AWS GenU 機能紹介 目次
はじめに
プログデンスの圓佛です。 AWS が公開している生成 AI アプリケーションのサンプルである GenU (Generative AI Use Cases) のうち、この記事では「音声認識」機能について説明します。
基本的な使い方
音声認識機能を使うと「音声データ」を「文字データ」へ変換することが出来ます。 入力する音声データは「マイクから入力」「ファイルから入力」どちらでも問題ありません。 入力データに音声ファイルを利用する場合、「ファイルを選択」をクリックして対象の音声ファイルを指定してから「実行」をクリックします。 音声ファイルの長さに応じて時間がかかりますが、処理が完了したら認識された文字データが表示されます。
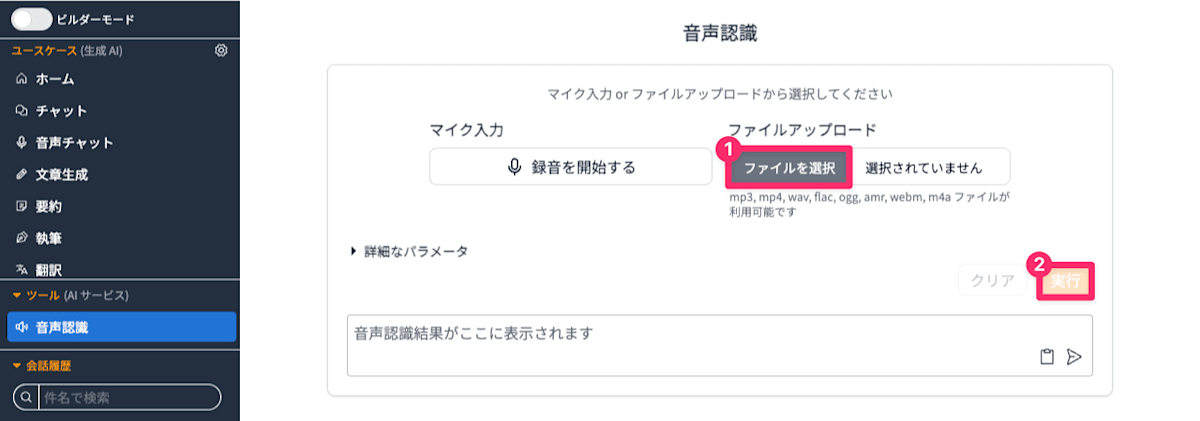
音声をアップロードして文字起こしする
サンプル音声/無料ダウンロード から以下の音声ファイルをダウンロードして利用させて頂きました。
G-21 (51 秒)
ナレーション原稿(始皇陵)
<注文データ>
文字数:100文字 / 速度:標準 / タイプ(性別):男性
タイプ(イメージ):元気に / 声のイメージ:弾むように
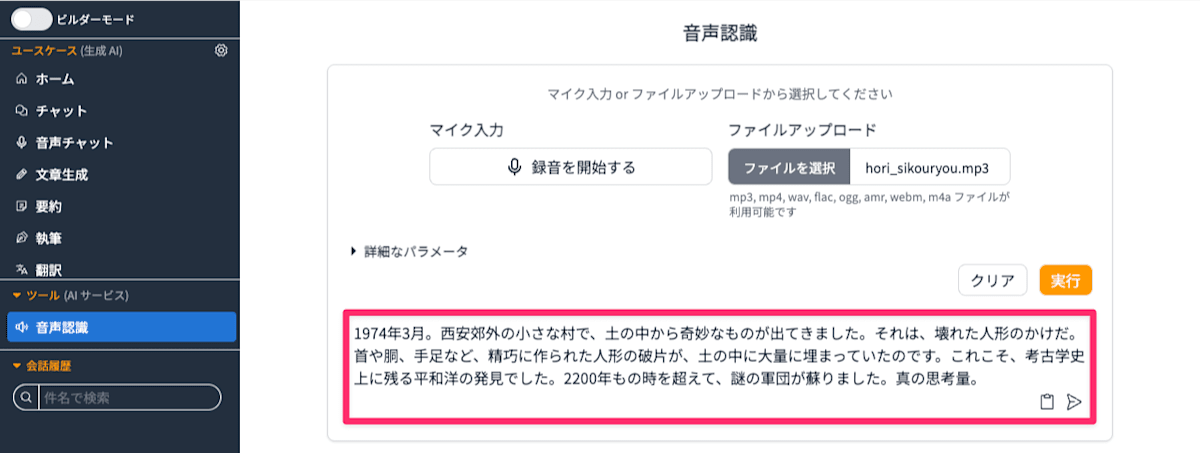
これを音声認識処理させると以下の結果になりました。 それなりに認識されていますが、うまく認識出来ていない部分もあります。
1974年3月。西安郊外の小さな村で、土の中から奇妙なものが出てきました。それは、壊れた人形のかけだ。首や胴、手足など、精巧に作られた人形の破片が、土の中に大量に埋まっていたのです。これこそ、考古学史上に残る平和洋の発見でした。2200年もの時を超えて、謎の軍団が蘇りました。真の思考量。
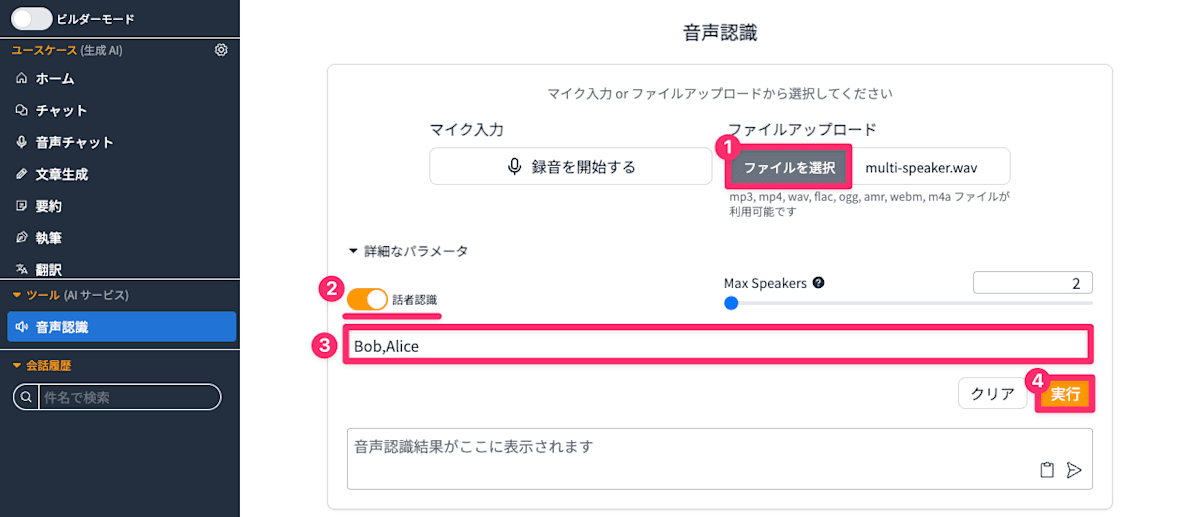
複数の話者を認識して文字起こしする
オンライン会議を録音した場合、複数の話者が登場することが多いと予想されます。 GenU の音声認識機能では複数話者を識別することも可能です。 複数話者を識別したい場合は「ファイルを選択」をクリックして入力データを指定した後、「詳細なパラメータ」の「話者認識」を有効化し、その下のテキストエリアに話者の名前をカンマ区切りで記載します。 指定が完了したら「実行」をクリックします。
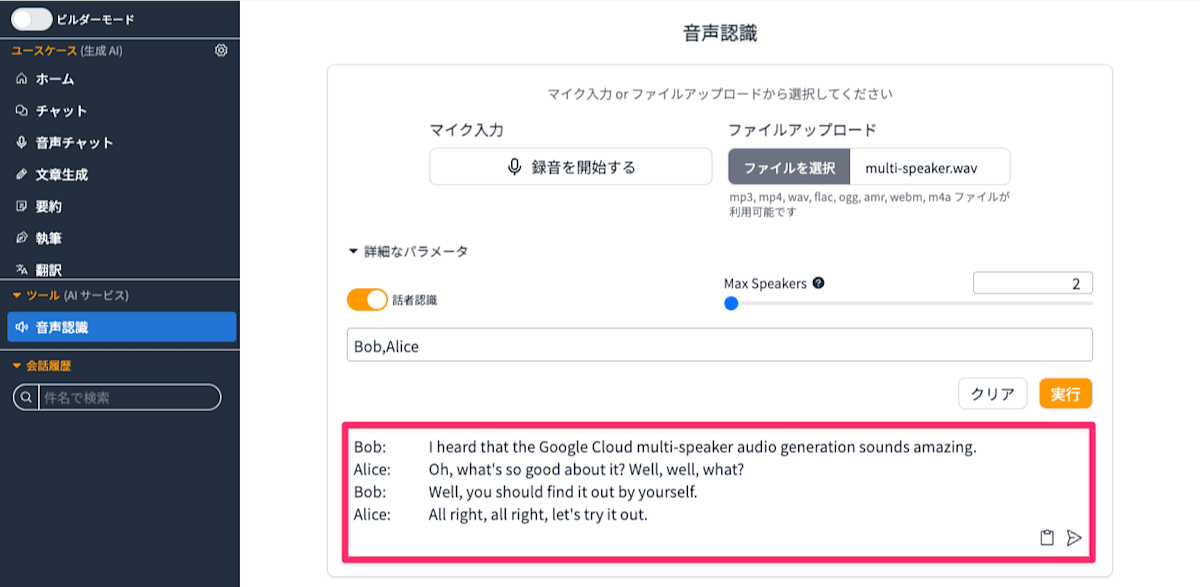
実際に 複数の話者による会話を生成する から音声サンプルデータをダウンロードして試してみます。 すると以下のように複数の話者を識別して音声認識処理されます。

株式会社プログデンス/BtoB向けのITソリューションを提供する企業です。 技術スタック: SASE / Prisma Access / Zscaler / Netskope / Cato Networks / Tanium / M365 / Cisco / Automation / Ansible