バイブコーディングでMCPサーバーを開発した
はじめに
個人的に最近はMCPサーバーに興味があり、触っています。界隈の注目度の高さもありますが、現状AI活用を考える上で機能拡張するのは必須だと思っており、そこに対して有力なアプローチがMCPだと思っているのも興味がある理由です。
上述の記事でもZennの記事フィードを取得するMCPサーバーを作っており、今回は個人ではてなブログのMCPサーバーを作りました。はてなブログへの記事の投稿・更新・記事の取得ができます。
また、バイブコーディングにも興味があり、どうせ作るならバイブコーディングで作ってみようということで、Claude Codeに計画〜実装〜レビューを任せるスタイルで開発をしました。
成果物
以下の5つのツールからなるMCPサーバーです。
-
hello_world: テスト用 -
create_blog_post: 新規記事投稿 -
update_blog_post: 既存記事の更新 -
get_blog_post: 記事の取得(ID指定) -
list_blog_posts: 記事一覧の取得 -
create_blog_post_from_markdown: Markdownファイルから記事投稿
開発方針
ディレクトリ構成
hatena-mcp-server/
├── .env # 環境変数(本番用設定)
├── .gitignore # Git除外設定
├── .python-version # Python バージョン指定
├── CLAUDE.md # Claude Code 開発指示書
├── README.md # プロジェクト説明
├── main.py # エントリーポイント
├── pyproject.toml # プロジェクト設定・依存関係
├── uv.lock # 依存関係ロックファイル
│
├── .kiro/ # Kiro開発フレームワーク
│ ├── steering/ # プロジェクト全体指針
│ │ ├── product.md # プロダクト要件・目標
│ │ ├── structure.md # ファイル構造・コード規約
│ │ └── tech.md # 技術スタック・アーキテクチャ
│ ├── specs/ # 機能仕様書
│ │ └── hatena-blog-mcp-server/
│ │ ├── requirements.md # 要件定義書
│ │ ├── design.md # 設計書
│ │ ├── tasks.md # タスク管理
│ │ └── spec.json # 仕様メタデータ
│ └── development-learnings.md # 開発学習ログ
│
├── .claude/ # Claude Code 設定
│ ├── settings.json # MCP設定
│ ├── settings.local.json # ローカル設定
│ └── commands/ # スラッシュコマンド
│ ├── init_serena.md # Serena MCP初期化
│ └── kiro/ # Kiro コマンド群
│ ├── spec-init.md # 仕様初期化
│ ├── spec-requirements.md # 要件定義
│ ├── spec-design.md # 設計フェーズ
│ ├── spec-tasks.md # タスク生成
│ ├── spec-status.md # 進捗確認
│ ├── steering.md # 全体指針管理
│ └── steering-custom.md # カスタム指針
│
├── src/ # ソースコード
│ └── hatena_blog_mcp/
│ ├── init.py
│ ├── server.py # MCP サーバーメイン
│ ├── auth.py # WSSE 認証
│ ├── blog_service.py # ブログ操作サービス
│ ├── config.py # 設定管理
│ ├── error_handler.py # エラーハンドリング
│ ├── http_client.py # HTTP クライアント
│ ├── markdown_importer.py # Markdown インポーター
│ ├── models.py # データモデル
│ ├── rate_limiter.py # レート制限
│ ├── service_factory.py # サービスファクトリ
│ └── xml_processor.py # AtomPub XML 処理
│
└── tests/ # テストコード
├── unit/ # ユニットテスト
│ ├── test_auth.py
│ ├── test_blog_service.py
│ ├── test_config.py
│ ├── test_http_client.py
│ ├── test_markdown_importer.py
│ ├── test_models.py
│ ├── test_rate_limiter.py
│ ├── test_server.py
│ └── test_xml_processor.py
└── integration/ # 統合テスト
├── test_api_communication.py
└── test_mcp_tools_e2e.py
技術スタック
- 言語: Python 3.12
- パッケージ管理: uv
- フレームワーク: FastMCP
- HTTP通信: httpx (非同期)
- XML処理: lxml (AtomPub用)
- データ検証: Pydantic
- テスト: pytest + pytest-asyncio
- 型チェック: mypy
- リント/フォーマット: Ruff
- 認証: WSSE Authentication
- プロトコル: AtomPub (Hatena Blog API)
Kiroスタイル
Kiroは、Amazonが開発したAIエージェント型IDEであり、VS Codeをベースにしています。
最大の特徴は、従来のAIコーディング支援をさらに一歩進めた「スペック駆動開発」を取り入れている点です。
単なるコード生成ツールではなく、要件定義(スペック)、デザイン、タスクの明確な分解といった開発プロセスをAIが効果的に支援します。
https://note.com/masa_wunder/n/nf1183852a1df
KiroはAIエージェントが組み込まれたIDEになっており、以下のような流れでスペック駆動開発を行っていきます。
- ユーザーがやりたいことを自然言語で入力
- → 入力内容を元にエージェントが
requirements.md(要件や受け入れ条件が記載された仕様書)を作成 - →内容に問題なければ次のステップに進み、エージェントが
design.md(技術スタックやアーキテクチャ、ロジックが書かれた設計書)を作成 - →内容に問題なければ次のステップに進み、エージェントが
tasks.md(実装する際のタスクリスト)を作成 - →内容に問題なければ実装開始
- プロジェクトの長期記憶として
Steeringがあり、以下の文書が生成される-
project.md: プロダクト要件・目標を定義 -
tech.md: 技術スタック・アーキテクチャを記載 -
structure.md: ファイル構造・コード規約を記載
-
スペック駆動開発の利点として、その場その場のプロンプトに比べてより複雑なプロダクトを開発できるという利点があります。最初に要件や設計、タスクを文書化させるので、全体像を追いやすく、AIがスムーズに開発できます。
Kiroを使えば簡単にスペック駆動開発ができるのですが、2025/8/19時点ではサブスクリプション制でクレジットのコスパが悪いという意見があります。
私が開発していた時点ではまだ正式にリリースされていないこともあり(サブスクが始まっただけで公式から正式というアナウンスはないらしい)、Claude CodeでKiroのスタイルを踏襲して開発しました。
ありがたいことに同じことをやっている先人がいたので、それを参考にしています。
こちらのリポジトリから拝借させていただきました。(ありがとうございます!)
以下のファイルを拝借させていただきました
-
.claude/commands/: Slash Commandsの定義 -
CLAUDE.md: Claude Codeの設定とプロジェクト指示。CLAUDE.mdについては、これをベースにしつつ開発中に追記しています。(全文英語なこともあり、実はちゃんと細部を読み込まず必要に応じて追記だけしてました……)
ディレクトリ構成の.kiro/配下のファイルはKiroスタイルで作成された各種ドキュメントです。
実装の流れも、上述したようなスペック駆動開発で行っています。
development-learnings.mdだけはKiroとは関係なく作成しています。開発をする中での細かい方針転換や学びをログとして残しておきたいなと思って作成したファイルです。AIに出力してもらってます。
利用したMCP
私の場合はユーザースコープ(=ローカルのどのプロジェクトでも利用可能)にSerenaとContext7を追加して利用できるようにしています。他にもMCPサーバーを入れているのですが、この開発で使ってそうだったのはこれだけだと思います。
Context7はフレームワークやライブラリについて最新のドキュメントを参照できるようになるMCPサーバーなのですが、MCPサーバーが不安定で度々Connection Errorが発生していたので、あまり活用できてないです。(原因あまりわかってないです……)ただ、今回の開発ではContext7がなくてもそこまで不便を感じなかったです。
Serenaはプロジェクトやワークスペース全体を把握してくれるMCPサーバーで、直近のClaude Code性能劣化事件(?)があったときに話題になったものです。エージェントの性能が底上げされたりコンテキストの消費量が抑えられたりというメリットがあるみたいです。私もSerenaを使う方が性能が上がる印象を受けました。
細かい話ですが、Serenaを入れるとClaude Code起動時に毎回ブラウザのタブが開くのですが、途中からこれを設定で開かないようにして使っていました。毎回画面遷移して面倒だったので快適になりました。
参考記事↓
Claude Code Action

Github上でレビューをしてもらうために導入しています。
私はGoogle CloudのVertexAIを使ってClaude Codeを動かしていたので、Claude Code ActionもVertexAI経由で設定しています。
設定方法ついては別途記事を書いているので、気になる方は見てもらえればと思います。
MCP Inspector

MCP InspectorはMCPサーバーをブラウザでテストするための開発者ツールで、この開発でも利用しています。
エージェントが単体テストや結合テストをするのとは別に、私自身がブラウザを開いて挙動確認する時に使っています。
開発の流れ
おおよそ以下の流れで行いました。
タスクの区切りごとにブランチを作成し、プルリクエスト→レビュー→マージの流れで開発しています。
基本的にエージェント主導で計画〜実装を行っています。
- プロジェクトの初期設定
- CLAUDE.md
- Kiroで仕様書、設計書、タスクリストを整備
- Claude Code Actionの設定
- Steeringの文書もここで作成
- 認証・通信周りの実装
- WSSE認証マネージャーの実装
- HTTP クライアントとAtomPub XML処理インフラ構築
- はてなブログAPI との通信層確立
- メイン機能の実装
- 記事投稿
- 記事更新
- 記事取得
- MCPツール化
- Markdownインポーターの機能追加
- MCPツールの統合
- 最終調整
- 筆者がMCP Inspecotorで挙動確認し、エラー対処
- このパートのみ、AI主導ではなく筆者起点で対話的に実装
実際の開発体験
今回は完全に個人の趣味だったこともあり、なるべくバイブコーディングでやり切るというスタンスでやっていました。
はてなブログの自動投稿や記事取得についてはテックブログや実装コードがたくさんあり、正直1からバイブコーディングするよりも既存コードをベースに少し改変する方が早かったと思います。ただ、バイブコーディングの感覚を養うことを優先し、できるだけ自然言語ベースで実装をしました(とはいえ、時々ソースコードを参照させたりはしました)。
以下、多少雑多になってしまいますが開発時の所感を箇条書きにしています。
全体的な所感
- Serenaを自動で使ってくれない
- 突然重くなって全然処理が終わらなくなることがある
- コンテキストが少なくなるとこの現象に陥りがち:コンテキスト減ってきたら状況をドキュメントに記録して再起動しているが面倒&原因分からず……
- uvも時々使ってくれない:
design.mdに記載があるが、時々python ~コマンドを使おうとするのでこちらから追加指示を出していた - ドキュメントは可読性の面で日本語で作りたい
- 今回は有志の
CLAUDE.mdをそのまま使ったというのもあるが、作成ドキュメントは一通り確認したいため日本語(母国語)の方がストレスが少ない
- 今回は有志の
- Kiroのドキュメンテーションと管理は悪くないが、細かいルールは自分で設計して足すのがベター
- Kiroで仕様や設計、タスクリストを作成
- そこにブランチルール、MCPの利用ルール、細かい開発の作法などを自分で足すと快適かも
- 実装し始めてから「ここ違くね?」と思うような箇所が出てきがちなので、状況見てドキュメントを柔軟に変更するマインドを人間もAIも持つ方が良さそう
GPT-5との比較
- 開発の一部分をGPT-5(Cursor CLI)で使ってみた
- GPT-5の方がより少ない指示で意図を組んで実装してくれる感じがした
- MCPなしのGpt-5≒MCPありのSonnet4という体感
- スピードは圧倒的にClaude Code
- (Cursor CLIの使い勝手がイマイチ……)
- Claude Codeでメイン実装→GPT-5で修正してプルリクの流れを試した
- 体感、Claude Codeのミスをいい感じに発見してくれる
- Claude Codeのコンテキストが汚染されてそうな時とか良いかも
MCP Inspectorでの調整
- 機能実装が一通り済んだらMCP Inspectorで挙動確認して仕上げる
- ここで大体エラーが出る
- ここはかなり対話的な作業になる
- 場合によって機能を作りすぎてエラーが出ていたりするので、基本的にはよりシンプルにするように変えることが多い:オプション的な機能はオミットしていく
- オミットしたもの
- 下書きで記事投稿する機能
- ブログ投稿時のsummaryフィールド:実際に活用されてるのか曖昧だったので無くした
やってないこと
- thinkingモードとの使い分け:毎回判断して指示するのが面倒
- Opusの使用:VertexAIでSonnetしか解放してなかったため使ってない
- サブエージェント:Claude Codeのバージョンを落としていた都合で使えてない
- 並列実行:認知負荷高いのでやってない
作成したMCPサーバーを使ってみる
今回は、ローカルのマークダウンファイルから記事を作成しました。
- MCPクライアント:Cursor
- MCPサーバー:hatena-mcp(今回開発したもの)
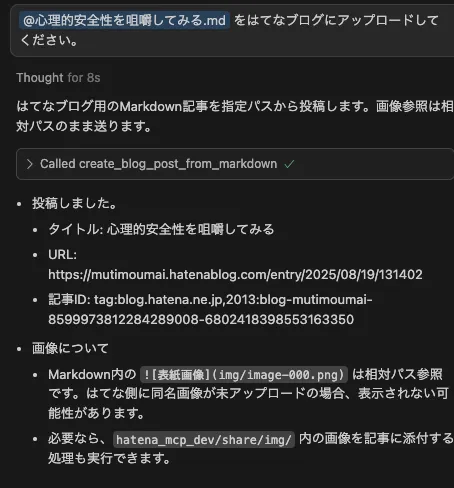

実際の記事はこちらです(全然テック系じゃないですが、気になる方がいれば読んでいただけると嬉しいです!)
使用感
箇条書きで記します。
- 基本的にはいい感じ
- 画像のアップロードができないのがネック
- はてなフォトライフのAPIを使えば可能らしいが、結局ローカルでファイル作成するときにはてなフォトライフに画像をアップロード→URL取得→置換、という作業が必要になる
- 文章だけ上げてからブラウザで追加編集するのと大差なさそうなので一旦機能追加は保留に
- MCPで記事を投稿した後に、画像を追加し全体の微調整を加えて完成
終わりに
AI周りはとんでもなくアップデートが早く情報を追うだけでもかなりの負荷がかかりますが、その一つ一つの技術に対して、自分で触ってみないと気づけないことが色々あるなあと思います。キャッチアップもしつつ、触って所感を持つことも意識していきたいなと思います。
バイブコーディングやMCPについても、今回自分で試して作ってみると色々な発見や体験があり面白いなと思いました。
今後も一定のペースでAIをキャッチアップし触っていく活動を続けたいと思います!
Discussion