【週末研究】03. 単語とグラフ構造の関係 - トピックモデルのグラフ表現
グラフの行列表現の自然言語処理における意味
今回は、グラフの行列表現の数学的意味、自然言語における意味についてトピックモデル(LSI, LDA)を例に挙げて考察していきます。
線形写像と基底変換との関係
まずは、線形写像と基底変換について見ておきます。
2つのベクトル空間(
この時、線形写像
尚、このセクションの内容は、Wikipediaの基底変換 をベースに作成しています。
外観図
基底変換と線形写像との間の関係の外観を以下に示します。
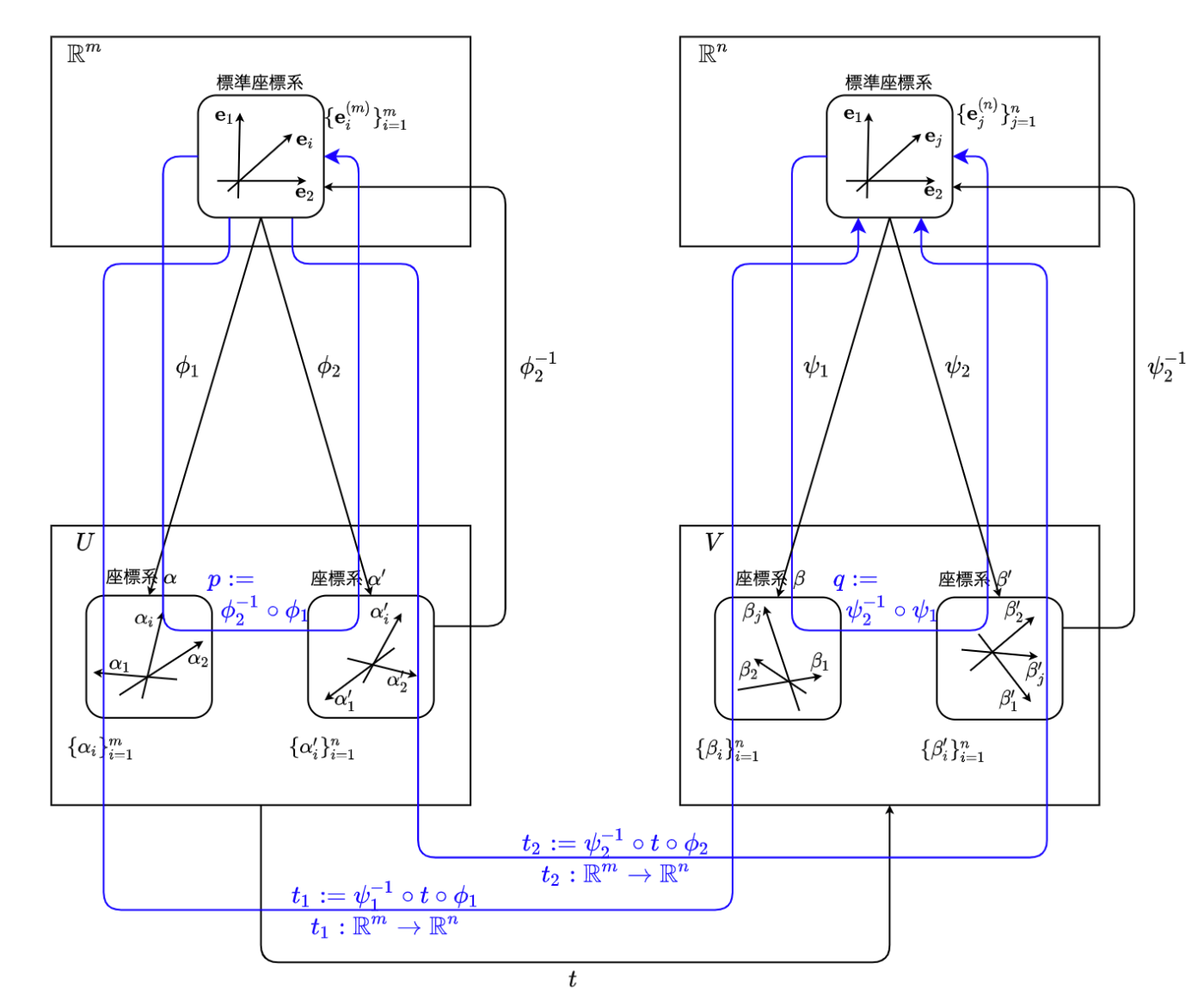
この時、線形写像
表現行列で表すと、
と表せます。
記号の定義
正確な理解のために、記号の定義を、以下のようにしておきます。
\mathbb{R}^m, \mathbb{R}^n
ベクトル空間
2 つのベクトル空間について、いくつか定義をしておきます。
ベクトル空間U, V
以下のように、ベクトル空間
ベクトル空間
座標同型
座標同型についても定義しておきましょう。
ベクトル空間U, V
以下のように、ベクトル空間
ベクトル空間
ベクトル空間上の線形写像
ベクトル空間
ここで、
ベクトル空間U, V \mathbb{R}^{m} \mathbb{R}^{n}
線形写像
また、
実ベクトル空間上の座標変換
すると、
また、
t_1, t_2
ここで、 線形写像
つまり、
特に、表現行列で表すと、
として、
特異値分解 for LSI
次に、特異値分解と座標変換との関係を見ていきます。
特異値分解は、トピックモデルの1つである、LSI (Latent Semantic Index) で利用されています。 より具体的には、LSI は、 TF-IDF 行列の特異値分解です。
特異値分解の定義
ここで、
-
U m U^{-1} = U^{\mathsf{T}} - 複素行列上では、ユニタリだがここでは実空間に限っている
-
V n V^{-1} = V^{\mathsf{T}} - 複素行列上では、ユニタリだがここでは実空間に限っている
-
\Sigma m \times n
i.e.
図で表現すると以下のようになります。
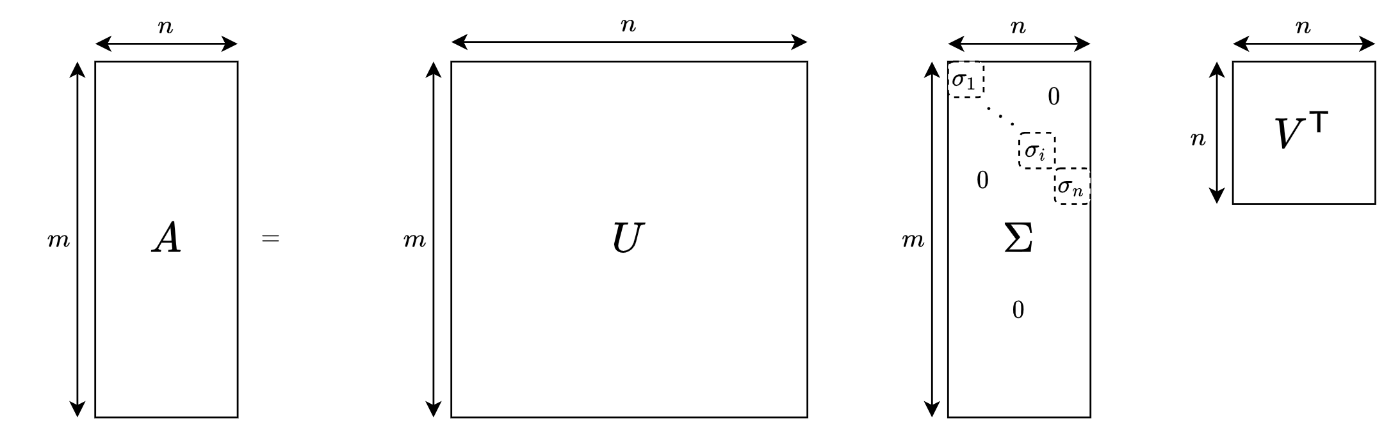
ここで、この図が表している式
さて、次元単位で各線形写像の表現行列の次元・軸(変数)の対応を図示すると以下のようになります。
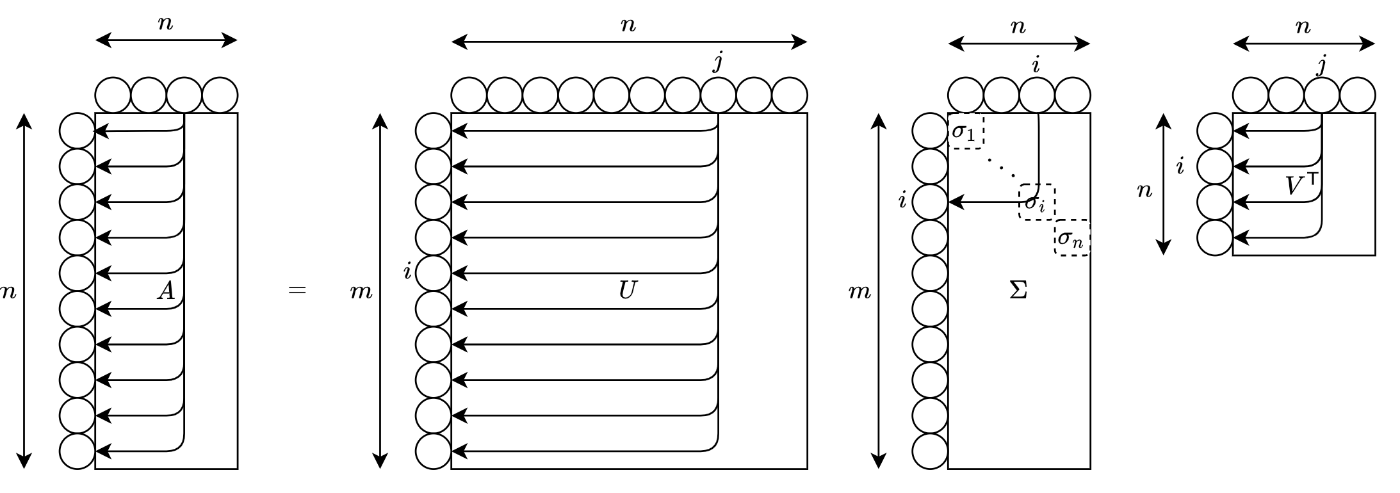
つまり、
この解釈は、前回 見た通り、行列をグラフと見た時にグラフ上の関係(エッジ)が遷移・合成する重みに対応していることからわかります。また、行列の積の意味を考えても自然にわかるでしょう。
別の視点として、上の図を参考に、以下のようなニューラルネットワークFFN(i.e. グラフ構造) としても表現できることにも触れておきます。 ただし、一般的なニューラルネットワークモデルの書き方とは異なり、右から入力される図になっている点にご注意ください。
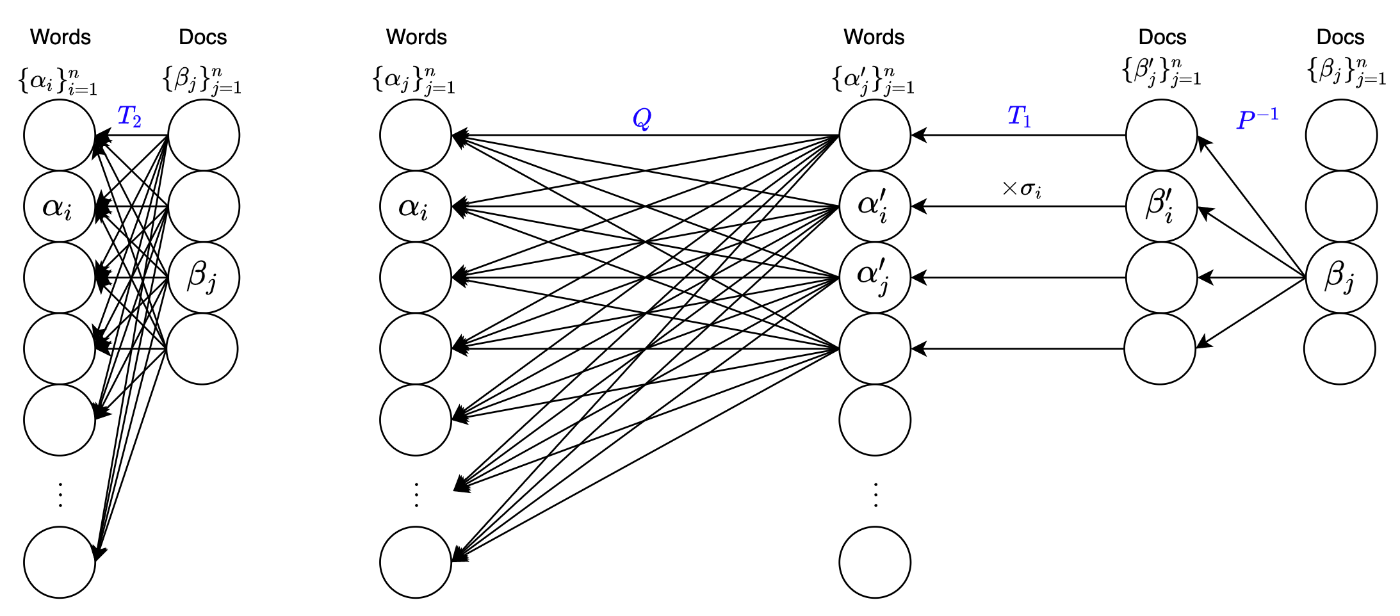
このモデル図からだと先ほどの図よりも、容易に座標変換との対応づけがしやすくなるかもしれません。
各Docs の標準座標系からDocs の別の座標系に変換され、スケールすることで Words の座標系へ変換されます。最後に、スケールによって得られた Words の座標系から Words の標準座標系に変換されるとわかります。
特に、
さらに言うと、この文書集合の合成、単語集合の合成から得られる軸の座標系(
つまり、特異値
まとめると、単語と文書の関係を表したグラフの隣接行列である BoW や TF-IDF などを、特異値分解することは、座標変換の合成、つまり、単語-トピック(単語座標の別座標系)間の関係を表現するグラフの隣接行列や、文書-トピック(文書座標の別座標系)間の関係を表すグラフの隣接行列に、分解できることを意味しています。すなわち、単語-文書間の関係グラフ
LDA (Latent Dirichlet Allocation)
次は、トピックモデルとしてよく使われるであろう、LSIの確率モデルPLSIのベイズ化である LDA について、行列表現(グラフ構造としての表現、隣接行列)との関係を見ていきます。
LDA のグラフィカルモデル
まずは、ベースとなるLDAのグラフィカルモデルを見てみましょう。
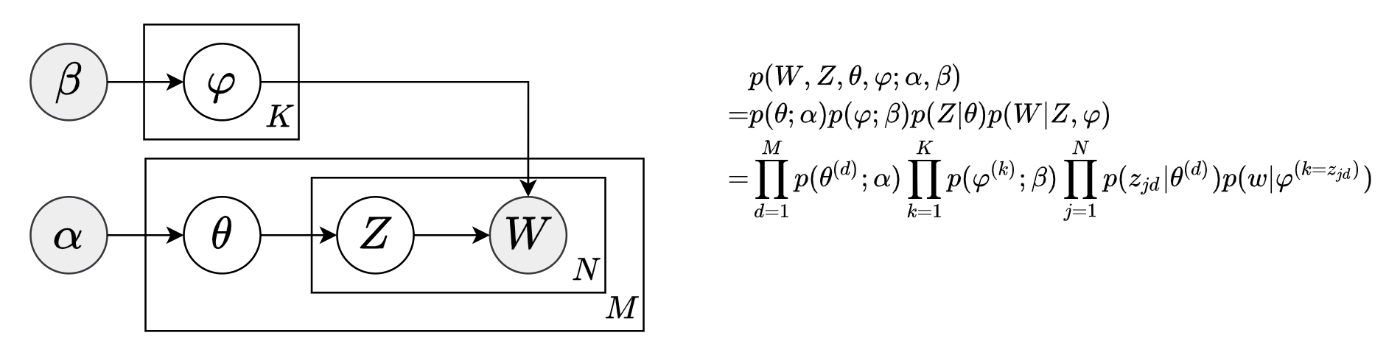
LDA のモデル図 (RAW文書データ)
さて、上記グラフィカルモデルをもう少し具体的に、より正確に図で理解したいと思います。しかし、なかなか自分が納得できそうな図をWeb上で見つけられなかったため、Wikipedia - Latent Dirichlet allocation を参考に下のような図に起こしました。(つまり、図中の各記号は、このWikipedia の内容に従っています。)
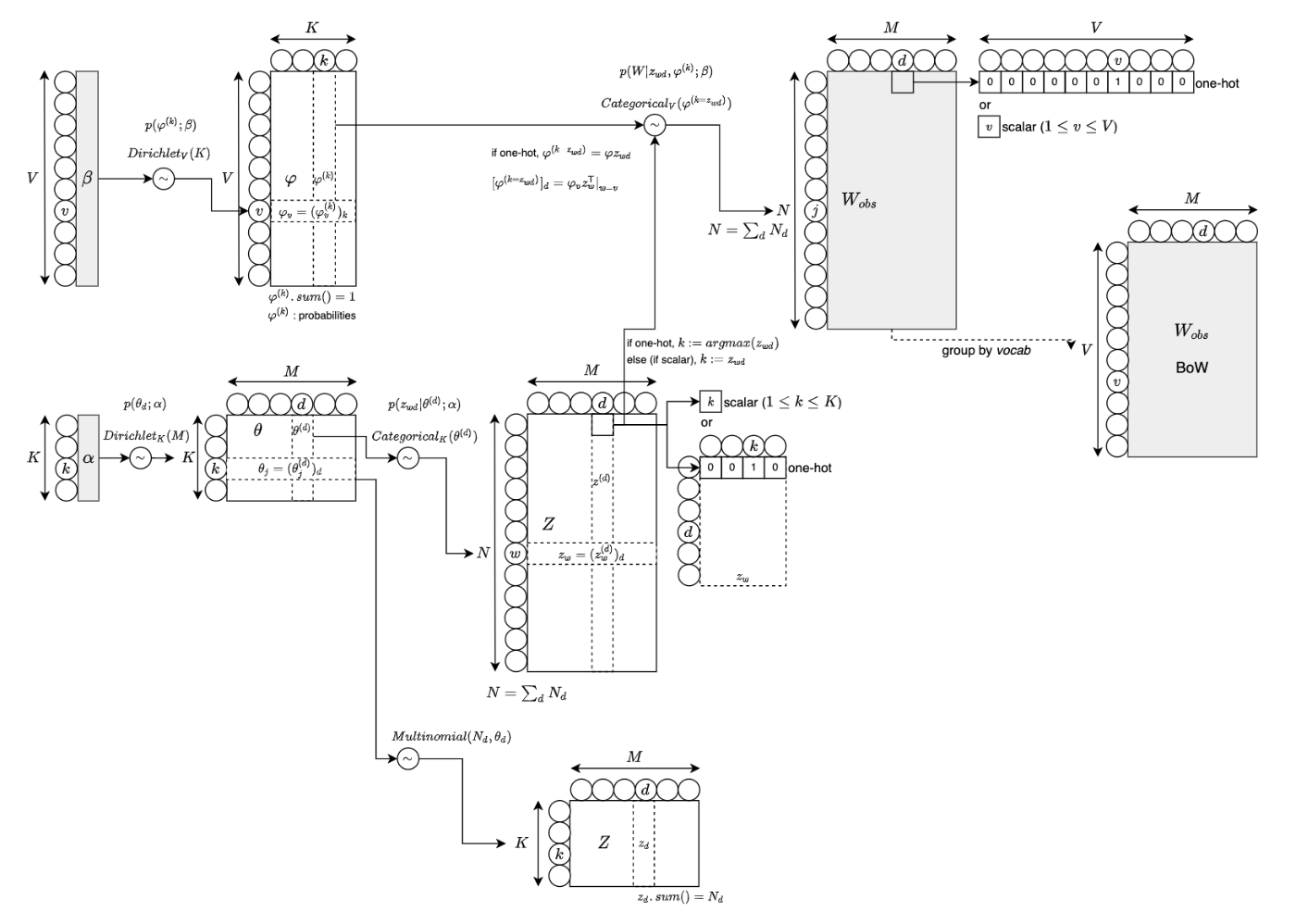
さて、LSI と比較して考えてみます。LSIでは、単語とトピック、文書とトピックの関係を表現した
つまり、BoW などの観測データを行列の積という構造に分解・構造化したものが LSI であり、観測データをベイズモデル(グラフィカルモデル)で分解・構造化したもの(特に、事前分布をディリクレ分布とする)が、LDA と言えるでしょう。
LDA のモデル図 (BoW文書データ)
以下の図は、BoW を観測データとした場合の図になります。
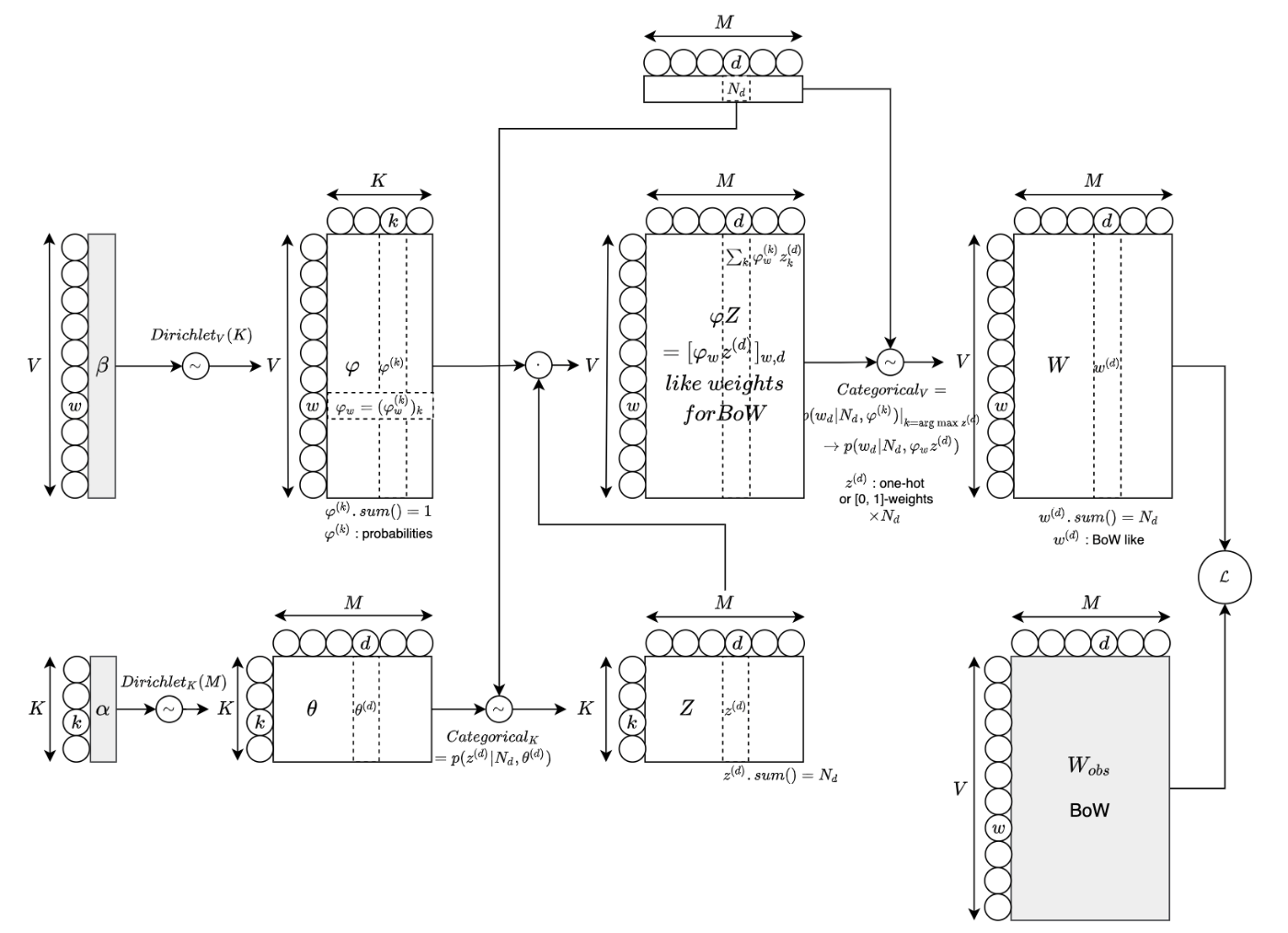
この図は、ニューラルネットワークでのモデル化としてもみることができます。つまり、図の右上の
さて、各行列(テンソル)を、グラフ構造の隣接行列として見ると、
gensim, sklearn の LDA
LDA モデルは、sklearn, gensim から使うことができます。コードを見た感じ、いずれもEMアルゴリズムで学習しているようです。
sklearn の LDAモデル (LatentDirichletAllocation) は、
gensim の LDAモデル (LdaModel) は、
また、gensim の LDAモデルの実装では、
以下にサンプルコードを載せておきます。
データをダウンロード
from sklearn.datasets import fetch_20newsgroups
d = fetch_20newsgroups()
N = 1000
X = d.data[:N]
y = d.target[:N]
sklearn のサンプルコード
import numpky
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
bow = CountVectorizer(min_df=0.04, stop_words="english")
X_bow = bow.fit_transform(X, y)
feature_names = numpy.array(bow.get_feature_names_out())
K = 50
beta = 1/len(feature_names)
# beta = 1/K # vocab が多すぎる場合は、0 につぶれないように、1/K (デフォルト値)で代替する
print("beta:", beta)
lda = LatentDirichletAllocation(n_components=K, max_iter=100, n_jobs=-1, topic_word_prior=beta)
lda.fit(X_bow)
print(lda.components_.shape) # (K, V)
gensim のサンプルコード
from gensim.corpora.dictionary import Dictionary
from gensim.parsing.preprocessing import remove_stopwords
from gensim.models import LdaModel
# cf. from sklearn code
import re
token_pattern=r"(?u)\b\w\w+\b"
tokenizer = re.compile(token_pattern).findall
from sklearn.feature_extraction._stop_words import ENGLISH_STOP_WORDS
def filter_sw(tokens: list):
return [tkn for tkn in tokens if tkn.lower() not in ENGLISH_STOP_WORDS]
def do_tokenize(text: str):
tokens = tokenizer(remove_stopwords(text))
return filter_sw(tokens)
tokenized = [do_tokenize(doc) for doc in X]
dct = Dictionary(tokenized)
X_nummed = [dct.doc2bow(docwords) for docwords in tokenized]
lda = LdaModel(X_nummed, num_topics=K, iterations=100, alpha=1/K, eta=1/K)
# lda = LdaModel(X_nummed, num_topics=K, iterations=100, alpha="auto", eta="auto") # ディリクレ分布のパラメータを学習させたい場合は、こちら
print(lda.expElogbeta.shape) # (K, N)
サンプルコードの全体(Colab)は、こちら です。Colab のコードでは、トピック毎の発生確率が高い単語とその発生確率を表示しています。ご参考までに。
まとめ
- LSI(特異値分解)は、座標変換の合成として見ることができます
- 特にトピックの座標系へ変換する行列
U, V \Sigma - LDA でいうと、
\varphi=U, \theta=V - グラフ上の意味としては、単語-文書間の関係グラフ
A V U
- 特にトピックの座標系へ変換する行列
- LDA は、グラフィカルモデル(ベイズモデル)をベースに構造化し、
\alpha, \beta, Z, W \varphi, \theta - LDA もニューラルネットワーク風にグラフで表現することで、DLフレームワークを使っても学習、推定ができそうです
- この時、中間出力を使って自己教師学習的なモデルにもできそうです
- gensim のLDAモデルは、生文書を数値化したデータを入力とし、sklearn のLDAモデルは、BoW を入力としています
- グラフ上の意味としては、
\varphi \theta - つまり、関係グラフを別の関係グラフに変換したり、合成(連結)したりするモデルが LDA (ベイズモデル) という見方もできます
- 以上から
- BoW/TF-IDF などの観測データを行列(座標変換)の積という構造に分解・構造化したものが LSI(特異値分解)
- 単純に2つのグラフの連結関係に分解・構造化
- 観測データをベイズモデル(グラフィカルモデル)で分解・構造化した(特に、事前分布をディリクレ分布とする)ものが、LDA
- 複数のグラフ間で変換、連結する関係に分解・構造化
- と考えるとよいでしょう
- BoW/TF-IDF などの観測データを行列(座標変換)の積という構造に分解・構造化したものが LSI(特異値分解)
- 行列をグラフとして見ることで、これまでの手法の拡張関係を外観でき、新しい視点でのモデル化ができそうな、そんな予感がしています
参考記事 / 参考URL
- 基底変換関係
- トピックモデル関係
- Wikipedia - Latent Dirichlet allocation
- 特異値分解 (SVD) と多次元解析
- 【入門】トピックモデルとは?トピック分析の3つの手法を解説
- Theory and Applications of Correspondance Analysis; p177
- Wikipedia - Dirichlet distribution
- Wikipedia - Multinomial distribution
- Wikipedia - Categorical distribution
- Wikipedia - Statistical inference
- Wikipedia - Dirichlet-multinomial distribution
- Wikipedia - Compound probability distribution
次回は、トピックモデルなどのトピックに名前を付与するモデルを設計してみようと思います。乞うご期待!
ちなみに、前回はこちら
Discussion