Transformerを用いた文章のクラスタリング
前記事のまとめ、および、本記事の目的
前記事では、ChatGPTのAPIキーを用いて、指示文を与えることでプログラムを作成可能なのかを確認しました。その結果、下記のような指示文を与えたら、以下のプログラムを作成できました。


このようにAPIを用いることでコメント文を記載しつつ、コーディング可能であることが分かります。ChatGPTは、2023/4/6時点で1000トークンで0.002ドルとかなり安いです。しかしながら、エラーのない正しいプログラムを書くためには、慣れるまで何回もやり直す必要があり、気が付いたら支払金額が多くなるという可能性があります。
そこで、指示文と今までできたプログラムの類似性を判断し、類似のプログラムを検索できるようなシステムを構築できれば、既に存在しているプログラムの中で適切なプログラムを抽出し、コメント文を見つつ微修正をすることで、正しいプログラムを作成できます。これにより、APIの使用頻度を少なくし、支払金額を低くすることができます。
上記のようなシステムを構築にあたり、プログラムの指示文の学習と実際のプログラムとの類似性の整理(参考論文1、参考論文2)が必要だと考えています。そのために、まずプログラムの指示文の類似性を判断してクラスタリングを実施します。続いて、そのクラスターの中で、与えられた指示文と最も類似した指示文のプログラムを抽出することで、最適なプログラムが出力できると考えています。
本記事では、最初のステップとして、プログラムの指示文の類似性を判断する方法を考えていきます。今回は自然言語を処理するのに適した、Transformerを用いたプログラムの指示文のクラスタリングの実装をしていきたいと思います。
Transformerとは
Transformerは、2017年にGoogleから発表されそれ以降自然言語処理の分野で多く使用されるようになりました。
自然言語データは文脈を考慮した上で単語の関係を保持しておく必要があります、このようなタスクに対する処理では、入力系列から取得する情報を隠れ状態(hidden state)という数値表現に変換し、変換した情報を後続に渡す処理を実施していきます。このとき、全ての表現を圧縮して渡すため、系列の最初の方の情報が失われることがありました。これを解消するために、アテンション(attention)と呼ばれる方法が転用されており、自然言語処理で使われているRNNでも用いられている考え方になります。
アテンションは、入力系列に対し単一の隠れ状態を出力する一方で、各時刻で隠れ状態を出力させます。その際に時刻ごとの重みづけを実施し、入力単語と文脈の関連性を把握可能にしました。しかしながら、この方法は単語ごとに順を追って計算をする都合上、計算の並列化は困難となり、学習時間がかかってしまうという問題がありました。そこで、文脈を考慮できる特性を持ちつつ、並列化に向いたモジュールを構築させる方法をTransformerでは適用しました。その結果学習データ数を多くすることができ精度が向上しました。詳しくは、原著論文や、こちらの解説記事をご覧ください。
このモジュールの肝になっているのが、Self-Attentionです。これは学習を実施するニューラルネットワークの同一層の全ての状態に対してアテンションを算出していくものです。具体的には、入力文章をモデルで用いる最小単位に分割し(トークン化)、トークンエンコーディングと呼ばれるone-hotベクトルを出力します(one-hotベクトルとは)。そうして表現されたベクトルに対して、文章全体を用いアテンションの重みづけを決定していきます。文章全体に重みづけを行うことで、文脈による単語の意味合いを判断することを可能としました。例えば英語だと、動詞・名詞で意味の異なる単語に対して、文脈を考慮することでどちらの意味が正しいかを判断できます。
では実際に実装をしていきたいと思います。実装は、書籍1や書籍2やこちらの記事などを参考に作成しました。
実装環境と学習対象
- 実装環境 : Google Colaboratory
- 学習対象 : プログラム指示文に該当する文章100文
Excelで用いられているプログラミング言語であるvbaのプログラムを作成すると考えています。そこで、文章は項目名や動詞の変更に加え、列の場所・色・シート名・フォルダ名に関わる部分に変更加えた文章を100文用意しました。
今回のプログラム指示文は主に3種類の指示に分かれています。 - 計算や比較結果の出力 : 何かしらの規則を基に計算や比較を実施。それをExcel上に表示
- グラフ描画 : Excelシートの値を基にグラフの描画
- Excel操作 : シート名の編集やコピー等のExcel操作
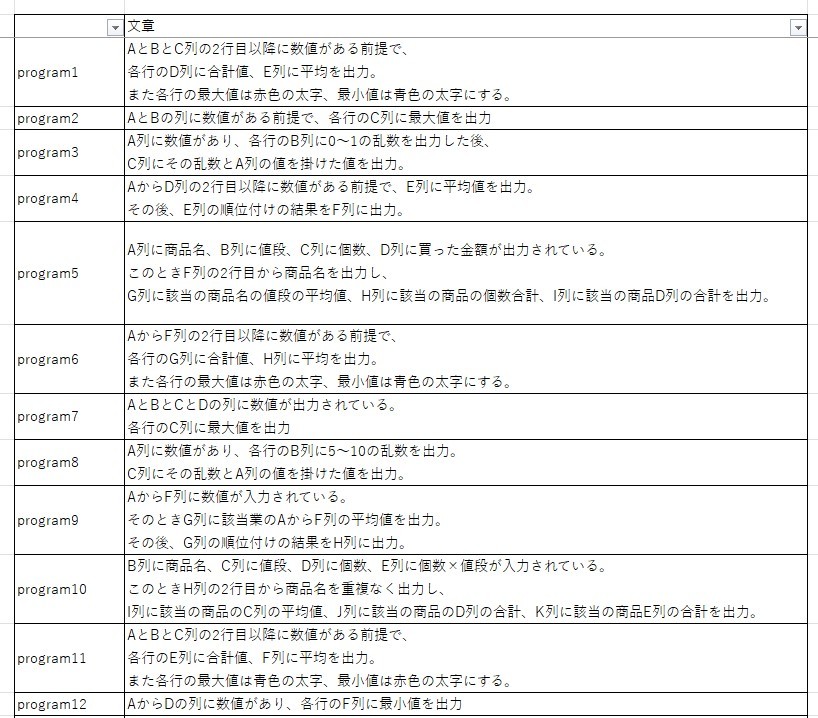
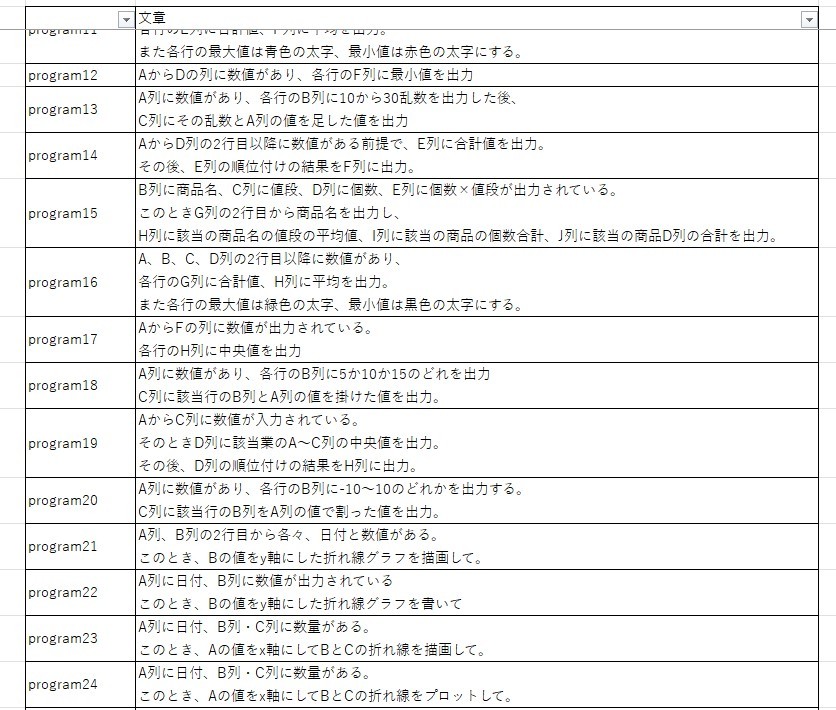

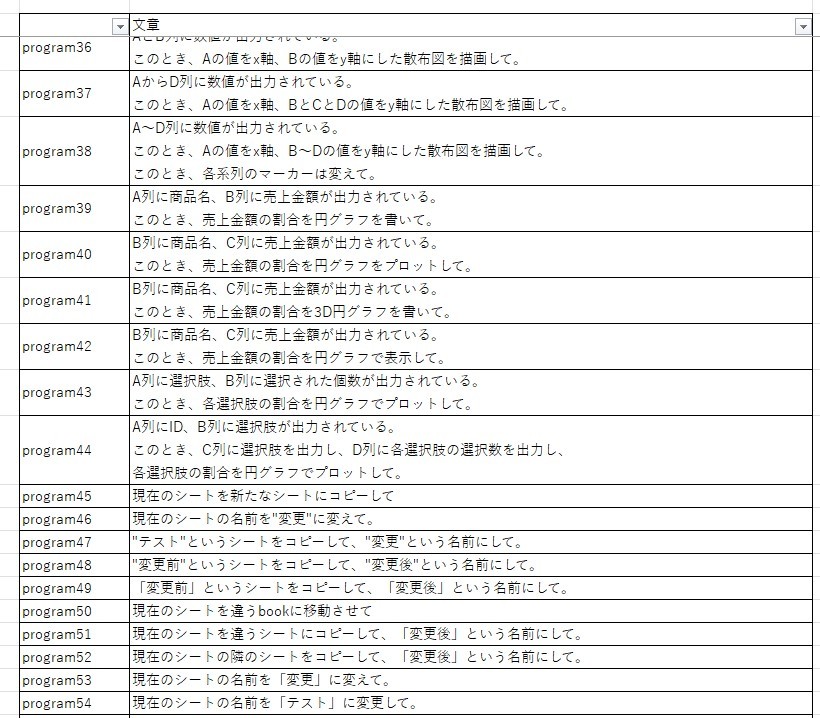

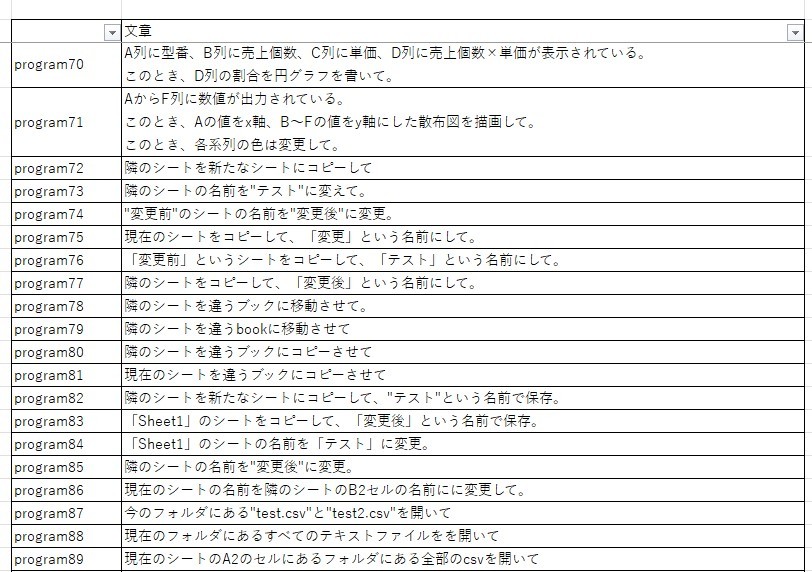

実装手順
Transformerを用いて文章をクラスタリングする手順は以下の通りです。
- STEP1 : 文章の正規化
文章を決められた基準で修正していきます。これにより、表記ゆれの修正・文字の統一化をして、類似の内容を同一単語として処理することが可能になります。 - STEP2 : サブトークン化
トークン化には、文字トークン化と単語トークン化の2種類の方法の方法があります。文字トークン化は、文字列全体からスペルミスや珍しい単語の処理に役立ちますが、単語の言語構造を学習する必要があり、膨大な計算時間やメモリが必要になります。単語トークン化は、単語毎に分割しトークン化する方法のため、文字から単語を学習する必要はなくなる一方、語形変化やスペルミス対応するために、語彙数が増えメモリが膨大になる欠点があります。
これらの問題を解決し双方の良い点を組み合わせた方法がサブトークン化です。珍しい単語やスペルミスに対応できるように単語を小さい単位に分割しつつ、頻出単語を一意に管理することで、メモリが膨大になることを防ぎます。 - STEP3 : 文章の分類
最後に各文章に対する隠れ状態を抽出していきます。そして隠れ状態を学習する際の特徴ベクトルを定義し、クラスタリングを実施していきます。
STEP1 : 文章の正規化
ここでは文章の正規化をします。今回は以下の正規化を実施します。
- スペース・タブ・改行はなくす
- “文字”や「文字」は、「xxxx」にする
- (任意の英字)+任意の文字+列は、xxxx列にする
import os
from google.colab import drive
import re
#ファイルパスの取得
drive.mount('/content/drive')
file_path = "/content/drive/MyDrive/statemment/"
#ファイルテキスト名取得
file_dir = os.listdir(file_path)
#re_programtxt_list : 正規化後文章リスト
re_programtxt_list = []
for file in file_dir:
program_file = file_path + file
with open(program_file,"r") as f :
#テキスト内容の正規化
#スペース・タブ・改行の削除
re_program = re.sub(r'[\s\t\n]','',f.read()))
# “”や「」でくくっている文字を「xxxx」に変更
re_program = re.sub(r'".*?"','「xxxx」',re_program)
re_program = re.sub(r'「.*?」','「xxxx」',re_program)
#英字+列の変更
re_program = re.sub(r'[a-zA-Z].*列','xxxx列',re_program)
#文字リストに追加
re_programtxt_list.append(re_program)
その結果、各指示文は以下のように正規化されます。

STEP2 : サブトークン化
続いて各文章に対するサブトークン化を実施していきます。最初にこれから必要になるライブラリをインストールします。
!pip install transformers
!pip install dependencies
!pip install fugashi
!pip install ipadic
transformersライブラリには日本語に対応した事前学習済みモデルによるトークナイザーがあり、以下のようにロードできます。
from transformers imporvocabraryt BertJapaneseTokenizer
#事前学習済みモデルのロード
model_name = 'cl-tohoku/bert-base-japanese-whole-word-masking'
tokenizer = BertJapaneseTokenizer.from_pretrained(model_name)
辞書の中身は以下のようになります。
tokenizer.vocab

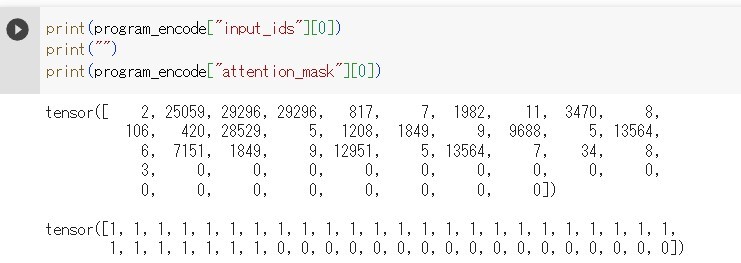
次に与えられた文章から隠れ状態を抽出するために文字列をテンソル型の数値の配列で出力します。出力内容は上記辞書を用いた単語(語彙)の数値列であるinput_idsと、クラスタリングの際に用いるトークン部分を「1」、無視するトークン部分を「0」にした配列であるattention_maskの2つの要素があります。また配列でを同一の長さにすることにより、文字数が違う指示文に対する比較を可能としています。
from transformers import AutoModel
#文章のトークン化関数
def tokenize(text) :
return tokenizer(text,
padding=True,
truncation=True,
return_tensors="pt")
#事前学習済みモデルの使用
model = AutoModel.from_pretrained(model_name)
#文章のトークンをエンコーディングしてテンソル型の配列にする
program_encode = tokenize(re_programtxt_list)
#出力例
print(program_encode["input_ids"][0])
print("")
print(program_encode["attention_mask"][0])
例えばinput_idsを見ると、「また」が辞書で106に、「各」が420になっていることが分かります。
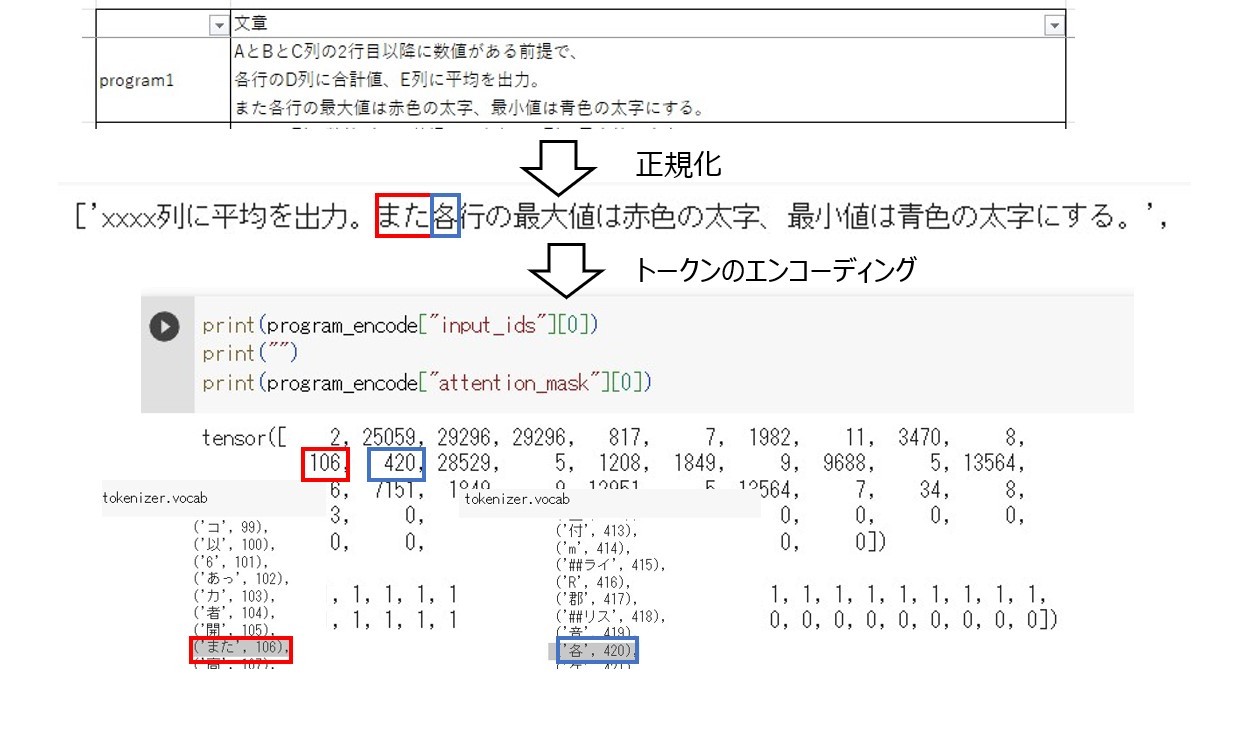
また、配列の長さに関しては、proguram1の正規化後の文章を数値化した文章分attention_maskに「1」が付与されており、それ以降は同じ数「0」詰めされていることが分かります。
これが各文章のサブトークン化の実装部分になります。
STEP3 : 文章の分類
まず隠れ層を格納します。以下のように格納できます。
import torch
#PyTorchによるGPUの利用可能判断
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
input = {k:v.to(device) for k,v in program_encode.items()}
#最後の隠れ状態を含んだテンソル配列の格納
with torch.no_grad():
outputs = model(**input)
#最後の隠れ状態の格納
last_hidden_state = outputs.last_hidden_state

それでは実際にクラスタリングを実施していきます。今回はUMAPによる次元削減を実施していきます。UMAPはt-SNEより高性能な次元削減方法です。UMAPは高次元データを各点の位置関係等の構造を維持しつつ、低次元データに変換する方法です。UMAPの仕組みについては、こちらの解説記事やこちらの動画を参考にしてください。
インストールと実装は以下のようになります。
!pip install umap-learn
from umap import umap_ as umap
from sklearn.preprocessing import MinMaxScaler
import numpy as np
#隠れ層の格納
lhs_array = np.array(last_hidden_state[:,0])
#[0,1]区間のスケール
X_scaled = MinMaxScaler().fit_transform(lhs_array)
#UMAPの次元削減
umap_programtxt = umap.UMAP(n_components=2,random_state=42,metric="cosine").fit(X_scaled)
#DataFrame作成
df_program = pd.DataFrame(umap_programtxt.embedding_, columns=["X","Y"])
次元削減した後の次元数は、n_componentsで指定できます。また、次元数に応じて、データフレームdf_programのcolumnsの列数は適宜変更してください。今回は次元数を2~5までで最適な次元数をエルボー法で考えていきます。結果は以下の通りです。なおクラスタリングはk-means法を用いて実施しています。
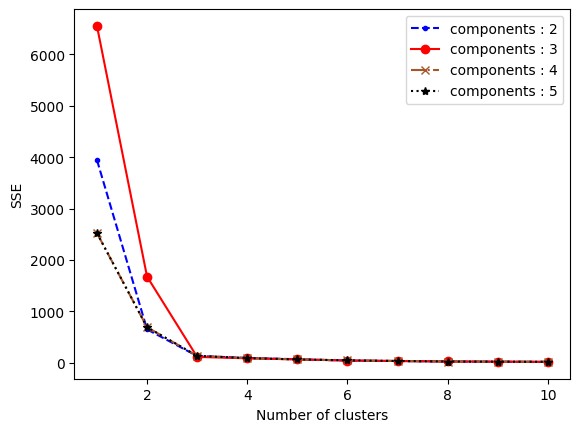
上図より最適なクラスター数は「3」であることが分かりますが、どの次元数が良いかが分かりにくいので、クラスター数が3以上でもう一度図を描画します。

したがって、最適な次元数とクラスター数はともに3です。この結果を基にクラスタリングをすると、結果は以下のようになります。なお、参考までに各次元数のクラスタリング結果も載せています。
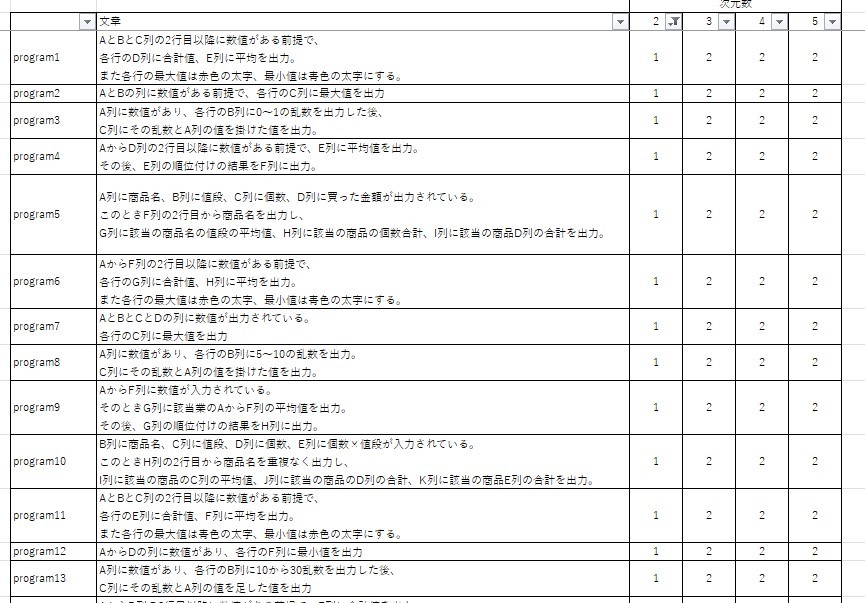
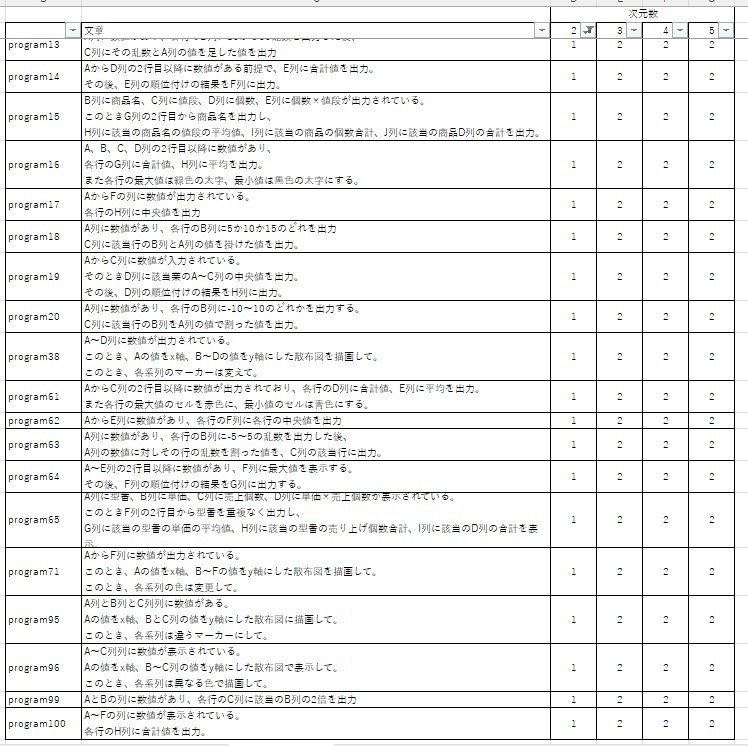

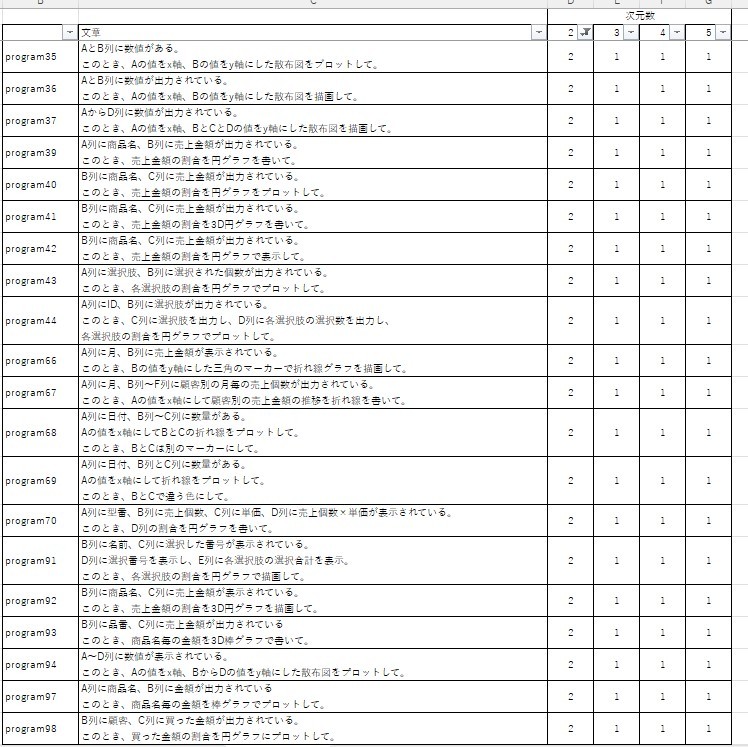

これらの表より、実装環境と学習対象の節で説明した指示の種類(計算や比較結果の出力・グラフ描画・Excel操作)の通り、ほぼクラスタリングできていることが分かります(次元数2はクラスター番号自体は違うものの、分類しているもの自体は同じです)
しかしながら、一部の指示において、計算や比較結果の出力のクラスターにグラフ描画の指示文が混ざっていることが分かります。このことから、正規化の方法を見直す必要性があることが分かります。
まとめ
本記事では、プログラムの指示文の類似性を判断する方法として、Transformerを用いた文章のクラスタリングを実装していきました。結果として、ほぼ指示文の種類通りにクラスタリングができることが分かりました。これにより正規化の方法を再度見直す必要性があります。また上手くいった正規化においても、
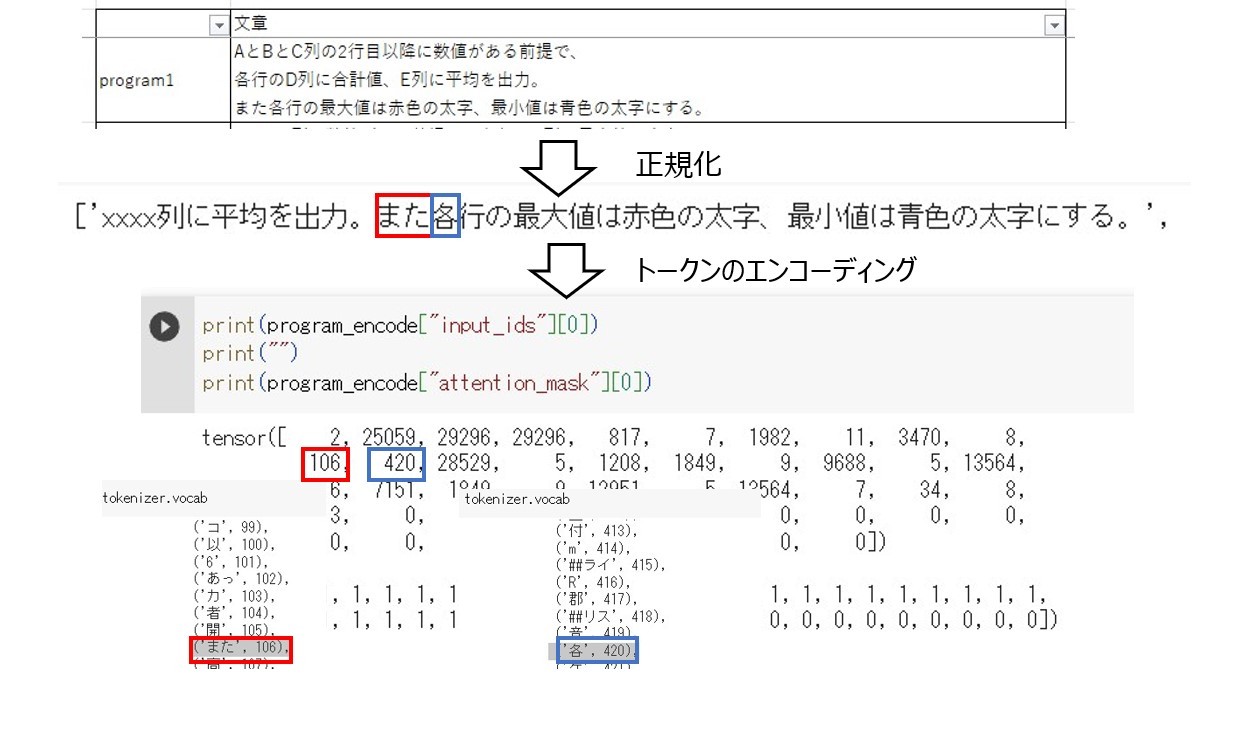
「AとBとC列の2行目以降に数値がある前提で、各行のD列に合計値、E列」を「xxxx列」と修正したように、列に関する修正をするときに文章の情報を圧縮しすぎた可能性があります。その結果、後続の処理である、指示文同士の類似度を測るときに上手くいかない可能性があります。このことを念頭に置き、指示文同士の類似度測定と適切なプログラム抽出を次記事では行っていきたいです。
参考文献
〇本記事目的の節での参考論文
矢嶋梨穂ら、ファイル操作に対する自然言語の指示文の学習、2020
小田悠介ら、プログラム間の類似性の定量化手法、2013
〇Transformer解説と実装
Ashish Vaswaniら、Attention Is All You Need、2017
RNNからTransformerまでの歴史を辿る ~DNNを使ったNLPを浅く広く勉強~
one-hot ベクトル [ディープラーニングの文脈で]
機械学習エンジニアのためのTransformers ―最先端の自然言語処理ライブラリによるモデル開発
つくりながら学ぶ!PyTorchによる発展ディープラーニング
Hugging Face Courseで学ぶ自然言語処理とTransformer 【part3】
Hugging Face Courseで学ぶ自然言語処理とTransformer 【part4】
Hugging Face Courseで学ぶ自然言語処理とTransformer 【part5】
t-SNEより強いUMAPを(工学的に)理解したい
UMAP Dimension Reduction, Main Ideas!!!
Discussion