こんにちは、スマートラウンドSREの@fillz_nohです。社内の開発者向けにAIを使った翻訳する仕組みを提供しています。
工夫の一端を2つの記事で書いてみました。
今回はその全体を書いてみたいと思います。
なぜRAGを使っているのか
なぜAmazon Bedrockのナレッジベース、つまりRAG(検索拡張生成)を使っているのかというと、先の記事でも触れましたが
- ファイナンスや法律の言葉も扱うので、出来るだけ確立された訳を使いたい
- その他の部分も統一感が大事なので、既存の翻訳を参考にした表現をして欲しい
の理由から、蓄積されたデータを検索してその結果を参考にして翻訳を実行するためとなります。
全体像
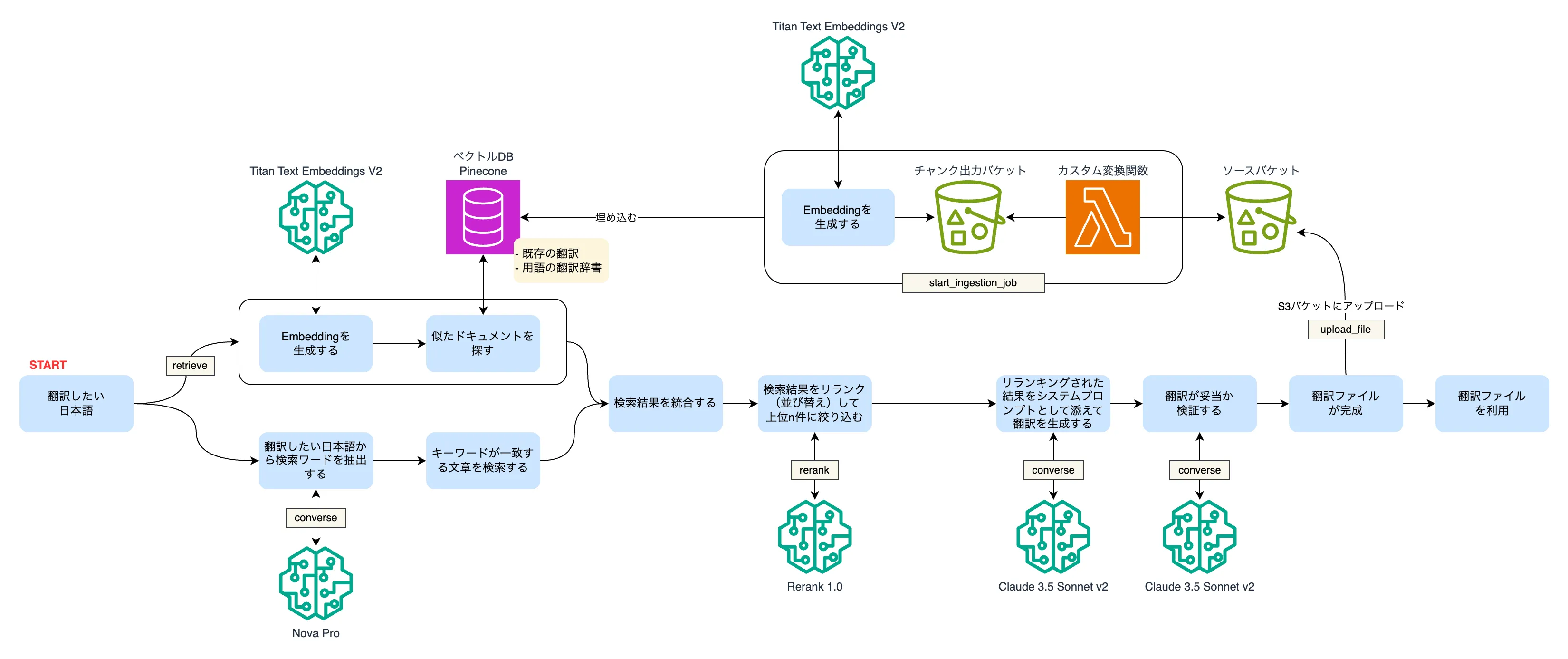
社内の開発者向けなので、ターミナルで実行し、ローカルPythonスクリプトがBedrockへリクエストしたり、テキスト処理を行います。
以下のような日本語JSONから翻訳して値の部分に英語を入れた英語JSONを作成します。
{
"サンプル1": "サンプル1",
"{0}より大きい": "{0}より大きい"
}
{
"サンプル1": "Sample1",
"{0}より大きい": "Greater than {0}"
}
実際には既存の翻訳が数千行あるファイルですので、実行時に未翻訳のキーを検出して翻訳対象としてリストアップしています。
前処理
前処理として、既存の翻訳や辞書を精度の高い検索が出来るようにLambda関数を使ったチャンキングを行います。
チャンクにノイズが多かったり、逆に足りなかったりすると大きく翻訳精度に影響しますので、根幹の処理となります。
ハイブリッド検索・リランキング
Bedrockナレッジベースへ Retrieve でベクトル検索する一方で、ローカルの同じソースファイルに対してキーワード検索を行い、ハイブリッド検索を実現しています。
このベクトル検索とキーワード検索は、非同期・並列で実行しています。
2つの検索結果を統合し、リランキング(専用モデルにて関連性が高い順に並び替え)を行います。多めの検索結果を取得し、5件程度に絞り込むことで、ノイズの少ない適切な量の参考情報を翻訳処理時に渡すことが出来ます。
未翻訳のキーを10件検出したら10件翻訳処理するのですが、時間をかけるとユーザー(社内開発者)に負荷を掛けるので、ハイブリッド検索とリランキングは各キーを並列で処理します。10件であれば直列で8秒程度掛かったりしますが、並列で2秒程度で収まりました。
Retrieve APIやAmazon Nova proにはQuotaがあるのでレートリミット処理(呼び出し数が最大値を超えそうな場合は待機、エラーとなった場合は指数バックオフのリトライ)も行っています。
翻訳
ユーザープロンプトには、シンプルに翻訳したい日本語のみを入れます。
システムプロンプトに、コンテキストと出力フォーマット指定、リランキングされた検索結果を記述します。
ベクトルDBに埋め込み済みの既存翻訳は、検索で参照できますがまだ反映されていない今回のバッチ(同一実行回)の翻訳も参照し一貫性を持たせたいので、翻訳は直列に処理し直前までの翻訳もシステムプロンプトに含めています。開発フロー上、同じバッチには関連する翻訳が多いのでこれは重要になります。
Reference materials:
The search results below contain previous translations and terminology used in the platform.
Use these to maintain consistency in your translations. When a term or phrase appears in the search results,
prioritize using the same translation for consistency.
<search_results>
{search_results}
</search_results>
Additionally, refer to the previous translations below:
<previous_translations>
{previous_translations}
</previous_translations>
また、出力には翻訳した英語のみを出力するように二重三重に厳命しています。
最終的なシステムプロンプトはモデルの呼び出しログで確認できます。
翻訳の検証
ここまでやって改善させてもエラー的な応答メッセージが紛れることはありえますし、ズレた翻訳する可能性もあります。
このため、各キーごとに日本語と翻訳された英語に違和感がないかをAIにダブルチェックさせています。NGとなった翻訳は成果ファイルに追加せずスキップします。
翻訳と同じモデルを使いますが、客観的な視点でチェックしてほしいので検索結果は添えずにリクエストしています。
また厳密にチェックすると多くの翻訳が合格できないので、大意として合っていて出力フォーマットにあっていればOKとしています。明らかな間違いやエラーのみを排除します。
後処理
翻訳ファイルが完成したら本筋の処理は終わりですが、今回の翻訳を次回実行時に反映出来るようにS3にファイルをアップロードし、ナレッジベースの同期を実行します。
更新されたファイルのチャンキングが実行され、ベクトルDBに埋め込まれます。
今後の課題
最初はシンプルなRAG運用の翻訳でしたが、いくつかの改善を行うことができました。まだ一部、本格的な運用にのせられていないので今後の経過を見て分析していきたいと思います。
また、参考にしている既存の翻訳部分にあまり良いとは言えない翻訳があるので、クオリティの底上げのために過去の翻訳を見直しをして表現の質だったり、表記揺れなどを修正していきたいと思います。
スマートラウンドでは色々な職種、ポジションで募集しています。ご興味ある方ぜひカジュアル面談に!

株式会社スマートラウンドは『スタートアップの可能性を最大限に発揮できる世界を作る』というミッションを掲げています。スタートアップと投資家の実務を効率化するデータ作成・共有プラットフォーム『smartround』を開発・提供しています。 採用ページはこちら-> jobs.smartround.com/
Discussion