2-①[AI][Kaggle][python]Kaggle入門(Pandasライブラリの使い方 1.生成/読込/書込)
Kaggle入門2(Pandasライブラリの使い方 1.生成/読込/書込)
Kaggle入門2(Pandasライブラリの使い方 2.インデックス作成、選択、割り当て)
Kaggle入門2(Pandasライブラリの使い方 3.生成/読込/書込)
Kaggle入門2(Pandasライブラリの使い方 4.生成/読込/書込)
Kaggle入門2(Pandasライブラリの使い方 5.生成/読込/書込)
Kaggle入門2(Pandasライブラリの使い方 6.生成/読込/書込)
← Kaggle入門1 機械学習Intro 1.モデルの仕組み
生成AI作る人への道。
「Python」っ言語のPandasライブラリの使い方を必須ってレベルで知っとく必要がある。Excelで操作するときとかもすごい便利なのでこの機会に覚えましょう。
とはいえ全編英語でお送り中なので翻訳しながら進めてみました。英語なのでニの足を踏んでる人向けに役に立つのではないかと。
Abstract
Kaggle「PandasのCreating, Reading and Writing」の翻訳と実行方法の解説
1. 生成/読込/書込
理論編
序論 (Introduction)
このマイクロコースでは、データ分析において最も人気のあるPythonライブラリ「pandas」についてすべてを学びます。
学習を進めながら、実際のデータを使ったいくつかの実践的な演習を行います。チュートリアルを読みながら、対応する演習に取り組むことをお勧めします。
このチュートリアルでは、独自のデータを作成する方法と、既存のデータを扱う方法について学びます。
はじめに
pandasを使用するには、通常、次のコード行から始めます
import pandas as pd
データの作成
pandasには、**DataFrame(データフレーム)とSeries(シリーズ)**という2つの主要なオブジェクトがあります。
DataFrame
DataFrameは「表」です。個々のエントリ(項目)の配列を含み、それぞれが特定の値を持ちます。各エントリは「行(レコード)」と「列」に対応しています。
例えば、次の単純なDataFrameを見てみましょう。
pd.DataFrame({'Yes': [50, 21], 'No': [131, 2]})
| Yes | No | |
|---|---|---|
| 0 | 50 | 131 |
| 1 | 21 | 2 |
この例では、「0行目のNo」のエントリは131という値を持ち、「0行目のYes」のエントリは50という値を持ちます。
DataFrameのエントリは整数に限定されません。例えば、値が文字列であるDataFrameは次のようになります。
pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'], 'Sue': ['Pretty good.', 'Bland.']})
| Bob | Sue | |
|---|---|---|
| 0 | I liked it. | Pretty good. |
| 1 | It was awful. | Bland. |
ここでは pd.DataFrame() コンストラクタを使用して、これらのDataFrameオブジェクトを生成しています。新しいDataFrameを宣言する構文は、「キーが列名(この例ではBobとSue)」で「値がエントリのリスト」である辞書形式です。これが新しいDataFrameを構築する標準的な方法であり、最もよく目にする形式です。
この「辞書とリスト」によるコンストラクタは、列のラベルに値を割り当てますが、行のラベルには 0 から始まる昇順の数値(0, 1, 2, 3...)をそのまま使用します。これで問題ない場合もありますが、自分で行ラベルを割り当てたいことも多々あります。
DataFrameで使用される行ラベルのリストは Index(インデックス) と呼ばれます。コンストラクタで index パラメータを使用することで、これに値を割り当てることができます。
pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'],
'Sue': ['Pretty good.', 'Bland.']},
index=['Product A', 'Product B'])
| Bob | Sue | |
|---|---|---|
| Product A | I liked it. | Pretty good. |
| Product B | It was awful. | Bland. |
Series
対照的に、Seriesはデータの値の「シーケンス(連続した集まり)」です。DataFrameが表であるなら、Seriesは「リスト」です。実際、リストひとつあれば作成できます。
pd.Series([1, 2, 3, 4, 5])
0 1
1 2
2 3
3 4
4 5
dtype: int64
Seriesは、本質的にはDataFrameの「単一の列」です。そのため、先ほどと同じように index パラメータを使用して行ラベルを割り当てることができます。ただし、Seriesには列名(column name)はなく、全体を指す name(名前)という属性のみを持ちます。
pd.Series([30, 35, 40], index=['2015 Sales', '2016 Sales', '2017 Sales'], name='Product A')
SeriesとDataFrameは密接に関連しています。 DataFrameは、実際には多くのSeriesが「貼り合わされたもの」 と考えると分かりやすいでしょう。これについては、チュートリアルの次のセクションで詳しく説明します。
データファイルの読み込み
手作業でDataFrameやSeriesを作成できるのは便利です。しかし、ほとんどの場合、自分たちでデータを手入力することはありません。その代わりに、すでに存在するデータを扱います。
データはさまざまな形式で保存されますが、群を抜いて基本的なのが、質素なCSVファイルです。CSVファイルを開くと、次のようになります。
Product A,Product B,Product C,
30,21,9,
35,34,1,
41,11,11
つまり、CSVファイルは「カンマで区切られた値の表」です。そのため、「Comma-Separated Values(CSV)」という名前がついています。
それでは、練習用のデータセットを脇に置いて、実際のデータセットをDataFrameに読み込んだときにどう見えるかを確認しましょう。データの読み込みには pd.read_csv() 関数を使用します。
wine_reviews = pd.read_csv("../input/wine-reviews/winemag-data-130k-v2.csv")
shape 属性を使用して、結果のDataFrameがどれくらいの大きさかを確認できます。
wine_reviews.shape
# 結果: (129971, 14)
この新しいDataFrameには、14の異なる列にわたって約13万件のレコードがあります。エントリの総数は約200万個にもなります!
head() コマンドを使用すると、出来上がったDataFrameの内容を確認できます。これは最初の5行を抽出するコマンドです。
wine_reviews.head()
| Unnamed: 0 | country | description | designation | points | price | province | region_1 | region_2 | taster_name | taster_twitter_handle | title | variety | winery | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | Italy | Aromas include tropical fruit, broom, brimston... | Vulkà Bianco | 87 | NaN | Sicily & Sardinia | Etna | NaN | Kerin O’Keefe | @kerinokeefe | Nicosia 2013 Vulkà Bianco (Etna) | White Blend | Nicosia |
| 1 | 1 | Portugal | This is ripe and fruity, a wine that is smooth... | Avidagos | 87 | 15.0 | Douro | NaN | NaN | Roger Voss | @vossroger | Quinta dos Avidagos 2011 Avidagos Red (Douro) | Portuguese Red | Quinta dos Avidagos |
| 2 | 2 | US | Tart and snappy, the flavors of lime flesh and... | NaN | 87 | 14.0 | Oregon | Willamette Valley | Willamette Valley | Paul Gregutt | @paulgwine | Rainstorm 2013 Pinot Gris (Willamette Valley) | Pinot Gris | Rainstorm |
| 3 | 3 | US | Pineapple rind, lemon pith and orange blossom ... | Reserve Late Harvest | 87 | 13.0 | Michigan | Lake Michigan Shore | NaN | Alexander Peartree | NaN | St. Julian 2013 Reserve Late Harvest Riesling ... | Riesling | St. Julian |
| 4 | 4 | US | Much like the regular bottling from 2012, this... | Vintner's Reserve Wild Child Block | 87 | 65.0 | Oregon | Willamette Valley | Willamette Valley | Paul Gregutt | @paulgwine | Sweet Cheeks 2012 Vintner's Reserve Wild Child... | Pinot Noir | Sweet Cheeks |
pd.read_csv() 関数は非常に多機能で、指定できるオプションのパラメータが30以上あります。例えば、このデータセットではCSVファイル自体にインデックスが含まれていますが、pandasはそれを自動的には認識しません。pandasに(新しく作り直すのではなく)その列をインデックスとして使わせるには、index_col を指定することができます。
wine_reviews = pd.read_csv("../input/wine-reviews/winemag-data-130k-v2.csv", index_col=0)
wine_reviews.head()
| country | description | designation | points | price | province | region_1 | region_2 | taster_name | taster_twitter_handle | title | variety | winery | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Italy | Aromas include tropical fruit, broom, brimston... | Vulkà Bianco | 87 | NaN | Sicily & Sardinia | Etna | NaN | Kerin O’Keefe | @kerinokeefe | Nicosia 2013 Vulkà Bianco (Etna) | White Blend | Nicosia |
| 1 | Portugal | This is ripe and fruity, a wine that is smooth... | Avidagos | 87 | 15.0 | Douro | NaN | NaN | Roger Voss | @vossroger | Quinta dos Avidagos 2011 Avidagos Red (Douro) | Portuguese Red | Quinta dos Avidagos |
| 2 | US | Tart and snappy, the flavors of lime flesh and... | NaN | 87 | 14.0 | Oregon | Willamette Valley | Willamette Valley | Paul Gregutt | @paulgwine | Rainstorm 2013 Pinot Gris (Willamette Valley) | Pinot Gris | Rainstorm |
| 3 | US | Pineapple rind, lemon pith and orange blossom ... | Reserve Late Harvest | 87 | 13.0 | Michigan | Lake Michigan Shore | NaN | Alexander Peartree | NaN | St. Julian 2013 Reserve Late Harvest Riesling ... | Riesling | St. Julian |
| 4 | US | Much like the regular bottling from 2012, this... | Vintner's Reserve Wild Child Block | 87 | 65.0 | Oregon | Willamette Valley | Willamette Valley | Paul Gregutt | @paulgwine | Sweet Cheeks 2012 Vintner's Reserve Wild Child... | Pinot Noir | Sweet Cheeks |
実践編
Introduction
最初のステップは、データファイルの読み取りです。この実践編では、手作業とデータファイルの読み取りの両方で、SeriesオブジェクトとDataFrameオブジェクトを作成します。
import pandas as pd
pd.set_option('display.max_rows', 5)
from learntools.core import binder; binder.bind(globals())
from learntools.pandas.creating_reading_and_writing import *
print("Setup complete.")
下記赤丸をクリック。Setup complete.が表示されればOK.

課題1.
下記のような DataFrame を作成します。

下記赤丸をクリック。Correctが表示されるとOK。

下記赤丸をクリックすると、ヒントと答えが表示されます。

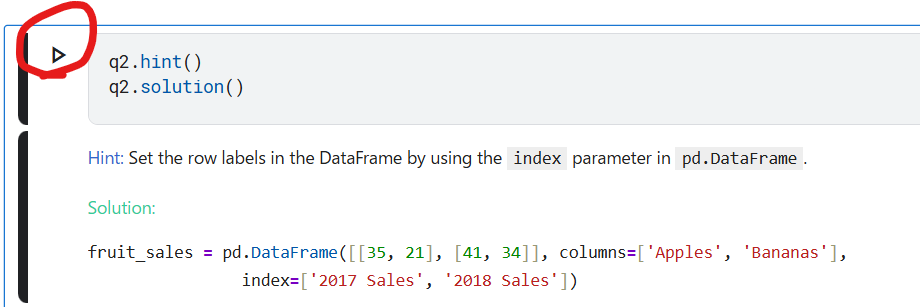
課題2.
下記赤丸をクリック。Correctが表示されるとOK。

下記赤丸をクリックすると、ヒントと答えが表示されます。
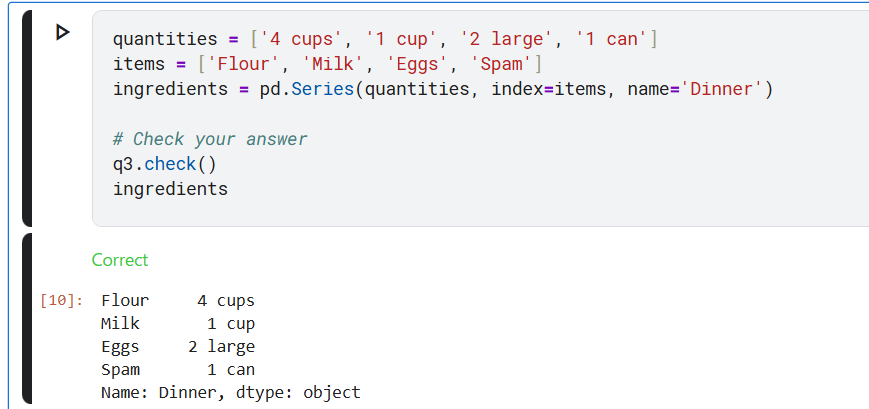
課題3.
次のようなSeries変数「材料」を作成します。
- 小麦粉 4カップ
- 牛乳 1カップ
- 卵 Lサイズ 2個
- スパム 1缶
- 名前: Dinner : dtype: object
下記赤丸をクリック。Correctが表示されるとOK。
下記赤丸をクリックすると、ヒントと答えが表示されます。
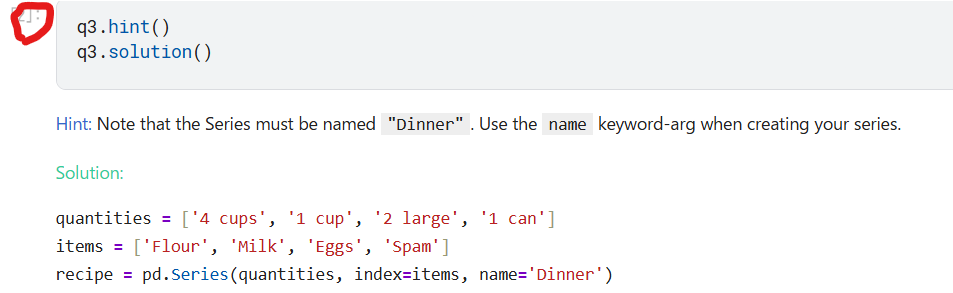
課題4.
次のワインのレビューの csv データセットを reviews という DataFrame に読み込みます。

csvファイルへのファイルパスは../input/wine-reviews/winemag-data_first150k.csvです。最初の数行は以下のようになります。
,country,description,designation,points,price,province,region_1,region_2,variety,winery
0,US,"This tremendous 100% varietal wine[...]",Martha's Vineyard,96,235.0,California,Napa Valley,Napa,Cabernet Sauvignon,Heitz
1,Spain,"Ripe aromas of fig, blackberry and[...]",Carodorum Selección Especial Reserva,96,110.0,Northern Spain,Toro,,Tinta de Toro,Bodega Carmen Rodríguez
下記赤丸をクリック。Correctが表示されるとOK。

下記赤丸をクリックすると、ヒントと答えが表示されます。

課題5.
以下のセルを実行して、animals という DataFrame を作成して表示します。

下のセルに、この DataFrame を cows_and_goats.csv という名前の csv ファイルとしてディスクに保存するコードを記述します。
下記赤丸をクリック。Correctが表示されるとOK。

下記赤丸をクリックすると、ヒントと答えが表示されます。

完了
次の章2.インデックス作成、選択、割り当てへ
Discussion