はじめに
TuringのBrain Research teamで頑張ってる井ノ上です。(Twitter: いのいち)
Turingは完全自動運転の開発を目指しており、その実現のためには賢い頭が必要だと考えています。その方法の一つとして、近年の大規模言語モデル(LLM)に見られるような文脈理解力をうまく取り入れられないかと考えており、LLMとVisionの情報をかけ合わせたモデルに注目して研究を行っています。自動運転とVision and languageモデルについては、ぜひこちらの記事を読んでみてください。
今回の記事は2023年7月に開催されたABCI LLMハッカソンで取り組んだときに開発していたGIT-LLMというモデルの開発について解説する記事となっています。途中のコードの解説部分などは少し退屈に感じるかもしれませんので、その場合はぜひ結果のパートだけでも見てみてください。いろいろ実験や解析をしましたので、こんなことができるのかと楽しんでもらえるかと思います。
実装は公開していますので、ぜひ動かしてみてください。
GITをLLM化する
それでは今回のテックブログの本題に入っていきましょう。
GITとは?
Generative Image-to-text Transformer、GITはMicrosoftから提案されたVision and languageモデルです。
構造は非常にシンプルで、画像エンコーダから抽出した特徴ベクトルをProjectionモジュールでテキストと同じように扱えるベクトルに変換し、テキストベクトルと一緒に言語モデルに入力して画像に対するキャプションやQ&Aを行うモデルとなります。動画もほぼ同じように扱うことができます。
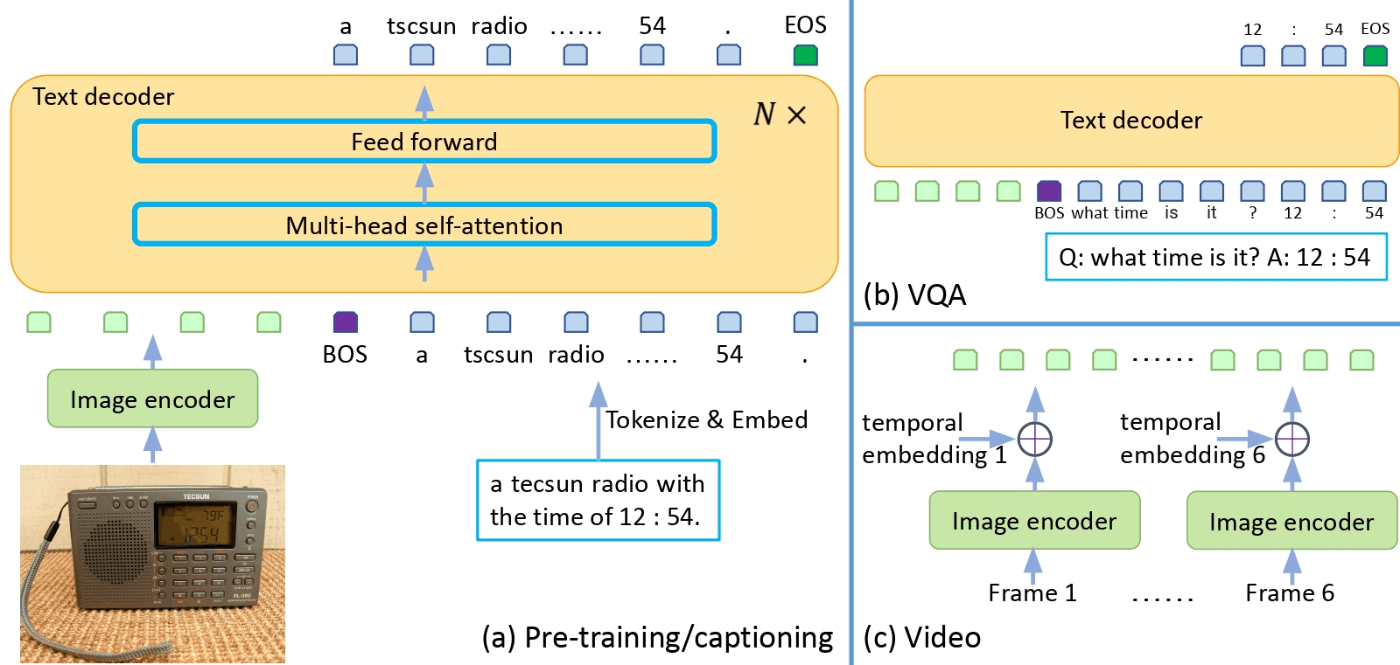
単純な構造ですが、Paper with codeのLeaderboardを見てみますと多くのタスクで上位にランクインしていることがわかります。
もともとGITは画像エンコーダにCLIPなどで学習された強いモデルを使用し、言語モデルの部分はスクラッチから学習させるという手法でもあります。しかし、今回はあえて言語モデルの部分にもとても強いLLMを用いてFinetuningさせてみようと思います。
TransformersでLLMを使う
今回の実装では、ライブラリはHuggingfaceのTransformersを使います。Transformersは、機械学習のモデルを扱うためのPythonのライブラリです。最先端の学習済みモデルも多数上がっているのですぐに推論させて試すこともできますし、訓練するためのツールも提供されているのでFinetuningなども簡単に行うことができます。Transformersは近年のLLMの派生モデルの開発にも大きく貢献していると思っています。公開されているほぼすべてのLLMはTransformersで扱えますし、そこから派生したマルチモーダルモデルもTransformersをベースに開発されてFinetuningを行っているものが多く感じます。
それでは実際にTransformersを使ってLLMの一つであるOPTを動かしてみましょう。推論で動かすだけならとても簡単で、以前のテックブログ「実践!大規模言語モデル / 1000億パラメータ越えモデルを動かすには? - 4.b.-bloom-1bを動かしてみる」で紹介しています。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "facebook/opt-350m"
model = AutoModelForCausalLM.from_pretrained(model_name).to("cuda")
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Hello, I'm am conscious and"
input_ids = tokenizer(prompt, return_tensors="pt").to("cuda")
sample = model.generate(**input_ids, max_length=64)
print(tokenizer.decode(sample[0]))
# Hello, I'm am conscious and I'm a bit of a noob. I'm looking for a good place to start.
OPTのモデルがどういうパラメータを持っているかを確認してみましょう。
OPTForCausalLM(
(model): OPTModel(
(decoder): OPTDecoder(
(embed_tokens): Embedding(50272, 512, padding_idx=1)
(embed_positions): OPTLearnedPositionalEmbedding(2050, 1024)
(project_out): Linear(in_features=1024, out_features=512, bias=False)
(project_in): Linear(in_features=512, out_features=1024, bias=False)
(layers): ModuleList(
(0-23): 24 x OPTDecoderLayer(
(self_attn): OPTAttention(
(k_proj): Linear(in_features=1024, out_features=1024, bias=True)
(v_proj): Linear(in_features=1024, out_features=1024, bias=True)
(q_proj): Linear(in_features=1024, out_features=1024, bias=True)
(out_proj): Linear(in_features=1024, out_features=1024, bias=True)
)
(activation_fn): ReLU()
(self_attn_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(final_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
)
)
)
(lm_head): Linear(in_features=512, out_features=50272, bias=False)
)
とてもシンプルですね。最初のembed_tokensの入力次元と最後のlm_headの出力次元が50,272となっていますが、これはこのモデルの学習に使用したTokenの種類の数を表しています。Tokenizerのボキャブラリーサイズを確認してみましょう。
print(tokenizer.vocab_size)
# 50265
特殊なトークンであるbos_token, eos_token, unk_token, sep_token, pad_token, cls_token, mask_tokenの7種類も含めた合計50,272種類のトークンの中から次の単語の確率を予測します。
これらのモデルがどのようにつながっているかは実装を見ればわかります。簡単に図示すると以下のようになります。

構造やデータの流れ自体はとてもシンプルになっています。〇〇Modelと〇〇ForCausalLMは他の言語モデルでも同じような枠組みになっています。〇〇Modelのクラスは主に言語モデルのTransformerの部分でで、例えば文章分類など別タスクを行う場合はここだけを使用します。〇〇ForCausalLMのクラスは文章生成用のクラスで、Transformerにかけた後のベクトルに対してトークン数のクラス分類器がついたものになります。Lossの計算もこのクラスのfowrard内で行います。embed_positionsはポジショなるエンコーディングで、project_inに加算しています。
GITをTransformersで使う
GITの公式ドキュメントページを参考に動かしてみます。画像の処理も一緒に行うため、Tokenizerも含んだProcessorを使用していきます。
from PIL import Image
import requests
from transformers import AutoProcessor, AutoModelForCausalLM
model_name = "microsoft/git-base-coco"
model = AutoModelForCausalLM.from_pretrained(model_name)
processor = AutoProcessor.from_pretrained(model_name)
# 画像のダウンロードと前処理
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
pixel_values = processor(images=image, return_tensors="pt").pixel_values
# テキストの前処理
prompt = "What is this?"
inputs = processor(
prompt,
image,
return_tensors="pt",
max_length=64
)
sample = model.generate(**inputs, max_length=64)
print(processor.tokenizer.decode(sample[0]))
# two cats sleeping on a couch
入力画像がこちらの画像で出力が「two cats sleeping on a couch」なのでうまく動いていることがわかります。
それではこちらも同じくモデルの構造を見ていきましょう。
GitForCausalLM(
(git): GitModel(
(embeddings): GitEmbeddings(
(word_embeddings): Embedding(30522, 768, padding_idx=0)
(position_embeddings): Embedding(1024, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(image_encoder): GitVisionModel(
(vision_model): GitVisionTransformer(
...
)
)
(encoder): GitEncoder(
(layer): ModuleList(
(0-5): 6 x GitLayer(
...
)
)
)
(visual_projection): GitProjection(
(visual_projection): Sequential(
(0): Linear(in_features=768, out_features=768, bias=True)
(1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
)
)
(output): Linear(in_features=768, out_features=30522, bias=True)
)
こちらは少し長いですが、分解してみると単純です。GitForCausalLMの中にGitModelがあって、さらにその中に以下のモジュールがあります。
- embeddings(GitEmbeddings)
- image_encoder(GitVisionModel)
- encoder(GitEncoder)
- visual_projection(GitProjection)
- output(Linear)
OPTとの大きな違いはGitVisionModelとGitProjectionがあることで、これがまさに画像をプロンプトライクなベクトルに変換しているモジュールになります。言語モデルの方でOPTはDecoderでGITはEncoderとありますが、これはAttention maskの作り方の違いを表しているだけで、Transformer layerの微妙な違いはあれど機能としては同じです。GITの方では画像の特徴に対してはすべてAttentionをかけてテキスト特徴量の方にCausal maskを使用するという特殊なAttention maskを使用するためEncoderという名前を使っていると思われます。
モデルのつながりを見てみましょう。

画像の情報をGitVisionModelとGitProjectionでテキストのEmbeddingsと同じ形にしています。その後は言語モデルのTransformerのLayerにテキストのEmbeddingsと並んで入力されています。微妙な違いこそあれど、言語モデルのところはほぼ同じような形をしています。
GITのAttention mask
通常の言語モデルとGITの言語モデルの部分はアーキテクチャはほぼ同じような形ですが、Attention maskのかけ方が違います。
言語モデルの場合は、未来のトークンを予測するために過去のトークンはみないようにAttention maskをかけます。Causal Attentionと呼ばれる方法で図の左側に相当します。1列目のトークンは自身だけを参照しており以降の単語に対してはSelf Attentionがかからないように0になっています。2列目は2単語目まででSelf Attentionを行い、3単語目以降は0になっています。このようなマスクをかけることでうまく次の1単語を予測できるように学習しています。
GITの入力には画像トークンとテキストトークンがあります。画像トークンは次の1トークンを予測するのではなく同時に入力されるので、Causal Attentionは適切ではありません。一方で、テキストトークンに対してはCausal Attentionを適用したいです。それを実現するために図の右側のようなマスクを設計しています。上3列の画像情報に対しては、すべてのトークン情報を含めたSelf Attentionを行い、テキストトークンからは1列下に進むたびに1単語ずつ参照できる単語を増やしていきます。

コードでも確認してみましょう。GITのマスクを作成するためのスニペットはこのようになります。
import torch
def create_git_attention_mask(
tgt: torch.Tensor,
memory: torch.Tensor,
) -> torch.Tensor:
num_tgt = tgt.shape[1]
num_memory = memory.shape[1]
# Attentionをかける部分は0, かけない部分は-inf
top_left = torch.zeros((num_memory, num_memory))
top_right = torch.full(
(num_memory, num_tgt),
float("-inf"),
)
bottom_left = torch.zeros(
(num_tgt, num_memory),
)
# Causal Attention Mask
bottom_right = torch.triu(torch.ones(tgt.shape[1], tgt.shape[1]), diagonal=1)
bottom_right = bottom_right.masked_fill(bottom_right == 1, float("-inf"))
# Concatenate masks
left = torch.cat((top_left, bottom_left), dim=0)
right = torch.cat((top_right, bottom_right), dim=0)
# add axis for multi-head
full_attention_mask = torch.cat((left, right), dim=1)[None, None, :]
return full_attention_mask
# batch_size, sequence, feature_dim
visual_feature = torch.rand(1, 3, 128)
text_feature = torch.rand(1, 4, 128)
mask = create_git_attention_mask(tgt=text_feature, memory=visual_feature)
print(mask)
"""
tensor([[[[0., 0., 0., -inf, -inf, -inf, -inf],
[0., 0., 0., -inf, -inf, -inf, -inf],
[0., 0., 0., -inf, -inf, -inf, -inf],
[0., 0., 0., 0., -inf, -inf, -inf],
[0., 0., 0., 0., 0., -inf, -inf],
[0., 0., 0., 0., 0., 0., -inf],
[0., 0., 0., 0., 0., 0., 0.]]]])
"""
MaskをQueryとKeyから作成したAttention weightに足します。なので、0の部分がSelf Attentionを行うところで、-infの部分がAttentionに含めない部分になります。このMaskをforwardで与えてあげることでテキストの部分だけCausal Attentionをできるようになります。このようにVison and languageモデルではMaskをうまく使うのも一つの鍵になってきます。
GITとOPTをつなげる
それではGITとOPTをつなげていきましょう。図のようなモデルを作るのが目標になります。

大枠の実装についてはTransformersのmodeling_git.pyが参考になります。
一番重要になってくるのがGitOPTModelの部分です。この中でVisionEncoderとLLMをつなげる必要があります。この中身の大事な部分を少し説明します。
class GitOPTModel(OPTModel):
def __init__(self, config: OPTConfig):
super(GitOPTModel, self).__init__(config)
self.image_encoder = CLIPVisionModel.from_pretrained(config.vision_model_name)
self.visual_projection = GitProjection(config)
self.embed_positions = OPTLearnedPositionalEmbedding(
config.max_position_embeddings, config.hidden_size
)
初期化関数の中で各種モジュールをインスタンス化しています。superではOPTModelの初期化を行っています。GITではCLIPで学習された強い画像バックボーンを使うことが勧められているので、CLIPで学習されたViTを使えるようにしています。GitProjectionについては、オリジナルのGITの実装から持ってきています。学習可能なPositional Encoddingの部分は、OPTの実装に従ってここでインスタンス化しています。
次にForwardの中身を見ていきましょう。実装に関してはOPTDecoderのforward部分をベースに画像エンコーダの情報を足していきます。少し長いですが、コード内にコメントを書いたのでぜひ1つづつ追ってみてください。
class GitOPTModel(OPTModel):
...
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
pixel_values: Optional[torch.Tensor] = None,
) -> BaseModelOutputWithPooling:
seq_length = input_shape[1]
# 1. ViTで画像特徴量の抽出
visual_features = self.image_encoder(pixel_values).last_hidden_state
# 2. ViTで抽出した特徴量をプロンプトライクなImage Embeddingsに変換
projected_visual_features = self.visual_projection(visual_features)
# 3. トークンのベクトル化
inputs_embeds = self.decoder.embed_tokens(input_ids)
# 4. Positional Encodingの取得
pos_embeds = self.embed_positions(attention_mask, 0)
# 5. OPT特有のText Embeddingsの次元調整
inputs_embeds = self.decoder.project_in(inputs_embeds)
# 6. Text Embeddings + Positional Encoding
embedding_output = inputs_embeds + pos_embeds
# 7. 画像のEmbeddingsとText Embeddingsを結合
hidden_states = torch.cat((projected_visual_features, embedding_output), dim=1)
# 8. Text領域用のCausal Attention Maskの作成
tgt_mask = self._generate_future_mask(
seq_length, embedding_output.dtype, embedding_output.device
)
# 9. GIT用のAttention Maskの作成
combined_attention_mask = self.create_attention_mask(
tgt=embedding_output,
memory=projected_visual_features,
tgt_mask=tgt_mask,
past_key_values_length=0,
)
# 10. Decoder layerに繰り返し通す、言語モデルのメイン部分
for idx, decoder_layer in enumerate(self.decoder.layers):
layer_outputs = decoder_layer(
hidden_states,
attention_mask=combined_attention_mask,
output_attentions=output_attentions,
use_cache=use_cache,
)
hidden_states = layer_outputs[0]
# 11. OPTに特有の次元調整MLP
hidden_states = self.decoder.project_out(hidden_states)
# 12. Outputのインターフェースを揃える
return BaseModelOutputWithPast(
last_hidden_state=hidden_states,
past_key_values=next_cache,
hidden_states=all_hidden_states,
attentions=all_self_attns,
)
複雑に見えますが、処理を順番に確認していくと絵に書いたとおりの流れになっていることがわかると思います。実際はもう少しコードが複雑に見えますが、メインの処理をまず抑えておくことで他の部分も理解しやすくなると思います。こちらは疑似コードなので細かい部分は公開した実装を見てください。
最後にGitOPTForCausalLMの部分を少しだけみていきましょう。
class GitOPTForCausalLM(OPTForCausalLM):
def __init__(
self,
config,
):
super(GitOPTForCausalLM, self).__init__(config)
self.model = GitOPTModel(config)
def forward(
...
) -> CausalLMOutputWithPast:
outputs = self.model(
...
)
sequence_output = outputs[0]
logits = self.lm_head(sequence_output)
loss = None
if labels is not None:
# タスクとして次の単語を予測します
num_image_tokens = self.image_patch_tokens
shifted_logits = logits[:, num_image_tokens:-1, :].contiguous()
labels = labels[:, 1:].contiguous()
loss_fct = CrossEntropyLoss()
loss = loss_fct(shifted_logits.view(-1, self.config.vocab_size), labels.view(-1))
return CausalLMOutputWithPast(
loss=loss,
logits=logits,
...
)
ここでは最後のトークン予測を行う全結合層のlm_headが追加されています。forwardの中身もモデルの処理はシンプルです。labelsが与えられたとき、つまり訓練のときはlossの計算もforward中で行います。shifted_logitsでは、テキストトークンの1トークン目から最後から2番めのトークンまでをとってきており、それを1単語ずらしたlabelsを正解としてCross Entropy Lossを計算しています。
一つ注意点としては、初期化関数のときにGitOPTModelを代入する変数名をself.modelにすることです。親クラスののOPTForCausalLMの実装を確認するとわかるのですが、superの初期化の中で一度OPTをself.modelに入れています。このインスタンス変数名を変えてしまうと2重にOPTを持ってしまうことになりメモリを圧迫してしまうので注意が必要です。
LoRA拡張
LLMをFinetuningするためにParameter-Efficient Fine-Tuning (PEFT)というライブラリを使用していきます。HuggingFaceが開発しているのでtransformersとの相性もよく、とても簡単に組み込むことができます。PEFTの中でもいくつか手法がありますが、今回はよくみかけるLow-rank adaptation(LoRA)という方法でFinetuningを試してみようと思います。
transformersで作ったモデルは、PEFTに対応しているものだとほんの数行でLoRA化できます。
from transformers import AutoModelForCausalLM
from peft import get_peft_config, get_peft_model, LoraConfig
model = AutoModelForCausalLM.from_pretrained('microsoft/git-base')
peft_config = LoraConfig(
task_type="CAUSAL_LM",
r=8,
lora_alpha=32,
lora_dropout=0.1,
target_modules=["v_proj"]
)
peft_model = get_peft_model(model, peft_config)
target_modulesの引数にLoRA化したい対象のモジュールを指定します。リストで渡した場合は、それぞれの文字列で終了するモジュールの場合はLoRA化するというように実装されています。文字列はState Dictで保存したときのKeyの文字列に相当します。
今回作成しているモデルでは画像エンコーダの部分にもViTを用いており、このように指定するとViTのSelf Attention部分もLoRA化されてしまう場合があるので注意が必要です。少々面倒ですが、Keyの名前がかぶらない部分まで細かく指定してtarget_modulesに与えると回避できます。
target_modules = [f"model.decoder.{i}.self_attn.v_proj" for i in range(len(model.model.decoder))]
このようにして得られたモデルはPeftModelForCausalLMというclassのインスタンスになっています。元のモデルをLoRA化したbase_modelという名前のインスタンス変数を持っています。LoRA化されたモジュールは以下のようになっています。
(self_attn): GitVisionAttention(
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(
in_features=768, out_features=768, bias=True
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=768, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=768, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
v_projのLinearの中にlora_A、lora_Bという全結合層などが追加されています。LoRA化されたLinearモジュールはPytorchのLinearとLoraLayerを継承した同名のLinear classで、ちょっと特殊なモジュールなので詳細が気になる方は実装を読んでみてください。
注意点として、PEFTで作成したモデルはそのままではLoRA部分しか保存されません。merge_and_unloadメソッドを使用してから保存する方法もありますが、Trainerで学習している途中で保存されるモデルもすべて保存したいです。Trainerの_save_checkpointsメソッドをオーバラードする方法もありますが、面倒なので学習の段階からPeftModelの中で保持しているもともとのモデルの部分だけを取ってくる方法で今回は対応しました。
model = get_peft_model(model, peft_config)
model.base_model.model.lm_head = model.lm_head
model = model.base_model.model
ここについてはもっと上手いやり方があると思うので研究中です。
GIT-LLMで実験する
それではここまでで作成したモデルを使っていくつか実験をしてみようと思います。
学習の設定方法などについては公開した実装と、こちらの記事がほとんど同じやり方ですので参照してください。
Dataset: M3IT
今回の実験のために画像とテキストのペアになっていて簡単に使えるデータを使いたいと思います。HuggingfaceのDatasetsからMultimodal Image-to-TextをみているとM3ITという上海AIラボが作成したマルチモーダルのInstruction Tuningのデータセットがありました。Instruction Tuningは少量のデータでも非常に強力な結果が出る手法です。M3ITは様々な既存のデータセットをInstruction Tuning用に再アノテーションしたデータセットのようです。
MMInstruction/M3IT · Datasets at Hugging Face
Documentのページにあるとおりで使用方法もとても簡単ですので、こちらのデータセットを使っていこうと思います。
M3ITを使って学習するために、カスタムのPytorch Datasetを作成する必要があります。
class SupervisedDataset(Dataset):
def __init__(
self,
vision_model_name: str,
model_name: str,
loaded_dataset: datasets.GeneratorBasedBuilder,
max_length: int = 128,
):
super(SupervisedDataset, self).__init__()
self.loaded_dataset = loaded_dataset
self.max_length = max_length
self.processor = AutoProcessor.from_pretrained("microsoft/git-base")
# それぞれのモデルに対応したProcessorを入れる
self.processor.image_processor = CLIPImageProcessor.from_pretrained(vision_model_name)
self.processor.tokenizer = AutoTokenizer.from_pretrained(
model_name, padding_side="right", use_fast=False
)
def __len__(self) -> int:
return len(self.loaded_dataset)
def __getitem__(self, index) -> dict:
# cf: https://huggingface.co/datasets/MMInstruction/M3IT#data-instances
row = self.loaded_dataset[index]
# textの入力の作成
text = f'##Instruction: {row["instruction"]} ##Question: {row["inputs"]} ##Answer: {row["outputs"]}'
# imageのロード
image_base64_str_list = row["image_base64_str"] # str (base64)
img = Image.open(BytesIO(b64decode(image_base64_str_list[0])))
inputs = self.processor(
text,
img,
return_tensors="pt",
max_length=self.max_length,
padding="max_length",
truncation=True,
)
# batch size 1 -> unbatch
inputs = {k: v[0] for k, v in inputs.items()}
inputs["labels"] = inputs["input_ids"]
return inputs
初期化関数の中でimage_processorとtokenizerはそれぞれのモデルに対応したものを持たせるようにしています。引数に渡すload_datasetはhuggingface datasetsのMMInstruction/M3ITから作ったものになります。
coco_datasets = datasets.load_dataset("MMInstruction/M3IT", "coco")
test_dataset = coco_datasets["test"]
cocoのInstruction Tuning用のデータセットは、訓練、検証、テストの分割方法は元のデータセットと同じなので、566,747枚、25,010枚、25,010枚ずつ画像-テキストペアがあります。他にもVQAやVideoのデータセットも同じように扱えるので検証用として使い勝手が良いデータセットだと思っています。
サンプルのデータはこのようになっています。

##Instruction: Write a succinct description of the image, capturing its main components, the relationships between them, and any notable details. ##Question: ##Answer: A man with a red helmet on a small moped on a dirt road.
cocoのデータセットはCaptionなので、Questionの部分は空欄になっています。
processorでの処理について見ていきましょう。基本的には画像の正規化とテキストのトークンかを行っています。その他にもmax_lengthに満たない語数の入力データはPaddingされるように設定しています。processorで処理したデータは辞書型で返されて以下の値を持ちます。
- input_ids: トークン化されたテキストの配列
- attention_mask: トークン化されたテキストに対するマスク(Paddingが0)
- pixel_values: 正規化された画像のアレイ。Channel firstにも変換されている。
このキーの名前はモデルのforward関数の引数に対応していますので、変更してはいけません。最後にlabelsというキーにinput_idsをそのまま渡します。GitOPTForCausalLMのforward関数の中でlossを計算するときに1単語ずらした次単語予測をするようにしています。なので個々ではそのまま渡しています。
実験1: どこをFinetuningするか
GITのモデルの学習について、論文では強いVision Encoderを用いて言語モデルの方はランダムなパラメータを使うと説明されていました。今回は最終的に7Bクラスの言語モデルを使用したいので言語モデルにも事前学習されたモデルを使用します。Finetuningの検討場所として以下の4つを検証してみます。GIT Projectionは初期化したモジュールなので必ず入れています。多少、意味のない組み合わせもありますが今回は試しにということで気にせず組み合わせています。
- Vision Encoder
- Head(lm_head)
- OPT
- LoRA
学習するモジュールは勾配をもたせて、それ以外は勾配を持たないように変更しました。
# 学習するパラメータを指定する (全部学習するとメモリが大きくなる)
for name, p in model.model.named_parameters():
if np.any([k in name for k in keys_finetune]):
p.requires_grad = True
else:
p.requires_grad = False
Vision EncoderとLLMは以下のものを使用して検証を行いました。
- openai/clip-vit-base-patch16
- facebook/opt-350m
訓練はcocoの訓練データを使用し、5エポック学習しています。

まず訓練Lossを見たところ、うまく行ってないグループがあることがわかります。これはOPTも学習に含めたケースでした。今回はすべての実験を極力条件を揃えて行いましたが、言語モデル部分をFinetuningするにはやはり学習率など細かい条件の調整が必要かもしれません。検証データでもOPTを学習に含めたものはうまく行っていなかったのでそれを除いた結果を見ていきましょう。


訓練Loss、検証Lossともに最も下がったのはProjection+LoRAのモデルでした。最終層のHeadの部分はどちらでもほぼさはなかったです。ViTも学習させた場合、Lossは少し高めで不安定な結果になっています。ViT学習時にLoRAを加えても少しLossが高めに出てしまっているので、今回のデータにおけるFinetuningの時は事前学習させたモデルはパラメタを更新しないほうが安定した結果が出るようです。LoRAの有効性は各所で聞きますが、今回もLoRAを足すことでLossの下がりは良くなったことがわかりました。
いくつかテストデータに対して推論させた結果を見てみましょう。

OPT自体も学習させたものはLossと同じく悪い結果で、言葉を失ってしまいました。さらに、ViTを学習させたものも意味としては通る文章になっていますが与えた画像とは全く違うことを言っています。その他の結果については少なくとも画像の特徴を捉えた表現になっていると思います。1枚目だと「猫」と「バナナ」が入っていますし、2枚目だと「交通標識」があるというあたりは認識できているようです。LoRAの有無で結果を比較しますと、LoRA無しだと同じような単語を繰り返してしまっていますが、LoRAをつけることでほんの少し自然になっている気がします。Headを学習させると最初の画像だとeatingではなくplayingを使ったりと他とは違った雰囲気の結果になっているのも興味深いところです。これらの結果の細かいところを見ると不自然な部分もありますが、とりあえず学習がうまくいって映像の特徴を捉えられるようになったと思います。
実験2: ビリオン級モデルの比較
Finetuningの条件検討では条件検討で複数実験をまわすためにOPT-350mという少し小さめの言語モデルを使用しました。今度は言語モデルの部分を7Bのモデルに変更しましょう。OPTだけだと物足りないのでLLaMAとMPTも追加しましょう。
これら2つのモデルを組み込むのはOPTと同じようにできます。LlamaModelとMPTModelのforward関数部分を参考にProjectionされた画像ベクトルをテキストトークンと組み合わせて、MaskをCausal Attention MaskからGITのAttention Maskに変更します。注意点としては、MPTはMaskが(0, -inf)ではなく(False, True)なところくらいです。後の処理の流れはほぼ同じように実装できると思います。
OPTで7Bクラスのモデルを使うには、モデル名をfacebook/opt-350mからfacebook/opt-6.7bに変更するだけでOKです。
LLaMAに関しては、ちょうどLLaMA2が使えるようになったのでそちらを使っていこうと思います。こちらの事前学習モデルを使うためには、Metaでの申請とHuggingfaceでの申請の2つが必要です。Huggingfaceで申請するためにはアカウントが必要ですので用意しておきましょう。どちらの申請も数時間で許可されると思います。その後、学習を実行するTerminal上でHuggingfaceにログインします。
huggingface-cli login
Huggingfaceのアカウント→Settings→Access Tokenで作成したトークンでログインすることができます。
学習の条件は、データは同じくcocoを使用します。訓練数は3エポックです。Finetuningする場所については、実験1の結果からProjection+LoRAにしました。
結果を見ていきましょう。


Lossの結果はLLaMA2とMPTをLLMとして使用したモデルの方がいい感じで下がっていることがわかります。推論結果も見てみましょう。

1枚目に関してはどのモデルに関してもOPT-350mよりも自然な表現になっているように感じます。「a banana with a banana」のような謎な表現もなくなっており、LLMの強さを感じます。2枚目に関しては、やはりまだ少し難しいようで「a traffic light」や「a building」など微妙な表現も入ってきているように感じます。このように複雑な画像の場合は、ViTの方をより大きなモデルにするといった工夫が必要ではないかと考えています。
次に、GPT-4で話題になった画像に対しても推論してみます。

LLMを使っているので流暢に話してくれるかなと期待しましたが、シンプルな返答になってしまいました。これはcocoだけで学習しているからかかもしれません。
実験3. データを増やす
最後の結果が微妙だったこともあり、coco以外のデータも加えて学習をしてみようと思います。今回使用しているM3ITはとても優秀なデータセットで、同じ形式でcoco以外にもかなり多くのデータを扱うことができるようになっています。

M3IT: A Large-Scale Dataset towards Multi-Modal Multilingual Instruction TuningのTable 3より引用
こちらのChineseとVideo以外のデータを使っていきたいと思います。もともとのcocoの訓練データセットサイズが566,747件データがあったのに対して、混ぜ合わせることで1,361,650件になりました。サイズ的には2倍程度ですが、タスクの多様性もかなり増えるのでより良質なデータセットになっていると考えられます。
複数のPytorchのDatasetを扱う方法は、ConcatDatasetを使うことで簡単に実現できます。
dataset_list = [
datasets.load_dataset("MMInstruction/M3IT", i) for i in m3it_name_list
]
train_dataset = torch.utils.data.ConcatDataset([d["train"] for d in dataset_list])
訓練数は1エポックで、モデルはLLaMA2を使用してFinetuningする場所は実験2と同じようにProjectionとLoRAを対象にしました。
今回はLossの比較対象がないのでさっそく推論結果を見ていきましょう。



これまでの簡単な問題に加えて、より複雑な問題も解けるようになりました。キャプションだけじゃなくより複雑なタスクのデータセットを足すことで一気にできることが広がりました。学習を1エポックしか行っていないのにこの精度が出るのは驚きでした。
最後に例の画像も試してみましょう。データセットの種類が多様化したこともあり、質問の与え方も少しだけ工夫して渡してみました。

「Umbrella」なのが惜しいですが、かなりそれっぽい説明になってきたと思います。ここからさらに良くするには、学習のエポック数を増やす、データセットの種類や量を増やす、ViTやLLMをより強力なものにする必要があるかと思います。しかし、半日程度の学習でこのくらいのモデルが作れたので計算機とデータがあればまだまだ強力なモデルも作れそうだなという所感はあります。
おまけ実験. 画像は言葉になったのか?
GITの構造をもう一度見てみましょう。

図の通り、画像はVision Encoderで特徴抽出した後にVisual Projectionによってベクトル化されたテキストと同列に扱われていることがわかります。言い換えるならば、Visual Projectionは画像ベクトルをテキストベクトルに変換しているのではないかとも考えられます。実際にVisual Projectionの後のベクトルがどうなっているのかを調べてみました。
Projection後のベクトルからテキストに戻す方法としてHeadを使うという方法もありますが、調べてみたところHeadを使う方法だとEmbeddingモジュールでベクトル化したベクトルですら元のテキストに戻すことはできませんでした。なので、LLMに入力する前のテキストベクトルに近いものを該当する単語として割り当てられるようにしましょう。まずTokenizerに登録されているトークンをEmbeddingモジュールですべてベクトル化し、そのベクトルのCosine類似度が最も大きいものを目的の単語としました。
使用するのはこちらの猫の画像です。

それでは実際に解析していきましょう。まずは登録されているトークンをすべてベクトル化します。
coco_datasets = datasets.load_dataset("MMInstruction/M3IT", "coco")
test_dataset = coco_datasets["test"]
supervised_test_dataset = SupervisedDataset(model_name, vision_model_name, test_dataset, 256)
ids = range(supervised_test_dataset.processor.tokenizer.vocab_size)
all_ids = torch.tensor([i for i in ids]).cuda()
token_id_to_features = model.model.embed_tokens(all_ids)
次に、ViTとProjectionで単語化されたであろう画像ベクトルを抽出します。
inputs = supervised_test_dataset[0] # てきとうにサンプルを取ってくる
pixel_values = inputs["pixel_values"]
out_vit = model.model.image_encoder(pixel_values).last_hidden_state
out_vit = model.model.visual_projection(out_vit)
このベクトルと単語ベクトルの内積を計算し、最大値のものを該当トークンIDとしてデコードしてみましょう。
# Dot product
nearest_token = out_vit[0] @ token_id_to_features.T
# 最大値のインデックスが該当トークンID
visual_out = nearest_token.argmax(-1).cpu().numpy()
decoded_text = supervised_test_dataset.processor.tokenizer.batch_decode(visual_out)
print(decoded_text)
"""
['otr', 'eg', 'anto', 'rix', 'Nas', ...]
"""
何やら意味のわからない単語が出てきました。いくつか同じ単語も出ているのでカウントしてみましょう。
print(pd.Series(decoded_text).value_counts())
"""
mess 43
atura 29
せ 10
Branch 10
Enum 9
bell 9
worden 7
...
"""
どうやらよくわからない単語がたくさん出てきているようです。場所に応じてなにか意味のある情報が出てくるかもしれません。単語を図に照らし合わせてプロットしてみましょう。
n_patches = 14
IMAGE_HIEGHT = 468
IMAGE_WIDTH = 640
y_list = np.arange(15, IMAGE_HIEGHT, IMAGE_HIEGHT//n_patches)
x_list = np.arange(10, IMAGE_WIDTH, IMAGE_WIDTH//n_patches)
plt.figure()
plt.axis("off")
plt.imshow(np.array(image), alpha=0.4)
for index in np.arange(n_patches ** 2):
y_pos = index // n_patches
x_pos = index - y_pos * n_patches
y = y_list[y_pos]
x = x_list[x_pos]
# 1 token目はbos tokenなので除く
word = decoded_text[index + 1]
# 単語ごとに色分けする場合はここで場合分け
plt.annotate(word, (x, y), size=7, color="blue")
plt.show()
plt.clf()
plt.close()

頻出している単語で少し色分けしています。結果としては「よくわからないが、意味のある単語に単純に投射されているわけではなさそう」ということがわかりました。「Cat」が猫にかぶっているおかげでなんとかそれっぽさは出たかもしれませんが、意味があるかは不明です。
今回よくわからない結果になったのは、Cosine類似度が大きい単語を無理やり1つ決めて取ってきているからかもしれません。いずれにせよ、単純に単語にキャストして画像プロンプトを作っているわけではないということです。画像から抽出されたベクトルはVisual Projectionによってトークン空間上のなにかしらそれっぽい意味を持つようなベクトルに変換されて、それが謎プロンプトとして機能しているようです。これ以上深追いするのはやめておきましょう。
まとめ
今回のテックブログではVision and languageモデルのGITをLLM化する方法について紹介しました。さらに、作成したモデルを使っていろいろな実験を行ってみました。うまくいったもの、いかなかったもの両方ありましたが、今後もVision and languageモデルで様々な実験を行って知見をためていきたいと思っています。この記事を参考にぜひ自分だけのVision and languageモデルを作成していろいろと遊んでみてください。
また、今回は単純なVision and languageモデルのタスクでしたが、自動運転に絡めたおもしろいタスクも現在取り組んでいるところです。学習に必要な計算リソースも潤沢になりつつあるし、大規模で計算するための技術もかなり研究しています。少しでも興味がある人はTwitter経由でもTuringのWebページ経由でもいいので、ぜひ気軽にお話を聞きに来てください。


Discussion