ぼくのかんがえたさいきょうの必殺技の名前を叫びたい!! ~スクレイピング&要約編~
本記事の動機
私には中学生頃から夢があります。それはカッコイイ技を考えて、それを自分の技として叫びながら発動することです。発動は無理なんですが、技名くらいは考えつきたいものでした。しかし、語彙力がない、センスもない私ではカッコイイ技名なんて思いつきもしないのです。。
そして時は過ぎていき、ChatGPTの出現&前記事でTransformerを学ぶ中で、
あれ、これってカッコイイ技名とその能力を多量に学ばせれば、自分の考えた能力の説明文→カッコいい技名の出力
できるのでは?と考えたのが本記事の動機です。
まとめると、Transformerを用いた学習をしつつ、分からなければChatGPTを使って、
- 不味い果実を食べてなくても、能力を宿す
- 霊力がなくても、卍解を習得する
- 印を結べなくても、忍術を使う
- 個性がなくても、ヒーローになる
- テニスラケットを持たなくても、五感を奪ったりする
等々を可能にすることが本記事、そして、これ以降の同記事の目標となります。
本記事以降の流れ
上記目標達成のために、本記事含め以下の記事を書く予定です。
-
スクレイピング&要約編 : Webから技名・能力名、および、能力の説明文を取得。後の説明文の比較のために、説明文を要約(本記事)。
-
データ数増加編 : 技名・能力名のデータをより増量。また、アニメのような技や能力は、異なる分野に由来があるものがあることもあるので、そのようなことも考慮して、異なる分野の言葉・説明も学習。
-
説明文比較&技名・能力名関係性考察編 : 要約文毎の類似性を算出し、技名・能力名との関係性をどのように表現するのが適切か考察。
-
技名・能力名と説明文学習編 : 上述の記事をまとめて、学習方法を考察し実装。
-
技名決定偏 : 能力や技の説明文を記載して、技名が出力されるのかテスト。
-
プログラム内容解説編 : プログラムの前提となる知識を説明しようとして文章が長くなる傾向があるので、本記事を含めあまり前提となる知識を説明しません。最後の記事では、上記プログラムの知識を説明する解説記事のようなものを執筆。
Webのスクレイピング
では実際に技名・能力名、および、説明文を取得していきましょう。今回はWikipediaのBLEACHの記事に対し、スクレイピングをして、技名・能力名、および、その説明文も取得します。そして、説明文を要約することで文章を短くして後に類似性を把握しやすくします。実装はGoogle Colaboratoryで行っています。
スクレイピングには、BeautifulSoupを使います。
import requests
from bs4 import BeautifulSoup
まず、技名・能力名の取得を考えていきます。htmlデータをみると、dtタブに名前があることが分かります。

そこでdtタブで取得したものに対して、技名・能力名であるかを判断しそれをwordsというリストに入れていきます。
#dtタブのリストを取得
r = requests.get('https://ja.wikipedia.org/wiki/BLEACH%E3%81%AE%E7%99%BB%E5%A0%B4%E4%BA%BA%E7%89%A9')
soup = BeautifulSoup(r.content)
dt_list = soup.find_all('dt')
words = [] #words : 技名・能力名のリスト
for dt in dt_list:
word = dt.text # 技名・能力名の候補テキスト
if is_word_bleach(word) : #is_word_bleach : 後述
words.append(word)
Is_word_bleachは技名・能力名であるかを判断する関数で以下のように定義します。dtタブの中で、ブリーチにおける技/能力の要素である、斬魄刀・卍解・完現術・帰刃・滅却師完聖体、に加えて技・能力で始まる要素も技や能力と捉えていきます。
def is_word_bleach(word) :
if word.startswith("斬魄刀:") or word.startswith("【卍解】:") or word.startswith("技『") or word.startswith("技「") or \
word.startswith("能力「") or word.startswith("完現術:") or word.startswith("帰刃:") or \
word.startswith("『") or word.startswith("「") or word.startswith("滅却師完聖体") :
if "、" in word or "。" in word :
return False
else :
return True
else:
return False
また、技名・能力名に対する説明文はdlタブで取得できます、またdl内には技名・能力名も存在しているので、技名・能力名に加え説明文も格納するリストであるword_statement_listを作成します。その後、説明文を分割していきます。
#技名・能力名と説明文があるdlタブの内容を抽出
soup = BeautifulSoup(r.content)
dl_list = soup.find_all('dl')
word_statement_list = [] # word_statement_list : 技名・能力名と説明文の格納リスト
count = 0
for dl in dl_list:
#改行タブで、dlタブ内の技名・能力名と説明文を取得
text = dl.text.split("\n")
for i in range(len(text)) :
# is_statement_list : 技名・能力名、説明文をリストに格納
if is_statement_list(dd_text[i],word_statement_list) :
word_statement_list.append(dd_text[i])
is_word_statement_listは、技名・能力名をis_word_bleachで判断し、文章はリストに格納されているかを判断する関数です。
def is_statement_list(txt,statement_list) :
judge = False
if is_word_bleach(txt) :
judge = True
else :
if txt not in statement_list :
judge = True
return judge
dlタブは入れ子になっていることもあり、この影響により技名・能力名が重複して抽出する可能性があります。
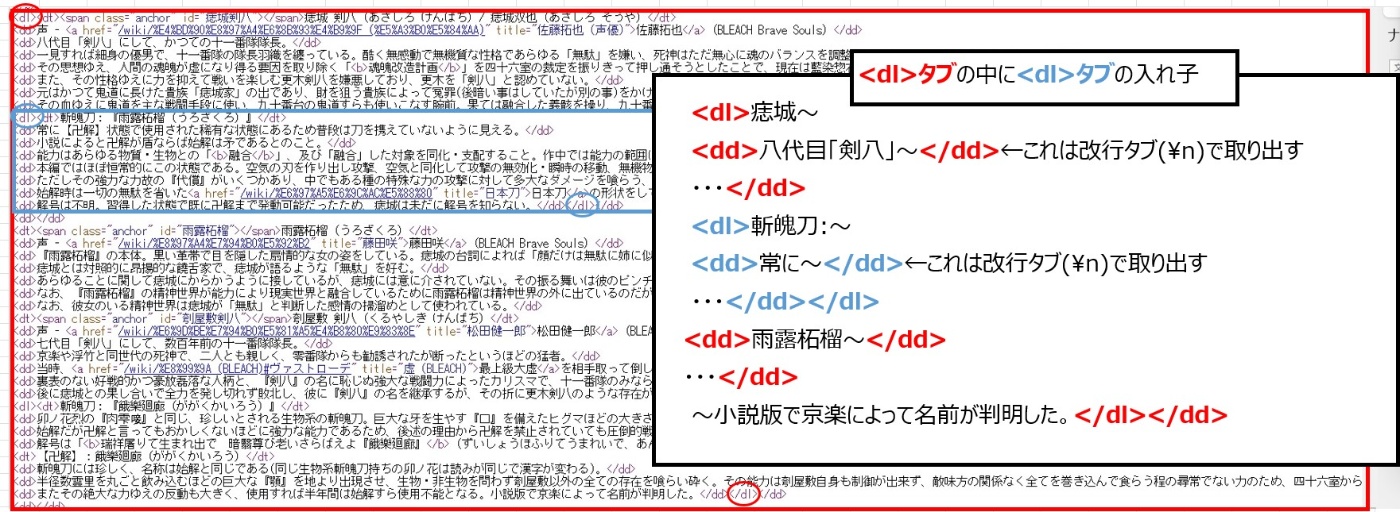
そこで、重複した該当の技名・能力名は削除します。
#is_word : 文章判断関数
def is_word(word) :
if "、" in word or "。" in word :
return False
else :
return True
i = 0
length = len(word_statement_list) #技名・能力名、説明文リスト
while i < length - 1:
current_word = word_statement_list[i] #現在の抽出単語
next_word = word_statement_list[i + 1] #次の抽出単語
# 削除条件 : 現在の抽出分は技名・能力名で、次の抽出分は文章でない
if is_word_bleach(current_word) and is_word(next_word) :
print(current_word," ",next_word)
del word_statement_list[i]
length -= 1
else :
i += 1
技・能力の説明がどこまで続くのかを考えていきます。
まず、画像のように次の技・能力が始まるまでの間が説明となります。そのため、技名・能力名のwordsの名前が技・能力名、説明文のリストであるword_statement_listが一致するまでを説明文と考えていきます。

またソースを確認すると、技名・能力名の説明が終わるとキャラクターの紹介文になることが分かりました。その説明文がキャラクターのものかどうかは、説明が始まった次の文、つまり、技名・能力名の説明文が終了した2行後の情報が声優さんの情報(声-)になることが分かりました。

以上より、word_statement_listから説明文を分割するプログラムは以下のように実装できます。なお、文章の正規化は、normalize_statement_bleach関数で行います。
def normalize_statement_bleach(statement) :
#卍解、技、能力の削除・変換
remove_statement =re.sub(r'【卍解】','',statement)
remove_statement =re.sub(r'(技「.*:」)|(技『.*:』)','技、「xxxx」',remove_statement)
remove_statement =re.sub(r'(能力「.*:」)|(能力『.*:』)','能力、「xxxx」',remove_statement)
#カッコや英字・数値の整理
remove_statement =re.sub(r'[「」『』]','',remove_statement)
remove_statement =re.sub(r'[a-zA-Z]','',remove_statement)
remove_statement =re.sub(r'\([^()]*\)','',remove_statement)
remove_statement =re.sub(r'\[\d+\]','',remove_statement)
#「:」で始める文字の削除
remove_statement =re.sub(r'.*:','',remove_statement)
#大文字・小文字や全角・半角などの複数の正規化処理 neologdn.normalize
remove_statement = neologdn.normalize(remove_statement)
return remove_statement
statement = ""
statements = [] #説明文格納リスト
statement_count = 0 #word_statement_list(技名・能力名と説明文の格納リスト)のインデックス
word_count = 0 #words(技名・能力名格納リスト)のインデックス
word_judge = False #説明文が終了したか判断変数(終了時、True)
while statement_count <= len(word_statement_list) -1 :
if word_judge :
if word_count + 1 <= len(words) - 1 :
#word_statement_listが技名・能力名が同じとき→技・能力の説明終了
if words[word_count + 1] in word_statement_list[statement_count] :
#説明文保存
statement = normalize_statement_bleach(statement)
statements.append(statement)
statement = ""
word_count += 1
word_judge = False
#説明文の2行先が"声 -"で始まっている→技・能力の説明終了
elif ("声 -" in word_statement_list[statement_count + 2]) :
#説明文保存
statement += word_statement_list[statement_count]
statement = normalize_statement_bleach(statement)
statements.append(statement)
statement = ""
word_count += 1
word_judge = False
else :
statement += word_statement_list[statement_count]
else :
#最後の技・能力用の説明文
if statement_count == len(word_statement_list) -1 :
statement = normalize_statement_bleach(statement)
statements.append(statement)
break
else :
if ("声 -" in word_statement_list[statement_count + 2]) :
statement += word_statement_list[statement_count]
statement = normalize_statement_bleach(statement)
statements.append(statement)
break
else :
statement += word_statement_list[statement_count]
if words[word_count] in word_statement_list[statement_count] :
#word_statement_listが技名・能力名が同じ(含まれているとき)、次の文から該当の技・能力の説明開始
word_judge = True
statement_count += 1
ここで複数の正規化が行えるneologdnモジュールは、別途インストールしてください。
!pip install neologdn
文章の要約の前に・・・
今回の文章の要約をTransformerでしていたのですが、文章が短いからか、文章の並びが乱雑で意味の分からない文章になったり、同じ名詞がずっと続いていたりと要約が上手くできませんでした。そこで以下の方法を考えていきます。
- 重要なキーワードを文章から抽出し、Transformerで取得する際に、取得しやすい文章に組替
- 形態素解析をして、意味の通じる可能性のある並びになる文章を取得
重要キーワードの抽出(ChatGPTの方法を用いて)
前者については、ChatGPTに聞いて把握できた方法になります。実際の質問のやり取りを下記に示します。

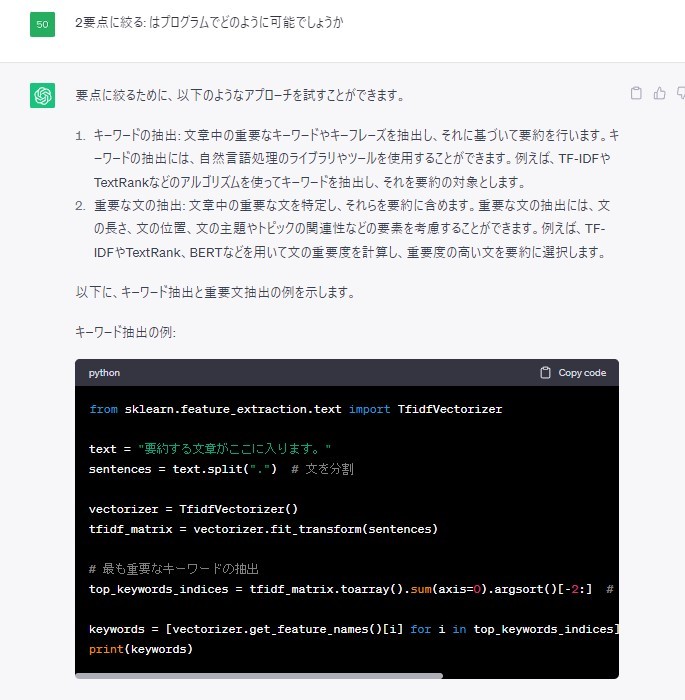
このTfidfVectorizerとは、文書中の単語の出現頻度と単語の需要度を組み合わせたtfidfという数値のようです(解説記事。最後の解説記事でまとめたときに、改めてきちんと解説できるようにしたいです)
文章中の重要な文を特定したのち、Transformerで抽出で組み合わせることができるようにキーワードとしてリスト化していくと良いようです。
ただエラーがでたので修正してもらいました。
そしてこのキーワードを元の文章に付け加えることで、重要なキーワードとして強調され上手な要約になる可能性が高いというご指導を頂きました。
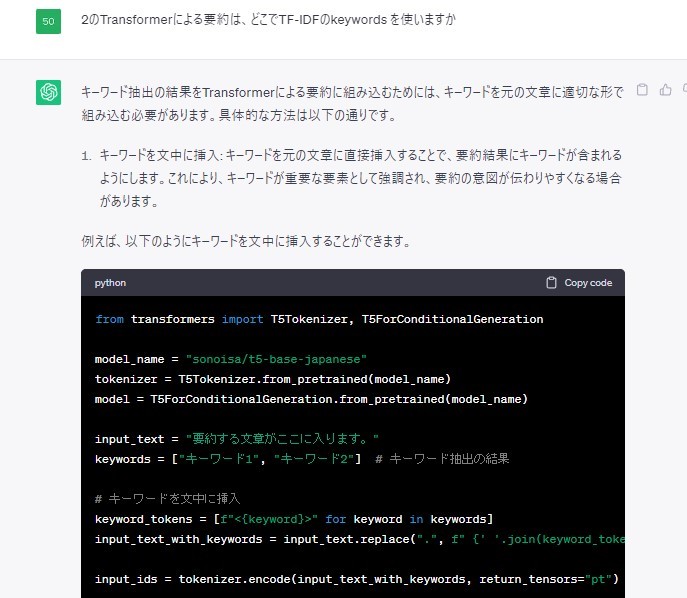
以上より、重要なキーワードの抽出を考えた文章の修正は以下のように実装できます。
重要なキーワードを抽出した文章に対して、技や能力を説明したキーワードを抽出できるように、技や力を含んだ文章であるか、また「~の能力」や「~斬魄刀」というような文章が多いことが分かったので、名詞で終わる文章も抽出できるようにしました。後述のis_select関数で行います。
名詞かどうかの判断には形態素解析が必要で、今回はJanomeを使います。
!pip install Janome
from janome.tokenizer import Tokenizer
def is_select(statement) :
#形態素解析
t = Tokenizer()
tokens = list(t.tokenize(statement))
if "技" in statement or "力" in statement :
return True
else :
if len(statement) > 0 and tokens[-1].part_of_speech.startswith("名詞") :
return True
else :
return False
では、キーワードを加えた文章を作成します。
before_summary_statements = []
summary_count = 0
for original_i in range(len(statements)) :
split_s = statements[original_i].split("。")
new_statement = ""
false_statement = ""
for split_i in range(len(split_s)) :
if is_select(split_s[split_i]) :
#new_statement : 力・技が文中にある、もしくは体言止めの文章
new_statement += split_s[split_i] + "。"
else :
#false_statement : 上以外の文章
false_statement += split_s[split_i] + "。"
# 文を分割
sentences = new_statement.split("。")
if sentences[0] == "" :
#この条件がTrue : new_statementなし
# 文章の中には一度も力・技の文言がない、もしくは体言止めの文章がない
sentences = false_statement.split("。")
# 最も重要なキーワードを3つ抽出
tfidf_matrix = vectorizer.fit_transform(sentences)
top_keywords_indices = tfidf_matrix.toarray().sum(axis=0).argsort()[-3:]
#キーワードのリスト化
keywords = [key for key in vectorizer.vocabulary_.keys() if vectorizer.vocabulary_[key] in top_keywords_indices]
#キーワードの分析
ability_keywords = []
for key in keywords :
#キーワードは特に能力・技の説明になっているかを判断したい
#技・力・奥義・必殺・可能・変(変化や変換等の文言)・倍(〇倍、倍化等の文言)があれば、より重要なキーワードとして抽出
if "技" in key or "力" in key or "奥義" in key or "必殺" in key or "可能" in key or "変" in key or "倍" in key :
ability_keywords.append(key)
#上記文言が全てのキーワードになければ、抽出したキーワードを全て適用
if len(ability_keywords) == 0 :
ability_keywords = keywords
# keywordの挿入
#各文章の最後に<キーワード>の形で挿入
input_keyword_steatements = ""
for new_i in range(len(sentences)) :
input_keyword_steatements += sentences[new_i] + "。"
for key in ability_keywords :
input_keyword_steatements += "<" +key + ">、"
#元の文章の長さが50以下であれば、変なキーワードを抽出してもよくないので、
#文章の挿入はせず、そのままの文章を保持
if len(statements[original_i]) > 50 :
if len(input_keyword_steatements) > 0 :
before_summary_statements.append(input_keyword_steatements)
#else :
# if len(statements[original_i]) == 0 :
# before_summary_statements.append(false_statement)
# else :
# before_summary_statements.append(new_statement)
else :
if len(new_statement) == 0 :
before_summary_statements.append(false_statement)
else :
before_summary_statements.append(new_statement)
形態素解析を用いた乱雑な文章の除去
ここでは、形態素解析を用いて、文章の要約した際に文章の並びのおかしい文章を削除することを考えていきます。今回は要約をしていく過程で発生した文章の状態、もしくは、その状態から考えられるおかしくない可能性の高い文章の並びに対し、文章を削除しないこととします。
条件は以下の通りです。
- 条件① 最初の単語が、助詞以外
- 条件② 最後の単語が助動詞か名詞、もしくは、助詞以外
- 条件③ 最初の単語が、助詞以外
- 条件④ 文末が助詞→記号の並びでない
- 条件⑤ 上記4つの条件を満たした上で、文章に動詞がある
また、同じ単語が続いていないこと(条件⑥)も条件に加えます。これらの条件を満たすかどうかを考える、is_summarystatement関数を実装します。
def is_summarystatement(statement) :
t = Tokenizer()
tokens = list(t.tokenize(statement))
split_words = []
judge = False
if not tokens[0].part_of_speech.startswith("助詞") or \ #条件①
tokens[-1].part_of_speech.startswith("助動詞") or tokens[-1].part_of_speech.startswith("名詞") or not tokens[-1].part_of_speech.startswith("助詞") : #条件③
if len(tokens) >= 2 :
if not (tokens[-2].part_of_speech.startswith("助詞") and tokens[-1].part_of_speech.startswith("記号")) : 条件④
for token in tokens :
split_words.append(token.surface) #形態素解析後の分割結果
if token.part_of_speech.startswith("動詞") : 条件⑤
judge = True
j = len(split_words) -1
while j >= 2 :
#条件⑥
if split_words[j-1] in split_words[j] or split_words[j-2] in split_words[j] :
judge = False
break
j -= 1
return judge
文章の要約
では実際に文章を要約するTransformerの実装を行っていきましょう。主に参考にした記事はこちらです。前提知識等の解説は、最終記事に書く予定なので、本記事ではコードのみ記載します。
まず必要なものをインストールします。なお、この順番でインストールすると、エラーが起きないようです(参考記事)
!pip install sentencepiece
!pip install transformers
トークナイザーとモデルをロードします。
from transformers import T5Tokenizer
from transformers import T5ForConditionalGeneration
model_name = "sonoisa/t5-base-japanese"
tokenizer = T5Tokenizer.from_pretrained(model_name)
model = T5ForConditionalGeneration.from_pretrained(model_name)
エンコーディングとデコーディング、そして、要約の生成関数は各々以下の通りです。
def encoding(text,tokneize) :
return tokneize.encode(text,padding=True,truncation=True,return_tensors="pt")
def generate_ids(model,input_ids,max_length) :
return model.generate(input_ids,
max_length=max_length,
repetition_penalty=8.0,
diversity_penalty=5.0,
temperature = 0.1,
num_beams=8,
num_beam_groups=4
)
def decoding(ids,tokenize) :
return tokenize.decode(ids, skip_special_tokens=True,clean_up_tokenization_spaces=True)
また、実際に要約文が文章としておかしくないかをis_summarystatement関数で判断し、要約文を完成させる関数である、make_statement関数も定義しておきます。
def make_steatment(steatment) :
temp_statements = []
summary_scentence = ""
for i in range(len(steatment)) :
summary_scentence += steatment[i]
#文章の終わりは、"、"か"。"で判断
if "、" in steatment[i] or "。" in steatment[i] or i == len(steatment) - 1 :
#"斬刀"か"魄刀"→"斬魄刀"
if "斬刀" in summary_scentence or "魄刀" in summary_scentence :
summary_scentence = summary_scentence.replace("魄刀","斬魄刀")
summary_scentence = summary_scentence.replace("斬刀","斬魄刀")
#文章として追加
temp_statements.append(summary_scentence)
summary_scentence = ""
#temp_statementsに同じ文章・単語が紛れていないかをCHECKし、
#紛れていたら削除する
i = 0
steatment_length = len(temp_statements)
while i < steatment_length :
#CHECK時に邪魔な句読点は削除しておく
del_scentence = temp_statements[i].replace("、", "").replace("。", "")
compare_index_list = [x for x in range(steatment_length) if x != i]
is_del = False
for j in compare_index_list :
#同じ文章・単語が紛れていたら、削除
if del_scentence in temp_statements[j] :
del temp_statements[i]
steatment_length -= 1
is_del = True
break
if not is_del :
i += 1
new_statments = ""
for s in temp_statements :
#要約文であるtemp_statementsが形態素解析時の条件①~⑥を満たせば、要約文として適用
if is_summarystatement(s) :
new_s = re.sub(r'[<>()【】]','',s)
new_statments += new_s
#print("新 : " , new_statments)
return new_statments
以上の関数を使った、要約プログラムは以下の通りです。
max_length = 350
summarize_lower_length = 60
after_summary_statements = []
for summary in before_summary_statements :
#print("要約前 : " , summary)
#要約を適用する文章が下限(今回は"60"")より大きければ要約対象
if len(summary) > summarize_lower_length :
#エンコーディング→テキスト生成→デコーディング
input_ids = encoding(summary,tokenizer)
summary_ids = generate_ids(model,input_ids,max_length)
summary_txt = decoding(summary_ids[0],tokenizer)
# 重複を除去
summary_txt = " ".join(list(set(summary_txt.split())))
# 不要な特殊トークンを削除
summary_txt =re.sub(r'[<>()【】]','',summary_txt)
# 不要な文末記号を削除
summary_txt = summary_txt.strip("。")
summary_txt = summary_txt.strip("、")
#print("要約文", summary_txt)
after_summary_statements.append(make_steatment(summary_txt))
else :
#print("要約前と同じ")
summary_txt = "同じ : " + summary
after_summary_statements.append(summary_txt)
after_summary_statements
評価と次記事予定
要約文がどうなるかを何パターンか見ていきます。
〇「剡月」
- 元の文章
柄に緒がつき、やや刃の広い斬魄刀。刀は腰に差さず、下げ緒を帯に結びつける形でぶら下げている。能力開放とともに柄の紐と刀身に炎を纏う焱熱系の斬魄刀で、口に含んだ自分の血を吹きかけることで刀身の炎を巨大化させる。卍解も修得済みだが、肉体に負担の大きいものらしく、重傷を負った状態では使用できない。ただし作中で卍解はしなかったため、能力は不明。
また、かつて自分も一度「最後の月牙天衝」を使ったことがあるような発言をしたが、詳しいことは最後まで明かされなかった。
一護の斬魄刀『斬月』と性質が近く、この斬魄刀をベースに一護が死神の力を取り戻すために浦原が開発し使用された「隊長格ら全死神の霊圧が込められた刀」が制作された(小説『The Death Save The Strawberry』より)。
解号は「燃えろ『剡月』(もえろ『〜』)」。
-
要約の前文(要約時に使用した文章)
-
柄に緒がつき、やや刃の広い斬魄刀。刀は腰に差さず、下げ緒を帯に結びつける形でぶら下げている。能力開放とともに柄の紐と刀身に炎を纏う焱熱系の斬魄刀で、口に含んだ自分の血を吹きかけることで刀身の炎を巨大化させる。卍解も修得済みだが、肉体に負担の大きいものらしく、重傷を負った状態では使用できない。ただし作中で卍解はしなかったため、能力は不明。また、かつて自分も一度最後の月牙天衝を使ったことがあるような発言をしたが、詳しいことは最後まで明かされなかった。一護の斬魄刀斬月と性質が近く、この斬魄刀をベースに一護が死神の力を取り戻すために浦原が開発し使用された隊長格ら全死神の霊圧が込められた刀が制作された。解号は燃えろ剡月。
-
要約文
-
解号は燃えろ月。柄に緒がつき、刀身には炎を纏う熱系の斬魄刀で能力は不明、
炎熱系の能力であることを熱系としていること、解号の斬魄刀名が月だけになっています。炎熱系と剡月という単語が認識されなかった可能性が考えられます。また、文章が読点で終了していますが、良い精度で要約されています。
〇ブック・オブ・ジ・エンド
月島さんの能力ですね。
- 元の文章
本の栞から変換した刀で斬りつけた対象の過去に自身の存在を挟み込み、相手の過去を改変させる能力を持つ。自身の存在は親戚や知り合い、恋人などさまざまな形で自在に挟み込めるために相手を抱き込むことも可能であり、その能力で遊子と夏梨、ケイゴ・たつき・水色、育美やXCUTIONメンバー、果ては織姫やチャドを取り込み、一護と銀城を孤立させた。また、それによって相手の過去や弱点をも把握できる。元の状態に戻すには、再度斬りつける必要がある。なお、能力を使わずに普通に斬りつけることも、もちろん可能。格上である相手にも通用し、白哉も月島によって記憶を改変された。ただし、今現在の相手の感情までは干渉できず、月島への感謝より一護への恩義を優先させた白哉には、最終的に切り伏せられている。『BLEACH Can't Fear Your Own World』では、軽微なダメージとはいえグリムジョーの鋼皮を突破する切れ味を見せたが、情よりも本能を優先する動物的な気性の人物には、過去を挟んでも効果が薄いことが判明した。さらに、生まれて数時間しか経っていないような相手には、過去を挟み込もうにも歴史が短すぎて有効的に作用しない。
また「挟む」対象は、人間のみならず物質や場所、相手の経験(技)などにさえも及び、その挟み込んだ対象に「以前来て細工しておいた」「元からそれを知っていた」「ともに開発した」などの過去を捏造することで、その場所に罠を仕掛けたり、相手の技を見切ることを可能とする。ただ、強引に過去を後から挟み込んだ場合、挟まれた人物の精神が矛盾に耐え切れずに崩壊する危険もある。
-
要約の前文(要約時に使用した文章)
-
本の栞から変換した刀で斬りつけた対象の過去に自身の存在を挟み込み、相手の過去を改変させる能力を持つ。自身の存在は親戚や知り合い、恋人などさまざまな形で自在に挟み込めるために相手を抱き込むことも可能であり、その能力で遊子と夏梨、ケイゴ・たつき・水色、育美やメンバー、果ては織姫やチャドを取り込み、一護と銀城を孤立させた。また、それによって相手の過去や弱点をも把握できる。元の状態に戻すには、再度斬りつける必要がある。なお、能力を使わずに普通に斬りつけることも、もちろん可能。格上である相手にも通用し、白哉も月島によって記憶を改変された。ただし、今現在の相手の感情までは干渉できず、月島への感謝より一護への恩義を優先させた白哉には、最終的に切り伏せられている。'では、軽微なダメージとはいえグリムジョーの鋼皮を突破する切れ味を見せたが、情よりも本能を優先する動物的な気性の人物には、過去を挟んでも効果が薄いことが判明した。さらに、生まれて数時間しか経っていないような相手には、過去を挟み込もうにも歴史が短すぎて有効的に作用しない。また挟む対象は、人間のみならず物質や場所、相手の経験などにさえも及び、その挟み込んだ対象に以前来て細工しておいた元からそれを知っていたともに開発したなどの過去を捏造することで、その場所に罠を仕掛けたり、相手の技を見切ることを可能とする。ただ、強引に過去を後から挟み込んだ場合、挟まれた人物の精神が矛盾に耐え切れずに崩壊する危険もある。
-
要約文
-
本の栞から変換した刀で斬りつけた対象の過去に自身の存在を挟み込み、相手の過去を改変させる能力を持つ、
後半の文章の過去を挟んだ対象に対する文章の要約が上手くいっていないように見えます。というより、最初の1文をそのまま要約文としています。
〇万物貫通(ジ・イグザクシス/The X-axis)
- 元の文章
聖文字“X”の能力。霊子兵装の銃口にX字の意匠がある巨大なライフル「ディアグラム」の射線上にある物体を等しく貫通する。
能力発動には狙撃の動作を取るが、その本質は弾丸そのものを発射しているわけではなく「銃口の先の物体を等しく貫通する」為、相手が標的を守ろうと何重に障壁を作ろうとも射程内にいる限り被害は免れず、引き金を引いた瞬間に攻撃が完了するため回避の余地がない。また、身体も万物貫通状態になり、たとえ刀で斬られたとしても刀が体を貫通するため武器で倒すことは不可能。この能力を使えるのは両目を開けているときのみで、さらに戦闘中のごく短い瞬間に限られているが、3度開くと以降開いたまま戦闘を行える。京楽に敗れた後は能力自体が失われた。
雑誌掲載時には、「石物貫通」と誤植されていた。
-
要約の前文(要約時に使用した文章)
-
聖文字“"の能力。霊子兵装の銃口に字の意匠がある巨大なライフルディアグラムの射線上にある物体を等しく貫通する。能力発動には狙撃の動作を取るが、その本質は弾丸そのものを発射しているわけではなく銃口の先の物体を等しく貫通する為、相手が標的を守ろうと何重に障壁を作ろうとも射程内にいる限り被害は免れず、引き金を引いた瞬間に攻撃が完了するため回避の余地がない。また、身体も万物貫通状態になり、たとえ刀で斬られたとしても刀が体を貫通するため武器で倒すことは不可能。この能力を使えるのは両目を開けているときのみで、さらに戦闘中のごく短い瞬間に限られているが、3度開くと以降開いたまま戦闘を行える。京楽に敗れた後は能力自体が失われた。雑誌掲載時には、石物貫通と誤植されていた。
-
要約文
-
京楽に敗れた後は能力自体が失われた
力というキーワードを重視しすぎたせいで、上記文と聖文字“"の能力をキーワードとして入力してしまったのが一つの要因と考えています。ブック・オブ・ジ・エンドのときと同様、文章の長さに応じて文章を分割し、各々にキーワードを抽出するという方法を今後考えてみたいです。
要約ができない&要約結果が、ネガティブな文章になってしまったことは、罪深かかったです。反省します。
他の技・能力も上の例のように、
- ある程度上手く要約できたが、単語単位でみると省略しすぎている
- 要約文自体はできているが、一部の部分しか要約できていない
- 技・力という今回重要としたキーワードの絞り方が間違えたからか、変な要約文になった
という他、そもそも上手くいっていない例も散見されており、上述の通り、キーワード抽出の方法の変更や技・力のように、私の即断で決めてしまった文章選定の基準をtfidf等、文章への重要度を測定するための手法の組込などをすることで要約精度を挙げられると考えているので、次の記事では、これらのことを考慮しつつ訓練データの構築を実施していきたいです。
最後に
BLEACH 千年血戦篇第2クール、2023年7月放送開始です。
是非、見てください!!
参考文献
BLEACHの登場人物
前記事
RequestsとBeautifulSoupでWikipediaをスクレイピングするサンプルコード
PytorchのTransformersのT5を使って要約モデルを作る
【Transformer】tokenizerでNoneType エラーが出た場合
scikit-learnでTF-IDFを計算する
T5について
Discussion