Amazon Nova使ってますか?
Amazon NovaはBedrockで使える基盤モデルです。個人的には速い!安い!上手い!が印象のモデルです。
が、結局Claude使ってしまいがちです。
どのようなケースでNovaを使うのか模索していましたが、1つ良い感じに使えたので共有させてください。
ハイブリッド検索を使いたい!でもOpenSearch Serverlessは気軽に使えない😢
前回の記事でも触れましたが、社内開発者向けにRAG(検索拡張生成)を使ったAI翻訳の仕組みを提供しています。RAGの精度改善として前回はチャンキングを改善しましたが、ハイブリッド検索を使ってさらに改善したいと考えています。
Amazon Bedrockにおいて現状ハイブリッド検索をサポートしているのはOpenSearch Serverlessのみになります。
OpenSearch Serverlessは最低OCUが0.5になったとはいえ、月額200ドルを超えるのでプロダクト向けの重要な機能ならまだしも、社内開発者向けの翻訳の提供となるとスタートアップには気軽には使えません。AWSのマーケットプレイス経由でPineconeを使っていますが、現状ではBedrockからハイブリッド検索は使えません。なので、自前でやってみることにしました。
そもそもハイブリッド検索とはなんぞや?
RAGの一般的なフローは以下の通りです。
- ユーザーからの質問(Query)を受け取る
- ベクトル検索などで関連性が高い情報を外部データから検索(Retrieve)する
- 検索で得られた情報をコンテキストとしてLLMに渡し、回答を生成(Generate)する
2番の検索の部分で、多くはベクトルデータベースを使った検索が使われます。何故ベクトル検索が使われるかというと、ユーザーの質問と論理的に近い文章を検索出来るためです。表現・表記揺れに対応した検索です。ユーザーは多様な言葉使い、あいまいな表現で質問するので、それを単純なキーワード検索では取得できないおそれがあります。
例
質問
資金調達をした企業の一覧を教えてください
データベース内の文章
増資を完了したスタートアップのリスト
エクイティファイナンス実施企業一覧
キーワード検索の場合が「資金調達」のワードで検索するので、上記の2つの文章は取得できません。しかし、ベクトル検索の場合は「資金調達」に意味が近い文章として取得できます。ユーザーのあいまいな質問に対応出来ますね。
凄く便利な反面、(今回の場合)1024次元の座標に変換されたベクトル空間の中で座標が近いものを取得するので、専門用語などの厳密な検索には難しいです。そのためベクトル検索とは別に、キーワード検索を併用することで、より良い検索結果を得ることが出来ます。このそれぞれの検索の長所でお互いを補完するのがハイブリッド検索になります。
私が取り組んでいるAI翻訳は、社内開発者向けに提供しているAI翻訳ですが、金融関係の言葉もあり法律用語も含まれ、既存の翻訳と表現を出来るだけ統一したいという思いがあるので、ハイブリッド検索を1人熱望しておりました。
前述の通りOpenSearch Serverlessには手が出ないので、自前でやってみることにしました。都合がいいことに、開発者向けとしてターミナル上で動く仕組みなのでローカルで対象ファイル内を検索します。
ローカルでのキーワード検索
ローカルのPythonスクリプトからBedrockに翻訳依頼を投げる仕組みなので、キーワード検索もPythonで行います。ChatGPTやClaudeに相談すると、WhooshやRapidFuzzなどのライブラリを提案されましたが、
- 出来るだけにシンプルで軽量にしたい
- あいまい検索はいらない
- 検索対象も数MB程度で大きくはない
のでPython標準の検索機能で十分だと判断しました。
問題は質問文(今回の場合は英訳したい日本語)から検索用のキーワードをどう選ぶかです。王道の形態素解析を使うことも考えましたが、単語は抜き出せてもどれが論理的に重要なワードなのか判別が難しいです。方法はあるのかもしれませんが知見がなさすぎて分かりません。こういうのはLLMが得意そうだなと思い、これもBedrockで処理させることにしました。
Amazon Novaを使って検索用のキーワードを抽出する
何故Amazon Novaを使うかというと、速くて安いからです。
Claudeが1秒超えるところ、同じプロンプトでNova Proでは0.5秒切ったりします。

Claude 3.5 Sonnet v1(オンデマンド クロスリージョン無し)
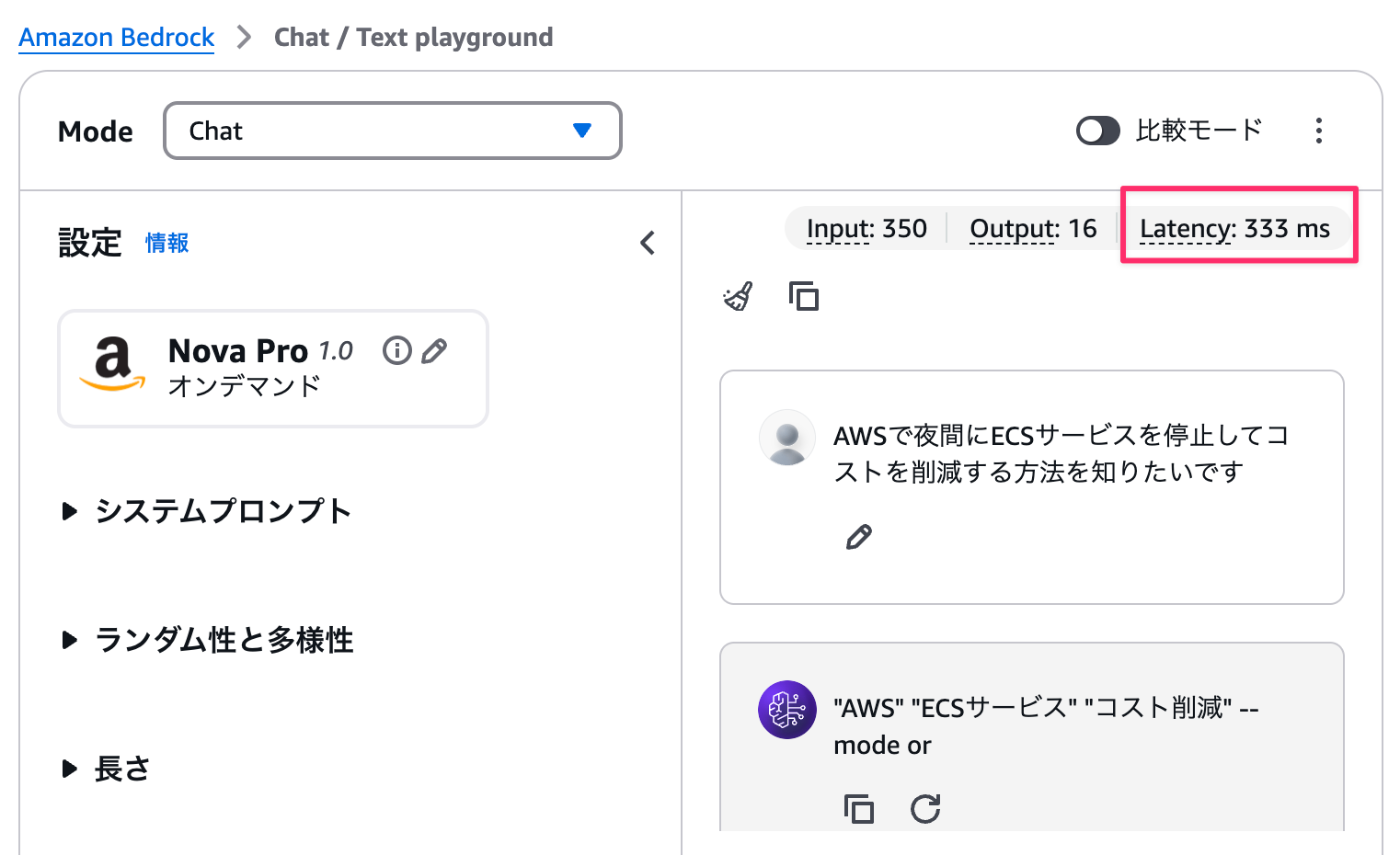
Amazon Nova Proのレイテンシー。爆速!
またClaude 3.5 Sonnet v2 / 3.7 Sonnetなど人気のモデルの場合はクロスリージョン推論になるので僅かですがさらにレイテンシーが増える場合があります。
そして安い!
2025年03月現在 (バージニア北部基準)の料金
| モデル | 1,000 入力トークンあたりの価格 | 1,000 出力トークンあたりの料金 |
|---|---|---|
| Claude 3.7 Sonnet | 0.003 | 0.015 |
| Claude 3.5 Sonnet | 0.003 | 0.015 |
| Claude 3.5 Haiku | 0.0008 | 0.004 |
| Amazon Nova Pro | 0.0008 | 0.0032 |
| Amazon Nova Lite | 0.00006 | 0.00024 |
| Amazon Nova Micro | 0.000035 | 0.00014 |
最上位のNova Proで3.5 Haiku並の安さです。
メインの翻訳処理ではClaudeを使っていますが、キーワードを抽出という小さな処理に費用を掛けたくないのでNovaが適しています。
そして上のスクリーンショット画像でも分かりますが、応答(アウトプット)のクオリティもClaudeに遜色ないことが多いです。たまにアレという時もありますが、9割Claude並みの印象です。アウトプットが短いほど、Claudeとの違いがほとんどなくなってくるので今回のような短いアウトプットの場合はNova Proが良いと判断しました。Liteでも十分通用します。
プロンプト
システムプロンプトを以下のようにして、インプットにはキーワードを抽出したい文章を入れ、出力にはキーワード検索をかけるキーワードと検索モード(AND/OR)のみを出すようにしました。
## TASK ##
ユーザーが提供した文章から「2〜3つのみ」の主要なキーワードを抽出し、検索クエリとして整形してください。
## KEYWORD SELECTION CRITERIA ##
- 文章の主題を表す重要な名詞を選択すること
- 固有名詞や専門用語を優先すること
- 一般的すぎる単語(「こと」「もの」など)は避けること
- 必ず2つか3つのキーワードのみを選定すること(それ以上は選ばないこと)
## OUTPUT FORMAT ##
以下の形式「のみ」で出力すること:
"キーワード1" "キーワード2" ["キーワード3"] --mode [or|and]
例:
"AWS" "ECS" "コスト削減" --mode or
重要: 上記の形式以外の説明文やプロセスの詳細は一切出力しないこと。
## SEARCH MODE RULES ##
- 基本的にOR検索を使用(`--mode or`)
- キーワードが2語で、かつ両方の語が必ず含まれる必要がある場合のみAND検索を使用(`--mode and`)
- キーワードが3語の場合は必ずOR検索を使用(`--mode or`)
参考までにAmazon Novaのプロンプトガイドは以下です。Claude向けに作ったプロンプトはほぼ通用する印象です。
結果としては先のスクリーンショット画像にもある通り
入力文: 「AWSで夜間にECSサービスを停止してコストを削減する方法を知りたいです」
出力: "AWS" "ECSサービス" "コスト削減" --mode or
という結果が得られました。このキーワードを使ってローカルファイルを検索します。
後続処理
A. RAG(ナレッジベース)からベクトル検索での結果を取得する(Retrieve API)
B. Amazon Novaで生成されたキーワードを使ってローカルファイルをキーワード検索する
直列処理では1つの翻訳に時間が掛かるので、asyncioを使って上記のAとBを非同期・並列に実行します。
AとBの両方をの検索結果が出たら、これを統合します。単純に合わせても上位結果を参考に生成(翻訳)を行うので、並び順が大事です。
リランキング
リランキングは、検索結果を別の方法で質問(クエリ)に沿った内容にモデル(AI)が再度ランキング(並び替え)する手法です。さらに並び替えて件数を上位からn件に絞り込む機能もあります。
BedrockではCohereのRerank 3.5とAmazonのRerank 1.0という2つのリランキング専用モデルが用意されています。Cohereの方が若干高速なようですが、料金が倍なのでAmazonを選びます。
| モデル | 1,000 クエリあたりの料金 |
|---|---|
| Cohere Rerank 3.5 | 2.00 |
| Amazon Rerank 1.0 | 1.00 |
制約上、バージニア北部リージョンでBedrockを使っているのですが、リランキングモデルがまだ使えません!仕方がないのでrerankだけオレゴンにリクエストします。ローカル実行なのでこの辺は柔軟に出来ます。でも早くバージニアにも来てくれー!
今回はローカルでのキーワード検索の結果と合わせる必要があるのでRerank APIを使いました。 Retrieve RetrieveAndGenerate でもリランキングはオプションとして使用できます。 InvokeModel でも使用出来るようです。
AとBでそれぞれ10件ずつ検索して、リランキングで並び替えて上位5件に絞り込みます。AとBで重複する結果はありますが、リランキングされた結果でも両方含まれていてもそれだけ重要ということで気にしないことにします。
{
"results": [
{
"index": 0,
"relevanceScore": 0.9930424094200134
},
{
"index": 5,
"relevanceScore": 0.8832359910011292
},
{
"index": 14,
"relevanceScore": 0.7774688601493835
},
{
"index": 1,
"relevanceScore": 0.5971968770027161
},
{
"index": 11,
"relevanceScore": 0.0025409925729036
}
]
}
上記のような結果を受け取ります。リランキングする前の順番とスコアが返ってきます。ドキュメント上だと、文章もレスポンスに含まれるはずですが、実際には含まれていませんでした。indexを照合して文章も付け足します。
あとはこの並び替えられた上位5件の検索結果を翻訳の際にシステムプロンプトとして添えるだけです!(翻訳の全体像を踏まえた続きの記事も書いていきたいと思います。)
まとめ
Amazon Novaを使ってキーワードを抽出して、キーワード検索を行い、その結果をリランキングしてハイブリッド検索を実現しました。
Novaは速くて安いので、ワークフローとして組み込むには持って来いと感じました。今後も取り入れていこうと思いました。
スマートラウンドでは色々な職種、ポジションで募集しています。ご興味ある方ぜひカジュアル面談に!

株式会社スマートラウンドは『スタートアップの可能性を最大限に発揮できる世界を作る』というミッションを掲げています。スタートアップと投資家の実務を効率化するデータ作成・共有プラットフォーム『smartround』を開発・提供しています。 採用ページはこちら-> jobs.smartround.com/
Discussion
全体像の記事を書きました