
完全自動運転の実現を目指すTuringでは、Webスケールのデータセットで学習した大規模視覚言語モデル(VLM)の持つ「常識」を利用することで、幅広い状況に対応できる自動運転モデルの開発を実現できると考えています。
この目標のもと、基盤AIチームでは2023年から視覚言語モデル「Heron」の開発に取り組んできました。
VLMを自動運転に活用していく上で重要な要件の一つが「軽量」であることです。Turingでは経済産業省およびNEDOが推進する日本の生成AIの開発力強化に向けたプロジェクト「GENIAC」第2期の支援のもと、2Bパラメタと比較的軽量なVLMの学習に取り組み、モデルサイズに対して非常に高性能な「Heron-NVILA-Lite-2B」の開発に成功しました。
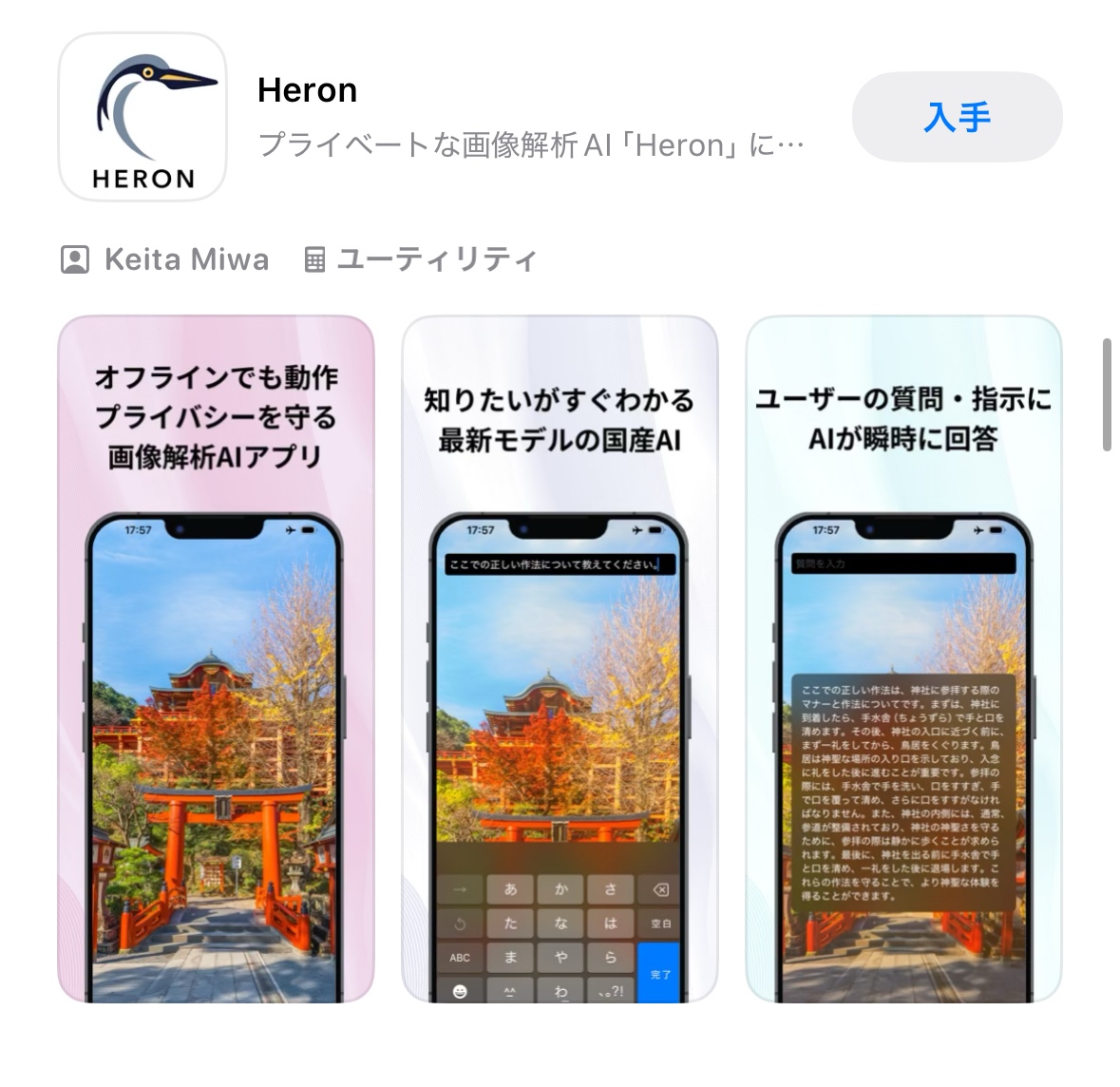
Heron-NVILA-Lite-2Bは軽量であるため、iPhoneのようなモバイル端末のローカル環境でも十分に動作します。そこでこのモデルをローカル環境で動作させ、プライベートな視覚的質問応答を実現するユーティリティアプリを開発し、App Storeで公開しました。
そこで、この記事ではHeron Appの開発について紹介します。
全体構成
こんな感じのアプリができました。

Vision Language Modelの構築
基盤AIチームではGENIAC第2期の支援のもと、VLMであるHeronシリーズの1つとして「NVILA」アーキテクチャを採用した軽量モデルを構築しました。
NVILAはNVIDIAの開発したVLMアーキテクチャで、視覚トークンをダウンサンプリングすることによって高い解像度に由来する精度と少ないトークン数による処理効率を両立させることができます。今回小規模でも性能の高いモデルを開発できた背景には、このNVILAアーキテクチャの採用があります。
今回開発したHeron-NVILA-Lite-2Bは、画像理解用のVision EncoderとしてSigLIPを、言語生成部には1.5BパラメタのQwen2.5-1.5B-Instructを採用した、総計約2BパラメタのNVILAモデルです。視覚特徴はエンコーダ後段の「mlp_downsample_2×2 fix Projector」でダウンサンプリングしてLLMに接続しており、NVILAの特長である「高解像度入力と少ないトークン数の両立」をそのまま活かしています。
学習では一般的な3-Stage Trainingを実施しました。まず日本語の画像キャプションペアやLLaVA-Pretrainなど110万件でProjectorを事前調整し、次に日本語Common Crawl(2024-46/51、2025-05)と各種画像混合データを合わせた3,300万件でLLMとProjectorを同時学習。最終ステージでは日英混在の指示データ110万件を用いてVision Encoderも含めた指示チューニングを行っています。
この結果、Heron-Bench、JA-VLM-Bench-In-the-Wild、JA-VG-VQA-500などの評価ベンチマークで同規模のモデルとしては国内トップクラスの日本語マルチモーダル性能を示しました。対応言語は日本語と英語で、モデルおよび推論コードはApache 2.0ライセンスで公開しています。
詳しくは以下の記事をご覧ください。
llama.cppによるローカル推論
2Bと軽量かつ比較的精度の高いモデルが作れたということで、これをiOSのローカル環境で推論するデモアプリを構築することにしました。iOSのローカル環境で機械学習モデルの推論を行いたい場合はCoreMLやMLXなどの選択肢がありますが、今回は社内にある程度の知見があったllama.cppを利用することにしました。
llama.cppはLLM向けの推論ランタイムです。モデル量子化を行いつつGPUを効率的に利用し、コンシューマー向けGPUでも7B、13Bといった大規模言語モデルの推論を行うことができます。
llama.cppでは公式のサンプルとして、Swift / SwiftUIを用いたLLMのiOSローカル推論デモアプリを提供しています。また、NVILAそのものは実装されていないものの、VLMであるLLaVAやQwen2-VL、Gemma 3といったモデルがサポートされています。
そこで、
- llama.cppでNVILAを実装し
- iOSでNVILAの推論をローカル実行する
- これにSwiftUIなどで構築したインターフェースを被せる
ことができれば、VLMを用いたローカル推論アプリを構築できることがわかります。
開発
実際にVLMを用いたローカル推論アプリを作っていく過程を紹介します。
llama.cppにNVILAを実装する
すでに「構築」で説明しましたが、NVILAは多くのVLMと同様、以下の3つのコンポーネントを持っています。この構成はllama.cppでサポートされているLLaVAなどと同様であるため、基本的にはこれに向けた実装を参考にできます。
- Vision Encoder
- Projector
- Language Model
ほとんどのVLMではVision EncoderとしてCLIPベースの手法が利用されます。NVILAはSigLIPを利用しています。SigLIPは標準的なCLIPと比較してGeLUの利用やアーキテクチャ面のわずかな違いがありますが、幸いどちらもllama.cpp内でサポートされているため、実装を流用することができます。
今回のHeron-NVILA-Lite-2BではLanguage ModelとしてQwen2.5-1.5Bを用いています。Qwen2.5は非常に人気のあるモデルなので、これもllama.cpp内でサポートされています。したがってこちらもそのまま使用できました。
さて、残る問題がProjectorです。ProjectorはVision EncoderとLanguage Modelをつなぐ役割を持つ重要なコンポーネントですが、ここにアーキテクチャ面でのNVILA独自の工夫であるSpatial Token Compressionが導入されています。

CLIPによって得られる表現は、例えば32x32の1024個の画像パッチに対してそれぞれ1152次元のベクトルです。つまり(1024, 1152)サイズの行列がVision Encoderの出力になります。
Spatial Token Compressionでは、もともと32x32で扱っていた画像パッチを、16x16の256個のより「粗いパッチ」に変換します。そうするとそれぞれの粗いパッチの中には4つの32x32粒度のパッチ(1152次元)が含まれることになるので、(256, 4608)サイズの行列が得られます。最後に1層のMLPをかけ、各4608次元のベクトルをLLMの期待する1536次元のベクトルに変換し、(256, 1536)サイズの行列を得ます。
これにより、256個のトークンがVLMの画像トークンということになります。
というわけで、おもに実装する必要があるのはProjectorです。具体的にはllama.cppの推論バックエンドであるGGMLのAPIでProjectorを書いてPyTorchによる実装と出力が一致するようにすればOKです。
GGMLは比較的プリミティブなAPIのみを提供しているため、例えばPyTorchにおけるLinearレイヤはテンソル積に対応するggml_mat_mulとテンソル和に対応するggml_addに分解して書く必要があります。また、テンソルの添字も異なるので、PyTorchの感覚でPermuteなどの操作を行うと非自明な挙動に見舞われることがあります。とはいえ、基本的には必要なAPIは揃っているので、正しく移植すれば動きます。PyTorch実装と出力が整合するかを確かめながら移植作業を進め、数日で適切に動作する移植が完成しました。
llama.cppをSwiftから使う
llama.cppは本家レポジトリがデモアプリケーションを提供しているだけあって、比較的容易にSwiftアプリケーションに組み込むことができます。具体的には、公式リリースに含まれるXCFrameworkをSwift Package Managerで読み込めば完了です。
ただし、残念ながら本家レポジトリのXCFrameworkのビルド設定ではSwift側に橋渡しされるAPIが限定されています。そこでLlava関連の実装のヘッダーを公開するよう変更を加え、Swift側からVLM推論ができるようにしました。C++ InteroperabilityではC++側のオーバーロードをSwift側で解決できないことがあったため一部のコードを書き換えるなどの対応も必要でしたが、全体で半日程度で実装できました。
Xcode Project側では、基本的にはCLIによる推論コードを移植する形で実装を行えます。ほとんどのAPIはシームレスに呼び出せるので、大体の処理は直感的に移植できます。
インターフェースを整える
推論ができたので、あとはインターフェースを整えていく作業です。
インターフェースはSwiftUIを用いて構築します。3つの画面の準備が必要です。
- キャプチャ画面:画面全体にカメラ画像を表示し、撮影を行う
- 質問画面: 撮影した画像に対して質問を入力する
- 回答画面: 質問に対する答えを表示する
iOSでカメラアプリを作る場合はAVFoundationを利用することができます。実装上は以下のレポジトリを参照しつつキャプチャ画面を構築しました。
質問画面、回答画面はiOS 18.4以上で利用できる「Visual Intelligence」の画面を参考に設計します。具体的には、キャプチャボタンを押すとテキストフィールドが現れ、質問をタイプできる、というシンプルな構成です。
デザインを整える
生成AIといえば虹色グラデーションは外せません。Apple Intelligenceもコテコテの虹色グラデーションを採用しています。

とはいえ、やりすぎても目に悪いのも事実です。Heron Appではキャプチャボタンやテキストフィールドの枠線にグラデーションを採用することで慎ましやかにノルマをクリアしました。

加えて、アプリアイコンも必要です。DALL·E 3を用いて作ったHeronロゴをベクタ画像として清書したものを用い、ライトモード、ダークモード、および色合い変更に対応する3種類のアイコンを準備しました。

動作を整える
iOSアプリケーション化ということで、ユーザ体験に配慮した動作の工夫も行いました。
NVILAの推論は一度動き始めれば高速ですが、プロンプトの処理に多少時間がかかるため、生成が始まるまでの遅延(Time-to-First-Token)が大きい傾向にあります。特に、画像部分は256トークンあるため、この部分の処理を待つ時間が遅延のかなりの部分を占めています。
しかし、利用時のフローとしては
- 写真を撮る
- 質問を入力する
- 処理が始まる
- 回答が表示される
となっているので、(1)と(3)の間、システム側には待ち時間が存在します。KVキャッシュを前提にすれば、質問に対するプレフィックスである「質問」「画像」部分については前もって評価しておき、入力された質問だけを後から追加で評価することで、ユーザ側の待ちを減らすことができるはずです。
そこで、今回公開したアプリケーションでは写真を撮ったらすぐに画像部分の評価が開始されるようにしました。ユーザがプロンプトを手入力している間に処理を進めておき、ユーザがプロンプトを送信したらプロンプト部分のみを評価することによって、生成がすぐに始まるようにすることができます。
入力内容が短いなどの理由でシステム側の待ちが短い場合は少し生成開始までに時間がかかることもありますが、基本的にはこのようにすることで体感上の遅延を大きく減らすことができました。
リリースする
もともとはデモアプリとして社内で試して終わる予定でしたが、せっかくなのでリリースすることにしました。自動運転の会社であるTuringにはiOSアプリをリリースする準備は全くなかったのですが、開発支援のメンバーに手伝っていただき、高速に準備を終えることができました。現在は審査を無事に通過し、App Storeで配信されています。
App Store審査にあたり、レビュアーの端末が非常に古いものであるためにアプリが動作せず、ガイドライン2.1の「パフォーマンス」の要件で一度リジェクトを受けました。このため、公開したアプリでは、端末の要件としてハイパフォーマンスなiPhoneにインストールを限定する制約を加えています。この制約はあまり細かく制御することができないため、残念ながらインストールにはiPhone 15 Pro以上が必要となっています。
まとめ
この記事ではTuringの軽量視覚言語モデル「Heron」を用いてローカル動作する視覚質問応答アプリケーションを構築した手順を紹介しました。ソフトウェア資産の積み重ねやオープンウェイトモデルの増加のおかげで、少し前までは困難だった体験の構築がどんどん簡単になっています。Turingとしては今後も軽量VLMに重点を置いて開発を進めていく予定ですので、アプリケーションの動作などもどんどん改善が進められるのではないかと思います。
Heron AppはiOSのApp Storeで配信しています。ぜひインストールしてお試しください。利用にはiPhone 15 Pro以降のApple Intelligence対応端末が必要です。

Discussion