データサイエンティストが生後4ヶ月までの成長を可視化する

© kurumaru
はじめに
育児アプリから出力したデータを可視化することで娘の成長を感じたい!という思いから 可視化 と 分析 を行ってみました。
育児アプリでミルクやおしっこなどのお世話を毎日何度もしていて直感的には「成長したな!」って思うこともありますが、これは数字にもちゃんと現れているのでは?という疑問からデータの処理をしてみました。
以下リンクで概要は確認できます。
データの抽出
データの取得方法については以下の記事でご紹介していますので割愛させて頂きます。
その他のアプリで同じようなことはできると思いますが、テキストファイルのフォーマットは当然異なるのでご注意ください。
変換の方法
テキストファイルの形式では、分析が困難な形式です。まずは、CSV形式の可視化したいフォーマットに変換して行きます。
【ぴよログ】2025年7月
----------
2025/7/1(火)
ももまる (2か月29日)
08:50 起きる (11時間10分)
08:55 おしっこ
09:10 母乳 左 10分 ← 右 10分 (70ml)
09:45 ミルク 120ml
手軽に実装できる Python を使用して幾つかのテキストファイルを読み込んで1つのCSVに変換します。
Python実装
お名前 の部分については、ご自身の子供のお名前を入力ください。
# -*- coding: utf-8 -*-
import pandas as pd, glob, re, os, io, numpy as np
from datetime import datetime
# 1) Read all uploaded text files
paths = sorted(glob.glob("data/テキスト-*.txt"))
rows = []
date_pattern = re.compile(r'^\s*(\d{4}/\d{1,2}/\d{1,2})\([月火水木金土日]\)')
time_event_pattern = re.compile(r'^\s*(\d{1,2}:\d{2})\s+(.+?)\s*$')
separator_pattern = re.compile(r'^-+\s*$')
summary_keywords = ["母乳合計", "ミルク合計", "睡眠合計", "おしっこ合計", "うんち合計"]
ignore_line_starts = ["お名前", "母乳合計", "ミルク合計", "睡眠合計", "おしっこ合計", "うんち合計"]
amount_ml_pattern = re.compile(r'(\d+)\s*ml', re.IGNORECASE)
temp_pattern = re.compile(r'(\d{2}\.\d)°C')
weight_pattern = re.compile(r'(\d+(?:\.\d+)?)\s*kg')
height_pattern = re.compile(r'(\d+(?:\.\d+)?)\s*cm')
for p in paths:
try:
with open(p, "r", encoding="utf-8") as f:
text = f.read()
except UnicodeDecodeError:
with open(p, "r", encoding="cp932", errors="ignore") as f:
text = f.read()
current_date = None
for line in text.splitlines():
line = line.rstrip("\n")
if not line.strip():
continue
# new date?
m_date = date_pattern.match(line)
if m_date:
current_date = m_date.group(1) # e.g. 2025/6/1
continue
# ignore separators and monthly headers
if separator_pattern.match(line):
continue
if any(line.startswith(k) for k in ignore_line_starts):
continue
# event line?
m_ev = time_event_pattern.match(line)
if m_ev and current_date is not None:
t_str = m_ev.group(1)
event_text = m_ev.group(2)
# category = first token
category = event_text.split()[0] if event_text.split() else ""
# extract amount_ml if exists
amount_ml = None
m_ml = amount_ml_pattern.search(event_text)
if m_ml:
try:
amount_ml = int(m_ml.group(1))
except:
amount_ml = None
# extract temperature/weight/height if present
temp_c = None
m_temp = temp_pattern.search(event_text)
if m_temp:
try:
temp_c = float(m_temp.group(1))
except:
temp_c = None
weight_kg = None
m_w = weight_pattern.search(event_text)
if m_w and "体重" in event_text:
try:
weight_kg = float(m_w.group(1))
except:
weight_kg = None
height_cm = None
m_h = height_pattern.search(event_text)
if m_h and ("身長" in event_text or "頭囲" in event_text or "胸囲" in event_text):
try:
height_cm = float(m_h.group(1))
except:
height_cm = None
# build datetime (assume local)
try:
dt = pd.to_datetime(f"{current_date} {t_str}", format="%Y/%m/%d %H:%M")
except Exception:
# fallback robust parsing
dt = pd.to_datetime(f"{current_date} {t_str}")
rows.append({
"datetime": dt,
"date": dt.date().isoformat(),
"time": dt.strftime("%H:%M"),
"hour": dt.hour,
"category": category,
"event": event_text,
"amount_ml": amount_ml,
"temp_C": temp_c,
"weight_kg": weight_kg,
"height_cm": height_cm,
"source_file": os.path.basename(p),
})
# Create DataFrame
df = pd.DataFrame(rows).sort_values("datetime").reset_index(drop=True)
# Save CSV (UTF-8 with BOM for Excel)
out_path = "events_sorted.csv"
df.to_csv(out_path, index=False, encoding="utf-8-sig")
変換後の CSVファイルは以下のようになっています。
datetime,date,time,hour,category,event,amount_ml,temp_C,weight_kg,height_cm,source_file
2025-04-02 16:20:00,2025-04-02,16:20,16,頭囲,頭囲 31.5cm,,,,31.5,テキスト-AE06C33904A3-1.txt
2025-04-02 16:20:00,2025-04-02,16:20,16,体重,体重 2.27kg,,,2.27,,テキスト-AE06C33904A3-1.txt
2025-04-02 16:20:00,2025-04-02,16:20,16,胸囲,胸囲 30.0cm,,,,30.0,テキスト-AE06C33904A3-1.txt
2025-04-02 16:20:00,2025-04-02,16:20,16,身長,身長 47.5cm,,,,47.5,テキスト-AE06C33904A3-1.txt
2025-04-03 17:50:00,2025-04-03,17:50,17,母乳,母乳 左 10分 ← 右 10分,,,,,テキスト-AE06C33904A3-1.txt
時系列情報を保持した表形式にまとめることで分析も容易なデータ形式になりました。
可視化
続いては時系列の表形式のデータを可視化していきます。
全体の可視化
ざっくりと全体のデータを育児イベントごとに可視化してみます。
縦軸を24時間の1日のサイクルにして、横軸は新生児から4ヶ月までの期間です。
Python実装
# -*- coding: utf-8 -*-
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import numpy as np
import warnings
warnings.simplefilter("ignore", )
import japanize_matplotlib
PATH_OUTPUT = 'output/001'
import os
os.makedirs(PATH_OUTPUT, exist_ok=True)
# 1) 読み込み
csv_path = "data/events_sorted.csv"
df = pd.read_csv(csv_path)
# 2) 解析用の列を整備
if "datetime" in df.columns:
df["datetime"] = pd.to_datetime(df["datetime"])
else:
# 念のため date と time から作成
df["datetime"] = pd.to_datetime(df["date"] + " " + df["time"])
# 時刻(0-24h)を算出
df["tod_hours"] = df["datetime"].dt.hour + df["datetime"].dt.minute/60.0
# 横軸用:日付(時刻は 00:00 に正規化)
df["date_only"] = df["datetime"].dt.normalize()
# 3) 散布図作成(イベント種類ごとに色分け/Matplotlib デフォルト色)
fig, ax = plt.subplots(figsize=(20, 10), dpi=120, facecolor="white", edgecolor="black")
for cat, g in df.groupby("category"):
ax.scatter(g["date_only"], g["tod_hours"], label=str(cat), s=14, alpha=0.8)
# 軸と凡例の体裁
ax.set_xlabel("日付")
ax.set_ylabel("時刻(時)")
ax.set_ylim(-0.5, 24.5)
# 目盛り:毎時刻
ax.set_yticks(np.arange(0, 25, 2))
# 横軸は日ごと
ax.xaxis.set_major_locator(mdates.DayLocator())
ax.xaxis.set_major_formatter(mdates.DateFormatter("%Y-%m-%d"))
plt.xticks(rotation=45, ha="right")
ax.grid(True, linestyle="--", linewidth=0.5, alpha=0.5)
ax.legend(title="イベント種類", loc="best", fontsize=8)
out_fig = f"{PATH_OUTPUT}/scatter_events_time_of_day_vs_date.png"
plt.tight_layout()
plt.savefig(out_fig, dpi=150)
plt.show();

© kurumaru
カテゴリー別の可視化
ミルク、母乳、おしっこのようにカテゴリーごとに区切って可視化してみましょう。
Python実装
# -*- coding: utf-8 -*-
import os, re
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import numpy as np
import warnings
warnings.simplefilter("ignore", )
# 日本語フォント(あれば有効化)
try:
import japanize_matplotlib # noqa: F401
except Exception:
pass
PATH_OUTPUT = 'output/001'
os.makedirs(PATH_OUTPUT, exist_ok=True)
# 1) 読み込み
csv_path = "data/events_sorted.csv"
df = pd.read_csv(csv_path)
# 2) 列整備
if "datetime" in df.columns:
df["datetime"] = pd.to_datetime(df["datetime"])
else:
df["datetime"] = pd.to_datetime(df["date"] + " " + df["time"])
df["tod_hours"] = df["datetime"].dt.hour + df["datetime"].dt.minute/60.0
df["date_only"] = df["datetime"].dt.normalize()
# 3) 出力対象カテゴリ(頻度順に並べ替え)
cats = df["category"].fillna("未分類").astype(str)
cat_order = cats.value_counts().index.tolist()
def sanitize_filename(name):
return re.sub(r"[^\w\-.]", "_", name, flags=re.UNICODE)[:80] or "category"
# 4) カテゴリごとに散布図を出力(横軸は1週間ごと)
for cat in cat_order:
g = df[df["category"].fillna("未分類").astype(str) == cat]
if g.empty:
continue
fig, ax = plt.subplots(figsize=(20, 10), dpi=120, facecolor="white", edgecolor="black")
ax.scatter(g["date_only"], g["tod_hours"], s=14, alpha=0.8)
ax.set_title(f"イベント: {cat}(日付×時刻の散布図)")
ax.set_xlabel("日付")
ax.set_ylabel("時刻(時)")
ax.set_ylim(-0.5, 24.5)
ax.set_yticks(np.arange(0, 25, 2))
# 週次(毎週)に主目盛り。月曜起点(必要に応じて mdates.SU などに変更可)
ax.xaxis.set_major_locator(mdates.WeekdayLocator(byweekday=mdates.MO, interval=1))
ax.xaxis.set_major_formatter(mdates.DateFormatter("%Y-%m-%d"))
plt.xticks(rotation=45, ha="right")
ax.grid(True, linestyle="--", linewidth=0.5, alpha=0.5)
out_fig = f"{PATH_OUTPUT}/scatter_{sanitize_filename(cat)}_weekly.png"
plt.tight_layout()
plt.savefig(out_fig, dpi=150)
plt.close(fig)

© kurumaru

© kurumaru

© kurumaru
頻度の可視化
イベントの頻度について可視化してみます。
どのような時刻がイベントが多い?何曜日が多い?また、全体として、どのようなイベントを対応することが多いのかが見えてきます。
Python実装
# 日付列の整備
if "datetime" in df.columns:
df["datetime"] = pd.to_datetime(df["datetime"])
else:
df["datetime"] = pd.to_datetime(df["date"] + " " + df["time"])
df["date_only"] = df["datetime"].dt.normalize()
df["hour"] = df["datetime"].dt.hour
df["dow"] = df["datetime"].dt.dayofweek # 0=Mon,6=Sun
dow_labels = ["Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun"]
df["category"] = df["category"].fillna("未分類").astype(str)
saved = []
# ========= 1) 日次集計:上位カテゴリの回数推移(折れ線) =========
top_n = 8
top_cats = df["category"].value_counts().head(top_n).index.tolist()
daily_counts = (
df[df["category"].isin(top_cats)]
.groupby(["date_only", "category"])
.size()
.reset_index(name="count")
.pivot(index="date_only", columns="category", values="count")
.fillna(0.0)
.sort_index()
)
fig, ax = plt.subplots(figsize=(20, 10), dpi=120, facecolor="white", edgecolor="black")
for cat in daily_counts.columns:
ax.plot(daily_counts.index, daily_counts[cat], label=str(cat))
ax.set_title("上位カテゴリの日次回数推移")
ax.set_xlabel("日付")
ax.set_ylabel("回数/日")
ax.xaxis.set_major_locator(mdates.WeekdayLocator(byweekday=mdates.MO, interval=1))
ax.xaxis.set_major_formatter(mdates.DateFormatter("%Y-%m-%d"))
plt.xticks(rotation=45, ha="right")
ax.grid(True, linestyle="--", linewidth=0.5, alpha=0.5)
ax.legend(loc="best", fontsize=8, ncols=2)
f1 = os.path.join(OUT_DIR, "daily_counts_top_categories.png")
plt.tight_layout()
plt.savefig(f1, dpi=150)
plt.show()
saved.append(f1)
# ========= 2) 時刻×曜日ヒートマップ(全イベント) =========
hour_week = (
df.groupby(["hour", "dow"]).size().unstack(fill_value=0).reindex(range(24), fill_value=0)
)
fig, ax = plt.subplots(figsize=(20, 10), dpi=120, facecolor="white", edgecolor="black")
im = ax.imshow(hour_week.values, aspect="auto", origin="lower")
ax.set_title("時刻 × 曜日 出現頻度(全イベント)")
ax.set_xlabel("曜日")
ax.set_ylabel("時刻(時)")
ax.set_xticks(np.arange(7))
ax.set_xticklabels(dow_labels)
ax.set_yticks(np.arange(0, 24, 2))
plt.colorbar(im, ax=ax, shrink=0.8, label="回数")
f2 = os.path.join(OUT_DIR, "heatmap_hour_by_weekday_all.png")
plt.tight_layout()
plt.savefig(f2, dpi=150)
plt.show()
saved.append(f2)
# ========= 3) 時刻×カテゴリ ヒートマップ(上位カテゴリ) =========
hour_cat = (
df[df["category"].isin(top_cats)]
.groupby(["hour", "category"])
.size()
.unstack(fill_value=0)
.reindex(range(24), fill_value=0)
)
fig, ax = plt.subplots(figsize=(20, 10), dpi=120, facecolor="white", edgecolor="black")
im = ax.imshow(hour_cat.values, aspect="auto", origin="lower")
ax.set_title("時刻 × カテゴリ 出現頻度(上位カテゴリ)")
ax.set_xlabel("カテゴリ")
ax.set_ylabel("時刻(時)")
ax.set_xticks(np.arange(len(hour_cat.columns)))
ax.set_xticklabels(hour_cat.columns, rotation=45, ha="right")
ax.set_yticks(np.arange(0, 24, 2))
plt.colorbar(im, ax=ax, shrink=0.8, label="回数")
f3 = os.path.join(OUT_DIR, "heatmap_hour_by_category_top.png")
plt.tight_layout()
plt.savefig(f3, dpi=150)
plt.show()
saved.append(f3)
# ========= 6) 日付×時刻ヒートマップ(活動カレンダー) =========
# 各日×時間のイベント回数を 2D 化
date_hour = (
df.groupby([df["date_only"], df["hour"]]).size().unstack(fill_value=0)
)
# 列: 0-23 の順に並べる
date_hour = date_hour.reindex(columns=range(24), fill_value=0)
# 画像化のために日付を昇順に
date_hour = date_hour.sort_index()
fig, ax = plt.subplots(figsize=(max(8, len(date_hour) * 0.15), 6))
im = ax.imshow(date_hour.values.T, aspect="auto", origin="lower")
ax.set_title("日付 × 時刻(活動カレンダー:出現回数)")
ax.set_xlabel("日付")
ax.set_ylabel("時刻(時)")
# 横軸の日付ラベル(間引き)
xticks = np.linspace(0, len(date_hour) - 1, num=min(20, len(date_hour))).astype(int) if len(date_hour) > 0 else []
ax.set_xticks(xticks)
ax.set_xticklabels([d.strftime("%Y-%m-%d") for d in date_hour.index[xticks]], rotation=45, ha="right")
ax.set_yticks(np.arange(0, 24, 2))
plt.colorbar(im, ax=ax, shrink=0.8, label="回数")
f6 = os.path.join(OUT_DIR, "heatmap_date_by_hour_calendar.png")
plt.tight_layout()
plt.savefig(f6, dpi=150)
plt.show()
saved.append(f6)
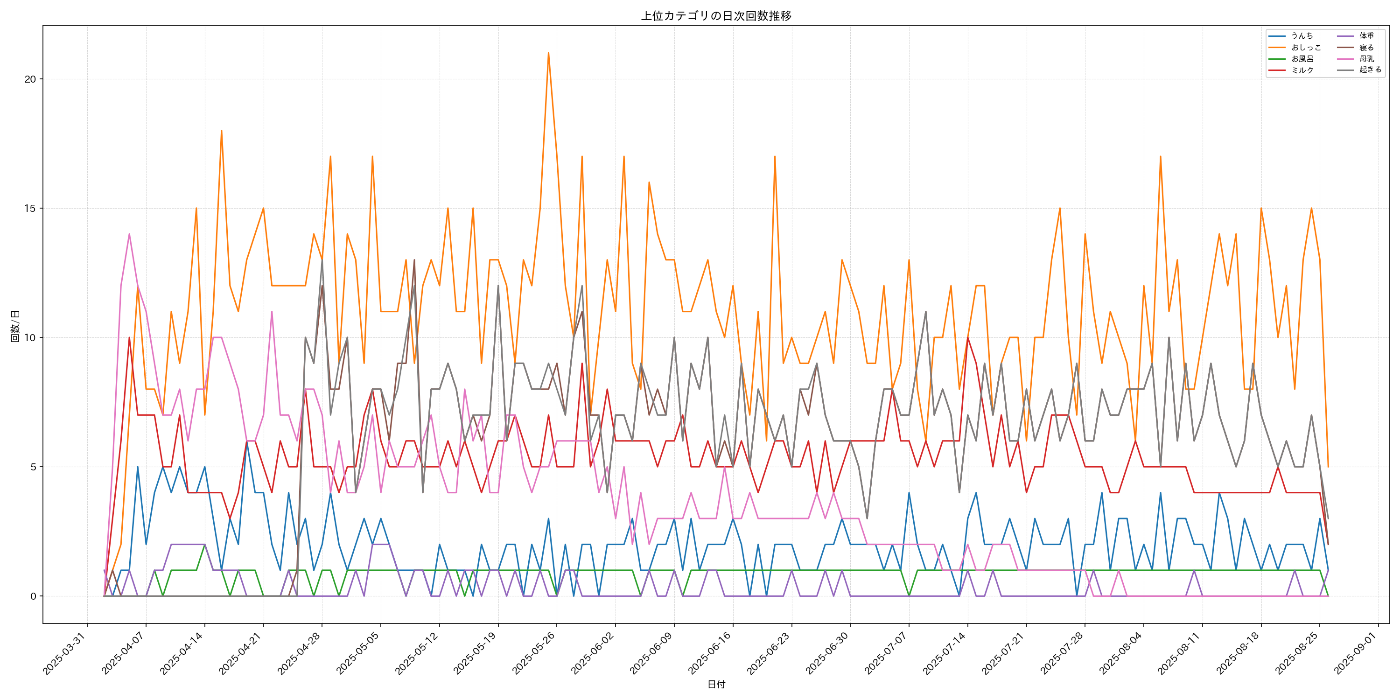
© kurumaru

© kurumaru

© kurumaru

© kurumaru
量変化の可視化
続いてはミルクや母乳の量の可視化を行います。
新生児期は特に、ミルクと母乳の合計量が重要になります。体重がある程度増えなければならないのでこちらも必死になりますよね、、、、
Python実装
# ========= 4) ミルク/母乳 量の日次合計と移動平均 =========
# amount_ml が入っているレコードを対象に集計
df_ml = df.copy()
# NaN を 0 にせず、集計時に sum(min_count=1) → 単純に sum で NaN は無視されるので OK
milk_cats = ["ミルク", "母乳"]
for target in milk_cats + ["合計"]:
if target == "合計":
sub = df_ml[df_ml["category"].isin(milk_cats)]
else:
sub = df_ml[df_ml["category"] == target]
daily_ml = sub.groupby("date_only")["amount_ml"].sum(min_count=1).dropna()
if daily_ml.empty:
continue
# 7日移動平均
ma7 = daily_ml.rolling(7, min_periods=3).mean()
fig, ax = plt.subplots(figsize=(20, 10), dpi=120, facecolor="white", edgecolor="black")
ax.plot(daily_ml.index, daily_ml.values, label=f"{target} 合計(ml)/日")
ax.plot(ma7.index, ma7.values, label="7日移動平均")
ax.set_title(f"{target} 量の日次合計と7日移動平均")
ax.set_xlabel("日付")
ax.set_ylabel("ml/日")
ax.xaxis.set_major_locator(mdates.WeekdayLocator(byweekday=mdates.MO, interval=1))
ax.xaxis.set_major_formatter(mdates.DateFormatter("%Y-%m-%d"))
plt.xticks(rotation=45, ha="right")
ax.grid(True, linestyle="--", linewidth=0.5, alpha=0.5)
ax.legend(loc="best")
fname = os.path.join(OUT_DIR, f"daily_amount_{target}.png")
plt.tight_layout()
plt.savefig(fname, dpi=150)
plt.show()
saved.append(fname)
# ========= 5) ミルクのインターバル分布(連続イベント間隔のヒストグラム) =========
mil = df[df["category"] == "ミルク"].sort_values("datetime")
if len(mil) >= 2:
intervals = mil["datetime"].diff().dropna().dt.total_seconds() / 3600.0 # hours
# 異常に長いものを除外(例:48h超)
intervals = intervals[(intervals > 0) & (intervals <= 48)]
if not intervals.empty:
fig, ax = plt.subplots(figsize=(18, 7), dpi=120, facecolor="white", edgecolor="black")
ax.hist(intervals.values, bins=24) # デフォルト色
ax.set_title("ミルクの連続イベント間隔(時間)分布")
ax.set_xlabel("間隔(時間)")
ax.set_ylabel("頻度")
ax.grid(True, linestyle="--", linewidth=0.5, alpha=0.5)
f5 = os.path.join(OUT_DIR, "hist_interval_milk_hours.png")
plt.tight_layout()
plt.savefig(f5, dpi=150)
plt.show()
saved.append(f5)

© kurumaru

© kurumaru

© kurumaru
間隔の可視化
ミルクから次のタイミングまでの間隔も重要です。新生児の時は、2時間ごとなどの子供のスケジュールに合わさざるを得ないです。では、新生児期から生後4ヶ月ではどれくらい変化するのかについての可視化です。
まずは、経過月ごとに可視化してみます。
Python実装
# -*- coding: utf-8 -*-
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 日本語フォント(ある場合のみ自動適用)
try:
import japanize_matplotlib # noqa: F401
except Exception:
pass
# ========= 設定 =========
# CSV_PATH = "/mnt/data/events_sorted.csv"
OUT_DIR = "output/003"
os.makedirs(OUT_DIR, exist_ok=True)
# ========= データ読み込み =========
# df = pd.read_csv(CSV_PATH)
if "datetime" in df.columns:
df["datetime"] = pd.to_datetime(df["datetime"])
else:
df["datetime"] = pd.to_datetime(df["date"] + " " + df["time"])
# ========= ミルクの連続イベント間隔を算出 =========
milk = df[df["category"] == "ミルク"].sort_values("datetime").copy()
# 2レコード未満だと間隔が出せないのでチェック
if len(milk) >= 2:
# 直前のイベントからの差分(後側のイベントの日時を基準)
milk["interval_h"] = milk["datetime"].diff().dt.total_seconds() / 3600.0
# 異常値の除外(0以下・48h超)
milk = milk[(milk["interval_h"] > 0) & (milk["interval_h"] <= 48)]
# 月ラベル(後側イベントの月)
milk["month"] = milk["datetime"].dt.to_period("M").astype(str) # 例: "2025-06"
# ========= 月別ヒストグラム(重ね描き) =========
bins = np.arange(0, 24 + 1, 0.25) # 0.25時間刻み、0〜24h
months = sorted(milk["month"].unique())
fig, ax = plt.subplots(figsize=(15, 7), dpi=120, facecolor="white", edgecolor="black")
for m in months:
vals = milk.loc[milk["month"] == m, "interval_h"].values
if len(vals) == 0:
continue
# デフォルトカラーマップに任せて月ごとに重ね描き(色指定する)
ax.hist(vals, bins=bins,
# histtype="step",
linewidth=1.6,
label=m,
alpha=0.5)
ax.set_title("ミルクの連続イベント間隔(時間)分布:月別(重ね描き)")
ax.set_xlabel("間隔(時間)")
ax.set_ylabel("頻度")
ax.set_xticks(np.arange(0, 49, 4))
ax.grid(True, linestyle="--", linewidth=0.5, alpha=0.5)
ax.legend(title="月", fontsize=8, ncols=2)
# 横軸は 20時間に制限
ax.set_xlim(0, 16)
out_fig = os.path.join(OUT_DIR, "hist_interval_milk_by_month_overlaid.png")
plt.tight_layout()
plt.savefig(out_fig, dpi=150)
plt.show()
else:
out_fig = None
out_fig

© kurumaru
月ごとに頻度を集計してを作成して出力してみます。月ごとの集計結果では変化が見られたので並べて可視化してみます。
Python実装
# -*- coding: utf-8 -*-
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# ========= 設定 =========
#
OUT_DIR = "output/004"
os.makedirs(OUT_DIR, exist_ok=True)
# ========= データ読み込み =========
# df = pd.read_csv(CSV_PATH)
if "datetime" in df.columns:
df["datetime"] = pd.to_datetime(df["datetime"])
else:
df["datetime"] = pd.to_datetime(df["date"] + " " + df["time"])
# ========= ミルクの連続イベント間隔を算出 =========
milk = df[df["category"] == "ミルク"].sort_values("datetime").copy()
generated_files = []
if len(milk) >= 2:
milk["interval_h"] = milk["datetime"].diff().dt.total_seconds() / 3600.0
milk = milk[(milk["interval_h"] > 0) & (milk["interval_h"] <= 48)]
milk["month"] = milk["datetime"].dt.to_period("M").astype(str) # "YYYY-MM"
months = sorted(milk["month"].unique())
# 0.25h刻みの共通ビン、0〜24h(表示は0〜16h)
bins = np.arange(0, 24 + 0.25, 0.25)
# 5件ずつ(月)に分けて個別PNGを連番出力
for i in range(0, len(months), 5):
batch = months[i:i+5]
for m in batch:
vals = milk.loc[milk["month"] == m, "interval_h"].values
if len(vals) == 0:
continue
fig, ax = plt.subplots(figsize=(12, 6), dpi=120, facecolor="white", edgecolor="black")
ax.hist(vals, bins=bins, linewidth=1.6, alpha=0.7) # 色はデフォルト
ax.set_title(f"ミルクの連続イベント間隔(時間)分布:{m}")
ax.set_xlabel("間隔(時間)")
ax.set_ylabel("頻度")
ax.set_xlim(0, 16)
ax.set_xticks(np.arange(0, 17, 2))
ax.grid(True, linestyle="--", linewidth=0.5, alpha=0.5)
out_png = os.path.join(OUT_DIR, f"hist_interval_milk_{m}.png")
plt.tight_layout()
plt.savefig(out_png, dpi=150)
plt.close(fig)
generated_files.append(out_png)
generated_files

© kurumaru

© kurumaru

© kurumaru
追加の可視化
最後に、寝るタイミングと起きるタイミングも、気になったので月ごとに集計をして頻度を可視化してみました。
Python実装
# -*- coding: utf-8 -*-
import os
import re
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# ========= 設定 =========
#
OUT_DIR = "output/005"
os.makedirs(OUT_DIR, exist_ok=True)
# ========= データ読み込み =========
# df = pd.read_csv(CSV_PATH)
if "datetime" in df.columns:
df["datetime"] = pd.to_datetime(df["datetime"])
else:
df["datetime"] = pd.to_datetime(df["date"] + " " + df["time"])
# 前処理
df["category"] = df["category"].fillna("").astype(str)
def pick_events(df, targets_exact=None, targets_regex=None):
"""カテゴリの抽出を頑健化。exact優先、なければregexで抽出。"""
sub = pd.DataFrame(columns=df.columns)
targets_exact = targets_exact or []
# exact
if targets_exact:
sub = df[df["category"].isin(targets_exact)].copy()
# regex fallback
if sub.empty and targets_regex:
pat = re.compile("|".join(targets_regex))
sub = df[df["category"].str.contains(pat)].copy()
return sub
def export_interval_histograms_by_month(sub_df, label, out_dir):
"""連続イベント間隔(時間)を算出し、月ごとに個別PNGを出力(単一プロット、色重ねなし)。"""
generated = []
if len(sub_df) < 2:
return generated
sub_df = sub_df.sort_values("datetime").copy()
sub_df["interval_h"] = sub_df["datetime"].diff().dt.total_seconds() / 3600.0
# 0 < interval <= 24 に限定
sub_df = sub_df[(sub_df["interval_h"] > 0) & (sub_df["interval_h"] <= 24)]
if sub_df.empty:
return generated
# 月ラベル(後側イベントの月)
sub_df["month"] = sub_df["datetime"].dt.to_period("M").astype(str)
months = sorted(sub_df["month"].unique())
# 0.1h刻み、0〜24h(表示は0〜16hに制限)
bins = np.arange(0, 24, 0.5)
# 5段出力
fig, axs = plt.subplots(nrows=5, ncols=1, figsize=(24, 12), dpi=120, facecolor="white", edgecolor="black")
axs = axs.flatten()
for i, m in enumerate(months):
vals = sub_df.loc[sub_df["month"] == m, "interval_h"].values
if len(vals) == 0:
continue
axs[i].hist(vals, bins=bins, linewidth=1.6, alpha=0.7, color=plt.cm.viridis(i / len(months))) # 色は月ごとに変える
axs[i].set_title(f"{label}の連続イベント間隔(時間)分布:{m}")
axs[i].set_xlabel("間隔(時間)")
axs[i].set_ylabel("頻度")
axs[i].set_xlim(0, 16)
axs[i].set_xticks(np.arange(0, 17, 2))
axs[i].grid(True, linestyle="--", linewidth=0.5, alpha=0.5)
out_png = os.path.join(out_dir, f"hist_interval_{label}.png")
plt.tight_layout()
plt.savefig(out_png, dpi=150)
plt.close(fig)
# 1) 「寝る」相当(exact優先、なければ正規表現でフォールバック)
sleep_df = pick_events(
df,
targets_exact=["寝る"],
targets_regex=[r"^ねんね", r"寝(る|開始)?"] # ねんね、寝る、寝…開始 等を幅広く
)
export_interval_histograms_by_month(sleep_df, "寝る", OUT_DIR)
# 2) 「起きる」相当(exact優先、なければ正規表現でフォールバック)
wake_df = pick_events(
df,
targets_exact=["起きる"],
targets_regex=[r"起(き|床)"] # 起き…, 起床 など
)
export_interval_histograms_by_month(wake_df, "起きる", OUT_DIR)
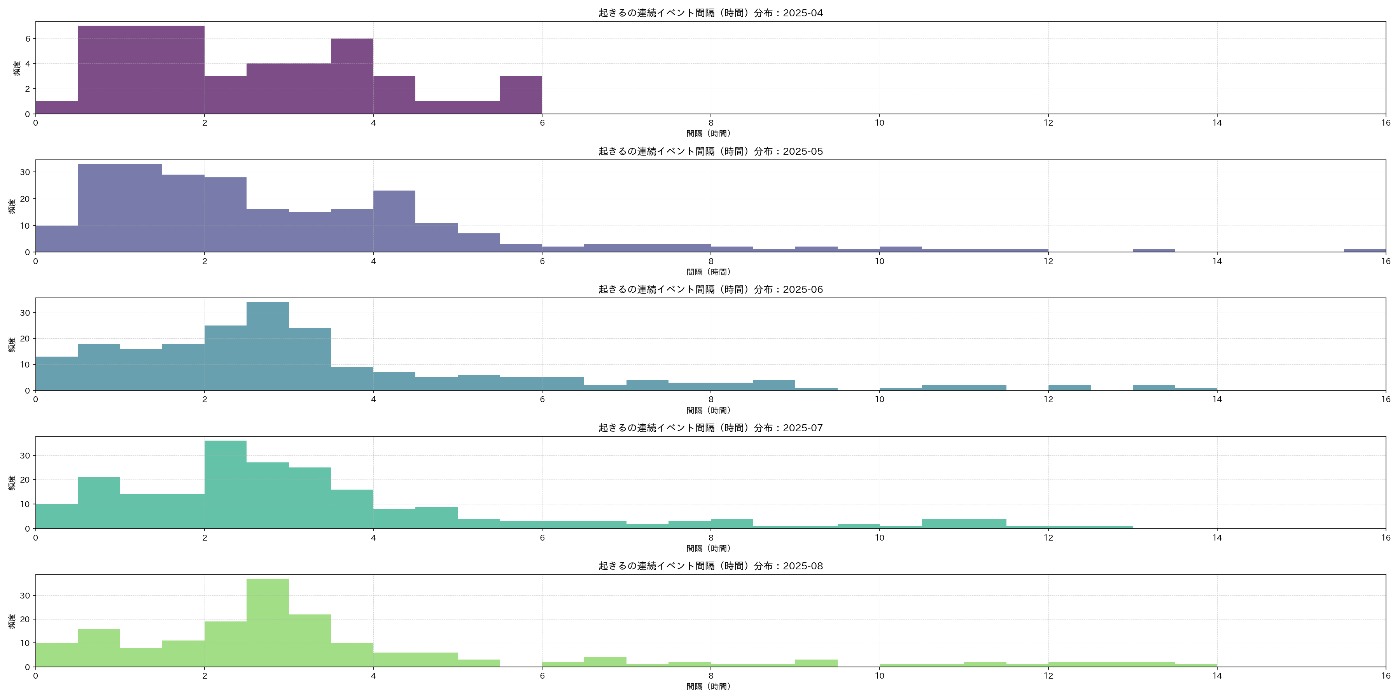
© kurumaru

© kurumaru
分析
分析については以下のスライドにまとめました。以下の方がわかりやすいと思います。
データでわかるあるある問題
あるあるについてもざっくりとまとめてみました。
データを可視化してみると解決やその理由が少しずつ見えてきたような気がします。
- 新生児の時の記憶がない
- 寝るとかまで記録をつける余裕がないことから本当に死にそうなことが理由
- ミルクの量が減った
- 夜を覚えて寝る時間が増えたため
- 夕方のギャン泣きが増えた
- ミルクの量を増やせておらず、お腹が減っていた
- ミルクや母乳を飲む量がわからない
- 個人差が大きいものの月ごとの値は変化を共有
- なんか楽になったのタイミング
- ミルクや母乳の回数が減ったとき
- 特に、生後4ヶ月のタイミングで4回になり規則正しくなった
さいごに
記録を振り返ると、あの日々の大変さが数字やグラフとして静かに語りかけてきます。授乳やミルクの量、寝つくまでの時間、夜泣きの回数――どれも当事者の私たちにとってはその瞬間の必死さが前面に出ますが、データとして積み重なると「できるようになったこと」「少しずつ減ってきた負担」がはっきり見えてきます。昨日より10分長く眠れた、1週間前より飲む量が安定した、夕方のぐずりが少し短くなった。小さな変化でも、並べてみると確かな成長の足跡です。数値は冷たいものではなく、私たちが毎日費やした時間と愛情の記録そのものなのだと気づかされます。
そして何より、ここまで一緒に走ってくれたパートナーや家族の存在が、行間から浮かび上がります。夜中の抱っこを交代してくれたこと、買い物や家事をそっと引き受けてくれたこと、悩みを聞いて「大丈夫」と支えてくれたこと。記録の背後には、見えないたくさんの「ありがとう」が積み重なっています。完璧でなくていい、理想通りに進まなくても大丈夫。今日もやれることをやり、無理な日は「休む」を選べた自分たちを、まずは労ってあげたいです。
これから先もきっと、思い通りにならない日が続きます。けれど、記録が教えてくれるのは「確実に前へ進んでいる」という事実です。できれば節目ごとに簡単なひとことでも良いので、感じたことを添えてみてください。数か月後、そこには数字だけでは語り切れない物語が残ります。大変さも含めて、今この瞬間は二度と戻りません。だからこそ、今日の私たちと、支えてくれる人たちに、心からの感謝を。小さな一歩を祝福しながら、明日もまた一緒に歩んでいきましょう。
宣伝
日頃はこのようなZennの個人記事を書いています。
また、近日には衛星画像解析の書籍を出版いたします。
自己紹介
普段は宇宙領域でテックリードをしております。X(旧Twitter)アカウントでは、宇宙領域や機械学習などの科学やコンペなどについて発言することが多いです。
SAR解析をよくやっていますが、画像系AI、地理空間や衛星データ、点群データ、3Dデータに関心があります。勉強している人は好きなので楽しく絡んでくれると嬉しいです。
SAR解析者への道シリーズ もよろしくお願いします!

衛星データ解析として、宙畑のライターもしています。
お仕事はとても忙しいのでご相談やご提案くらいでしたら可能です。
Discussion