
こんにちは、TURING株式会社(チューリング)でインターンをしている、東大大学院修士一年の舘野です。
TURINGは完全自動運転EVを開発しているベンチャー企業です。
完全自動運転を実現するには、車の周りの環境をセンシングし認識するシステムが不可欠です。センシングのためのセンサーは様々考えられますが、TURINGでは主にカメラを用いています。
自動運転AIにはカメラデータから信号機・標識・周囲の車、などの情報を読み取る必要がありますが、そのためにはそれぞれの目的に対応した学習が必要です。
一番単純な方法は、学習させる各動画フレームに対して人間が信号機・標識・周囲の車などの正解情報を付与し、AIモデルが動画を見て正解情報を予測できるようにすることです。下図は、画像から車を検出するモデルの例です。モデルの中身は画像の特徴量を抽出する部分と、分類を行う部分を分けて表現していますが、学習時は元データと正解情報を用いてend-to-endで学習を行っています。
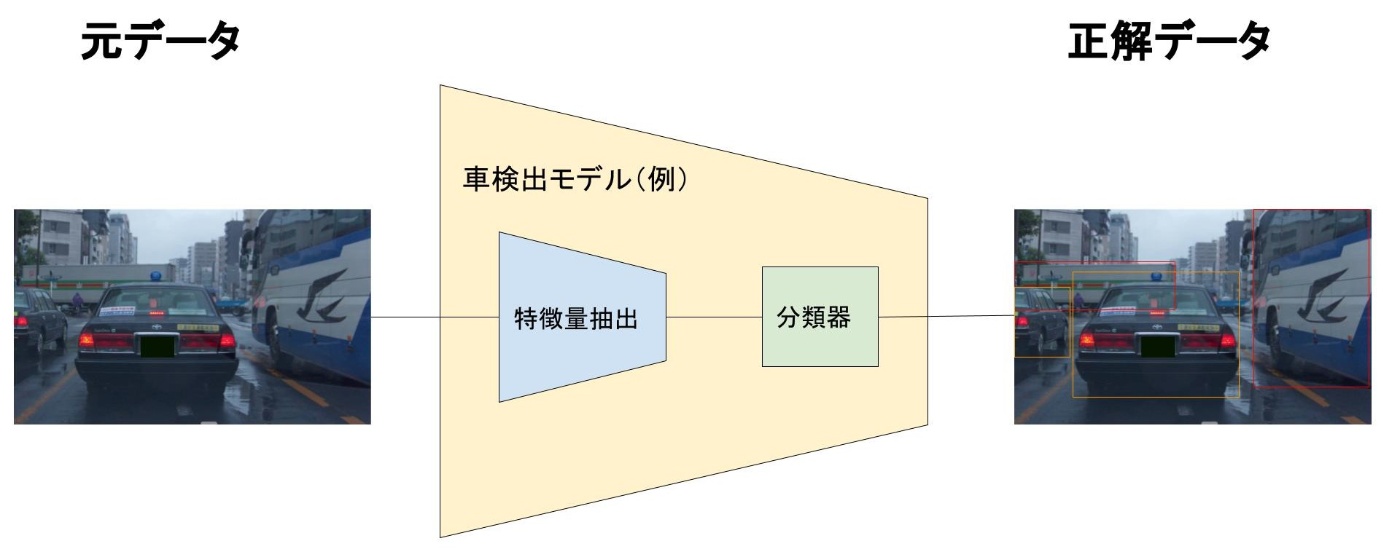
TURINGでは現在、この正解情報を付与する(アノテーションをする)する作業の一部を手動で行っています。
しかし、膨大な量のデータに対して手動で行うには、とてつもない時間と労力がかかります。
そこで今回は人間によるアノテーションを最小限に抑える学習方法である、自己教師あり学習を紹介します!
まとめる内容は以下の通りです。
-
自己教師あり学習とは?
1-a. 人手によるデータセット作成の問題点
1-b. 自己教師あり学習の用途 - 事前学習のための自己教師あり学習
- 生成タスクのための自己教師あり学習
- Contrastive Learning
- 自動運転への応用
- まとめ
1. 自己教師あり学習とは?
モデルを学習させる学習方法の一種です。モデルを学習させるとき、学習データそのものから作られた学習目標(教師データ)を利用することで、人間による正解ラベルを必要としない学習を行います。
いかにして元データを正解情報として利用するか、が肝となります。

1-a. 人手によるデータセット作成の問題点
機械学習のためのデータを用意する際に、人間によるラベリングを行うと以下のような問題が起こります。
- ラベリングが大変
- 作業者のバイアスがかかる
- 付与した正解情報は、ほかのタスクも汎用的に解けるものではない
特にラベリングが大変というところは致命的で、何十万・何百万というデータに正解情報を付与するとなると膨大な時間と労力がかかってしまいます。
1-b. 自己教師あり学習の用途
自己教師あり学習がどういった場面に使えるのかを説明するために、まず機械学習モデルの学習の大変さを説明します。
あるタスクに関する機械学習モデルを一から学習させ、高い精度を出すためには膨大な量のデータと時間が必要になります。そのため大規模なデータで事前に学習を行ったモデルを流用できると非常に効率的です。例えば画像処理系の機械学習モデルではImageNetなどの大規模データセットを用いて学習されたモデルを組み込むことがよく行われます。すると、すでにある程度学習されたところから始めることができるので、同じ量のデータや時間をかけて学習させたモデルでも精度が高くなります。このときImageNetによる学習は本当に解きたいタスクの事前に行われているものなので、「事前学習」と呼ばれます。
では、ImageNetによる事前学習では画像分類のタスクを行っているのに、なぜそのモデルをほかのタスクに使うことができるのでしょうか?
それは、機械学習のモデルが下図のように、画像からその特徴的な部分をベクトルとして抽出する特徴抽出器と、特徴ベクトルをもとにタスクの正解を出すための分類器に分解できるからです。「画像からどういった特徴を抽出すべきか」がわかっている特徴抽出器を下流タスク(図における車検出)に埋め込めば、下流タスクの学習が非常に効率的になります。
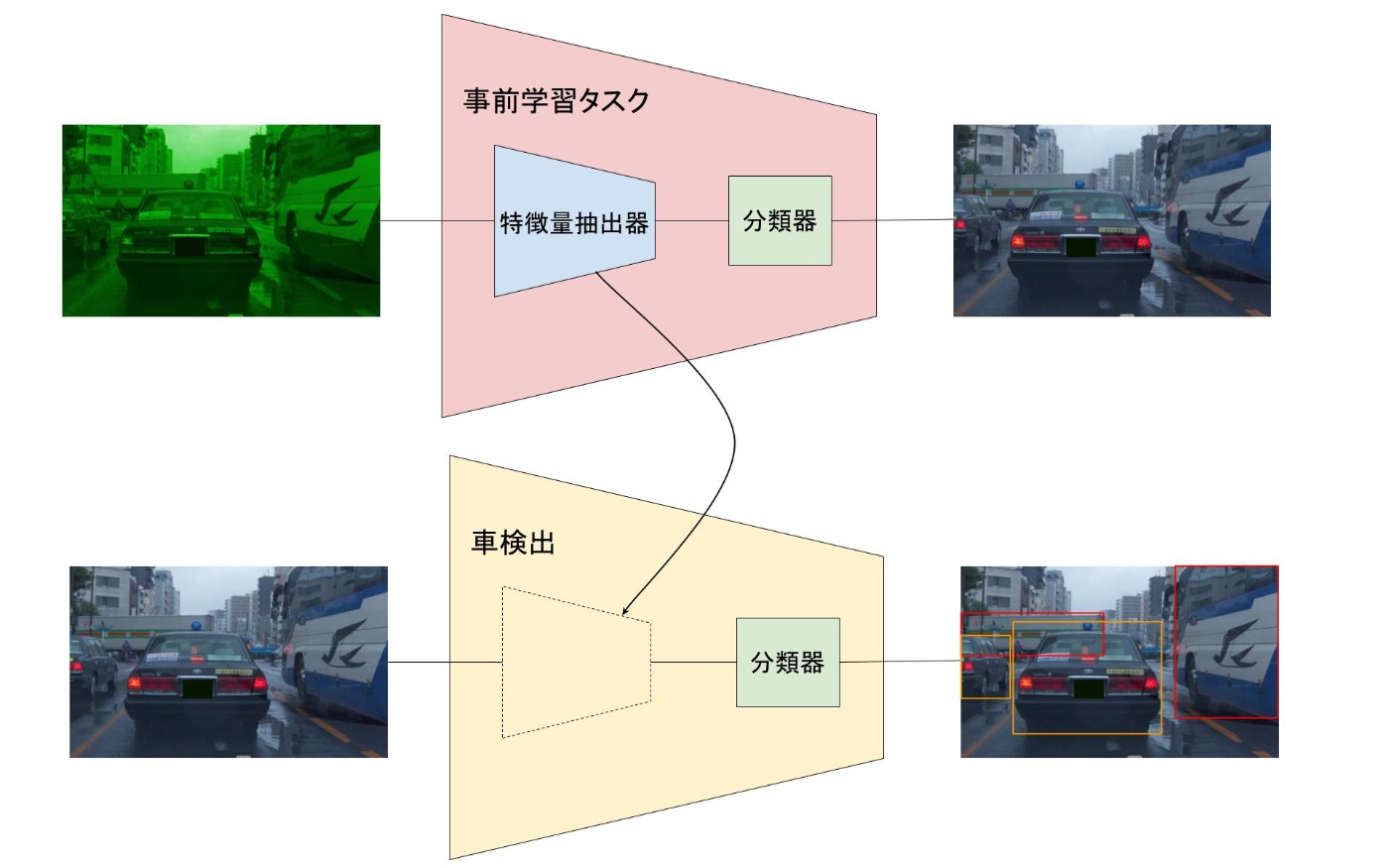
ただ、ImageNetによる画像分類が最強の事前学習なのかというとそうではありません。ImageNetによる事前学習モデルが使われるのはそれが大規模なデータで学習されているからです。
もし車検出に近い事前学習を大規模にできるのであれば、そちらをやったほうがいい特徴抽出器ができるでしょう。しかしそのための大規模な正解情報を用意するのは非常に大変です。
ここで有効なのが、自己教師あり学習になります。
自己教師あり学習によって、正解情報のアノテーションを必要としない事前学習を行えれば、下流タスクの精度を高めることができます。
次章では、どのような事前学習を行えばよいのか、各方法の特徴も踏まえて紹介します。
2. 事前学習のための自己教師あり学習
最終的に解くタスク(下流タスク)をより汎用的に解けるように、モデルの事前学習を行う際に自己教師あり学習が用いられます。事前学習でどのようなタスク(Pretext task)を設定するかは、下流タスクに応じて設定します。つまり、下流タスクにおいてモデルが抽出したい特徴量を抽出できるように事前学習タスクを設定します。
事前学習の基本的な流れは、以下の通りです。
- 元のデータに何らかの変化を加える
- 1で加えた変化の内容や、元データを予測するタスクを解かせる(学習させる)
上記の手順では元のデータが正解情報(教師)となるので、ラベル付けが必要なくなります。
今回は特に動画像のためのPretext taskをいくつか紹介します。
-
Appearance statistics prediction
画像に対してColorやRotationについてデータ拡張(Augmentation)を施したうえで、同じ画像は同じと判定させる学習を行います。こうすることで、Augmentationに惑わされない特徴抽出器が完成します。
また、どのようなAugmentationを行ったのかを予測するというタスク設定もあります。
どのAugmentationを用いるべきか、は何の下流タスクを解きたいかによりますが、完全な正解はなく、研究対象の問題であると考えられます。

様々なAugmentationの例[1]。

Augmentationの内容を当てるタスク[2]。 -
Playback speed
こちらは動画に用いられます。動画の速度を変更してそれを当てたり、その他ランダム、周期的、または歪んだ変換のいずれかを適用し、どれを適用したのか当てるタスクを行います。つまり、2つの分類タスクを解いていて、「どの変換が使われたか」とその「スピード」を予測するということです。さらに精度を上げるためにモデルに元動画を再構成(Reconstruction)させる方法もあります。つまり、推論した変換情報を使って編集後の動画から編集前の動画(元動画)を作ってみて、実際の元動画との差をとってさらに学習させるという方法です。

再生速度に関するAugmentation内容を当てるタスク[2]。 -
Temporal order classification
動画からいくつかフレームを持ってきて、その順番を入れ替えて、本来の順番を当てさせるタスクもあります。
順番の入れ替え方も種類があり、一つだけ順番がおかしいフレームを用意してどれがそれかを当てるタスクと、いくつかのフレームをシャッフルして、元の順番をあてるタスクがあります。

順序を当てるタスクの例[2]。a)はフレームがシャッフルされたかどうかを当てるタスク。b)は正しい順番に並び替えるタスク。 -
Jigsaw
ジグソーパズルを解くように、元の画像をパッチに分解してシャッフルしたものを、正しい場所に再配置するタスクです。動画に応用するときは、図b)のように同一動画内の複数フレームのすべてのパッチをシャッフルする方法があります。

ジグソータスクの例[2]。a)は画像の場合。b)は動画の場合。 -
Masked Modeling
この方法はNLPにおけるBERTと同じような方法です。簡単に言うと、系列データの一部をMaskして、そこに入るべきデータ(の特徴量)を予測するタスクとなります。動画の分野で使うときは、動画を系列データとして扱ってMaskした問題を解きます。Vision-TextやVision-Audioの分野においては[CLS]トークンを使って、VideoとText/Audioが時間的に同期(align)しているかどうかを判定するタスクを解きます。また、クロスモーダルな特徴量を改善するために、Masked Modeling (MM)が提案されました。MMとは、あるモダリティからのTokenを用いてもう一つのモダリティのトークンを再構成する方法です。
以上のように、様々な方法で元の動画像に変更を加えたうえで、元の動画像を正解情報として学習を行っています。
自己教師あり学習はこれまで見てきた認識タスクのみでなく、生成タスクにも用いられます。次章では生成タスクにおける自己教師あり学習の利用方法について紹介します。
3. 生成タスクのための自己教師あり学習
動画像の生成を行う場合も自己教師あり学習が用いられています。
生成タスクは新たな動画像を生成するGenerativeタスクと、動画の将来フレームを予測するPredictiveタスクに分類できます。いずれも、生成したデータが学習用データのデータポイントに近寄るように学習していきます。

自己教師あり学習を用いた生成タスク[2]。a)はノイズから動画像を生成する例。b)は前のフレームから将来フレームを予測する例。
-
Generative
上図のa)に対応するようなGANsの形のネットワークです。データはノイズやその他の入力をもとに生成されます。内部にはGeneratorとDiscriminatorが存在し、Generatorが生成したデータをDiscriminatorが本物か偽物か(Real/Fake)を判定します。GeneratorはよりDiscriminatorを騙せるように本物に近い画像を生成するように学習し、Discriminatorは本物を見抜けるように学習します。
また、最近話題のDiffusion Modelも以下のようにノイズと生成画像を行き来しながら学習しています。「画像をノイズにして過程の逆を行うと元の画像に戻るはず」という考えを用いて学習させています。この場合は元画像が正解情報として機能しています。

Diffusionモデルの動作[3]。 -
Predictive
上図のb)のようにそれまでの系列情報を用いて将来のフレームを予測しています。予測はRGBに限らず動画の場合はOptical Flowなどの場合もあります。
以上のように、生成タスクも自己教師あり学習を用いて学習できます。
そして、最後に自己教師あり学習の一つの手法であるContrastive Learningを次章で紹介します。これはこれまで紹介してきたようなタスク設定の一種ですが、画像分類のなどの分野において教師あり学習に匹敵する精度をたたき出すということで注目を浴びている学習方法です。
4. Contrastive Learning
最近注目を浴びている自己教師あり学習の手法です。データ同士を比較し、同じ種類のデータを同じもの、違う種類のデータを違うものに分類する学習法です。データ間の関係性を用いて学習しているので直接的なラベルは必要ない、ということになります。
学習データのうちanchor, positive, negativeの3つのサンプルを考えます。あるデータをanchorとし、anchorと同じ種類のものとして学習させたいサンプルをpositiveサンプル、違う種類のものとして学習させたいサンプルをnegativeサンプルとします。特徴量空間において、anchorデータに対してpositiveデータを近くに、negativeデータを遠くになるように学習させています。このpositive/negativeサンプルをどのように用意(生成)するかで手法が様々あります。

Contrastive Learningの例[2]。a)は見た目のAugmentation。b)は時空間におけるAugmentation。c)はモダリティ間の関係を用いた方法。
動画におけるアプローチをいくつか紹介します。
-
View Augmentation
動画に様々な見た目に関するAugmentationを加えます。(crop, jitter, grey, rotation…)そして同じビデオから持ってきたフレームのペアを
positive、違うビデオから持ってきたペアをnegativeとして学習させます。 -
Temporal/Spatio-Temporal Augmentation
動画において、フレームの順番をシャッフルし、同じビデオの時間的に近いフレームは
positiveペア、違うビデオのフレームはnegativeペアとして扱います。 -
Cross-Modal
Vision以外に、Audioなどの他のモダリティも利用可能な場合、例えばビデオと音声が一致している
positiveペアと一致してないnegativeペアで学習を行います。
5. 自動運転への応用
TURINGが目指す自動運転AIは将来的に完全自動運転が求められます。これを可能にするには、人間のドライバーが自然に実現できているようにさまざまなタスクを複合的にこなす必要があります。自己教師あり学習はそのための共通の潜在表現の獲得を行うのに有効であると考えています。
少し古いですが、2019年のTesla Autonomy Dayにおいてもイーロン・マスクがDojoというスーパーコンピューターを用いて大量のデータからの自己教師あり学習をおこなう旨を話しています。
The car is an inference-optimized computer. We do have a major program at Tesla — which we don’t have enough time to talk about today — called Dojo. That’s a super powerful training computer. The goal of Dojo will be to be able to take in vast amounts of data — at a video level — and do unsupervised massive training of vast amounts of video with the Dojo computer. But that’s for another day.
そして最近のTesla AI Dayの発表では、まさにこのDojoや訓練された潜在空間表現を用いて複合的な自動運転タスクに取り組む事例が紹介されました。こちらのTesla AI Dayに関する記事も併せてご覧ください。
具体的に、どのような自己教師あり学習が考えられるのか、例を示します。
ここでは車載カメラ特有の以下のような特性を生かした自己教師あり学習の可能性を紹介します。
- 車の動きに従ってカメラが移動する
- 複数視点のカメラがある(TURINGでは複数のカメラを車に設置します)
1の特性を使った自己教師あり学習を考えてみましょう。
これは白線検知に使える可能性があります。車載カメラでとらえた白線は近くにあるものははっきり認識できますが、遠くに行くほど精度が落ちてしまいます。しかし、動画データであれば進行方向遠くにある白線は、自動車が動いているため、数秒後に近くにやってきます。つまり遠くにある白線が実際にはどうなっているのかということが数秒後によくわかるようになる、ということです。したがって、時刻t秒の動画フレームを入力、t+Δt秒の白線の状態を正解情報とすれば自己教師あり学習が成立するでしょう。

次に、2の特性を使った自己教師あり学習を考えてみます。
これは事前学習に使える可能性があります。カメラaとカメラbで撮影した動画があったときに、片方の動画からもう片方の動画を予測する学習を行います。この学習がうまくいけば、視点の違いを理解するようなモデルが出来上がるでしょう。そうすればこのモデルを鳥瞰図の生成モデルに用いることができるかもしれません。
このように自動運転にも様々な方法で自己教師あり学習を利用することができます。
自己教師あり学習の自動運転への詳しい応用方法や最近のトレンドなどは別途まとめて投稿したいと思っております。
6. まとめ
自己教師あり学習は、正解情報を必要としない学習方法でした。事前学習としてタスクを設定する(Pretext task)場合もあれば、実際に解いてほしいタスクそのもので学習させる場合もあります。そして認識タスクだけでなく生成タスクにも利用されています。
最近はContrastive Learningというデータ同士を比較することでタスクを解くための学習が注目されており、教師あり学習の精度に迫る精度を誇ります。
自動運転においても自己教師あり学習は有効であり、TURINGでは今後複雑な問題解決が可能な機械学習モデルの開発に向け利用方法を模索していく方針です。
最後に
最後まで読んでいただきありがとうございます。
TURINGでは2022年の500時間の走行データ取得目標を達成し、次なる50,000時間の目標に向けて着々と準備が進んでいます。同時に、完全自動運転に向けた機械学習モデルの開発も加速しています。
完全自動運転には、複雑な環境を理解し様々なタスクを複合的に解決することができる機械学習モデルが不可欠です。
TURING自動運転MLチームでは、
- 膨大な走行データを扱う情報基盤を作りたい
- 自動運転AIの設計・実装がしたい
という思いを持ったAI開発人材を募集しています。
AI開発に自信/強い興味のある学生インターンもお待ちしています。
問い合わせ先
弊社での開発業務にご興味をお持ち頂けた方は、求人一覧、Wantedlyを是非ご覧下さい。
その他、ご質問や気になる点がありましたら、お気軽にTwitterのDMをお送りください。共同代表山本、青木どちらもDMを開放しております。→@issei_y, @aoshun7
参考文献
[1] Ashish Jaiswal, Ashwin Ramesh Babu, Mohammad Zaki Zadeh, Debapriya Banerjee, and Fillia Makedon. A survey on contrastive self-supervised learning. Technologies, 9(1):2, 2021.
[2] Madeline C. Schiappa, Yogesh S. Rawat and Mubarak Shah, Self-supervised learning for videos: A survey, arxiv, 2022.
[3] Jonathan Ho, Ajay Jain and Pieter Abbeel. Denoising diffusion probabilistic models. NeurIPS, 2020.

Discussion