AWS 構成の基礎知識 - 1: Cloud Design Pattern
僕の未知の領域へのアプローチは「単語を仕入れまくって関連要素の整理をしたり今の自分にとっての関係度を整理する」こと
なので
- 情報の取り捨て選択もできない状態からの脱却を目指す
- 自分が今調べるべきことが何かわかる状態にする
- とりあえずざっと見る
- パターンの深追いは、必要な箇所だけ二週三週とやる
1 つ 5m で見ても 5h かかるか...
一週目の雑記
キャリア的にインフラがクソ弱点
- ガチガチオンプレ + 申請ベースの環境で 10 年近くやったので、自分で構成を考える経験が極端に少ない
- 考える必要に迫られたが、考えられるという段階ではない
- 考えられないのなら愚直に知るところからやるしかない
-
単語を仕入れまくって関連要素の整理をしたり今の自分にとっての関係度を整理する
-
広く漁る
- パターンはあえて取り捨て選択せず全部見たのが功を奏した
- たまたま目に入ったものか、それとも頻出するものかを判断できないので、母数を増やした
- 結果的に、繰り返し出てくる scaling や caching や ondemand という考え方に少し慣れた
- 自分の知ってること、知らないことを少し細かく把握できた
- 思ったほどの完全無知ではなかった
- 疎結合の観点や並行稼働・検証や移行に関することなどは 「モノリスからマイクロサービスへ」サマリのサマリ で学んだことが多かった
- そもそもその課題を抱えている地獄をよく知っているし、そこから脱却するためにいろいろ考えてたことはちゃんと地肉になってた
- 会社で共有される事例紹介や障害事象がまんまパターンやリスクに該当するケースがあった
- 思ったほどの完全無知ではなかった
- あとぶっちゃけると、インフラ頑張るモードにしてスイッチを入れるためってのが大きい
- パターンの理解自体は目的ではないのでそこそこに
- ページが結構古いし、方法が陳腐化している可能性は結構高いと思う
- 具体手段ではなくて課題とアプローチの方にフォーカスする
- コピペ構築したいわけじゃあなくて、理解が目的だから
- とはいっても全部が今必要なわけではないので、そこらへんを考えて 1 つ 5m ペース
- 1 つ 5m ペースはほぼムラなく保った
- 集中を保ちつつかつ深追いはしないちょうど良い設定だった
今後
- 最初に目論んだ別の調査をして良さそう
- そこで考慮した方が良さそうなことに何点か気付いたし、結果オーライ
- ここで切らないと一生インフラスクラップがクローズできないので、これはここまで
20000 文字超えると post できないのかw
基本のパターン
Snapshot パターン
データのバックアップ
- 💡 ある瞬間のデータを複製したバックアップを
スナップショットって言うぞ - 💡 EBS ( 仮想ストレージ ) で撮って S3 で保管するゾ
- 👍 自動化が容易だぞ
- 🤔 タイミングと整合性に注意しろよ

Stamp パターン
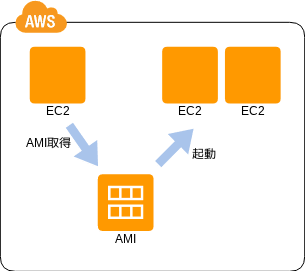
サーバの複製
- 💡 物理サーバと違って仮想サーバは増減させやすいぞ
- 💡 ミドルやアプリの設定を行えば、以後はスタンプのようにコピーして複製できるぞ
- 👍 同じインスタンスを容易に用意できる
- 🤔 スナップショットの運用や複製後のベースイメージへのバージョンアップの適用をちゃんと考えろよ
Scale Up パターン
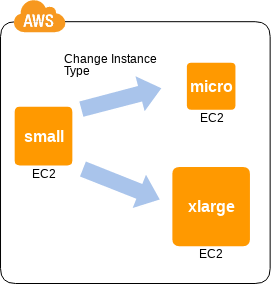
動的なサーバのスペックアップ / ダウン
- 💡 マシン単体のスペックを上げるアプローチを
スケールアップって言うぞ - 👍 最初に厳密なスペック見積もりがいらないぞ
- 👍 時期や負荷に応じて適度な設定にすることでコストを抑えられるぞ
- 🤔 変更には停止が伴うぞ
- 🤔 仮想サーバとは言っても上限はあるぞ
Scale Out パターン
サーバ数の動的増減
- 💡 サーバを複数並べるアプローチを
スケールアウトって言うぞ - 👍 スケールアップに比べて上限が高い
- 👍 停止を伴わずトラフィックに合わせて増減させられる
- 🤔 判断と増減に時間がかかるので数分刻みの急激な変化には追従できないぞ
- 🤔 Web / AP サーバと比べて DB サーバでこれをやるのは一般に難しいぞ → リレーショナルデータベースのパターン

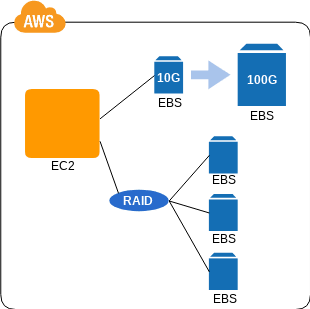
Ondemand Disk パターン
動的なディスク容量の増減
- 💡 仮想ディスク EBS を使えば任意のタイミングで任意の容量を確保できるぞ
- 👍 最初に厳密なスペック見積もりがいらないし、物理ディスクの様に最初に大きく調達する必要がないぞ
- 🤔 EBS は使用領域じゃあなくて確保領域で課金するから気をつけろよ
可用性を向上するパターン
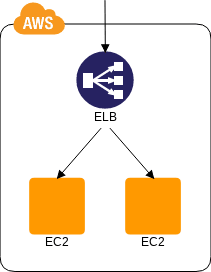
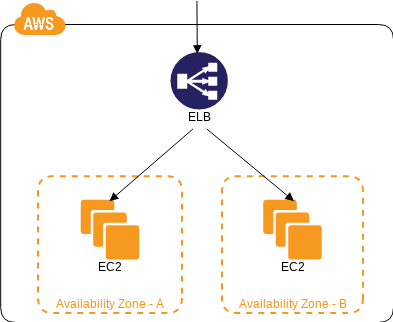
Multi-Server パターン
サーバの冗長化
- 💡 仮想サーバを複数並べロードバランサを用いて負荷を振り分けることを
Multi-Serverと言うぞ - 👍 ELB は EC2 のヘルスチェック機能がついてるので死んだ EC2 には振り分けないぞ
- 👍 Auto Scaling と組み合わせて使うと最低稼働台数を保証したりできるぞ
- 🤔 ミドルやアプリで共有するデータ ( セッションなど ) は、セッション DB とかを使うぞ → State Sharing パターン
- 🤔 DB を冗長化する場合はデータ同期に気をつけろよ → DB Replication パターン
Multi-Datacenter パターン
データセンターレベルの冗長化
- 💡 Multi-Server はサーバ障害を想定しているが、停電や火災によるデータセンターレベルの障害には対応できないぞ
- 👍 東京などの
リージョンの中にAZと呼ぶデータセンターが複数存在し、専用線でつながっているぞ - 👍 専用線だから高速だし、どこを使うかは利用者で決められるぞ
- 👍 AZ はコストに影響しないので、単一 AZ でも複数 AZ でも費用は同じだぞ
- 🤔 専用線とはいえ AZ 内通信よりは劣る
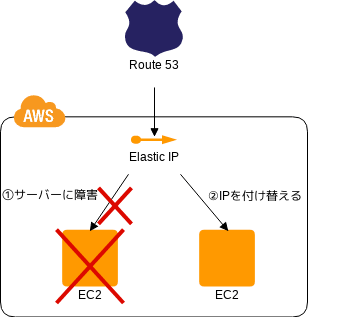
Floating IP パターン
IP アドレスの動的な移動
- 💡 サーバにパッチを当てたりスペック変更をする場合のサーバ停止に備えて DNS を使って予備サーバに切り替えたりすることがあるぞ
- 💡 IP アドレス設定の API とかがあるので、それをオンプレより簡単にできるぞ
- 👍 フォールバックが容易だぞ
- 👍 EIP は AZ をまたがって適用できる
- 🤔 とはいえ数秒はかかるぞ
Deep Health Check パターン
システムのヘルスチェック
- 💡 LB や DNS のヘルスチェックではバックエンドの AP や DB サーバまで把握できないぞ
- 💡 LB や DNS のヘルスチェック機能でプログラムをチェックする様に設定し、そのプログラムで DB などまで疎通チェックをすると、奥まで把握できるぞ
- 👍 プログラムによるチェックはカスタマイズの余地が多いぞ
- 🤔 プログラム自体に高度な安定性が要求されるぞ
- 🤔 チェック自体が負荷をかけない様にしろよ
- 🤔 DB サーバが単一障害点だと全滅判定になっちゃうので気をつけろよ → DB Replication パターン

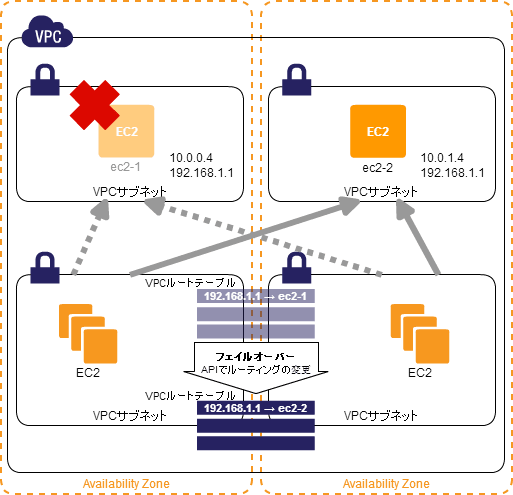
Routing-Based HA パターン
ルーティングによる接続先の透過的な切り替え
- 💡 フェイルオーバーの切り替えは同一サブネットなら比較的容易だけどサブネットやデータセンターを超えると難しいぞ
- 💡 クラウドによっては複数データセンターの扱いが容易であり、かつルーティングの変更が API でできる場合は容易になるぞ
- 👍 このパターンだと AZ ( 必然的にサブネットも ) を跨いだフェイルオーバーにも利用できるぞ
- 🤔 API 利用のためのインターネットへの https outbound が必要になるぞ
動的コンテンツを処理するパターン
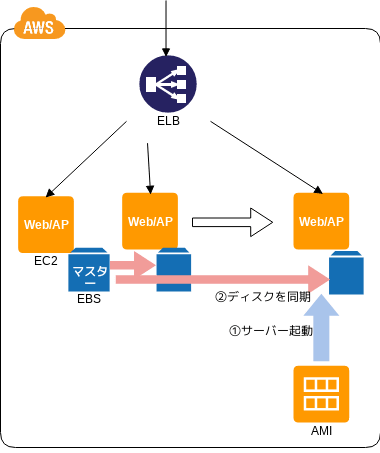
Clone Server パターン
サーバのクローン
- 💡 従来負荷分散を想定していなかったシステムを負荷分散可能にするぞ
- 💡 現行サーバをマスターとし、そのイメージでサーバを追加するぞ
- 👍 既存システムの大きな変更がいらないぞ
- 🤔 マスターのインスタンスが単一障害点になってしまうので気をつけろよ
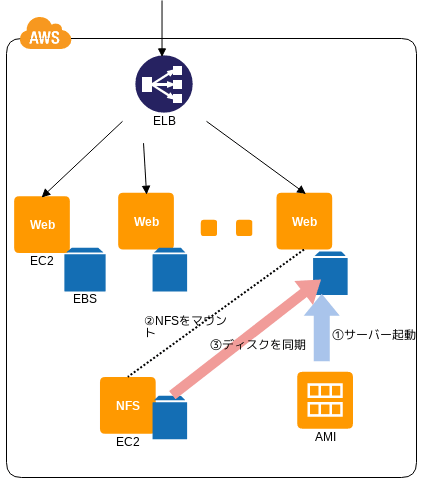
NFS Sharing パターン
共有コンテンツの利用
- 💡 複数サーバで負荷分散している場合、データの同期が大変だぞ
- 💡 定期的な動機では遅延が問題になったり、スレーブ側の変更が他のスレーブやマスターに反映できなかったりするぞ
- 💡 なのでコンテンツのマスターを NFS サーバとするといいぞ
- 👍 マウントするだけなので簡単だぞ
- 🤔 NFS クライアント ( = EC2 ) が増えるとパフォーマンスの問題がでるぞ
- 🤔 NFS サーバが単一障害点になりやすいぞ → 今は EFS 使えばいいぞ

NFS Replica パターン
共有コンテンツの複製
- 💡 NFS Sharing パターンにおいてNFS クライアントが増えるとパフォーマンスが劣化してくるぞ
- 💡 各サーバに仮想ディスク ( EBS ) を用意して NFS サーバのコピーをしておくと参照レプリカとして使えるぞ
- 👍 NFS サーバへのアクセスがないのでパフォーマンス問題が緩和されるぞ
- 👍 NFS サーバがダウンしても単一障害点にならないぞ
- 🤔 共有ファイルを変更する場合は
rsyncなどを使わないと EC2 まで反映されないぞ
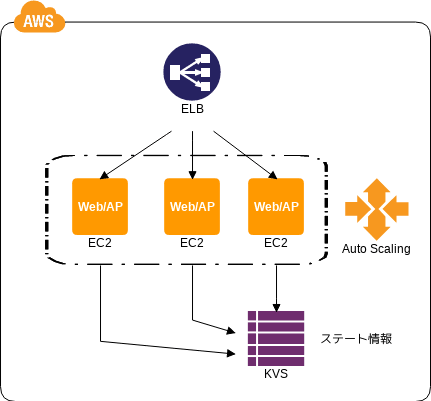
State Sharing パターン
ステート情報の共有
- 💡 ユーザ固有の状態を持つステート情報 ( HTTP セッション ) を各サーバで持っているとサーバダウンやスケールアウトで消失するぞ
- 💡 耐久性の高い共有データストア ( メモリやディスク ) に置くと各サーバをステートレスにできるぞ
- 💡 インメモリキャッシュである ElastiCache ( Memcached, Redis ) や NoSQL ( DynamoDB, SimpleDB ) や RDB ( RDS ) とかから選んでな
- 🤔 アクセスが集中するのでボトルネックにならない様にな
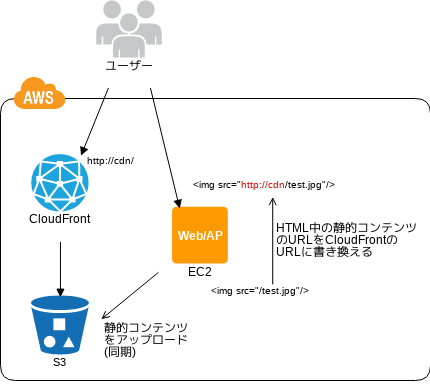
URL Rewriting パターン
静的コンテンツの退避
- 💡 スケールアップやスケールアウトで高負荷に備えるけど、実は大半が静的コンテンツへのアクセスってことが多いぞ
- 💡 静的コンテンツの URL をインターネットストレージに変更したり、コンテンツ配信サーバから配信するといいぞ
- 👍 CloudFront を使うと全世界配信に対する距離を起因とするレイテンシー対策にもなるぞ
- 🤔 CloudFront を使うならキャッシュされるのでそこらへん注意な
Rewrite Proxy パターン
URL 書き換えプロキシの設置
- 💡 URL Rewriting パターンだとコンテンツの URL 変更などの既存システム変更が必要だぞ
- 💡 コンテンツサーバの手前にプロキシを置くといいぞ
- 👍 既存システムの変更をしなくてよくなるぞ
- 🤔 プロキシサーバを冗長化しないと、それが単一障害点になるぞ

Cache Proxy パターン
キャッシュの設置
- 💡 スケールアウトはコストがかかるので予算が少ないなら増やさない方法も考えたいよな
- 💡 変化の ( あまり ) ないコンテンツをキャッシュして配信するといいぞ
- 👍 動的コンテンツのコンテンツ生成の負荷を大きく低減できるぞ
- 👍 HTTP ヘッダーや URL や Cookie で柔軟な設定ができるぞ
- 🤔 キャッシュサーバを冗長化しないと、それが単一障害点になるぞ

Scheduled Scale Out パターン
サーバ数のスケジュールに合わせた増減
- 💡 5 分以内のような突発的なアクセス増加や一定時間のみ大量リソースを使いたい場合、オートスケールではうまくいかないことがあるぞ
- 💡 アクセス急増が読める場合や必要リソースが増える時間がわかっている場合、スケジューリングするといいぞ
- 👍 ちゃんと運用できると結果的にコスト削減できるぞ
- 🤔 課金ルールをちゃんと把握しておけよ、例えば EC2 はすぐ破棄しても最低で 1h 単位の課金だぞ

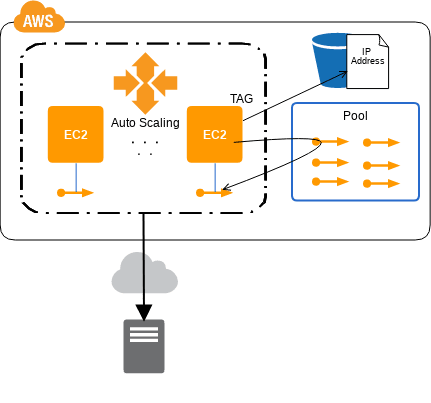
IP Pooling パターン
接続許可済み IP アドレスのプール
- 💡 様々な理由で接続元 IP でアクセス制限をすることが多いが、手でやってるとクラウドのメリットが得づらいぞ
- 💡 事前に必要なグローバル IP を確保して登録しておいて、サーバの変更や増減時にその IP プールから持ってきて割り当てるといいぞ
- 👍 オートスケーリングでも利用できるぞ
- 🤔 EC2 に紐づいてない ElasticIP は課金対象だから注意な
静的コンテンツを処理するパターン
Web Storage パターン
可用性の高いインターネットストレージ活用
- 💡 でかいファイルを 1 台で配信すると負荷が問題になるし、複数台で配信するとコストが問題になるぞ
- 💡 インターネットストレージに配置してそこから配信すると負荷や同期の問題が解決するぞ
- 👍 S3 は耐久性が高いから安心だぞ
- 🤔 メインサイトの DNS 名をそのまま使えないので S3 のコンテンツは別名にする必要があり、作成済みのコンテンツリンクを変更する必要があるかもしれないぞ

Direct Hosting パターン
インターネットストレージで直接ホスティング
- 💡 画像や動画に限らず HTML などもホスティングしちゃうと負荷やスケールアウトコストが問題になりづらいぞ
- 👍 S3 は耐久性が高いから安心だぞ
- 🤔 S3 で配信したコンテンツに JS を埋め別サーバにもアクセスさせる場合とかだと CORS 対応が必要だぞ
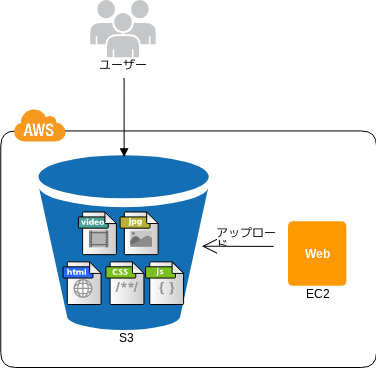
Private Distribution パターン
特定ユーザへのデータ配布
- 💡 特定ユーザのみに配信する場合などは認証などを考えないといけないが、インターネットストレージだけではアクセス制限が難しいぞ
- 💡 インターネットストレージの制限付き URL 発行という機能を使うと、アクセス元や期間を設定できるぞ
- 👍 結果的にプライベートコンテンツの配布を実現できるし、EC2 を通さず行われるので負荷に強いぞ
- 🤔 認証システムと期限付き URL を発行するサーバは必要だぞ

Cache Distribution パターン
ユーザに物理的に近い位置へのデータ配置
- 💡 より多くの地域から、よりでかいデータにアクセスする様になってきているが、物理的に遠いとどうしても遅延するぞ
- 💡 世界各地にコンテンツのキャッシュを配置して物理的に近いところから配信するといいぞ
- 👍 負荷分散と UX 向上に繋がるぞ
- 🤔 あくまでキャッシュなのでコンテンツ更新の反映などは考えろよ

Rename Distribution パターン
変更遅延のない配信
- 💡 Cache Distribution ではキャッシュが無効になるまでマスターの更新が反映されないぞ
- 💡 コンテンツの名前を変え URL 自体を変えることで、即配信できるぞ
- 👍 任意のタイミングで配信できる
- 🤔 古い URL でアクセスされると困る場合は必要に応じて消したり無効化したりしろよ

Private Cache Distribution パターン
CDN を用いたプライベート配信
- 💡 特定のユーザにコンテンツを配信するためには認証とか考えないといけないぞ
- 💡 あらかじめ定めたアクセス元や期間や地域に合致した場合のみコンテンツデリバリーの署名付き URL 認証機能を発行すると制御できるぞ
- 👍 実質プライベートコンテンツの配信ができるぞ
- 🤔 認証システムと期限付き URL を発行するサーバは必要だぞ

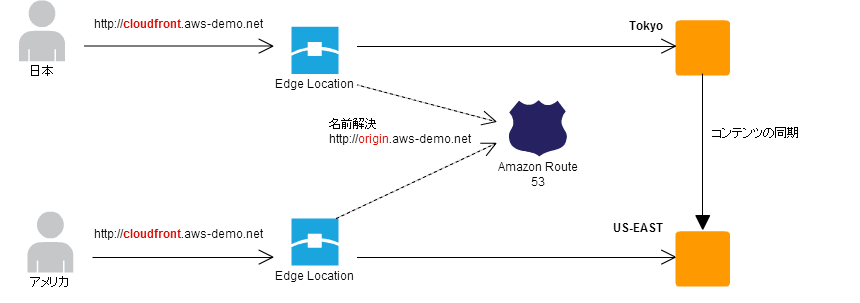
Latency Based Origin パターン
地域によりオリジンサーバを変更
- 💡 ブランディングとかしたいからグローバル展開しているコンテンツを CDN から全世界に同じ URL でアクセスさせたいとかあるよな
- 💡 エッジサーバにキャッシュがあればいいけど、ない場合は遠いオリジンまでアクセスするので遅くなるぞ
- 💡 オリジンサーバを複数用意し同一コンテンツを保持させ、1 DNS 名に対して複数のオリジンサーバ DNS を登録し、近いのを返してもらうぞいいぞ
- 👍 地域によって URL を作ったりしなくていいぞ
- 🤔 全てのオリジンを S3 にはできないぞ
- 🤔 コンテンツの同期は色々気をつけてやれよ
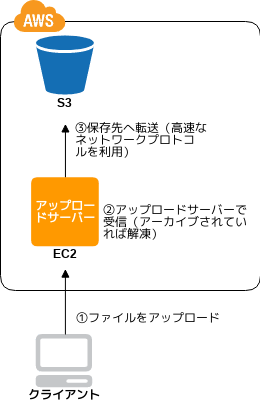
データをアップロードするパターン
Write Proxy パターン
インターネットストレージへの高速アップロード
- 💡 インターネットストレージは read には強いけど write は比較的劣るぞ
- 💡 クライアントからインターネットストレージ直接ではなく、仮想サーバで一度受けてから転送するといいぞ
- 👍 HTTP より高速な UDP ベースのプロトコルが使えたり、アーカイブして転送したりできる様になるぞ
- 👍 インターネットストレージと仮想サーバは同一リージョンなら専用線なのでクライアントからより早いぞ
- 🤔 EC2 ( EBS ) への書き込み速度がボトルネックになりがちなので考慮しろよ → Ondemand Disk パターン
- 🤔 小さい EC2 は相対的に回線が細いので気をつけろよ
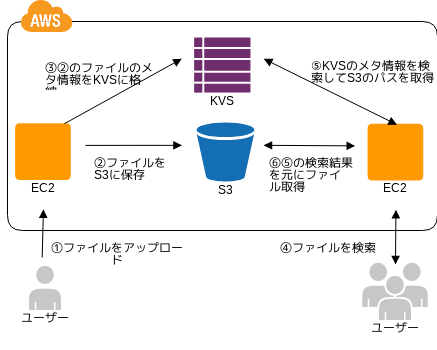
Storage Index パターン
インターネットストレージの効率化
- 💡 インターネットストレージは高度な検索ができないことがあり、特定ユーザの一覧とか日付範囲で絞ったりはアプリの工夫が必要になるぞ
- 💡 インターネットストレージへの格納時に検索性能の高い KVS にメタ情報を格納し、それをインデックスとして使うといいぞ
- 👍 堅牢で大きな read と早い search を両取りできるぞ
- 🤔 当たり前だけどメタ情報のミスマッチには注意な
Direct Object Upload パターン
アップロード手順の簡略化
- 💡 写真や動画の共有サイトでは大きなデータのアップロードが多く、サーバ側のネットワーク負荷が高くなりがちだぞ
- 💡 クライアントから仮想サーバを経由せず直接インターネットストレージにアクセスさせるといいぞ
- 👍 サーバ側は楽になるぞ
- 🤔 S3 と EC2 の連携は複雑になるぞ

リレーショナルデータベースのパターン
DB Replication パターン
オンライン DB の複製
- 💡 DB のレプリケーションはコストの関係で同じデータセンターで済ますことが多いが、データセンターごと損傷を受けるケースを想定しろよ
- 👍 AZ を考慮すれば異なるデータセンターに透過的に EC2 を配置できるぞ
- 🤔 フェイルオーバーのダウンタイムには注意な

Read Replica パターン
読込専用レプリカによる負荷分散
- 💡 DB は write より read の比率の方が一般には高いので、read 処理を分散してシステム全体のパフォーマンス向上を目指すといいぞ
- 💡 読み込みを read レプリカに分散させ、マスターの write に追従させるといいぞ
- 👍 大量データの参照や解析クエリなどが マスター ( write ) に負荷をかけないくなるぞ
- 🤔 冗長化が目的ではないので、耐久性を高める場合は read レプリカではなく DB レプリカを考えろよ
- 🤔 一般的には非同期レプリケーションなので、ラグがあることを意識しろよ

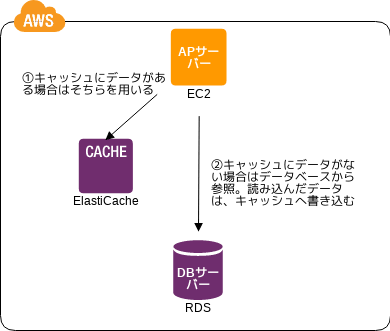
Inmemory DB Cache パターン
頻度の高いデータのキャッシュ化
- 💡 別の read 改善の方法として、頻繁に read されるデータをメモリーにキャッシュするというのもあるぞ
- 👍 raed 負荷を下げるとシステム全体のパフォーマンスが向上するぞ
- 🤔 read の頻度と write の頻度を考えてキャッシュする価値があるか判断しろよ
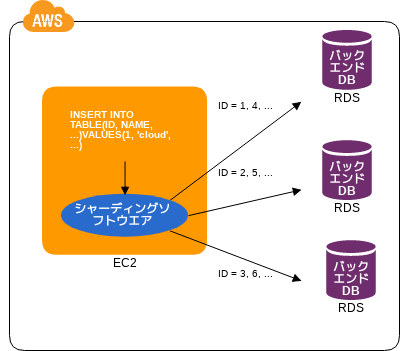
Sharding Write パターン
書き込みの効率化
- 💡 write の高速化をする方法に
シャーディングがあるぞ - 💡 基本的には同じ構造の DB を用意してテーブルのカラムをキーにして分割し write を分散することだぞ
- 👍 DB の地域を分散することでワールドワイドに展開できるぞ
- 🤔 シャーディングを実現するソフトウェアや通信の暗号化が必要だったりするぞ
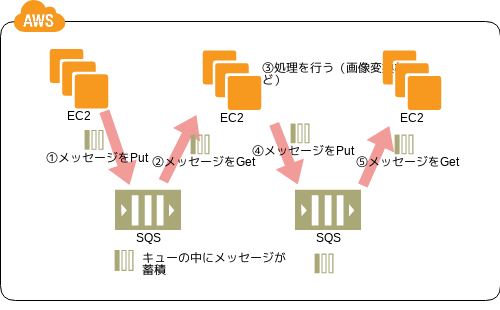
非同期処理/バッチ処理のパターン
Queuing Chain パターン
システムの疎結合化
- 💡 一連の逐次的な処理 ( ex: 画像 up, 保存, encoding, サムネ作成 ) を行うシステムが密結合だと問題になりやすいぞ
- 💡 主にパフォーマンスがボトルネックになるのと、障害時の復旧が煩雑になるので、疎結合にしておくといいぞ
- 💡 対処する方法の 1 つはシステムをキューでつなぎ連携をメッセージ送受信でやることだぞ
- 👍 メッセージを受信するサーバを並列化しやすいぞ
- 👍 メッセージを受信するサーバがダウンしても未処理のメッセージがキューに残るので復旧・再開が容易だぞ
- 🤔 SQS では dequeue の順番は完全には保障されないので注意な
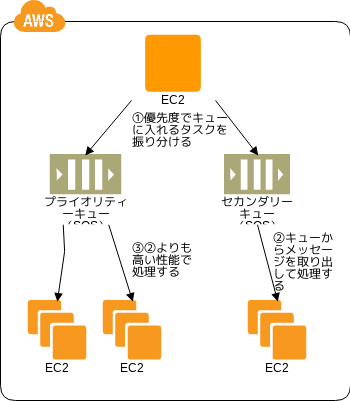
Priority Queue パターン
優先順位の変更
- 💡 例えばプランに応じてジョブの優先度を設定したいみたいなときは、キューを優先順位の数だけ作るといいぞ
- 👍 EC2 の増減でいろいろ対応できるぞ
- 👍 Queuing Chain のメリットも当然受けられるぞ
- 🤔 構成とリクエスト次第でキューの仕事量が期待と逆転することがあるので、監視とかをしっかりな
Job Observer パターン
ジョブの監視とサーバの追加・削除
- 💡 負荷分散のためにキューを用いて並列化する方法だと、ピーク時に合わせて調達するのでコスト効率が悪くなったり、想定を上回るリクエストを捌き切れなかったりするぞ
- 💡 SQS のキュー内のメッセージ数を監視してオートスケールさせるといいぞ
- 👍 コスト効率がいいぞ
- 👍 Queuing Chain のメリットも当然受けられるぞ
- 🤔 課金ルールをちゃんと把握しておけよ、例えば EC2 はすぐ破棄しても最低で 1h 単位の課金だぞ

Fanout パターン
複数種類の処理を非同期かつ並列に実行
- 💡 ある処理を元に複数の処理を実行する ( ex: 画像 up → サムネイル, 画像認識, メタデータスキャン ) 場合に問題が起きやすいぞ
- 💡 単純に直列だと長くなりがちなのと、処理 ( ex: モノクロ画像作成 ) が増えた時にプログラム改修が必要になるって問題だぞ
- 💡 処理から処理を呼ぶのではなく、通知コンポーネントとキューイングコンポーネントを入れてキューを監視するといいぞ
- 👍 非同期かつ疎結合にできるぞ
- 👍 キューを監視するシステムを増減すればいいだけなのでプログラム改修がいらないぞ
- 🤔 進行のトレースなどは管理 DB が必要だぞ

運用保守のパターン
Bootstrap パターン
起動設定の自動取得
- 💡 Stamp パターンの適用に際し、イメージに含める範囲はトレードオフの検討が大事だぞ
- 💡 ミドルからアプリ全てを設定済みにすれば立ち上げは早くなるが、どれか 1 つの変更でイメージの再生性が必要になるぞ
- 💡 サーバ起動時に GitHub や S3 などに配置したパラメータに応じてインストール・設定するイメージを作ることで解消できるぞ
- 👍 AMI の作り直しをある程度減らせるぞ
- 🤔 固定的なレイヤーと動的なレイヤーはトレードオフを考慮して決めろよ

Cloud DI パターン
変更が多い部分の外出し
- 💡 構築を自動化する時に外出ししたい情報 ( ex: DB 接続先, サーバ名, 各種 ID など ) をタグで設定する方法があるぞ
- 👍 マネジメントコンソールで容易に設定できるぞ
- 🤔 文字数制限があったりするので、その場合は値を記した S3 URL などのポインタ情報をタギングするといいぞ

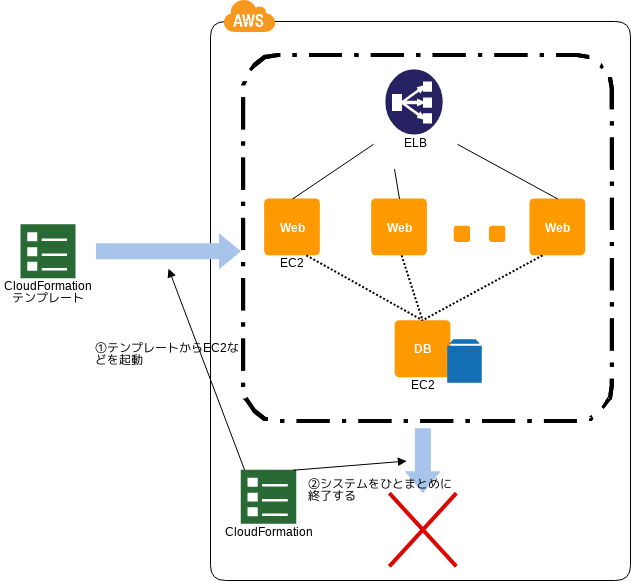
Stack Deployment パターン
サーバ群立ち上げのテンプレート化
- 💡 テスト環境はステージング環境を常に本番と同じスペックで保持するとコスト効率が悪すぎるので、テンプレートを作って一気に構築するといいぞ
- 👍 構築順なども制御できるし、破棄も容易だぞ
- 👍 テンプレートをバージョン管理することでシステム攻勢の履歴が容易に管理できるぞ
- 🤔 テンプレートを使わずにサーバ構成を変えると辛い目にあうぞ
Server Swapping パターン
サーバの移行
- 💡 サーバが故障してもディスクは問題ない場合も少なくないが、クラウドでは仮想ディスクを容易に別の仮想サーバに付け替えて復旧できるぞ
- 👍 障害直前までの早急なリカバリーができるぞ
- 🤔 EBS のスナップショットなどによる障害考慮は必要だぞ

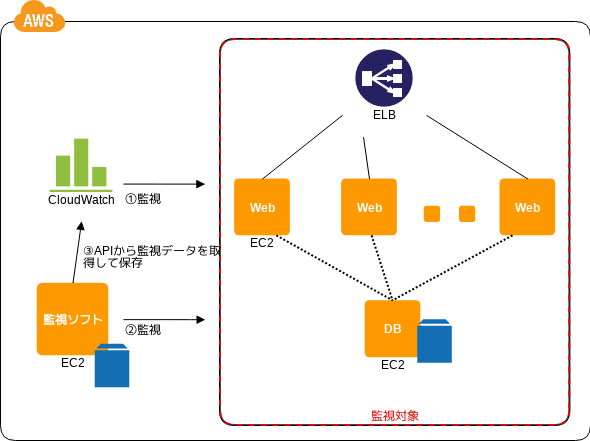
Monitoring Integration パターン
モニタリングツールの一元化
- 💡 クラウドのモニタリングサービスは仮想サーバ内 ( OS / ミドル / アプリ... ) の監視までできないので、用途ごとにモニタリングが増えて煩雑になるぞ
- 💡 仮想サーバは自前で監視し、クラウドモニタリングサービスでは大体提供される情報取得 API を使って情報を取り、自前側で一元管理するといいぞ
- 👍 CloudWatch のデータを自前で取り込むことで、長期保存や加工や整理が行いやすくなるぞ
- 🤔 CloudWatch の API 利用料はかかるぞ
Weighted Transition パターン
重み付けラウンドロビン DNS を使った移行
- 💡 システムをある地域からある地域へ移行する時に、ドメインを変えずにかつシステム求めたくないというのはよくある要望だ
- 💡
重み付けラウンドロビンという機能を使い、最初は少しだけ新システムに振り分け問題がなければ新システムへの配分を増やすという方法があるぞ - 👍 システムに手を入れず、かつトラフィックをコントロールしながら移行できるぞ
- 🤔 DB 動機が必要な場合は、それは別途考慮しろよ

Log Aggregation パターン
ログの集約
- 💡 大規模システムだとログが各所に分散しがちだし、オートスケールインするとログが紛失するぞ
- 💡 AP サーバなどにログ収集エージェントなどを常駐させ、ログをインターネットストレージに集約させるといいぞ
- 👍 特別なログ収集サーバが必要ないし、S3 ならそれと親和性の高い EMR や Redshift でログが解析できるぞ
- 🤔 オートスケールインによるログロストを防ぐ場合は Auto Scaling の Lifecycle Hook を使いな

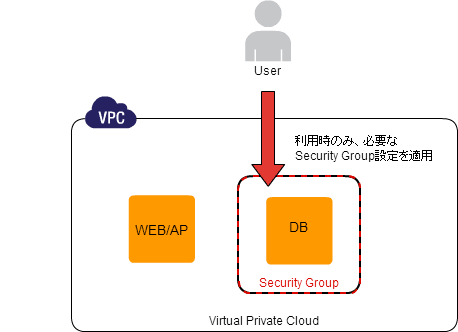
Ondemand Activation パターン
メンテナンス時の一時的な設定変更
- 💡 セキュアにするために通常は inbound / outbound は最低限に制限されているが、os アップデートまでできなくなったりとメンテナンス容易性とはトレードオフだぞ
- 💡 踏み台を必要な時だけ API で立てたりファイアウォールを任意のタイミングで設定を API で変えたりすると柔軟性が増すぞ
- 👍 コスト効率とセキュアの両取りができるぞ
- 🤔 オペミス防止のために操作の自動化をしたり操作のテンプレート化をするといいぞ
- 🤔 事故防止のために後片付け作業の自動化をしたりするといいぞ
① 踏み台サーバの一時的な起動

② NATサーバの一時的な起動

③ セキュリティグループの一時的な設定変更
ネットワークのパターン
Backnet パターン
管理用ネットワークの設置
- 💡 不特定多数のユーザからアクセスされるサーバの管理目的でのアクセスを、高セキュリティにするためには分離したくなるよな
- 💡 複数ネットワークインターフェースを作り管理用を設けることを
バックネットと呼ぶぞ - 👍 ネットワークリスクの低減ができるぞ
- 👍 明確にネットワークインターフェースが違うのでオペミスが減るぞ
- 🤔 物理線が別れるわけではないので、ENI を追加しても帯域は増えないぞ

Functional Firewall パターン
階層的アクセス制限
- 💡 ファイアウォールのルールが多くなると煩雑で運用コストも高くなるし、ルールをサーバへ適用する際のつけ間違えも増えるよな
- 💡 ファイアウォールをグループ化し、グループ単位で適用するといろいろ改善するぞ
- 👍 Scale Out パターンとかでもそのままいけるぞ
- 🤔 上限はないが適度に扱わないと全体像把握がしづらくなるから気をつけろよ

Operational Firewall パターン
機能別アクセス制限
- 💡 大規模システムで組織 ( 会社 ) が複数になる場合 ( ex: 開発会社, 監視会社, 保守会社 ) に、ファイアウォールの変更や破棄が大変だ
- 💡 Functional Firewall パターンと同じくグループで管理するといいぞ
- 👍 Functional Firewall と同じだし、併用もできるぞ
- 🤔 接続元による制限がメインなので、ユーザごとの制御をしたい場合は OS やアプリでの制御が必要だぞ

Multi Load Balancer パターン
複数ロードバランサの設置
- 💡 PC / SP など複数のデバイスからアクセスされる場合にデバイスごとの振り分け設定を EC2 自体で行ってしまうと、スケーリングしづらくなるぞ
- 💡 複数の ELB に EC2 をぶら下げる構成が考えられるぞ
- 👍 今は 1 EC2 n ENI, 1 ENI n IP が設定できるので、本パターンを用いなくても 1 EC2 n SSL が実現できるぞ
- 🤔 メンテ時などに EC2 を ELB から切り離す場合は、全ての ELB から切り離さないとだめだからな

WAF Proxy パターン
高価な Web Application Firewall の効率的な活用
- 💡 重要個人情報を扱うサイトはセキュリティを高めるために
Web Application Firewallを導入することが多いが、後から入れることを考慮されてるシステムは少ないよな - 💡 スケールアウト / インとかが前提だと必要ライセンス数も読めなくて大変だしな
- 💡 サーバごとに WAF を導入するのは非現実的なので、上流にプロキシを置いてそこに WAF を入れる方が効果的だぞ
- 👍 Web / AP サーバに手を入れなくても WAF を導入できるぞ
- 🤔 プロキシサーバを冗長化しないと、それが単一障害点になるぞ

CloudHub パターン
VPN 拠点の設置
- 💡 拠点間連携での VPN 接続をフルメッシュ型で構成すると増加に伴いメンテナンスコストが跳ね上がるぞ
- 💡 スター型で構成するとハブ接続なので設定は楽だが単一障害点になりやすいので可用性が大事だぞ
- 👍 同一リージョンの VPC 間通信は VPC Peering で低レイテンシ・低コストで実現できるぞ
- 🤔 通信が必ず VPC を通るので課金が発生するぞ
- 🤔 VPN GW に接続しているネットワークは互いに通信できてしまうので、必要に応じて VPN ルーターでアクセス制限をしろよ

Sorry Page パターン
バックアップサイトへの自動切り替え
- 💡 不具合や大規模メンテ時に一時的に Web サイトを封鎖したいことがあるが、アクセス自体ができなくなると UX が悪化するよな
- 💡 インターネットストレージは静的サイトをホストできるので、Sorry Page や静的ページを代替配信するといいぞ
- 👍 ヘルスチェック機能と連携して自動的にバックアップサイトに切り替えたりもできるぞ
- 👍 重み付きラウンドロビンや一部地域でのみ配信するといったことも可能だぞ

Self Registration パターン
自分の情報をデータベースに自動登録
- 💡 サーバの起動 / 停止時にサーバ自体の設定を永続化する必要があるよな
- 💡 EC2 は容易にメタデータを取れるし、SimpleDB や DynamoDB といった KVS もあるので、起動時に登録して停止時に削除するってことができるぞ
- 👍 簡単な検索をするなら KVS なら容易に実現できるぞ
- 🤔 仮想サーバの停止が異常終了した場合は KVS とのずれが発生するので、定期的に整合性チェックとかしろよ

RDP Proxy パターン
Windows インスタンスへのセキュアなアクセス
- 💡 EC2 Windows インスタンスに RDP で接続したいが、社内都合で RDP が許可されてなかったりして使えないことがあるよな
- 💡 Windows 標準の RD ゲートウェイを使うと SSL で接続できるぞ
- 👍 RDP ( TCP:3389 ) が使えない環境でも EIP 付与してないインスタンスにセキュアに接続できるぞ
- 🤔 RD ゲートウェイをサポートした RDP クライアントを使えよ
- 🤔 ルート証明書とパスワードの管理は厳密にな

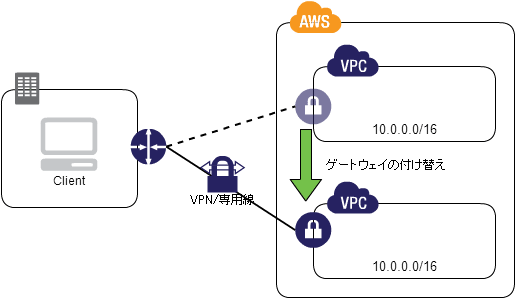
Floating Gateway パターン(存在しないページ)
クラウド上のネットワーク環境の切り替え
- 💡 開発環境やテスト環境の差異はなくしたいし、アップグレードをするときは改修じゃあなくてまるっと立て直した方がいいよな
- 💡 けど新たな環境の IP アドレスレンジが変わっちゃうと、設定やプログラムを変えなきゃいけなくなるよな
- 💡 同一の設定を持った仮想ネットワークを複数作成でき、同一設定の仮想ネットワークは IP やルーティングを同じにできるので、差異を少なくできるぞ
- 👍 オンプレのルータ設定とかが不要
Shared Service パターン
システム共通サービスの共有化
- 💡 共通サービス ( ex: ログ収集, 監視, WAF, ウイルス定義配布 ) をサービスごとに作り込むとコストがかさむよな
- 💡 個別のシステムは独立したネットワーク内に構築し、共通サービスは共通サービス用の独立ネットワーク内に構築し、論理接続するといいぞ
- 👍 VPC Peering は AWS アカウントが違っていてもできるので、コストは責任範囲を明確に分けられるぞ
- 🤔 VPC Peering で接続した VPC 間はセキュリティグループで設定できないので IP ベースでの設定になるからな

High Availability NAT パターン
冗長化された NAT インスタンス
- 💡 インターネットに公開しないサーバはプライベートサブネットに置くことが多いが、外に出るための NAT やプロキシがダウンすると全体障害に直結するよな
- 💡 単一障害点にならないように冗長化しろよ
- 🤔 NAT はスケールアウトできないので、性能限界の考慮はしておけよ
①NAT切り替え

②ELBを使った冗長化
