コード
Heron-NVILAの学習コードは公式リポジトリを活用しました。MOMIJIなどの独自データを使うためにデータセットクラスを追加、連続学習時間制限を削除、チャットテンプレートのシステムプロンプトを日本語にするなど軽微な変更は入れていますが、lossなど学習の主要部分は公式実装を流用しました。
追加したデータセットクラスのサンプルコード
# VILA/llava/data/dataset.py
class LazyMOMIJIDataset(Dataset):
def __init__(
self,
data_path: str,
image_folder: str,
tokenizer: transformers.PreTrainedTokenizer,
data_args: DataArguments,
training_args: TrainingArguments,
image_following_text_only: bool = False,
text_only: bool = False,
):
super().__init__()
pkl_files = sorted(glob.glob(f"{data_path}/**/*.pkl", recursive=True)) + sorted(
glob.glob(f"{data_path}/*.pkl")
)
count_files = sorted(glob.glob(f"{data_path}/**/*.count", recursive=True)) + sorted(
glob.glob(f"{data_path}/*.count")
)
pkl_files = list(dict.fromkeys(pkl_files))
count_files = list(dict.fromkeys(count_files))
if data_args.mm4c_n_shards_start != -1:
s, e = data_args.mm4c_n_shards_start, data_args.mm4c_n_shards_end
count_info_list = count_files[s:e]
else:
count_info_list = count_files
n_samples = [
int(open(os.path.join(data_path, f)).read().strip()) for f in count_info_list
]
print("total MOMIJI samples", sum(n_samples))
pgm = get_pg_manager()
seq_parallel = training_args.seq_parallel_size if pgm else 1
rank = training_args.process_index // seq_parallel
world_size = training_args.world_size // seq_parallel
shared_size = len(count_info_list) // world_size
gpu_samples = [sum(n_samples[i * shared_size : (i + 1) * shared_size]) for i in range(world_size)]
self.n_samples = min(gpu_samples) * world_size
self.idx_offset = rank * min(gpu_samples)
shard_start, shard_end = rank * shared_size, (rank + 1) * shared_size
print(f"* loading data from shard {shard_start}-{shard_end}")
shard_names = [
d.replace(".count", ".pkl") for d in count_info_list[shard_start:shard_end]
]
self.data_list, self.data_path_list = [], []
for shard_name in shard_names:
with open(os.path.join(data_path, shard_name), "rb") as f:
part = pickle.load(f)
self.data_list.extend(part)
self.data_path_list.extend([os.path.join(data_path, shard_name)] * len(part))
print(f"* loaded totally {len(self.data_list)} samples")
self.tokenizer = tokenizer
self.data_args = data_args
self.image_folder = image_folder
self.image_following_text_only = image_following_text_only
self.text_only = text_only
def __len__(self):
return self.n_samples
@property
def modality_lengths(self):
lengths = []
for info in self.data_list:
num_images = min(6, len(info["image_info"]))
sentences = [info["text_list"][x["matched_text_index"]] for x in info["image_info"][:num_images]]
cur_len = num_images * self.num_image_tokens // 2 + sum(len(s) for s in sentences)
lengths.append(cur_len)
return lengths
def __getitem__(self, i) -> Dict[str, torch.Tensor]:
info = self.data_list[i - self.idx_offset]
sentences = [s.replace("<image>", "<IMAGE>") for s in info["text_list"]]
sim_matrix = info["similarity_matrix"]
images, sentence_ixs = [], []
if not self.text_only:
for sample_image, _ in zip(info["image_info"], sim_matrix):
rawbytes = base64.b64decode(sample_image["image_base64"])
image = Image.open(io.BytesIO(rawbytes)).convert("RGB")
images.append(image)
sentence_ixs.append(sample_image["matched_text_index"])
max_num_images = 6
if len(images) > max_num_images:
images, sentence_ixs = images[:max_num_images], sentence_ixs[:max_num_images]
images = [images[idx] for idx in np.argsort(sentence_ixs)]
for ix in sentence_ixs:
sentences[ix] = f"<image>\n{sentences[ix]}"
if self.image_following_text_only:
text = self.tokenizer.pad_token.join(sentences)
else:
text = " ".join(sentences)
text = text.replace("<image> ", "<image>").replace(" <image>", "<image>")
text = f"{text}{self.tokenizer.eos_token}"
if images:
if self.data_args.image_aspect_ratio == "dynamic_s2":
images, block_sizes = dynamic_s2_process_images_and_prompt(
images, text, self.data_args, self.image_folder
)
elif self.data_args.image_aspect_ratio == "dynamic":
images, text = dynamic_process_images_and_prompt(
images, text, self.data_args, self.image_folder, max_tiles=6
)
else:
images = torch.stack(
[process_image(img, self.data_args, self.image_folder) for img in images]
)
else:
images = None
input_ids = tokenizer_image_token(text, self.tokenizer, return_tensors="pt")
image_token_id = self.tokenizer.media_token_ids["image"]
if input_ids[-1] == image_token_id:
last_non_img = torch.where(input_ids != image_token_id)[0][-1] + 1
input_ids = input_ids[:last_non_img]
n_im_patch = (input_ids == image_token_id).sum().item()
if self.data_args.image_aspect_ratio != "dynamic_s2":
images = images[:n_im_patch]
assert len(images) == n_im_patch
if self.tokenizer.bos_token_id is not None and input_ids[0] != self.tokenizer.bos_token_id:
input_ids = torch.cat([torch.tensor([self.tokenizer.bos_token_id]), input_ids])
targets = input_ids.clone()
if self.image_following_text_only:
label_idx = 0
while label_idx < targets.shape[-1] and targets[label_idx] != image_token_id:
targets[label_idx] = IGNORE_INDEX
label_idx += 1
pad_token = self.tokenizer.pad_token_id
for pad_token_idx in torch.where(targets == pad_token)[0]:
token_idx = pad_token_idx + 1
while token_idx < targets.shape[-1] and targets[token_idx] != image_token_id:
targets[token_idx] = IGNORE_INDEX
token_idx += 1
targets[targets == pad_token] = IGNORE_INDEX
data_dict = dict(input_ids=input_ids, labels=targets, image=images)
if self.data_args.image_aspect_ratio == "dynamic_s2":
data_dict["block_sizes"] = block_sizes
return data_dict
学習のメインコード
# VILA/llava/train/train.py
import copy
import logging
import math
import os
import warnings
from dataclasses import dataclass, field
from typing import Any, Dict, List, Optional, Sequence
import torch
import transformers
from torch.utils.data import Dataset
from transformers import AutoConfig, AutoTokenizer, HfArgumentParser, LlamaForCausalLM, set_seed
from transformers.modeling_utils import unwrap_model
import llava.data.dataset as dataset
import llava.data.datasets_mixture as datasets_mixture
from llava import conversation as conversation_lib
from llava.constants import IGNORE_INDEX
from llava.data import make_supervised_data_module
from llava.mm_utils import process_image
from llava.model import LlavaLlamaConfig, LlavaLlamaModel
from llava.model.language_model.qllava_qllama import QLlavaLlamaModel, quantize_args_to_model_class
from llava.train.args import DataArguments, ModelArguments, TrainingArguments
from llava.train.callbacks.autoresume_callback import AutoResumeCallback
from llava.train.llava_trainer import LLaVATrainer, VILADPOTrainer
from llava.train.sequence_parallel import set_pg_manager
from llava.train.slurm_utils import TimeoutTerminateCallback
from llava.train.utils import (
get_checkpoint_path,
mprint,
prepare_config_for_training,
unit_test_rope_scaling,
vision_resolution_elevation,
)
from llava.trl.trainer.utils import DPODataCollatorWithPadding
local_rank = None
if "WANDB_PROJECT" not in os.environ:
os.environ["WANDB_PROJECT"] = "VILA"
def get_nb_trainable_parameters(model) -> tuple[int, int]:
r"""
Returns the number of trainable parameters and the number of all parameters in the model.
"""
trainable_params = 0
all_param = 0
for _, param in model.named_parameters():
num_params = param.numel()
if num_params == 0 and hasattr(param, "ds_numel"):
num_params = param.ds_numel
if param.__class__.__name__ == "Params4bit":
if hasattr(param, "element_size"):
num_bytes = param.element_size()
elif not hasattr(param, "quant_storage"):
num_bytes = 1
else:
num_bytes = param.quant_storage.itemsize
num_params = num_params * 2 * num_bytes
all_param += num_params
if param.requires_grad:
trainable_params += num_params
return trainable_params, all_param
def maybe_zero_3(param, ignore_status=False, name=None):
from deepspeed import zero
from deepspeed.runtime.zero.partition_parameters import ZeroParamStatus
if hasattr(param, "ds_id"):
if param.ds_status == ZeroParamStatus.NOT_AVAILABLE:
if not ignore_status:
logging.warning(f"{name}: param.ds_status != ZeroParamStatus.NOT_AVAILABLE: {param.ds_status}")
with zero.GatheredParameters([param]):
param = param.data.detach().cpu().clone()
else:
param = param.detach().cpu().clone()
return param
def get_peft_state_maybe_zero_3(named_params, bias):
if bias == "none":
to_return = {k: t for k, t in named_params if "lora_" in k}
elif bias == "all":
to_return = {k: t for k, t in named_params if "lora_" in k or "bias" in k}
elif bias == "lora_only":
to_return = {}
maybe_lora_bias = {}
lora_bias_names = set()
for k, t in named_params:
if "lora_" in k:
to_return[k] = t
bias_name = k.split("lora_")[0] + "bias"
lora_bias_names.add(bias_name)
elif "bias" in k:
maybe_lora_bias[k] = t
for k, t in maybe_lora_bias:
if bias_name in lora_bias_names:
to_return[bias_name] = t
else:
raise NotImplementedError
to_return = {k: maybe_zero_3(v, ignore_status=True) for k, v in to_return.items()}
return to_return
def get_peft_state_non_lora_maybe_zero_3(named_params, require_grad_only=True):
to_return = {k: t for k, t in named_params if "lora_" not in k}
if require_grad_only:
to_return = {k: t for k, t in to_return.items() if t.requires_grad}
to_return = {k: maybe_zero_3(v, ignore_status=True).cpu() for k, v in to_return.items()}
return to_return
def get_mm_adapter_state_maybe_zero_3(named_params, keys_to_match):
to_return = {k: t for k, t in named_params if any(key_match in k for key_match in keys_to_match)}
to_return = {k: maybe_zero_3(v, ignore_status=True).cpu() for k, v in to_return.items()}
return to_return
def find_all_linear_names(model, lora_llm, lora_vt):
cls = torch.nn.Linear
lora_module_names = set()
multimodal_keywords = ["mm_projector", "vision_resampler"]
assert lora_llm or lora_vt, "Not applying LoRA to any of the modules..."
if not lora_llm:
multimodal_keywords += ["llm"]
if not lora_vt:
multimodal_keywords += ["vision_tower"]
for name, module in model.named_modules():
if any(mm_keyword in name for mm_keyword in multimodal_keywords):
continue
if isinstance(module, cls):
if not "lm_head" in name:
lora_module_names.add(name)
return list(lora_module_names)
def safe_save_model_for_hf_trainer(trainer: transformers.Trainer, output_dir: str):
"""Collects the state dict and dump to disk."""
if trainer.deepspeed:
torch.cuda.synchronize()
trainer.save_model(output_dir, _internal_call=True)
return
state_dict = trainer.model.state_dict()
if trainer.args.should_save:
cpu_state_dict = {key: value.cpu() for key, value in state_dict.items()}
del state_dict
trainer._save(output_dir, state_dict=cpu_state_dict) # noqa
def smart_tokenizer_and_embedding_resize(
special_tokens_dict: Dict,
tokenizer: transformers.PreTrainedTokenizer,
model: transformers.PreTrainedModel,
):
"""Resize tokenizer and embedding.
Note: This is the unoptimized version that may make your embedding size not be divisible by 64.
"""
num_new_tokens = tokenizer.add_special_tokens(special_tokens_dict)
model.resize_token_embeddings(len(tokenizer))
if num_new_tokens > 0:
input_embeddings = model.get_input_embeddings().weight.data
output_embeddings = model.get_output_embeddings().weight.data
input_embeddings_avg = input_embeddings[:-num_new_tokens].mean(dim=0, keepdim=True)
output_embeddings_avg = output_embeddings[:-num_new_tokens].mean(dim=0, keepdim=True)
input_embeddings[-num_new_tokens:] = input_embeddings_avg
output_embeddings[-num_new_tokens:] = output_embeddings_avg
def make_conv(prompt, answer):
return [
{
"from": "human",
"value": prompt,
},
{
"from": "gpt",
"value": answer,
},
]
@dataclass
class DPODataCollator(DPODataCollatorWithPadding):
tokenizer: Any = None
def collate(self, batch):
padded_batch = {}
for k in batch[0].keys():
if k.endswith("_input_ids") or k.endswith("_attention_mask") or k.endswith("_labels"):
to_pad = [torch.LongTensor(ex[k]) for ex in batch]
if k.endswith("_input_ids"):
padding_value = self.pad_token_id
elif k.endswith("_labels"):
padding_value = self.label_pad_token_id
else:
continue
padded_batch[k] = torch.nn.utils.rnn.pad_sequence(to_pad, batch_first=True, padding_value=padding_value)
else:
padded_batch[k] = [ex[k] for ex in batch]
for k in ["chosen_input_ids", "rejected_input_ids"]:
attn_k = k.replace("input_ids", "attention_mask")
padded_batch[attn_k] = padded_batch[k].ne(self.pad_token_id)
return padded_batch
def tokenize_batch_element(self, prompt: str, chosen: str, rejected: str) -> Dict:
"""Tokenize a single batch element.
At this stage, we don't convert to PyTorch tensors yet; we just handle the truncation
in case the prompt + chosen or prompt + rejected responses is/are too long. First
we truncate the prompt; if we're still too long, we truncate the chosen/rejected.
We also create the labels for the chosen/rejected responses, which are of length equal to
the sum of the length of the prompt and the chosen/rejected response, with
label_pad_token_id for the prompt tokens.
"""
batch = {}
chosen_sources = make_conv(prompt, chosen)
rejected_sources = make_conv(prompt, rejected)
chosen_data_dict = dataset.preprocess([chosen_sources], self.tokenizer, has_image=True)
rejected_data_dict = dataset.preprocess([rejected_sources], self.tokenizer, has_image=True)
chosen_data_dict = {k: v[0] for k, v in chosen_data_dict.items()}
rejected_data_dict = {k: v[0] for k, v in rejected_data_dict.items()}
for k, toks in {
"chosen": chosen_data_dict,
"rejected": rejected_data_dict,
}.items():
for type_key, tokens in toks.items():
if type_key == "token_type_ids":
continue
batch[f"{k}_{type_key}"] = tokens
return batch
def __call__(self, features: List[Dict[str, Any]]) -> Dict[str, Any]:
tokenized_batch = []
Xs, keys = [], []
for feature in features:
prompt = feature["prompt"]
chosen = feature["chosen"]
rejected = feature["rejected"]
batch_element = self.tokenize_batch_element(prompt, chosen, rejected)
batch_element["images"] = feature["images"]
tokenized_batch.append(batch_element)
padded_batch = self.collate(tokenized_batch)
return padded_batch
import json
def load_jsonl(save_path):
with open(save_path) as f:
data = [json.loads(line) for line in f.readlines()]
return data
def load_json(path):
with open(path) as f:
data = json.load(f)
return data
def load_data(data_path):
if "jsonl" in data_path:
data_list = load_jsonl(data_path)
else:
data_list = load_json(data_path)
return data_list
class DPODataset(Dataset):
"""Dataset for supervised fine-tuning."""
def __init__(self, data_mixture: str, tokenizer: transformers.PreTrainedTokenizer, data_args: DataArguments):
super(Dataset, self).__init__()
data_path = datasets_mixture.DATASETS_LEGACY[data_mixture].data_path
list_data_dict = load_data(data_path)
print("Formatting inputs...Skip in lazy mode")
self.tokenizer = tokenizer
self.list_data_dict = list_data_dict
self.data_args = data_args
self.image_folder = datasets_mixture.DATASETS_LEGACY[data_mixture].image_path
def __len__(self):
return len(self.list_data_dict)
@property
def lengths(self):
length_list = []
for sample in self.list_data_dict:
img_tokens = 128 if "image" in sample else 0
length_list.append(sum(len(conv["value"].split()) for conv in sample["conversations"]) + img_tokens)
return length_list
def __getitem__(self, i) -> Dict[str, torch.Tensor]:
"""
{
'prompt': 'Is there a snowman wearing a green scarf and hat in the background?',
'chosen': 'No, there is no snowman wearing a green scarf and hat in the background of the image. The image features a person ...',
'rejected': 'No, there is no snowman in the background.',
'image_path': '/mnt/bn/liangkeg/data/ruohongz/dpo_data/dpo_images/LRVInstruction-000000009569.jpg',
'image_name': 'LRVInstruction-000000009569.jpg'
}
"""
data_dict = copy.deepcopy(self.list_data_dict[i]) # inplace modification following
video_file = data_dict["video"] + ".mp4"
video_folder = self.image_folder
video_path = os.path.join(video_folder, video_file)
num_video_frames = self.data_args.num_video_frames if hasattr(self.data_args, "num_video_frames") else 8
loader_fps = self.data_args.fps if hasattr(self.data_args, "fps") else 0.0
fps = None
frame_count = None
images, frames_loaded = dataset.LazySupervisedDataset._load_video(
video_path, num_video_frames, loader_fps, self.data_args, fps=fps, frame_count=frame_count
)
image_tensor = torch.stack([process_image(image, self.data_args, None) for image in images])
image_tensor = torch.stack([process_image(image, self.data_args, None) for image in images])
data_dict["images"] = image_tensor
prompt = data_dict["prompt"]
prompt = prompt.replace("<video>", "").strip()
prompt = "<image>\n" * frames_loaded + prompt
data_dict["prompt"] = prompt
return data_dict
def train():
global local_rank
parser = HfArgumentParser((ModelArguments, DataArguments, TrainingArguments))
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
if os.getenv("RUN_NAME") is not None:
training_args.run_name = os.getenv("RUN_NAME")
else:
training_args.run_name = training_args.output_dir.split("/")[-1]
local_rank = training_args.local_rank
compute_dtype = torch.float16 if training_args.fp16 else (torch.bfloat16 if training_args.bf16 else torch.float32)
bnb_model_from_pretrained_args = {}
if training_args.bits in [4, 8]:
from transformers import BitsAndBytesConfig
bnb_model_from_pretrained_args.update(
dict(
device_map={"": training_args.device},
quantization_config=BitsAndBytesConfig(
load_in_4bit=training_args.bits == 4,
load_in_8bit=training_args.bits == 8,
llm_int8_skip_modules=["lm_head"],
llm_int8_threshold=6.0,
llm_int8_has_fp16_weight=False,
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=training_args.double_quant,
bnb_4bit_quant_type=training_args.quant_type, # {'fp4', 'nf4'}
),
)
)
set_seed(training_args.seed)
sp_degree = training_args.seq_parallel_size
ring_degree = training_args.seq_parallel_ring_size
if sp_degree > 1:
set_pg_manager(sp_degree, ring_degree, ring_type=training_args.seq_parallel_ring_type)
print(f"Sequence parallelism is enabled, SP = {sp_degree}")
resume_path, continue_training = get_checkpoint_path(training_args.output_dir)
if not continue_training:
print(f"Models has been ready under {training_args.output_dir}. Skipp training")
exit(0)
if resume_path:
resume_from_checkpoint = True
if training_args.lora_enable:
model_cls = LlavaLlamaModel
config = LlavaLlamaConfig.from_pretrained(model_args.model_name_or_path, resume=resume_from_checkpoint)
config.resume_path = model_args.model_name_or_path
else:
config = AutoConfig.from_pretrained(resume_path, trust_remote_code=True)
config.resume_path = resume_path
model_cls = eval(config.architectures[0])
else:
resume_from_checkpoint = False
if (
model_args.quantize_model in quantize_args_to_model_class.keys()
): # However, qmem should not used currently becuase I haven't merge the memory reduction version into VILA
from llava.model.language_model.qllava_qllama import QLlavaLlamaModel
model_cls = QLlavaLlamaModel
else:
assert (
model_args.quantize_model == "false"
), f"{model_args.quantize_model} for model_args.quantize_model is not supported"
model_cls = LlavaLlamaModel
config = LlavaLlamaConfig.from_pretrained(model_args.model_name_or_path, resume=resume_from_checkpoint)
if getattr(config, "resume_path", None) is not None:
config.resume_path = model_args.model_name_or_path
prepare_config_for_training(config, model_args, training_args, data_args)
if model_args.quantize_model in quantize_args_to_model_class.keys():
model = model_cls(
config=config,
model_args=model_args,
attn_implementation="flash_attention_2",
model_max_length=training_args.model_max_length,
cache_dir=training_args.cache_dir,
**bnb_model_from_pretrained_args,
)
else:
model = model_cls(
config=config,
attn_implementation="flash_attention_2",
model_max_length=training_args.model_max_length,
cache_dir=training_args.cache_dir,
**bnb_model_from_pretrained_args,
)
if not resume_path or training_args.lora_enable:
if model_args.mlp_path is not None:
state_dict = torch.load(model_args.mlp_path, map_location="cpu")
state_dict_new = {}
for k, v in state_dict.items():
if k == "0.weight":
state_dict_new["layers.1.weight"] = v
if k == "0.bias":
state_dict_new["layers.1.bias"] = v
if k == "1.weight":
state_dict_new["layers.2.weight"] = v
if k == "1.bias":
state_dict_new["layers.2.bias"] = v
if k == "3.weight":
state_dict_new["layers.4.weight"] = v
if k == "3.bias":
state_dict_new["layers.4.bias"] = v
model.get_mm_projector().load_state_dict(state_dict_new)
vision_resolution_elevation(model, config)
if unit_test_rope_scaling(model, model.llm.config, training_args):
return
if 'phi' in model_args.model_name_or_path:
model.resize_token_embeddings(len(model.tokenizer))
mprint(model)
model.llm.config.use_cache = False
def need_to_modify_do_sample(generation_config):
if generation_config is None:
warnings.warn("generation config is None, skip do sample modification")
return False
if generation_config.do_sample is False:
if generation_config.temperature is not None and generation_config.temperature != 1.0:
return True
if generation_config.top_p is not None and generation_config.top_p != 1.0:
return True
return False
if need_to_modify_do_sample(model.llm.generation_config):
model.llm.generation_config.do_sample = True
if training_args.bits in [4, 8]:
from peft import prepare_model_for_kbit_training
model.llm.config.torch_dtype = (
torch.float32 if training_args.fp16 else (torch.bfloat16 if training_args.bf16 else torch.float32)
)
model.llm = prepare_model_for_kbit_training(
model.llm, use_gradient_checkpointing=training_args.gradient_checkpointing
)
if training_args.gradient_checkpointing:
if hasattr(model.llm, "enable_input_require_grads"):
model.llm.enable_input_require_grads()
else:
def make_inputs_require_grad(module, input, output):
output.requires_grad_(True)
model.get_input_embeddings().register_forward_hook(make_inputs_require_grad)
if training_args.lora_enable:
from peft import LoraConfig, PeftModel, get_peft_model
lora_config = LoraConfig(
use_dora=training_args.use_dora,
r=training_args.lora_r,
lora_alpha=training_args.lora_alpha,
target_modules=find_all_linear_names(model, training_args.lora_llm, training_args.lora_vt),
lora_dropout=training_args.lora_dropout,
bias=training_args.lora_bias,
task_type="CAUSAL_LM",
)
if training_args.bits == 16:
if training_args.bf16:
model.to(torch.bfloat16)
if training_args.fp16:
model.to(torch.float16)
if resume_from_checkpoint:
if os.path.exists(os.path.join(resume_path, "non_lora_trainables.bin")):
non_lora_trainables = torch.load(
os.path.join(resume_path, "non_lora_trainables.bin"),
map_location="cpu",
)
non_lora_trainables = {
(k[11:] if k.startswith("base_model.") else k): v for k, v in non_lora_trainables.items()
}
if any(k.startswith("model.model.") for k in non_lora_trainables):
non_lora_trainables = {
(k[6:] if k.startswith("model.") else k): v for k, v in non_lora_trainables.items()
}
model.load_state_dict(non_lora_trainables, strict=False)
mprint("Resume from checkpoint...", resume_path)
model = PeftModel.from_pretrained(model, resume_path, is_trainable=True)
else:
mprint("Adding LoRA adapters...")
model = get_peft_model(model, lora_config)
mprint(model)
model.print_trainable_parameters()
if training_args.lora_enable:
if not training_args.lora_llm:
model.get_llm().requires_grad_(training_args.tune_language_model)
if model.get_vision_tower():
if training_args.lora_vt:
def make_inputs_require_grad(module, input, output):
output.requires_grad_(True)
model.get_vision_tower().vision_tower.get_input_embeddings().register_forward_hook(
make_inputs_require_grad
)
elif training_args.tune_vision_tower:
model.get_vision_tower().requires_grad_(training_args.tune_vision_tower)
model.get_mm_projector().requires_grad_(training_args.tune_mm_projector)
mprint(f"mm projector {training_args.tune_mm_projector}")
model.print_trainable_parameters()
else:
model.get_llm().requires_grad_(training_args.tune_language_model)
mprint(f"Tunable parameters:\nlanguage model {training_args.tune_language_model}")
if model.get_vision_tower():
model.get_vision_tower().requires_grad_(training_args.tune_vision_tower)
model.get_mm_projector().requires_grad_(training_args.tune_mm_projector)
mprint(f"vision tower {training_args.tune_vision_tower}")
mprint(f"mm projector {training_args.tune_mm_projector}")
trainable_params, all_param = get_nb_trainable_parameters(model)
print(
f"trainable params: {trainable_params:,d} || all params: {all_param:,d} || trainable%: {100 * trainable_params / all_param:.4f}"
)
if not any(
[training_args.tune_language_model, training_args.tune_vision_tower, training_args.tune_mm_projector]
):
logging.warning("You are not tuning any part of the model. Please check if this is intended.")
tokenizer = model.tokenizer
if tokenizer.bos_token is None:
smart_tokenizer_and_embedding_resize(
special_tokens_dict=dict(bos_token="[BOS]"),
tokenizer=tokenizer,
model=model.llm,
)
tokenizer.pad_token = tokenizer.unk_token
if tokenizer.pad_token is None:
smart_tokenizer_and_embedding_resize(
special_tokens_dict=dict(pad_token="[PAD]"),
tokenizer=tokenizer,
model=model.llm,
)
if model_args.version in conversation_lib.conv_templates:
conversation_lib.default_conversation = conversation_lib.conv_templates[model_args.version]
else:
conversation_lib.default_conversation = conversation_lib.conv_templates["vicuna_v1"]
vision_tower = model.get_vision_tower()
if vision_tower is not None:
data_args.image_processor = vision_tower.image_processor
data_args.is_multimodal = True
if hasattr(data_args, "num_video_frames") and data_args.num_video_frames != None:
model.config.num_video_frames = data_args.num_video_frames
else:
model.config.num_video_frames = 8
if hasattr(data_args, "fps"):
model.config.fps = data_args.fps
else:
model.config.fps = 0.0
model.config.image_aspect_ratio = data_args.image_aspect_ratio
model.config.mm_projector_lr = training_args.mm_projector_lr
model.config.vision_tower_lr = training_args.vision_tower_lr
if model_args.mm_use_im_start_end:
num_new_tokens = tokenizer.add_tokens([DEFAULT_IM_START_TOKEN, DEFAULT_IM_END_TOKEN], special_tokens=True)
assert not model_args.mm_use_im_patch_token
model.config.num_time_tokens = data_args.num_time_tokens = model_args.num_time_tokens
model.config.time_token_format = data_args.time_token_format = model_args.time_token_format
if model_args.num_time_tokens > 0:
time_tokens = [model.config.time_token_format.format(t=t) for t in range(model.config.num_time_tokens)]
num_new_tokens = tokenizer.add_tokens(time_tokens)
assert len(time_tokens) == num_new_tokens or num_new_tokens == 0
model.resize_token_embeddings(len(tokenizer))
model.config.time_token_ids = tokenizer.convert_tokens_to_ids(time_tokens)
else:
model.config.time_token_ids = []
model.config.soft_ce_std = model_args.soft_ce_std
num_patches = model.get_vision_tower().num_patches
downsample_rate = model.get_mm_projector().downsample_rate
num_image_tokens = math.ceil(num_patches**0.5 / downsample_rate) ** 2
data_args.num_image_tokens = num_image_tokens
if training_args.bits in [4, 8]:
from peft.tuners.lora import LoraLayer
for name, module in model.named_modules():
if isinstance(module, LoraLayer):
if training_args.bf16:
module = module.to(torch.bfloat16)
if "norm" in name:
module = module.to(torch.float32)
if "lm_head" in name or "embed_tokens" in name:
if hasattr(module, "weight"):
if training_args.bf16 and module.weight.dtype == torch.float32:
module = module.to(torch.bfloat16)
data_args.s2_scales = list(map(int, model_args.s2_scales.split(",")))
data_module = make_supervised_data_module(
tokenizer=tokenizer,
data_args=data_args,
training_args=training_args,
)
if training_args.total_time_limit != -1:
callbacks = [AutoResumeCallback(), TimeoutTerminateCallback(total_time_limit=training_args.total_time_limit)] # 連続学習時間制限指定できるようにする
else:
callbacks = [AutoResumeCallback(), TimeoutTerminateCallback()] # 4時間連続学習しかできない。4時間超えるとjob落ちる
if training_args.dpo:
ref_model = model_cls(
config=config,
attn_implementation="flash_attention_2",
model_max_length=training_args.model_max_length,
cache_dir=training_args.cache_dir,
**bnb_model_from_pretrained_args,
)
train_dataset = DPODataset(tokenizer=tokenizer, data_mixture=data_args.data_mixture, data_args=data_args)
data_collator = DPODataCollator(
tokenizer=tokenizer,
label_pad_token_id=IGNORE_INDEX,
pad_token_id=tokenizer.pad_token_id,
)
extra_info = []
extra_info.append(len(train_dataset))
training_args.sample_lens = extra_info
trainer = VILADPOTrainer(
model=model,
dpo_alpha=1.0,
gamma=0,
ref_model=ref_model,
tokenizer=tokenizer,
args=training_args,
beta=training_args.dpo_beta,
callbacks=callbacks,
train_dataset=train_dataset,
data_collator=data_collator,
)
else:
trainer = LLaVATrainer(model=model, tokenizer=tokenizer, args=training_args, callbacks=callbacks, **data_module)
if model_args.quantize_model in ["fp8Activation_qwen2", "fp8ActivationResidual_qwen2"]:
from llava.model.coat.fp8_trainer import CoatFP8Trainer
trainer._inner_training_loop = CoatFP8Trainer._inner_training_loop.__get__(
trainer, LLaVATrainer
) # GPT told me to do this
print(
"length of dataloader:",
len(trainer.get_train_dataloader()),
len(trainer.train_dataset),
flush=True,
)
print(
"[GPU memory] before trainer",
torch.cuda.memory_allocated() / 1024 / 1024 / 1024,
flush=True,
)
trainer.train(resume_from_checkpoint=resume_from_checkpoint)
if training_args.debug_e2e:
exit()
trainer.save_state()
model.llm.config.use_cache = True
model.config.resume_path = model.config._name_or_path = training_args.output_dir
if training_args.lora_enable:
state_dict = get_peft_state_maybe_zero_3(model.named_parameters(), training_args.lora_bias)
non_lora_state_dict = get_peft_state_non_lora_maybe_zero_3(model.named_parameters())
if training_args.local_rank == 0 or training_args.local_rank == -1:
model.config.save_pretrained(training_args.output_dir)
model.save_pretrained(training_args.output_dir, state_dict=state_dict)
torch.save(
non_lora_state_dict,
os.path.join(training_args.output_dir, "non_lora_trainables.bin"),
)
else:
safe_save_model_for_hf_trainer(trainer=trainer, output_dir=training_args.output_dir)
if __name__ == "__main__":
train()
学習を実行するシェルスクリプトは公式リポジトリの https://github.com/NVlabs/VILA/tree/main/scripts/NVILA-Lite をベースにしました。
主な変更点は次のとおりです。
-
Slurm ジョブスケジューラ対応 –
sbatchでジョブ投入できるよう変更 -
MPI 実行対応 –
mpirun経由での起動に合わせてランク/環境変数の設定を調整 -
DeepSpeed ZeRO-2 による分散学習 – 高速な並列学習を実現するため
deepspeed --zero_stage 2で実行
実際に使用したシェルスクリプトは以下です。
Heron-NVILA-Lite-15BのStage1学習で用いたシェルスクリプト
#!/bin/bash
#SBATCH --job-name=align_14b
#SBATCH --time=100:00:00
#SBATCH --partition=aws-p5
#SBATCH --nodes=2
#SBATCH --gpus-per-node=8
#SBATCH --ntasks-per-node=8
#SBATCH --cpus-per-task=24
#SBATCH --output=sbatch_outputs/%j-%x.out
#SBATCH --error=sbatch_outputs/%j-%x.out
#SBATCH --nodelist=aws-p5-st-h100-13,aws-p5-st-h100-14
DEFAULT_GLOBAL_TRAIN_BATCH_SIZE=2048
DEFAULT_GRADIENT_ACCUMULATION_STEPS=16
source scripts/setups/train_aws_v4.sh
OUTPUT_DIR="runs/train/NVILA-Lite_14b_siglip_aws_env2_obelics_ja/$SLURM_JOB_NAME"
DATA_MIXTURE="llava_1_5_mm_align_en+llm_jp_mm_pair_step0_558k"
STAGE_PATH="/data/models/Qwen/Qwen2.5-14B-Instruct"
CHAT_TEMPLATE="qwen2_jp"
VISION_TOWER="/data/models/Efficient-Large-Model/paligemma-siglip-so400m-patch14-448"
OPTIONS=" \
--deepspeed scripts/zero2.json \
--model_name_or_path $STAGE_PATH \
--chat_template $CHAT_TEMPLATE \
--data_mixture $DATA_MIXTURE \
--vision_tower $VISION_TOWER \
--mm_vision_select_feature cls_patch \
--mm_projector mlp_downsample_3x3_fix \
--tune_vision_tower False \
--tune_mm_projector True \
--tune_language_model False \
--mm_vision_select_layer -2 \
--mm_use_im_start_end False \
--mm_use_im_patch_token False \
--image_aspect_ratio dynamic \
--bf16 True \
--output_dir $OUTPUT_DIR/model \
--num_train_epochs 1 \
--per_device_train_batch_size $PER_DEVICE_TRAIN_BATCH_SIZE \
--gradient_accumulation_steps $GRADIENT_ACCUMULATION_STEPS \
--evaluation_strategy no \
--save_strategy steps \
--save_steps 500 \
--save_total_limit 1 \
--learning_rate 1e-3 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type cosine \
--logging_steps 1 \
--model_max_length 4096 \
--gradient_checkpointing True \
--dataloader_num_workers 8 \
--report_to tensorboard \
--total_time_limit 6000 \
"
mpirun -np $NUM_GPUS \
--npernode $NUM_GPU_PER_NODE \
-x MASTER_ADDR=$MASTER_ADDR \
-x MASTER_PORT=$MASTER_PORT \
-x CUDA_LAUNCH_BLOCKING=1 \
-x CUDA_DEVICE_MAX_CONNECTIONS=1 \
-x LD_LIBRARY_PATH \
-x PATH \
--hostfile $hostfile \
--mca pml ^cm,ucx \
--mca btl tcp,self \
--mca btl_tcp_if_exclude lo,docker0,veth_def_agent \
--bind-to none -map-by slot \
--mca orte_debug_daemons 1 \
--mca plm_base_verbose 5 \
python llava/train/train_mem_mpirun.py ${OPTIONS}
Heron-NVILA-Lite-15BのStage2学習で用いたシェルスクリプト
#!/bin/bash
#SBATCH --job-name=pretrain_14b
#SBATCH --time=600:00:00
#SBATCH --partition=aws-p5
#SBATCH --nodes=12
#SBATCH --gpus-per-node=8
#SBATCH --ntasks-per-node=8
#SBATCH --cpus-per-task=24
#SBATCH --output=sbatch_outputs/%j-%x.out
#SBATCH --error=sbatch_outputs/%j-%x.out
#SBATCH --nodelist=aws-p5-st-h100-[1-12]
DEFAULT_GLOBAL_TRAIN_BATCH_SIZE=1152
DEFAULT_GRADIENT_ACCUMULATION_STEPS=6
source scripts/setups/train_aws_v4.sh
OUTPUT_DIR="runs/train/NVILA-Lite_14b_siglip_aws_env2_obelics_ja/$SLURM_JOB_NAME"
DATA_MIXTURE="mix_wikipedia_ja_llava_pretrain_ja_stair_captions_less_filter+llm_jp_mm_interleaved_step1_6m_v2+llm_jp_mm_pair_step1_6m+coyo_6m+mmc4core_6img_filter_text_filter+obelics_ja"
STAGE_PATH="runs/train/NVILA-Lite_14b_siglip_aws_env2_obelics_ja/align_14b/model"
VISION_TOWER="/data/models/Efficient-Large-Model/paligemma-siglip-so400m-patch14-448"
OPTIONS=" \
--deepspeed scripts/zero2.json \
--model_name_or_path $STAGE_PATH \
--data_mixture $DATA_MIXTURE \
--vision_tower $VISION_TOWER \
--mm_vision_select_feature cls_patch \
--mm_projector mlp_downsample_3x3_fix \
--tune_vision_tower False \
--tune_mm_projector True \
--tune_language_model True \
--mm_vision_select_layer -2 \
--mm_use_im_start_end False \
--mm_use_im_patch_token False \
--image_aspect_ratio dynamic \
--bf16 True \
--output_dir $OUTPUT_DIR/model \
--num_train_epochs 1 \
--per_device_train_batch_size $PER_DEVICE_TRAIN_BATCH_SIZE \
--gradient_accumulation_steps $GRADIENT_ACCUMULATION_STEPS \
--evaluation_strategy no \
--save_strategy steps \
--save_steps 500 \
--save_total_limit 10 \
--learning_rate 5e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type cosine \
--logging_steps 1 \
--model_max_length 4096 \
--gradient_checkpointing True \
--dataloader_num_workers 4 \
--report_to tensorboard \
--total_time_limit 360000 \
"
mpirun -np $NUM_GPUS \
--npernode $NUM_GPU_PER_NODE \
-x MASTER_ADDR=$MASTER_ADDR \
-x MASTER_PORT=$MASTER_PORT \
-x CUDA_LAUNCH_BLOCKING=1 \
-x CUDA_DEVICE_MAX_CONNECTIONS=1 \
-x LD_LIBRARY_PATH \
-x PATH \
--hostfile $hostfile \
--mca pml ^cm,ucx \
--mca btl tcp,self \
--mca btl_tcp_if_exclude lo,docker0,veth_def_agent \
--bind-to none -map-by slot \
python llava/train/train_mem_mpirun.py ${OPTIONS}
Heron-NVILA-Lite-15BのStage3学習で用いたシェルスクリプト
#!/bin/bash
#SBATCH --job-name=sft_14b_GPT4_v6
#SBATCH --time=600:00:00
#SBATCH --partition=aws-p5
#SBATCH --nodes=12
#SBATCH --gpus-per-node=8
#SBATCH --ntasks-per-node=8
#SBATCH --cpus-per-task=24
#SBATCH --output=sbatch_outputs/%j-%x.out
#SBATCH --error=sbatch_outputs/%j-%x.out
#SBATCH --nodelist=aws-p5-st-h100-[1-12]
DEFAULT_GLOBAL_TRAIN_BATCH_SIZE=2304
DEFAULT_GRADIENT_ACCUMULATION_STEPS=12
source scripts/setups/train_aws_v4.sh
OUTPUT_DIR="runs/train/NVILA-Lite_14b_siglip_aws_env2_obelics_ja/$SLURM_JOB_NAME"
DATA_MIXTURE="llava_instruct_v1_5_en_subset+llava_instruct_ja+japanese_photos_conv+ja_vg_vqa+synthdog_ja_subset+ai2d_train_12k+synthdog_en+sherlock"
STAGE_PATH="runs/train/NVILA-Lite_14b_siglip_aws_env2_obelics_ja/pretrain_14b/model"
VERSION="qwen2_sft_jp"
VISION_TOWER="/data/models/Efficient-Large-Model/paligemma-siglip-so400m-patch14-448"
OPTIONS=" \
--deepspeed scripts/zero2.json \
--model_name_or_path $STAGE_PATH \
--data_mixture $DATA_MIXTURE \
--vision_tower $VISION_TOWER \
--version $VERSION \
--mm_vision_select_feature cls_patch \
--mm_projector mlp_downsample_3x3_fix \
--tune_vision_tower True \
--tune_mm_projector True \
--tune_language_model True \
--mm_vision_select_layer -2 \
--mm_use_im_start_end False \
--mm_use_im_patch_token False \
--image_aspect_ratio dynamic \
--bf16 True \
--output_dir $OUTPUT_DIR/model \
--num_train_epochs 1 \
--per_device_train_batch_size $PER_DEVICE_TRAIN_BATCH_SIZE \
--gradient_accumulation_steps $GRADIENT_ACCUMULATION_STEPS \
--evaluation_strategy no \
--save_strategy steps \
--save_steps 100 \
--save_total_limit 1 \
--learning_rate 2e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type cosine \
--logging_steps 1 \
--model_max_length 4096 \
--gradient_checkpointing True \
--dataloader_num_workers 4 \
--vflan_no_system_prompt True \
--report_to tensorboard \
--total_time_limit 36000 \
"
mpirun -np $NUM_GPUS \
--npernode $NUM_GPU_PER_NODE \
-x MASTER_ADDR=$MASTER_ADDR \
-x MASTER_PORT=$MASTER_PORT \
-x CUDA_LAUNCH_BLOCKING=1 \
-x CUDA_DEVICE_MAX_CONNECTIONS=1 \
-x LD_LIBRARY_PATH \
-x PATH \
--hostfile $hostfile \
--mca pml ^cm,ucx \
--mca btl tcp,self \
--mca btl_tcp_if_exclude lo,docker0,veth_def_agent \
--bind-to none -map-by slot \
python llava/train/train_mem_mpirun.py ${OPTIONS}
苦労した点
計算資源はGENIACの支援で確保したH100インスタンス16ノードを使用し、2〜15ノードでマルチノード学習を行いました。
H100インスタンスのスペック
| 項目 | AWS (P5.48xlarge) |
|---|---|
| GPU | H100 × 8 |
| CPU (2 Socket) | AMD EPYC 7R13 @ 2.65 GHz, 48 cores × 2 計 96 cores / 192 threads |
| Memory | 2,048 GB |
| SSD | NVMe SSD 3.84 TB × 8 |
| Interconnect | AWS EFA 100 Gbps × 32 計 3.2 Tbps |
| Shared Storage | FSx for Lustre (最大 40.8 GB/s) |
最も苦労したのはマルチノード学習の安定化で、学習ジョブがエラーログも残さず途中で停止する現象に長く悩まされました。PyTorch・CUDA・cuDNN・NCCLのバージョンをNVIDIAのドキュメントに従って揃えても症状は完全には解消せず、外れノードを引き当てている可能性に行き着きました。
最終的には、
- 数百stepごとにcheckpointを保存
- 学習が止まったらノードを再起動してインスタンスを引き直す
- 保存したcheckpointから学習再開
という運用でジョブを走らせました。
その他に以下のような問題も起きました。
-
ストレージ容量
- 画像件数が膨大であることから jpg/png で画像を保持するとinode(ファイル数)上限に達するため、一部の画像は tar/pkl に固めてファイル数を削減しました。また、学習に使わなかったデータも含めるとデータだけで50TB程度ストレージ容量が必要になりました。
-
データライセンス & 取得方法
- データセットは研究目的限定/商用不可のものも多く、画像は URL のみの提供で img2dataset などで自前クロールが必要でした。テキストと画像で取得フローが異なる場合もありダウンロード作業が煩雑でした。
-
VRAM要件
- マルチ画像入力により VRAM 消費が増大するバッチも発生しました。ノード追加・マイクロバッチサイズ削減などで調整しました。
-
学習の安定化
- 画像とテキストの不整合などが原因で発生したと推定される loss spike や 極端に長いテキスト、超高解像度画像を伴うサンプルによって OOM が発生しました。学習中で問題発生 → 問題とおぼしきデータを確認・除去 → 学習やり直し を繰り返しました。
評価
定量評価
日本語VLMの性能評価ツールであるllm-jp-eval-mmで日本語ベンチマークを評価しました。
llm-jp-eval-mmで使用した評価コード
# llm-jp-eval-mm/examples/heron_nvila.py
from base_vlm import BaseVLM
from utils import GenerationConfig
import torch
from transformers import GenerationConfig as HFGenerationConfig, AutoModel
import unittest
def create_prompt(text, image):
if image is None or (isinstance(image, list) and len(image) == 0):
return [text] if text else []
if not isinstance(image, list):
image = [image]
if not text:
return image
if "<image>" not in text:
prompt = image.copy()
prompt.append(text)
return prompt
parts = text.split("<image>")
prompt, idx = [], 0
if parts[0] == "":
prompt.append(image[idx])
idx += 1
parts = parts[1:]
for i, part in enumerate(parts):
if part:
prompt.append(part)
if idx < len(image) and (i < len(parts) - 1 or text.endswith("<image>")):
prompt.append(image[idx])
idx += 1
return prompt
class VLM(BaseVLM):
def __init__(self, model_id="turing-motors/Heron-NVILA-Lite-15B"):
self.model_id = model_id
self.model = AutoModel.from_pretrained(
model_id, trust_remote_code=True, device_map="auto"
)
def generate(self, image, text: str, gen_kwargs: GenerationConfig = GenerationConfig()):
gen_cfg = HFGenerationConfig(**gen_kwargs.__dict__)
prompt = create_prompt(text, image)
with torch.no_grad():
return self.model.generate_content(prompt, generation_config=gen_cfg)
if __name__ == "__main__":
unittest.main(argv=["first-arg-is-ignored"], exit=False)
VLM("turing-motors/Heron-NVILA-Lite-15B").test_vlm()
LLM-as-a-Judgeの評価モデルは「gpt-4o-2024-11-20」を使用しています。 LLMが確率的に回答を生成するためスコアは再実行ごとにわずかに変わります。例えば、Heron Benchなら±0.3未満程度でスコアが上下します。Hugging Face のモデルページにもスコアを記載していますがあちらは評価モデルが「gpt-4o-2024-05-13」での結果です。LLM-as-a-Judgeは評価モデルによってスコアが大きく変わります。
同程度のパラメータ数のモデルと比較して特に良かったベンチマークは以下です。ベンチマークの全項目は列数が多いためトグルで隠しています。Heron-NVILA以外のスコアは2025/5/3時点のllm-jp-eval-mmリーダーボードの値です。
| Model | Heron /LLM | VG-VQA /LLM | JVB-ItW /LLM | MulIm-VQA /LLM | JMMMU /Acc |
|---|---|---|---|---|---|
| Heron-NVILA-Lite-1B | 58.2 | 3.4 | 3.4 | 3.0 | 26.4 |
| Heron-NVILA-Lite-2B | 63.6 | 3.7 | 4.0 | 3.0 | 37.0 |
| Heron-NVILA-Lite-15B | 73.5 | 4.0 | 4.4 | 4.3 | 49.5 |
| stabilityai/japanese-stable-vlm | 48.4 | 3.5 | 3.3 | 2.3 | 3.4 |
| SakanaAI/Llama-3-EvoVLM-JP-v2 | 47.6 | 3.4 | 3.5 | 3.1 | 36.4 |
| cyberagent/llava-calm2-siglip | 54.1 | 3.6 | 3.7 | 2.8 | 6.1 |
| llm-jp/llm-jp-3-vila-14b | 68.0 | 3.9 | 4.1 | 3.5 | 19.0 |
| sbintuitions/sarashina2-vision-8b | 60.5 | 3.7 | 4.1 | 2.6 | 39.2 |
| sbintuitions/sarashina2-vision-14b | 60.1 | 3.7 | 4.0 | 2.6 | 43.0 |
| MIL-UT/Asagi-14B | 41.9 | 2.0 | 2.9 | 2.0 | 21.7 |
| OpenGVLab/InternVL2-26B | 59.7 | 3.6 | 3.1 | 3.3 | 39.0 |
| Qwen/Qwen2.5-VL-7B-Instruct | 70.3 | 3.7 | 4.3 | 4.1 | 48.2 |
| google/gemma-3-12b-it | 72.2 | 3.7 | 4.3 | 4.2 | 47.6 |
| microsoft/Phi-4-multimodal-instruct | 45.5 | 3.3 | 3.2 | 3.4 | 39.2 |
llm-jp-eval-mmの全項目
| Model | Heron /LLM | VG-VQA /LLM | VG-VQA /Rouge | JIC /Acc | MECHA /Acc | MMMU /Acc | JVB-ItW /LLM | JVB-ItW /Rouge | LLAVA /LLM | LLAVA /Rouge | JDocQA /Acc | JDocQA /LLM | MulIm-VQA /LLM | MulIm-VQA /Rouge | JMMMU /Acc |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Heron-NVILA-Lite-1B | 58.2 | 3.4 | 14.5 | 48.0 | 29.0 | 22.3 | 3.4 | 42.7 | 2.4 | 33.2 | 15.2 | 2.1 | 3.0 | 28.2 | 26.4 |
| Heron-NVILA-Lite-2B | 63.6 | 3.7 | 17.0 | 46.4 | 48.2 | 35.9 | 4.0 | 48.8 | 2.9 | 35.4 | 17.7 | 2.4 | 3.0 | 42.7 | 37.0 |
| Heron-NVILA-Lite-15B | 73.5 | 4.0 | 25.9 | 80.9 | 68.3 | 47.1 | 4.4 | 50.6 | 3.6 | 36.6 | 19.2 | 2.7 | 4.3 | 60.0 | 49.5 |
| stabilityai/japanese-stable-vlm | 48.4 | 3.5 | 45.7 | 69.3 | 4.8 | 7.1 | 3.3 | 23.2 | 1.4 | 0.6 | 13.1 | 2.1 | 2.3 | 40.7 | 3.4 |
| SakanaAI/Llama-3-EvoVLM-JP-v2 | 47.6 | 3.4 | 24.7 | 67.0 | 50.7 | 38.9 | 3.5 | 48.4 | 2.9 | 27.9 | 15.4 | 2.4 | 3.1 | 44.3 | 36.4 |
| cyberagent/llava-calm2-siglip | 54.1 | 3.6 | 17.7 | 58.5 | 11.2 | 26.7 | 3.7 | 46.3 | 1.9 | 2.9 | 8.2 | 2.0 | 2.8 | 40.6 | 6.1 |
| llm-jp/llm-jp-3-vila-14b | 68.0 | 3.9 | 16.2 | 81.3 | 45.6 | 32.7 | 4.1 | 52.4 | 3.4 | 36.0 | 17.3 | 2.5 | 3.5 | 47.0 | 19.0 |
| sbintuitions/sarashina2-vision-8b | 60.5 | 3.7 | 25.4 | 78.7 | 56.3 | 29.7 | 4.1 | 44.8 | 2.5 | 16.9 | 22.6 | 3.0 | 2.6 | 30.2 | 39.2 |
| sbintuitions/sarashina2-vision-14b | 60.1 | 3.7 | 25.3 | 80.0 | 64.4 | 33.8 | 4.0 | 44.3 | 2.5 | 15.6 | 23.9 | 3.1 | 2.6 | 35.3 | 43.0 |
| MIL-UT/Asagi-14B | 41.9 | 2.0 | 9.3 | 76.2 | 24.1 | 15.3 | 2.9 | 30.9 | 1.6 | 0.1 | 10.4 | 2.0 | 2.0 | 18.4 | 21.7 |
| llava-hf/llava-1.5-7b | 43.1 | 3.0 | 14.0 | 44.0 | 38.2 | 34.0 | 3.0 | 40.8 | 2.9 | 34.5 | 14.8 | 2.2 | 2.5 | 35.8 | 29.6 |
| llava-hf/llava-v1.6-mistral-7b | 30.0 | 3.0 | 11.7 | 58.2 | 34.4 | 35.9 | 2.9 | 28.6 | 3.3 | 30.7 | 14.4 | 2.0 | 2.3 | 25.2 | 25.4 |
| neulab/Pangea-7B | 57.0 | 4.1 | 54.2 | 85.6 | 56.5 | 43.7 | 3.9 | 33.5 | 3.5 | 25.9 | 16.2 | 2.4 | 3.4 | 40.3 | 37.4 |
| mistralai/Pixtral-12B-2409 | 60.9 | 3.5 | 13.1 | 61.1 | 56.4 | 48.6 | 3.9 | 38.3 | 3.6 | 31.6 | 14.8 | 2.4 | 4.1 | 34.5 | 18.7 |
| meta-llama/Llama-3.2-11B-VI | 38.1 | 3.3 | 14.2 | 78.7 | 49.3 | 38.2 | 3.4 | 30.4 | 3.7 | 30.2 | 17.6 | 2.5 | 2.6 | 24.5 | 34.6 |
| Efficient-LM/VILA1.5-13B | 46.9 | 3.2 | 13.0 | 58.2 | 46.4 | 37.0 | 3.5 | 42.5 | 3.6 | 35.0 | 14.8 | 2.2 | 3.2 | 40.0 | 33.5 |
| OpenGVLab/InternVL2-8B | 49.8 | 3.5 | 11.7 | 65.7 | 50.5 | 49.7 | 3.5 | 33.8 | 3.1 | 31.5 | 19.8 | 2.7 | 2.9 | 34.5 | 39.1 |
| OpenGVLab/InternVL2-26B | 59.7 | 3.6 | 11.6 | 73.9 | 51.3 | 48.2 | 3.1 | 26.7 | 3.8 | 30.6 | 15.3 | 2.6 | 3.3 | 45.4 | 39.0 |
| Qwen/Qwen2.5-VL-7B | 70.3 | 3.7 | 9.0 | 82.7 | 60.0 | 50.0 | 4.3 | 29.6 | 3.9 | 27.1 | 26.5 | 3.6 | 4.1 | 50.4 | 48.2 |
| Qwen/Qwen2.5-VL-32B | 74.8 | 3.8 | 5.2 | 96.0 | 68.4 | 59.1 | 4.3 | 14.7 | 4.0 | 18.9 | 25.2 | 3.8 | 4.6 | 42.2 | 48.8 |
| Qwen/Qwen2.5-VL-72B | 85.5 | 3.9 | 9.8 | 90.4 | 74.7 | 63.0 | 4.4 | 32.0 | 4.0 | 28.7 | 23.9 | 3.9 | 4.8 | 60.9 | 60.6 |
| google/gemma-3-4B-it | 52.8 | 3.4 | 12.5 | 75.4 | 47.2 | 40.7 | 3.7 | 37.1 | 3.6 | 22.1 | 17.6 | 2.6 | 3.7 | 52.7 | 37.0 |
| google/gemma-3-12B-it | 72.2 | 3.7 | 12.5 | 85.7 | 62.6 | 48.1 | 4.3 | 35.7 | 4.0 | 22.1 | 20.1 | 3.0 | 4.2 | 59.7 | 47.6 |
| google/gemma-3-27B-it | 69.2 | 3.8 | 10.9 | 88.2 | 67.7 | 56.1 | 4.4 | 30.9 | 3.9 | 21.1 | 20.2 | 3.1 | 4.3 | 56.3 | 50.5 |
| microsoft/Phi-4-multimodal | 45.5 | 3.3 | 19.0 | 52.3 | 46.4 | 53.7 | 3.2 | 26.8 | 3.4 | 29.5 | 22.9 | 2.9 | 3.4 | 42.3 | 39.2 |
| gpt-4o-2024-11-20 | 93.7 | 3.9 | 11.8 | 95.8 | 83.7 | 56.1 | 4.4 | 32.2 | 4.1 | 29.8 | 22.0 | 3.6 | 4.8 | 62.5 | 57.5 |
各列の説明
- Model: モデル名
- Heron/LLM: GPT-4o(gpt-4o-2024-11-20) で評価したJapanese Heron Bench の総合スコア。Heron Bench は日本の風景や文化を写した画像を説明できるかを評価。
- VG-VQA/LLM, Rouge: JA-VG-VQA500 を GPT-4o(gpt-4o-2024-11-20) で評価したスコアとROUGE-L 類似度。JA-VG-VQA500 はVisual Genome の日本語 VQA サブセット500 問。
- JIC/Acc: JIC-VQA の正解率。JIC-VQA は日本の食事・花・施設などを写した画像に対する多肢選択問題。
- MECHA/Acc: MECHA-ja の正解率。MECHA-ja は日本国内で撮影された画像に対する多肢選択問題。
- MMMU/Acc: MMMU の正解率。MMMU は大学レベルの知識と推論能力を評価する多肢選択問題。
- JVB-ItW/LLM, Rouge: JA-VLM-Bench-In-the-Wild を GPT-4o(gpt-4o-2024-11-20) で評価したスコアとROUGE-L 類似度。JA-VLM-Bench-In-the-Wild はLLaVA-Bench-In-the-Wild の日本語版。
- LLAVA/LLM, Rouge: LlaVA-Bench-In-the-Wild を GPT-4o(gpt-4o-2024-11-20) で評価したスコアとROUGE-L 類似度。LlaVA-Bench-In-the-Wild は風景写真やミーム、絵画など実世界の画像を説明できるかを評価する。
- JDocQA/Acc, LLM: JDocQA の正解率と GPT-4o(gpt-4o-2024-11-20) で評価したスコア。JDocQA は日本語PDF から答えを生成するドキュメント QA。
- MulIm-VQA/LLM, Rouge: JA-Multi-Image-VQA を GPT-4o(gpt-4o-2024-11-20) で評価したスコアとROUGE-L 類似度。JA-Multi-Image-VQA は2〜4 枚の画像を見て答えるマルチイメージ VQA。
- JMMMU/Acc: JMMMU の正解率。JMMMU は日本版 MMMU。
定性評価
Heron-Benchの質問に対するHeron-NVILAの回答と筆者の主観評価を残します。
- 〇 = 質問意図を正しく汲み取り、内容も概ね的確
- × = 要求に合っていない、もしくは明らかな誤答

質問: 信号機の色は何色ですか?
| 主観評価 | Model | 回答 |
|---|---|---|
| 〇 | Heron-NVILA-Lite-15B | 信号機の色は赤色です。 |
| 〇 | Heron-NVILA-Lite-2B | 信号機の色は赤色です。 |
| 〇 | Heron-NVILA-Lite-1B | 信号機の色は赤色です。 |

質問: こたつと言えば、何の果物が思い浮かびますか?
| 主観評価 | Model | 回答 |
|---|---|---|
| 〇 | Heron-NVILA-Lite-15B | こたつと言えば、ミカンが思い浮かびます。ミカンは冬の果物として人気があり、こたつの上に置かれたミカンのボウルは、温かい部屋でリラックスしながら楽しむための典型的なシーンを表しています。 |
| 〇 | Heron-NVILA-Lite-2B | こたつと言えば、一般的にはみかんが思い浮かびます。この画像では、こたつの上にいくつかのオレンジが置かれていますが、みかんである可能性が高いです。みかんなのは、冬の寒い季節に温かいお茶やお菓子と一緒に楽しむのにぴったりな果物です。また、こまごまとした果物が置かれたテーブルは、和風の雰囲気を醸し出しており、居心地の良い空間を演出しています。 |
| × | Heron-NVILA-Lite-1B | こたつと言えば、一般的にオレンジが思い浮かびます。この画像では、こたつの上にオランジェットが置かれています。オレンヂは、温かみのある果物として人気があり、特に冬の季節に温かい飲み物として好まれます。また、こだわりのこたつなデザインは、居心地の良さやリラックスした雰囲気を演出するため、家族や友人と一緒に過ごす場面にぴったりです。このように、オレンチーや果物は、日本の伝統的な生活スタイルや家庭の温かさを象徴する要素として、多くの人に愛されています。 |

質問: この場所における制限速度はいくつですか?
| 主観評価 | Model | 回答 |
|---|---|---|
| 〇 | Heron-NVILA-Lite-15B | この場所の制限速度は40キロメートル毎時(40 km/h)です。 |
| × | Heron-NVILA-Lite-2B | この場所の制限速度は23キロメートル/時です。 |
| × | Heron-NVILA-Lite-1B | この場所では、制限速度は23キロメートル/時(約40キロ)です。 |

質問: 左の真ん中あたりには何が書かれていますか?
| 主観評価 | Model | 回答 |
|---|---|---|
| 〇 | Heron-NVILA-Lite-15B | 左の真ん中あたりには「雪舟」と書かれています。 |
| × | Heron-NVILA-Lite-2B | 左の真ん中あたりには「守備」と書かれています。 |
| × | Heron-NVILA-Lite-1B | 左の真ん中あたりには「夢」の文字が書かれています。 |
4件だけですが、〇の数とパラメータ数は比例しており 15 B > 2 B > 1 B で性能差があることがわかります。
おわりに
GENIAC第2期の支援のもと開発したVLM Heron-NVILA を紹介しました。モデルは Hugging Face でダウンロードできるのでぜひ触ってみてください!!!
Heron-NVILA-Lite-2B を搭載した以下のようなiOSアプリも公開予定です。
アプリの解説記事はこちらです。
最後に宣伝ですが、私の所属するチューリングの基盤AIチームは自動運転への活用を目指してVLMや動画生成モデルなどさまざまな基盤AIの開発を行っています。この記事を読んで興味を持っていただけた方は応募検討してもらえると嬉しいです。カジュアル面談やオフィス見学などライトな交流も大歓迎です!!!
詳細についてはチューリングの採用情報をご覧ください。

Discussion