JuliaでOpenStreetMapのXMLをparseした話
Twitter芸人名@cocomoffです.
この記事はJulia Advent Calendar 2021の18日目の記事です.15日目にはTuring.jlを使ったネタで書いたのですが,普段自分でちょっとしたプログラムを書くためにもJuliaを使っていることがあるので,今日はだいぶ前に自分で書いたJuliaプログラムに関する記事です.
OpenStreetMapについて
概要
名前ぐらいは聞いたことがある人も多いかもしれないですが,https://www.openstreetmap.org/ で公開されている地図情報です(?).
OpenStreetMapは、道路、通路、カフェ、鉄道駅など、世界中にあるすべてのものに関するデータを提供・メンテナンスしているマッパーのコミュニティによって構築されました。
ライブラリ
OpenStreetMapを扱うライブラリやソフトウェアはいろいろあります.例えばPythonだと,osmnxと呼ばれる高性能なライブラリが開発されています.
データ
自分で細かい処理をやろうと思うとき,たまに既存実装では追いつかず自分で処理する必要が出てきます.そうなると元のOpenStreetMapデータを見に行くのですが,例えばこういったサイトで公開されています.日本だと日本全体や日本の各地方のデータが1つの塊になっています.
例として関東のデータだと,kanto-latest.osm.bz2などをダウンロードしてきて解凍すれば良いです.ダウンロードしたosmという拡張子のファイル(中身はXML)がbz2の状態で500MB程度,解凍した状態で6GB程になるのことだけが問題です.そのため適当なライブラリで全部メモリ上にデータを読み込むと,普通の環境だと死んでしまいます.ですので自分でXMLファイルを解析するためには,Juliaを使ってEzXMLのストリーム読み込みモードを使う必要があるわけですね~(雑な導入).
とりあえずこの記事では,OpenStreetMapの一分の情報を抜き出してきて,ダウンロードしてきたOSMファイルから道路ネットワークを表すJuliaのグラフライブラリGraphs.jlのオブジェクトを作成することを目指します.
EzXML.jlを使ったOSMファイルのパース
ライブラリ
EzXML.jlはすごいXML処理用のライブラリです(投げっぱなし)
OSMデータの構造を見る
EzXML.jlを使う前に小さめのosmファイルを落としてきて,データの構造をグッと睨んでみようと思います.適当にダウンロードしてきたものを抜粋してここに貼り付けします.
<?xml version="1.0" encoding="UTF-8"?>
<osm version="0.6" generator="CGImap 0.8.5 (2979634 spike-07.openstreetmap.org)" copyright="OpenStreetMap and contributors" attribution="http://www.openstreetmap.org/copyright" license="http://opendatacommons.org/licenses/odbl/1-0/">
<bounds minlat="35.6854000" minlon="139.6876000" maxlat="35.6991000" maxlon="139.7023000"/>
<node id="158030410" visible="true" version="11" changeset="35089059" timestamp="2015-11-04T21:36:35Z" user="Luis36995" uid="1829683" lat="35.6903957" lon="139.7045284"/>
<node id="158030491" visible="true" version="15" changeset="46574233" timestamp="2017-03-04T14:53:05Z" user="nakanao" uid="618878" lat="35.6979039" lon="139.7074388">
<tag k="highway" v="traffic_signals"/>
<tag k="name" v="新宿七丁目"/>
<tag k="name:en" v="Shinjuku 7"/>
<tag k="name:ja" v="新宿七丁目"/>
<tag k="name:ja_kana" v="しんじゅくななちょうめ"/>
<tag k="name:ja_rm" v="Shinjuku nanachōme"/>
</node>
<node id="191499365" visible="true" version="14" changeset="57408375" timestamp="2018-03-22T04:29:41Z" user="roguish" uid="1059224" lat="35.6958598" lon="139.6884285">
~~~
</node>
<node id="191500702" visible="true" version="9" changeset="12121027" timestamp="2012-07-05T14:33:08Z" user="nakanao" uid="618878" lat="35.6877392" lon="139.6965455">
~~~
</node>
~~~
<way id="965405384" visible="true" version="1" changeset="108200950" timestamp="2021-07-18T17:14:21Z" user="近場行き" uid="12272282">
<nd ref="1813863769"/>
<nd ref="5498655294"/>
<tag k="highway" v="secondary"/>
<tag k="lanes" v="2"/>
<tag k="name" v="議事堂通り(西新宿)"/>
<tag k="oneway" v="yes"/>
<tag k="ref" v="3510"/>
<tag k="source" v="Bing 2012"/>
<tag k="surface" v="paved"/>
</way>
<way id="965405385" visible="true" version="1" changeset="108200950" timestamp="2021-07-18T17:14:21Z" user="近場行き" uid="12272282">
~~~
</way>
~~~
<relation id="21087" visible="true" version="502" changeset="108572144" timestamp="2021-07-25T16:30:34Z" user="近場行き" uid="12272282">
~~~
</relation>
</osm>
概ねこういう感じの構造になっています.
- 先頭のほうに色々なメタデータがある
- 最初にnodeが定義されている,中身にタグがついていたりついていなかったりする
- 次にwayが定義されている,wayを構成するnodeが参照される,中身にタグがついていたりついていなかったりする
- 後ろのrelationが定義されている
- 残りはいろいろある
今回はGraphs.jlのオブジェクトを作るところまでが目的だったので,nodeとwayを取ってくると良いことが分かります.
wayを取ってくるためにnodeを取ってくる
ところでnodeという属性が曲者で,実は道路ネットワーク
OpenStreetMapは、道路、通路、カフェ、鉄道駅など、世界中にあるすべてのものに関するデータを提供・メンテナンスしているマッパーのコミュニティによって構築されました。
とあるように,建物などの情報もnodeとして書き込まれているからです.そのため,nodeの中でwayに使われているものはwayを構成する ということに注意してデータを取ってくる必要があります.そのため私の実装では先にnode情報とway情報をCSVファイルに書き出し,自分が選択するwayの情報を抜き出し,後でnodeの情報を保存しておいたCSVから取ってくるという二度手間な感じで実装しています.もしかしたら真面目にXML処理を読めばスマートに処理出来た可能性もありますが,プログラムを動かすPCのメモリがいつも十分にあるとは限らないので,一度HDDに処理情報を書き出しておくことは悪くない選択肢です.
まずは先のノードの処理をします.ノードには後でrefされるidの他に,緯度経度情報が付与されているので一緒に保存しておきます.ファイルサイズが大きいので,ストリームモードで読んで逐次処理します.
using EzXML
filename = "kanto-latest.osm"
basename = splitdir(splitext(filename)[1])[2]
outfileV = joinpath(OUTPUT_DIR, "$(basename)_nodeid.csv")
reader = open(EzXML.StreamReader, filepath)
open(outfileV, "w") do outfile
while (item = iterate(reader)) !== nothing
if reader.name == "node"
nid, nlat, nlon = reader["id"], reader["lat"], reader["lon"]
write(outfile, "$nid,$nlat,$nlon,$amenity\n")
end
end
end
wayを取ってくる
次にwayからnodeのref情報を取ってきます.node処理する際に一度ストリームを読み切ったので,もう一度開いて最初からやり直していきます.ここでストリーム処理中に,wayの中の子elementとして含まれているrefを取ってきたいです.そのためメモリが心配ですが,各wayのところでexpandtreeを使って普通のtreeに戻し,そこから各子のwayの情報 (highwayタグ)と,どのノードで構成されたwayかを取得します.ここでwayに付与されているhighwayタグが自分の気になるタグであるとき,前処理のCSVファイルに情報を書き残すことにします.highwayタグと我々が普段目にしている道の対応関係については,こちらのページを参考にしてください.
実装例です.
# 取得するタグ
const target_set = Set{String}(["trunk", "primary", "secondary", "tertiary", "unclassified", "residential"])
outfileE = joinpath(OUTPUT_DIR, "$(basename)_edgeid.csv")
open(outfileE, "w") do outfile
reader = open(EzXML.StreamReader, filepath)
while (item = iterate(reader)) !== nothing
if reader.name == "way" && reader.type == EzXML.READER_ELEMENT
way_id = reader["id"]
tree = expandtree(reader) # ここで展開する
highwayType = "" # OSMのhighwayタグを見る
refs = String[]
for c in eachelement(tree)
if c.name == "tag" && c["k"] == "highway"
highwayType = c["v"] # wayのhighwayタグ
elseif c.name == "nd"
push!(refs, c["ref"]) # wayの構成要素
end
end
# 対象とするhighwayタグの種類集合
if highwayType in target_set
edgelist = join(refs, ",")
write(outfile, "$(way_id) $(edgelist)\n")
end
end
end
end
これで巨大なXMLファイルを前処理して,道路ネットワークのグラフを構築するための情報をCSVファイルに保存することができました.せっかくなので前処理した情報をJuliaで使いやすいようにまとめてJLD2で保存しておくことにします.
using ProgressBar
outdict = joinpath(OUTPUT_URL, "$(basename)_plotinfo.jld2")
# 円の距離
const R = 6371000
function dG(lat1, lon1, lat2, lon2; r = R)
φi, λi = deg2rad(lat1), deg2rad(lon1)
φj, λj = deg2rad(lat2), deg2rad(lon2)
v1 = sin((φj - φi) / 2)
v2 = sin((λj - λi) / 2)
return 2 * r * asin(sqrt(v1^2 + cos(φi) * cos(φj) * v2^2))
end
# 辺を処理
used_ids = Set()
dict_edges = Dict()
for line in ProgressBar(eachline(open(outfileE)))
linesplit = split(line, " ")
way_id = parse(Int, linesplit[1])
ids = parse.(Int, split(linesplit[2], ","))
dict_edges[way_id] = ids
for id in ids
push!(used_ids, id)
end
end
# 辺に使われているnodeだけを残す
dict_lat_lon = Dict()
count0, count1 = 0, 0
for line in ProgressBar(eachline(open(outfileV)))
linesplit = split(line, ",")
nid = parse(Int, linesplit[1])
lat, lon = parse.(Float64, linesplit[2:3])
if nid in used_ids
dict_lat_lon[nid] = (lat, lon)
end
end
# 辺の距離を地球上の大円距離で計算して保存
remove_ids = []
for (way_id, way) in dict_edges
flag = true
for p in way
if !haskey(dict_lat_lon, p)
flag = false
break
end
end
# all nodes are valid (ちゃんとnodeがあるway)
if flag
for i = 1:length(way)-1
pi, pj = way[i:i+1]
lat1, lon1 = dict_lat_lon[pi]
lat2, lon2 = dict_lat_lon[pj]
dij = dG(lat1, lon1, lat2, lon2)
dict_dist[(pi, pj)] = dict_dist[(pj, pi)] = dij
end
else
push!(remove_ids, way_id)
end
end
# node情報が欠けてたwayは削除
for way_id in remove_ids
delete!(dict_edges, way_id)
end
# JLDに残す
jldopen(outdict, "w") do f
f["dict_edges"] = dict_edges
f["dict_lat_lon"] = dict_lat_lon
f["dict_edge_dist"] = dict_dist
end
グラフオブジェクトを作る
前処理で取得した情報をまとめます.
- 道wayに対応付けられた頂点nodeのIDと緯度経度
- 道を構成する頂点のリスト
ここまでくれば残りは普通にGraphs.jlを作成するだけです.位置情報をノードに保存するためにはMetaGraphs.jlを使っておくといいかもしれません.また辺に重さ (距離)を付与したい場合には,SimpleWeightedGraphs.jlを使っておくと良いかもしれません.場合によって適当なやつを使います.以下が実装例です.実装でlightgraphという名前が出てくるのですが,これはこのプログラムを書いていたときはGraphs.jlではなくLightGraphs.jlを使っていたので,その名前の名残です.
function build_lightgraph(;
name = "kanto-latest.osm",
jld2nameD = "kanto-latest.jld2",
target_set = target_set)
# ファイル名など
basename = splitdir(splitext(name)[1])[2]
outname = "$(basename)_graph.jld2"
jld2nameG = joinpath(OUTPUT_URL, outname)
# 前処理したファイルからデータを読んでグラフにする
jldopen(jld2nameD, "r") do file
dict_edges = file["dict_edges"]
dict_lat_lon = file["dict_lat_lon"]
dict_edge_dist = file["dict_edge_dist"]
dict_map = Dict()
inv_dict_map = Dict()
# 頂点数Nのメタグラフに属性を突っ込む
N = length(dict_lat_lon)
g = MetaGraph(N)
for (idn, (n, (lat, lon))) in enumerate(dict_lat_lon)
dict_map[n] = idn
inv_dict_map[idn] = n
# 緯度経度のメタデータ設定
set_prop!(g, idn, :lat, lat)
set_prop!(g, idn, :lon, lon)
end
for (idc, (_, ids)) in enumerate(dict_edges)
for i = 1:length(ids)-1
ni, nj = ids[i], ids[i+1]
ii, jj = dict_map[ni], dict_map[nj]
dij = dict_edge_dist[(ni, nj)]
eij = Edge(ii, jj)
add_edge!(g, eij)
# 円距離のメタデータ設定
set_prop!(g, eij, :dist, dij)
end
end
# ちぎれている部分を処理するための最大の連結成分を残す
cc = connected_components(g)
sizes = [(length(elem), elem) for elem in cc]
sort!(sizes, by = x -> x[1], rev = true)
target = sizes[1][2]
gg = g[target]
@info "Graph size |V|=$(nv(g)), |E|=$(ne(g))"
@info "Top CC size: $([k[1] for k in sizes[1:min(5, length(sizes))]])"
@info "Largest connected component of size $(length(target))"
# 使いやすいSimpleWeightedGraphsを作る
sg = SimpleWeightedGraph(nv(gg))
for e in edges(gg)
weight = get_prop(gg, e, :dist)
add_edge!(sg, e.src, e.dst, weight)
end
# 書き出す
jldopen(jld2nameG, "w") do outfile
outfile["graph"] = gg
outfile["swgraph"] = sg
outfile["node_map"] = dict_map
outfile["target"] = target
end
end
end
これで完成です!細かくみてみるとグラフをもう少し直す必要があるのですが,とりあえずは望み通りの処理に使えそうです.JuliaのMetaGraphs.jl/SimpleWeightedGraphs.jlの形でデータを出力したので,グラフ描画ライブラリとセットで利用できます.少し古いですが,過去の記事を参考にしてください.
他にも緯度経度を都道府県単位でフィルタリングしたい場合には,shpファイルを使えると便利なときがあります.
オマケ
いくつか適当に描画したものを貼って終わります.
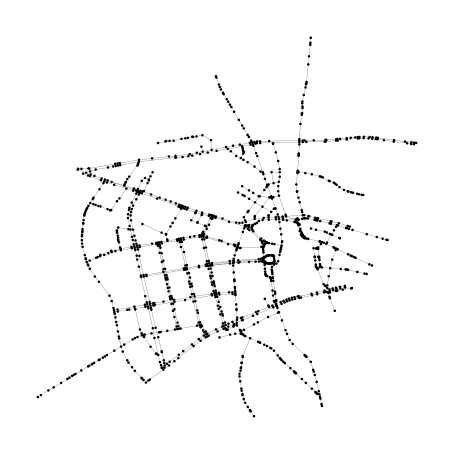
例1 新宿
実装中のテストで使っていた新宿のOSMから太めの道を抜き出したやつです.このファイルを処理しながらEzXML.jlに慣れました.
例2 関東
大きめのデータがメモリ落ちせずに処理できそうになったので,関東の大きめの道を抜き出してみました.この実装をしてた頃に,連結成分の計算みたいなことを思いました.
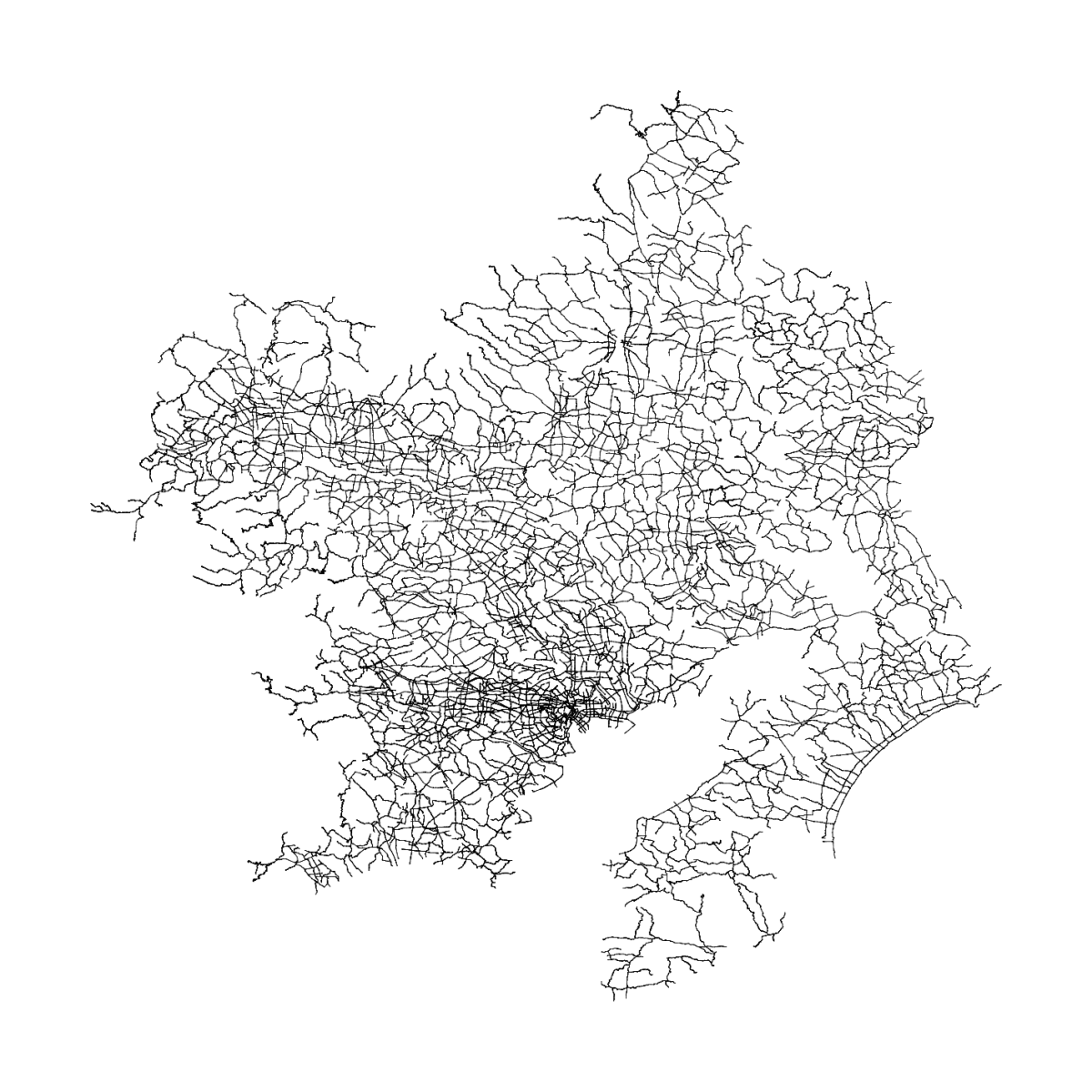
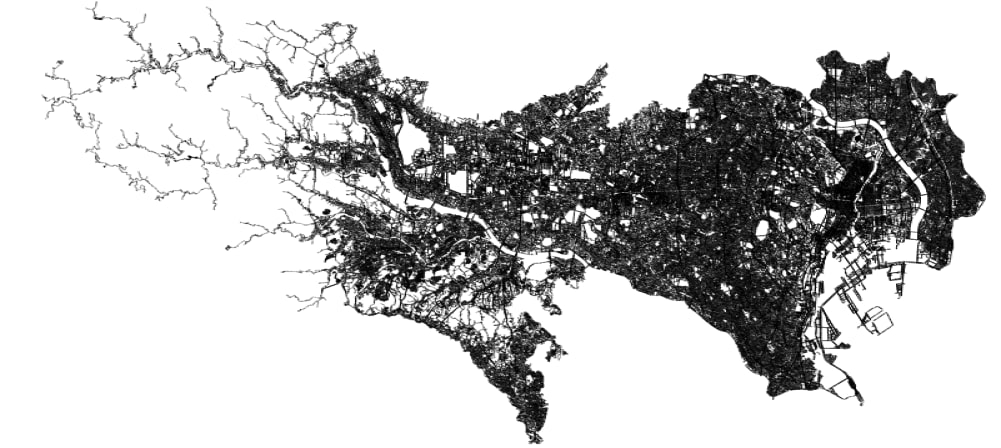
例3 東京
highwayタグが意外と細かくついていることに気づき,またpython経由でshpファイルを処理できることに気づいたので,東京の道を細かく抜き出しました.
例4 東京の一部のhighwayタグ変更
こちらも別の地域として,適当に四角に区切った東京のOSMファイルに対して,道の種類を変更したときに抜き出せるグラフ構造の違いを確認しました.
| あらく | こまかく |
|---|---|
 |
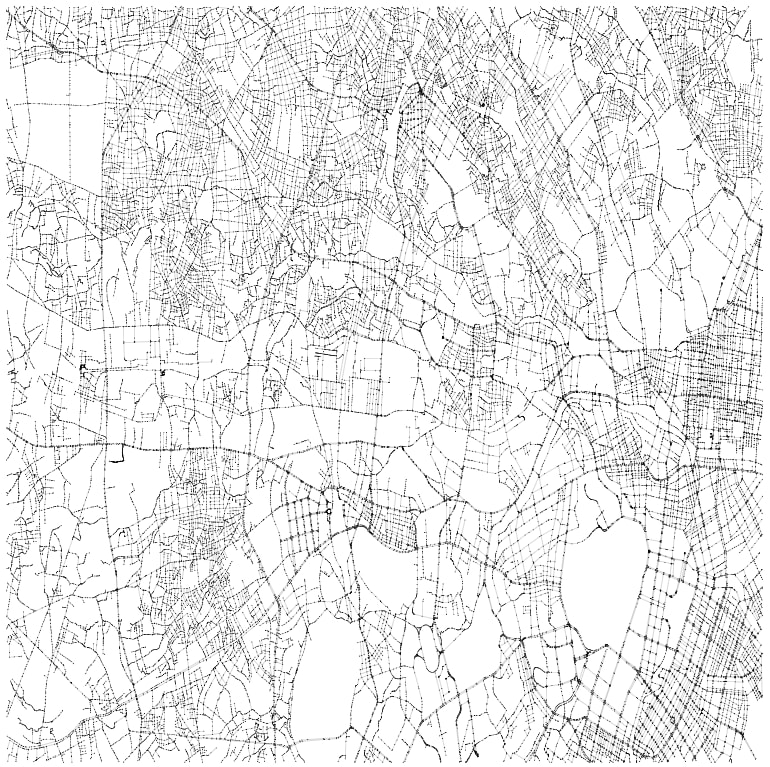 |
ここで本当に終わりです.
Discussion