【論文5分まとめ】Multiresolution Hash Encoding
概要
低コストなNeural Graphics PrimitiveであるMultiresolution Hash Encodingを提案。階層的なハッシュテーブル構造により、効率的な位置エンコーディングを実現。CUDAレベルでの最適化も組み合わせて行うことで、わずか数十秒でNeRFモデルを訓練できるなど、さまざまなアプリケーションでの訓練を高速化できる。

書誌情報
- Müller, Thomas, et al. "Instant Neural Graphics Primitives with a Multiresolution Hash Encoding." arXiv preprint arXiv:2201.05989 (2022).
- https://arxiv.org/abs/2201.05989
- https://github.com/NVlabs/instant-ngp
ポイント
Neural Graphics Primitive
Neural GraphicsにおけるPrimitiveとは、位置情報から得られるコードであり、例えば、スカラー位置
Multiresolution Hash Encoding
入力座標
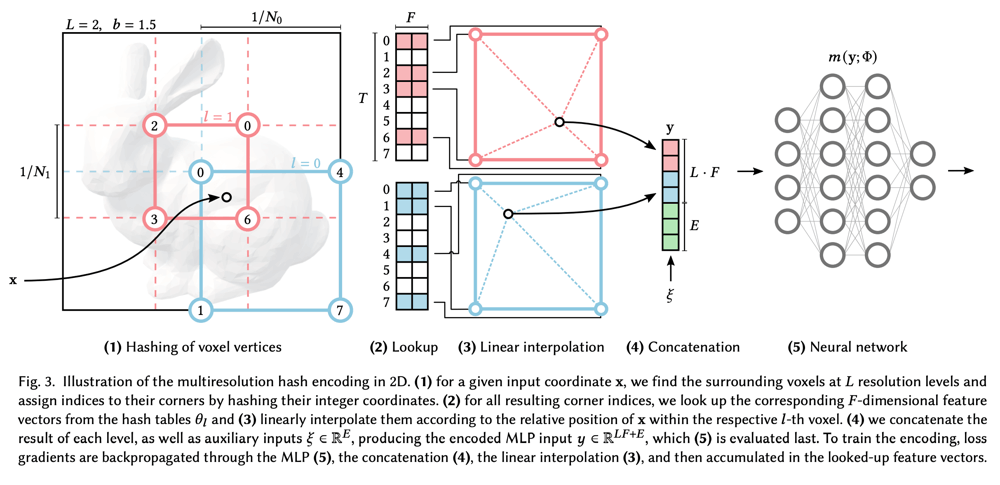
各階層の格子の数(解像度)は以下のように定義する。上図の例では、
各階層では、
各格子点には、疑似乱数的なハッシュキーが下式によって与えられる。
近傍の格子点のハッシュキーからハッシュテーブルを参照し、ハッシュ値(上図では
モデルによっては、位置情報のエンコード以外の入力が存在する。例えば、NeRFでは、視線の方向や材質を表す反射特性などが挙げられる。このような
上図は極めて単純な例ではあるが、実際には下の表のような値が使用されている。

以上のような仕組みによって得られる入力
いくつかの論点
パフォーマンスとクオリティ
ハッシュの衝突
ハッシュテーブルは全階層で同じ大きさ
低解像度の階層ではハッシュ衝突が起きず、単射的にハッシュ値が決まる一方で、高解像度の階層では
幸い、ハッシュキーは空間上にランダムに散らばっているため、全階層の同一点で同時に生じることはまず無い。また、各種タスクの再構成において重要な点(NeRFで言えば密度が高い点)と重要でない点(NeRFで言えば密度が低い点)があり、ハッシュ衝突を起こしている全ての点がいずれも重要な点であるということはほとんどない。
仮に、同程度に重要な点同士がある階層でハッシュ衝突を起こしていたとしても、その階層のハッシュテーブルは片方の点を重視して訓練が進み、近隣の別の階層のハッシュテーブルでもう片方の点を重視した訓練が進むだけであり、全体としてはとしてはいずれの重要な点に関しても訓練が進むことになる。
オンライン適応
本手法は、訓練中に
このような特性は、継続的に新しいデータが与えられるneural radiance cachingのようなモデルで有効に働く。
d-linear補間
補間なしでは、格子状の不連続な領域が生じてしまうので、格子点からの距離に応じた補間を行う必要がある。その場合の補間の重み(
このような標準的な線形補間以上に滑らかな補間(2次補間、3次補間)が必要な場合がある(例:法線ベクトルも再構成したい時)。その場合は、低コストの代替手段として、
実装
実装状の工夫を箇条書きでまとめておく。
- 実装は、tiny-cuda-nn frameworkを使用している。
- ハッシュテーブルをGPUのL2キャッシュ(RTX 3090で6MB)に格納することで、高速な演算を可能にしている。そのため、
T - OptimizerはAdamを使用し、
\beta_1=0.9, \beta_2=0.99, \epsilon=10^{-15} \beta_1, \beta_2 \epsilon - 長期の訓練による発散を抑制するため、ある程度訓練が進んでから、MLPに対してのみ弱いL2正則化(重みは
10^{-6} -
T
Discussion