要約
- ソースデータがCSVやJSON、XMLだとかの構造化データの場合は、Lambda関数でのチャンキングが向いてるぞ!
- バッチリ綺麗で論理的にも過不足無いチャンクが出来るぞ!
- メタデータも自在に付与できて良い
きっかけ
こんにちは、スマートラウンドSREの@fillz_nohです。社内の開発者向けにAIを使った翻訳する仕組みを提供しているのですが、既に翻訳済みのものや専門用語辞書を参考にして欲しいので、Amazon Bedrockのナレッジベースを使ったRAGを運用しています。
概ね問題なさそうに翻訳出来ている感じでしたが、稀にうまく翻訳出来ない、処理出来ないというLLMの応答 Sorry, I am unable to assist you with this request. になっておりました。制約上、前後の文が無い単文翻訳故にと、LLMだから一定の割合でこうなるのは仕方がないかなと思っていました。しかし、モデルの呼び出しログを確認してみるとRAG検索の結果はかなり精度が悪いことが判明しました。
チャンキングの課題
具体的にどのように検索結果の精度が悪いか、ソースデータのサンプルとして法務省の日本法令外国語訳データベースシステムにて提供されている法令用語日英標準対訳辞書を使って説明します。[1]
PDFやXMLもありますが、今回はCSVを使用しました。
例えば「投資事業有限責任組合」でベクトルDBを検索した場合、以下のような検索結果を受け取りました。[2]
{
"retrievalResults": [
{
"content": {
"text": "meaning the investment equities that the investment corporation issues at the time of its incorporation; the same applies below).,投資信託及び投資法人に関する法律第68条,,\r 投資顧問契約,とうしこもんけいやく,,investment advisory contract,証券の場合,,,,,\r 投資事業,とうしじぎょう,,investment business,,,,,,\r 投資事業有限責任組合,とうしじぎょうゆうげんせきにんくみあい,1,investment limited partnership,,,,,,\r 投資事業有限責任組合,とうしじぎょうゆうげんせきにんくみあい,2,investment business limited partnership,,,,,,\r 投資者,とうししゃ,,investor,,投資者(の)保護,protection of investors,,,\r 当事者,とうじしゃ,,party,,,,,,\r 当事者訴訟,とうじしゃそしょう,,public law related action,,,,,,\r 当事者適格,とうじしゃてきかく,,standing,,,,,,",
"type": "TEXT"
},
"location": {
"s3Location": {
"uri": "s3://example-bucket/datasource/utf8_law.je.dic.17.0.a.csv"
},
"type": "S3"
},
"metadata": {
"x-amz-bedrock-kb-source-uri": "s3://example-bucket/datasource/utf8_law.je.dic.17.0.a.csv",
"x-amz-bedrock-kb-data-source-id": "ABCDEFGHIJ"
},
"score": 0.49147337675094604
},
...
]
}
「投資事業有限責任組合」が含まれている結果にはなりますが、ノイズが多く分かりにくいですよね(今回はサンプルとして単一ワードで検索しましたので比較的まともな結果ですが…)
これはソースドキュメントを検索可能な塊(チャンク)として適切に分割出来ていないためです。
困りごととしては以下の3点です。
- セマンティックチャンキングを行ってもぶつ切りになることがある
(検索結果1番目の先頭は前の言葉の翻訳例が途中で切れている) - 余計なノイズが多い
- CSVの場合、何のカラムの値かチャンクからは分からない
Amazon Bedrockのチャンキング戦略
RAGを実装する際、ドキュメントをどのように分割するかは検索精度に大きく影響します。Amazon Bedrockでは以下のチャンキング戦略が用意されています:
-
Default chunking (デフォルトチャンキング)
ドキュメントを約300トークンのチャンクに分割し、文の境界を維持します。 -
Fixed-size chunking (固定サイズチャンキング)
ドキュメントを指定したトークン数の約同じサイズのチャンクに分割します。 -
Hierarchical chunking (階層的チャンキング)
ドキュメントを親子2レベルに分割します。親チャンク(大きい)と子チャンク(小さい)の両方を作成し、検索時には子チャンクを検索しつつ、より広い文脈を提供するために適宜親チャンクに置き換えます。 -
Semantic chunking (セマンティックチャンキング)
構文的な区切りよりも意味的なまとまりを優先してドキュメントを分割します。文の類似度や関連性に基づいて自然な意味の区切りを検出し、理解しやすいチャンクを作成します。基盤モデルを使用するため、追加のコストがかかります。 -
No chunking (チャンキングなし)
各ドキュメントを丸ごと1つのチャンクとして扱います。ドキュメントが小さい場合や内容が一貫している場合に適しています。
Lambda関数を使ったカスタムチャンキングを行う場合は、このオプションを選択します。
今回は「チャンキングなし」を選択し、Lambda関数を使ってカスタムチャンキングを行いました。
カスタムチャンキングでの改善例
Lambda関数を使って以下のようなチャンク結果を取得できるようにしました。
{
"retrievalResults": [
{
"content": {
"text": "用語: 投資事業有限責任組合\n読み: とうしじぎょうゆうげんせきにんくみあい\n訳語候補番号: 1\n訳語候補: investment limited partnership",
"type": "TEXT"
},
"location": {
"s3Location": {
"uri": "s3://example-bucket/datasource/utf8_law.je.dic.17.0.a.csv"
},
"type": "S3"
},
"metadata": {
"x-amz-bedrock-kb-source-uri": "s3://example-bucket/datasource/utf8_law.je.dic.17.0.a.csv",
"x-amz-bedrock-kb-data-source-id": "ABCDEFGHIJ",
"用語": "投資事業有限責任組合",
"読み": "とうしじぎょうゆうげんせきにんくみあい",
"訳語候補番号": "1",
"訳語候補": "investment limited partnership",
"使い分け基準": "",
"用例(和文)": "",
"用例(英文)": "",
"用例出典": "",
"注釈1": "",
"注釈2": ""
},
"score": 0.6461276412010193
},
...
]
}
contentのtextには、値があるカラムのみ出力するようにして、metadataとしても付与するようにしました。metadataを使ったフィルタリングは現在行っていませんが、大した手間ではないので将来のことも考えて付与します。こんなんなんぼあってもいいですからね。
Lambda関数は、以下の公式ドキュメントを提供してLLMにさくっと書いてもらいました。
- Customize ingestion for a data source - Amazon Bedrock
- Use a custom transformation Lambda function to define how your data is ingested - Amazon Bedrock
- Advanced chunking strategies provided by Amazon Bedrock Knowledge Bases
def process_csv_content(csv_text):
"""CSVファイルを適切なチャンクに変換する処理"""
processed_chunks = []
csv_file = io.StringIO(csv_text)
reader = csv.DictReader(csv_file)
# 処理対象の列名リスト
columns = ["用語", "読み", "訳語候補番号", "訳語候補", "使い分け基準", "用例(和文)", "用例(英文)", "用例出典"]
for idx, row in enumerate(reader):
# 値がある列のみを含めたテキストを作成
content_lines = []
for col in columns:
value = row.get(col, "").strip()
if value: # 空でない場合のみ追加
content_lines.append(f"{col}: {value}")
# チャンクのテキスト部分
chunk_text = "\n".join(content_lines)
# チャンクの構造を作成
chunk_content = {
"fileContents": [{
"contentBody": chunk_text,
"contentType": "TEXT",
"contentMetadata": row # メタデータとして全カラムを付与
}]
}
processed_chunks.append((f"chunk_{idx}.json", chunk_content))
return processed_chunks
def write_chunk_to_s3(s3_client, bucket, key, content):
"""チャンクをS3に書き込む処理"""
s3_client.put_object(
Bucket=bucket,
Key=key,
Body=json.dumps(content, ensure_ascii=False),
ContentType="application/json" # ここが重要
)
評価
Amazon Bedrockには、評価機能があるのでこれでRAGを客観的に評価します。
Before(セマンティックチャンキング)

After(カスタムチャンキング)
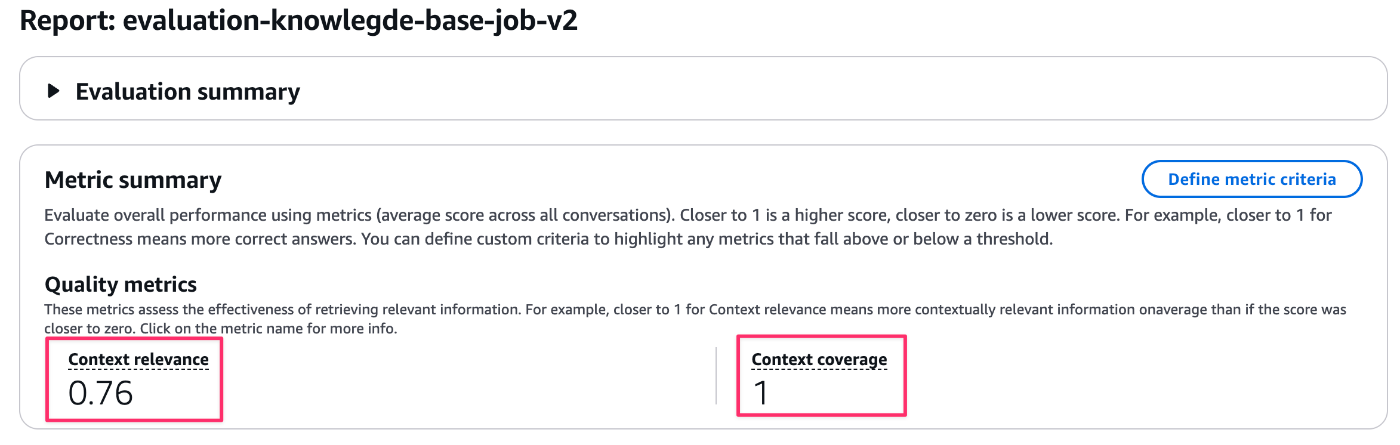
| Context relevance | Context coverage | |
|---|---|---|
| before | 0.88 | 0.93 |
| after | 0.76 | 1 |
見事、カバレッジは満点の1.0に改善しました。これは、カスタムチャンキングによってクエリに対する必要な情報が一つのチャンク内に過不足なく含まれるようになった効果です。
一方、関連性(relevance)のスコアは0.88から0.76へと少し下がっています。これは改善前は検索結果5件のうち複数のチャンクに分散してヒットしていたのが、改善後は検索結果1件目で正確にヒットしているため残り4件がベクトルDB上の論理的な意味の近似値として検索結果に含まれており直接的な関連性が無く、検索結果5件全体の評価としては下がるためになります。
その結果「関連性スコア」自体は下がりましたが、検索結果の最上位がいつも最適な情報になるので、実質的な検索精度や使い勝手はグッと向上しているかと!
まとめ
RAGのチャンクデータはよく言われることとして、チャンクサイズが大きいとコンテキストも含められるがノイズも多くなる、逆にチャンクサイズが小さいとノイズが減るがコンテキストが欠落してしまうという問題があります。これを解決するためにセマンティックチャンキングがありますが、それでも完璧ではありません。特にCSVやJSON、XMLといった構造化データにおいては、(よく考えれば当たり前ですが)Lambda関数によるカスタムチャンキングが非常に効果的だということが分かりました。
例えば公共系のオープンデータは多くがXML形式で提供されており、e-Gov法令検索などの法令データもXMLで入手可能です。以前、PDFを使った法令RAGを試した際には、精度を上げるためにLLMパーサーを使用しましたが、予想以上のコストがかかりました。今後は、Lambda関数でXMLを直接処理する方法でコストを抑えて高い精度を持てるよう検討していきたいと思います。
スマートラウンドでは色々な職種、ポジションで募集しています。ご興味ある方ぜひカジュアル面談に!
-
「法令用語日英標準対訳辞書」(法務省)を加工して作成 ↩︎

株式会社スマートラウンドは『スタートアップの可能性を最大限に発揮できる世界を作る』というミッションを掲げています。スタートアップと投資家の実務を効率化するデータ作成・共有プラットフォーム『smartround』を開発・提供しています。 採用ページはこちら-> jobs.smartround.com/
Discussion
全体像の記事を書きました