🐕
NVlabs: FoundationPose at CVPR2024


Overview
- model-base, model-freeの両方の使い方ができる手法を提案
- CADモデル or 少ない枚数のRGB画像があれば、fine-tuning無しで実行することができる
- ADDやADD-Sのメトリクスにおいて、既存手法の評価値より、高い評価値を達成
Introduction・Related work
- カメラに対する物体の位置姿勢を求めるタスク(6D object pose estimation)には様々な手法が存在する
- 古典的な方法は、Instance levelの手法で、この方法では学習したモデルのみ認識することができる
- この手法では、テクスチャ付きのCADモデルが学習データとして必要になる
- よく知られている手法は、Direct reggressionや2D画像と3Dの対応点をPnP問題として解く方法、3Dと3Dの対応点を最小2乗数方で解く方法である
- category-levelの手法では、Instance-levelにおける条件(未学習物体は認識できない、CADモデルが必要)を除くことができるが、事前設定したカテゴリー内でのみでしか学習できない
- また、この手法における学習データは、学習データにおける姿勢を正規化等の処理にかける必要があり、このようなデータ生成における課題があることで有名である
- 上記のような古典的な手法における制限があるため、現在は任意の新規オブジェクトのFinetuning無しの認識手法に焦点が当てられている
- この手法では、テスト時に入手可能なデータに応じて、model-baseとmodel-freeの手法に分けられる
- model-based: 対象物体のテクスチャ付きの3Dモデルがある場合
- model-free: 対象物体の2D画像がある場合
- 代表的な手法
-
NeRF-Pose, ICCV2023 workshop
- 対象物体の複数の画像からNeRFを構築し、物体の座標とマスク画像の半教師データを作成し学習する
- 未学習物体は対応できない
-
Gen6D, ECCV2023
- Finetuningすれば未学習物体も対応可能
-
OnePose++, NeurIPS 2022
- SfMで物体をモデリングし、Pretrainされた2D-3D間のマッチングをするモデルで姿勢を推定する
-
FS6D, CVPR2022
- 提案手法と似た仮定を置いて手法を提案しているが、テクスチャレスな物体やオクルージョンに弱い
-
NeRF-Pose, ICCV2023 workshop
- 代表的な手法
- 2つの手法はそれぞれ多くの進展があるが、様々なアプリでは様々な情報が得られるため、2つの手法のどちらにも適用可能な1つの手法が必要である
- 提案する手法は、model-basedでもmodel-freeでも適用可能な手法であり、2つの手法間のギャップをニューラルネットワークの中間表現を学習する方法によって、16枚以下の画像から新規視点からの画像を合成することによって、以前の手法より高速なレンダリングを実現している
Approach
Language-aided Data Generation at Scale

- 高い汎化性能を出すためには、多様性に富んだ大規模なオブジェクトやシーンが必要である
- 現実世界では、大規模なデータセットのための、正確な6D Poseのアノテーションには法外なコスト(時間、費用)がかかる
- シミュレータにおける合成データは、3Dアセットの数が少なく、多様性も小さい
- 上記の問題を解決するために、大規模な3DモデルのデータセットやLLM、Deffusion Modelを用いた合成データ生成パイプラインを作った
- 大規模な3Dデータモデルのデータセット
-
LLMを活用したテクスチャ拡張
- Objaverseのモデルの形状は本物に対して正確に表現されているが、テクスチャの表現については忠実さが不足している
- FS6DではImageNetもしくはMS-COCOからランダムにテクスチャを引用し貼り付けて、使用していた
- この方法の場合には、本物のテクスチャには存在しないテクスチャ間のつなぎ目が生じてしまう問題があった
- また、全体的なシーン画像をテクスチャとして貼り付けてしまう場合もあり、そのようなテクスチャには現実未がないことも問題であった
- 提案する拡張方法では、TexFusionにテキストと、オブジェクトの形状、ランダムなノイズを加えたテクスチャ入力し、テクスチャを拡張した
- TexFusion
- 上記のTexFusion(ICCV2023,Oral)でテキストを手動で入力する点は、スケーラブルな拡張性とは相容れないため、2段階の階層型のプロンプト入力を構成した
- まず、ChatGPTにプロンプトとして、対象オブジェクトの取りうる外観について説明してほしいというプロンプトを入力し、出力を得る
- プロンプトはテンプレート化されており、データセットから取得できるTagの部分だけ置き換えれば使用できる
- 次にChatGPTからの出力をDiffusionモデルに入力する
- この方法により、テクスチャ拡張を自動化することができ、データセットをスケール化することができる
-
データ生成
- 忠実度が高いフォトリアリスティックなレンダリングによるパストレーシングをするために、データ生成ではIsaac Simを使用した
- シミュレート時には、重力等の物理パラメータをONに設定した状態で実施し、現実世界のようなシーンになるようにした
- オブジェクト側の設定では、ランダムにデータセット(オリジナル + テクスチャ拡張したもの)内のオブジェクトを選定し、シーンに配置していた
Neural Object Modeling
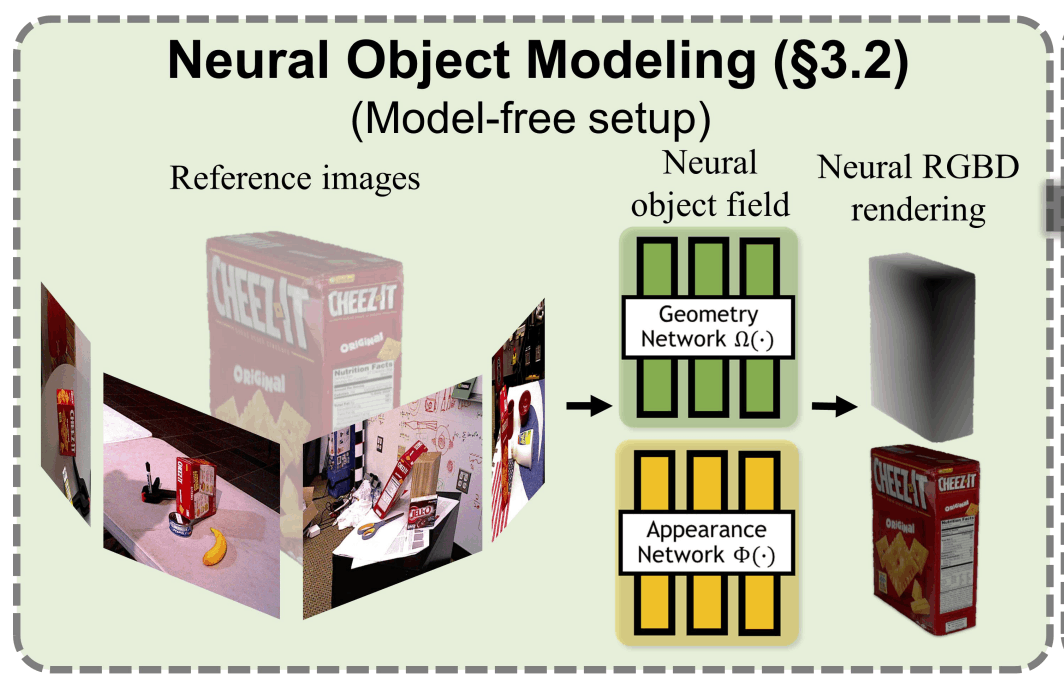
-
model-freeの場合、推論時に3Dモデルを使用することができないため、画像からオブジェクトを後段のモジュールで使用できる程度の質でレンダリングできることが重要である
-
ニューラル場によるレンダリングは、新規視点からの画像を生成できることや、GPUを用いた並列化により、複数の姿勢候補を効率よくレンダリングすることができる
-
ニューラル場の表現方法
- オブジェクトを2つのネットワークで表現する
- 1つ目のネットワークでは、入力を3次元上の位置X(x,y,z)とし、出力を1次元の符号付き距離とした式とする
- 2つ目のネットワークでは、入力をジオメトリ側のネットワークから得られる中間表現のベクトルと正規化された3次元位置、3次元の視点方向とし、出力をRGBとする
- ベクトルと方向は、2次の球面調和関数の係数として使用される
- NeRFと比較して符号付き距離による表現方法(SDF)は、Densityのしきい値設定を自動化し、質の高いDepthレンダリングを実現することができる
-
ニューラル場の学習方法
- テクスチャ学習では、切り取られた表面近くの領域に対するボリューメトリックレンダリングを実施している
- w(x)は、bell-shapedな確率密度関数であり、暗黙的なオブジェクト表面の点からの符号付き距離から得られる
- αはネットワークの出力を反映具合を調整するパラメータである
- z(r)はデプス画像の輝度値であり、λは切り捨てるデプス値を決定するパラメータである
- 効率的に学習するために、表面からλ以上離れている空の空間については学習に寄与しないようにしている
- また、自己オクルージョンをモデル化するために0.5λ以上の距離のみ使用している
- 学習中はカラーの目標値として参照RGB画像とλの大きさを比較している(損失関数)
- C(r)は光線rが通過するピクセルのカラーのGT
- Geometry Learningでは、ハイブリッドSDFを適用している
- ハイブリッドSDFでは、SDFを学習するために2つの損失(空領域の損失と表面近辺の損失)を使用している
- また表面近辺のSDFに対して、アイコナール正則化を適用している
- アイコナール方程式
- 光の伝搬を表す基礎方程式
- アイコナール方程式
- 損失関数は合計で3つ存在する(4,5,6)
- xは分割された空間内の光線にそったサンプリングされた3次元点を表す
- dxとdDはそれぞれ、サンプルされた点の光線の原点からの距離と観測されたデプスの値を表す
- テンプレート画像はmodel-freeのオフラインのセットアップで事前に用意できるため、不確かなfree-spaceの損失関数は使用していない
- これらの損失関数により、学習では事前準備無しでオブジェクトごとに最適化され、またそれらは数秒以内に実行することができる
- 上記により、1度の学習で新規オブジェクトをニューラル場に適用することができる
-
レンダリング
- 一度学習できると、ニューラルフィールドは従来グラフィックパイプラインに代わって使用することができ、後続のレンダリングと比較のイテレーションのためにオブジェクトの効率なレンダリングを実現することができる
- 提案手法では、オリジナルのNeRFのカラーレンダリングに加えて、ポーズ推定とトラッキングに基づいたRGBD画像のためのデプスレンダリングも必要である
- 上記を実現するために、matching cubeを利用して、カラープロジェクションと組み合わせて、SDFのゼロレベルからテクスチャ付きのメッシュを抽出する
- 推論時には、オブジェクトの姿勢からラスター化に沿ってRGBDイメージをレンダリングする
- sphere tracingに沿ってオンラインでΩより直接デプス画像をレンダリングすると、効率が下がることが分かった
- 特に平行でレンダリングする姿勢の候補が多く存在する場合には顕著である
Pose Hypothesis Generation
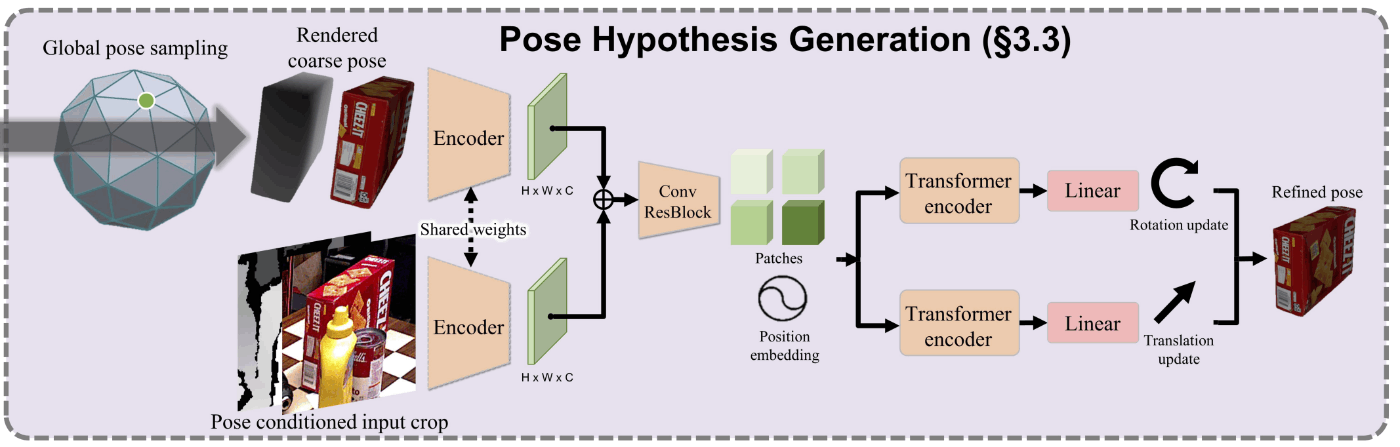
-
Poseの初期化
- RGBDイメージ中の対象オブジェクトは、従来のMask R-CNNやCNOSのような手法で認識される
- オブジェクトの初期位置は、セグメンテーションモデルの出力から得られる2Dのバウンディングボックス内のデプスの平均値である3次元点の位置によって初期化される
- オブジェクトの初期姿勢は、まずオブジェクトを中心においた20面球体の面上にオブジェクトの方向を向いたNs個の視点を均一にサンプルリングする
- 面内を離散化したNsでサンプリングされた姿勢を拡張し、Ns・Niをネットワークに入力する姿勢の初期値とする
-
PoseのRefinement
- 初期化の際の精度が粗いPoseにはかなりノイズが乗ってしまっているため、姿勢の精度を上げるためにはrefinementする必要がある
- refinementネットワークの入力は、粗いPoseのオブジェクトのレンダリングとサンプリングされた視点で取得された画像をクロップしたものとする
- ネットワークの出力は、質を向上させたPoseとする
- アンカー点を特定するために粗いPoseの周りの複数視点をレンダリングするMegaPose(CoRL 2022)とは異なり、粗いPoseに対応する1つの視点をレンダリングすることだけで十分であることが分かった
- 入力観測は、2Dの認識を元にした一定のクロッピングの代わりに、位置を更新するためのフィードバックを与えるPoseに対応したクロッピング手法を適用した
- 具体的には、まずクロッピング中心をオブジェクトの中心を画像空間に投影することで決定する
- 次に、Pose候補の周囲のコンテキストとオブジェクトに近いクロッピングのサイズを決定するためにわずかに拡大させたオブジェクトの直径を投影する
- このクロッピングは粗いPoseに対応しており、オブジェクトの位置を更新するためにネットワークがより良いクロッピングをするように更新するように影響する
- refinementプロセスは、複数回繰り返され、ネットワークの出力したPoseを次の入力とし、Poseの質を向上させる
- refinementネットワークの構造
- まず重みを共有するCNNのEncoederに2つのRGBDイメージを入力し、特徴量マップを抽出する
- 次に特徴量マップを連結し、連結したものを残渣接続を持ったCNNに入力する
- CNNからの出力をposition embeding(参考)によっていくつかのパッチに分けることによって、トークン化する
- 最後にtransformer encoder(参考1, 参考2)によって3次元の位置tと三次元の回転Rが推定され、それらは出力の次元に線形投影される
- 具体的には⊿tはサンプルされたフレームごとの位置の変化量であり、同様に⊿Rは回転の変化量である
- 実験では回転は、各軸の回転量として扱う
- 同様の結果を出す、6D representation(CVPR2019)も実験した
- 入力の粗いPoseは現在のPoseに追加するように更新する
- 単一の均一されたPoseを更新する方法ではなく、位置と姿勢を別々で更新することによって、位置を更新する際の姿勢への依存を除去することができる
- 上記により、更新と入力の観測が統合され、学習プロセスが簡略される
- ネットワークの損失関数は、GTの位置と姿勢それぞれに対する推定した位置と姿勢の差とし、各項をスケーリングするwは1に設定した
Pose Selection

- 前記ネットワークから得られたいくつかのPose候補を、階層的にPoseを優先順位付けするネットワークに入力し、それぞれのスコアを比較する
- 最もスコアが高いPoseを最終的に推定したPoseとする
-
Hierarchical Comparison
- ネットワークでは2段階の比較を行う構造にしている
- まず、それぞれのPose候補に対して、レンダリングした画像をPose条件付きのクロッピングによる入力の観測値と比較する
- この比較処理は、バックボーンがPoseをRefinementするネットワークの特徴量抽出部と同様であり、Poseを順位付けするEncoderとして機能する
- 得られた特徴量は、連結された後にトークン化され、比較においてグローバルなイメージとコンテキストをより良くするためにmulti-head self attention(参考1、参考2、参考3)部に入力される
- Poseを順位付けするEncoderでは、平均プーリングにより512元のfeature embedingを出力する
- このFeature Embedingはレンダリングと観察の間のアライメントの品質を意味する
- この時点で、従来の手法と同様にFeature Embedingを類似度を示すスカラーに投影することもできる
- ただし、この場合には、他のPose候補が無視されてしまうため、ネットワークを絶対的なスコアを学習するようにする必要があるが、そのような学習は困難である
- より情報に基づいた結果にするために、全てのPose候補のグローバルなコンテキストを活用するために、2段階目のK個のPose候補間の比較をしている
- Multi-head seld-attentionは、連結されたfeatured embedingを使用し、全てのPoseからのPoseのアライメントをエンコードする
- シーケンスととしてFeature embedingを扱うことによって、このアプローチは自然にKの長さの変化として一般化される
- Feature EmbedingにPosition Encodingを適用しないことによって、順列に影響されないようにしている
- 適用された特徴量は線形的に、Pose候補に割り当てられるK次元のスコアに投影される
-
Contrast Validation
- Poseを順位付けするネットワークを学習させるために、Pose条件付きTriplet損失を使用した
- αは対象的なマージンであり、i-とi+は、それぞれ正負のPoseを示し、それぞれGTを用いたADDを算出することによって決定される
- 標準化された上記の損失の差は、入力が位置を考慮してPose候補に依存するため、アンカーサンプルが正負のPoseにおいて共有されない
- この損失はそれぞれのペアについて計算できるが、GTからそれぞれのPoseが離れている場合、比較は曖昧になりやすくなる
- よって、比較を有効化するためにGTに対して十分に近い視点からの正のPoseを持つペアを使用した
- Dは回転の候補とGTの間のgeodesic distance(直線距離?)を示す
- dは事前に設定するしきい値である(どうやって決定している?)
- InfoNCE(元論文、ttps://blog.recruit.co.jp/data/articles/ssl_vision_01/)の損失関数も試したが、パフォーマンスは悪かった
- 上記の損失関数で上手くいかなかった原因としては、上記の手法と今回提案する手法にpける仮定が異なるためであると考えている
- Poseを順位付けするネットワークを学習させるために、Pose条件付きTriplet損失を使用した
Experiments
Dataset and Setup
- データセットには次の5つのものを使用した
-
LINEMOD
- 15個のテクスチャレスのhousehold系のオブジェクトで構成されている
- それぞれのオブジェクトには、1つのクラスがアノテーションされており、1つのデータでは、1つのオブジェクトがアノテーションされている
- 複数物体が置かれている中においているため、軽度のオクルージョンが存在する
- ライセンスはCC BY 4.0
-
Occuluded LINEMOD
- LINEMODの1つのデータ内に存在する全てのオブジェクトにアノテーションしたデータセット
- ライセンスはCC BY-SA 4.0
-
YCB-Video
- 21個のYCB objectを使用し、92個のシーンで構成されている
- ライセンスはMIT
-
T-LESS
- 工業製品に使用される30個の部品使用し、20個のシーンで構成されている
- ライセンスはCC BY 4.0
-
YCBinEOAT
- 既存のデータセットだと、テーブルの上にオブジェクトが配置されている例が多く、また、動画撮影は人間の手によって実施されていたことが多かった
- そこで、3つの異なるエンドエフェクタと5個のYCB Objectで9個のシーンで構成するデータセットを作成した
- ライセンスは独自ライセンス
-
LINEMOD
- 上記のデータセットを用いて、model-based, model-freeの2つのセットアップと、pose estimationとpose trackingの2つのタスクの合計4通りで評価した
- 1つの学習済みモデルを使用し、そのモデルを使用したFine-tuningは実施せずに全ての評価を行った
Metric
- ADDとADD-SのAUC(Area under the curve)
-
ADD(average distance)
- GTの回転Rと並進Tと、推定された回転Rと並進Tの平均距離

-
ADD-S
- 形状が対象なオブジェクトの場合、異なる姿勢だったとしても、ADDが小さくなってしまう場合がある
- そこで、ADDを計算する際に最も近い点のペアを用いて計算する

-
ADD(average distance)
-
ADD-0.1d
- ADDのしきい値を0.1に設定した指標
-
BOPのVSD, MSSD, MSPD
- VSD(Visible Surface Discrepancy)
- 見えている部分において、GTの姿勢と推定した姿勢でオブジェクトをそれぞれレンダリングした際の距離が事前に決めたしきい値より小さい場合には0、それ以外は1になる

- MSSD(Maximum Symmetry-Aware Surface Distance)
- GTの姿勢と推定した姿勢におけるモデルの頂点間の最大距離

- MSPD((Maximum Symmetry-Aware Projection Distance)
- GTの姿勢と推定した姿勢でモデルを2次元画像に投影した際の最大Pixel間距離
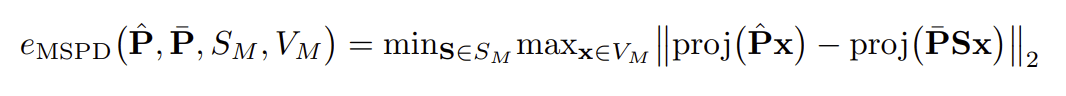
- VSD(Visible Surface Discrepancy)
Pose Estimation Comparison
-
Model-free
- YCB-Video
- PREDATOR, LoFTR, FS6D-DPMと比較した
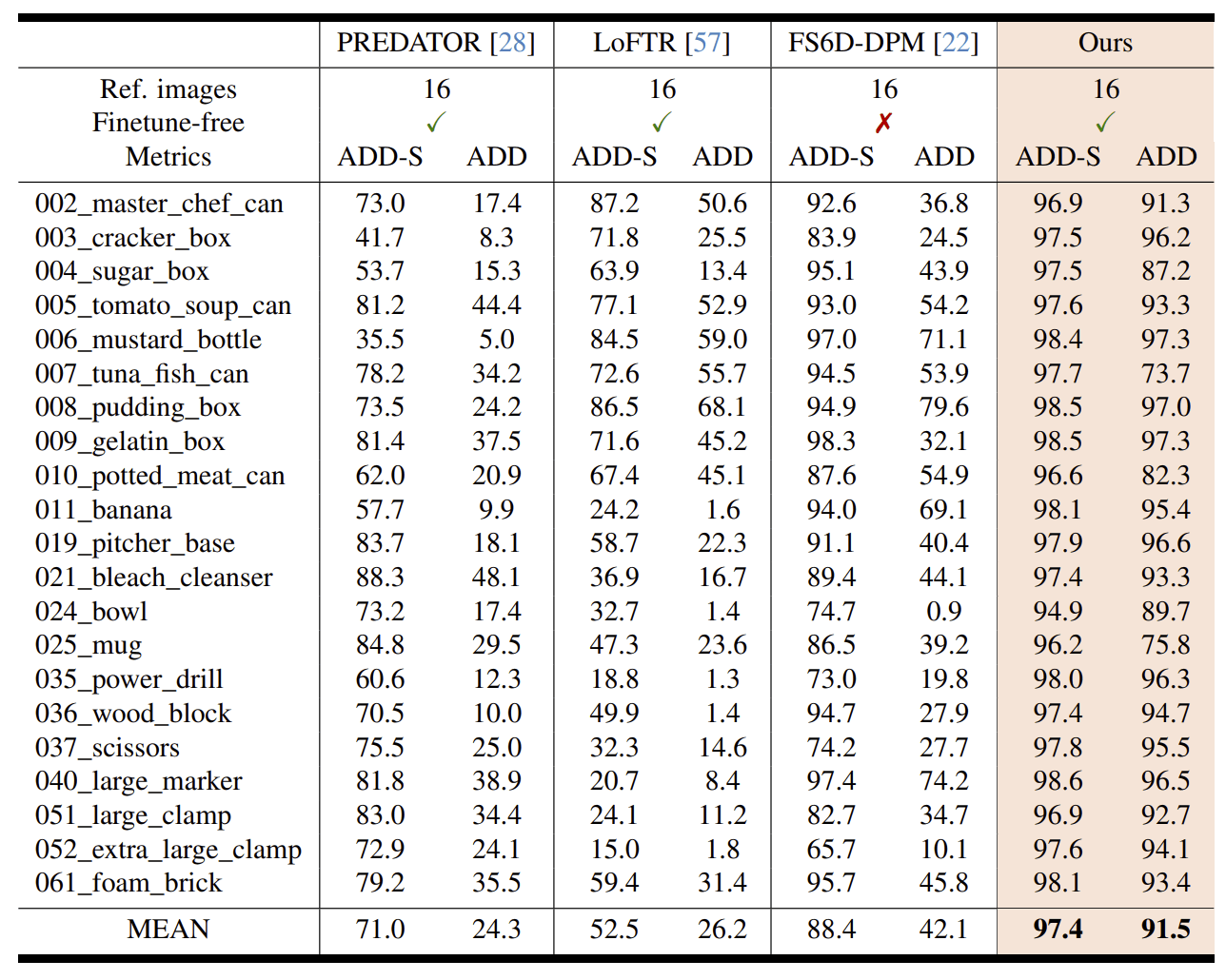
- ADD-0.1d on LINEMOD
- YCB-Video
-
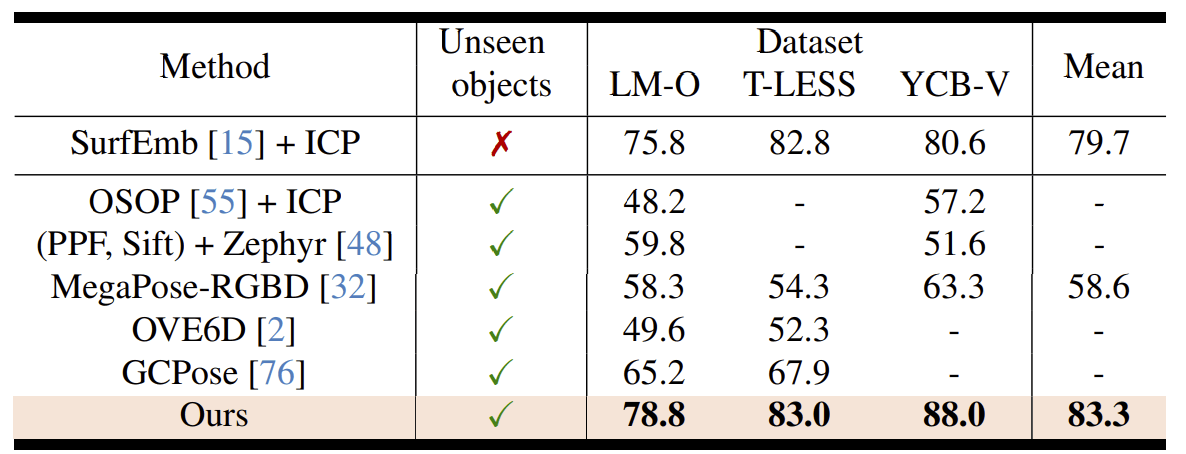
Model-based
- 物体検出はMask R-CNNの結果を使用している
- Occluded-LINMOD, YCB-Video, T-LESS

Pose Tracking Comparison
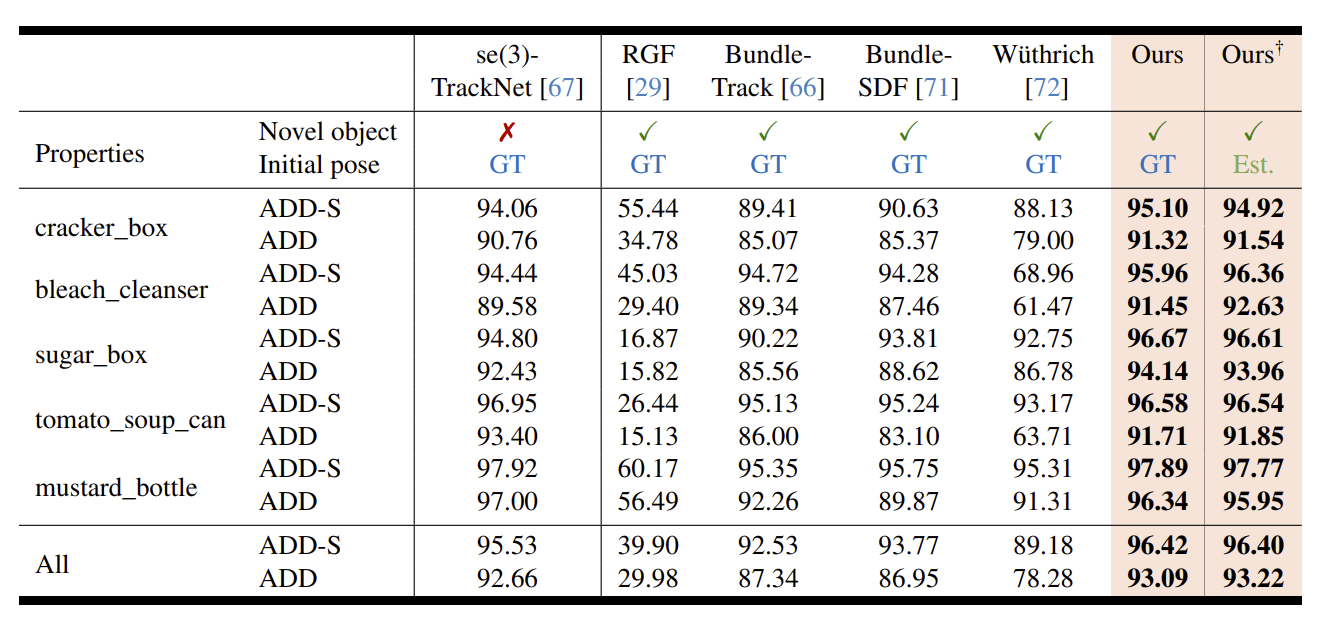
-
AUC of ADD and ADD-S on YCBInEOAT dataset
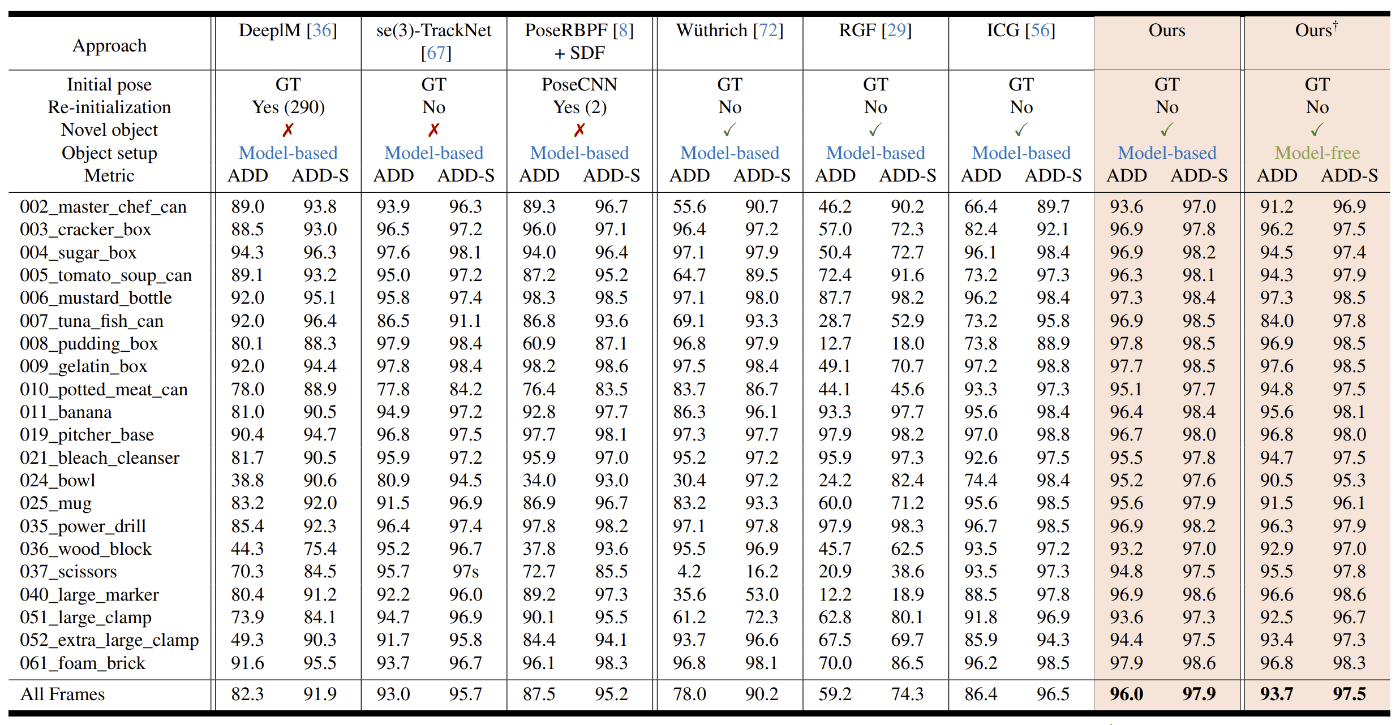
-
AUC of ADD and ADD-S on YCB-Video dataset
Analysis
-
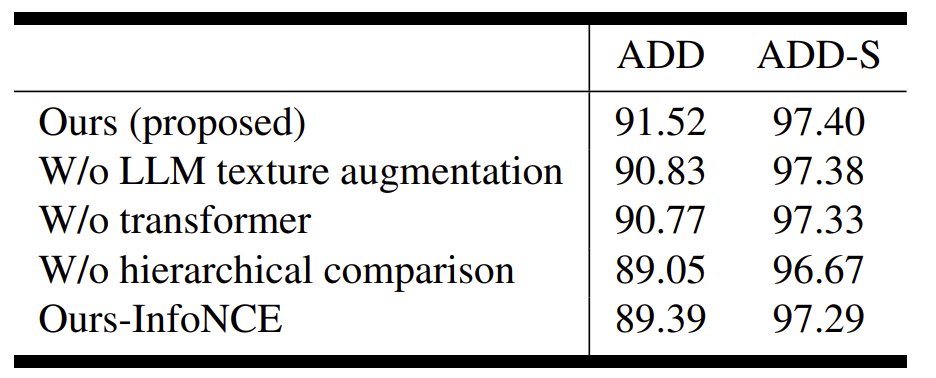
Ablation study
- AUC of ADD and ADD-S metrics on the YCB-Videoで比較した
- 提案する手法において、LLMを用いたテクスチャ拡張、transformer部分、Pose推定時の2段階評価、InfoNCEの損失関数をそれぞれ、既存手法に置き換えた際のADDとADD-Sを比較している
- LLMやTransformer部分より、2段階評価部分の寄与が高い
-
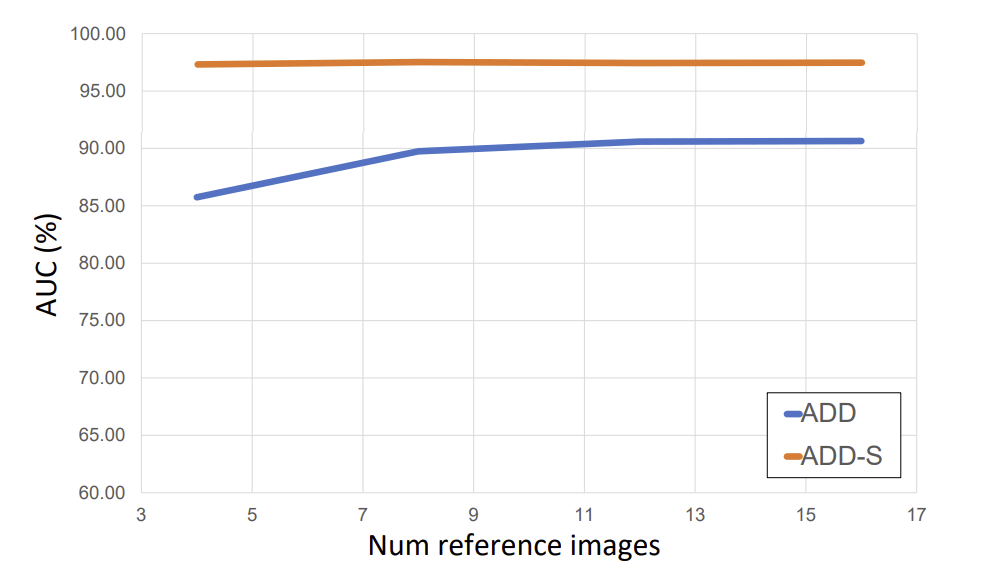
Effects of number of reference images
- 参照する画像の枚数による、AUC of ADD and ADD-S on YCB-Video datasetへの影響
- ADDは9枚程度で頭打ちになり、ADD-Sは枚数による影響を受けていない
-
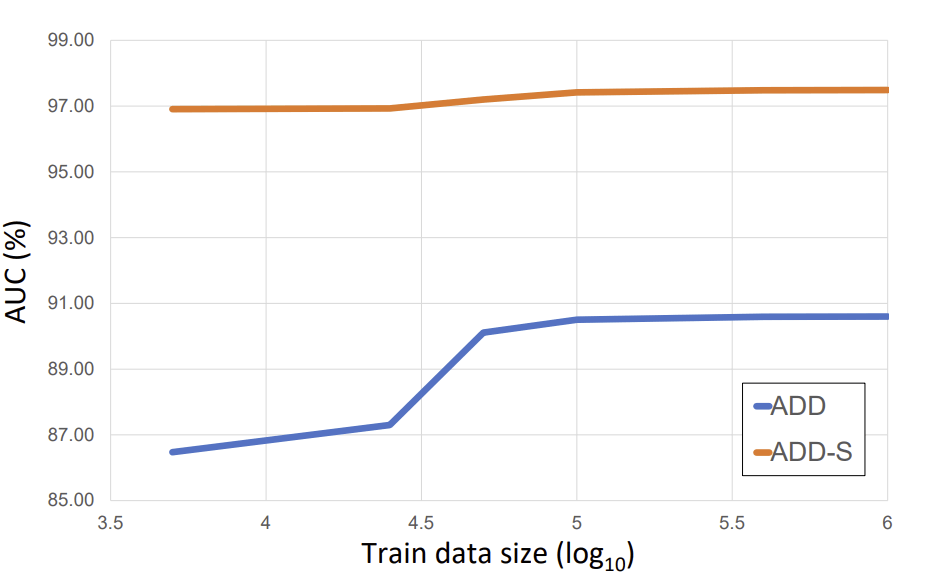
Training data scaling law
- 学習用データのサイズによる、AUC of ADD and ADD-S on YCB-Video datasetへの影響
- ADDは1M程度で頭打ちになり、ADD-Sは5Kくらいから頭打ちになっている
- 1Mくらいはデータ量が必要
-
Running time
- Intel i9-10980XE、NVIDIA RTX 3090で検証
- 1つのオブジェクトの推論時間は1.3sec
- 姿勢の初期化に0.004sec, refinementに0.88sec, Poseの選定に0.42sec掛かっている
- Trackingは最大で32KHzで動作する
Test code
- REAMDEの記載通りに、実行することができます
Env
- コードを実行したPCのスペックは次の通りです
| unit | specification |
|---|---|
| CPU | i9-11900H |
| GPU | GeForce RTX 3080 Laptop |
| RAM | 32GB |
| OS | Ubuntu 20.04.3 LTS |
- Nvidia Driverバージョン
- 535.171.04
Setup
- Docker imageをPullします
cd docker/
docker pull wenbowen123/foundationpose && docker tag wenbowen123/foundationpose foundationpose
bash docker/run_container.sh
- 次にビルドするために、にbuild_all.shを実行します
bash build_all.sh
- readmeのdata prepareの1,2に学習済みの重みファイルとサンプルデータがあるのでダウンロードします
Run demo
- build後、run_demo.pyを実行すると、YCB datasetの黄色の洗剤をトラッキングするデモが実行さます
- 異なるオブジェクトの画像から推論させる際には、Pythonから実行する時の引数のオブジェクトのPathを指定します
mustard bottle
python run_demo.py

- 実行時のパフォーマンスに関する結果は次の通り
| metrics | result |
|---|---|
| GPU memory | 822MB |
| input image size | 640x480 |
| avg inference time per 1 image | 200msec |
drill
python run_demo.py --mesh_file ./demo_data/kinect_driller_seq/mesh/textured_mesh.obj --test_scene_dir ./demo_data/kinect_driller_seq/

- 実行時のパフォーマンスに関する結果は次の通り
| metrics | result |
|---|---|
| GPU memory | 750MB |
| input image size | 1280x720 |
| avg inference time per 1 image | 200msec |
LINEMOD
- LINEMODのデータセットで推論する場合には、まずデータセットをBOPのページからダウンロードします
- 次のスクリプトを実行すると、データセットをダウンロードすることができます
- ZIP形式で30GBあるデータであり、解凍すると1TB以上になるので、ダウンロード先PCに十分な空き容量があることを確認してダウンロードして下さい
mkdir -p FoundationPose/datasets
cd FoundationPose/datasets
export SRC=https://huggingface.co/datasets/bop-benchmark/datasets/resolve/main
wget $SRC/lm/lm_base.zip # Base archive with dataset info, camera parameters, etc.
wget $SRC/lm/lm_models.zip # 3D object models.
wget $SRC/lm/lm_test_all.zip # All test images ("_bop19" for a subset used in the BOP Challenge 2019/2020).
wget $SRC/lm/lm_train_pbr.zip # PBR training images (rendered with BlenderProc4BOP).
unzip lm_base.zip # Contains folder "lm".
unzip lm_models.zip -d lm # Unpacks to "lm".
unzip lm_test_all.zip -d lm # Unpacks to "lm".
unzip lm_train_pbr.zip -d lm # Unpacks to "lm".
YCB-Video
- YCB-Videoデータセットは、ワシントン大学のRSE Labのサイトからダウンロードすることができます
- ただし、データセットの大きさが256GBあるのでダウンロードする際には、ダウンロードするPCに十分な空き容量があるかチェックする必要があります。
Training
Discussion