1-③[AI][Kaggle]Kaggle入門(機械学習Intro 3.初めての機械学習モデル)
Kaggle入門1 機械学習Intro 1.モデルの仕組み
Kaggle入門1 機械学習Intro 2.基本的なデータ探索
Kaggle入門1 機械学習Intro 3.初めての機械学習モデル
Kaggle入門1 機械学習Intro 4.モデルの検証
Kaggle入門1 機械学習Intro 5.アンダーフィッティングとオーバーフィッティング
Kaggle入門1 機械学習Intro 6. ランダムフォレスト
Kaggle入門1 機械学習Intro 7. 機械学習コンペティション 最終回
→Kaggle入門2 Python Pandasライブラリの使い方 1.生成/読込/書込
Kaggle入門(機械学習Intro 2.基本的なデータ探索)の続きです。
Abstract
Kaggle「Intro to Machine LearningのYour First Machine Learning Model」の翻訳と実行方法の解説
3. 初めての機械学習モデル
理論編
🤖 モデリングのためのデータの選択 (Selecting Data for Modeling)
あなたのデータセットには、把握したり、きれいに印刷することさえ難しいほど多くの変数が含まれていました。この圧倒的な量のデータを、理解できるものに絞り込むにはどうすればよいでしょうか?
まず、直感を使っていくつかの変数を選ぶことから始めます。後のコースでは、変数の優先順位を自動的に決定するための統計的手法を紹介します。
変数(列)を選択するためには、データセット内のすべての列のリストを見る必要があります。これは、DataFrameの columns プロパティ(以下のコードの最後の行)を使って行います。
import pandas as pd
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
melbourne_data = pd.read_csv(melbourne_file_path)
melbourne_data.columns
Index(['Suburb', 'Address', 'Rooms', 'Type', 'Price', 'Method', 'SellerG',
'Date', 'Distance', 'Postcode', 'Bedroom2', 'Bathroom', 'Car',
'Landsize', 'BuildingArea', 'YearBuilt', 'CouncilArea', 'Lattitude',
'Longtitude', 'Regionname', 'Propertycount'],
dtype='object')
メモ: メルボルンのデータには欠損値(一部の住宅で記録されていない変数がある)が含まれています。欠損値の扱いは後のチュートリアルで学びます。今回のアイオワのデータには、使用する列に欠損値はありません。 そのため、今のところは最も簡単なオプションとして、データから該当する住宅を削除します。今のところは、この点についてあまり心配しないでください。コードは以下の通りです。
# dropna は欠損値(na は "not available"、利用不可の意)を削除します。
melbourne_data = melbourne_data.dropna(axis=0)
データの一部を選択する方法はたくさんあります。Pandasコースではこれらをより詳しく掘り下げますが、ここでは今のところ2つのアプローチに焦点を当てます。
- ドット記法("予測ターゲット"を選択するために使用)
- 列リストによる選択("特徴量"を選択するために使用)
🎯 予測ターゲットの選択 (Selecting The Prediction Target)
変数はドット記法を使って取り出すことができます。この単一の列はSeriesに格納されます。Seriesは、おおまかに言えば、データが1列しかないDataFrameのようなものです。
私たちは、予測したい列、すなわち予測ターゲットを選択するためにドット記法を使います。慣例として、予測ターゲットは y と呼ばれます。したがって、メルボルンデータ内の住宅価格を保存するために必要なコードは以下のようになります。
y = melbourne_data.Price
✨ 「特徴量」の選択 (Choosing "Features")
モデルに入力され(そして後に予測を行うために使用される)列は**「特徴量」(features)**と呼ばれます。私たちの場合、それらは住宅価格を決定するために使われる列になります。ターゲットを除くすべての列を特徴量として使うこともあれば、より少ない特徴量の方が良い結果になることもあります。
今のところは、いくつかの特徴量のみを使ってモデルを構築します。後で、異なる特徴量で構築されたモデルを反復して比較する方法を確認します。
複数の特徴量を選択するには、角括弧 [] の中に列名のリストを提供します。そのリスト内の各項目は、文字列(引用符で囲む)である必要があります。
例は以下の通りです。
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'Lattitude', 'Longtitude']
慣例として、このデータは X と呼ばれます。
X = melbourne_data[melbourne_features]
describe メソッドと、最初の数行を表示する head メソッドを使って、住宅価格の予測に使用するデータを手早く確認しましょう。
X.describe()
| Rooms | Bathroom | Landsize | Lattitude | Longtitude | |
|---|---|---|---|---|---|
| count | 6196.000000 | 6196.000000 | 6196.000000 | 6196.000000 | 6196.000000 |
| mean | 2.931407 | 1.576340 | 471.006940 | -37.807904 | 144.990201 |
| std | 0.971079 | 0.711362 | 897.449881 | 0.075850 | 0.099165 |
| min | 1.000000 | 1.000000 | 0.000000 | -38.164920 | 144.542370 |
| 25% | 2.000000 | 1.000000 | 152.000000 | -37.855438 | 144.926198 |
| 50% | 3.000000 | 1.000000 | 373.000000 | -37.802250 | 144.995800 |
| 75% | 4.000000 | 2.000000 | 628.000000 | -37.758200 | 145.052700 |
| max | 8.000000 | 8.000000 | 37000.000000 | -37.457090 | 145.526350 |
X.head()
| Rooms | Bathroom | Landsize | Lattitude | Longtitude | |
|---|---|---|---|---|---|
| 1 | 2 | 1.0 | 156.0 | -37.8079 | 144.9934 |
| 2 | 3 | 2.0 | 134.0 | -37.8093 | 144.9944 |
| 4 | 4 | 1.0 | 120.0 | -37.8072 | 144.9941 |
| 6 | 3 | 2.0 | 245.0 | -37.8024 | 144.9993 |
| 7 | 2 | 1.0 | 256.0 | -37.8060 | 144.9954 |
これらのコマンドを使用してデータを視覚的に確認することは、データサイエンティストの仕事の重要な部分です。ときに、データセットにはさらなる調査に値する驚くべきことが頻繁に見つかります。
🏗️ モデルの構築 (Building Your Model)
モデルの作成には、scikit-learn ライブラリを使用します。サンプルコードで確認できるように、コーディング上ではこのライブラリは sklearn と記述されます。scikit-learn は、DataFrameに通常格納されるタイプのデータをモデリングするための、間違いなく最も人気のあるライブラリです。
モデルを構築し、使用するためのステップは以下の通りです。
- 定義 (Define): どのような種類のモデルにするか? 決定木か? それとも他の種類のモデルか? モデルの種類のその他のパラメータもここで指定します。
- 適合 (Fit): 提供されたデータからパターンを捉えます。これはモデリングの中心となる作業です。
- 予測 (Predict): その名の通り、予測を行います。
- 評価 (Evaluate): モデルの予測がどの程度正確であるかを判断します。
scikit-learnを使って決定木モデルを定義し、特徴量とターゲット変数で適合させる例を以下に示します。
from sklearn.tree import DecisionTreeRegressor
# モデルを定義。実行ごとに同じ結果を保証するために random_state に数値を指定
melbourne_model = DecisionTreeRegressor(random_state=1)
# モデルを適合
melbourne_model.fit(X, y)
DecisionTreeRegressor(random_state=1)
多くの機械学習モデルでは、モデルの訓練にある程度のランダム性が許容されます。random_state に数値を指定することで、実行ごとに同じ結果が得られることが保証されます。これは良い習慣と考えられています。どの数値を設定しても構いません。モデルの品質は、あなたが選択した正確な値に大きく依存することはありません。
これで、予測を行うために使用できる適合済みモデルができました。
実際には、すでに価格がわかっている住宅ではなく、市場に出てくる新しい住宅に対して予測を行いたいと考えるでしょう。しかし、ここでは predict 関数がどのように機能するかを見るために、訓練データの最初の数行について予測を行います。
print("Making predictions for the following 5 houses:")
print(X.head())
print("The predictions are")
print(melbourne_model.predict(X.head()))
Making predictions for the following 5 houses:
| Rooms | Bathroom | Landsize | Lattitude | Longtitude | |
|---|---|---|---|---|---|
| 1 | 2 | 1.0 | 156.0 | -37.8079 | 144.9934 |
| 2 | 3 | 2.0 | 134.0 | -37.8093 | 144.9944 |
| 4 | 4 | 1.0 | 120.0 | -37.8072 | 144.9941 |
| 6 | 3 | 2.0 | 245.0 | -37.8024 | 144.9993 |
| 7 | 2 | 1.0 | 256.0 | -37.8060 | 144.9954 |
The predictions are
[1035000. 1465000. 1600000. 1876000. 1636000.]
実践編
ここまでのまとめ
データを読み込み、以下のコードで確認しました。下記赤丸のセルを実行して、前のステップで中断したコーディング環境をセットアップしてください。
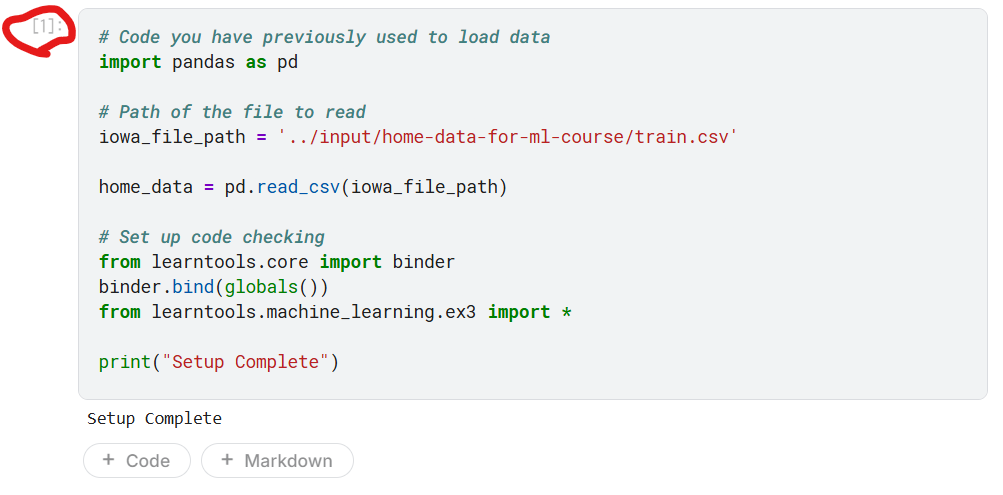
演習
ステップ1:予測対象を指定する
販売価格に対応するターゲット変数を選択します。これを「y」という新しい変数に保存します。必要な列の名前を見つけるには、列のリストを確認する必要があります。

これを「y」という新しい変数に保存するコードです。下記赤丸を実行してください。

この演習のヒントと答えです。

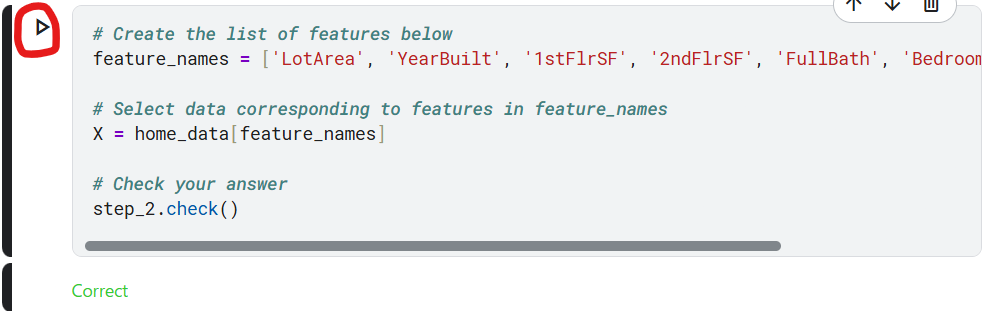
ステップ2:Xを生成
予測特徴量を含む X という DataFrame を作成します。 元データから一部の列のみを取得したいので、まず X に必要な列名のリストを作成します。
リスト内の次の列のみを使用します (入力の手間を省くためにリスト全体をコピーして貼り付けることもできますが、その場合でも引用符を追加する必要があります)。
下記赤丸を実行してください。
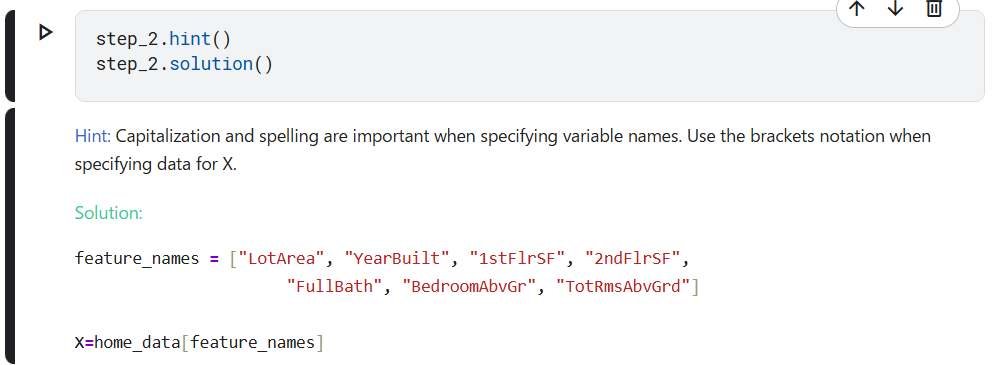
この演習のヒントと答えです。
下記赤丸を実行してください。
データの確認
モデルを構築する前に、Xをざっと見て、妥当かどうかを確認してください。
下記赤丸を実行してください。

ステップ3:モデルの指定と適合
Decision Treeの予測変数を作成し、iowa_model として保存します。このコマンドを実行するには、sklearn から必要なインポートが完了していることを確認してください。 次に、上記で保存した X と y のデータを使用して、作成したモデルを適合させます。
下記赤丸を実行してください。

この演習のヒントと答えです。
下記赤丸を実行してください。

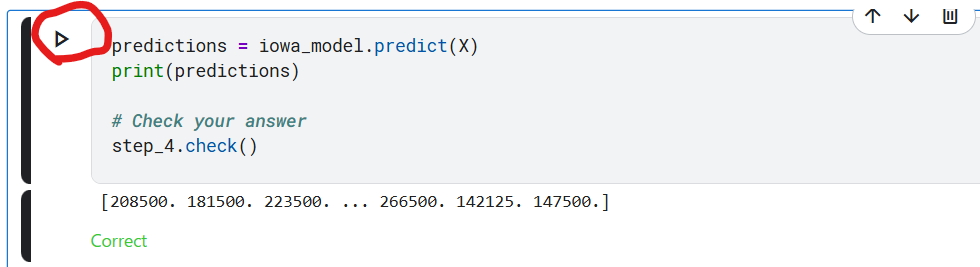
ステップ4:予測を行う
Xをデータとしてモデルの予測コマンドで予測を行い、結果をpredictionsという変数に保存します。
下記赤丸を実行してください。
この演習のヒントと答えです。
下記赤丸を実行してください。

結果について考えてみる。
head関数を使って、上位数件の予測と、同じ住宅の実際の住宅価格(y単位)を比較します。結果はどうなったでしょうか?

モデルの予測精度はどの程度なのか、そしてそれをどのように改善できるのかを疑問に思うのは当然です。それが次のステップになります。
次の章(4.モデルの検証)へ
下記も参考になりました。
Discussion