こんにちは上野(@ueeeeniki)です。
みなさんの会社では、今年のDev DayでOpenAIが発表した蒸留機能であるModel Distillationをうまく活用できているでしょうか。
蒸留とは、大きいモデルの出力を小さいモデルの学習に利用する方法です。これにより、大きいモデルに匹敵する精度を持つ小さいモデルを作ることができます。
この蒸留を行うModel Distillationという新機能を上手く使えばLLMアプリケーションのコストを劇的に削減することができます。
例えば、GPT-4oの出力を使って蒸留したGPT-4o-miniの料金は、下記の表では、fine-tuned gpt-4o-miniにあたります。
ファインチューニングしたGPT-4o-miniのコストは、生のGPT-4o-miniの2倍ですが、それでもGPT-4oの約1/10のコストです。
| モデル | 料金 |
|---|---|
| gpt-4o-2024-08-06 | $2.50 / 1M input tokens $10.00 / 1M output tokens |
| gpt-4o-2024-05-13 | $5.00 / 1M input tokens $15.00 / 1M output tokens |
| gpt-4o-mini | $0.150 / 1M input tokens $0.600 / 1M output tokens |
| fine-tuned gpt-4o-mini | $0.30 / 1M input tokens $1.20 / 1M output tokens |
私たちは以前にもGPT-4o-miniをファインチューニングして運用しているというお話をシェアして大きな反響いただきました。
上の記事では、GPT-4oの出力を人手で修正(アノテーション)して、GPT-4-miniをファインチューニングする運用をご紹介していますが、蒸留はGPT-4oの出力をそのまま使用するのが大きな違いです。
また、今回の発表の肝は、この蒸留をOpenAIのDashboad上で簡単に行えるようになったことです。
ですが、他社さんでも実際に蒸留を使っているというお話はあまり聞ないので、蒸留の基本とModel Distillationの使い方をご紹介しつつ、使い所と注意点をシェアしたいと思います。
o1-previewとo1-miniが同時に発表されたことを見ても、今後も"高性能で高価なモデル"と"少し性能は劣るが安価なモデル"は(多少の時期の違いがあっても)セットでリリースされる流れは続きそうです。
今回蒸留が公式にサポートされたことで、利用者は実質安価なモデルの料金で、高価なモデルと同程度の性能を手に入れたことになります。
OpenAI社からすれば売上は小さくなってしまいそうですが、ユーザーの利便性を高め、LLM利用のハードルを下げることにそれだけ本気ということでしょう。
あくまで個人的な予想ですが、AnthropicもClaudeのOpus、Sonnet、Haikuという異なるグレードのモデルを出しており、ファインチューニングも提供していることから、他社も蒸留を公式に提供するという追従を見せてもおかしくはないと思っています。
OpenAI DevDay 2024の発表内容概要と蒸留(Model Distillation)
-
リアルタイムAPI
音声入力と音声出力をリアルタイムで処理するAPIです。これまでは音声処理のアプリケーションを作ろうと思うと、複数のモデルを組み合わせる必要がありましたが、1つのAPIで実現できるようになりました。 -
Vision Fine-tuning(画像のファインチューニング)
GPT-4oを画像とテキストの両方でファインチューニングすることを可能にする機能です。 -
Prompt Caching(プロンプトのキャッシュ化)
一度使用したプロンプトをキャッシュすることで、API呼び出しのコストとレイテンシを削減する機能です。先にClaudeで提供されたことで有名になりました。特に長いプロンプトや頻繁に使用するプロンプトを使用する場合に有効です。 -
Model Distillation(モデルの蒸留)
大規模なモデルの出力を使用して、より小型で効率的なモデルをファインチューニングする技術です。これにより、大規模モデルと同等のパフォーマンスでコストとレイテンシを大幅に削減したモデルを作成できます。
今回取り上げる「蒸留(distillation)」は、従来の機械学習でも使われていた用語で、大きなモデルの出力を使って、小さいモデルを学習させる手法です。
大きな機械学習モデルはコストも掛かりますし、計算速度も遅いので、より軽量で安価なモデルで置き換えていこうという発想自体は一昔前からあったということです。
また、冒頭でもご紹介した『GPT-4o-miniのファインチューニングのすゝめ』という記事では、LangSmithというLangChain社が提供するLLMOpsツールを使用してデータセットを作成していましたが、
今回のModel DistillationはOpenAIが公式に提供しており、OpenAIのDashboad内で簡単に蒸留を行えるのが大きな特長です。
(※ 今後、OpenAIの機能を呼ぶときはModel Distillation、行為を指すときは蒸留と表記します。)
運用中のLLMアプリケーションのコストを削減する方法
蒸留はLLMの利用コストを大幅に削減するための手法ですが、その他に精度を下げずに運用中のLLMのコストを削減する方法は実は限られています。
かつて取り得たコスト削減方法は、
- ①LLMの入出力結果をキャッシュして再利用する
- ②自社でデータセットを作成して安価なモデルを作成 or ファインチューニングする(※ただし、規約による大幅な制限あり)
ぐらいだったのではないでしょうか。
①LLMの入出力結果をキャッシュして再利用する
①は、prompt cachingが出るまでは、キャッシュする方法を自作するしかありませんでした。
例えば、論文を入れれば要約してくれるサービスを提供している場合を考えてみてください。
一度入力された論文のLLMによる要約結果をキャッシュに入れておけば、同じ論文が入力された際にはキャッシュの中から要約結果を返すこともできるでしょう。
しかし、この方法は入力のパターンが限られたケースがメインの使い所になることはご理解いただけるでしょう。
この問題を根本的に解決してくれるのがOpenAIやAnthropicが提供するPrompt Cachingです。
(Geminiにもcontext cachingという同様の機能がありますが、こちらは少し使い勝手が悪いようです。)
このPrompt Cachingが凄いのは、入力となるプロンプトが全く同じ入力ではなくとも、プロンプト内の同じ箇所がキャッシュされるという点です
(厳密に言うと少し異なるのですが、)イメージで言えば、下記のようなプロンプトの場合、共通箇所をキャッシュしてくれます。
/*
* 共通箇所
* LLMがまもるべき前提条件や出力のルールが記載されている
*/
以上を踏まえて下記のユーザーの質問に答えてください。
{ユーザーからの入力}
このため、ユーザーからの入力が異なってもキャッシュしてくれるというのが、自作した場合との大きな違いです。
モデル内の計算の仕組みそのものに関わるため、モデル提供企業のみが為せるわざと言えます。
しかも、各社がキャッシュ機能を簡単に使える方法を用意してくれています。
実際には各社制限や特色が微妙に異なるので、詳細は確認してください。
キャッシュですので、当然有効期限があるため、リクエストの多いプロンプトで有効であるという制限はあります。
②自社でデータセットを作成して安価なモデルを作成 or ファインチューニングする
②はモデル自体を安くしようという発想です。
例えば、文章のトピック(記事の「経済」や「スポーツ」)や極性(コメントの「肯定的」「否定的」)の分類のようなタスクは、GPT-4oやClaude 3.5 Sonnetでなくとも解けなくはないタスクです。
(詳しくは『大規模言語モデル入門』などを参照してください。)
自社独自のタスクであっても、分類、判別、回帰系のようなタスクであれば、より軽量なモデルで解くことはできるはずです。
例えば、社内ルールについて回答するSlack botを作る際に、まずその質問が労務系や人事系か等に分類してから質問に答えるというユースケースを想像してください。
このような分類タスクは、「大量の学習用のデータがあれば」もっと軽量なモデルでも解くことができます。
ただし、この「大量の学習用のデータがあれば」という注釈が厄介です。
大量のデータセットを自社で作るのは非常に手間がかかります。
そこで、まずはこのようなタスクを解く処理をGPT-4oやClaude 3.5 Sonnetのような高度なモデルでリリースし、その入出力を記録しておいて、軽量なモデルの学習用のデータに使うという手段も思いつきます。
しかし、OpenAIの利用規約では、同社のサービスから得られる出力(アウトプット)を使用して、競合するモデルを開発することを禁止しています。
具体的には、禁止事項として、
アウトプットを使用して、OpenAIと競合するモデルを開発すること。
と明記されています。
これは当たり前といえば当たり前で、OpenAIからすれば自分たちのモデルの出力を利用して安価なモデルを作られてしまい、自社モデルを使ってくれなくなってしまっては商売あがったりです。
この問題をOpenAIが公式に解決してくれようとしているのが、今回のModel Distillationという訳です。
同じOpenAI社内のモデル同士であれば、高価なモデルのアウトプットを使って、安価なモデルを作ることをOpenAIが公式に推奨しているという大きな意味を持ちます。
逆を返せば、OpenAIのモデルを使って、オープンソースの技術を使って自作で安価なモデルを作ったり、他社のモデルをファインチューニングすることはやめて欲しいという明確なメッセージだとも取れます。
prompt cachingに比べれば、蒸留には少し手間はかかりますが、後述するように慣れてしまえばそこまで難しくはありません。
それで冒頭でも示したような劇的なコスト削減ができるのですから、是非試していただくとよいのではないでしょうか。
| モデル | 料金 |
|---|---|
| gpt-4o-2024-08-06 | $2.50 / 1M input tokens $10.00 / 1M output tokens |
| fine-tuned gpt-4o-mini | $0.30 / 1M input tokens $1.20 / 1M output tokens |
(※ここでは最新のgpt-4o-2024-08-06とファインチューニングされたGPT-4o-miniの比較だけを示した)
ただし、Model Distillationも無料ではないので、すべてのプロンプトを蒸留するのは得策ではありません。
超簡単に言えば、
Model Distillationコスト < API利用料削減コスト
にならなければなりません。
当然、投資回収期間は短い方がいいでしょうから、自社のアプリケーションの中でも利用数の多いプロンプトから優先順位をつけて蒸留していくのがよいでしょう。
蒸留の最大の注意点: 上位のモデル(GPT-4oやo1-preview)よりも基本的には劣化する
最大の注意事項があるとすれば、蒸留をしても、元にした上位のモデルを超えてくることはありません。
特に、OpenAIから提供されているModel Distillationでは、出力を修正することができないので、解決したいタスクに対して蒸留元の上位モデルの性能を超えてくることはありません。
何度かご紹介した『GPT-4o-miniのファインチューニングのすゝめ』という記事では、
GPT-4oの出力を人手で修正してからGPT-4o-miniに与えてファインチューニングしています。
この結果、特定のタスクにおいてファインチューニングされたGPT-4o-miniがGPT-4oの性能を超えてくるという結果を確認しています。
特に、分類、判別、回帰系のタスクは、ファインチューニングによる精度向上が見込めそうでした。
一方、文章作成などの自由度の高いタスクではファインチューニングの効果は比較的薄そうだという結果を得ています。
これは蒸留でも同じ傾向だと思います。
蒸留で気をつけるべき点は下記です。
(※GPT-4oをo1-preview、GPT-4o-miniをo1-miniと置き換えていただいても問題ありません。)
- ①GPT-4oでプロンプトエンジニアリングで十分な(95%以上?99%以上?の)精度を達成している入出力のデータを蓄積する
- 同じプロンプトでは名前のGPT-4o-miniの精度は7〜8割ぐらいだろう(数値は私の経験則)
- ②ファインチューニングされたGPT-4o-miniの精度を確かめるが、この際元のモデルよりも精度は数%下がる
①は、まず大きいモデルのプロンプトエンジニアリングで十分な性能を達成している必要があるということです。
ファインチューニングは入出力のセットを学習データとして行います。
ですので、基本的には蒸留元の大きいモデルのプロンプトとそのデータを用いてファインチューニングされた小さいモデルのプロンプトは同じものを使う方が望ましいです。
古いプロンプトで溜めた入出力データセットでファインチューニングし、あまり精度が出ないからと新しいプロンプトに変更してしまうと、古いプロンプトの学習結果は参考にしかなりません。
この観点からも十分プロンプトの改善が行われおり、ある程度安定稼働しているプロンプトに対して蒸留を行うべきだということになるでしょう。
②でGPT-4o-miniがどの程度①のGPT-4oの精度に近づけるかは、
a) 同じプロンプトで蒸留されていないGPT-4o-miniがどれくらいの精度を出せるタスクなのか、
b) 蒸留用のデータの数がどれくらいか
によります。
蒸留されていないGPT-4o-miniがどれくらいの精度を出せるタスクなのかはコントロールできる余地はあまりないので、
基本的には蒸留用のデータをたくさん与えてあげればあげるほど、GPT-4oの精度に近づくということにはなります。
タスクとプロンプトによるので一概には言えませんが、PharmaXでの経験則では、
数百から数千ぐらいのデータを与えて蒸留してあげれば、十分GPT-4oと遜色ないレベル(GPT-4oの95%以上)に達するように感じます。
(※あくまで私の経験則なので、実験してみていただければ幸いです。)
Model Distillationの使い方
さっそくModel Distillationの使い方を紹介していきますが、ここからは公式ドキュメントに準じます。
Model Distillationを使った蒸留の手順(※私の意訳を含む)は以下のとおりです。
- 蒸留のための入出力データを蓄積する
- 保存された入出力データに対して大小両方のモデルで評価し、ベースラインを確立する
- 保存された入出力から蒸留に使用するものを選択し、小さなモデルをファインチューニングする
- ファインチューニングされたモデルを評価し、大きなモデルの性能と比較する
1.蒸留のための入出力データを蓄積する
OpenAIの場合、データを蓄積するのは非常に簡単です。
下記のようにChat Completions APIで「store:true」を設定するだけです。
import OpenAI from "openai";
const openai = new OpenAI();
const response = await openai.chat.completions.create({
model: "gpt-4o",
messages: [
{ role: "system", content: "You are a corporate IT support expert." },
{ role: "user", content: "How can I hide the dock on my Mac?"},
],
store: true,
metadata: {
role: "manager",
department: "accounting",
source: "homepage"
}
});
console.log(response.choices[0]);
metadataは手順2・4で使う評価用のデータや、3でファインチューニングするデータを絞り込むのに用います(下図も参照)。

私たちは使用しているプロンプトごとに蒸留するためにプロンプト名をmetadataに入れています。
また、プロンプトのバージョン管理をLangSmithで行っているので、LangSmithで払い出されるcommit番号もmetadaに入れています。
データの蓄積については、下記のようにデータの保存期間は30日という制限があることにご注意ください。
このため、それなりにリクエストのある(1日最低数十リクエストぐらいは)プロンプトでなければ十分なデータが溜まらないということになるでしょう。
When using the store: true option, completions are stored for 30 days. Your completions may contain sensitive information and so, you may want to consider creating a new Project with limited access to store these completions.
このことから考えても、特にリクエスト数の多いプロンプトから蒸留するのがよいでしょう。
現時点では、データ蓄積のみならば無料(公式ドキュメント)なので、蓄積するデータ量が多くなりすぎることに気をつける必要はありません。
Stored Completions is available for free.
2.保存された入出力データに対して大小両方のモデルで評価し、ベースラインを確立する
次に蒸留でファインチューニングされたモデルの性能と比較するために大小両方のモデルの出力を評価します。
通常は、
小さいモデル < ファインチューニングされた小さいモデル < 大きいモデル
という性能になることが想定されます。
どの程度蒸留がうまく行っているかを確認するための基準(ベースライン)を設定するために、テストデータに対して大小のモデルので実行結果を評価するイメージです。
大きいモデルの性能に寄れば寄るほどファインチューニングがうまくいっているということになります。
この際、蒸留用の入出力データセットは大きいモデルから作られているので、再度大きいモデルで出力させ、評価する必要はあるのか?という疑問も浮かぶでしょう。
ですが、大きいモデルで再度実行してみて、どの程度出力がバラつくのか(精度が落ちるのか)を確認しておくことは重要です。
例えば、GPT-4oで98%の精度が出ていて、ファインチューニングされたGPT-4o-miniが97%だとしたら、ほぼGPT-4oとほぼ同等の精度が出ていると言ってもいいでしょう。
評価を実行するには、テスト対象のデータを選択して、Evaluateを押します。
この際、metadataなどで対象のデータをfilterすることが可能です。
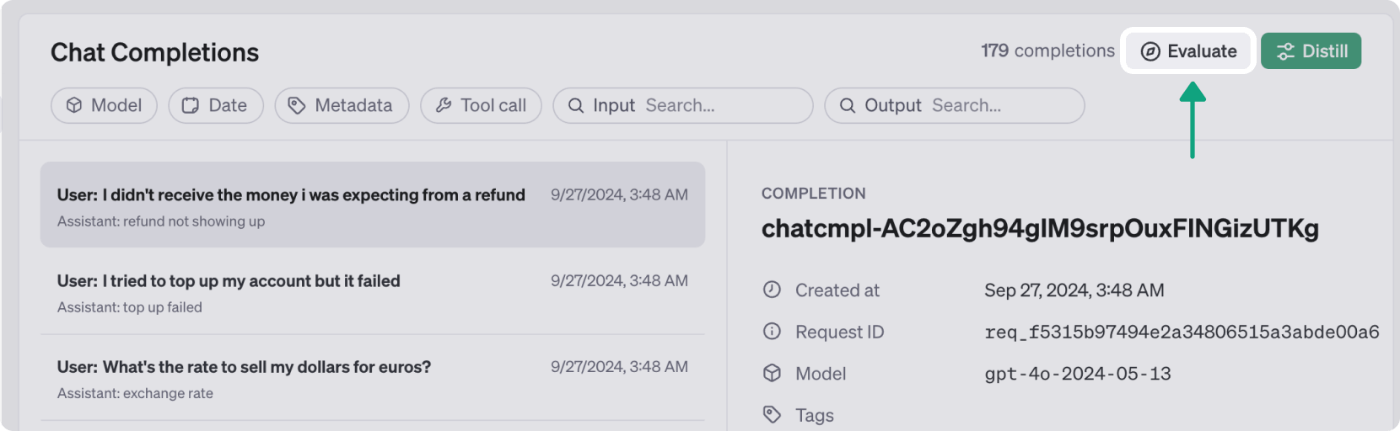
公式ドキュメントから引用
下記のようにEvaluate用の設定画面が開くので、諸々の設定を行います。
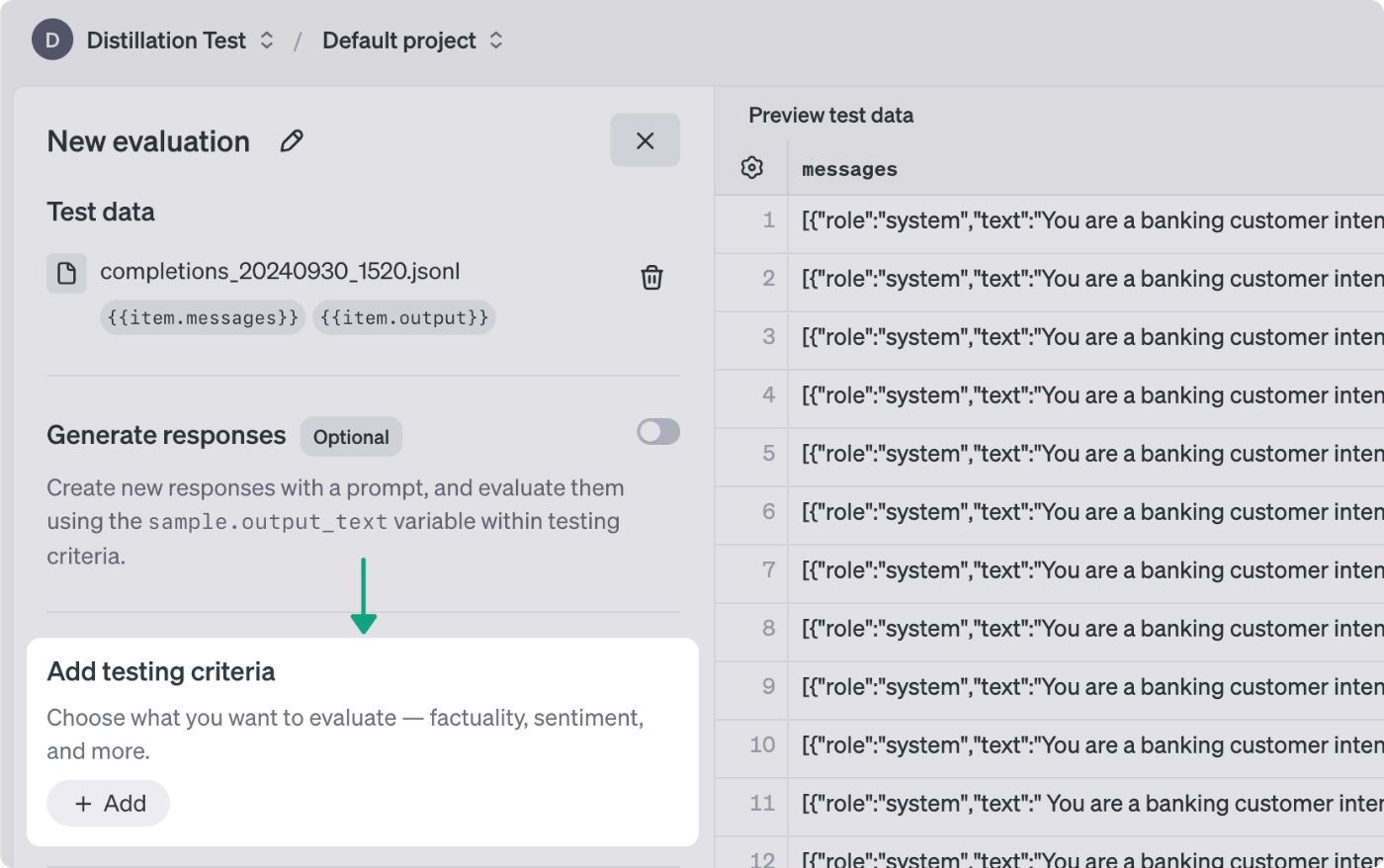
公式ドキュメントから引用
Add Testing Criteriaを押すと、評価指標を選択することが可能です。
評価として提供されているのは以下のような指標です。

1.事実性(Factuality)
モデルの応答内容が事実に基づいて正確かどうかを確認する基準です。正確な情報やデータの正しさが重要なタスクに役立ちます。
2.意味の類似性(Semantic similarity)
生成されたテキストと参照テキストを比較し、意味的にどれだけ類似しているかを確認する基準です。モデルの応答が期待する回答や解釈と一致しているかどうかを確認するのに役立ちます。
3.カスタムプロンプト(Custom prompt)
独自の評価基準を作成するためにカスタムプロンプトを定義できるオプションです。他の既存の基準でカバーしきれない特定のケースやシナリオのテストに柔軟に対応できます。
4.感情(Sentiment)
モデルの応答の感情的なトーン(ポジティブ、ネガティブ、中立など)を識別する基準です。応答の感情的な影響が重要なアプリケーションに役立ちます。
5.文字列チェック(String check)
モデルの応答に特定の文字列やキーワードが含まれているかどうかを確認する基準です。必要な用語やフレーズが含まれているかどうかを確認するのに役立ちます。
6.有効なJSONまたはXML(Valid JSON or XML)
モデルの応答が正しいJSONまたはXML形式であるかを検証する基準です。構造化データの出力が必要なアプリケーションに役立ちます。
7.スキーマの一致(Matches schema)
モデルの応答が指定された構造やスキーマに従っているかどうかを確認する基準です。予め定義された形式に従う必要がある応答に適しています。
8.基準の一致(Criteria match)
モデルの応答がユーザー定義の特定の基準を満たしているかどうかを評価します。主観的な評価が必要な場合に柔軟に利用できる基準です。
9.テキスト品質(Text quality)
BLEU、ROUGE、Cosineなどのアルゴリズムを用いて、応答の品質を評価する基準です。言語的な品質や参照テキストとの一致度を評価する際に役立ちます。
例えば、意味の類似性(Semantic similarity)であれば、テスト用データセットの出力とモデルで新たに出力した結果を比較します。
ある程度フォーマットが固定された出力で、テスト用データセットと同じような出力が出ていればいいのであれば、Semantic similarityで十分かもしれません。
下記のようにCustom promptを使えば、自由に評価基準を定義してLLMに評価させるLLM-as-a-Judgeを行うことも可能です。

公式ドキュメントから引用
LLM-as-a-Judgeについては下記の記事もご覧ください。
実際に実行してみると、添付の画像のように結果を見ることが出来ます。
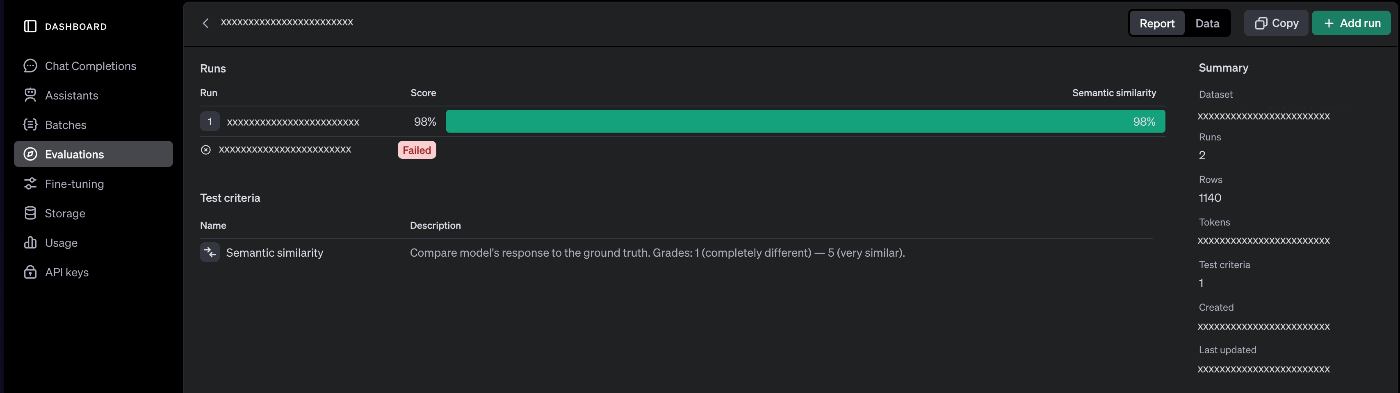
OpenAIのDashboardのEvaluationsから評価結果を確認
この例であれば、Semantic similarityを使っているので、データセットの出力と対象モデルで実行した出力とが98%で似ているということになります。
評価がFailになったデータは以下のように確認することも可能です。
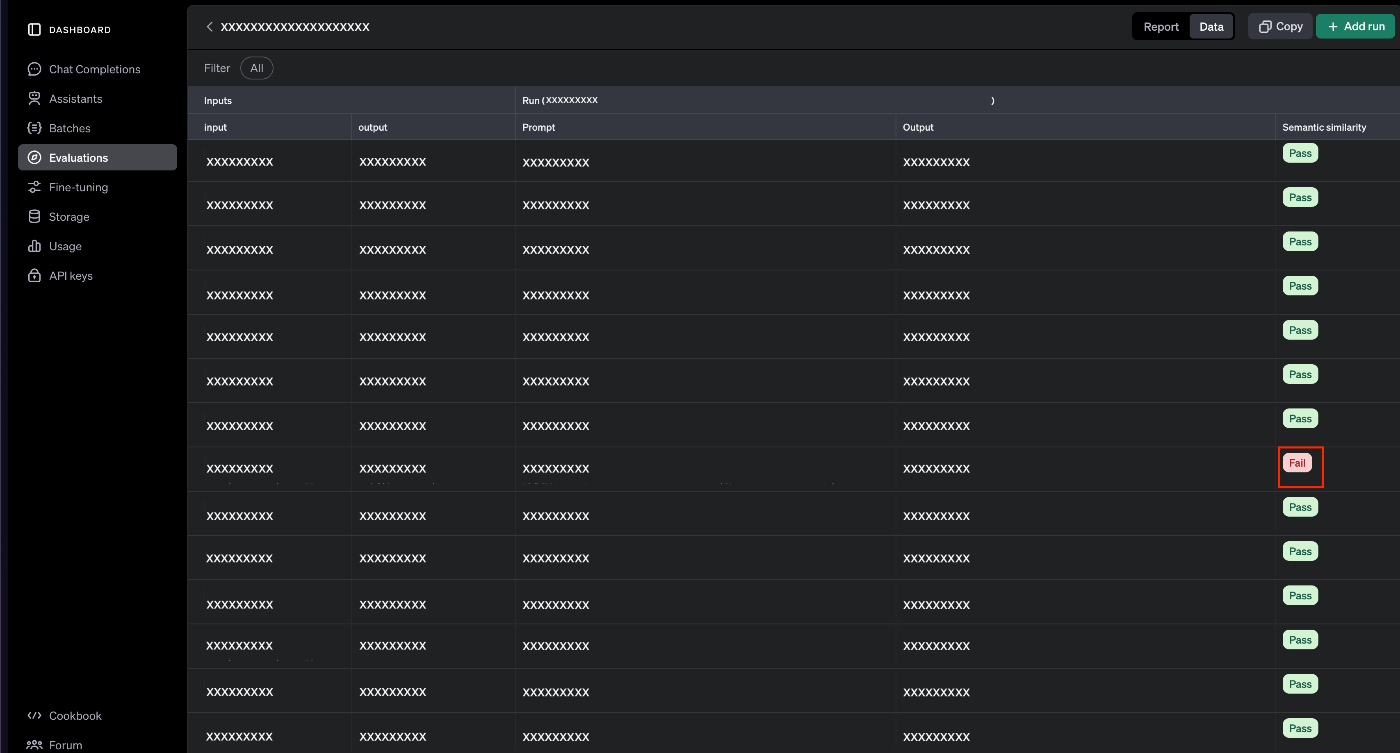
Evaluationsのデータタブから各データに対する結果を確認可能
3.保存された入出力から蒸留に使用するものを選択し、小さなモデルをファインチューニングする
蒸留も普通のファインチューニングと同じ手順で、非常に簡単にです。
OpenAIにGUIが用意されていくので、ボタンを押して行くだけです。
まず、学習用のデータセットを選択し、Distillを押します。
このとき評価と同じようにmetadata等でfilterすることが可能です。

公式ドキュメントから引用
そうすれば設定画面が開きます。
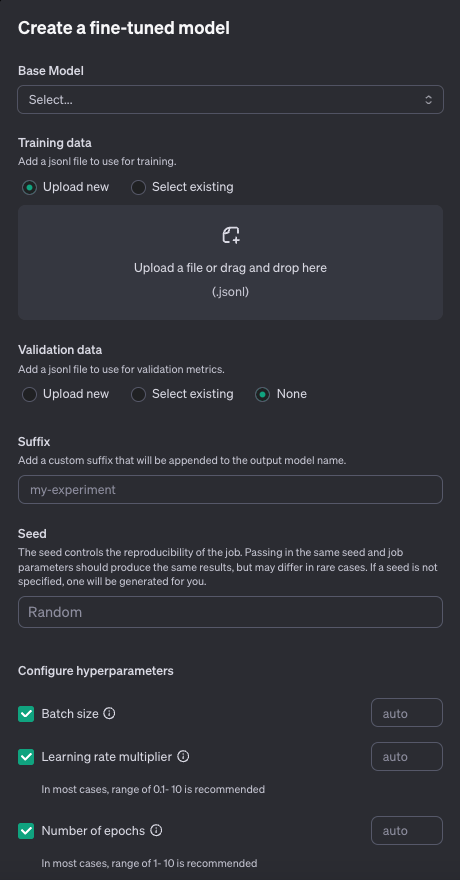
ベースとなるモデルを選択します。
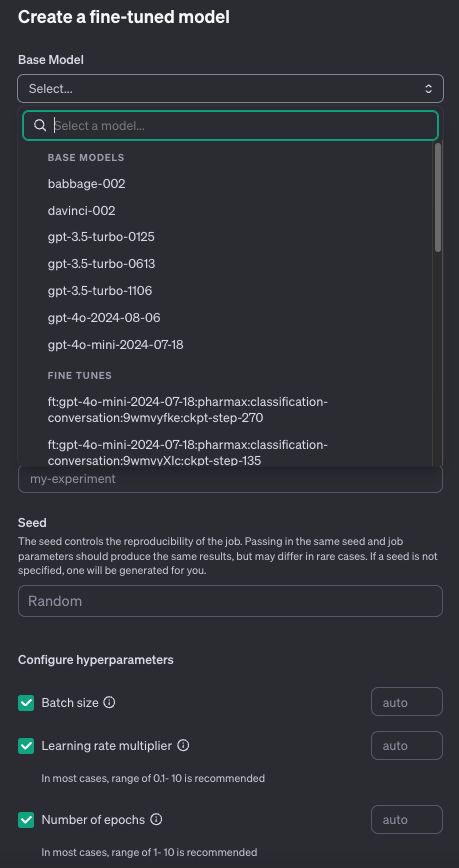
Training dataは上記で選択したデータセットが勝手に選ばれた状態になります。
モデルのsuffixをつけてあげます。これはファインチューニングしたモデルを区別するためです。
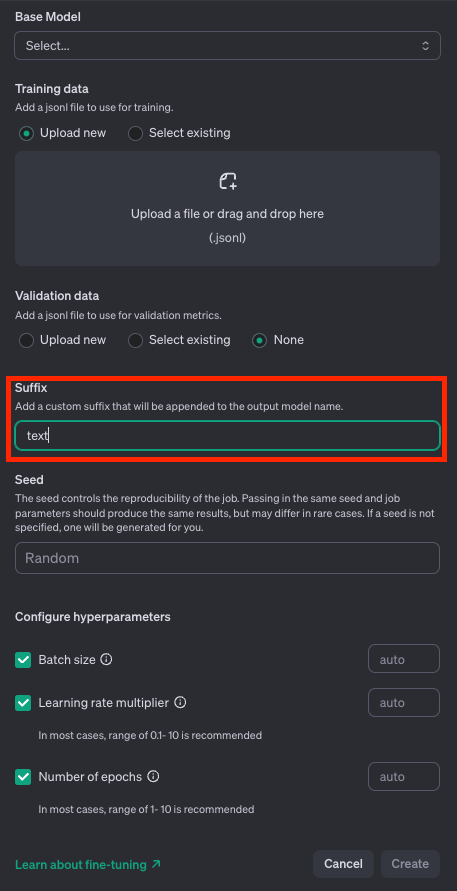
あとは、seedやパラメータを決めるだけですが、これはデフォルトのままでも大丈夫です。
色々試してみてはいかがでしょうか。
後は、Createを押して、待っていればファインチューニング可能です。
かなり簡単なのがお分かりいただけたかと思います。
4.ファインチューニングされたモデルを評価し、大きなモデルの性能と比較する
これは2で行った評価と同様です。
データセットを選択し、先程ファインチューニングしたモデルで実行し、結果を評価します。
この際、当然ながら2で使ったテストデータと同じものを使う必要があります。
結果は、2と同様に下記のように確認することが出来ます。
OpenAIのDashboardのEvaluationsから評価結果を確認
基準(ベースライン)として出力した大きなモデルの性能に近づけば蒸留はうまく行っているということになります。
まとめ
今回はOpenAIがDevDayで発表した蒸留機能であるModel Distillationについて紹介してきました。
蒸留は、運用中のLLMアプリケーションの非常に強力なコスト削減手段であり、OpenAIのダッシュボード上で非常に簡単に実施できるので、是非ご活用いただければと思います。
データ保存期間の制限など、OpenAI独自の制限はあるので、その点はご注意ください。
また、蒸留された(ファインチューニングされた)小さく安価なモデルの性能が、蒸留元の大きく高価なモデルの性能を超えることはないので、まずはプロンプトエンジニアリングを行い、大きなモデルで精度高く運用する必要があることに注意してください。
蒸留はあくまで十分にワークしているプロンプトを安価に運用するための手段でしかないと捉えるとよいと思います。
ビジネス的な価値が生み出せていないプロンプトのコストを削減しても仕方がないとも言えるので、まずはリリースしたLLMアプリケーションが十分に価値を発揮している状態を目指しましょう。
徐々に、継続的に運用されてビジネス上の価値を生むLLMアプリケーションも出てきているように感じます。
OpenAIがこのタイミングで蒸留機能を公式サポートしたということは、世界的にはLLMアプリケーションの運用フェーズに入っている企業も出てきているということでしょう。
今後OpenAIだけではなく、他社が追従して蒸留機能をサポートする可能性は十分にあると思いますので、是非試してみてはいかがでしょうか。
この記事がLLMアプリケーションの継続的改善を目指す皆さまの参考になれば嬉しいです。
PharmaXでは定期的にLLM関連のイベントを行っており、次回はLLMアプリケーションの評価を行います。
ご興味のある方は、是非ご参加いただければ嬉しいです!

PharmaXエンジニアチームのテックブログです。エンジニアメンバーが、PharmaXの事業を通じて得た技術的な知見や、チームマネジメントについての知見を共有します。 PharmaXエンジニアチームやメンバーの雰囲気が分かるような記事は、note(note.com/pharmax)もご覧ください。
Discussion