こんにちは。
PharmaXの上野(@ueniki)です。
今回は、これまで何度か取り上げてきたオンライン評価、特にオンラインでのLLM-as-a-JudgeをLangSmith上で簡単に行う方法についてご紹介します。
評価に関しては下記の記事もご参考にしていただければと思います。
基礎的なことからご紹介しているので、LLMアプリケーションの評価とは?というところから理解したい方は是非お読みいただければと思います。
LangSmithでは、オンライン評価を自動で行う設定をGUI上で行うことができる機能があります。
この方法であれば、オンライン評価を実装する必要がないため、簡単に実行可能です。
ただし、この方法を使える場面には制限があるので、制限もご紹介します。
また、そんな時にはどのようにオンラインLLM-as-a-Judgeを行うべきかもご紹介いたします。
LLMアプリケーションの評価とは
LLMをアプリケーションに組み込んでいると、LLMの出力を評価する必要が出てきます。
LLMの「出力は確率的である(毎回異なる)」ためです。
また、LLMの出力はハルシネーションを含む可能性がありますし、間違いではないにしてもサービス提供者の意図とは違った出力をエンドユーザーに提示してしまうかもしれません。
そのため、出力を評価して、ユーザーに正しい出力が提示されることを担保しましょうというのが評価の目的です。
ただし、LLMアプリケーションは、出力結果だけを評価すれば良いわけではありません。
こちらの記事では評価について基礎から解説し、評価には、複数のレイヤーがあるという話をしてきました。
抜粋すると以下のとおりです。
- レベル1: LLM機能・アプリケーションそのものに対する評価
- 出力に対するの評価
- 期待するアウトプット=Grand Truthと実際のアウトプットの比較
- 出力の妥当性の評価(LLM as a Judgeで扱う)
- レイテンシーなどの非機能要件の評価
- 出力に対するの評価
- レベル2: LLM機能・アプリケーションに対するユーザーの反応や挙動に対する評価
- ユーザーからの直接的なフィードバック(Good/Badボタンでの評価など)
- ユーザーの利用状況(クリック率や受入れ率など)
- レベル3: KPIが向上したかどうかの評価
LLMを組み込んだ機能やアプリケーションを作った目的はビジネス上の成果を達成することのはずです。
ですから、最終的には、そのLLM機能がゴールであるビジネス上のKPIを向上させたかどうかを評価する必要があります。
それがレベル3です。
その先行指標として、レベル1やレベル2の評価指標でも評価します。
その中でも、LLM-as-a-Judgeは、レベル1のLLMの出力の妥当性をLLMで評価する手法です。
評価指標を設定することの難しさは、『LLMアプリケーションの評価入門〜基礎から運用まで徹底解説〜』をご覧ください。
LLM-as-a-Judgeとは
上記でも述べたようにLLM-as-a-Judgeとは、LLM機能の出力の妥当性を"LLMで"評価するものです。
画像認識の機械学習モデルなら、画像認識の正解率を評価するので話は簡単です。
一方で、LLMは文章を生成するので、そう簡単にはいきません。
例えば、「日本で一番高い山は?」という質問に対して、
「富士山」
「富士山です」
「富士山に決まってんだろーが!」
「富士山。標高3776.12m。その優美な風貌は…(略)」
と答えるのはどれも正解です。
ですが、文章の生成は自由度が高すぎるので難しいのです。
正しいと言える出力の幅が広すぎると言うこともできるでしょうか。
評価方法の1つとして、期待するアウトプットと比較するという方法があります。
期待するアウトプットを定義し、期待するアウトプットとの文字列間の距離をEmbedding DistanceやLevenshtein Distanceでスコアリングすることで評価が可能です。
ただし、LLMの出力が正しいかどうかや期待するアウトプットとの差異だけではなく、様々な観点でサービスの要件を満たしているかを評価する必要があります。
例えば、
- 答え方が簡潔であるか
- ユーザーに出力するのに適した言葉遣いか
のような観点は、自社のアプリケーションの特性を考えて、自社なりの評価観点を定義する必要があります。
出力を基準に照らし合わせて、スコアリングする、もしくは、合格/不合格(True/False)を評価します。
ですが、色んな観点ですべての出力を人間が評価するのは現実的ではありません。
そのため、「LLMの出力をLLMを使って評価する」 LLM-as-a-Judgeという手法がよく使われるというわけです。
何よりLLMは疲れません。気分によって評価が変わるということもありません。
LLM-as-a-JudgeにLLMを使えば、出力をリアルタイムに評価し、評価結果をアプリケーションで活用することも可能になります。
LangSmithでのオンライン評価
LangSmithでは、GUI上でオンライン評価を設定し、自動で行うことのできる機能があります。
評価の設定
下記の画像のようなイメージでルールを追加すれば、それに該当するRunを自動的に評価することが可能です。
まずはAdd Ruleでルールを追加します。
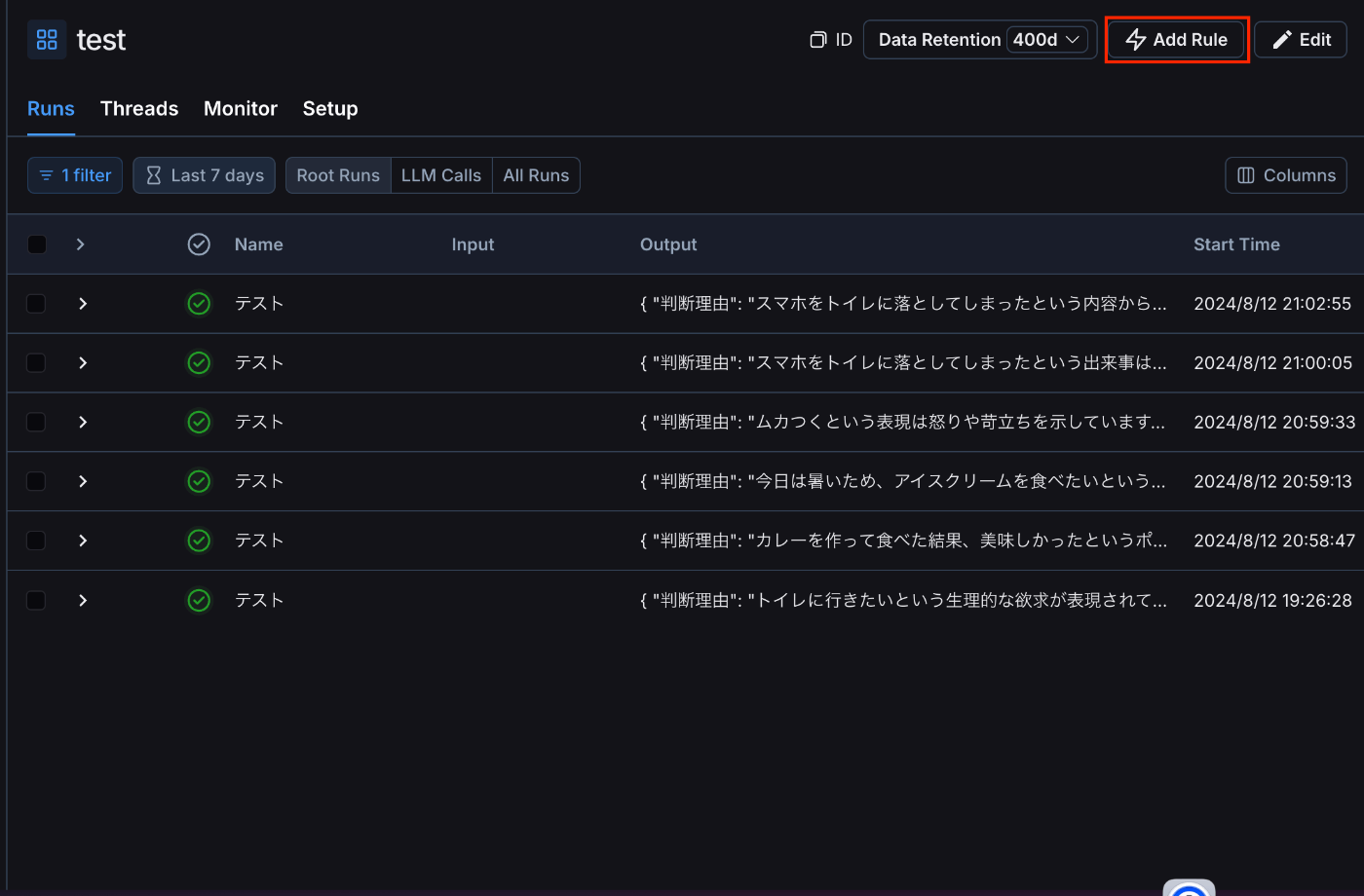
Actionとしては、Online evaluationを選択してください。
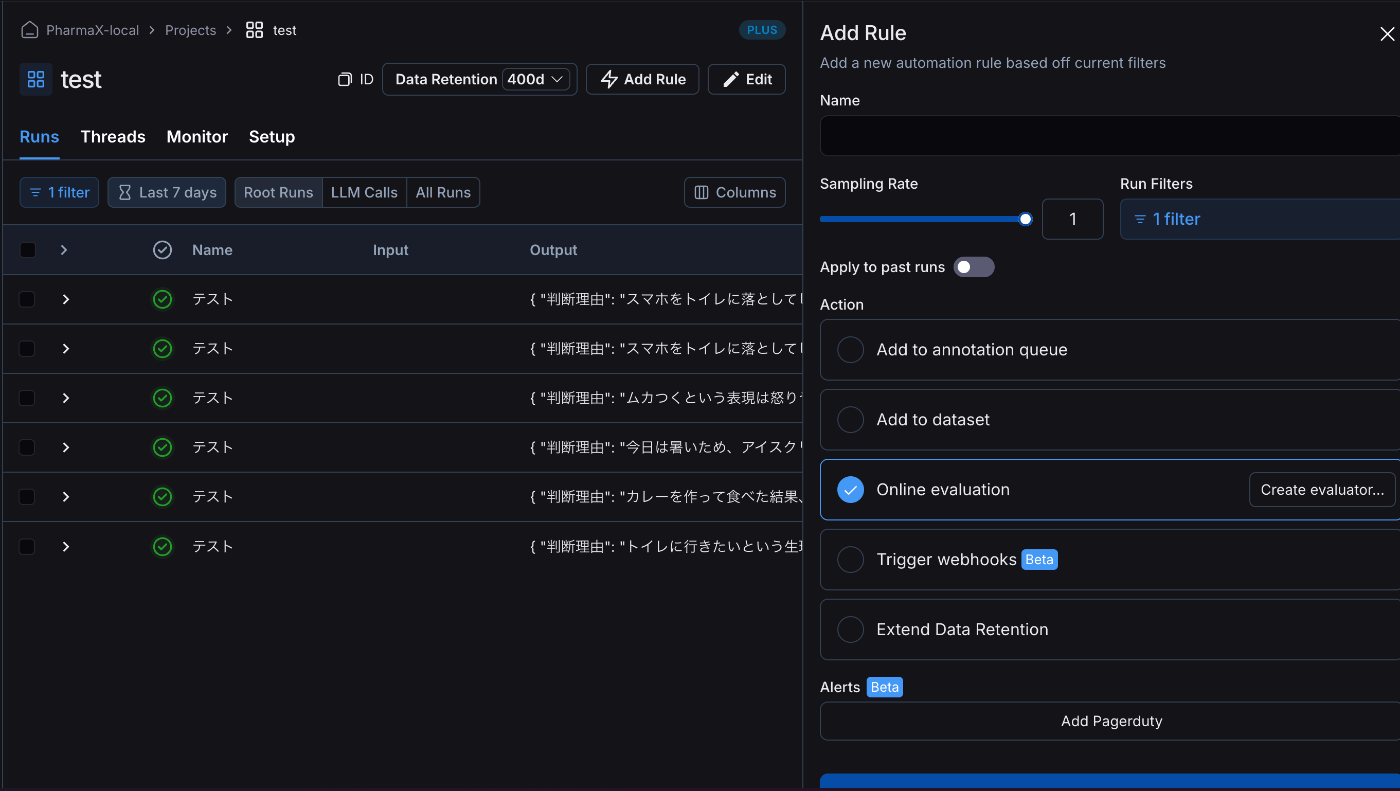
ルールの追加
評価方法を選択します。
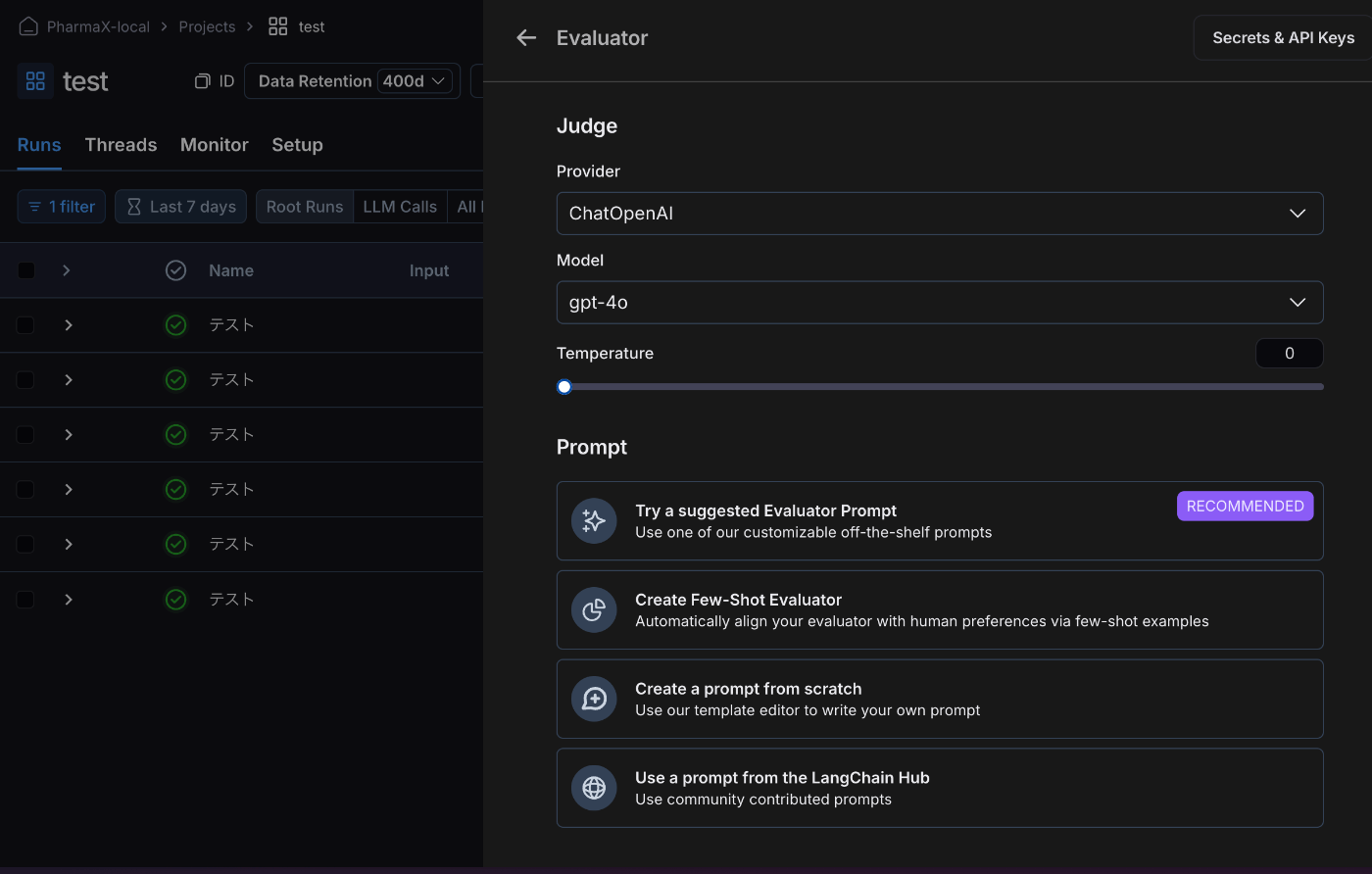
評価用方法の選択画面
例えば、Use a Prompt from the LangChain Hubを選択すると、LangChain Hubもしくは自作のプロンプトから選択することができます。

評価用のプロンプトを選択する
API Keyを入れなければ評価は動かないのでご注意ください。
実際に評価が実行されるとFeedbackとして記録されます。
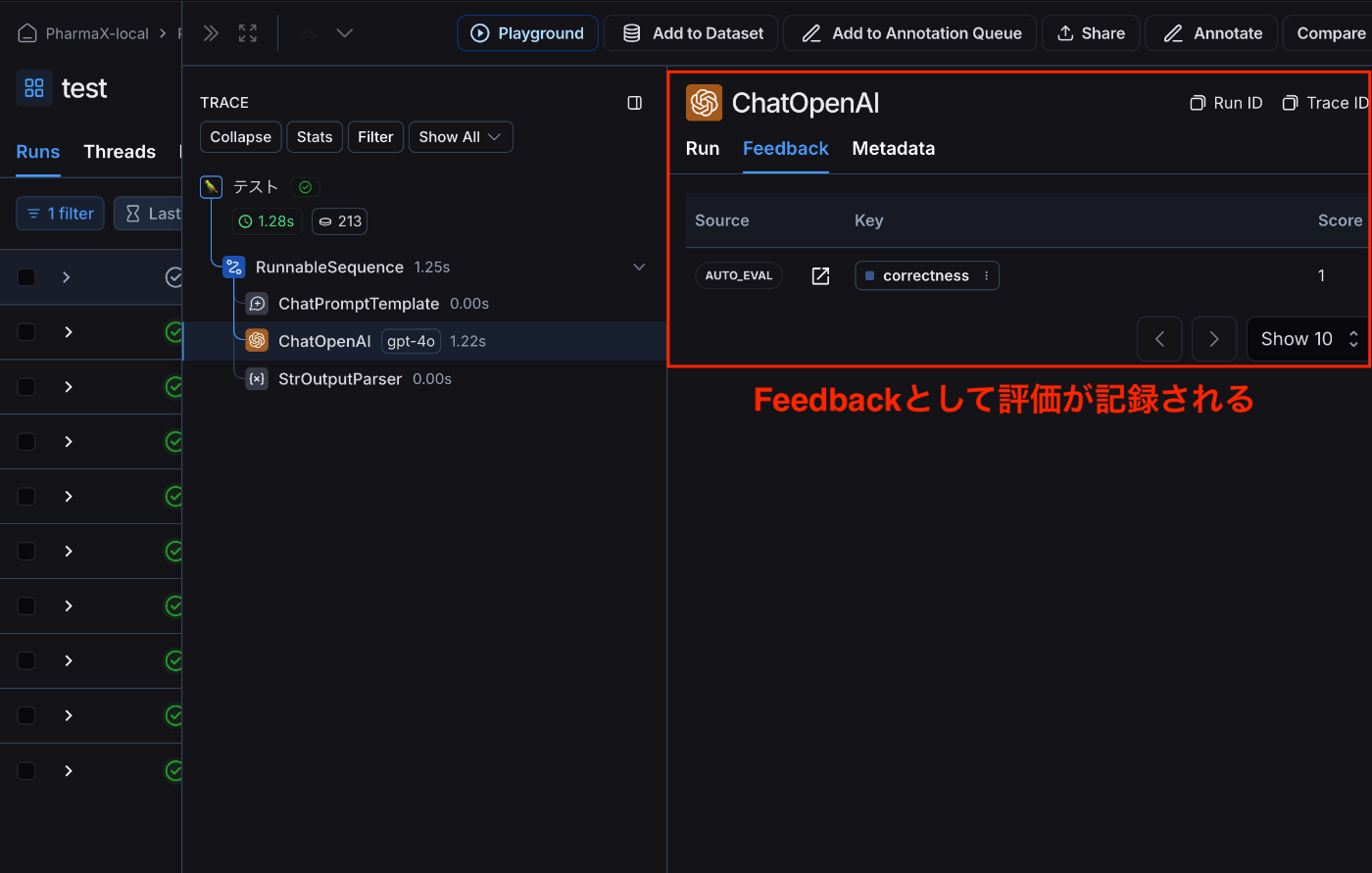
RunにFeedbackが記録される
ちなみに評価が実行されるまでには多少時間がかかります。
評価用プロンプトに関する注意
LangSmithが推奨しているというわけではないのですが、今回ご紹介したLangSmithの機能では、
評価用プロンプトのフォーマットがある程度決まってしまっています。
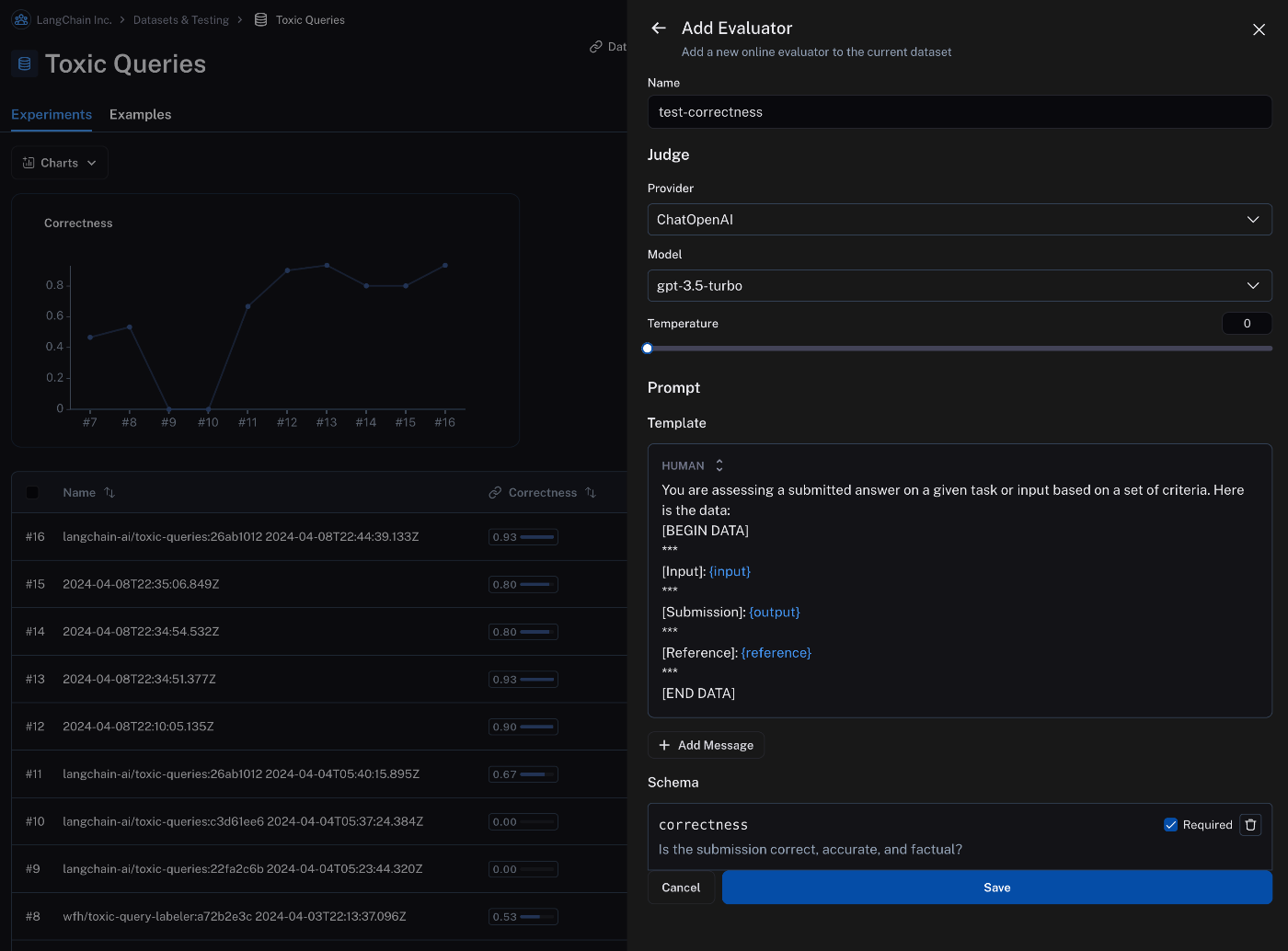
公式ドキュメントから引用
上記の画像では見えづらいかもしれないので、評価用のプロンプトだけを抜き出すと、
You are assersing a submitted answer on a given lask or input based on a set of criteria. Here in the data:
[BEGIN DATA]
***
[Input]: {input}
***
[Submission]: {output}
***
[Reference]: {reference}
***
[END DATA]
のようになっています。
イメージが付くでしょうか?
inputに"評価対象の出力"のinputを、outputに"評価対象の出力"を入れろということです。
比較するGrand Truthがあれば、referenceに入れます。
公式ドキュメントの文章を引用すると、
Automatic evaluators you configure in the application will only work if the inputs to your evaluation target, outputs from your evaluation target, and examples in your dataset are all single-key dictionaries. LangSmith will automatically extract the values from the dictionaries and pass them to the evaluator.
LangSmith currently doesn't support setting up evaluators in the application that act on multiple keys in the inputs or outputs or examples dictionaries.
(アプリケーションで設定した自動評価器は、評価ターゲットへの入力、評価ターゲットからの出力、データセット内の例がすべてシングルキーの辞書である場合にのみ動作します。LangSmith は自動的に辞書から値を抽出し、評価器に渡します。
LangSmithは現在のところ、入力や出力、サンプル辞書の複数のキーに作用する評価器の設定をサポートしていません。)
ということです。
確かにこの方式であれば、自由度はないですが、評価用のプロンプトのフォーマットを統一的に扱えます。
inputに評価対象のプロンプトが丸々入るので、出力に使われたすべての情報を評価用のプロンプトが見ることができます。
すなわち、評価用のプロンプトに評価観点で必要な情報を変数として1つ1つ代入しなくても、すべてはinputに評価対象のプロンプトを入れることで解決しています。
ただし、この書き方の問題点は、inputに評価対象のプロンプトが丸々入るので、評価対象のプロンプトも長い場合、
それを代入した評価用のプロンプトも非常に長くなってしまうことです。
コストが高くなってしまうというのもそうですが、それ以上にプロンプトが長くなることで、指示が利きづらくなってしまいそうです。
このような懸念はあるものの、LangSmithのオンライン評価では、現状この方式しかサポートされていないので従うしかありません。
評価の結果によって次の処理を変える場合にはLangSmith上でのオンライン評価は使えない
ここまで説明してきたようにLangSmith上でのオンライン評価は非常に簡単です。実装なしで評価が行えます。
ただし、注意があります。
評価の結果によって次の処理を変えたい場合には、今回ご紹介したLangSmith上でオンライン評価を行う方法は使いづらいです。
PharmaXのYOJOというサービスのメッセージサジェスト機能の例で言えば、評価が特定の値を下回った場合は、サジェストされたメッセージを修正して、再度LLMにサジェストさせ直させています。
このようにLLMの出力を評価し、評価の結果によって、再出力したり、出力を修正するような処理を組んでいる場合は、LLM-as-a-Judgeの結果をアプリケーションで受け取る必要があります。
ですので、今回ご紹介した方法のようにLangSmith上で評価が行われると、その結果をまたwebhookで受けて次のアクションをトリガーするような実装を行わなければイケなくなってしまいます。
確かに、Add Ruleでwebhookを設定する方法はあります。
しかし、webhookの結果が飛んでくるのはいつのタイミングになるかはわかりません。
出力の記録は遅くなってしまっても大した問題にはなりませんし、最悪の最悪、記録が落ちてしまってもアプリケーションには影響がないので、記録するだけならLangSmithの可用性や処理速度はあまり気にする必要がありません。
一方で、アプリケーションの処理のトリガーをLangSmithに任せてしまっては、気にすべき対象が増えてしまいます。
PharmaXのYOJOでは、オンラインLLM-as-a-JudgeもLLMによるメッセージサジェストと同等に扱い、一連の処理としてアプリケーション側で実行しています。
その結果、下の添付写真のようにメッセージ作成の次の評価の処理もでRunに記録されます。

評価も一連の処理として記録している
まとめ
今回は、LangSmith上でオンライン評価を簡単に実行する方法をご紹介しました。
制限はそれなりにあるものの、オンラインでのLLM-as-a-Judgeを試してみるにはいいのではないでしょうか。
オンラインでのLLM-as-a-Judgeはやってみて初めて気がつくことも多いので、サクッと始めてみると面白いかと思います。
もしなにかご質問やディスカッションしたいことがあれば、是非ご連絡いただければ嬉しいです!

PharmaXエンジニアチームのテックブログです。エンジニアメンバーが、PharmaXの事業を通じて得た技術的な知見や、チームマネジメントについての知見を共有します。 PharmaXエンジニアチームやメンバーの雰囲気が分かるような記事は、note(note.com/pharmax)もご覧ください。
Discussion