機械翻訳、および、述語などの単語の言い換えを組み合わせた文章クラスタリングの実装と評価
目次
- 本記事の動機
- 前記事の課題、および、本記事の実装内容の簡単な説明
- 今回の学習データセット、および、実装環境
- 機械翻訳前の正規化
- DeepLのAPIを用いた機械翻訳の実装
- 文末語の整理
- 単語の言い換え処理
- 文章クラスタリングの実装と評価
- 本記事のまとめ、および、次記事の予定
- 参考文献
本記事の動機
以前の記事では、transformerを用いて、ChatGPTに与える日本語のプログラミングの指示文のクラスタリングを実施しました。この記事ではクラスタリングが上手くいっていない点があり、正規化の方法の見直しが課題となっておりました。
自然言語処理の勉強をしている中で、別の記事のプログラムを考えている際、文章の言い換えをする上で、機械翻訳を行う方法や文末語の整理(参考文献1、参考文献2、参考文献3、参考文献4)が有効な方法の1つであることが分かりました。
そこで、本記事ではDeepLのAPIの機械翻訳をしつつ、正規化として文末語の整理をすることによって、クラスタリングの精度向上が見込めるのかを確認したいです。
前記事の課題、および、本記事の実装内容の簡単な説明
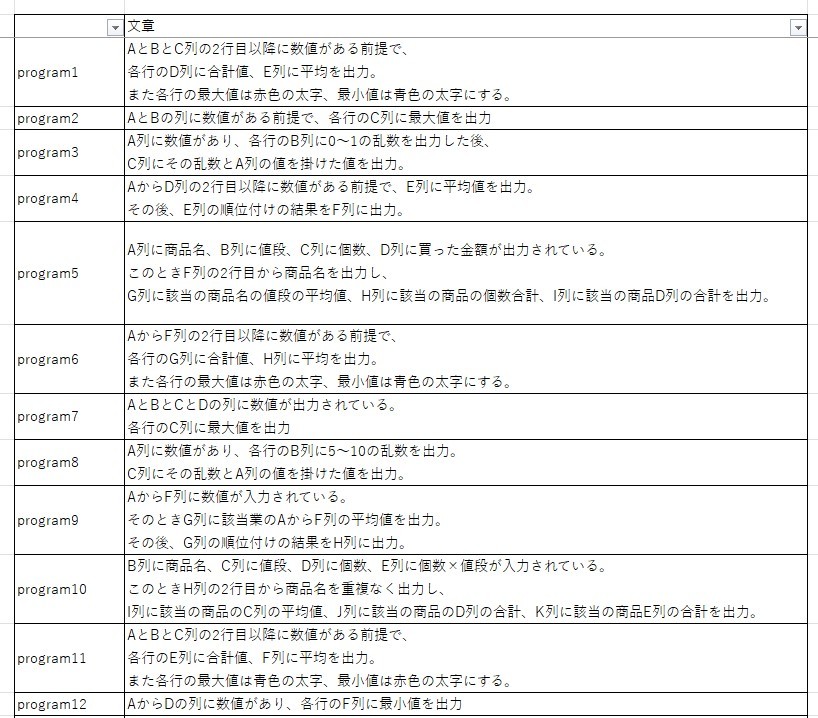
前記事では、日本語のプログラム指示文100文に対してtransformerを用いてクラスタリングできるかを実装して確認しました。プログラム指示の100文は
- 計算や比較結果の出力 : 何かしらの規則を基に計算や比較を実施。それをExcel上に表示
- グラフ描画 : Excelシートの値を基にグラフの描画
- Excel操作 : シート名の編集やコピー等のExcel操作
の3種類の指示に分かれていると考えて、プログラム指示文が 3種類のクラスターに分割可能かを確認しました。しかし、実装結果は画像のように、グラフ描画のプログラム指示文の一部(クラスターNo.1)が、計算や比較結果の出力のプログラム指示文(クラスターNo.2)のクラスターに分類されていました。

これはグラフ描画以外の情報を重く見てしまい、計算や比較結果の出力のクラスターに分類てしいると考えました。これを回避する方法として、文章の言い換えが有効な可能性があると発見しました。
文章の言い換えに関する研究として、言語学習者に対する難解な表現を平易な表現に言い換えて、言語学習者のレベルに応じた文章を作成する研究が、上記参考文献以外にもなされています。その中でも、機械翻訳を用いた言い換えの手法の研究も数多くなされているようです。(参考文献5、参考文献6)
そこで、本記事では機械翻訳による文章の言い換えを行い、精度の良いクラスタリングができるのかを試しました。その際、翻訳結果を見つつ冗長表現や同じ意味で使用している名詞や、動詞・助動詞などの述語を正規化して修正することにより、文章の表現ゆれを可能な限りなくすことでクラスタリング精度を向上させる方法を考えました。(参考文献2、参考文献3)
今回の学習データセット、および、実装環境
今回の学習データセットは、以前の記事で用いたプログラム文指示文100文です。また、実装はGoogle Colaboratoryで行いました。



機械翻訳前の正規化
まず機械翻訳前に正規化して翻訳時の日本語に表現ゆれが生じないようにしました。本記事の主な正規化内容は以下の通りです。
- 出力箇所の表現ゆれの修正 : Excelのどの列に出力するか、どこの列に表示されているかの表現が各文章で表現のゆれがあるので、その部分を「○列」という表現になるように修正。

- Excel固有表現やファイル関連の表現ゆれの修正 : ブックやシートといったExcelの固有の単語がカタカタと英語で表現のゆれがあったのでカタカタで修正。またフォルダの指定方法も表現のゆれがあったので修正。

- 数値の桁の修正 : 数字の桁等が異なるといけないので、「○」で修正。
その他の正規化の含め、以下の関数で実装しました、
import re
import neologdn
def normarilize_txt(text) :
#改行文字、空白文字の変換
re_text = re.sub(r'[\s\t\n]','',text)
#~関連文字列変換
re_text = re.sub(r'[~~-]','から',re_text)
#括弧の変換
re_text = re.sub(r'[\'"「](.*?)["\'」]','「XX」',re_text)
# Unicode正規化と全角英字の半角変換
re_text = unicodedata.normalize('NFKC', re_text)
re_text = re_text.lower()
#英字列変換
re_text = re.sub(r'[a-zA-Z]と+','○列、',re_text)
re_text = re.sub(r'[a-zA-Z]の列','○列',re_text)
re_text = re.sub(r'[a-zA-Z]+列','○列',re_text)
re_text = re.sub(r'([a-zA-Z]、)+','○列、○列',re_text)
re_text = re.sub(r'[a-zA-Z]の値','○列の値',re_text)
re_text = re.sub(r'(○列、)+','○列、○列',re_text)
re_text = re.sub(r'[a-z]から○列','○列、○列',re_text)
re_text = re.sub(r'(○列)+','○列',re_text)
#セル名変換
re_text = re.sub(r'([a-z])+[+-]?\d+','○',re_text)
#Excel関連の用語変換
re_text = re.sub(r'book','ブック',re_text)
re_text = re.sub(r'sheet','シート',re_text)
re_text = re.sub(r'cell','セル',re_text)
re_text = re.sub(r'excel','エクセル',re_text)
#数値変換
re_text = re.sub(r'[+-]?\d+(\.\d+)?','×',re_text)
#フォルダの名前変換
re_text = re.sub(r'c:.*フォルダ','あるフォルダ',re_text)
#その他正規化
re_text = neologdn.normalize(re_text)
return re_text
機械翻訳の実装
機械翻訳を用いた言い換え方法を実装するにあたり、本記事ではDeepLを用います。APIの登録や実装方法は、この記事を参考にしました。
まずライブラリのインストールを行います。
!pip install deepl
import deepl
続いて、日本語のプログラムを英訳をした後、その英訳文を再度日本語訳する関数を実装しました。なお、セル名や列番号の「○」が「 _ 」に訳されていた文章があり複数回翻訳する際に変な訳文になったので、そこだけ「XX」に修正するように実装しています。
def TranslateforSimple(JA_txt,before_from_lang,before_to_lang,simple_from_lang,simple_to_lamg,count) :
#英訳
print(str(count) + "回目英訳前 : ", JA_txt)
start_translate_txt = translator.translate_text(JA_txt, source_lang=before_from_lang, target_lang=before_to_lang)
print(str(count) +"回目英訳後 : ", start_translate_txt.text)
start_txt = re.sub("(_)+","XX",start_translate_txt.text)
#日本語訳
simple_translate_txt = translator.translate_text(start_txt, source_lang=simple_from_lang, target_lang=simple_to_lamg)
print(str(count) + "回目日本語訳 : ", simple_translate_txt.text)
return simple_translate_txt.text
本記事では2回翻訳を繰り返した結果を言い換え文(second_simple_lists)として採用します。実装方法は以下の通りです、
#翻訳語の設定
formJA_lang = 'JA'
toEN_lang = 'EN-GB'
fromEN_lang = 'EN'
toJA_lamg = 'JA'
#APIキーを指定
API_KEY = "XXXXXX-XXXXXXX"
# イニシャライズ
translator = deepl.Translator(API_KEY)
# first_simple_lists : 1回目訳文リスト(今回使用しない)
first_simple_lists = []
#secound_simple_lists : 2回目訳文リスト
second_simple_lists = []
end_count = 2
for pro_txt in programtxt_list :
translate_count = 1
#1回目翻訳
next_txt = TranslateforSimple(pro_txt,formJA_lang,toEN_lang,fromEN_lang,toJA_lamg,translate_count)
first_simple_lists.append(next_txt)
#2回目翻訳
if translate_count < end_count :
while translate_count < end_count :
translate_count += 1
next_txt = TranslateforSimple(next_txt,formJA_lang,toEN_lang,fromEN_lang,toJA_lamg,translate_count)
second_simple_lists.append(next_txt)
second_simple_listsとTranslateforSimple.pyの関係性は以下の通りです。

また結果は以下のようになります。

文末語の整理
文章の冗長表現をなくす作業として、文末の動詞や助動詞を修正していきます。
例えば、~する必要があるという表現は、~するという表現でも指示文の場合は同じ意味になります。そこで同様の文末語を探して正規化しました。内容は以下の通りです。また以下の関数では、文末語の正規化だけでなく他の正規化も行っています。
def normalize_second(txt):
#Excelのブックとシートの変更
re_text = re.sub(r'席','シート',txt)
re_text = re.sub(r'本','ブック',re_text)
#括弧の削除
re_text = re.sub(r"「|」|'|'",'',re_text)
#英字や記号の正規化
re_text = re_text.lower()
re_text = re.sub('列','x列',re_text)
re_text = re.sub('(x+)|(○+)','x',re_text)
#空白文字の削除
re_text = re.sub('\s','',re_text)
#ファイル関連の正規化
re_text = re.sub('フォルダー','フォルダ',re_text)
re_text = re.sub('カレント','現在の',re_text)
#文末語の修正
re_text = re.sub('されます','する',re_text)
re_text = re.sub('必要がある','',re_text)
re_text = re.sub('べきである','',re_text)
re_text = re.sub('でなければならない','にする',re_text)
return re_text
その他の文末語については、単語を見出し語である基本形に変換するレンマ化と呼ばれる方法を用いて文末を統一化しました(参考記事)。
レンマ化は文末を品詞ごとに分解して、2つ前までの品詞の組み合わせによってどこまでを基本形に変換するかを判断しました。条件はコードを参照してください。
def Paraphrasing_Sentence(tokens) :
pos_lists = []
#形態素解析
for t in tokens :
pos_lists.append(t.part_of_speech.split(",")[0])
#レンマ化 : 見出し語の抽出
lemmatized_lists = [t.base_form for t in tokens]
i = 0
result_txt = ""
end_index = 0
while i < len(pos_lists) :
#is_period = False
if pos_lists[i].startswith("記号") :
#文末の品詞が以下の並びの場合、文末の最後の2つの品詞までに対してレンマ化を実施
#「動詞」+「動詞」
#「助動詞」+「助動詞」
#「助詞」+「動詞」
#「助動詞」+「動詞」
if (pos_lists[i-1].startswith("動詞") and pos_lists[i-2].startswith("動詞")) or (pos_lists[i-1].startswith("助動詞") and pos_lists[i-2].startswith("助動詞")) or (pos_lists[i-1].startswith("助詞") and pos_lists[i-2].startswith("動詞")) or (pos_lists[i-1].startswith("助動詞") and pos_lists[i-2].startswith("動詞")) :
for j in range(end_index,i-1) :
result_txt += lemmatized_lists[j]
if pos_lists[i-1].startswith("動詞") or pos_lists[i-2].startswith("動詞") :
result_txt += "。"
else :
result_txt += lemmatized_lists[i]
#それ以外の場合は、全体にレンマ化を実施
else :
for j in range(end_index,i) :
result_txt += lemmatized_lists[j]
if pos_lists[i-1].startswith("動詞") or pos_lists[i-2].startswith("動詞") :
result_txt += "。"
else :
result_txt += lemmatized_lists[i]
#print(result_txt)
end_index = i + 1
i += 1
return result_txt
文末の更新した後のリストをnew_sentence_listsとすると、このリストは以下のように取得できます。
new_sentence_lists = []
for st in second_simple_lists:
re_st = normalize_second(st)
print("更新前 : ", re_st)
tokens = make_token(re_st)
new_sentences = Paraphrasing_Sentence(tokens)
print("更新後 : ", new_sentences)
new_sentence_lists.append(new_sentences)
結果は以下のようになります。

単語の言い換え処理
文章の言い換えに対して、既出の動詞や名詞を統一化することで、文章を数値ベクトル化した時の値を一致させ、クラスタリングの精度を向上させようと考えました。そこで、上記正規化し終えたプログラムの指示文における動詞や名詞の単語数を数えて、低頻度の単語を同じ意味の高頻度の単語に入れ換えていきます。単語数の出現数を数えるコードは以下のように実装しました。
#noun_dicts : 名詞の単語数辞書
#verb_dicts : 動詞の単語数辞書
noun_dicts = {}
verb_dicts = {}
for nsl in new_sentence_lists :
token_nsl = make_token(nsl)
for t in token_nsl :
input_string = str(t.surface)
#名詞の単語数の格納
if t.part_of_speech.split(",")[0].startswith("名詞") :
#既出の名詞であれば 単語数を+1、それ以外は 1
if input_string in noun_dicts:
if noun_dicts[input_string] is not None :
noun_dicts[input_string] += 1
else :
noun_dicts.update({input_string : 1})
else :
noun_dicts.update({input_string : 1})
#動詞の単語数の格納
elif t.part_of_speech.split(",")[0].startswith("動詞") :
#既出の名詞であれば 単語数を+1、それ以外は 1
if input_string in verb_dicts:
if verb_dicts[input_string] is not None :
verb_dicts[input_string] += 1
else :
verb_dicts.update({input_string : 1})
else :
verb_dicts.update({input_string : 1})
#降順に並び替え
sorted_noun_dicts = sorted(noun_dicts, key=lambda x: noun_dicts[x],reverse=True)
sorted_verb_dicts = sorted(verb_dicts, key=lambda x: verb_dicts[x],reverse=True)
上記プログラムを実行すると、以下のようになります。

例えば、画像のように~を表示すると~を出力するという述語は、Excelのプログラムの指示文において、ほぼ同じ意味になると考え、〜を出力するに修正しました。同様に、同じ意味としていい単語は高頻度の単語に言い換えました。

修正する正規化の関数は以下のように実装しました。
def normalize_new_sentence(txt):
#グラフ、折れ線グラフの動詞を「描く」に統一
re_text = re.sub(r'(引く)|(書く)','描く',txt)
#貼り付け関係のレンマ化の修正
re_text = re.sub(r'付ける','付け',re_text)
#「表示」→「出力」に修正
re_text = re.sub(r'表示','出力',re_text)
#「プロットする」→「描画する」に修正
re_text = re.sub(r'プロット','描画',re_text)
#グラフ関連を「グラフ」に修正
re_text = re.sub(r'(円グラフ)|(棒グラフ)|(散布図)|(折れ線)|(棒)|(破線)|(線)','グラフ',re_text)
re_text = re.sub(r'(グラフ)+','グラフ',re_text)
#「当該」→「該当」に修正
re_text = re.sub(r'当該','該当',re_text)
#「隣接する」→「隣の」に修正
re_text = re.sub(r'隣接する','隣の',re_text)
#「パーセンテージ」→「割合」に修正
re_text = re.sub(r'パーセンテージ','割合',re_text)
#英字の修正
re_text = re.sub(r'(ix)|(cxc)|(dx)|(cx)|(xd)|(xx)','x',re_text)
#「前提」→「仮定」に修正
re_text = re.sub(r'前提','仮定',re_text)
return re_text
上記正規化をしつつ、クラスタリングをする文章を作成します。このとき、前記事の課題の節でも記載したが、プログラム指示において実際の作業に当たる部分以外をクラスタリングの際の要素としてみなさないように、
- グラフ描画に対する文章のみを抽出するために、グラフという単語があればその文章を抽出。またグラフに対する動詞を「描く」に統一。
- 出力作業に対するプリグラム指示文は、出力という単語があればその文章を抽出。
- ファイル操作に関してはそれ以外の動詞が使われていると考え、特に操作なし
という実装を行うことで、クラスタリングの精度向上を試みました。
final_sentence_lists = []
for ns in new_sentence_lists:
final_txt = normalize_new_sentence(ns)
split_txt = final_txt.split("。")[::-1]
print(split_txt)
is_txt = False
new_txt = ""
for st in split_txt[1:] :
print(new_txt," , ",st)
#グラフという単語があればその文章を抽出
if "グラフ" in st :
tokens = make_token(st)
for i in range(len(tokens)) :
if i + 1 < len(tokens) - 1 :
if "グラフ" in tokens[i+1].surface :
#動詞を「描く」に統一
new_txt += tokens[i].surface + "グラフを描く。"
is_txt = True
print("グラフ関連文章 : ",new_txt)
break
else :
new_txt += tokens[i].surface
else :
new_txt += tokens[i].surface + "。"
break
#出力作業プリグラム指示文の抽出
elif "出力" in st :
new_txt += st
print("出力関連文章 : ",new_txt)
is_txt = True
break
#それ以外のプログラム指示文の抽出
else :
new_txt += st + "。"
print("グラフ・出力関連以外文章 : ",new_txt)
if is_txt :
break
#final_sentence_lists : クラスタリング用文章リスト
final_sentence_lists.append(new_txt)
ここで、make_token関数は、以下の関数です。
def make_token(txt) :
#形態素解析
t = Tokenizer()
tokens = list(t.tokenize(txt))
token_lists = [token for token in tokens]
return token_lists
それでは、上記結果を基に、具体的にはfinal_sentence_listsの文章を使って、クラスタリングを実施します。
文章クラスタリングの実装と評価
final_sentence_listsをtransformerで数値ベクトル化し、UMAPで次元削減し、k-meansでクラスタリングしていきます。実際の実装は前記事のSTEP1~STEP3を参考にしてください。今回は、UMAPの次元は3で、距離測定の変数metricは、ユークリッド距離(euclidean)を使用しました。
UMAPの次元削減
umap_programtxt = umap.UMAP(n_components=3,random_state=42,metric="euclidean").fit(X_scaled)
#X_scaled : final_sentence_listsを数値ベクトル化し、[0,1]の正規化したもの
#DataFrame作成
df_program = pd.DataFrame(umap_programtxt.embedding_, columns=["X","Y","Z"])
また、k-meansでSSEを測定した結果、クラスターが4つが良さそうな結果が得られることが分かりました。
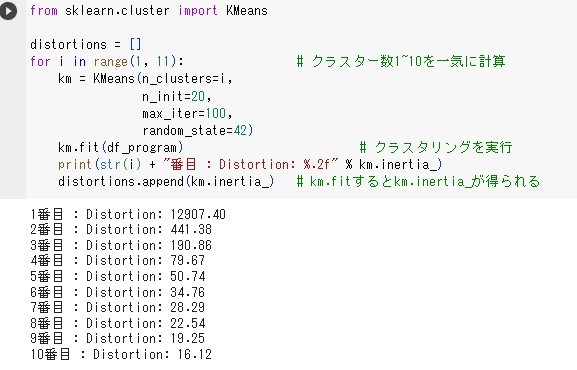
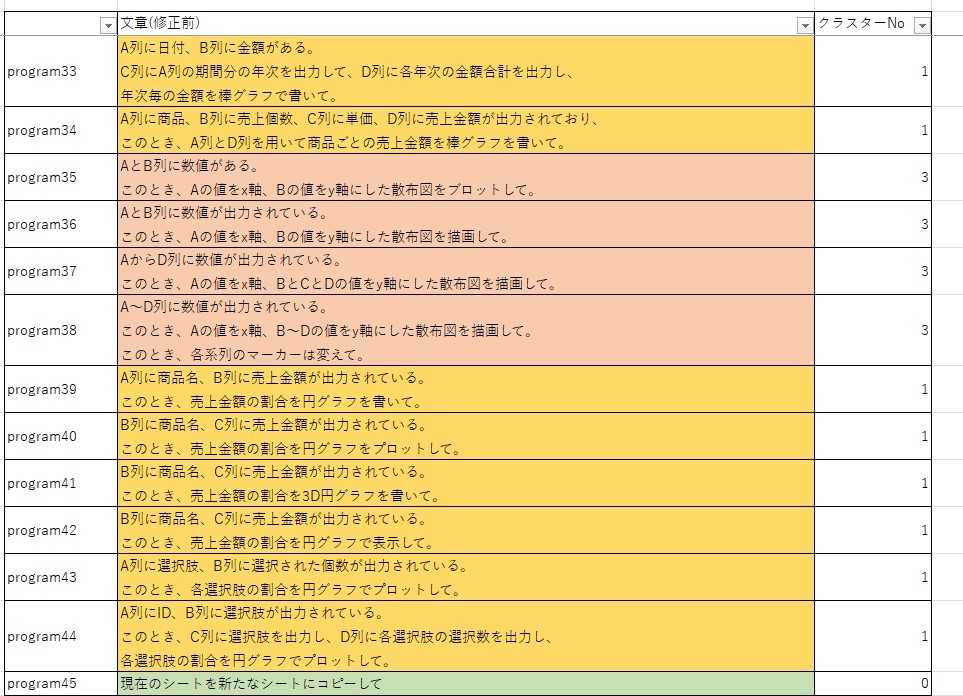
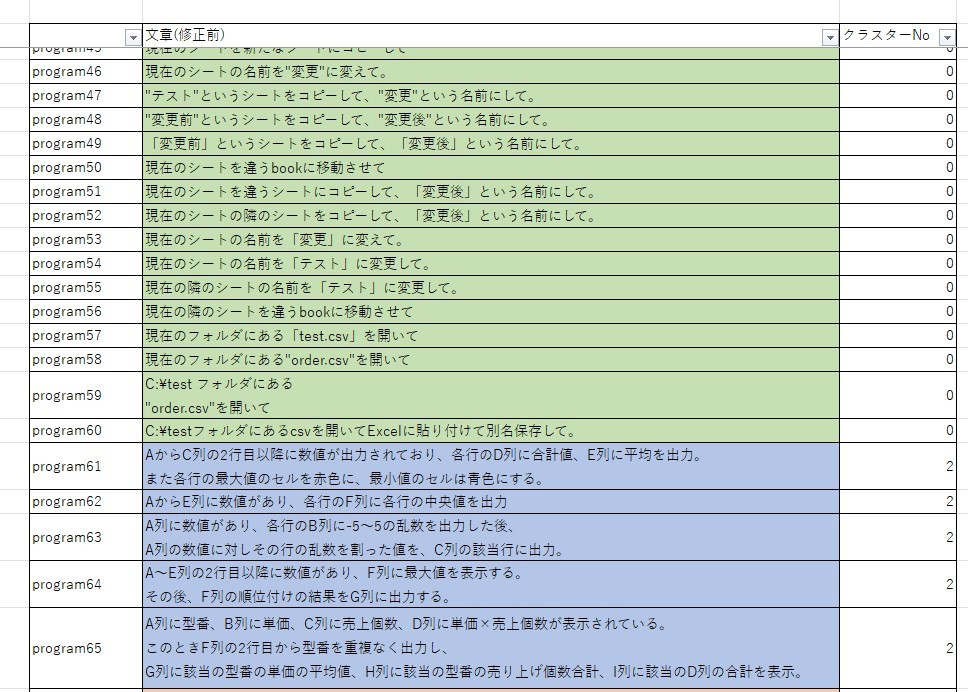
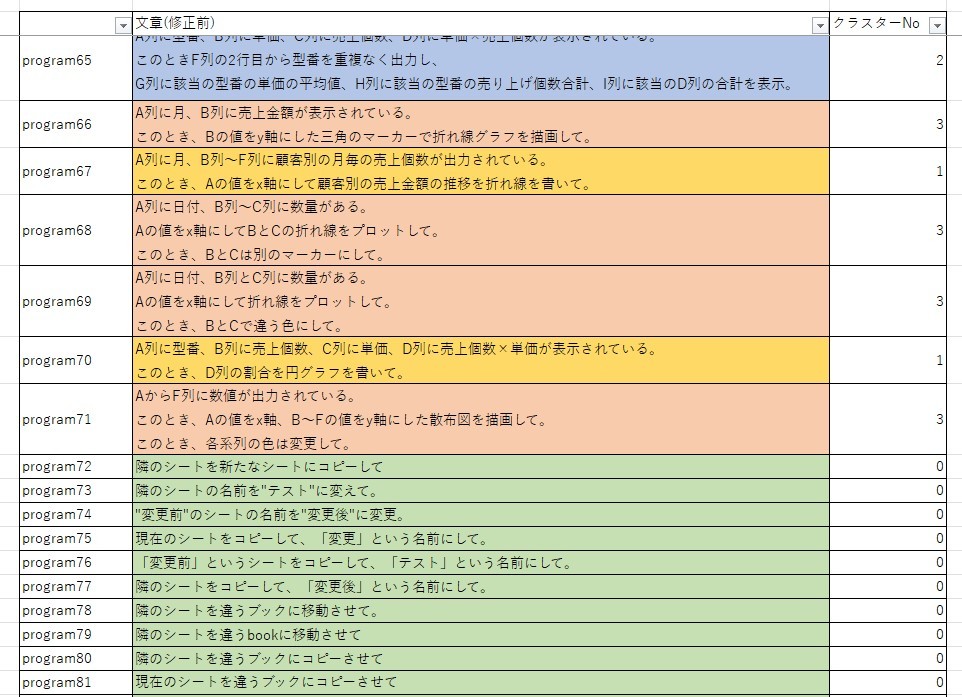
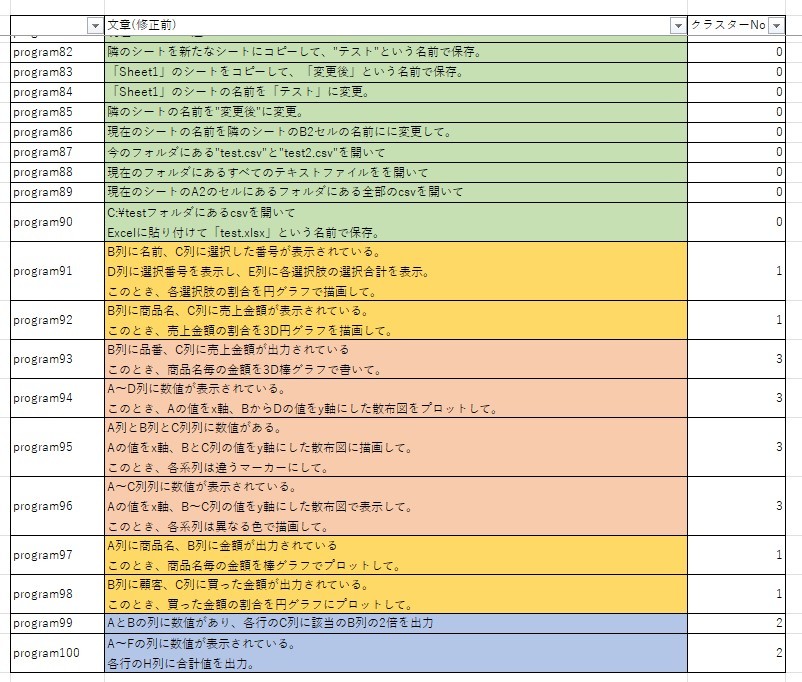
そこで、実際に4つのクラスターで分類してみました。すると、画像のように
グラフ描画のプログラム指示文において、円グラフや棒グラフのグラフ描画 (クラスターNo 1)、および、折れ線や散布図のグラフの描画 (クラスターNo 3)の2つに分割されていることが分かります。
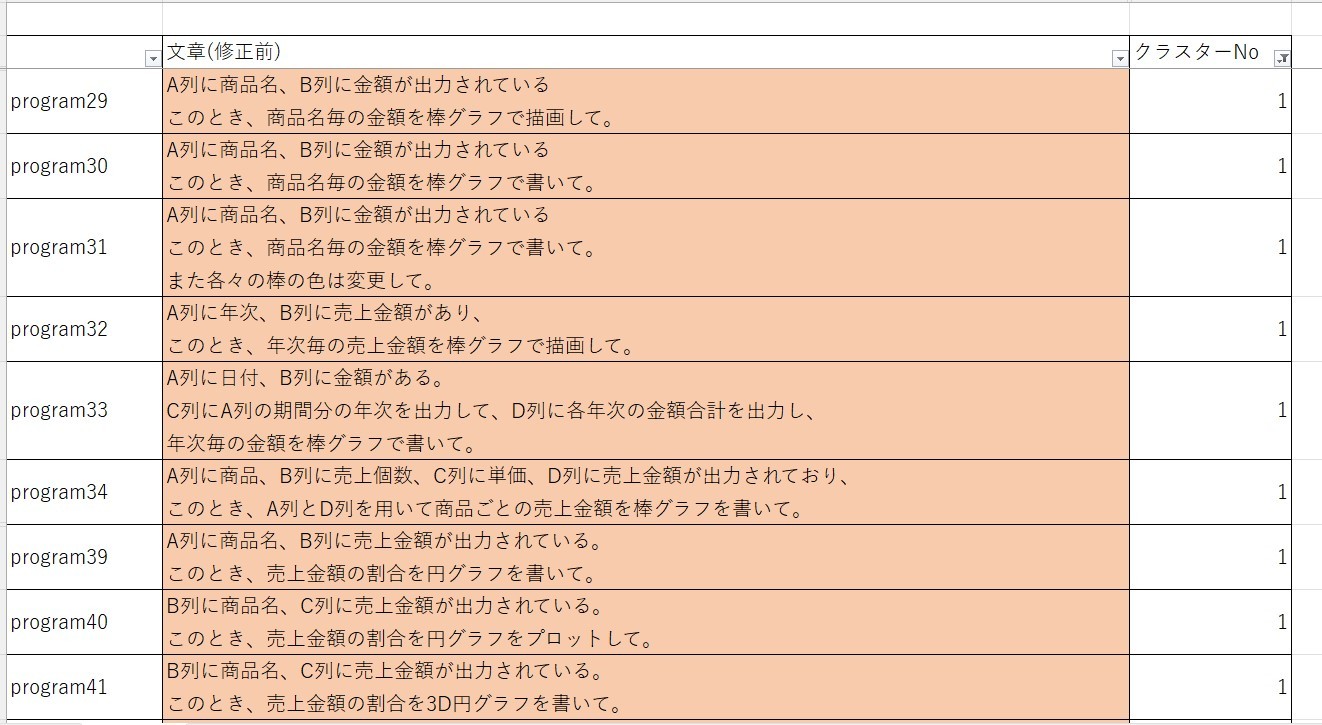
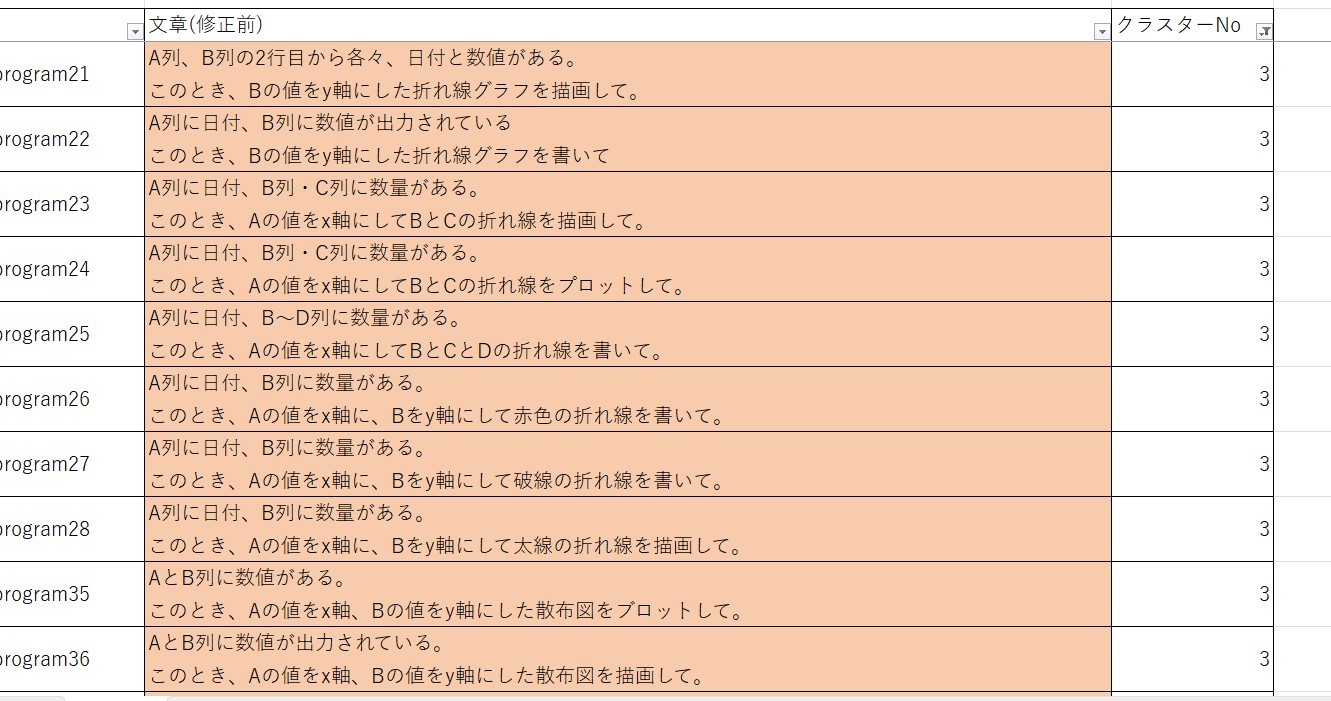
これは、数量・金額・割合が重要となるグラフである円グラフや棒グラフと、x軸・y軸が重要となる折れ線や散布図の違いによるものであると考えられます。したがって、年次ごとの金額の推移を折れ線グラフで描くというように、折れ線は描画するものの、軸の設定をしない文章の場合どのクラスターになるかは今後確認する必要があると考えています。
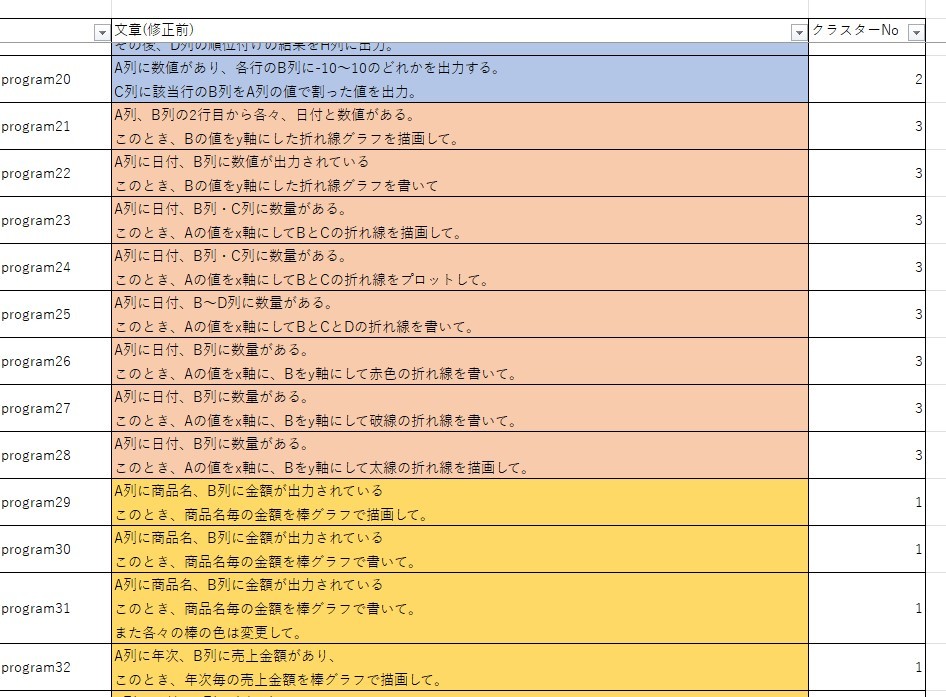
その他のクラスタリングは以下のようになります。


本記事のまとめ、および、次記事の予定
本記事では、機械翻訳、および、述語などの単語の言い換えのための正規化方法を実装しました。その後、正規化後の文章をtransformerを用いてクラスタリングを実施しました。その結果、以前の記事よりクラスタリングの精度を向上させることができました。しかしながら、前節でも述べた通り、例えば折れ線グラフの描画は軸の説明をしない文章にすることができるので、そのような言い換え文も考えていきたいです。また、グラフ描画と計算や比較結果の出力作業を組み合わせてある文章も存在すると考えられるので、そのような文章への対応を考えていきたいです。その後、文章とプログラムコードの関係性を整理することが今後の課題だと考えています。
参考文献
○私の記事
○その他の参考記事
○参考論文
Discussion