
AIと連携し、Excel感覚で操作できるクラウドBIサービス、Sigma(Sigma Computing)。
個人的にはここまで何本かSigma関連のエントリを公開してきましたが、実践系のエントリも徐々に増やしていこうと思います。
当エントリではSnowflakeの実践チュートリアルが多数公開・展開されているサイト『Snowflake Quickstarts』の中から、SnowflakeとSigmaを連携しながらSigmaの操作や機能を紹介していくコンテンツ『Getting Started with Sigma』の実践内容をお届けします。全11ステップ、エントリ文字数約35000文字とかなり長い内容となっておりますがどうぞお付き合いください。
1. Lab Overview(クイックスタート概要)
準備する環境
今回のQuickstartで利用する環境は以下の通り。
-
Snowflake実行環境
- 所定のデータやオブジェクト要素が利用出来れば問題なし。
- 今回は30日間無料トライアルの環境を用いました。
- リージョンは任意。今回は東京リージョンとしました。
- またエディションについてはEnterpriseとしました。
-
Sigma実行環境
- トライアル環境を用意。
実践する内容
今回のQuickstartでは以下のアクションを実践していきます。
- Snowflakeのトライアル環境を用意
- Snowflakeデータベース、テーブル、ステージ、ウェアハウスを作成
- Snowflake環境に構造化データと半構造化データをロード
- Partner Connect を使用して、Snowflake に接続された Sigma の無料トライアルアカウントを開始
- Sigmaのトライアル環境を用意
- Snowflakeのサンプルデータをモデル化するSigmaデータモデルを構築
- サンプルデータを分析する洗練されたSigmaワークブックを構築
- データを探索・分析し、可視化とダッシュボードを作成
2. Snowflake環境の準備
このステップでは、Snowflake環境に関する指定と、後述の実践ステップで使うSQLファイルに関する言及がありました。下記リンクからダウンロード出来ますが、ここではその内容をエントリ本文にも貼り付けておきます。
use role sysadmin;
use warehouse pc_sigma_wh;
create or replace database plugs_db;
use database plugs_db;
use schema public;
CREATE or REPLACE STAGE plugs_db.public.sigma_stage
URL = 's3://sigma-snowflake-vhol/data/';
ls @sigma_stage;
create or replace table transactions
(order_number integer,
date timestamp,
sku_number string,
quantity integer,
cost integer,
price integer,
product_type string,
product_family string,
product_name string,
store_name string,
store_key integer,
store_region string,
store_state string,
store_city string,
store_latitude integer,
store_longitude integer,
customer_name string,
cust_key integer);
CREATE FILE FORMAT "PLUGS_DB"."PUBLIC".COMMA_DELIMITED
TYPE = 'CSV'
COMPRESSION = 'AUTO'
FIELD_DELIMITER = ','
RECORD_DELIMITER = '\n'
SKIP_HEADER = 1
FIELD_OPTIONALLY_ENCLOSED_BY = 'NONE'
TRIM_SPACE = FALSE
ERROR_ON_COLUMN_COUNT_MISMATCH = TRUE
ESCAPE = 'NONE'
ESCAPE_UNENCLOSED_FIELD = '\134'
DATE_FORMAT = 'AUTO'
TIMESTAMP_FORMAT = 'AUTO'
NULL_IF = ('\\N');
COPY INTO transactions from @sigma_stage/Plugs_Transactions.csv FILE_FORMAT = ( FORMAT_NAME = 'COMMA_DELIMITED' );
SELECT COUNT(*) FROM TRANSACTIONS;
create or replace table Customer
(cust_key integer,
cust_json variant);
COPY INTO Customer from @sigma_stage/Plugs_Customers.csv FILE_FORMAT = ( FORMAT_NAME = 'COMMA_DELIMITED' );
select * from Customer;
grant USAGE on DATABASE PLUGS_DB to role PC_SIGMA_ROLE;
grant USAGE on SCHEMA PLUGS_DB.PUBLIC to role PC_SIGMA_ROLE;
grant SELECT on TABLE PLUGS_DB.PUBLIC.TRANSACTIONS to role PC_SIGMA_ROLE;
grant SELECT on TABLE PLUGS_DB.PUBLIC.CUSTOMER to role PC_SIGMA_ROLE;
use role PC_SIGMA_ROLE;
select * from Customer;
select count(*) from transactions;
3. SnowflakeのUIについて
ここから本格的に手を動かして進めていきます。まずはSnowflake環境の準備から。前述の通り、トライアルアカウントを準備します。手順に関しては下記ドキュメントなどを参考にしてください。
Snowflakeアカウントを作成出来たらログイン処理を済ませておいてください。

ログインできたら早速上記で言及したSQLファイルを見ていきます。画面左上の[+Create]メニューから[SQL Worksheet]を選択。

開かれたワークシートの3点メニューから[Import SQL from File]を選択。上記でダウンロードしたファイルを指定します。

SQLワークシート上にSQL実行内容が表示されました。

4. Sigmaの環境準備
Quickstartの手順では「Partner Connect」からSigma環境を準備する形となっていましたが、この手順ではトライアル環境を別途申し込み、準備する形を採ります。
Sigmaに関してはトライアルでの利用が可能です。下記サイトから申し込みを行ってください。
環境が準備出来たらログインします。

ログイン後のTOP画面。

ちなみにTOP画面に表示されているガイドメニューはクリックで表示/非表示の切り替えが可能です。


Snowflakeへの直接接続
Sigmaは、他の多くのBI製品とは異なり、フルマネージドSaaSであり、Snowflakeへの直接接続を提供し、すべてのクエリをSnowflakeにプッシュして実行するという点で独特ではあります。
- Sigmaがアクセスするデータは常にライブで正確
- SigmaはSnowflakeのコンピューティングリソースを活用するため、クエリ速度とスケールは無制限
- 最大数千億行に及ぶクエリでも、高いパフォーマンスを発揮
- データが Snowflake から外に出ることはなく、単一のアクセス ポイントから簡単に権限を制御できるため、セキュリティとガバナンスが強化される
- 他の多くのBI製品では、分析のためにデータがSnowflakeからローカルデスクトップ/サーバーに抽出されるが、これによりデータが古くなり、スケールと速度が制限され、抽出データが多数のデスクトップやファイル共有に分散されるためセキュリティ上の問題が発生
- アカウントに作成されるオブジェクトを示すダイアログボックスが表示されます。このラボでは、PC_SIGMA_WH ウェアハウスと PC_SIGMA_ROLE を使用します。これらは LAUNCH の一環として自動的に作成されます。
QuickstartではPartner Connectでの手順を進めることで以下の要素が作成されています。
- データベース:
PC_SIGMA_DB - ウェアハウス:
PC_SIGMA_WH(X-Small) - システムユーザー:
PC_SIGMA_USER - システムパスワード:(自動&ランダム生成)
- システムロール:
PC_SIGMA_ROLE
ですが、当エントリではSnowflake環境を独自のトライアルアカウントで準備する方針としていますので、ここではそれぞれの要素を独自に作成する形で進めていきます。下記のSQLコマンドをそれぞれ実行してください。
--// データベースの作成.
CREATE DATABASE PC_SIGMA_DB;
use PC_SIGMA_DB;
--// ウェアハウスの作成.
CREATE OR REPLACE WAREHOUSE PC_SIGMA_WH
WITH
WAREHOUSE_TYPE = STANDARD
WAREHOUSE_SIZE='X-SMALL'
AUTO_RESUME = TRUE
AUTO_SUSPEND = 60
COMMENT = 'for Getting Started SIGMA Quickstart.';
--// ユーザーの作成は当エントリでの操作が出来るユーザーであればOK.
--// 当エントリではSnowflakeアカウント作成時に利用したユーザーで進めることにします.
--// ロールの作成、権限付与
CREATE ROLE PC_SIGMA_ROLE;
GRANT ROLE PUBLIC TO ROLE PC_SIGMA_ROLE; --// PC_SIGMA_ROLEがPUBLICロールの権限を継承
GRANT ROLE PC_SIGMA_ROLE TO ROLE SYSADMIN; --// SYSADMINロールがPC_SIGMA_ROLEの権限を継承
--// Option条件を実現するための各種GRANT文を実行.
GRANT USAGE ON DATABASE PC_SIGMA_DB TO ROLE PC_SIGMA_ROLE;
GRANT USAGE ON ALL SCHEMAS IN DATABASE PC_SIGMA_DB TO ROLE PC_SIGMA_ROLE;
GRANT SELECT ON ALL TABLES IN SCHEMA PC_SIGMA_DB.PUBLIC TO ROLE PC_SIGMA_ROLE;
GRANT SELECT ON FUTURE TABLES IN SCHEMA PC_SIGMA_DB.PUBLIC TO ROLE PC_SIGMA_ROLE;
5. Snowflake環境にデータを投入
このQuickstartハンズオンでは、架空の実店舗「Plugs Electronics」の一般的な販売データを扱います。このデータには、注文番号とSKU番号、商品名、価格、店舗名と地域、顧客データが含まれます。これらのデータの一部は構造化されており、一部はJSON形式の半構造化データです。
このデータをSnowflakeに読み込み、Snowflakeの機能をいくつか紹介します。次に、BIプラットフォームであるSigmaをSnowflakeに接続し、データに対して分析を実行し、複数のチャートを作成してダッシュボードを作成していきます。
データベースとテーブルを作成
以下SQLを逐次実行。
--// このコンテキストではSYSADMINを利用。ACCOUNTADMINは使わない.
use role sysadmin;
--// ウェアハウスに前述で作成したものを選択.
use warehouse pc_sigma_wh;
--// アカウント上にPLUGS_DBというデータベースを作成し、ワークシートのコンテキストも変更.
create or replace database plugs_db;
use database plugs_db; --// セッションにplugs_dbデータベースを使用するように指定.
use schema public; --// スキーマを使用するように WORKSHEET のコンテキストを設定.
--// ラボで使用するデータ ファイルがある外部 S3 バケットを指す外部ステージを Snowflake に作成
CREATE or REPLACE STAGE plugs_db.public.sigma_stage
URL = 's3://sigma-snowflake-vhol/data/';
lsを実行。以下のような結果が表示されました。
--// 作成されたステージのすべての内容を一覧表示
ls @sigma_stage;
| name | size | md5 | last_modified |
|---|---|---|---|
| s3://sigma-snowflake-vhol/data/Plugs_Customers.csv | 1944250 | af03f41f1b06b36b6fe1efb9bfd70b5a | Wed, 7 Apr 2021 22:02:29 GMT |
| s3://sigma-snowflake-vhol/data/Plugs_Transactions.csv | 1049980179 | 3b77384fe93bb994d4fad275acfa0186-62 | Wed, 7 Apr 2021 21:08:29 GMT |

データをSnowflakeにロード
参考までに、ここで使用するデータは、「Plugs Electronics」という架空の実店舗のデモデータです。このデータは、us-west-1 (北カリフォルニア)リージョンの AWS S3バケットにエクスポートされ、事前にステージングされており、ファイルは2つ存在しています。
Transactionsテーブルへのロード
最初のデータファイルは「Plugs Transactions.csv」で、注文番号とSKU番号、商品名、価格、店舗名と地域、顧客データが含まれています。カンマ区切り形式で、二重引用符で囲まれ、ヘッダー行が1行あります。データは470万行、合計サイズは1kMBです。
前のリスト (ls) に示されているように、ステージにはデータファイルがあります。
TRANSACTIONテーブルに関する以下SQL文を実行。
--// テーブル定義を作成.
create or replace table transactions
(order_number integer,
date timestamp,
sku_number string,
quantity integer,
cost integer,
price integer,
product_type string,
product_family string,
product_name string,
store_name string,
store_key integer,
store_region string,
store_state string,
store_city string,
store_latitude integer,
store_longitude integer,
customer_name string,
cust_key integer);
--// ファイルフォーマットを定義.
CREATE FILE FORMAT "PLUGS_DB"."PUBLIC".COMMA_DELIMITED
TYPE = 'CSV'
COMPRESSION = 'AUTO'
FIELD_DELIMITER = ','
RECORD_DELIMITER = '\n'
SKIP_HEADER = 1
FIELD_OPTIONALLY_ENCLOSED_BY = 'NONE'
TRIM_SPACE = FALSE
ERROR_ON_COLUMN_COUNT_MISMATCH = TRUE
ESCAPE = 'NONE'
ESCAPE_UNENCLOSED_FIELD = '\134'
DATE_FORMAT = 'AUTO'
TIMESTAMP_FORMAT = 'AUTO'
NULL_IF = ('\\N');
これらのファイルには、データを適切にロードするためにSnowflakeで定義する必要がある特定の形式があります。今回は、COMMA_DELIMITEDというファイル形式を作成します。これは、ファイル内のデータがコンマで区切られていること、圧縮されていること、レコード区切り文字が改行文字「\n」であること、最初の行のレコードにスキップする必要がある列名が含まれていることなどを指定します。ファイル形式に関する詳細は、以下をご参照ください。
--// COPY INTO文でステージからtransactionテーブルへデータを投入.
COPY INTO transactions from @sigma_stage/Plugs_Transactions.csv FILE_FORMAT = ( FORMAT_NAME = 'COMMA_DELIMITED' );
--// 投入件数確認.
SELECT COUNT(*) FROM TRANSACTIONS;
このCOPY INTOコマンドにより、Plugs_Transactions.csvファイルからデータがコピーされ、transactions テーブルにロードされます。
テーブルに対してSELECT COUNT(*)を実行すると、4,709,568 行がロードされたことがわかります。

Customerテーブルへのロード
続けて以下のSQL文を実行。
--// テーブル定義を作成.
create or replace table Customer
(cust_key integer,
cust_json variant);
--// COPY INTO文でステージからCustomerテーブルへデータを投入.
COPY INTO Customer from @sigma_stage/Plugs_Customers.csv FILE_FORMAT = ( FORMAT_NAME = 'COMMA_DELIMITED' );
--// 全件内容を表示.
select * from Customer;
ここでは2つ目のデータファイル(「Plugs_Customers.csv」)の顧客テーブルが作成されます。このテーブルは構造化データと半構造化データで構成されています。Plugs Electronicsの顧客情報(年齢層、居住状況、住所、性別、ロイヤルティプログラムへの参加状況など)で構成されています。このテーブルもAWS上にステージングされており、データは5,000行、合計サイズは1.9MBです。
cust_json列はVARIANTとして定義されています。JSON、Parquet、ORC、Avro、XML は半構造化データであるため、これらのデータを格納するためにVARIANTデータ型を使用します。詳細については以下をご覧ください。
構造化を適用せずにデータを格納し、パス表記法を使用したSQLを使用して、半構造化データに対してそのままクエリを実行できます。
SigmaとSnowflakeの統合により、パス表記法を使用したSQLが生成されるため、SQLを自分で記述する必要はありません。(詳細はエントリの後半で説明します)
cust_json列の内容がわかるキャプチャを以下に添付します。

半構造化データ
Snowflakeは、JSON、Parquet、Avroなどの半構造化データを変換なしで簡単に読み込み、クエリを実行できます。これは重要な点です。なぜなら、今日生成されるビジネス関連データの多くは半構造化されており、多くの従来のデータウェアハウスではこの種のデータの読み込みやクエリは容易では無いからです。Snowflakeであれば容易に対応が行えます。
--// COPY INTO文でステージからCustomerテーブルへデータを投入.
COPY INTO Customer from @sigma_stage/Plugs_Customers.csv
FILE_FORMAT = ( FORMAT_NAME = 'COMMA_DELIMITED' );
先程実行した上記COPY INTO文では、ステージから顧客テーブルにデータをロードしており、このコピー処理により、テーブルには4,972行がロードされます。
半構造化データと構造化cust_key列の違いを確認するには、select * from customer;を実行することをお勧めします。下の図では、結果一覧のcust_json列の2行目のセルをクリックしてみると、UIが詳細ダイアログボックスを開き、JSONの内容(キーと値のペア)が表示されました。これは便利ですね。

引き続き以下SQL文を実行。所定の権限からでもデータが参照出来ることを確認します。
--// Snowflakeのアクセス権は、ロールベースのアクセス制御(RBAC)に基づいており、
--// PC_SIGMA_ROLEがplugs_dbデータベースを使用できるようにする必要がある
grant USAGE on DATABASE PLUGS_DB to role PC_SIGMA_ROLE;
--// PC_SIGMA_ROLEがplugs_db.publicスキーマを使用できるように対応.
grant USAGE on SCHEMA PLUGS_DB.PUBLIC to role PC_SIGMA_ROLE;
--// pc_sigma_roleにtransactionsテーブルのSELECTアクセス権を付与.
grant SELECT on TABLE PLUGS_DB.PUBLIC.TRANSACTIONS to role PC_SIGMA_ROLE;
--// pc_sigma_roleにCUSTOMERテーブルのSELECTアクセス権を付与.
grant SELECT on TABLE PLUGS_DB.PUBLIC.CUSTOMER to role PC_SIGMA_ROLE;
--// テーブルとデータへのアクセスをPC_SIGMA_ROLEに付与することが完了.
--// これで、ユーザはこのロールを使用してシグマからのデータのレポートを
--// 開始できるようになる
--// このコマンドは、シグマがデータにアクセスできることを確認できるように、
--// このロールを使用していることをUIのコンテキストに設定している
use role PC_SIGMA_ROLE;
--// 上記処理が問題なければこのSELECT文も動くはず.
select * from Customer;
--// PC_SIGMA_ROLEがcustomerテーブルにもアクセスできるこを確認.
select count(*) from transactions;
6. Sigmaで分析&可視化
QuickstartではSnowflakeのPartner Connectを利用しているので接続先情報も出来上がっている状態ですが、当エントリの手順では別途接続を作成する必要があります。実際にやってみましょう。
Sigmaの画面左上、ユーザーアイコンのメニューから[Add connection]を選択。
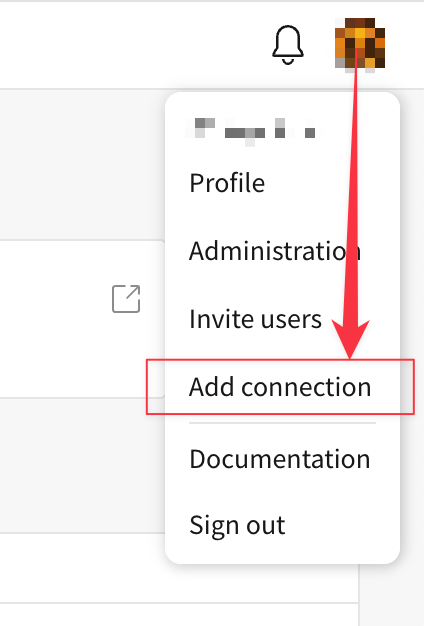
接続名(Name)に任意の名称、接続タイプ(Type)にSnowflakeを指定。ここでは接続名をshinyaa31_snowflake_plugs_electronicsとしました。

Connection Credentialsの各種項目に前述手順で指定・作成した値を入力。
- Account:Snowflake接続先アカウント名
- Warehouse:前述手順で作成したウェアハウスの名称
- Authentication:任意の接続方法(ここではユーザーアクセスする際の手法と合わせました)
- User:前述手順で各種要素を作成したときに用いたユーザー
- Password:上記ユーザーのアクセス時に用いたパスワード
- Role:前述手順で作成したロールの名称

ちなみに認証方法は以下のように「Key Pair」「OAuth」「Basic Auth」の3つが選択可能です。情報が入力できたら[Create]押下。

接続が作成されました。[Browse connection]を押下。
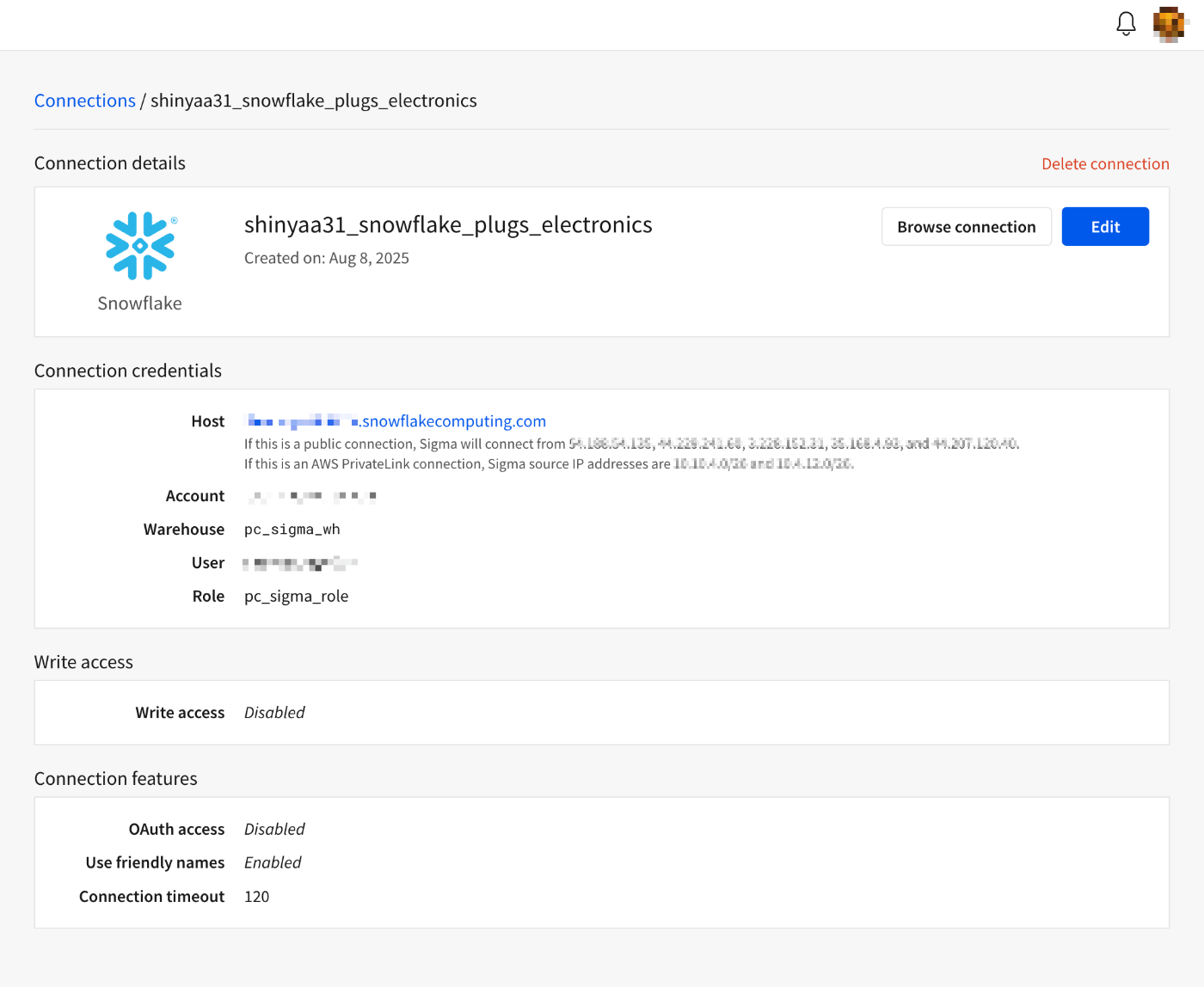
接続の詳細が表示されます。ここから、接続に対するユーザーアクセスの設定を行います。表示されているいずれかの[Grant Access]ボタンを押下。
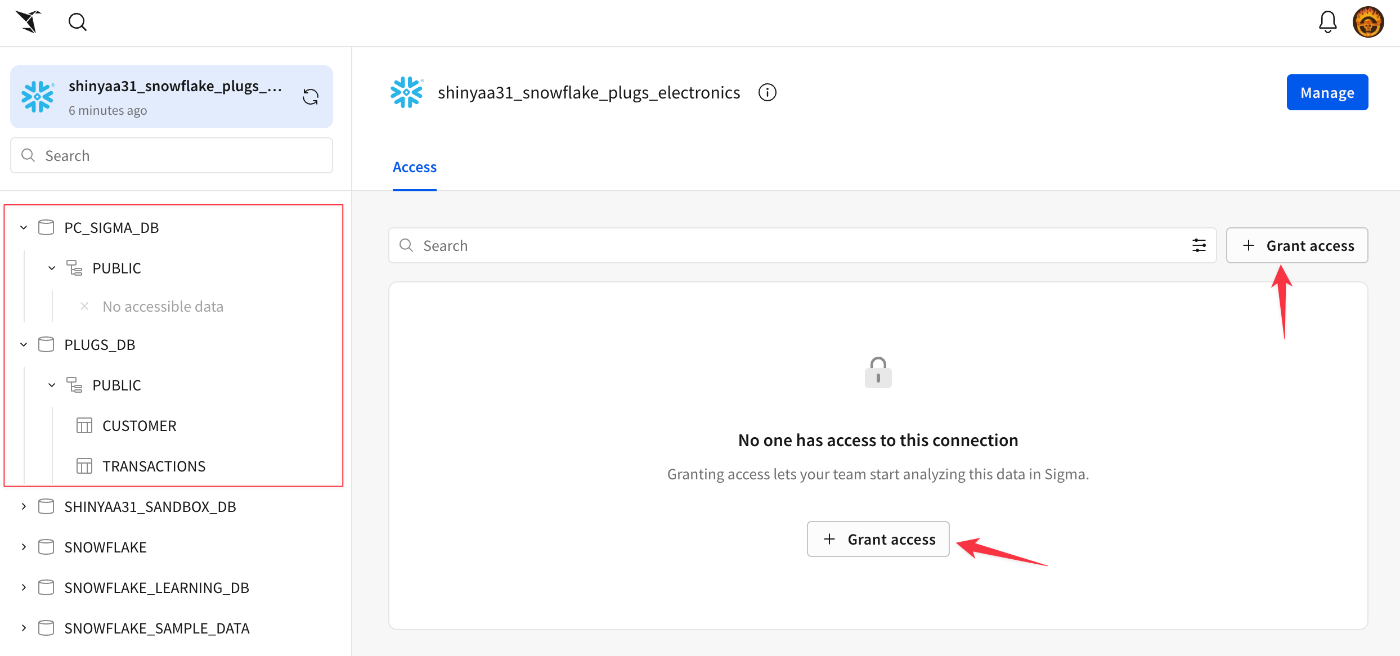
接続に対するユーザー(毎)の権限を設定する画面に遷移。この時実施した手順では複数メンバーで一括してアカウントを取得、組織としてトライアル環境を準備していたので関連するメンバーの名前も併せてラインナップされていました。選択肢の一番上「All users〜」を選べばこの接続を全てのユーザーが何らかアクセス出来るようになる、という形です。Sigmaのデータアクセスに関する詳細は下記ドキュメントをご参照ください。

ここでは一旦、自分だけがアクセス出来る形としました。操作できる権限は以下のように任意の強度を選べます。
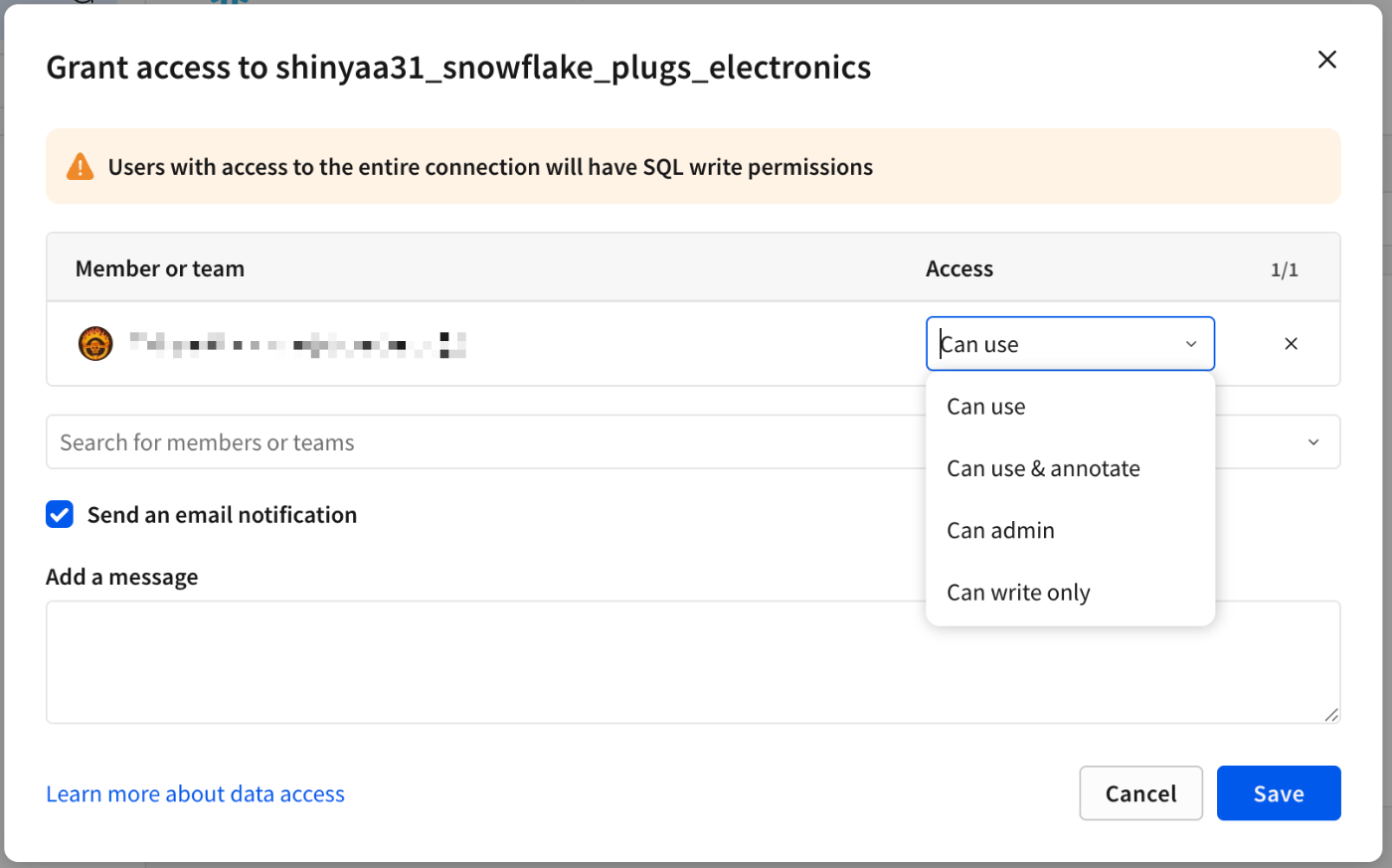
[Save]押下で設定完了。

画面左側のSnowflakeオブジェクト一覧から、前述手順で用意したデータベース・テーブルにアクセスしてみます。比較的早いレスポンスでデータ内容を参照することが出来ていました。


7. Sigmaデータモデリング実践 - Sigmaデータモデルの作成
Sigmaのデータモデルは、一元化されたデータ定義を構築し、データ探索をガイドする柔軟な方法です。Sigmaは、管理制御と、新しいデータの検索、追加、そして信頼の自由度を両立させています。データモデルはワークブックのデータソースとして機能します。
Sigma は、テーブル、他のデータモデル、CSVアップロード、またはデータモデル内の独自のSQLを結合する機能を備えています。このセクションでは、テーブルを結合してデータモデルを構築する方法と、Sigma UI内で半構造化JSONデータを操作する方法について進めていきます。
Sigma UIの左上にある小さな鶴(?)のアイコンをクリックすると、ホームページに移動します。

Sigmaの各種作業で参照することになるデータ定義=データモデル(Data model)を作成していきます。ページ左上の[+Create new]から[Data model(データモデル)]を選択。

データモデルの"柄"だけ作成されたようです。画面下部の[Data]→[Table]を選択。

ここでは前述手順で用意した2つのテーブル、TransactionsとCustomerを結合したものをデータモデルとして作成していきます。ダイアログ下部の[Join]を選択。

まずは1つめのテーブル、結合元のテーブルとしてTransactionsを指定します。カラム選択などはデフォルト指定のままでOKです。[Select]押下。

GUI画面が出てきました。併せて現行のTransactionテーブルの中身もプレビュー出来ています。画面左上の[+Add source]を選択。

結合対象のテーブルとしてCustomerを指定、[Select]押下。

2つのテーブルを結合する際の条件を編集する画面に遷移します。ここは結合方式は[Left outer join]のまま、結合キーを共に[Cust Key]としてください。出来たら画面右上の[Preview output]を押下。

2つのテーブルが指定した項目で結合され、出力結果もそれに沿った形の内容がプレビューされていることを確認出来ました。[Done]押下。

Sigmaでは列レベルの編集加工も様々な処理が行えます。[Cust JSON]の中身はJSON形式となっていますが、この内容から指定の項目値を抜き出す(JSON 内のキーと値のペアを抽出する)ことも出来ます。Cust JSON ヘッダーのドロップダウンを選択し、[Extract columns]を選択。

抽出したいキーと値のペアを選択。ここではAGE_GROUP、CUST_GENDER、LOYALTY_PROGRAMの3フィールドを指定しました。[Confirm]押下。

指定の項目値が抽出され、結果に追記される形となりました。併せてここまでの加工結果にも内容に即した名称を与えました。

データモデルの名称も任意の内容に変更可能です。
データモデルが出来上がりました!

作成したデータモデルはSigmaメニューの[My documents]から参照・アクセス可能です。
8. Sigmaでデータアクセス - ワークブックの作成
続いてSigmaワークブックの作成に取り掛かります。
Sigmaにおける ワークブック(workbook) とは、データ・UI・コントロール要素を追加し、カスタマイズ可能な分析・レポート作成用の作業スペースです。
ワークブック内では、表やチャートの作成、データアプリや埋め込み分析の追加などが可能で、ExcelやGoogle Sheetsのようなスプレッドシート感覚で直感的に操作できます。この項ではそのワークブックを作っていきます。
ページ左上の[+Create new]から[Workbook(ワークブック)]を選択。

画面下部メニューの[Data]→[Table]を選択。
参照するデータモデルを選ぶことが出来るようになります。ここは前述手順で作成したデータモデルを選択してみます。

更にデータソースを選択。

内容がスプレッドシート形式で表示されました。[Save as]でワークブックとして保存しておきます。

保存完了。作成したコンテンツはSigmaメニューの[My documents]から参照・アクセス可能です。

保存場所とワークブック名を指定して[Save]押下。

Sigma はスプレッドシートのようなインターフェースを備えており、保有するデータの概要を素早く把握し、ワークブックやデータモデルを迅速に開発できます。一般的なビジネスユーザーは、Sigmaのワークブックを使用して、ガバナンスが確立された安全な方法でデータの探索やセルフサービスを行うことができます。
スプレッドシート風のインターフェースを有するSigma は、ユーザーが既に使い慣れているスプレッドシートというインターフェースで分析を行えるという点で他に類を見ません。スプレッドシートでよく使われる関数も使用できます。Sigmaインターフェースは、ユーザーのすべての操作を自動的に、そしてバックグラウンドで最適化されたSQLに変換するため、SQLの知識は必要ありません。このインターフェースは、特に技術に詳しくないビジネスユーザーにとって、ユーザー導入と成功のスピードアップに役立ちます。
9. Sigmaでデータ分析
この項では、ここまでで準備したコンテンツを活用する形で分析作業を進めていきます。大きく2つのステップに分かれています。
- ワークブック(Workbooks)を活用した分析
- 可視化(Visualizations)を作成
ワークブック(Workbooks)を活用した分析
ここでは、架空の企業であるPlugs Electronicsのデータを見ていきます。
このデータには、全国の店舗における小売取引データと、購入に至る顧客に関する属性が含まれています。計算式の作成、テーブルの結合、JSONデータの解析、そして可視化(Visualizations)の構築を行い、最終的には地域営業マネージャーが各店舗のパフォーマンスに関するインサイトを得られるダッシュボードを作成して組み込むことを目指します。
[My documents]の中から、先程作成したワークブックを選択。

ワークブックが表示されました。[Edit]をクリック。

ワークブックが編集出来るようになりました。Cost列の上にある列ヘッダーを選択し、[Add new column]を選択。

数式を書くことができる数式バーが表示されます。ここでは[Quantity] * [Cost]と入力し、Enterをクリックして売上原価を求めます。

列のヘッダーをダブルクリックして、列の名前を「Cogs」に変更します。
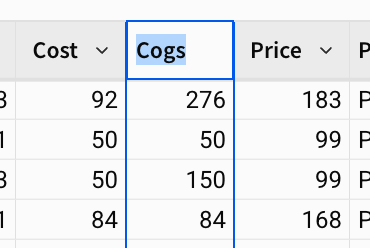
列を通貨に変換するといったフォーマットの変換も行えます。
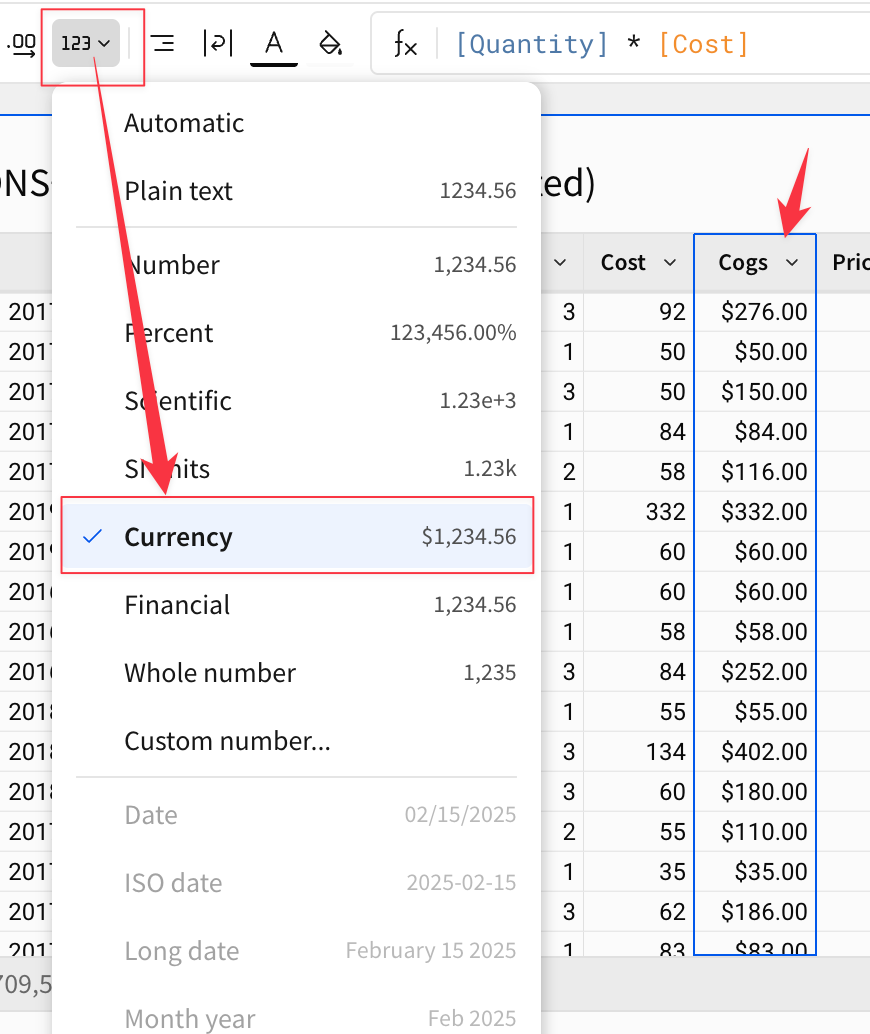
上記で作成したものはシンプルな関数でしたが、数式バーの左側にある「ƒx」アイコンをクリックすると、シグマがサポートしているすべての関数の一覧を見ることができます。また、シグマは数式バー内に便利なツールチップとオートコンプリートを表示し、関数の使い方をユーザーに案内します。

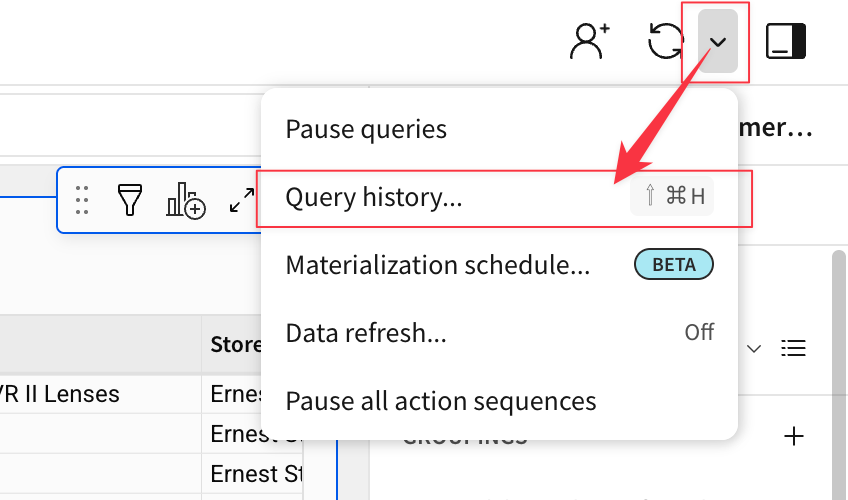
Sigmaで行うすべてのアクションは、生成されたANSI準拠のSQLを生成し、Snowflakeにプッシュされるため、データは常に安全で最新の状態に保たれます。Sigmaは、クラウドデータソースからデータを抽出したり、クラウドデータソースのデータを変更したりすることはありません。Sigmaが生成しているクエリは、右上の更新ボタンの横にあるドロップダウンをクリックし、"クエリ履歴 "を選択することで確認できます。

次いで、Price列の上にある列ヘッダーを選択し、[Add New Column]選択。

数式を書くことができるファンクション・バーが表示されます。[Quantity] * [Price]と入力し、編集を反映します。

列のヘッダーをダブルクリックして、列の名前を Revenueに変更、表示形式も通貨形式に変更します。

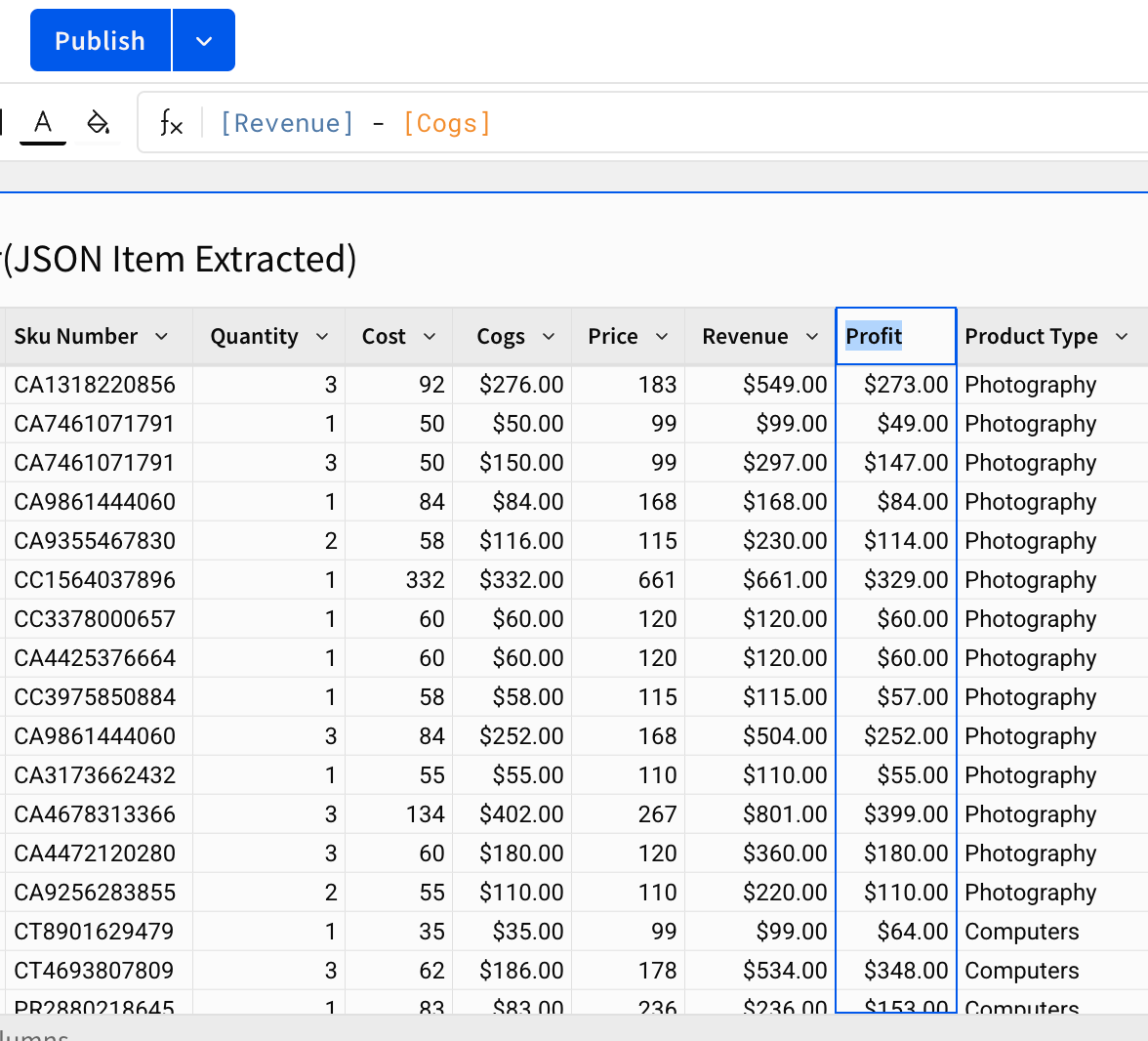
更に、列のヘッダーを選択し[Add New Column]を選択、もう1つ列を追加します。
数式を使って[Revenue] - [Cogs]と入力し、Profitを作成。
可視化(Visualizations)を作成
データを可視化することで、傾向や異常値、あるいはさらなる疑問へとつながる洞察を発見しやすくなることがよくあります。Sigmaでは、データの可視化(Visualization)を簡単に作成することができ、同時にその可視化を構成するデータを詳しく調べることもできます。
棒グラフを作成(州毎の利益を利益の高い順に表示)
可視化(Visualization)の作成を開始するには、先ほど作成した表の右上にある グラフアイコンから[Chart]選択。

テーブルの下にビジュアライゼーションが追加されます。左側のバーには、サポートされているすべてのビジュアライゼーションがリストされたドロップダウンが表示されます。

ビジュアライゼーションの領域を選択すると画面右側に編集メニューが表示されます。
棒グラフ(Bar)を選択されていることを確認し、X軸(X-axis)にあるでプラスボタンクリック。検索窓にStore Stateと入力します。すると以下のように追加したい列を検索することができます。Store Stateを選択。

画面右下にある[ADD COLUMN]配下にある項目要素を軸エリアにドラッグすることでも項目追加が行えます。Profit列をそのように操作すると、
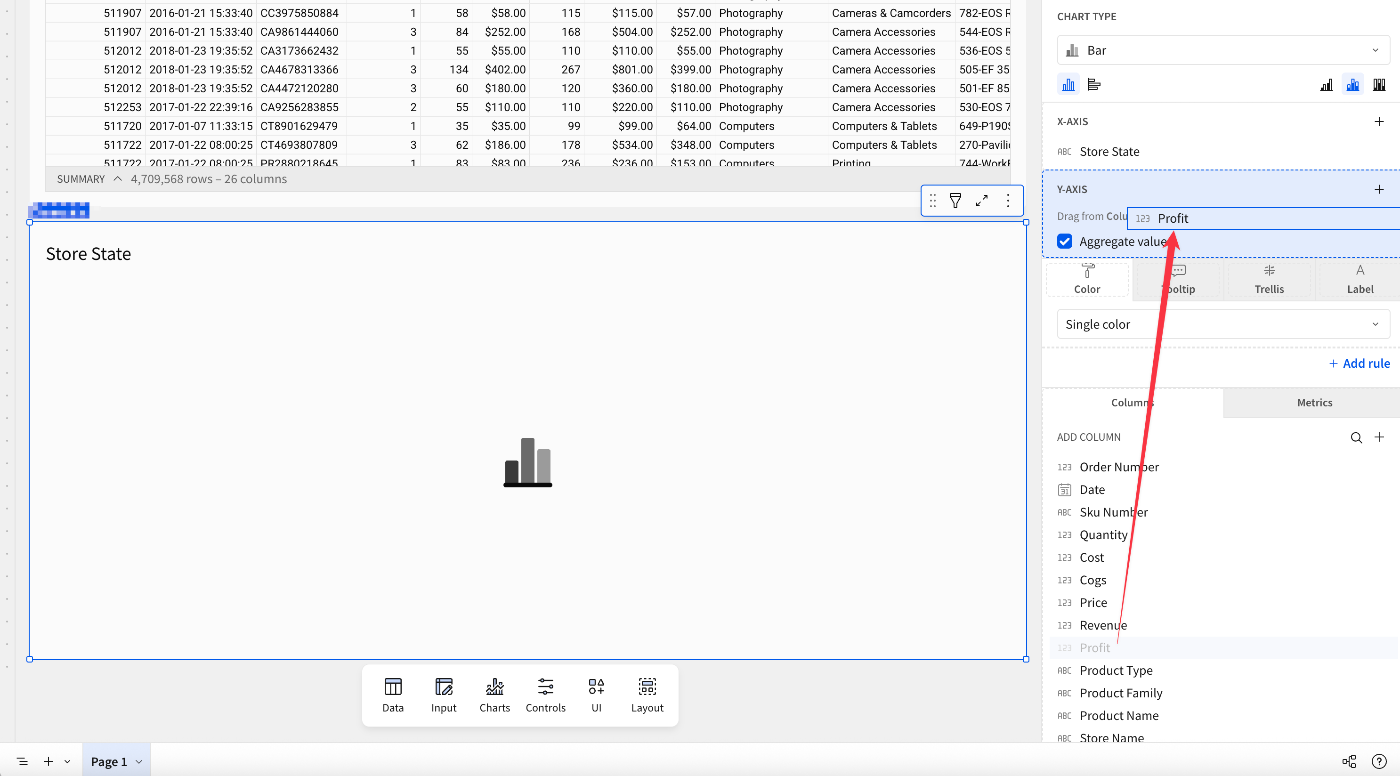
値が自動的に集約され、利益の合計(Sum of Profi)となり、X軸に設定したStore Stateの要素を踏まえた棒グラフが生成されました。

グラフの右上にある3点メニューから展開される[Sort]で、グラフ値の並び替えを行えます。Sum of Profitを選択すると下記のようにX軸の値の並びがSum of Profitの降順になりました。

線グラフを作成(売上高を時系列で表示)
次いで新たなビジュアライゼーションとして『売上高を時系列で表す線グラフ』を作成します。先程同様に子要素として[Chart]を追加。

領域が追加されましたが、どうせなら線グラフの下に配置したいですね。

要素はドラッグアンドドロップでの移動が可能です。追加された領域を線グラフの下の方に持っていきます。

領域自体は移動出来ました。空いたスペースは[Trim Space]で除去出来ます。

線グラフは同様に個別作成したデータソースを使って行います。Chart TypeにLineを選択。

X軸にDateを指定。Sigmaの自動判別でDay of Date(Dateの日付表示)と認識されます。ここでは月単位の表示としたいと思います。項目メニューから[Truncate Date]→[Month]と指定。
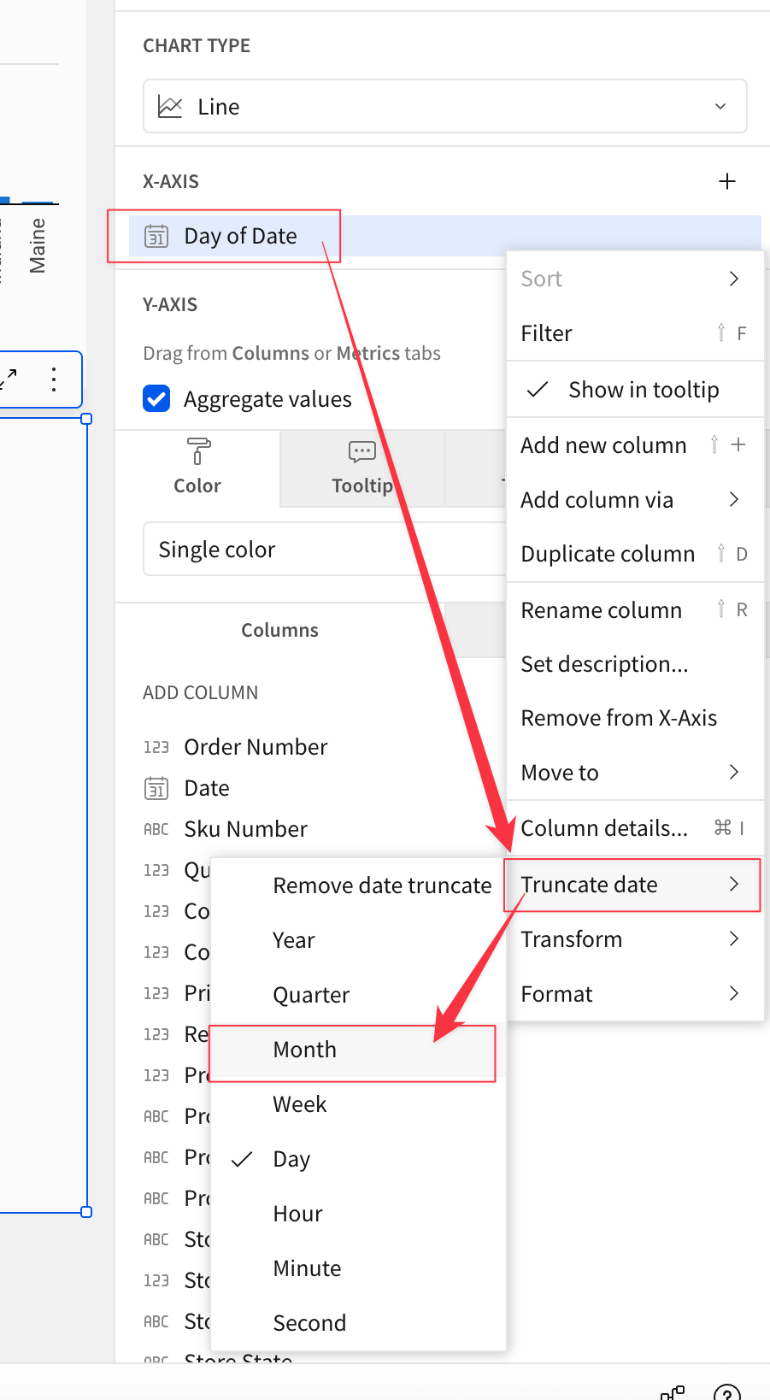
項目表記がMongh of Dateに変わりました。

Y軸にRevenueを指定。すると以下のように線グラフが時系列(月単位)で表示されるようになりました!ただこれだとシンプルに売上高の時系列遷移を表示しただけです。もうちょっと細かく見ていきたいですね。

ということで、地域毎の遷移を見る形にしていきたいと思います。[Color]タブで表示方法を『カテゴリ毎(By category)』に変更。

[SELECT COLUMN]を選択し、[Store Region]を指定。

売上高の表示が地域(Store Region)ごとに表示される形となりました。

棒グラフを作成(製品ファミリーの顧客数を店舗地域毎に表示)
顧客と地域の情報を使って『製品ファミリーの顧客数を店舗地域毎に表示』するビジュアライゼーションを追加します。
新しいチャートを追加し、チャートのタイプを棒グラフ、X軸に製品ファミリー(Product Family')、Y軸に顧客キー(Cust Key`)を追加。

顧客キーのプルダウンから[Set Aggregate]→[CountDistinct]を選択。棒グラフの数値が顧客数での表示になりました。

顧客を地域別に分けてみましょう。「店舗地域」をカラーセクションにドラッグします。この状態だと積み上げ状態(Stacked)になっているので表示方法を切り替えます。

積み上げ状態の変更は「表示形式:棒グラフ」の近くにあるアイコンを押下することで行えます。左から
- No Stacking(積み上げ無し)
- Stacked(積み上げ
- Stacked 100%(100%積み上げ)
といった形に切り替え可能です。左のNo Stackingを押下することで製品ファミリーごとの顧客数が店舗地域毎に色分け表示されるようになりました。

ピボットテーブルを作成(顧客ファミリー毎の利益を性別ごとに表示)
最後に、顧客属性に基づいたピボットテーブルを作成します。新しい要素でピボットテーブル(Pivot Table)を選択。

Product Familyをピボット行に、CUST_GENDERをピボット列に、Profitを値セクションに指定して出来上がりました。ワークブックの名前もここまでの作業内容を反映したものに変更しておきました。

10. ワークブックのファイナライズ
フィルタの追加
この項では、作成したワークブックにフィルタを追加してみます。ワークブック全体に対するフィルタは、コントロール・エレメントをキャンバスに追加することで行います。
ここは日付範囲のフィルタを作成してみます。画面下部のメニューから[Control]→[Data Range]を選択。

日付範囲コントロールの要素が生成されます。画面右側の編集メニューにてControl IDに任意の値を指定。
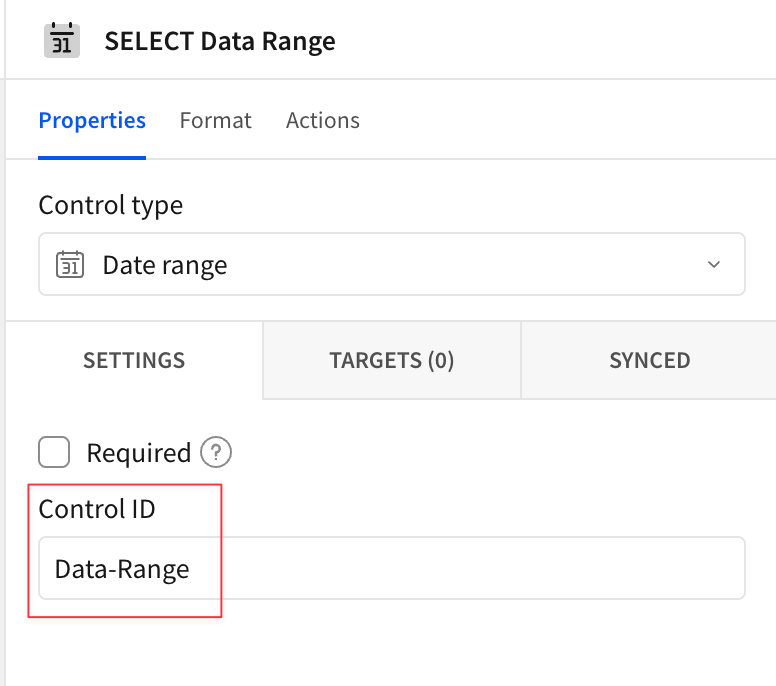
またラベルにも任意の文字列を指定しておきます。

フィルタを適用するターゲットも指定します。[Targets]タブにて、今回作成したデータモデルを指定。これで日付範囲の効果がデータモデル(及び該当するデータモデルを使っている要素)に影響するようになります。

試しに日付範囲を指定してみます。いい感じにデータが絞り込み表示されました。

追加できるフィルタには他にも色々あります。詳細は下記ドキュメントをご参照ください。
フィルタは個別のチャートから展開していくこともできます。試しにピボットテーブルにある"Store State"列に対してやってみましょう。列のドロップダウンから[Filter]を選択。

フィルタのダイアログが表示され、件数表示の棒グラフと併せて絞り込みが行えるようになっています。試しに"California"のみ指定。

同じように"Store City"に対してもフィルタリングしてみます。フィルタが追加されました。

ここまでの状態だと単一の要素(今回はピボットテーブル)に対するフィルタリングが効いている状態です。全体に対して効かせたい場合はこのフィルタを"昇格"させることができます。3点メニューから[Convert to page control]を選択。
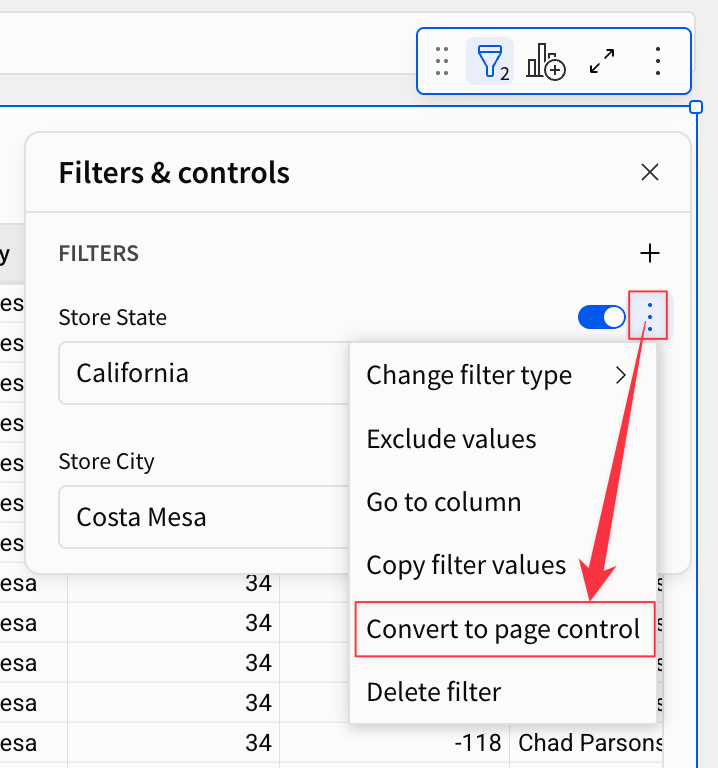
ページ上部にフィルタが移動し、絞り込みを全体に効かせられるようになりました。

キャンバスをきれいにする
この項では、作成したコンテンツをより洗練したものにする幾つかのtipsを紹介します。手始めに、ベース・データ・テーブルを別のページに移動してみます。これは、テーブルの右上にある3点メニューから[Move to page]→[New page]と指定することで実現できます。
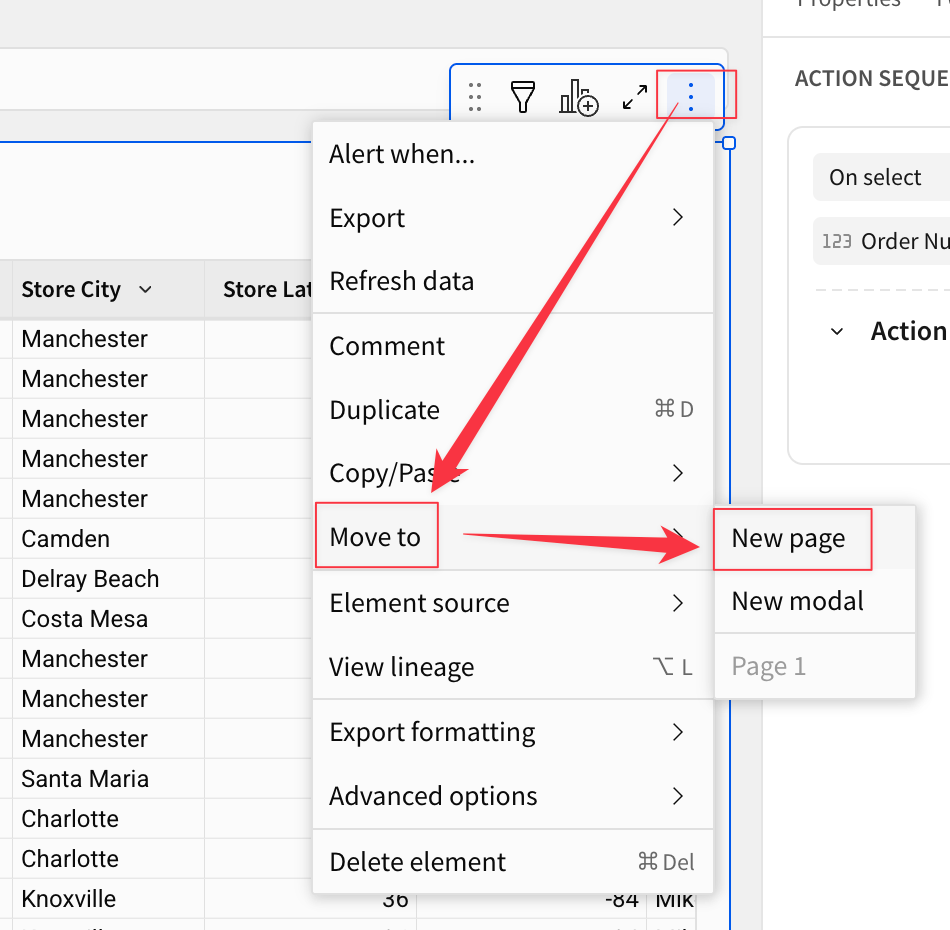
新たなページが作成され、コンテンツの移動が完了しました。

各ページのタブは名称を変更可能です。1ページ目は[Visual]、

そして2ページ目は[Data]に変更しておきました。

キャンバス上の要素のレイアウトを自由に変更することも出来ます。試しにタイル状に各チャートを並べてみます。キャンバス上の要素をそれぞれドラッグアンドドロップで移動させ、

サイズもそれぞれいい感じに微調整していきます。(要素の端っこを摘むことでサイズ変更も可能です)

キャンバス上の各種要素をいい感じに並べ替えることができました。

ワークブックに追加できる各種要素
ここまでの手順でSigmaのワークブックに色々とコンテンツを追加・編集してきました。Sigmaのワークブックには様々な種類の様々な要素を追加する事が可能となっています。ここではメニューベースでどういったものがあるか眺めてみたいと思います。
データ(Data)

- Table
- Pivot Table
インプット(Input)

グラフ(Charts)

- Bar (棒グラフ)
- Line (線グラフ)
- Combo (複数チャートの組み合わせ)
- Area (面グラフ)
- KPI (KPI:重要業績評価指標)
- Dount (ドーナツチャート)
- Pie (パイチャート)
- Scatter (散布図)
- Box (箱ひげ図)
- Waterfall (ウォーターフォールチャート)
- Sankey (サンキー・ダイアグラム:工程間の流量を表現する図)
- Funnel (ファネルチャート:プロセスにおける段階ごとの変化を視覚的に表示)
- Gauge (ゲージグラフ)
- Region (地理情報:地域)
- Point (地理情報:ポイント)
- Geography (チリマップ)
コントロール

- List Values (リスト値)
- Text Input (テキスト入力)
- Text Area (テキストエリア)
- Segmented (セグメントコントロール)
- Date (日付)
- Date Range (日付範囲)
- Number input (数値入力)
- Number range (数値範囲)
- Slider (スライダー)
- Range Slider (範囲スライダー)
- Switch (スイッチ)
- Checkbox (チェックボックス)
- Top N (上位N)
- Drill down (ドリルダウン)
- Legend (凡例)
詳細は以下参照。
UI
レイアウト

- Container (コンテナ)
- Tabbed container (タブ付きコンテナ)
- Model (モデル)
- Popover (ポップオーバー)
11. Quickstartまとめ
このQuickstartでは、SnowflakeとSigma(いずれもトライアル環境)でSigmaの実践を進めていくプロセスを行いました。Snowflakeの外部ステージを活用し、データをテーブルにコピーしました。最後に、軽いモデリングと分析を行い、「セールスパフォーマンス」ダッシュボードを作成しました。
SnowflakeからSigmaへのシームレスな移行は、データ専門家が迅速かつ容易に反復することを可能にします。これにより、Sigmaは堅牢なクライアント向けツールを提供するだけでなく、データエンジニアがSnowflakeに取り込まれたばかりのデータをプロファイリングし、実験するための素晴らしいサンドボックスにもなります。
- 実践した内容
- Snowflake無料トライアルへのサインアップ
- Snowflakeへのサンプルデータのロードと環境設定
- Sigma無料トライアルへのサインアップ、環境設定
- Snowflake でサンプルデータをモデル化するSigmaデータモデルの構築
- サンプルデータを分析する洗練されたシSigmaワークブックの構築
- 参考リソース
まとめ
という訳で、Snowflake社が提供・展開するSigmaとの連携実践チュートリアル『Getting Started with Sigma』の紹介でした。この内容をお読み頂き、また読みながら実践を進めて頂きありがとうございます(&長丁場お疲れ様でした)。
一連のステップをそれぞれ(読み)進めていく事で、Sigmaがどういうものなのか、Sigmaでどういう事が出来るのかの一旦を垣間見る事が出来たのではと思います。私自身も一通り作業を進めていく中でSigmaを理解・把握することが出来たと思います。引き続きSigmaに関する実践及び実践内容の紹介は行って参ります。その際は改めてエントリをお読み頂けますと幸いです。
