コサイン類似度を用いた文章の類似性比較、および、キーセンテンス抽出方法の一考察
目次
- 本記事の目的
- 前記事の課題の詳細、および、本記事の目的との関係性の整理
- 今回の学習データセット、および、学習内容
- 実装の流れ
- ステップ1 スクレイピング
- ステップ2以降のプログラムコード
- ステップ2 文章の分割
- ステップ3 コサイン類似度の算出
- ステップ4 類似キーセンテンスの抽出
- ステップ5 キーセンテンスを利用した文章の抽出
- 評価
- 本記事のまとめ
- 参考文献
本記事の目的
2つの文章を比較する際、その類似性を判断し後続の分析に利用することが必要になることがあると思います。例えば、プログラミングを指示する文章をクラスタリングした後、そのクラスターの中でどの文章と一番似ているかを判断することで、与えた指示文を満たすプログラムを抽出するといったことが可能になると考えています。この方法には、プログラミングコード自体の類似性を考える方法もありそうですが、どちらの方法を適用するにせよ、類似性の測定は重要になっていきます。またこの類似性の測定は、前記事から始めている、自分で与えた文章から、新しい単語(カッコイイ技名)を出力する際にも、与えた文章と学習した文章の関係性を整理し単語を出力するための最初のステップとして重要になっていくと考えています。
そこで、本記事では2つの文章の類似性を測定し分類する方法として、Transformerで数値ベクトル化した文章をコサイン類似度で分類していく方法を実装&考察していきます。
前記事の課題の詳細、および、本記事の目的との関係性の整理
本記事では、前記事の内容を例に文章の類似性の算出方法を考えていきます。前述の通り、この記事は自分で与えた文章に対してその文章に適した単語を出力することを目標にしています。前記事ではスクレイピングとTransformerで文章の要約を行いました。要約の際に、文章の重要なキーセンテンスを抽出して要約することで、重要な文節を残した上で要約文を作成できるのではないかと考えましたが、上手くキーセンテンスを選択できず良い要約文を生成できませんでした。このことから、重要な情報を残した上で良い要約文を作成することにおいて、キーセンテンスの選択方法を考え、要約文に組み込むことが重要であることが分かりました。
ところで、漫画やアニメを見ていて良かったと思う技名には以下の4種類がありました。
- ①難しめの単語、外国語を使用している単語
- ②語感がよい単語
- ③語感が似ている単語に当てはめて表現している単語
- ④技の能力や技の内容にちなんだ単語
①については、データ量を増やせば解決するとは思います。②については、韻を踏むという行為が似ていると感じており、既に他の方がやられているようです。③に関しては、ダジャレという観点でそのような記事を見つけることができました(参考記事1、参考記事2)。しかしながら、④についてはそのような記事を見つけられませんでした。④の実装を考えると、技の能力文や内容と学習データ上の文章という2つの文章の関係性を整理する作業が求められると考えています。その作業として、文章同士の類似性を測定することは1つの方法であり、本記事の目的とも一致します。
そこで本記事では、与えられた文章に対して基準となる文章の類似しているキーセンテンスを抽出する方法を考えていきます。具体的には、与えられた文章と基準となる文章をコサイン類似度で測定し、与えられた文章と似ている部分をキーセンテンスとして抽出。そのキーセンテンスに基づいて重要な文章を出力することを実装できればと考えています。
今回の学習データセット、および、学習内容
今回は前節の④の学習を行うため、単語に対して由来があるデータセットが必要です。由来がある言葉と由来の文章の組み合わせは故事成語が挙げられると考え、本記事ではこのページの故事成語を学習していきます。故事成語に由来した言葉は、「〇〇〇」という物語があって、その物語から「××」という意味になったという言葉になります。例えば、矛盾という言葉をgoo辞書から引用すると以下のように記載してあります。まず、由来となった物語として以下が記載されています。
《昔、中国の楚の国で、矛 (ほこ) と盾 (たて) とを売っていた者が、「この矛はどんなかたい盾をも突き通すことができ、この盾はどんな矛でも突き通すことができない」と誇ったが、「それではお前の矛でお前の盾を突けばどうなるか」と尋ねられて答えることができなかったという「韓非子」難一の故事から》
そして、この由来から意味は以下のようになります。
二つの物事がくいちがっていて、つじつまが合わないこと。
前節④の技の能力や技の内容にちなんだ単語については、能力や技の内容が、その物語に沿っていたり、物語に沿いつつ単語の意味とも一致していたとしたら、厨二心がくすぐられます。そこで、意味と由来となる物語の2つの文章の類似性を判断していきます。これは、似ているキーセンテンスを抽出し、そのキーセンテンスに近しい文章を記載したら、能力名が出力できるようなシステムの第1歩として重要になっていくと考えています。
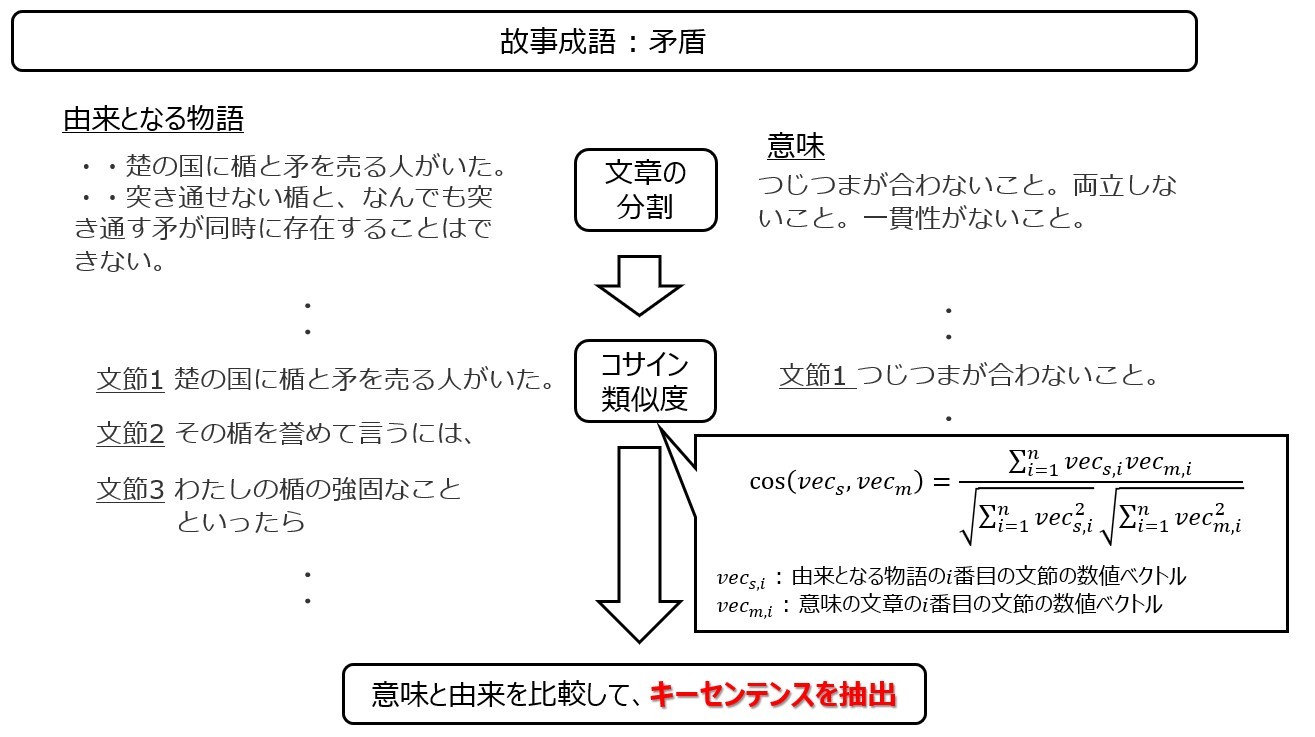
実装の流れ
実装は以下の流れで行われます。
- ステップ1 スクレイピング : 前述の記事における故事成語の意味・由来となる物語を抽出。このときに、括弧や改行文字等を除去する正規化を実施。
- ステップ2 文章の分割 : 由来となる物語を句読点や文字数に応じて分割、意味の文章も句読点に応じて分割。
- ステップ3 コサイン類似度の算出 : 分割した文章同士の類似度をコサイン類似度で測定。
- ステップ4 類似キーセンテンスの抽出 : 条件に基づいて類似度が高いキーセンテンスを抽出。
- ステップ5 キーセンテンスを利用した文章の抽出 : キーセンテンスを用いて、由来となる物語のうち故事成語の意味の元になったであろう文章を抽出。
では実際に実装をしていきます。
スクレイピング
本記事でスクレイピングするページは故事成語の一覧が乗っており、そのページに飛ぶことで、該当の故事成語の意味と由来が記載してあるページになります。以下のように実装しました。
#故事成語一覧ページ
original_url = 'http://www.katch.ne.jp/~kojigai/seigo.htm'
orignial_htm = requests.get(original_url)
orignial_htm.encoding = 'utf-8'
#aタブのリストで取得
soup = BeautifulSoup(original_htm.content)
a_list = soup.find_all('a')
#故事成語意味&由来のurlの取得
kogi_url = 'http://www.katch.ne.jp/~kojigai/'
urls = []
for a in a_list:
if a['href'].endswith('htm') and 'index' not in a['href'] and 'seigo' not in a['href'] :
urls.append(kogi_url + a['href'])
では故事成語(words)、故事成語の意味(meanings)、故事成語の由来(before_sentences)を上記のページから取得しています。
words = [] # 故事成語
meanings = [] # 故事成語の意味
before_sentences = [] #故事成語の由来
for url in urls :
#urlの内容取得(pタブのtext01クラス)
url_request = requests.get(url)
url_request.encoding = 'utf-8'
soup_word = BeautifulSoup(url_request.content)
text0_list = soup_word.find_all('p', class_='text01')
#text0クラスの要素の取得
txt = ""
for text0 in text0_list :
txt += text0.text
#h1タブの内容を取得して、wordsとbefire_sentencesを取得
h1_list = soup_word.find_all('h1')
for h1 in h1_list :
words.append(re_word(h1.text))
before_sentences.append(re_sentenceCN(txt))
#head2タブの内容を取得して、meaningsを取得
h2_list = soup_word.find_all('td', class_='head2')
for h2 in h2_list :
meanings.append(re_word(h2.text))
このとき、正規化を行っている部分(re_word、re_sentenceCN)は、
words.append(re_word(h1.text))
before_sentences.append(re_sentenceCN(txt))
の部分で実装しています。まずre_wordはこのように定義します。
# 括弧内の言葉・改行文字の削除
# 「意味:」の部分の削除
def re_word(word) :
after_word = re.sub(r'\([^()]*\)','',word)
after_word = re.sub('\n','',after_word)
after_word = neologdn.normalize(after_word)
after_word = re.sub('意味:','',after_word)
after_word = re.sub('[「」]','',after_word)
return after_word
次はre_sentenceCNはこのように定義します。
# 括弧内の言葉・改行だけの空白行の削除
# 括弧の種類を修正し削除
def re_sentenceCN(sentence) :
after_sentence = re.sub(r'\([^()]*\)','',sentence)
after_sentence = re.sub('\n\s*\n','\n',after_sentence)
after_sentence = re.sub('『','「',after_sentence)
after_sentence = re.sub('』','」',after_sentence)
after_sentence = re.sub('[「」]','',after_sentence)
after_sentence = after_sentence.strip()
after_sentence = neologdn.normalize(after_sentence)
return after_sentence
これにより故事成語・故事成語の意味・故事成語の由来を取得できます。



ステップ2以降のプログラムコード
STEP2以降のプログラムコードを記載し、少しずつ説明していきます。
pattern = r"[、。]|「|」" #文章の分割パターン
count = 0 #リストのインデックス
while count < len(meanings) :
#while count < 1 :
cos_sim_dicts = [] #コサイン類似度格納辞書
now_length = 0 #分割時の文章文字数
now_sentence = "" # 各分割時の文章
#故事成語の由来の文章を改行で分割
b_s = before_sentences[count]
b_s_lists = b_s.split("\n")
#故事成語の意味の分割と文字列長
meaning_lists = re.split(pattern,meanings[count])
meaning_length = sum(len(m) for m in meaning_lists[0:])
#由来の文章を分割し、意味の文章と類似度を測定する際に
#どこまでの文章を比較対象にするかを判断する
#文字列長の上限(max_length)と下限(min_length)
min_length = round((meaning_length / len(meaning_lists)),0)
max_length = round((1.5 * meaning_length / len(meaning_lists)),0)
print(meanings[count])
print("min_length : ", min_length)
print("max_length : ", max_length)
for i in range(len(b_s_lists)) :
# now_length : 現在の文字列長
now_length = len(now_sentence)
#文字数の上限比較
if now_length <= max_length :
after_length = sum(len(s) for s in b_s_lists[i:])
#現在のセンテンス以降の文字数(after_length)が下限以下であれば
#類似度の測定が上手くいかない可能性もある
#そのため、after_lengthが下限以下の場合、類似度を測定
if after_length <= min_length :
# now_sentence : 比較する由来の文章
now_sentence = now_sentence + b_s_lists[i] + ''.join(b_s_lists[i:])
#cos_sim_dicts : コサイン類似度格納辞書
#格納要素 meanings : 類似度を測定した意味の分割センテンス
# sentences : 類似度を測定した由来の分割センテンス
# cosine_similarity : コサイン類似度
temp_dicts = meaning_sentence_similarity(pattern,now_sentence,meanings[count])
cos_sim_dicts.extend(temp_dicts)
now_sentence = ""
else :
now_sentence += b_s_lists[i]
#最後の由来のセンテンスのときのみ、コサイン類似度の測定
if i == len(b_s_lists) - 1 :
temp_dicts = meaning_sentence_similarity(pattern,now_sentence,meanings[count])
cos_sim_dicts.extend(temp_dicts)
else :
now_sentence += b_s_lists[i]
#文字列が上限に達したら、コサイン類似の比較を実施
temp_dicts = meaning_sentence_similarity(pattern,now_sentence,meanings[count])
cos_sim_dicts.extend(temp_dicts)
#now_sentence = b_s_lists[i]
now_sentence = ""
#類似度での降順ソート
sorted_cs_dicts = sorted(cos_sim_dicts, key=lambda x: x['cosine_similarity'],reverse=True)
#類似度が高く、文章として問題ないものを
#コサイン類似度(cs_lists)に格納
cs_lists = []
after_sentences = []
for cs in sorted_cs_dicts :
if cs["sentences"] not in after_sentences and is_select(cs["sentences"]) :
cs_lists.append(cs["cosine_similarity"])
after_sentences.append(cs["sentences"])
#四分位範囲の測定
q1 = np.percentile(cs_lists, 25, interpolation='midpoint')
q3 = np.percentile(cs_lists, 75, interpolation='midpoint')
index = np.where((np.array(cs_lists) < q3) & (np.array(cs_lists) > q1))[0][0]
print("TOP4の類似度:", cs_lists[index:index+4])
print("TOP4の文章:", after_sentences[index:index+4])
#df_sentences(故事成語に対するキーセンテンスを格納するデータフレーム)への追加
#コサイン類似度TOP4に対して、前後1文ずつ抽出
important_sentences = ""
remove_b_s = b_s.replace("\n", "")
for a_s in after_sentences[index:index+4] :
important_sentences += "〇"
#前1文の抽出
split_sentences = remove_b_s.split(a_s)
period_count = 0
inverse_str = ""
for split_s in split_sentences[0][::-1] :
#print(split_s)
if "。" in split_s :
period_count += 1
if period_count == 2 :
break
else :
inverse_str += split_s
else :
inverse_str += split_s
#前の文 + キーセンテンス
important_sentences += inverse_str[::-1] + a_s
#キーセンテンス以降の文(。まで)の抽出
for split_s in split_sentences[1] :
#print(split_s)
if "。" in split_s :
important_sentences += "。\n"
break
else :
important_sentences += split_s
#重複分の削除
important_split_s = important_sentences.split("〇")
unique_important_sentences = "〇".join(list(set(important_split_s)))
#データフレームの追加
rows = {"故事成語": words[count], "意味": meanings[count], "重要文章": unique_important_sentences}
df_sentences.loc[len(df_sentences)] = rows
count += 1
それではSTEP2 文章の分割にあたる部分から説明をします。
文章の分割
コサイン類似度測定までの流れは以下の通りです。
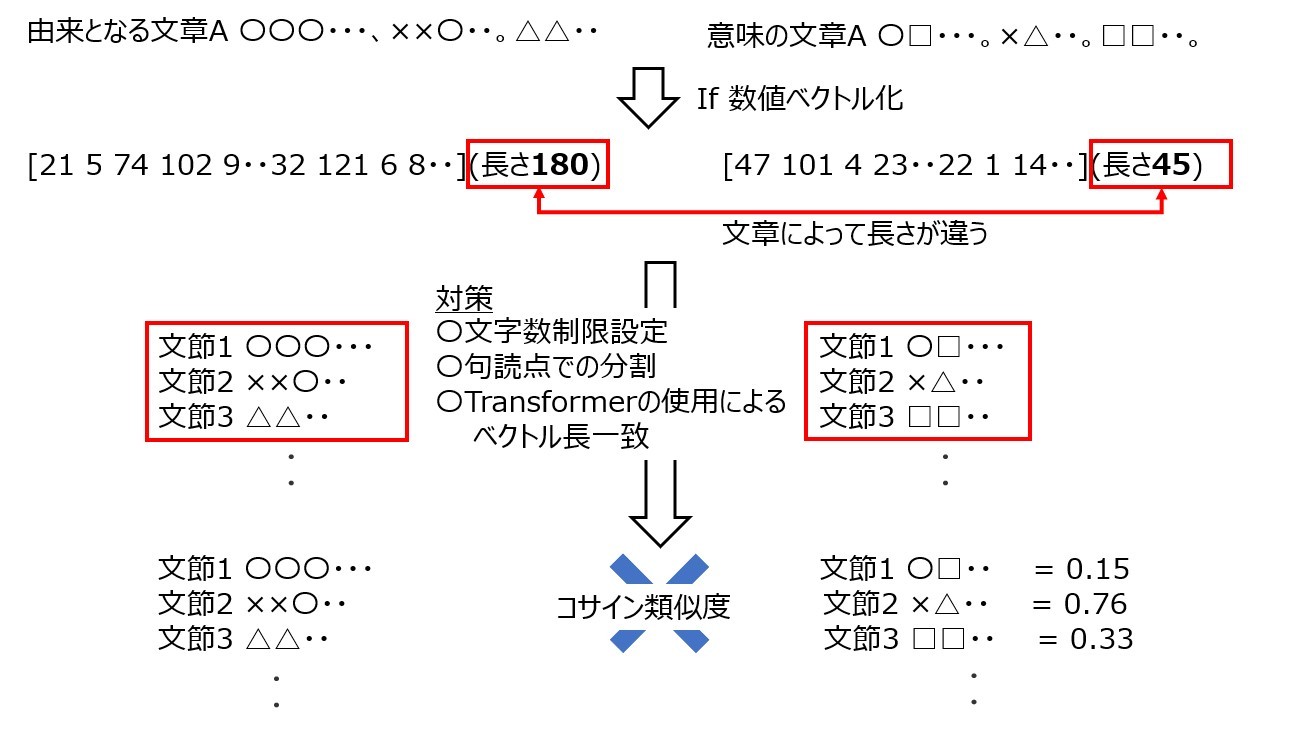
STEP2では上図における対策の部分を実装します。
Transformerを用いてエンコーディングをした場合、最大長に応じてバディングされます。つまり、2つの文章を数値ベクトル化した際に、短い文章はもう片方の文章の長さ依存し、0詰めされて同一長のベクトルで表現されます。これはコサイン類似度の算出式より正確な類似度が算出できない要因になると考えました。

そこで文字数制限については、意味の文章の長さに応じて上限(max_length)、および、下限(min_length)を設定して由来の文章の長さを決定するようにしました。この部分にあたる部分は、前節のコーディング(make_key_sentences.py)のうち、
#由来の文章を分割し、意味の文章と類似度を測定する際に
#どこまでの文章を比較対象にするかを判断する
#文字列長の上限(max_length)と下限(min_length)
min_length = round((meaning_length / len(meaning_lists)),0)
max_length = round((1.5 * meaning_length / len(meaning_lists)),0)
の部分に該当します。この設定により、意味の文章に対して可能な限り上限以上の長さの文字列を指定しないようにしました。また下限の設定は、意味の文章に対して短すぎる文字列を指定しないための設定になります。
これら制限を適用した文章は、句読点・括弧で分割し、エンコーディングで数値ベクトル化していきます。これはmake_key_sentences.pyの以下の部分で設定しています。
pattern = r"[、。]|「|」" #文章の分割パターン
####
中略
####
#cos_sim_dicts : コサイン類似度格納辞書
#格納要素 meanings : 類似度を測定した意味の分割センテンス
# sentences : 類似度を測定した由来の分割センテン
# cosine_similarity : コサイン類似度
temp_dicts = meaning_sentence_similarity(pattern,now_sentence,meanings[count])
cos_sim_dicts.extend(temp_dicts)
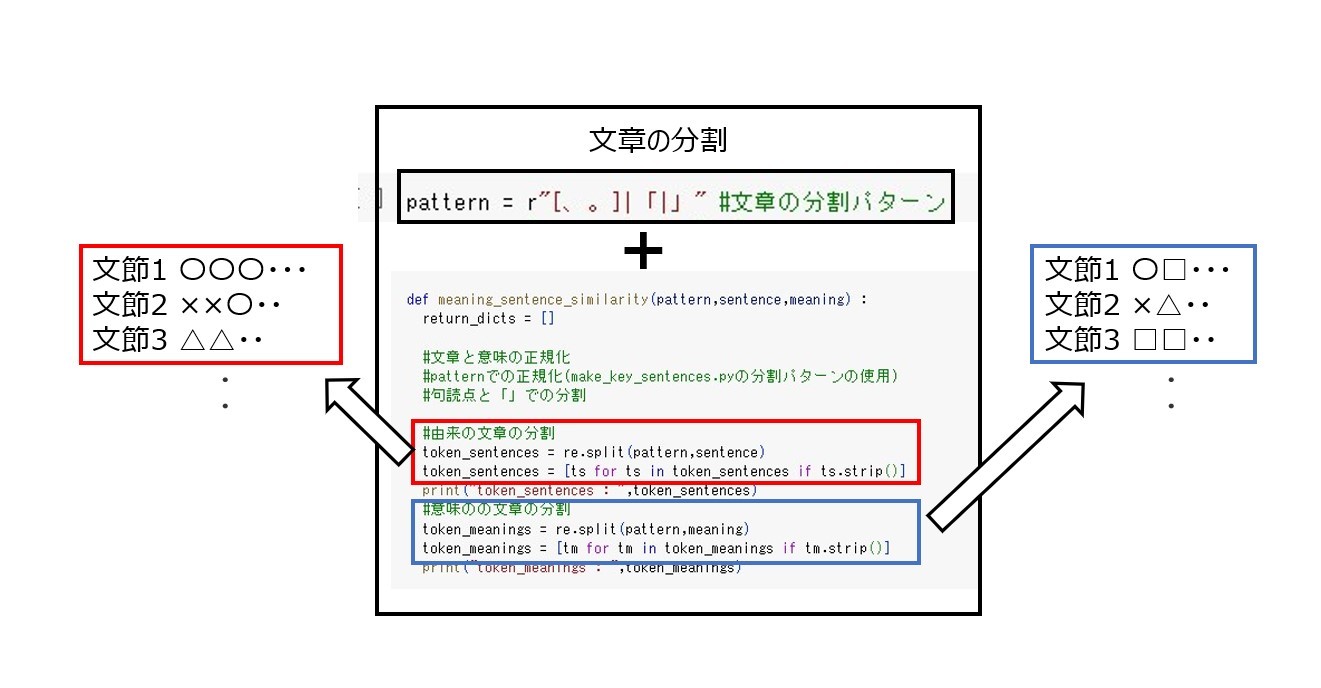
meaning_sentence_similarityは各文章をpatternで分割し、エンコーディングし数値ベクトル化、コサイン類似度を算出する関数になります。以下のように実装します。
import re
from sklearn.preprocessing import MinMaxScaler
def meaning_sentence_similarity(pattern,sentence,meaning) :
return_dicts = []
#文章と意味の正規化
#patternでの正規化(make_key_sentences.pyの分割パターンの使用)
#句読点と「」での分割
#由来の文章の分割
token_sentences = re.split(pattern,sentence)
token_sentences = [ts for ts in token_sentences if ts.strip()]
print("token_sentences : ",token_sentences)
#意味のの文章の分割
token_meanings = re.split(pattern,meaning)
token_meanings = [tm for tm in token_meanings if tm.strip()]
print("token_meanings : ",token_meanings)
#由来と意味文章のエンコーディング
#sentences_encode = tokenize(token_sentences)
#meanings_encode = tokenize(token_meanings)
#由来と意味文章の数値ベクトル化
#sentence_vectors = sentences_encode.input_ids
#meaning_vectors = meanings_encode.input_ids
for mv_count,mv in enumerate(token_meanings) :
#意味の文節の格納
compare_cos_sim = []
compare_cos_sim.append(mv)
for sv_count,sv in enumerate(token_sentences) :
#由来の文節の格納
compare_cos_sim.append(sv)
#由来と意味文節のエンコーディング
compre_cos_sim_encode = tokenize(compare_cos_sim)
#PyTorchによるGPUの利用可能判断
input = {k:v.to(device) for k,v in compre_cos_sim_encode.items()}
#最後の隠れ状態を含んだテンソル配列の格納
with torch.no_grad():
outputs = model(**input)
#最後の隠れ状態の格納
last_hidden_state = outputs.last_hidden_state
lhs_array = np.array(last_hidden_state[:,0])
#[0,1]区間のスケール
cs_X_scaled = MinMaxScaler().fit_transform(lhs_array)
#print(cs_lhs_array[1])
for cs_count,cs in enumerate(cs_X_scaled[1:]) :
#コサイン類似度内容(辞書型)
cos_sim_dict = {"meanings":token_meanings[mv_count],"sentences" : token_sentences[cs_count], "cosine_similarity" : round(cos_sim(cs_X_scaled[0],cs_X_scaled[cs_count]),3)}
#辞書への格納
return_dicts.append(cos_sim_dict)
return return_dicts
上記関数時に必要な各種関数定義は、以前の記事より以下のように定義しました。
from transformers import BertJapaneseTokenizer
tokenizerの作成
model_name = 'cl-tohoku/bert-base-japanese-whole-word-masking'
tokenizer = BertJapaneseTokenizer.from_pretrained(model_name)
#事前学習済みモデルの使用
from transformers import AutoModel
model = AutoModel.from_pretrained(model_name)
#文章のトークン化関数
def tokenize(text) :
return tokenizer(text,
padding=True,
truncation=True,
return_tensors="pt")
import torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
各文章をpatternで分割するコードと結果の関係性を下図に示します。
コサイン類似度の算出
コサイン類似度は前節のmeaning_sentence_similarity.pyのうち以下の部分で算出しています。
#コサイン類似度内容(辞書型)
cos_sim_dict = {"meanings":token_meanings[mv_count],"sentences" : token_sentences[cs_count], "cosine_similarity" : round(cos_sim(cs_X_scaled[0],cs_X_scaled[cs_count]),3)}
ここで、関数cos_simは以下のように定義します。
import numpy as np
def cos_sim(v1, v2):
return np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2))
cos_sim_dictは以下の3つの要素を格納した辞書になります。
- meanings : 句読点・括弧で分割した意味の文章
- sentences : 句読点・括弧で分割した由来の文章
- cosine_similarity : meaningsとsentencesのコサイン類似度
上記のコードは、由来の文章と意味の文章を分割した各文節に対してコサイン類似度を算出するコードになっています。
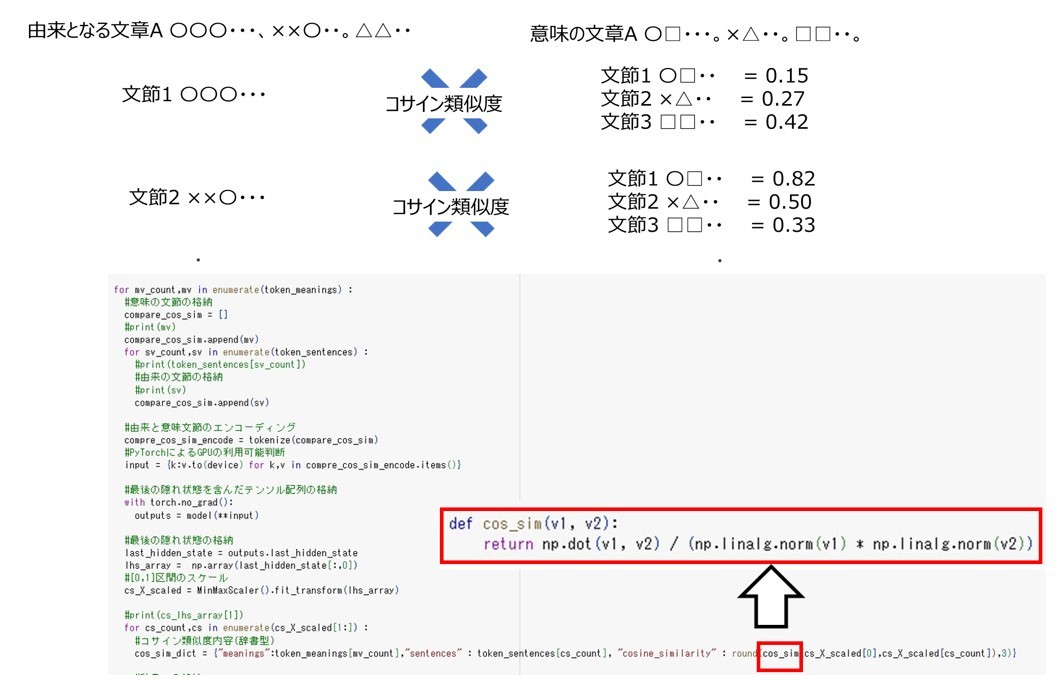
STEP4ではこのcosine_similarityの大小を比較して、キーセンテンスを抽出します。
類似キーセンテンスの抽出
前節までで求めたコサイン類似度を参照してキーセンテンスを抽出します。
コサイン類似度を算出する際には、前述の通り由来の文章・意味の文章を句読点と括弧で分割します。分割後はコサイン類似度の降順でソートをして、類似度の大きいものから重複なく抽出します。また由来の文章を分割した結果、
短すぎる文章、もしくは、1単語のみの文章、もしくは、文章がおかしい文章になってしまう文章になる可能性もあります。


そこでキーセンテンスとして抽出すべき文章かを判断します。今回は設定した条件は以下の2つです。なお、下記条件はJanomeを使って形態素解析をして考えます。
- 主語・述語がある文章 : 名詞が必ずあり、動詞、助動詞、形容詞のどれかが存在する文章
- 体言止めの可能性がある文章 : 最後が名詞である文章
まとめると下記のような条件でキーセンテンスを抽出します。
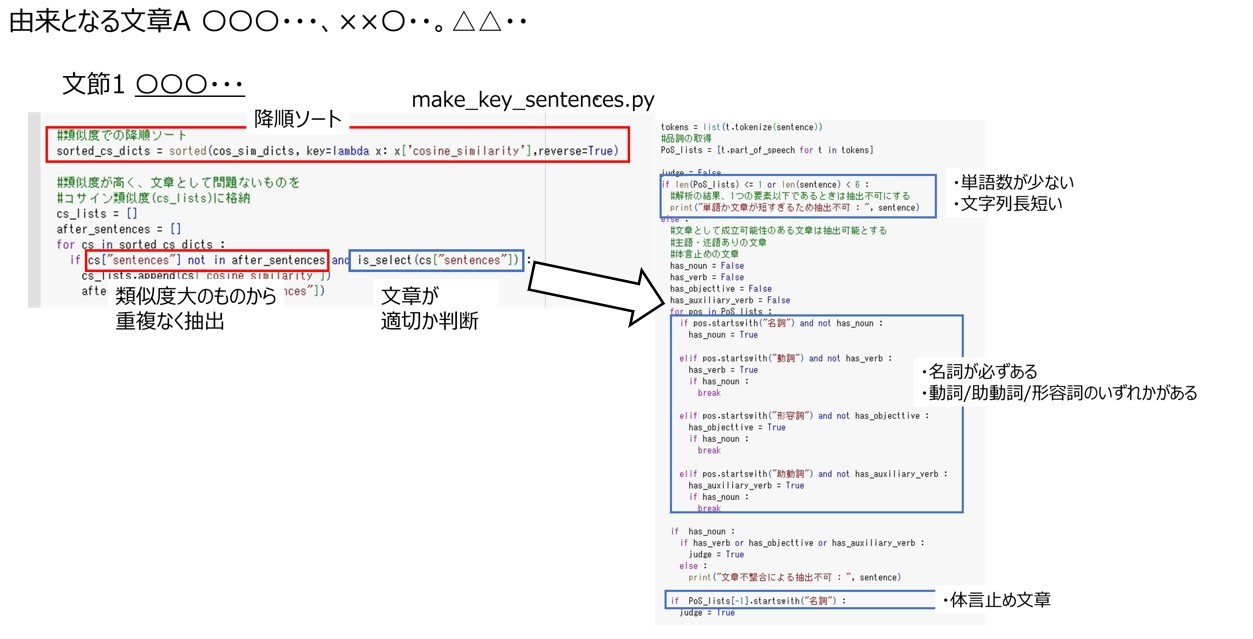
キーセンテンスとして抽出すべき文章かを判断する関数is_selectは以下のようなコードになります。
from janome.tokenizer import Tokenizer
def is_select(sentence) :
#形態素解析
t = Tokenizer()
tokens = list(t.tokenize(sentence))
#品詞の取得
PoS_lists = [t.part_of_speech for t in tokens]
judge = False
if len(PoS_lists) <= 1 or len(sentence) < 6 :
#解析の結果、1つの要素以下であるときは抽出不可にする
print("単語か文章が短すぎるため抽出不可 : ", sentence)
else :
#文章として成立可能性のある文章は抽出可能とする
#主語・述語ありの文章
#体言止めの文章
has_noun = False
has_verb = False
has_objecttive = False
has_auxiliary_verb = False
for pos in PoS_lists :
#名詞あり判断
if pos.startswith("名詞") and not has_noun :
has_noun = True
#動詞あり判断
elif pos.startswith("動詞") and not has_verb :
has_verb = True
if has_noun :
break
#形容詞あり判断
elif pos.startswith("形容詞") and not has_objecttive :
has_objecttive = True
if has_noun :
break
#助動詞あり判断
elif pos.startswith("助動詞") and not has_auxiliary_verb :
has_auxiliary_verb = True
if has_noun :
break
#主語述語あり判断
if has_noun :
if has_verb or has_objecttive or has_auxiliary_verb :
judge = True
else :
#体言止め判断
if PoS_lists[-1].startswith("名詞") :
judge = True
else :
print("文章不整合による抽出不可 : ", sentence)
return judge
上記を用いて抽出したコサイン類似度のリストに基づき重要なキーセンテンスを取得します。コサイン類似度のリストを見ると、極端に大きい値、もしくは、極端に小さい値があったので、今回は四分位範囲の考えを用いて、外れ値を外そうと考えました。四分位範囲についてはこのサイトを参考にしてください。今回はコサイン類似度が上位25%の数から75%の範囲を求めて、TOP4のものをキーセンテンスとして抽出します。これは、make_key_sentences.pyの以下の部分で設定しています。
#四分位範囲の測定
q1 = np.percentile(cs_lists, 25, interpolation='midpoint')
q3 = np.percentile(cs_lists, 75, interpolation='midpoint')
index = np.where((np.array(cs_lists) < q3) & (np.array(cs_lists) > q1))[0][0]
print("TOP4の類似度:", cs_lists[index:index+4])
print("TOP4の文章:", after_sentences[index:index+4])
キーセンテンスを利用した文章の抽出
STEP4まででコサイン類似の中で外れ値を考慮しつつ、重要なキーセンテンスを抽出することができました。最後にこのキーセンテンスを利用した重要な文章を抽出します。
由来となる文章に対するキーセンテンスはコサイン類似度で抽出したため。故事成語の意味の文章と類似性がある程度認められる文節だと考えています。故事成語の意味は、「今回の学習データセット、および、学習内容の節」で述べたように、物語の文脈があって、その中から学べる事等が故事成語の意味になっていることが多いと考えています。そこで、キーセンテンスを含んでいる文章だけでなく、前の文章も参照して重要な文章と考えることにしました。(今回は前の1文を参照します)これは、make_key_sentences.pyの以下の部分になります。
#df_sentences(故事成語に対するキーセンテンスを格納するデータフレーム)への追加
#コサイン類似度TOP4に対して、前後1文ずつ抽出
important_sentences = ""
remove_b_s = b_s.replace("\n", "")
for a_s in after_sentences[index:index+4] :
important_sentences += "〇"
#前1文の抽出
split_sentences = remove_b_s.split(a_s)
period_count = 0
inverse_str = ""
for split_s in split_sentences[0][::-1] :
if "。" in split_s :
period_count += 1
if period_count == 2 :
break
else :
inverse_str += split_s
else :
inverse_str += split_s
#前の文 + キーセンテンス
important_sentences += inverse_str[::-1] + a_s
#キーセンテンス以降の文(。まで)の抽出
for split_s in split_sentences[1] :
if "。" in split_s :
important_sentences += "。\n"
break
else :
important_sentences += split_s
#重複分の削除
important_split_s = important_sentences.split("〇")
unique_important_sentences = "〇".join(list(set(important_split_s)))
以上より、STEP1~5までの実装を終え、故事成語の意味の文章に対する以来の物語の中で意味に該当する重要な文章の抽出を実装できました。
評価例
上記のコードに対する評価していきます。今回は全102種のうち、5つの言葉に注目して評価していきたいと思います。
青は藍より出でて藍より青し
意味 : 弟子が師を超えることのたとえ。「出藍の誉れ」ともいう。本来は、学問を中断しなければ、優れた成果が上がると説いた言葉。
〇 元の由来の文章
君子は言う、学ぶことをやめてはいけない。青色は藍草から取り出すが、藍草よりも青い。 氷は水からできるが、水よりも冷たい。
墨縄にぴったり当たるほどまっすぐな木材でも、たわめて輪にすれば、コンパスにぴったり合うほど円くなる。 たとえ乾いても、元のようにまっすぐになることはない。たわめたことでそうなったのである。
だから、木は墨縄に当てればまっすぐであり、金は研ぐことで鋭利になる。君子は広く学び、そして、日々自らを省みる。 そうすれば、聡明となり、行為に間違いがなくなる。だから、高い山に登らなければ、天の高さはわからない。深い谷のそばに行かなければ、地の厚さをわからない。 古代の王の残した言葉を聞かなければ、学問の偉大さがわからない。
干(かん)、越(えつ)、夷(い)、貉(はく)の子供も生まれたときの産声は同じなのに、時間がたつと異なる風俗になる。 これは教育によるものである。
『詩経』にいう、「汝君子は安逸をむさぼってはならない。 慎み深く、自らの責務を果たし、正直な徳を好み、神にしてこれを聴き、汝の大きな福を心がけよ」 神で最も大事なのは道に同化することであり、福で最も良いのは禍いがないことである。
〇 抽出した重要な文章
- 君子は広く学び、そして、日々自らを省みる。そうすれば、聡明となり、行為に間違いがなくなる。
- だから、高い山に登らなければ、天の高さはわからない。深い谷のそばに行かなければ、地の厚さをわからない。
- たわめたことでそうなったのである。だから、木は墨縄に当てればまっすぐであり、金は研ぐことで鋭利になる。
- 君子は言う、学ぶことをやめてはいけない。青色は藍草から取り出すが、藍草よりも青い。
学問を中断しなければ成果が上がると説いた言葉に対して、
君子は広く学び、そして、日々自らを省みる。そうすれば、聡明となり、行為に間違いがなくなる
君子は言う、学ぶことをやめてはいけない。
というような学びに関して、学問はやめない方がよいという文章を取得できいます。しかし、その結論が出た要因は上手く取得できたとは言えないように思います。これは意味に対する比喩表現の抽出が上手くできないことが要因と考えています。
市に虎あり
意味 : どんなにあり得ぬことでも大勢の人が言うと信用されてしまうことのたとえ。
〇 元の由来の文章
魏の龐葱(ほうそう)は太子と共に邯鄲(かんたん)へ人質となって行くことになり、魏王に目通りをして言った。
「今一人の者が市場に虎がおりますといったら、王はお信じになりますか」
魏王は言った。
「信じぬ」
「では、二人の者が市場に虎がいますと言ったら、王はお信じになりますか」
「半信半疑であろう」
と魏王は答えた。
「それでは、三人の者が市場に虎がいますと言ったら、王はお信じになりますか」
「わしは信じるであろう」
「そもそも、市場に虎などいないのはわかりきったことです。 しかし、三人の者が言えば虎がいることになってしまいます。 わたくしはこれから邯鄲へ参りますが、大梁(たいりょう)から邯鄲までの距離は、 王宮から市場までの距離よりはるかに遠く、また、わたくしのことを悪く言うものも三人にとどまりますまい。 王におかれては、なにとぞこの点をよくお考え下さいませ」
「わしは自分で判断するとしよう」
そこで、龐葱は出かけて行ったが、さっそく龐葱の讒言をする者が現れた。
後に太子が人質を解かれたが、龐葱は、結局王に目通りすることもかなわなかった。
〇 抽出した重要な文章
- 魏の龐葱は太子と共に邯鄲へ人質となって行くことになり、魏王に目通りをして言った。今一人の者が市場に虎がおりますといったら、王はお信じになりますか魏王は言った。
- 今一人の者が市場に虎がおりますといったら、王はお信じになりますか魏王は言った。信じぬでは、二人の者が市場に虎がいますと言ったら、王はお信じになりますか半信半疑であろうと魏王は答えた。
- わたくしはこれから邯鄲へ参りますが、大梁から邯鄲までの距離は、王宮から市場までの距離よりはるかに遠く、また、わたくしのことを悪く言うものも三人にとどまりますまい。王におかれては、なにとぞこの点をよくお考え下さいませわしは自分で判断するとしようそこで、龐葱は出かけて行ったが、さっそく龐葱の讒言をする者が現れた。
上記抽出文には2点の問題点があります。
1点目の問題は、文章の取得間違えている点です。抽出した2つのめの分葉では、括弧がある他、信じぬではというような文章がおかしな点があります。これは、正規化後の文章に基づいてキーセンテンスが入っている文章を抽出したからです。
2点目の問題は、由来となっている文章を抽出できていないという点です。先程の故事成語では意味に対応した直接的な文章がありましたが、今回の故事成語はありません。そのため、比喩にあたる部分をきちんと抽出する必要があります。
「今一人の者が市場に虎がおりますといったら、王はお信じになりますか」
魏王は言った。
「信じぬ」
「では、二人の者が市場に虎がいますと言ったら、王はお信じになりますか」
「半信半疑であろう」
と魏王は答えた。
「それでは、三人の者が市場に虎がいますと言ったら、王はお信じになりますか」
「わしは信じるであろう」
「そもそも、市場に虎などいないのはわかりきったことです。 しかし、三人の者が言えば虎がいることになってしまいます。
といった、複数人がいったら信じるしかないという部分を抽出することが正解だと思いますが、この全てを抽出できておりません。
漁夫の利
意味 : 人と人とが争っている間に、第三者が利益を得てしまうことのたとえ。
〇 元の由来の文章
戦国時代、趙(ちょう)が燕(えん)を攻めようとした。
蘇代(そだい)は燕のために趙の恵王(けいおう)に言った。
「いましがた、私がこちらへ参りますとき、 易水(えきすい)を通りましたところ、 ちょうど、カラス貝が一匹、日光浴をしておりました。 するとそこへ、シギが一羽飛んで参りまして、 カラス貝の肉をついばもうとしました。 カラス貝は急いで殻を閉じて、シギのくちばしを挟みました。 シギが申します。
『今日も雨が降らず、明日も雨が降らねば、死んだカラス貝が一匹出来上がるだろうな』
カラス貝も言いました。
『今日もくちばしを出せず、明日も出せなかったら、ここに死んだシギができるのは間違いないな』
両者とも讓ろうとしません。 そこへ漁師がやってまいりまして、二匹とも捕まえて行ってしまいました。
ところで今、趙は燕を討とうとしております。燕と趙が長い間攻めあい、 民衆が疲弊すれば、強国の秦が漁師となるのではないかと私は心配しております。 どうか、王におかれてはこのことをよくよくお考えください」
恵王は、
「なるほど」
と言い、燕征伐を取りやめた。
〇 抽出した重要な文章
- 今日もくちばしを出せず、明日も出せなかったら、ここに死んだシギができるのは間違いないな両者とも讓ろうとしません。そこへ漁師がやってまいりまして、二匹とも捕まえて行ってしまいました。
- 蘇代は燕のために趙の恵王に言った。いましがた、私がこちらへ参りますとき、易水を通りましたところ、ちょうど、カラス貝が一匹、日光浴をしておりました。
いましがた、私がこちらへ参りますとき、易水を通りましたところ、ちょうど、カラス貝が一匹、日光浴をしておりました。するとそこへ、シギが一羽飛んで参りまして、カラス貝の肉をついばもうとしました。 - そこへ漁師がやってまいりまして、二匹とも捕まえて行ってしまいました。ところで今、趙は燕を討とうとしております。
前述の故事成語のように、正規化が原因で括弧等の不足があり、読みにくい文章になっておりますが、
『今日もくちばしを出せず、明日も出せなかったら、ここに死んだシギができるのは間違いないな』
両者とも讓ろうとしません。 そこへ漁師がやってまいりまして、二匹とも捕まえて行ってしまいました。
の重要な部分は抽出できています。しかし、登場するカラス貝やシギの言い争いの部分は抜き出すことはできず、その部分は不足していると考えています。
背水の陣
意味 : 逆境に追い込まれて覚悟を決め、全力をあげて勝負すること。逃げようのない位置に自分をおき、決死の覚悟で戦うこと。
〇 元の由来の文章(長いため、抽出した箇所周辺と、重要であろう部分以外引用しません。全文はこちらで確認ください)
「漢の将軍韓信は西河(黄河)を渡り、魏王、夏説(かえつ)を捕らえ、・・
そうなると、兵糧は必ずはるか後方に取り残されます。どうか、わたくしに奇兵三万をお貸しください。間道を伝って、その輜重を断ち切りましょう。あなたは堀を深くほり、土塁を高くして陣営を守り、戦ってはなりません。彼らは進もうにも戦えず、退こうにも退けず、我が奇兵がその退路を断てば、彼らは荒野では何も手に入れることができません。・・」
・・
「兵法に、兵力が十倍ならば敵を包囲し、二倍なら戦え、とあると聞く。今、韓信の兵は数万と称しているが、その実、数千に過ぎぬ。千里もの道を歩き、我が軍を襲おうとしているが、すでにその疲労は極みに達している。今、このように避けて戦わず、後に強大な後続部隊が来たときには、どうするつもりだ。諸侯はわしを臆病者と思い、あなどり、伐ちに来るであろう」
そう言って、広武君の策を用いなかった。
・・
韓信はまず、一万の兵を先行させ、河水を背に布陣させた。・・しばらく激戦が続いた。
そこで、韓信・張耳はわざと旗鼓を棄て、河水の自陣に逃げ込んだ。・・漢軍はみな必死になって戦ったので、なかなか敗れない。
・・
趙軍は勝つことができず、韓信らを捕らえることもできないので、砦に帰ろうとしたところ、砦にはみな漢ののぼりが立っている。驚きのあまり、漢はすでに趙の将軍をみな捕らえてしまったと思い込んだ。そこで、兵たちは大混乱に陥り、次々と逃げ出した。
「・・将軍は我々に水を背にして布陣させ、趙を破って宴にしようとおっしゃいました。・・」
・・
「・・このような状況下では、死地に置いて、自ら戦わなければならないようにしむけないと、仮に生地を与えたらば、みな逃げ出してしまうだろう。これではどうして、彼らを使って勝つことができようか・・」
・・
〇 抽出した重要な文章
- 千里もの道を歩き、我が軍を襲おうとしているが、すでにその疲労は極みに達している。今、このように避けて戦わず、後に強大な後続部隊が来たときには、どうするつもりだ。
- 兵法に、兵力が十倍ならば敵を包囲し、二倍なら戦え、とあると聞く。今、韓信の兵は数万と称しているが、その実、数千に過ぎぬ。
- あなたは堀を深くほり、土塁を高くして陣営を守り、戦ってはなりません。彼らは進もうにも戦えず、退こうにも退けず、我が奇兵がその退路を断てば、彼らは荒野では何も手に入れることができません。
- 趙軍は勝つことができず、韓信らを捕らえることもできないので、砦に帰ろうとしたところ、砦にはみな漢ののぼりが立っている。驚きのあまり、漢はすでに趙の将軍をみな捕らえてしまったと思い込んだ。
このように長い文章では前の文章1文のみを参照したとしても、上手くいかない場合があります。今回由来となる文章と意味の文章を比較した類似性のみで、キーセンテンスを抽出しましたが、故事成語が由来となる文章の単語から抽出されると考えると、由来となる文章と故事成語の単語の比較も重要であると感じました。
本記事のまとめ
本記事では2つの文章の類似性を算出する方法として、コサイン類似度を用いて文章の類似性を考えて、キーセンテンスを抽出する方法を考えていきました。結果を通して、この方法について以下のことが分かりました。
- 由来の文章に対して、意味の文章に類似の単語や文節があった場合、それはキーセンテンスとして抽出可能
- キーセンテンスに対して、由来となった文章の文脈を考えたい場合、前の文章を1文だけ取得する方法は、長い文章であると上手くいかない可能性が高い。
- 由来の文章が比喩表現であったり、その状況の様子を表現した故事成語を抽出した場合は、それに応じた学習方法を用いる必要性が高い
これらのことから、文章の言い換えによる文章の推敲や比喩表現に対する学習を別途行うことが重要であると感じています(参考論文①、参考論文②)。また、N-gram等の文字分割も使用する方法も今後は考えてみようと思います。
参考文献
〇私の以前の記事
・Transformerを用いた文章のクラスタリング
・ぼくのかんがえたさいきょうの必殺技の名前を叫びたい!! ~スクレイピング&要約編~
〇他の参考記事
・ラップができるAIを作ろう Part.1 ~韻を検索する~
・おもしろいダジャレを入力すると布団が吹っ飛ぶ装置を作った
・ダジャレを判定する
・「コサイン類似度」で文書がどれだけ似ているかを調べてみた
・四分位数・四分位範囲・四分位偏差をわかりやすく図解
〇学習ページ
・故事成語のお話
〇参考論文
・小田悠介ら,プログラム間の類似性の定量化手法,2013
・呉 浩東,難解な表現の言い換えによるテキストの平易化,2023
・寺岡 丈博.比喩理解に関する自然言語処理研究の紹介,2020
Discussion