【週末研究】04. 単語とグラフ構造の関係 - トピックモデルの自動ラベル付与
トピックモデルの自動ラベル付与
- UPDATE: コード誤りがあったため、よくない結果であったが、コードを修正したら改善した
外観
今回は、クラスタリングなどの課題である各トピックに対するラベル付けを、自動的にしてみます。
アイデアとしては、トピックモデルの各単語(語彙)の発生確率を使って、
word2vec などの別途学習した埋込ベクトル(上位10個など)を使って、トピックベクトルの期待値(加重平均)を算出。
算出したトピックの期待値ベクトルに最も類似する、単語ベクトルに対応する単語文字列をラベルとします。
i.e.
以上を、図示すると以下のように表現できます。
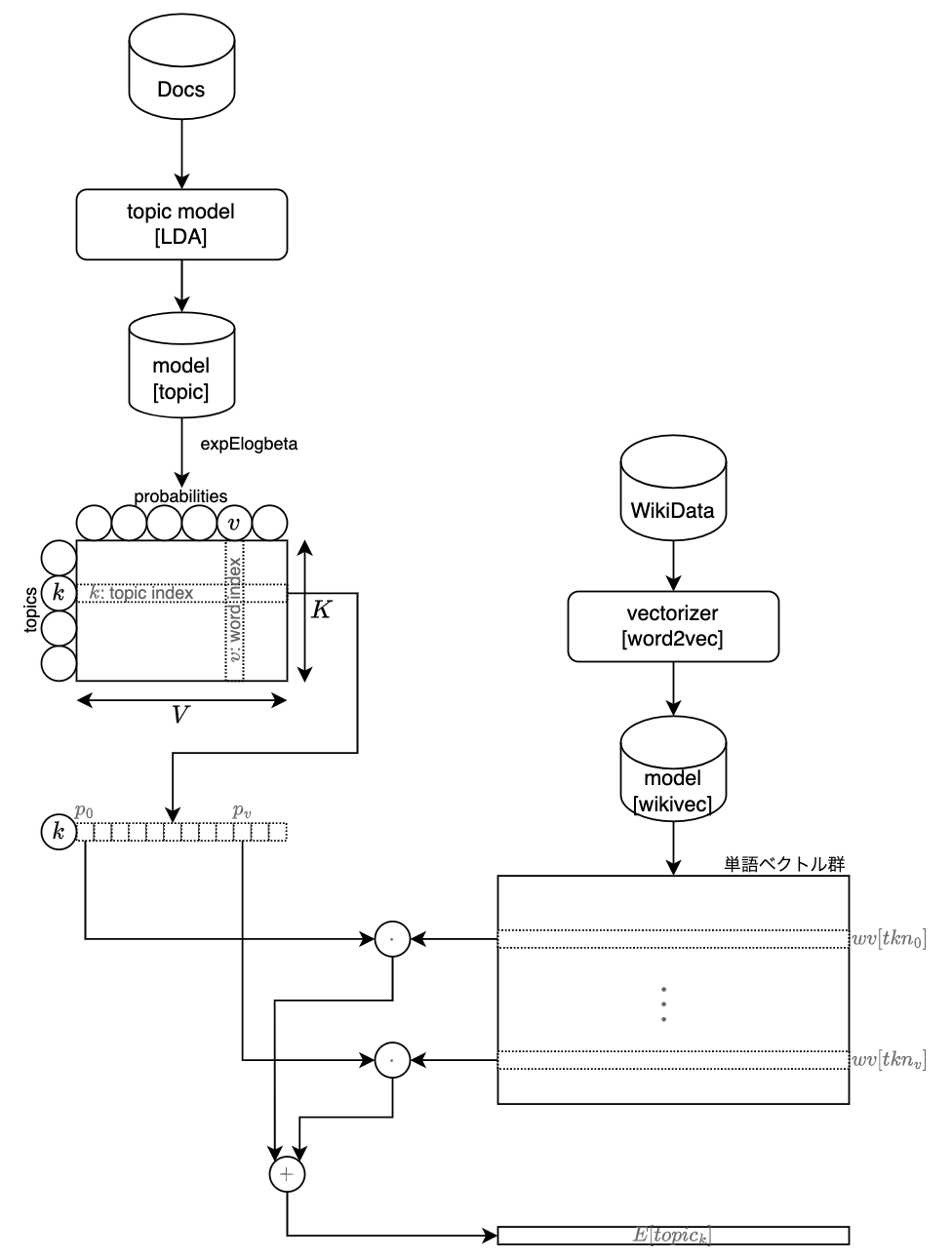
トピックモデルの学習(左側)とは別に、単語の埋込ベクトルを学習するデータセット(上記↑の図では、Wikipedia データ)を用意し、モデルを学習しておきます(右側)。
トピックモデル(LDA)の学習により得られる、トピック
対応する埋込ベクトルを、word2vec モデルから取得して、トピック
この期待値ベクトル
実機検証
では早速、実機検証した結果を見て、考察していきます。
以下では、コードを抜粋して説明します。
実験用コードの全貌を参照されたい方は、notebookを参照ください。
リポジトリは、こちらにありますので、独自定義のクラスの中身など、参照ください。
トピック抽出したい文書
import requests
from bs4 import BeautifulSoup
url = "https://ledge.ai/authorinterview-book-bert-int/"
# url = "https://www.yomiuri.co.jp/world/20230104-OYT1T50056/"
# url = "https://www3.nhk.or.jp/kansai-news/20230104/2000069636.html"
# url = "https://news.yahoo.co.jp/articles/fad0c4f41d46b686e0566bf10e4c016a641a9dab"
# url = "https://news.yahoo.co.jp/articles/4d2d14fd1ca1dc9b134c5f493896a7e30fc1e781"
res = requests.get(url)
soup = BeautifulSoup(res.content, "lxml")
for tg in ["script", "noscript", "meta"]:
try:
soup.find(tg).replace_with(" ")
except:
pass
簡易クレンジングして保持
- UPDATE: 結果には影響はなかったが、"。" だけの行をスキップ処理とした
import re
def clean_text(text: str):
contents = []
for txt in re.split(r"(。|\n)", text):
txt = txt.strip().replace("\u200b", "").replace("\u3000", " ")
txt = re.sub(r"\n+", "\n", txt)
txt = re.sub(r"([\W])\1+", " ", txt)
if not txt:
continue
if txt == "。":
continue
# contents.append(txt)
# contents.append(txt.split("\n")[-1])
contents.extend(txt.split("\n"))
return contents
text = soup.get_text()
contents = clean_text(text)
後に、↓のように使います
X: TextSequences = [contents]
pipe_topic.fit(X)
白ヤギコーポレーションの word2vec モデル
まずは、すぐに試せる点を考慮し、白ヤギコーポレーション社が公開してくれている、軽い学習済 word2vec モデルを使って試してみます。
# use shiroyagi's word2vec pretrained model
from gensim.models.word2vec import Word2Vec
w2v = Word2Vec.load("data/word2vec.gensim.model")
w2v
関数コードサンプルの紹介
以下、関数化したコードサンプルを紹介していきます
各トピックの上位単語の取得
- UPDATE: コード誤りがあったため修正
- 引数に、model_bow を指定すべきところを global な変数を参照していたため、不整合なvocab を使用していた
def pickup_topic_words(model_topic: TopicModel, model_bow: VectorizerBoW, topn: int = -1):
# topn: 各トピックの上位の単語の数
topics = []
for topic_probs in model_topic.get_topic_probabilities():
indices = topic_probs.argsort()[::-1][:topn]
topic = [(model_bow.vocab[idx], topic_probs[idx]) for idx in indices]
topics.append(topic)
return topics
名詞(っぽい)単語リストと数値リストへの分解
def parse_topic(topics: list):
words = []
numbs = []
for w, p in topics:
do_skip: bool = False
do_skip |= bool(re.search(r"^[あ-ん]", w)) # です、ます などは、スキップ
do_skip |= bool(re.search(r"[あ-ん]$", w)) # 動名詞 などは、スキップ
do_skip |= w[0].isnumeric() # 数字から始まるラベルはスキップ
if do_skip:
continue
words.append(w)
numbs.append(p)
return words, numbs
トピックラベルの推定
import numpy
import re
def estimate_topic_label(w2v, topics: list):
proper_topics = {}
topic_labels = []
for idx_tpc, tpc in enumerate(topics):
# トピック情報を、単語リストとその確率リストに分解する
_words, _probs = parse_topic(tpc)
# word2vec モデルに含まれる単語のみに絞る
words = [w for w in _words if w in w2v.wv]
probs = [p for w, p in zip(_words, _probs) if w in w2v.wv]
# 単語リストからベクトルに変換し、期待値ベクトルを算出
vectors = w2v.wv[words]
probs = numpy.array(probs).reshape(-1, 1)
topic_vector = (vectors * probs).sum(axis=0) # 期待値ベクトル
# トピックに対する期待値ベクトルに類似するベクトルを十分な数(topn=100) を取得しておく
estimated_topic_labels = w2v.wv.similar_by_vector(topic_vector, topn=100)
# ラベルと類似度を取得し、最も類似度が高い最初のインデックスの要素を保持
labels, similarities = parse_topic(estimated_topic_labels)
topic_label = labels[0]
similarity = similarities[0]
# 重複しないトピックラベル集合(proper_topics)として記録しておく
if topic_label not in proper_topics:
proper_topics[topic_label] = (idx_tpc, similarity, words, probs)
# 重複を許すトピックラベル(topic_labels)として記録しておく
topic_labels.append((topic_label, similarity))
return topic_labels, proper_topics
トピック数の自動推定
# トピック数を自動で特定するサンプル
# # トピック数が proper_topics と一致するまで、減らしていくことで、トピック数を特定する
# w2v : is already loaded
topic_label_counter = {}
n_topic_words = 7 # to calculate the average over ... あまり多くするとノイズに近いベクトル値が加算される
n_topics = 15 # default topic numbers
rs = numpy.random.RandomState(12345)
while True:
# トピックモデルのパイプラインを構築
pipe_topic = Pipeline(
steps=[
(TokenizerWord(use_stoppoes=True, use_orgform=True), None),
(VectorizerBoW(), None),
(TopicModel(n_topics=n_topics, n_epoch=2000, random_state=rs), None),
],
name="pipe_topic",
do_print=False,
)
# トピックモデルを学習
X: TextSequences = [contents]
pipe_topic.fit(X)
model_bow: VectorizerBoW = pipe_topic.get_model(1)
model_topic: TopicModel = pipe_topic.get_model(-1)
topics = pickup_topic_words(model_topic, model_bow, topn=n_topic_words)
topic_labels, proper_topics = estimate_topic_label(w2v, topics)
# トピックラベルをカウント
for tpc in proper_topics:
cnt = topic_label_counter.get(tpc, 0) + 1
topic_label_counter[tpc] = cnt
# ループの終了条件
if len(proper_topics) >= n_topics:
break
# 状態/処理文脈としてトピック数を更新・保持
n_topics = len(proper_topics)
出力結果例
# トピックの出力
# # 自動付与したラベルと、各トピックの上位単語の表示
# # 理想的には、この出力結果に違和感がないこと
for idx_tpc, (lbl, sim) in enumerate(topic_labels):
print("-" * 100)
print(f"topic[{idx_tpc}]: {lbl} : {topic_label_counter[lbl]} ({sim:0.3f})")
print(" " * 4 + f" ... {[_t for _t, _s in topics[idx_tpc][:20]]}")
トピックの出力
----------------------------------------------------------------------------------------------------
topic[0]: 人工知能 : 5 (0.887)
... ['する', 'BERT', '自然言語処理', 'いる', 'AI', 'の', 'できる']
ざっくりと「人工知能」というラベルが付与されました
# 実際に期待値ベクトルを算出するときに使った単語を表示
# # 上記の自動付与ラベルと上位単語の関係性に違和感があるときに確認すると良いだろう
print("estimated n_topic:", len(proper_topics))
for lbl, v in proper_topics.items():
tpc_idx, sim, words, probs = v
print(f"[{tpc_idx:02d}]: {lbl}: {words}")
実際に、期待値ベクトルの算出に使った単語(ベクトル)を確認すると
estimated n_topic: 1
[00]: 人工知能: ['自然言語処理', 'AI']
「自然言語処理」、「AI」の2つの単語から推定されるトピックのラベルとして、「人工知能」が付与されたようです。
独自に学習させた Wikipedia のモデルを使った結果
Tensorflow Datasets の "train" データセットの約180万のパラグラフを、10,000パラグラフずつ追加学習した独自学習モデルを使った結果です。
----------------------------------------------------------------------------------------------------
topic[0]: AI : 3 (0.916)
... ['する', 'BERT', '自然言語処理', 'AI', 'いる', 'ある', 'の']
----------------------------------------------------------------------------------------------------
topic[1]: 自然言語処理 : 3 (0.923)
... ['する', 'BERT', '自然言語処理', 'いる', 'AI', 'の', 'できる']
実際に、トピックラベル推定に使った単語は、「AI」と「自然言語処理」でそのまま、という結果に
estimated n_topic: 2
[00]: AI: ['自然言語処理', 'AI']
[01]: 自然言語処理: ['自然言語処理', 'AI']
ニュース記事で word2vec モデルを追加学習した結果
上記の Tensorflow Datasets の "train" データセットの独自学習モデルに、さらに
ニュース記事をクロールして追加学習したモデルを使った結果です。
----------------------------------------------------------------------------------------------------
topic[0]: BERT : 3 (0.915)
... ['BERT', 'する', '自然言語処理', 'AI', 'の', 'いる', 'できる']
----------------------------------------------------------------------------------------------------
topic[1]: ユニモーダルモデル : 1 (0.850)
... ['する', '自然言語処理', 'BERT', 'AI', 'いる', 'できる', 'データセット']
----------------------------------------------------------------------------------------------------
topic[2]: 自然言語処理 : 3 (0.882)
... ['する', '自然言語処理', 'いる', 'BERT', 'AI', 'できる', 'の']
実際に、トピックラベル推定に使った単語は、以下の通り
estimated n_topic: 3
[00]: BERT: ['BERT', '自然言語処理', 'AI']
[01]: ユニモーダルモデル: ['自然言語処理', 'BERT', 'AI', 'データセット']
[02]: 自然言語処理: ['自然言語処理', 'BERT', 'AI']
00 と 02 は、トピックを構成する単語群が同じで、もっとも確率が高いトピックを構成する単語の違いがそのまま反映されているようです。
一方で、01 は、「データセット」が追加され、暗黙の前提である「ユニモーダルモデル」というトピックを抽出している点は非常に興味深いところです。
特に、最近のニュース記事をクロールして学習させたため、先の2つの Wikipedia だけのトピックラベルの推定よりも、より具体的なトピックラベルの推定結果になったように感じます。
参考記事 / 参考URL
- 学習済 word2vec モデル (日本語)
- 白ヤギコーポレーション社の学習済 word2vec モデル
- ワークスアプリケーション社の chiVe モデル
次回は、今回の記事では省略した、Word2Vec の追加学習の仕方や Spider を使ったニュース記事のクロールについて補足しようと思います。
ちなみに、前回はこちら
Discussion