こんにちは。Turing株式会社の機械学習チームでインターンをしている九州大学修士1年の岩政(@colum2131)です。
Turingは完全自動運転EVの開発をするスタートアップです。
自動運転技術において、カメラやセンサ情報は正確な制御をする上で不可欠な要素である一方、自然言語やマルチモーダルな処理が必要となる状況もしばしば存在します。特に完全自動運転車においては、音声認識によってドライバーの音声命令を認識し、リアルタイムで適切な制御を行うことや、複雑な交通状況の背景にあるコンテクストを理解させるといった要求が出てきます。そのために、「基盤モデル」と呼ばれるような、自然言語処理を含む大規模モデルの学習が必要になってくると、私たちは考えています。
そこで本記事では、言語モデルの発展の流れとTuringが目指す基盤モデルの開発について紹介します!
1. 言語モデルとは?
近年の言語処理モデルにおいて、大規模なテキストデータを事前学習したニューラルネットワーク(NN)が幅広いタスクで非常に高い精度を達成しています。これらのモデルは身近なところに使われており、機械翻訳や文章の要約、ChatGPTを始めとするチャットボットなどがあります。
この言語モデルは急速に発達しています。要因はいくつもあり、中でも従来のNNの構造より画期的な構造であったTransformerの提案と、大規模なテキストデータを人がラベル付けを行わずに学習する自己教師あり学習による事前学習とタスクに合わせた比較的少数のデータでの学習(ファインチューニング)の流れの確立が主要であるように思います。
もしTrasnformerが気になる方がいれば「【深層学習】Transformer - Multi-Head Attentionを理解してやろうじゃないの【ディープラーニングの世界vol.28】(https://www.youtube.com/watch?v=50XvMaWhiTY)」や「30分で完全理解するTransformerの世界」が非常に勉強になります。
1.a. 具体的な言語モデル
Transformerが実用レベルで普及した初期の言語モデルとしてBERT(Bidirectional Encoder Representations from Transformers)が挙げられます。
このモデルはTransformer構造を応用し、事前学習では大量の文章から一部の単語を見えなく(mask)してその単語が何なのか予測する、といったようなMasked Language Modeling(MLM)を行っています。事前学習済みのBERTを文章分類や質疑応答といったタスクそれぞれでファインチューニングすることで、そのタスクに特化し、かつ高い精度のモデルに学習することができます。
言語モデルはこのBERT以外にも多数存在します。BERTと同じTransformer構造のエンコーダーという構造を用いているRoBERTaやDeBERTa、デコーダーという構造を用いるGPT、エンコーダー・デコーダー構造の両方を用いているT5やBARTといったモデルが存在します。
エンコーダー構造を用いるモデルはテキスト分類や固有表現抽出といったタスクに、デコーダー構造を用いるモデルは文章生成に、エンコーダー・デコーダー構造を両方を用いるモデルは機械翻訳や要約といったタスクに適していると言われています。
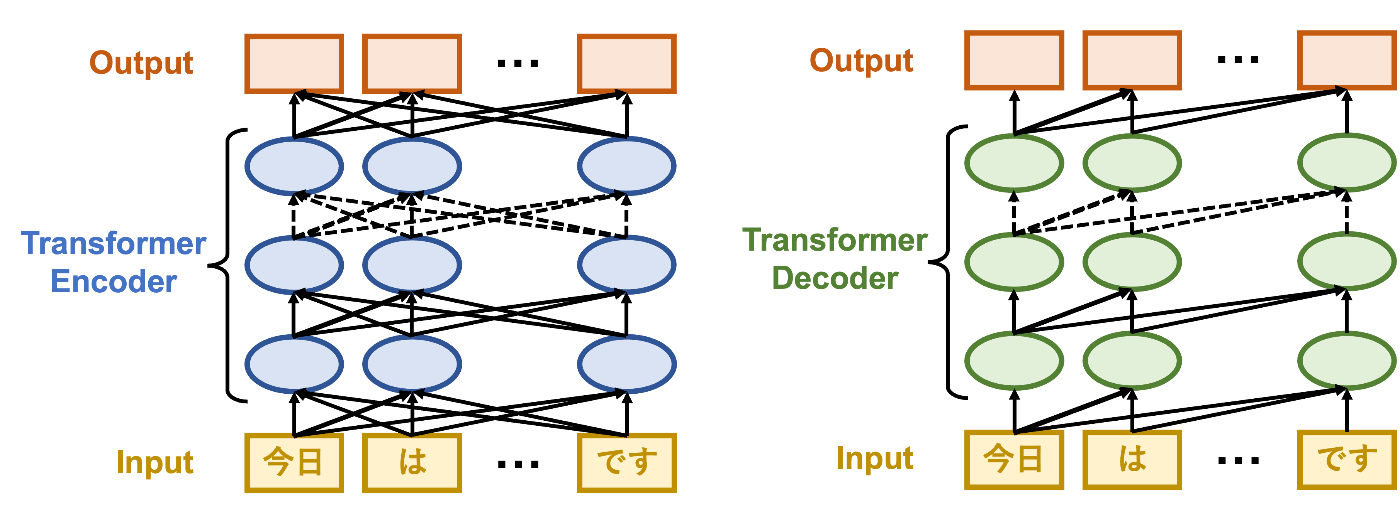
Transformer Encoder/Decoderの概念図:Transformer Encoderは入力データは全てのトークン(例えば”今日”)全体を用いる一方、Decoderは入力トークンより未来のトークンは用いないようなAttentionを行なっている
同じTransformer構造を用いているモデルであっても、事前学習に用いるテキストデータや事前学習の方法、Transformer構造における注意機構(Attention)の違いなどがあり、それぞれ適しているドメインやタスクなどが分かれています。
例えば、SciBERTは大量の科学論文データを事前学習することで科学ドメインにおけるタスクで従来のBERTよりも精度を改善することができ、大規模なプログラミング言語を事前学習したCodeBERTはコード生成や自然言語によるコード検索において従来のモデルより優れた性能を示しています。
1.b. 言語モデルを動かしてみる
このような言語モデル,特にGPT系のモデルであればAPIが公開されているためそれを用いることができます。一方で、自分で言語モデルを学習する場合や、自身の計算環境で推論するにはどうすればいいでしょうか?
一つの方法としてHugging Faceといったモデルハブを利用することができます。Hugging Faceには事前学習済み言語モデルやモデルの学習や評価に用いる多数のデータセットが公開されています。
また、Hugging Faceはtransformersというライブラリを公開しています。transformersは言語モデル以外にも画像や音声解析に使われる様々なTransformerモデルを学習や推論等を簡単に行うAPIやコードを提供しています。
このtransformersを使うことで、テキスト分類を始めとした固有表現抽出や質問応答、ビデオ分類や画像から文章を生成するといった様々なタスクを簡単に学習することができます。
1.c. 言語モデルの問題点
このような言語モデルはタスク特有のファインチューニングを行うことで様々なタスクが解ける一方、個別タスクでファインチューニングが必要なこと自体が欠点でもあります。タスク固有の教師付きデータセットやそのタスクごとに専用のモデルを構築する必要があること、そのデータセットに依存した学習をしてしまい汎用的なモデルを構築することが困難である、といった問題があります。
そもそも人間がある言語タスクを学習するのに大規模な教師付きデータセットを必要とせず、短い指示や少数の例を見ることでそのタスクを実行することができます。言語モデルにこの柔軟性と汎用性を持たせることはできないのでしょうか?
2. 大規模言語モデルのGPT-3とは
このような問題点がある中、2020年にOpenAIから発表されたGPT-3が1つの解決策になります。
GPT-3はTransformerのデコーダー構造を用いたGPTの構造をもとに1750億のパラメータ数で、45TBもの大規模なテキストデータで事前学習されています。このパラメータ数は非常に大きく、BERTではパラメータ数は1億から3億程度、GPT-3以前のGPT-2では15億のパラメータ数と40GBのテキストデータで、これまでのモデルと比べると大幅なスケールアップになっています。

GPTからChatGPTへの系譜
2.a. GPT-3の凄さ
GPT-3の凄さは、ファインチューニングを必要とせず少数例のサンプルで様々な言語タスクを解くfew-shot learningの精度が従来のモデルよりも大幅に向上したことです。
従来の言語モデルでは各タスクのためのデータセットを作り、そのタスク専用の学習が必要でした。しかし、GPT-3は、大規模なモデルで大規模なテキストデータを自己教師あり学習によって学習して簡単な例を示すことで任意の言語タスクを遂行できるようになった、これがGPT-3をはじめとする大規模言語モデルの凄さです。
2.b. 大規模言語モデルの発展
GPT-3の発表から、パラメータ数が1000億から兆の桁に乗るほどの大規模言語モデルが開発されており、それらのモデルを用いたAPIが公開されたり、様々なサービスが展開されています。
2023年2月現在、GPT-3をベースとしたチャットボットサービスであるChatGPTや、Googleでは対話型の検索エンジンのBard、MicrosoftでもGPTを搭載した検索エンジンを発表しており、今後ますます大規模言語モデルが身近になっていきます。
一方で大規模言語モデルの運用には莫大な計算コストがかかり、何らかに特化した言語処理タスクを行う上では不向きな場合もあります。特に1000億ものパラメータ数を持つNNモデルは推論であっても単一のGPUでは処理ができず、大規模な計算環境が必要になります。
3. Turingが目指す基盤モデル
大量のデータで学習して様々なタスクに適応できるようになった大規模モデルは基盤モデルと言われています。基盤モデルはファインチューニングすることや、zero-shot・few-shotで様々なタスクに活用することができます。前述したBERTやGPT-3のようなモデルが含まれます。
完全自動運転を実現するにあたり、Turingでは、人間と同じように画像・自然言語・音声などを解釈できるマルチモーダルな基盤モデルを開発する必要があると考えています。
現在運用されている多くの自動運転技術は、カメラ・LiDAR・レーダーなどのセンサで周囲の状況を計測し、その結果に基づいて車両の制御を行っています。例えばカメラで車線を認識して、そのレーンから逸脱しないようにハンドルを制御させたり、前方の車までの距離、速度を計測して、アクセルやブレーキを動作させています。
こういったシステムは、例えば高速道路などシンプルな交通環境では、人間と同等の性能を発揮できます。一方で、自動車を取り巻く環境は、しばしば「人間が認識すること」を前提とした複雑な表示や状況が存在します。
例えば、市街地の複雑な信号、交通標識の他、道路工事の誘導員のハンドサイン、周囲の歩行者・車とのコミュニケーションなどがそれにあたります。このような状況は、人間であれば無意識に(そして適切に)対処することができますが、現在の自動運転技術では非常に困難な課題です。そのため、完全自動運転のためには、自然言語を前提とした高度な「コンテクストの理解」が必要になる、と私たちは考えています。

複雑な補助標識を含む標識の例
また、自動運転車の乗客がシステムに指示したり、周囲の人間(例えば駐車場の整理員)とコミュニケーションするためにも、音声や自然言語のインターフェースが必要になります。このように、人間の運転タスクを全て代替するためには、カメラなどのセンサ情報や自然言語処理をもとに周囲を理解し、総合的な運転判断につなげるような大規模な基盤モデルが必要となってきます。
4. 1000億越えのパラメータの言語モデルを動かす?
大規模言語モデルを動かすにはどれだけの計算資源が必要か実際に試してみます。Hugging FaceにはBLOOMという1760億パラメータ数からなる大規模言語モデルが公開されています。
4.a BLOOMとは?
BLOOMは2022年に公開された1.5TBの46言語と13のプログラミング言語のテキストデータで自己教師あり学習されたGPTモデルです。そのためChatGPTのような文章を生成することができ、明示的に学習させていないタスクでも文章の生成タスクとして指示することができます。
BLOOMはGPT-3と同程度のパラメータ数を持ち、軽量化されたモデルであっても329GBの容量が必要です。2023年2月現在、コンシューマー向けの最上位のGPUであるGeForce RTX3090やRTX4090であってもメモリサイズ24GBなので、最低でも14枚以上必要になります。
また、学習には384枚のNVIDIA A100というGPUが使われています。約4ヶ月間学習され、そのコストは200万ドルから500万ドルかかったとされています。その際の発熱は大学の暖房に再利用されています。
BLOOMにはパラメータ数が5億から70億程度の比較的小さなモデルも公開されており、GPU1枚で使うことができるモデルもあります。実際に動かしてみましょう。
4.b. BLOOM-1Bを動かしてみる
10億パラメータ数程度のモデルであれば、GPUメモリが12GB以上のGPUであれば推論することが可能です。Google Colaboratoryで提供されているGPUインスタンスで動かすことができます。試しにcolabでハードウェアアクセラレータをGPUに設定し、以下のコードで動かしてみましょう。
! pip install transformers -q
from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
import torch
torch.set_default_tensor_type(torch.cuda.FloatTensor)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = AutoModelForCausalLM.from_pretrained("bigscience/bloom-1b7", use_cache=True)
tokenizer = AutoTokenizer.from_pretrained("bigscience/bloom-1b7")
set_seed(42)
prompt = 'こんにちは!'
input_ids = tokenizer(prompt, return_tensors="pt").to(device)
sample = model.generate(**input_ids, max_length=64)
print(tokenizer.decode(sample[0], truncate_before_pattern=[r"\n\n^#", "^'''", "\n\n\n"]))
すると、以下の変な文章が返ってきました。
>> こんにちは! 俺は、こんにちは! 俺は、こんにちは! 俺は、こんにちは! 俺は、こんにちは! 俺は、こんにちは! 俺は、こんにち
GPTはこれまでの文章から次の単語(トークン)を予測するため、貪欲に確率が高い単語をつなげてしまうと同じ言葉が連続して続くことが多いです。そのため文章を生成する上で、より自然な文章にするような予測単語を探索する必要があります。
詳しくはHugging FaceのHow to generate textというブログ記事に書かれています。少しパラメータをいじると以下のような結果になり、自然な文章っぽくなったかもしれません。
sample = model.generate(**input_ids, max_length=64, top_k=50, num_beams=5, no_repeat_ngram_size=3)
>> こんにちは! もう少しだけだよ! わたしはいつもここにいるから! どんなことがあっても、こんなにもいい! だけど、あなたがいないから! こん
4.c. パラメータ数の違いによる性能について
10億パラメータ数だけでは特定のタスクを遂行できるような文章生成は少し困難かもしれません。より大きいパラメータ数で学習した場合はどうなるのか見てみましょう。
70億パラメータ数をもつbloom-7b1で文章生成を行なってみます。
例えば、「One thing to keep in mind when buying a car:」と入力すると以下のような文章が生成されて、より自然な文章になったかもしれません。
>> One thing to keep in mind when buying a car: If you are buying a used car, make sure that the car has been inspected by a mechanic, and that the mechanic has inspected the car. The mechanic should be able to tell you if there are any problems with the car, and
簡単なタスクも解くことができます。翻訳の例を示して、異なる文章を翻訳させてみましょう。
prompt = """
日本語から英語に翻訳します。
日本語: 今日はいい天気ですね English: Today is a good day
日本語: 車を買うときに気をつけたいことは何ですか? English:
"""
(10億パラメータ数の場合) >> I want to buy a car when I am tired
(70億パラメータ数の場合) >> What should I pay attention to when I buy a car?
10億パラメータ数では不正確な翻訳になりましたが、70億パラメータ数では自然な翻訳になります。実際、GPTをはじめとするTransformer構造を持つモデルはモデルパタメータ数や学習データセットサイズなどに性能が依存することが知られており、より大きいパラメータ数を持つGPTモデルがより自然な文章が生成可能です。
4.d. BLOOM-176Bを動かしてみる?
では実際1000億パラメータを超えるBLOOMを動かすにはどうすればいいでしょうか?
単純な解決策として、その大規模モデルが乗る計算環境を構築することができますが、もしそのレベルのスペックをオンプレミスのサーバーで整える場合は数千万円規模になってしまいます。また、AWSやGCPなどのクラウドコンピューティングサービスで大規模実験環境を整えることもできます。例えば、AWSのEC2 P4dインスタンスであれば8枚のA100のGPUメモリが計320GBと640GBの環境を1時間あたり30~40ドル程度で扱うことができます。
面白い解決策として大規模モデルを他のユーザーと共同で動かすといった解決策もあります。Petalsは、BLOOM-176Bなどの大規模言語モデルを共同で実行するプラットフォームです。モデルの一部をロードし、他の人が担当する部分とチームを組んで推論や学習を行うことができます。Google Colabolatoryを用いたサンプルコードもあります。
また、解決策はモデルを軽量化するためにより少ないビット数で表現するような量子化が挙げられます。transformersでもbitsandbytesというライブラリを用いた8bit量子化が紹介されています。この量子化により、本来329GBあったBLOOM-176Bを200GBのGPUメモリで動かすことが可能になります。
最近では、このような量子化で大規模言語モデルを動かすことも話題となり、特に有名なFlexGenを最後に紹介します。
5. GPU 1枚で推論を可能にするFlexGen
これまで説明してきたとおり、大規模言語モデルはそもそもパラメータサイズが大きくモデルをロードするだけでもかなりのリソースが必要になります。モデルが1枚のGPUに乗り切らない場合はモデルを分割して複数のGPUにロードすることになるのですが、A100のような高性能なGPUを複数枚用意する必要がありハードルがとても高いものでした。
FlexGenはこういった課題を解決するために、T4(16G)やRTX3090(24G)といったスペックのGPU 1枚でも推論を行えるようにしたライブラリになります。動かすことも簡単にできるので、公開されて間もなく多くの人が実際に手元のマシンでOPT-30BやOPT-66Bサイズのモデルを動かしていました(参考: 自宅で動くChatGPTと噂のFlexGenをDockerで手軽に動かす)。
さらにRAMメモリ 200GB弱ほどあればOPT-175Bも1枚のGPUを搭載したマシンで動かすことができるので、FlexGenは大規模言語モデルの活用面でかなりのインパクトがありました。
では、どのようにしてFlexGenは1枚のGPUで動くようにしているのでしょうか。これを実現するために2つのテクニックを用いており、その方法について紹介したいと思います。
5.a GPU/CPU/Diskをフル活用した推論環境
まず1つ目は、モデルのパラメタやTransformerのKey/Valueのキャッシュを、GPUだけでなくRAMメモリやディスクストレージに割り振りを行っています。各デバイスに割り振られたTensorを同じように扱うために、独自でTorchTensorというラッパーを作っています。そしてこのTorchTensorを1枚のCPUやGPUで計算するための環境としてTorchDeviceというクラスも作っています。このクラスの中でMulti-head attentionやMLPなどの実際の計算を、各デバイス上で保持されているTensorデータをPytorchで計算する関数が定義されています。これに加えて、TorchDiskというディスクストレージにおいてあるパラメタやキャッシュを扱う関数も用意して、オフロードの計算も同じように扱えるようにしています。
モデルのパラメタをどのデバイスにアサインするかについては実行時の引数で与えることができます。そして、ディスクストレージ → RAMメモリ → GPUメモリの順でモデルをロードしていきます。
このような独自のラッパークラスを用意することで、GPU/CPU/ディスクを最大限活用した推論環境を作り上げています。
5.b 4bitsの圧縮
2つ目のテクニックは、パラメータやキャッシュの一部を4ビットで圧縮して保持してるところです。これまでの説明の通り大規模言語モデルはモデルのパラメータ自体がかなり大きいので、FlexGenではパラメータの一部やキャッシュを4ビットで保持しています。4ビットに圧縮するためにTorchCompressedDeviceというクラスを用意し、そこで圧縮/展開を実装しています。
4ビットにする方法は、データをノーマライズしたあと4ビット(0~15)でクランプします。ノーマライズに使った倍率(scale)と最小値(min_val)は展開のときに使うので保持しておきます。次に4ビットで表現されたデータをuint8型のデータに格納しています。そのために4ビットで表現したデータを2分割して半分を前半4ビットに、残りの半分を後半の4ビットに割り当てることで実現しています。こうすることで圧縮されたデータの実体としてはuint8のTensorになるのですが、その中には2倍のサイズの4ビットで表現されたデータが入っていることになります。
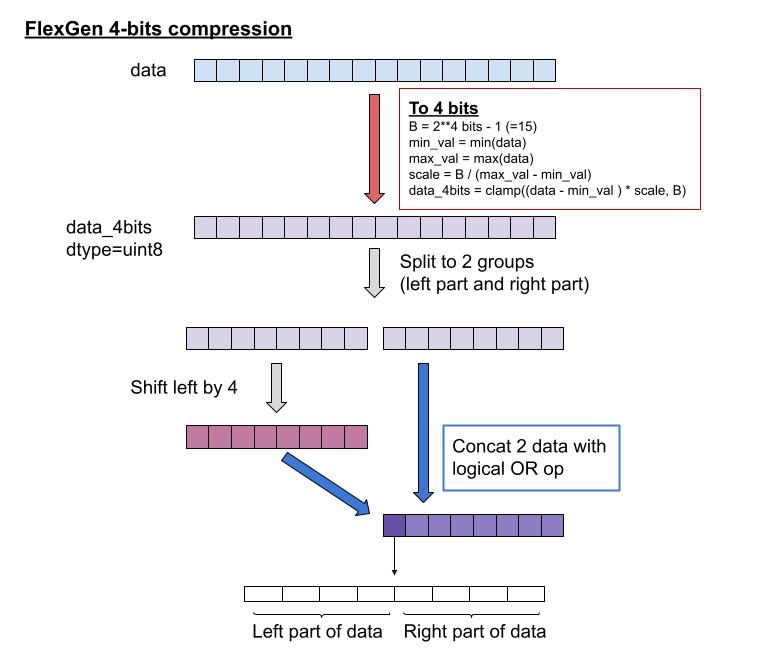
この圧縮はパラメータの保持だけに活用されているので、計算時には展開してfloat16などの精度で計算されています。
こういった技術によってFlexGenを使うことでGPUが1枚しか搭載されていないマシンでもOPT-175Bといった大規模言語モデルの推論を可能にしています。
6.まとめ
この記事では、近年の言語モデルの発展からTuringが目指す基盤モデルの開発について紹介しました。
自動運転車は、高度なカメラやセンサー情報を収集することによって、周囲の環境を認識し、適切な制御を行います。現在の自動運転技術には、カメラやセンサが使われていますが、これらの情報だけでは、複雑な交通状況や周囲の環境を正確に理解することができません。
例えば、市街地の複雑な信号、交通標識の他、道路工事の誘導員のハンドサイン、周囲の歩行者・車とのコミュニケーションなどがそれにあたります。これらの状況に対処するためには、自然言語を前提とした高度な「コンテクストの理解」が必要で、基盤モデルはその解決策の1つになります。
自動運転モデルや基盤モデルの構築には、大規模なデータセットの収集や学習基盤の構築が欠かせません。Turingでは、大規模走行データを収集しており、機械学習技術、学習データセットの構築に両方に注力しています。
自動運転モデルの開発に興味がある方は、Turingの公式Webサイト、採用情報などをご覧ください。話を聞きたいという方は私やAIチームのディレクターの山口さんのTwitter DMからでもお気軽にご連絡ください。

Discussion