Hugging Face Courseで学ぶ自然言語処理とTransformer 【part5】
はじめに
この記事ではHugging Face CourseのTokenizersあたりの内容をベースに、テキストのトークン化の役割を担うTokenizerについてまとめています。
一個前の記事はこちら
コードの実行は今回もGoogle Colabで行う例になります。
Tokenizer
part3でも触れたように、Tokenizerの役割はテキストデータを言語処理モデルに合った入力形式に変換することでした。
モデルは数値データしか扱えないので、テキストのままでは入力できません。
そのためテキストに対して以下のような処理を実施し、数値データへ変換します。
- テキストを単語、サブワード、記号などのモデルにとって意味をなすであろう最小の単位(トークンと呼ばれる)に区切る。
- ぞれぞれのトークンにIDを振る。
- モデルの入力に必要な情報となるスペシャルトークンを入力テキストに追加する。
では実際にテキストからトークンを作る方法にはどのようなものがあるでしょうか。
単語ベースでのトークン化
トークン化の方法で最もシンプルで直感的なのは、単語ごとに分割する方法です。
英語のテキストの場合は単語ごとにスペースで区切られているのが一般的ですね。
The quick brown fox jumps overt the lazy dog.
なので、Pythonのstr.split()メソッドなどを使えば、とりあえず単語ごとに区切るのは簡単そうです。
単語ごとに区切れば、あとはそれぞれにIDを振ってやればトークンとしてひとまず完成です。
text = "The quick brown fox jumps over the lazy dog."
words = text.split()
tokens = {word:i for i, word in enumerate(words)}
print(tokens)
出力結果
{'The': 0, 'quick': 1, 'brown': 2, 'fox': 3, 'jumps': 4, 'over': 5, 'the': 6, 'lazy': 7, 'dog.': 8}
ですが、これでは句読点の扱いや文法による単語形態の変化などカバーし切れていない要素がたくさんありそうですね。
上の例だとTheとtheは実際は同じ単語ですが別のトークン扱いになってしまいます。
また、jumpやjumpingなどの同じ単語の形態違いが別のテキストで出てきた場合もそれぞれ別のトークンとなってしまい、こうなっていると学習前のモデルにとってはそれぞれ異なる意味を表す単語として認識されるため、学習効率や性能も悪くなりそうです。
また日本語のように文中の単語が特に意味のある記号で区切られているわけではない言語もあり、英語と同様の区切り方が通用しないものも多くあります。
未知語の扱い
トークンは基本的には学習用のテキストデータからその辞書が得られますが、いくつか追加で特別なトークンを用意する必要もあります。
例えばトークンの辞書に含まれない単語が出てきたとき、それは未知語として扱う必要があります。
よく"[UNK]"や""で表されます。
この未知語ですが、要するに"モデル学習時には出てこなかったトークン"であり、それらの意味についてはモデルは学習できていないことになるので、実際にテキストをトークン化した結果の中にはあまり含まれないのが望ましいと言えます。
実際の応用の場面では学習データに含まれない単語や環境や時代に応じて新たに作られたり変化する単語などもあるわけで、未知語を完全に無くすというのは難しいですが、それでも学習モデルの性能を上げるにはなるべく減らす努力をする必要があります。
文字ベースでのトークン化
未知語が現れないような方法の一つに、文字ベースでのトークン化があります。
文字1個1個をトークンとして扱ってやろうということで、ある意味究極のトークン化とも言えるのではないでしょうか?
愚直にやると以下のような感じでしょうか。
text = "The quick brown fox jumps over the lazy dog."
chars = [c for c in text] # 文字単位で分ける
chars = set(chars) # setにして重複を除く
tokens = {char:i for i, char in enumerate(chars)}
print(tokens)
出力結果
{'q': 0, 'c': 1, ' ': 2, 'u': 3, 'r': 4, 'i': 5, 'h': 6, 'f': 7, 'x': 8, 'b': 9, 'y': 10, 'n': 11, 's': 12, 'o': 13, 'z': 14, 'm': 15, 'v': 16, 'w': 17, 'p': 18, 'a': 19, 'd': 20, 'l': 21, 't': 22, '.': 23, 'T': 24, 'g': 25, 'e': 26, 'j': 27, 'k': 28}
あらゆる単語は既に言語の中で確立されている文字の組み合わせで作られているはずなので、文字ベースでトークン化することによって未知語が出現する可能性を限りなく0に近づけることができます。(未知語として扱われる可能性がありそうなのは、新しい絵文字などでしょうか。)
また、辞書に含まれるトークンの種類(語彙数)が少なくなるというメリットもあります。
モデルは辞書に含まれるトークンの数だけ高次元ベクトルの意味表現を学習するので、トークンの種類が少ないほどそのサイズが小さくなり軽量になるというメリットに繋がるわけですね。
一方で文字単位で区切ると情報が失われすぎてしまうという欠点があります。
中国語のように漢字一文字に意味情報が含まれる言語は文字単位で区切っても問題なさそうですが、英語のアルファベットや日本語のかな文字のように一文字だけでは多くの意味を持たない言語に関しては文字ベースのトークン化は有効でないかもしれません。
また単語ベースに比べて文字ベースでトークン化すると、一つのテキストに対するトークンの数は何倍にもなってしまい、モデルが入力に対して処理する必要のあるデータの大きさが増すという欠点もあります。
サブワードによるトークン化
単語ベースと文字ベース、それぞれの長所と短所をまとめると以下のようになります。
| 長所 | 短所 | |
|---|---|---|
| 単語ベース | 直感的にそれぞれ意味を持つ単語ごとにトークンを作ることができる。 | トークンの辞書が膨大になる上、未知語に出会す可能性も高い。 |
| 文字ベース | トークンの辞書の大きさを抑えられ、未知語に出会す確率も下げられる。 | 情報の損失リスクや、テキストあたりのトークン数の増加などの問題がある。 |
ここからわかるのは、
- トークンごとの情報量をできるだけ保持する。
- トークンの辞書の大きさはできるだけ抑える。
の2点がトレードオフになっているという点です。
この2点をバランスよく満たすために考えられた方法の一つがサブワードによるトークン化です。
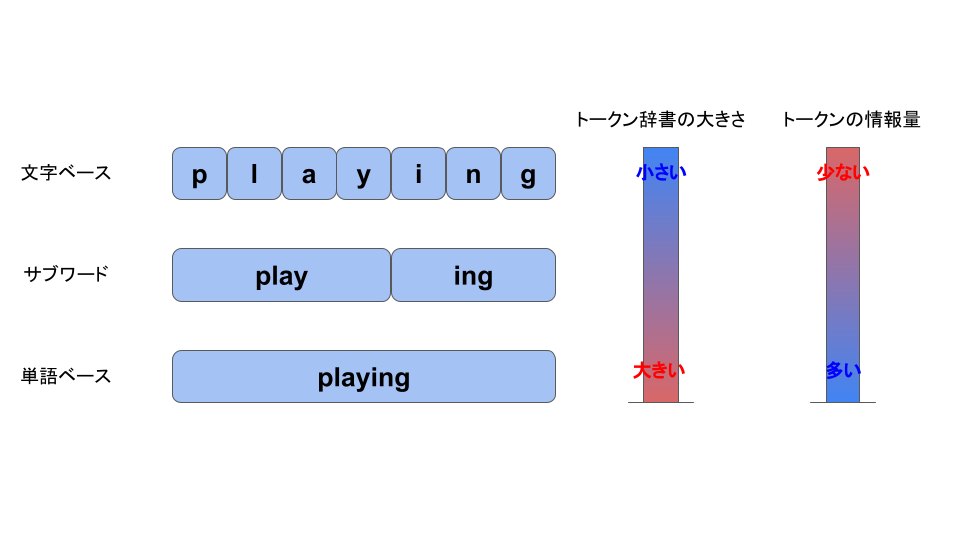
サブワードによるトークン化では、テキストに含まれる単語に対して、単語本体と接頭辞や接尾辞といった部分に分けるということをしています。
例えばplayingという単語はplayと##ingという風に単語本体と接尾辞に分け、「遊ぶ」という単語そのものの意味と「〜している」という現在進行形の意味に分けて解釈しているという感じです。##という記号は接尾辞、接頭辞の直前または直後にくっつく文字列の部分を表すワイルドカード的な意味で用いられています。
このようにするとどういう効果があるでしょうか。
例えば学習用のテキストデータにplay, run, walk, swim, playing, running, walkingという単語があったとします。
単語ベースで分割する場合はトークンの辞書としては
[play, run, walk, swim, playing, running, walking]
となり7個のトークンを含むことになります。
一方サブワードによる分割だと、
[play, run, walk, swim, ##ing]
という形になり、5個に減らすことができます。
また新しく入力するテキストに学習用データにはなかったswimmingが出てきたとしても、[swim, ##ing]というトークンに分けられるので、未知のトークン扱いにならずに済みます。
...といった具合で、サブワードによる分割はトークンごとの情報量もある程度保持しつつ辞書の大きさも抑えられ、未知語対策としてもそれなりに期待できるということがわかりますね。
ここで一つポイントとなるのが、どの単語に対してもこのルールを適用するわけではないという点です。
サブワードによるトークン化では、学習用のテキストデータの中で出現頻度の高いものは接尾辞や接頭辞の分解は行わないという原則があります。
分割できるところは分割する方針ではあるものの、出現頻度が高い単語に関しては、それを分解して全体のトークン数を増やすよりは、一つのトークンとして扱った方が効率が良くなるということです。
そして単語の出現頻度を考慮するという点からもわかるように、サブワードによるトークン分割の結果はデータセットから学習によって得られる形になります。
学習済みのTokenizerを使う
学習済みモデルの場合と同じような感覚で、AutoTokenizerクラスを使いcheckpointを指定することで使いたいtokenizerを読み込むことができます。
from transformers import AutoTokenizer
checkpoint = "bert-base-cased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
text = "The quick brown fox jumps over the lazy dog."
print(tokenizer(text))
出力結果
{
'input_ids': [101, 1109, 3613, 3058, 17594, 15457, 1166, 1204, 1103, 16688, 3676, 119, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
}
Encoding
テキストをトークンごとのIDに変換する部分だけやると以下のようになります。
- まずはトークンごとに分割
tokens = tokenizer.tokenize(text)
print(tokens)
['The', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog', '.']
- 次にトークンをIDに変換
ids = tokenizer.convert_tokens_to_ids(tokens)
print(ids)
[1109, 3613, 3058, 17594, 15457, 1166, 1103, 16688, 3676, 119]
上記の処理はencodeメソッドだけでもできますが、こちらの場合はモデルの学習のために用意されているスペシャルトークンのIDも含まれた形で変換されます。
ids = tokenizer.encode(text)
print(ids)
[101, 1109, 3613, 3058, 17594, 15457, 1166, 1103, 16688, 3676, 119, 102]
先頭の101は[CLS]というBERTモデルで文頭を示すトークンを指し、最後の102は[SEP]という文の区切りを表すトークンを指しています。
Decoding
IDからテキストへの変換は下記のように行います。
decoded_string = tokenizer.decode(ids)
print(decoded_string)
The quick brown fox jumps over the lazy dog.
スペシャルトークンなどは自動で除去してくれるので、推論結果の出力を行う際に活用しやすい形になっています。
サブワードによるTokenizerを作ってみる
学習済みのTokenizerがそのまま使えればそれに越したことはありませんが、場合によっては手元にあるデータセットに対して最適なトークン化をしてくれるようなものを自身で用意することも考えられます。特に専門的な用語が多く含まれるテキストを対象にしたケースなどでは、学習済みのものをそのまま使うより効果的であると考えられます。
サブワードによるトークン分割の代表的な手法として以下のようなものがあります。
ここでは公式のチュートリアル[4]を参考に、BERTでも使用されているWordPieceを使ってTokenizerを一から作り、学習済みのものを使った結果と比較してみたいと思います。
Hugging Faceが提供するtokenizersライブラリを使用します。
!pip install tokenizers
使うデータセットを用意します。今回は無料で手に入り、サイズ的にも手頃なwikitext-103を使います。
!wget https://s3.amazonaws.com/research.metamind.io/wikitext/wikitext-103-raw-v1.zip
!unzip wikitext-103-raw-v1.zip
from tokenizers import Tokenizer
from tokenizers.models import WordPiece
from tokenizers.pre_tokenizers import Whitespace
from tokenizers.trainers import WordPieceTrainer
# BPE tokenizerのインスタンスを作成
tokenizer = Tokenizer(WordPiece(unk_token="[UNK]"))
# スペース区切りで得られる単語をベースとなるトークンとする
tokenizer.pre_tokenizer = Whitespace()
# 学習器のインスタンスを用意
# 辞書に含めたいスペシャルトークンもここで指定する。
trainer = WordPieceTrainer(
special_tokens = [
"[UNK]",
"[CLS]",
"[SEP]",
"[PAD]",
"[MASK]"
]
)
# 学習用データの指定
files = [
f"./wikitext-103-raw/wiki.{split}.raw" for split in ["test", "train", "valid"]
]
# 学習処理を走らせる
tokenizer.train(files, trainer)
Colaboratoryだと数十秒程度で学習が終わり、tokenizerが完成します。
辞書の中身を見てみると以下のようになりました。
tokenizer.get_vocab()
{'##appers': 26951,
'br': 9301,
'##etw': 9103,
'screenplay': 19537,
'Springfield': 19955,
'̣': 472,
'monastic': 29136,
'К': 579,
'contemporary': 13037,
'alone': 12980,
'sequ': 11011,
'jurisd': 17834,
'##itorium': 29883,
'᾿': 1673,
'implemented': 19066,
'Sant': 12878,
'裝': 4135,
...
wikitext-103には色々な言語が含まれているのか、漢字も辞書の中に含まれていますね。
テキストをトークン化すると以下のようになります。
text = "The quick brown fox jumps over the lazy dog."
output = tokenizer.encode(text)
print(output.tokens)
['The', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'la', '##zy', 'dog', '.']
BERTのcheckpointから読み込んだ場合とはlazyという単語の分割が違う結果になっていますね。
学習データが変われば作られるトークンの辞書の中身も変わってくるということがわかります。
tokenizersライブラリについて
tokenizersはCPUによる演算処理によって動くようプログラムが組まれています。
Hugging Faceのtokenizersライブラリは最新バージョンではRustという低レベル言語で実装されており、1GBのテキストに対してトークン化にかかる時間は20秒程度で、実用面でも十分高速な処理が実現できているとのことです。
日本語のテキストに対してサブワードベースのTokenizerを動かすには?
ここまでは英語のテキストに対してTokenizerを使用してきましたが、日本語でやりたい場合はどうしたら良いのでしょうか。
学習済みのTokenizerとしてはpart3などでやったように日本語版BERTのチェックポイントから同様に読み込んで使用することができます。
一から用意する場合は上の例のように学習させなければなりません。
サブワード分割する場合は基本的にまずテキストを基本トークン(単語)に分割させる処理を挟むことになり、英語の場合はとりあえずスペースで区切ればよかった(tokenizer.pre_tokenizer = WhiteSpace()としていた)のですが、日本語の場合はこの部分を形態素解析器に置き換えないといけませんね。
この辺りの詳しいやり方はこちらのMNTSQ株式会社さんのTechブログなどに詳しく書かれているので、興味のある方はチェックしてみてください。(私も日本語テキストデータで何かやるときは参考にさせていただきます・・・)
まとめ
今回はTokenizerについて詳しくみてきました。
本編の内容に加えてこちらの本などを参考に、単語ベース・文字ベース・サブワードの3種類の方法について整理してみました。
テキストデータをトークンに分割するというだけでも、辞書の大きさ、トークンの情報量の保持、未知語対策など様々な観点での工夫が必要で、奥が深いということを実感として持てました。
次回は入力するテキストデータに関して、複数テキストの処理、異なる長さのテキストなどの点について見ていき、Chapter2: Using 🤗 Transformersの締めに入れたらと思います。
Discussion